
1. Introdução
Neste codelab, você vai aprender a usar os processadores especializados da Document AI para classificar e analisar documentos especializados usando Python. Para a classificação e divisão, vamos usar um arquivo PDF de exemplo com faturas, recibos e extratos de serviços públicos. Em seguida, para a análise e a extração de entidades, vamos usar uma fatura como exemplo.
Esse procedimento e o exemplo de código funcionam com qualquer documento especializado compatível com a Document AI.
Pré-requisitos
Este codelab se baseia no conteúdo apresentado em outros codelabs da Document AI.
Recomendamos que você conclua os codelabs a seguir antes de continuar:
- Reconhecimento óptico de caracteres (OCR) com a Document AI e Python
- Análise de formulário com a Document AI (Python)
O que você vai aprender
- Como classificar e identificar pontos de divisão para documentos especializados.
- Como extrair entidades esquematizadas usando processadores especializados.
O que é necessário
2. Etapas da configuração
Este codelab parte do princípio de que você concluiu as etapas de configuração da Document AI listadas no Codelab básico.
Conclua as etapas a seguir antes de continuar:
Você também precisa instalar o Pandas, uma biblioteca de análise de dados conhecida para Python.
pip3 install --upgrade pandas
3. Criar processadores especializados
Primeiro, crie instâncias dos processadores que você vai usar neste tutorial.
- No console, navegue até a Visão geral do Document AI Platform.
- Clique em Criar processador, role para baixo até Especializado e selecione Divisor de documentos de compras.
- Nomeie como "codelab-procurement-splitter" ou de outra forma, desde que você se lembre. Em seguida, selecione a região mais próxima na lista.
- Clique em Criar para criar seu processador.
- Copie o ID do processador. Você precisará usá-la em seu código mais tarde.
- Repita as etapas de 2 a 6 com o analisador de faturas (que você pode nomear como "codelab-invoice-parser").
Testar o processador no console
É possível fazer upload de um documento para testar o analisador de faturas no console.
Clique em "Fazer upload do documento" e selecione uma fatura para analisar. É possível fazer o download e usar este exemplo de fatura se você não tiver um disponível.
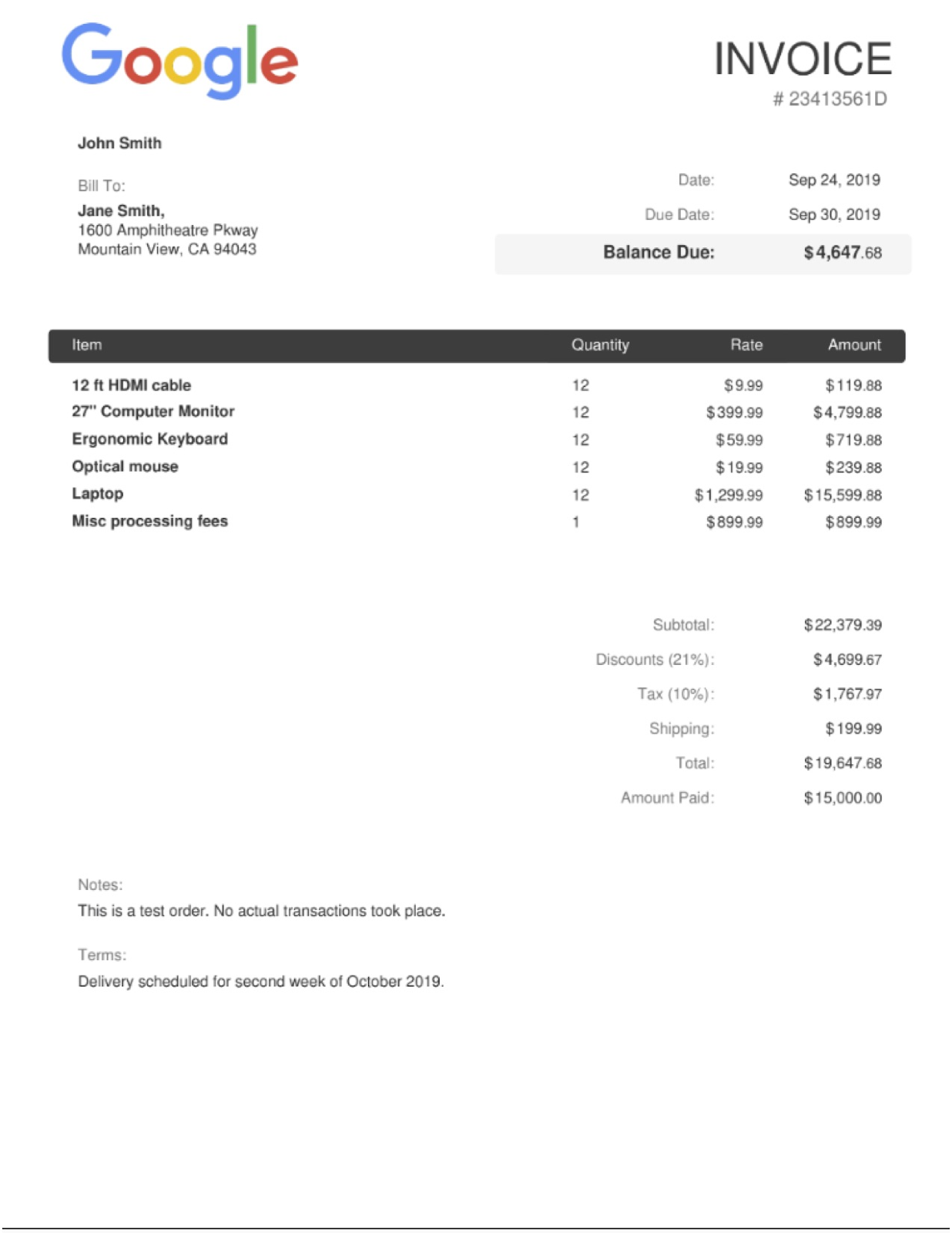
A saída será parecida com esta:
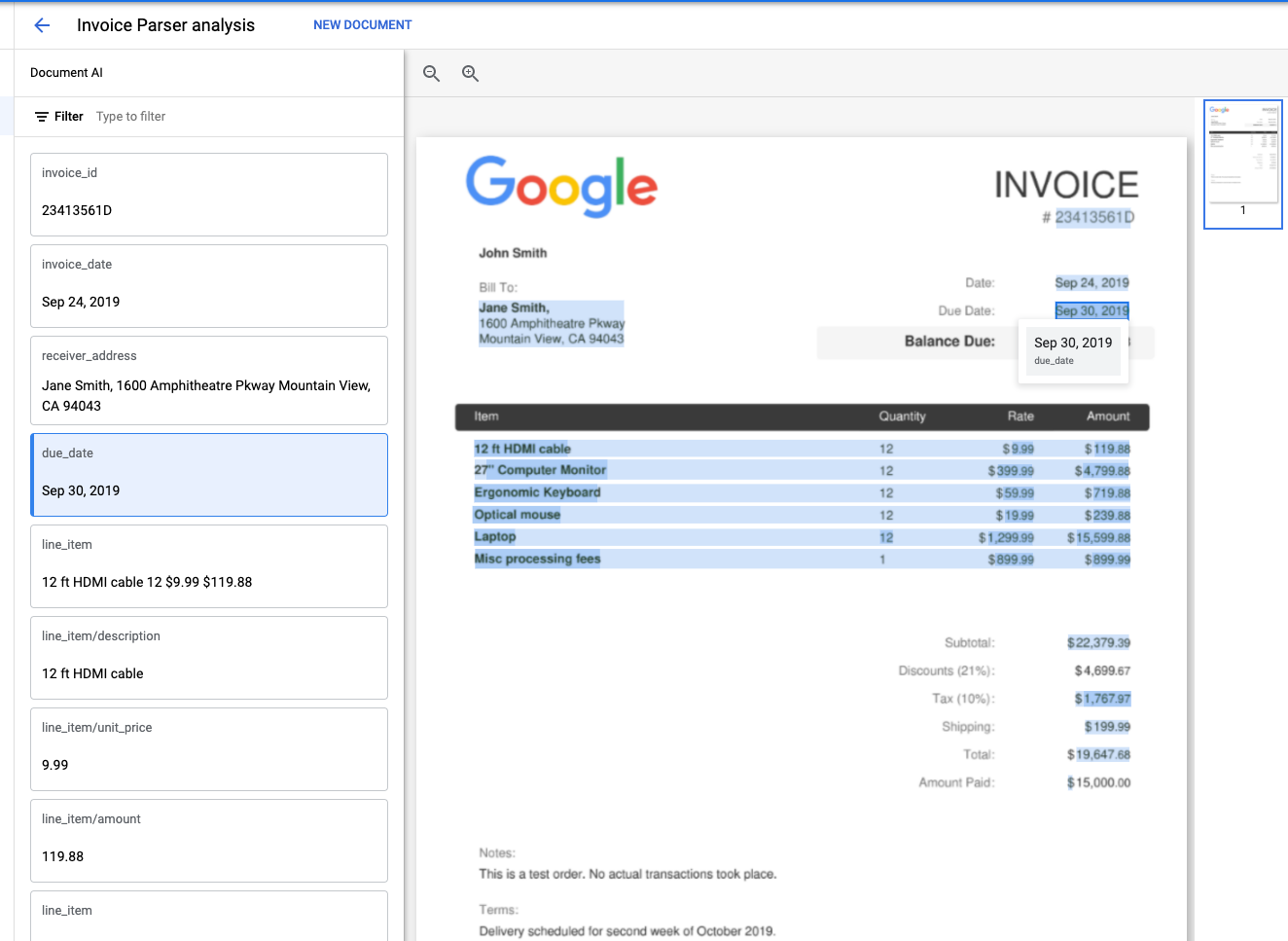
4. Baixar amostras de documentos
Temos alguns exemplos para usar neste laboratório.
Faça o download dos PDFs usando os links abaixo. Em seguida, faça o upload deles na instância do Cloud Shell.
Como alternativa, faça o download deles no bucket público do Cloud Storage usando gsutil.
gsutil cp gs://cloud-samples-data/documentai/codelabs/specialized-processors/procurement_multi_document.pdf .
gsutil cp gs://cloud-samples-data/documentai/codelabs/specialized-processors/google_invoice.pdf .
5. Classificar e dividir os documentos
Nesta etapa, você vai usar a API de processamento on-line para classificar e detectar pontos de divisão lógica em um documento de várias páginas.
Você também pode usar a API de processamento em lote se quiser enviar vários arquivos ou se o tamanho do arquivo exceder o máximo de páginas para processamento on-line. Consulte como fazer isso no codelab de OCR da Document AI.
O código para fazer a solicitação de API é idêntico para um operador geral, exceto o ID do operador.
Divisor/classificador de compras
Crie um arquivo chamado classification.py e use o código abaixo.
Substitua PROCUREMENT_SPLITTER_ID pelo ID do processador de divisão de compras que você criou anteriormente. Substitua YOUR_PROJECT_ID e YOUR_PROJECT_LOCATION pelo ID do projeto do Cloud e pela localização do processador, respectivamente.
classification.py
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as file:
file_content = file.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=file_content, mime_type=mime_type)
# Configure the process request
request = documentai.ProcessRequest(name=resource_name, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "PROCUREMENT_SPLITTER_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "procurement_multi_document.pdf"
# Refer to https://cloud.google.com/document-ai/docs/processors-list
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
print("Document processing complete.")
types = []
confidence = []
pages = []
# Each Document.entity is a classification
for entity in document.entities:
classification = entity.type_
types.append(classification)
confidence.append(f"{entity.confidence:.0%}")
# entity.page_ref contains the pages that match the classification
pages_list = []
for page_ref in entity.page_anchor.page_refs:
pages_list.append(page_ref.page)
pages.append(pages_list)
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame({"Classification": types, "Confidence": confidence, "Pages": pages})
print(df)
A saída será parecida com esta:
$ python3 classification.py
Document processing complete.
Classification Confidence Pages
0 invoice_statement 100% [0]
1 receipt_statement 98% [1]
2 other 81% [2]
3 utility_statement 100% [3]
4 restaurant_statement 100% [4]
O divisor/classificador de compras identificou corretamente os tipos de documentos nas páginas 0 a 1 e 3 a 4.
A página 2 contém um formulário de admissão médica genérico, então o classificador o identificou corretamente como other.
6. extrair as entidades
Agora você pode extrair as entidades esquematizadas dos arquivos, incluindo pontuações de confiança, propriedades e valores normalizados.
O código para fazer a solicitação de API é idêntico ao da etapa anterior e pode ser feito com solicitações on-line ou em lote.
Vamos acessar as seguintes informações das entidades:
- Tipo de entidade
- (por exemplo,
invoice_date,receiver_name,total_amount)
- (por exemplo,
- Valores brutos
- Valores de dados conforme apresentados no arquivo original do documento.
- Valores normalizados
- Valores de dados em um formato normalizado e padrão, se aplicável.
- Também pode incluir aprimoramento do Enterprise Knowledge Graph
- Níveis de confiança
- O quanto o modelo tem "certeza" de que os valores são precisos.
Alguns tipos de entidade, como line_item, também podem incluir propriedades, que são entidades aninhadas, como line_item/unit_price e line_item/description.
Este exemplo simplifica a estrutura aninhada para facilitar a visualização.
Analisador de faturas
Crie um arquivo chamado extraction.py e use o código abaixo.
Substitua INVOICE_PARSER_ID pelo ID do processador de análise de faturas que você criou antes e use o arquivo google_invoice.pdf
extraction.py
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as file:
file_content = file.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=file_content, mime_type=mime_type)
# Configure the process request
request = documentai.ProcessRequest(name=resource_name, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "INVOICE_PARSER_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "google_invoice.pdf"
# Refer to https://cloud.google.com/document-ai/docs/processors-list
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
types = []
raw_values = []
normalized_values = []
confidence = []
# Grab each key/value pair and their corresponding confidence scores.
for entity in document.entities:
types.append(entity.type_)
raw_values.append(entity.mention_text)
normalized_values.append(entity.normalized_value.text)
confidence.append(f"{entity.confidence:.0%}")
# Get Properties (Sub-Entities) with confidence scores
for prop in entity.properties:
types.append(prop.type_)
raw_values.append(prop.mention_text)
normalized_values.append(prop.normalized_value.text)
confidence.append(f"{prop.confidence:.0%}")
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame(
{
"Type": types,
"Raw Value": raw_values,
"Normalized Value": normalized_values,
"Confidence": confidence,
}
)
print(df)
A saída será parecida com esta:
$ python3 extraction.py
Type Raw Value Normalized Value Confidence
0 vat $1,767.97 100%
1 vat/tax_amount $1,767.97 1767.97 USD 0%
2 invoice_date Sep 24, 2019 2019-09-24 99%
3 due_date Sep 30, 2019 2019-09-30 99%
4 total_amount 19,647.68 19647.68 97%
5 total_tax_amount $1,767.97 1767.97 USD 92%
6 net_amount 22,379.39 22379.39 91%
7 receiver_name Jane Smith, 83%
8 invoice_id 23413561D 67%
9 receiver_address 1600 Amphitheatre Pkway\nMountain View, CA 94043 66%
10 freight_amount $199.99 199.99 USD 56%
11 currency $ USD 53%
12 supplier_name John Smith 19%
13 purchase_order 23413561D 1%
14 receiver_tax_id 23413561D 0%
15 supplier_iban 23413561D 0%
16 line_item 9.99 12 12 ft HDMI cable 119.88 100%
17 line_item/unit_price 9.99 9.99 90%
18 line_item/quantity 12 12 77%
19 line_item/description 12 ft HDMI cable 39%
20 line_item/amount 119.88 119.88 92%
21 line_item 12 399.99 27" Computer Monitor 4,799.88 100%
22 line_item/quantity 12 12 80%
23 line_item/unit_price 399.99 399.99 91%
24 line_item/description 27" Computer Monitor 15%
25 line_item/amount 4,799.88 4799.88 94%
26 line_item Ergonomic Keyboard 12 59.99 719.88 100%
27 line_item/description Ergonomic Keyboard 32%
28 line_item/quantity 12 12 76%
29 line_item/unit_price 59.99 59.99 92%
30 line_item/amount 719.88 719.88 94%
31 line_item Optical mouse 12 19.99 239.88 100%
32 line_item/description Optical mouse 26%
33 line_item/quantity 12 12 78%
34 line_item/unit_price 19.99 19.99 91%
35 line_item/amount 239.88 239.88 94%
36 line_item Laptop 12 1,299.99 15,599.88 100%
37 line_item/description Laptop 83%
38 line_item/quantity 12 12 76%
39 line_item/unit_price 1,299.99 1299.99 90%
40 line_item/amount 15,599.88 15599.88 94%
41 line_item Misc processing fees 899.99 899.99 1 100%
42 line_item/description Misc processing fees 22%
43 line_item/unit_price 899.99 899.99 91%
44 line_item/amount 899.99 899.99 94%
45 line_item/quantity 1 1 63%
7. Opcional: teste outros processadores especializados
Você conseguiu usar a Document AI para compras para classificar documentos e analisar uma fatura. A Document AI também aceita outras soluções especializadas listadas aqui:
Você pode seguir o mesmo procedimento e usar o mesmo código para lidar com qualquer processador especializado.
Se quiser testar outras soluções especializadas, execute o laboratório novamente com outros tipos de processadores e documentos de amostra especializados.
Documentos de amostra
Aqui estão alguns exemplos de documentos que você pode usar para testar os outros processadores especializados.
Solução | Tipo de processador | Documento |
Identidade | ||
Empréstimo | ||
Empréstimo | ||
Contratos |
Veja outros documentos de amostra e a saída do processador na documentação.
8. Parabéns
Parabéns! Você usou a Document AI para classificar e extrair dados de documentos especializados. Incentivamos você a testar outros tipos de documentos especializados.
Limpeza
Para evitar cobranças dos recursos usados neste tutorial na conta do Google Cloud, siga estas etapas:
- No console do Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto e clique em "Excluir".
- Na caixa de diálogo, digite o ID do projeto e clique em "Encerrar" para excluí-lo.
Saiba mais
Saiba mais sobre a Document AI com estes codelabs de acompanhamento.
- Gerenciamento de processadores da Document AI com Python
- Document AI: human in the loop
- Document AI Workbench: treinamento aprimorado
- Document AI Workbench: processadores personalizados
Recursos
- O futuro dos documentos — Playlist do YouTube (em inglês)
- Documentação da Document AI
- Biblioteca de cliente Python da Document AI
- Amostras da Document AI
Licença
Este conteúdo está sob a licença Atribuição 2.0 Genérica da Creative Commons.