
1. מבוא
Document AI הוא פתרון להבנת מסמכים שמקבל נתונים לא מובנים, כמו מסמכים, אימיילים וכו', והופך את הנתונים לקלים יותר להבנה, לניתוח ולשימוש.
בעזרת שיפור המודל באמצעות Document AI Workbench, אתם יכולים להשיג רמת דיוק גבוהה יותר בעיבוד מסמכים. לשם כך, אתם יכולים לספק דוגמאות מסומנות נוספות לסוגים מיוחדים של מסמכים וליצור גרסה חדשה של המודל.
בשיעור ה-Lab הזה תיצרו מעבד לניתוח חשבוניות, תגדירו את המעבד לאימון מתקדם, תתייגו מסמכים לדוגמה ותבצעו אימון מתקדם של המעבד.
מערך הנתונים של המסמכים שבו משתמשים בשיעור ה-Lab הזה מורכב מחשבוניות שנוצרו באופן אקראי עבור חברת צנרת פיקטיבית.
דרישות מוקדמות
ה-Codelab הזה מבוסס על תוכן שמוצג ב-Codelabs אחרים של Document AI.
מומלץ להשלים את ה-Codelabs הבאים לפני שממשיכים.
- זיהוי תווים אופטי (OCR) באמצעות Document AI (Python)
- ניתוח טפסים באמצעות Document AI (Python)
- מעבדים ייעודיים עם Document AI (Python)
- ניהול מעבדים של Document AI באמצעות Python
- Document AI: האדם שבתהליך
מה תלמדו
- הגדרת שיפור מתמשך למעבד Invoice Parser.
- מתייגים נתוני אימון של Document AI באמצעות כלי ההערות.
- מאמנים גרסה חדשה של המודל.
- בודקים את רמת הדיוק של גרסת המודל החדשה.
מה תצטרכו
2. תהליך ההגדרה
ב-Codelab הזה מניחים שהשלמתם את שלבי ההגדרה של Document AI שמפורטים ב-Codelab המבואי.
לפני שממשיכים, צריך לבצע את הפעולות הבאות:
3. יצירת מעבד
כדי להשתמש בשיעור ה-Lab הזה, צריך קודם ליצור מעבד Invoice Parser.
- במסוף, עוברים לדף סקירת AI של Document AI.

- לוחצים על Create Processor (יצירת מעבד), גוללים למטה אל Specialized (התמחות) (או מקלידים "Invoice Parser" (מנתח חשבוניות) בסרגל החיפוש) ובוחרים באפשרות Invoice Parser (מנתח חשבוניות).

- נותנים לו את השם
codelab-invoice-uptraining(או שם אחר שתזכרו) ובוחרים את האזור הכי קרוב ברשימה.

- לוחצים על יצירה כדי ליצור את המעבד. אחרי כן יוצג הדף 'סקירה כללית של מעבד המידע'.

4. יצירת קבוצת נתונים
כדי לאמן את המעבד, נצטרך ליצור מערך נתונים עם נתוני אימון ובדיקה שיעזרו למעבד לזהות את הישויות שאנחנו רוצים לחלץ.
תצטרכו ליצור קטגוריה חדשה ב-Cloud Storage כדי לאחסן את מערך הנתונים. הערה: לא מומלץ להשתמש באותה קטגוריית אחסון שבה המסמכים מאוחסנים כרגע.
- פותחים את Cloud Shell ומריצים את הפקודות הבאות כדי ליצור קטגוריה. אפשר גם ליצור מאגר חדש ב-Cloud Console. חשוב לשמור את השם של הקטגוריה, כי תצטרכו להשתמש בו בהמשך.
export PROJECT_ID=$(gcloud config get-value project)
gsutil mb -p $PROJECT_ID "gs://${PROJECT_ID}-uptraining-codelab"
- עוברים לכרטיסייה Dataset ולוחצים על Create Dataset.

- מדביקים את שם הקטגוריה מהקטגוריה שיצרתם בשלב הראשון בשדה Destination Path (נתיב יעד). (לא כולל
gs://)

- מחכים שמערך הנתונים ייווצר, ואז אמורים להיות מועברים לדף ניהול מערך הנתונים.

5. ייבוא מסמך בדיקה
עכשיו נייבא קובץ PDF של חשבונית לדוגמה למערך הנתונים שלנו.
- לוחצים על ייבוא מסמכים.

- יש לנו קובץ PDF לדוגמה שתוכלו להשתמש בו בשיעור ה-Lab הזה. מעתיקים את הקישור הבא ומדביקים אותו בתיבה Source Path (נתיב המקור). בינתיים, משאירים את האפשרות 'פיצול נתונים' כ-'לא הוקצה'. לוחצים על ייבוא.
cloud-samples-data/documentai/codelabs/uptraining/pdfs
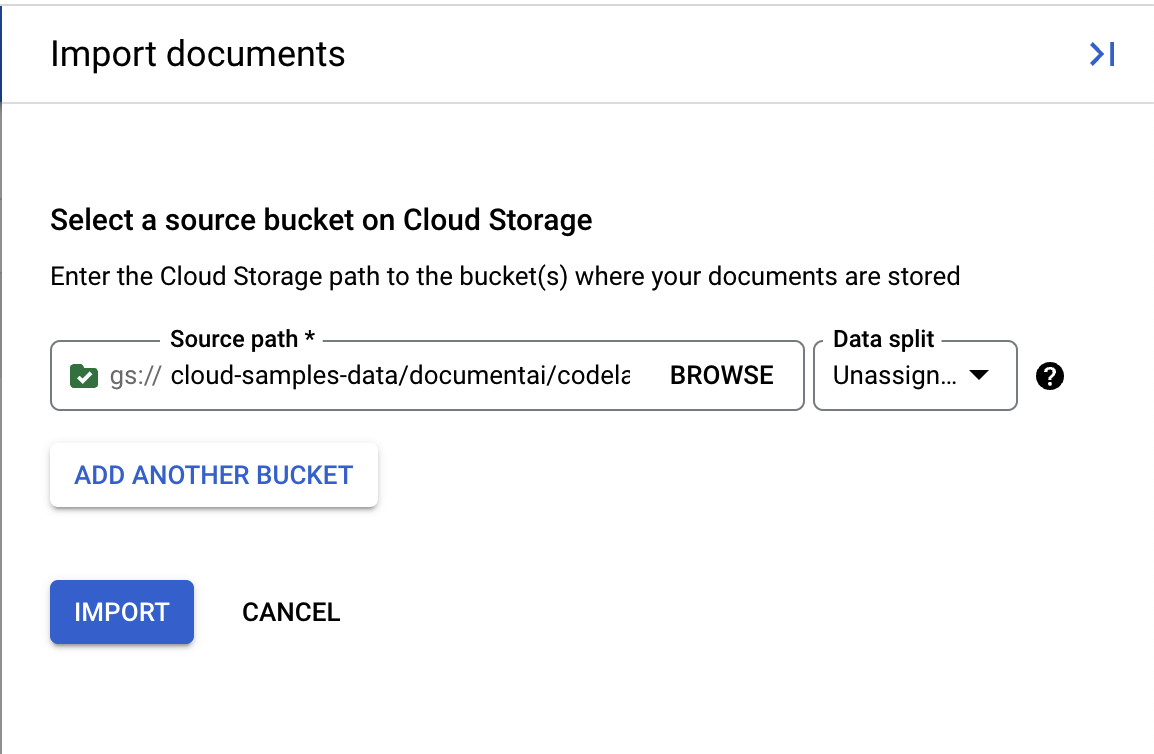
- ממתינים לייבוא המסמך. בבדיקות שלי, התהליך נמשך פחות מדקה.

- בסיום הייבוא, המסמך אמור להופיע בממשק המשתמש של ניהול מערך הנתונים. לוחצים עליו כדי להיכנס למסוף התיוג.
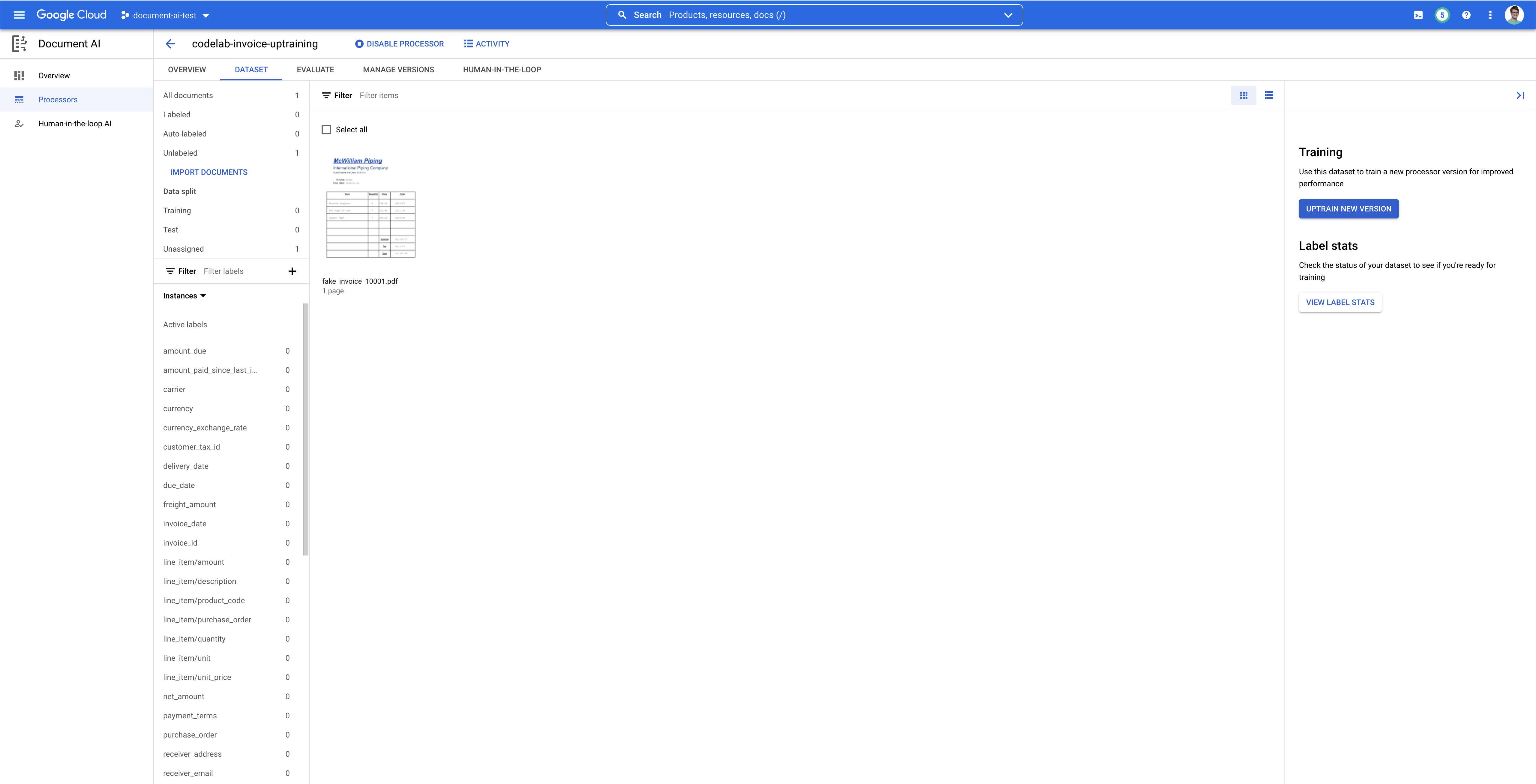
6. הוספת תוויות למסמך הבדיקה
בשלב הבא נזהה רכיבי טקסט ותוויות של הישויות שאנחנו רוצים לחלץ. התוויות האלה ישמשו לאימון המודל שלנו כדי לנתח את מבנה המסמך הספציפי הזה ולזהות את הסוגים הנכונים.
- עכשיו אתם אמורים להיות במסוף התיוג, שייראה בערך כך.

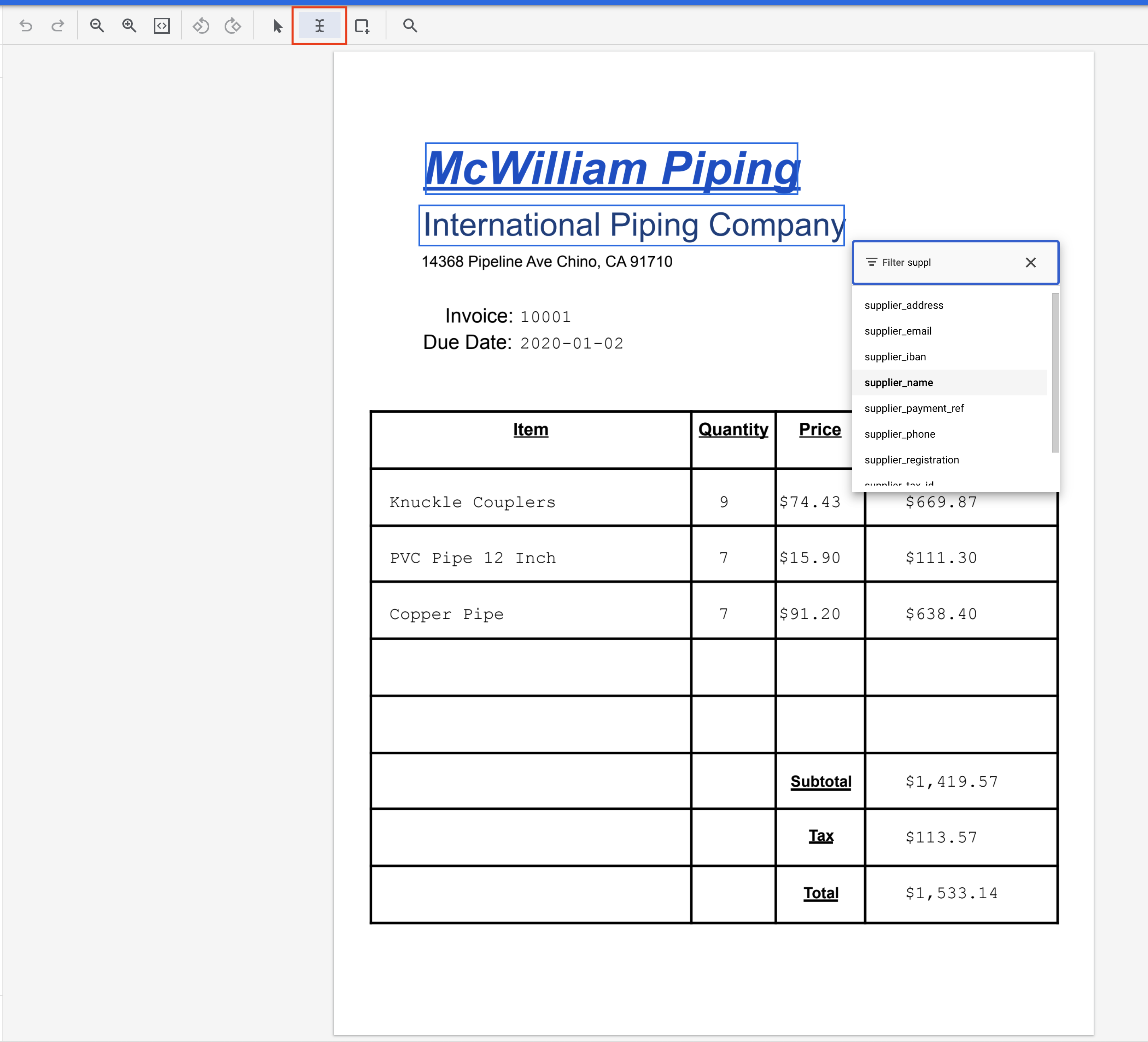
- לוחצים על הכלי 'בחירת טקסט', מדגישים את הטקסט 'McWilliam Piping International Piping Company' ומקצים את התווית
supplier_name. אפשר להשתמש במסנן הטקסט כדי לחפש שמות של תוויות.
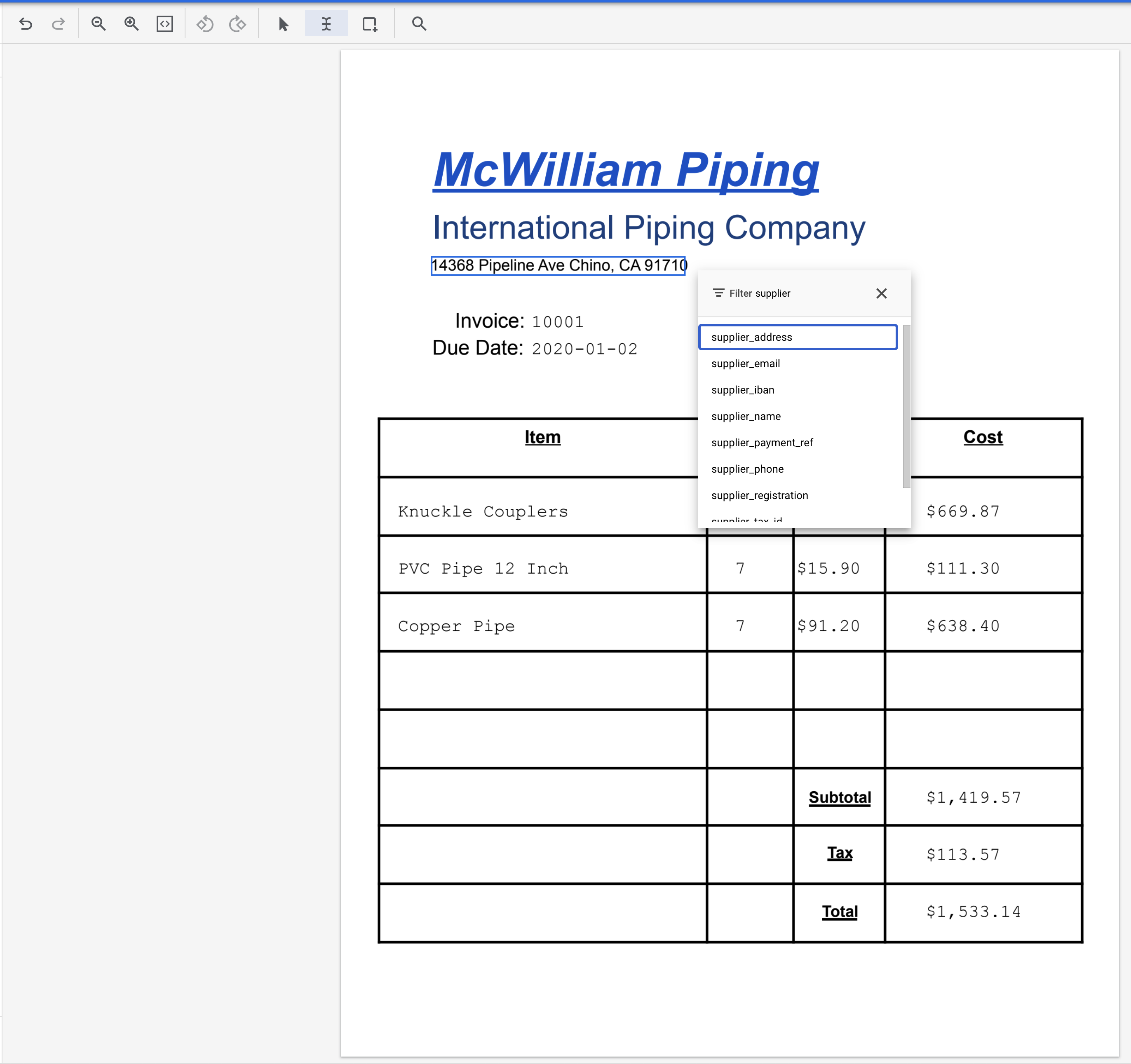
- מדגישים את הטקסט '14368 Pipeline Ave Chino, CA 91710' ומקצים את התווית
supplier_address.
- מדגישים את הטקסט '10001' ומקצים את התווית
invoice_id.
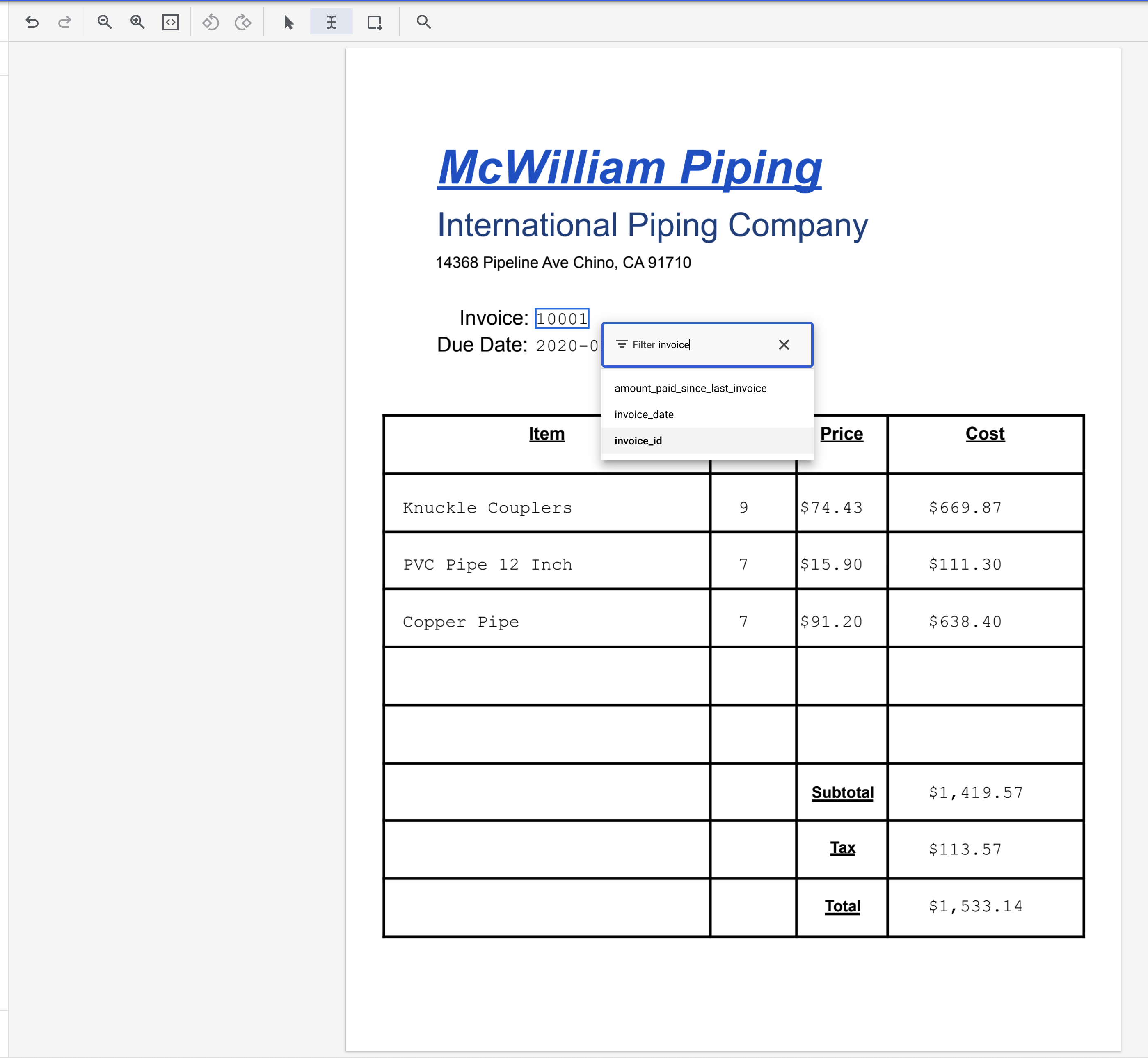
- מדגישים את הטקסט '2020-01-02' ומקצים את התווית
due_date.

- עוברים לכלי 'תיבת תוחמת'. מדגישים את הטקסט Knuckle Couplers (חיבורי מפרק) ומקצים את התווית
line_item/description.

- מדגישים את הטקסט '9' ומקצים את התווית
line_item/quantity.

- מדגישים את הטקסט '74.43' ומקצים את התווית
line_item/unit_price.
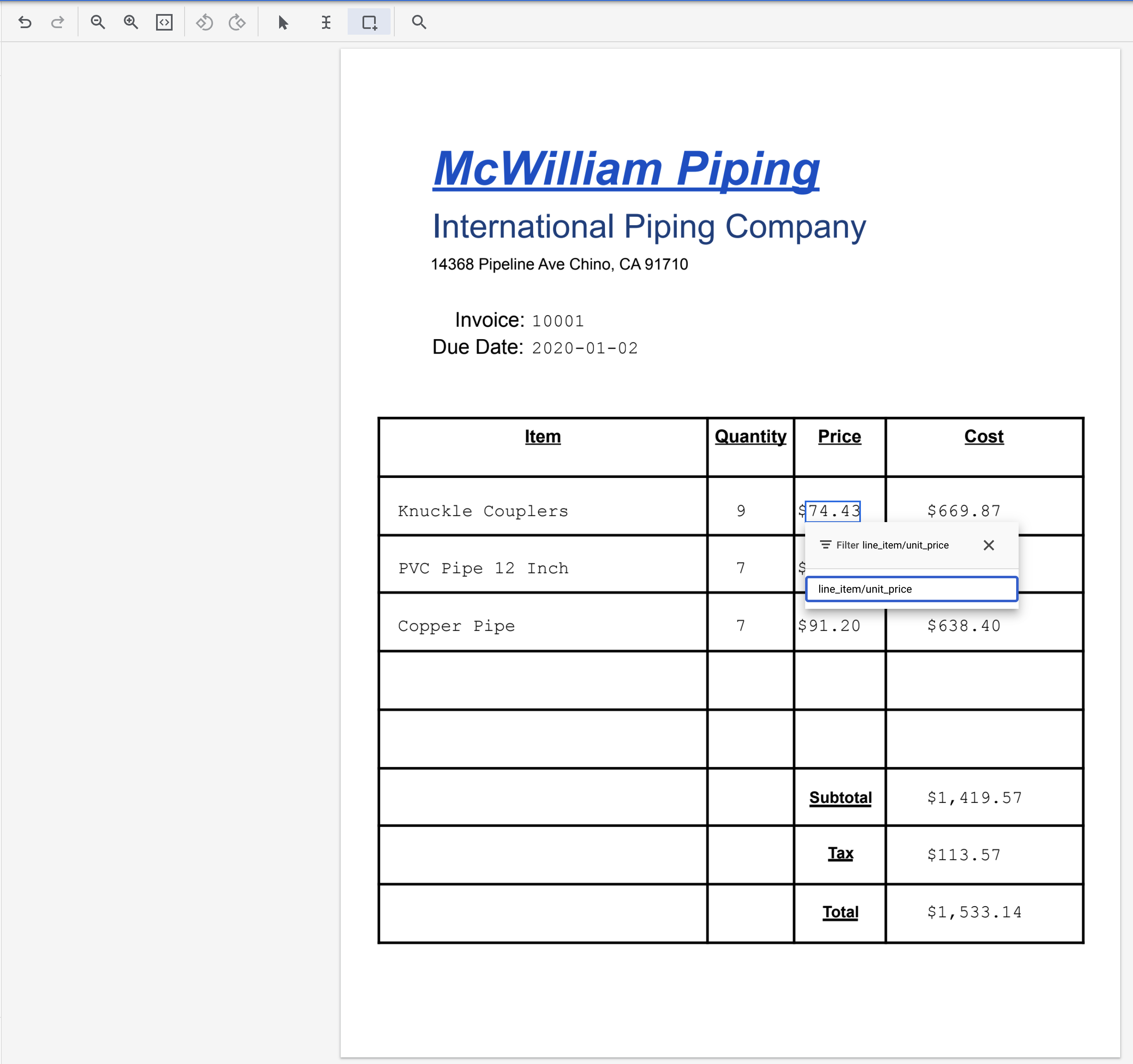
- מדגישים את הטקסט '669.87' ומקצים את התווית
line_item/amount.

- חוזרים על 4 השלבים הקודמים לגבי שני פריטי הקו הבאים. כך זה אמור להיראות בסיום.

- מדגישים את הטקסט '1,419.57' (לצד 'סיכום ביניים') ומקצים את התווית
net_amount.
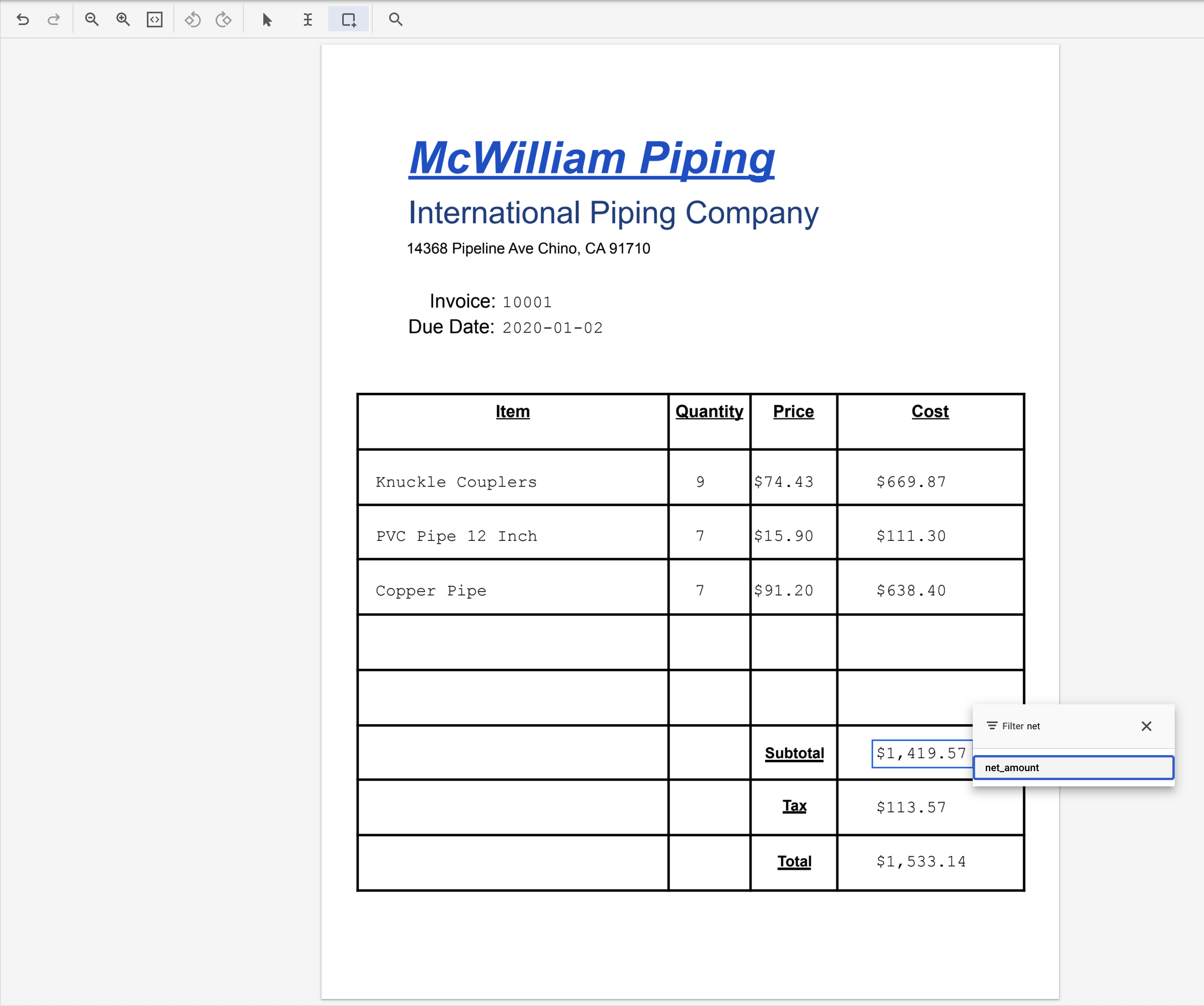
- מדגישים את הטקסט '113.57' (ליד 'מס') ומקצים את התווית
total_tax_amount.

- מדגישים את הטקסט '1,533.14' (לצד 'סך הכול') ומקצים את התווית
total_amount.

- מסמנים את אחד מהתווים '$' ומקצים את התווית
currency.

- כך צריך להיראות המסמך המתויג בסיום התהליך. הערה: אפשר לבצע שינויים בתוויות האלה בלחיצה על תיבה תוחמת (bounding box) במסמך או על השם או הערך של התווית בתפריט צד. בסיום התיוג, לוחצים על שמירה.

- הרשימה המלאה של התוויות והערכים
שם התווית | טקסט |
| McWilliam Piping International Piping Company |
| 14368 Pipeline Ave Chino, CA 91710 |
| 10001 |
| 2020-01-02 |
| מחברי אגרוף |
| 9 |
| 74.43 |
| 669.87 |
| צינור PVC 12 אינץ' |
| 7 |
| 15.90 |
| 111.30 |
| צינורות נחושת |
| 7 |
| 91.20 |
| 638.40 |
| 1,419.57 |
| 113.57 |
| 1,533.14 |
| $ |
7. הקצאת מסמך לקבוצת נתונים לאימון
עכשיו אתם אמורים לחזור למסוף לניהול מערכי נתונים. שימו לב שמספר המסמכים המתויגים והלא מתויגים השתנה, וגם מספר התוויות הפעילות.

- אנחנו צריכים להקצות את המסמך הזה לקבוצה 'אימון' או לקבוצה 'בדיקה'. לוחצים על המסמך.

- לוחצים על הקצאה לערכה ואז על אימון.
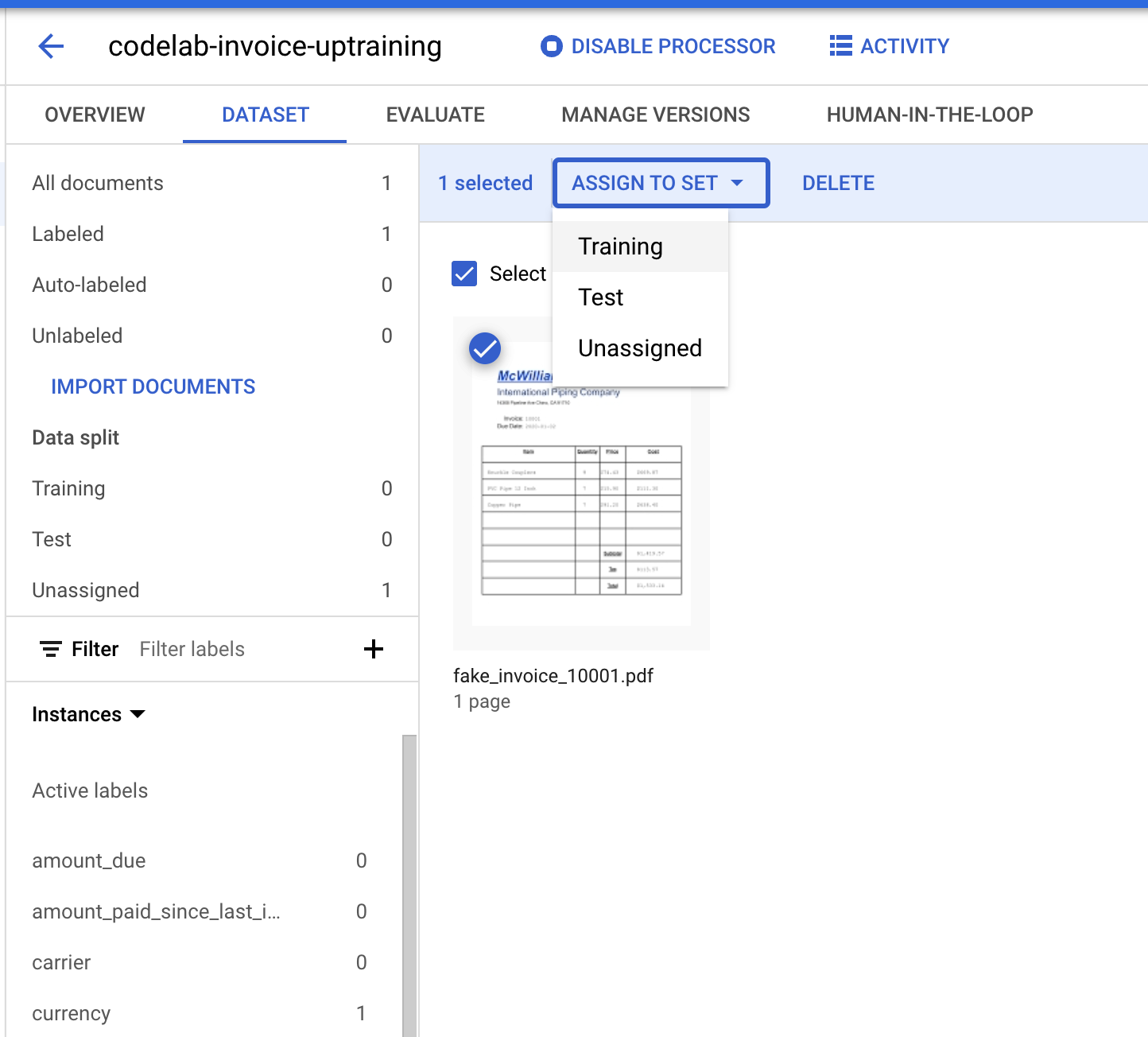
- שימו לב שהמספרים של חלוקת הנתונים השתנו.

8. ייבוא נתונים שכבר סומנו
כדי לשפר את האימון של Document AI, צריך לפחות 10 מסמכים גם בקבוצת האימון וגם בקבוצת הבדיקה, וגם 10 מקרים של כל תווית בכל קבוצה.
כדי לקבל את הביצועים הכי טובים, מומלץ לכלול בכל קבוצה לפחות 50 מסמכים עם 50 מקרים של כל תווית. בדרך כלל, ככל שיש יותר נתוני אימון, כך הדיוק גבוה יותר.
ייקח הרבה זמן לתייג 100 מסמכים באופן ידני, לכן יש לנו כמה מסמכים שכבר תויגו שאפשר לייבא ל-Lab הזה.
אפשר לייבא קבצים של מסמכים עם תוויות מוכנות מראש בפורמט Document.json. אלה יכולות להיות תוצאות של קריאה למעבד ואימות הדיוק באמצעות האדם שבתהליך (HITL).
- לוחצים על ייבוא מסמכים.
- מעתיקים ומדביקים את הנתיב הבא ב-Cloud Storage ומקצים אותו לקבוצת האימון.
cloud-samples-data/documentai/codelabs/uptraining/training
- לוחצים על הוספת מאגר נוסף. אחר כך מעתיקים ומדביקים את הנתיב הבא ב-Cloud Storage ומקצים אותו לקבוצת Test.
cloud-samples-data/documentai/codelabs/uptraining/test

- לוחצים על ייבוא וממתינים עד שהמסמכים יובאו. הפעם התהליך ייקח יותר זמן כי יש יותר מסמכים לעיבוד. בבדיקות שלי, התהליך נמשך כ-6 דקות. אפשר לצאת מהדף הזה ולחזור אליו מאוחר יותר.
- אחרי שתסיימו, המסמכים אמורים להופיע בדף 'ניהול מערך הנתונים'.

9. עריכת התוויות
מסמכי הדוגמה שבהם אנחנו משתמשים בדוגמה הזו לא מכילים כל תווית שנתמכת על ידי הכלי לניתוח חשבוניות. לפני האימון, נצטרך לסמן את התוויות שלא בשימוש כלא פעילות. אפשר גם לפעול לפי שלבים דומים כדי להוסיף תווית מותאמת אישית לפני ההכשרה המתקדמת.
- לוחצים על ניהול תוויות בפינה הימנית התחתונה.
- עכשיו אתם אמורים להיות במסוף לניהול תוויות.
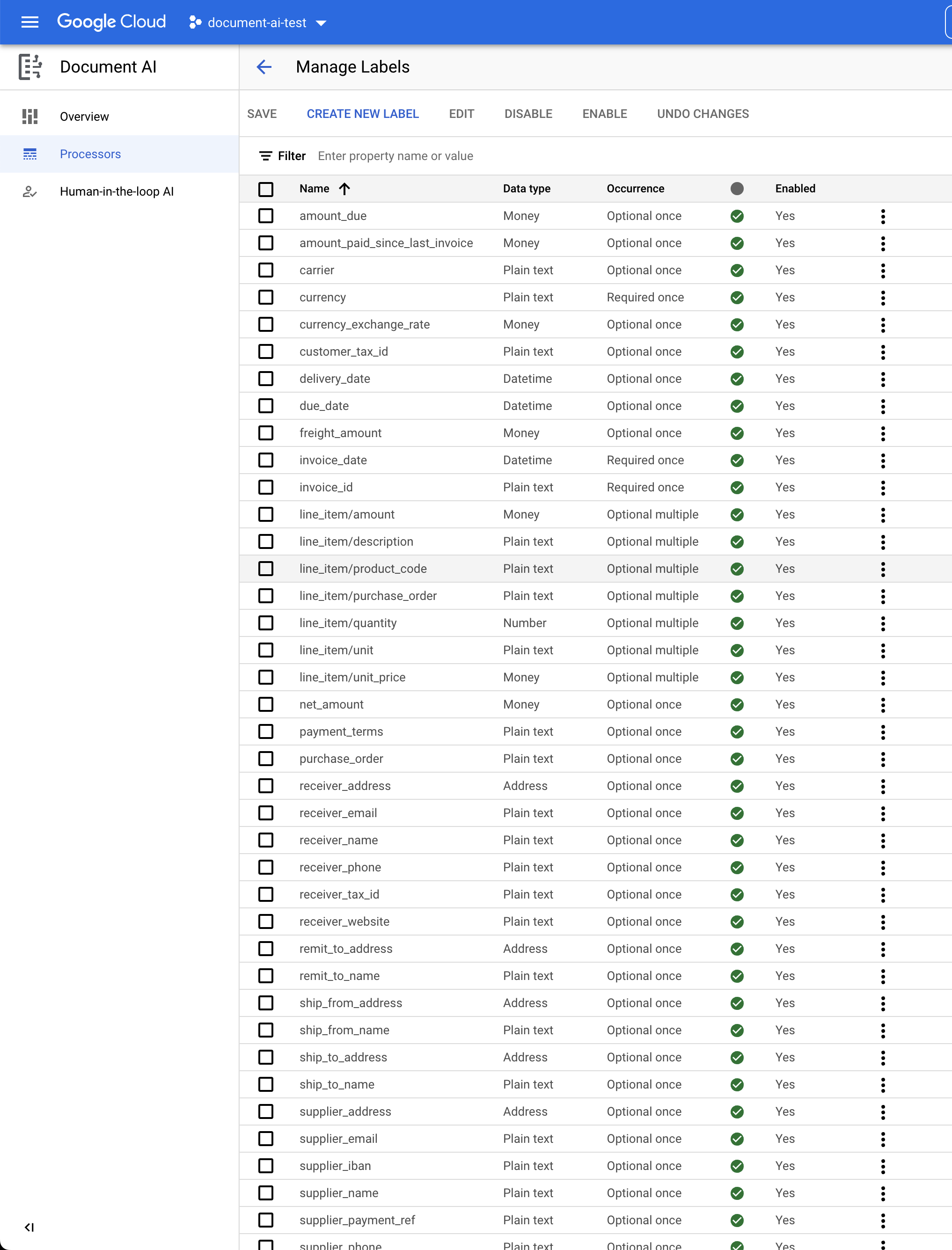
- משתמשים בתיבות הסימון ובכפתורים השבתה/הפעלה כדי לסמן רק את התוויות הבאות כמופעלות.
currencydue_dateinvoice_idline_item/amountline_item/descriptionline_item/quantityline_item/unit_pricenet_amountsupplier_addresssupplier_nametotal_amounttotal_tax_amount
- בסיום התהליך, המסך ב-Console אמור להיראות כך. בסיום, לוחצים על שמירה.

- לוחצים על החץ 'חזרה' כדי לחזור למסוף לניהול מערכי נתונים. שימו לב שהתוויות עם 0 מופעים סומנו כלא פעילות.

10. אופציונלי: סימון אוטומטי של מסמכים חדשים שיובאו
כשמייבאים מסמכים לא מתויגים למעבד עם גרסה קיימת של מעבד שהופעלה, אפשר להשתמש בתיוג אוטומטי כדי לחסוך זמן בתיוג.
- בדף Train (אימון), לוחצים על Import Documents (ייבוא מסמכים).
- מעתיקים ומדביקים את הנתיב הבא: . הספרייה הזו מכילה 5 קובצי PDF של חשבוניות ללא תוויות. ברשימה הנפתחת פיצול נתונים, בוחרים באפשרות אימון.
cloud-samples-data/documentai/Custom/Invoices/PDF_Unlabeled - בקטע הוספת תוויות אוטומטית, מסמנים את התיבה ייבוא עם הוספת תוויות אוטומטית.
- בוחרים גרסה קיימת של מעבד כדי לתייג את המסמכים.
- לדוגמה:
pretrained-invoice-v1.3-2022-07-15
- לוחצים על ייבוא וממתינים עד שהמסמכים יובאו. אפשר לצאת מהדף הזה ולחזור אליו מאוחר יותר.
- כשהפעולה מסתיימת, המסמכים מופיעים בדף Train בקטע Auto-labeled.
- אי אפשר להשתמש במסמכים עם תוויות אוטומטיות לאימון או לבדיקה בלי לסמן אותם ככאלה שסומנו. כדי לראות את המסמכים עם התוויות האוטומטיות, עוברים לקטע Auto-labeled.
- בוחרים את המסמך הראשון כדי להיכנס למסוף התיוג.
- בודקים את התוויות, תיבות התוחמות והערכים כדי לוודא שהם נכונים. מציינים תווית לכל הערכים שהושמטו.
- כשמסיימים, בוחרים באפשרות סימון כ'סומן בתווית'.
- חוזרים על אימות התוויות לכל מסמך שסומן אוטומטית, ואז חוזרים לדף אימון כדי להשתמש בנתונים לאימון.
11. המשך אימון המודל
עכשיו אנחנו מוכנים להתחיל לאמן את הכלי לניתוח חשבוניות.
- לוחצים על אימון גרסה חדשה.
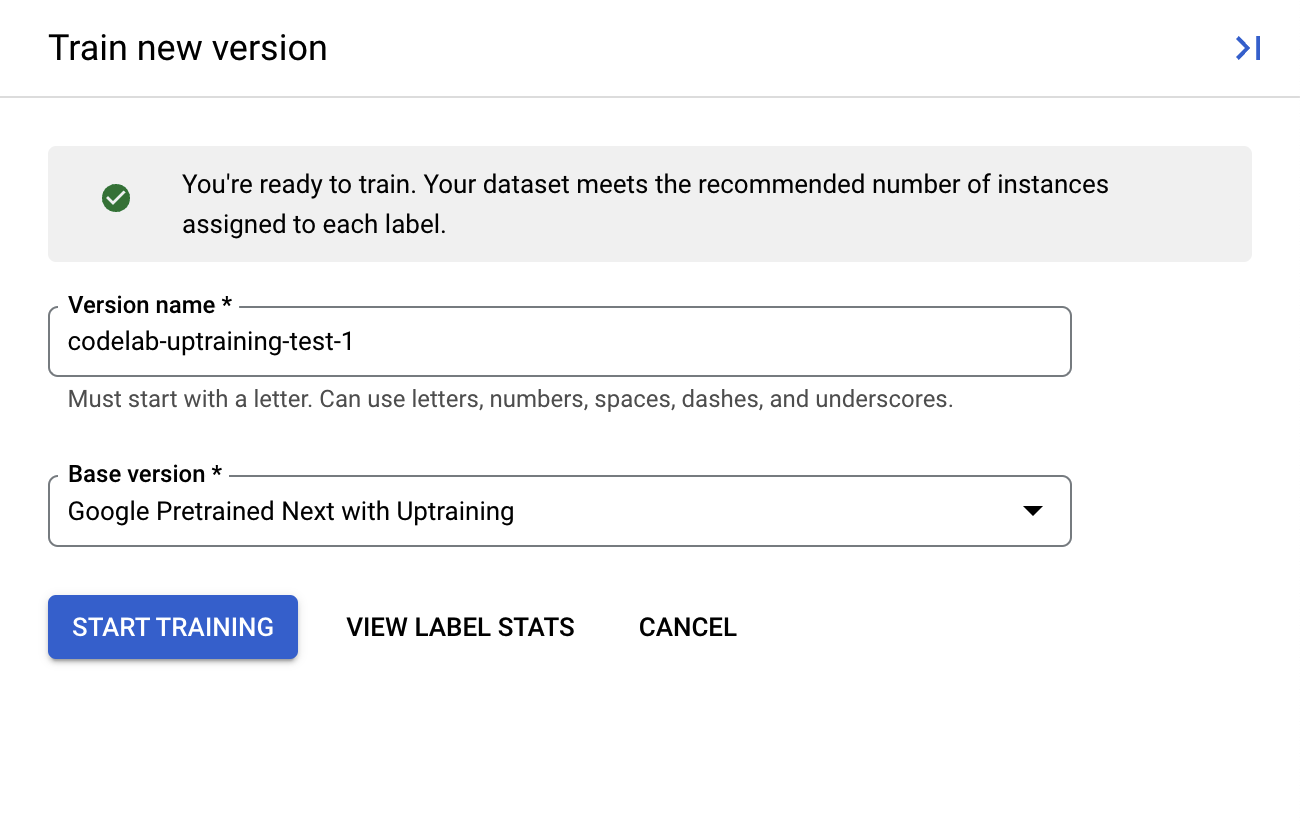
- נותנים לגרסה שם שקל לזכור, למשל
codelab-uptraining-test-1. גרסת הבסיס היא גרסת המודל שממנה תיבנה הגרסה החדשה. אם אתם משתמשים במעבד חדש, האפשרות היחידה שצריכה להיות זמינה היא Google Pretrained Next עם Uptraining.
- (אופציונלי) אפשר גם ללחוץ על הצגת נתונים סטטיסטיים של התוויות כדי לראות מדדים לגבי התוויות במערך הנתונים.
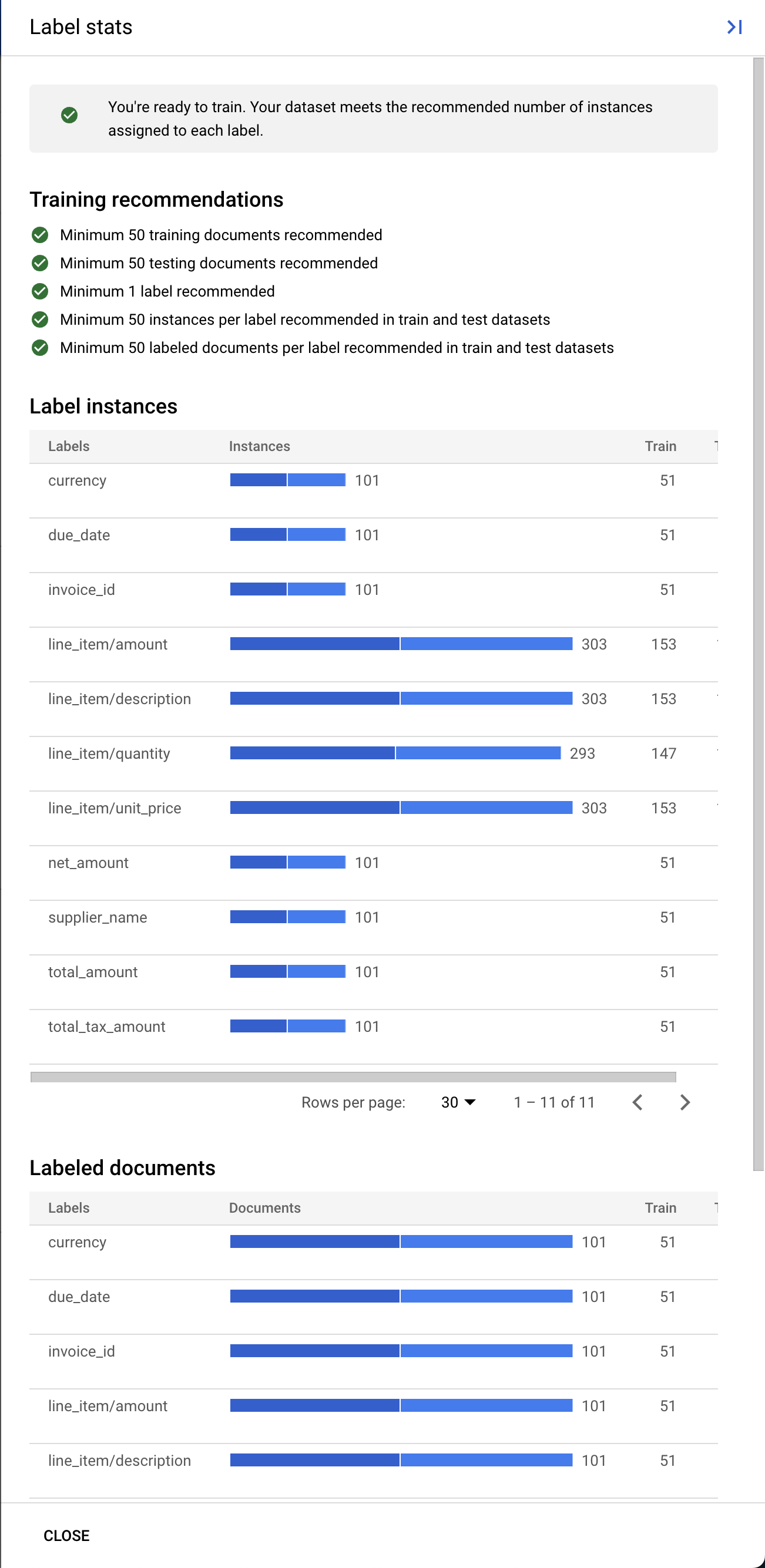
- כדי להתחיל בתהליך ההכשרה, לוחצים על Start Training (התחלת ההכשרה). המערכת אמורה להפנות אתכם לדף 'ניהול מערכי נתונים'. הסטטוס של ההדרכה מוצג בצד שמאל. תהליך האימון יימשך כמה שעות. אפשר לצאת מהדף הזה ולחזור אליו מאוחר יותר.
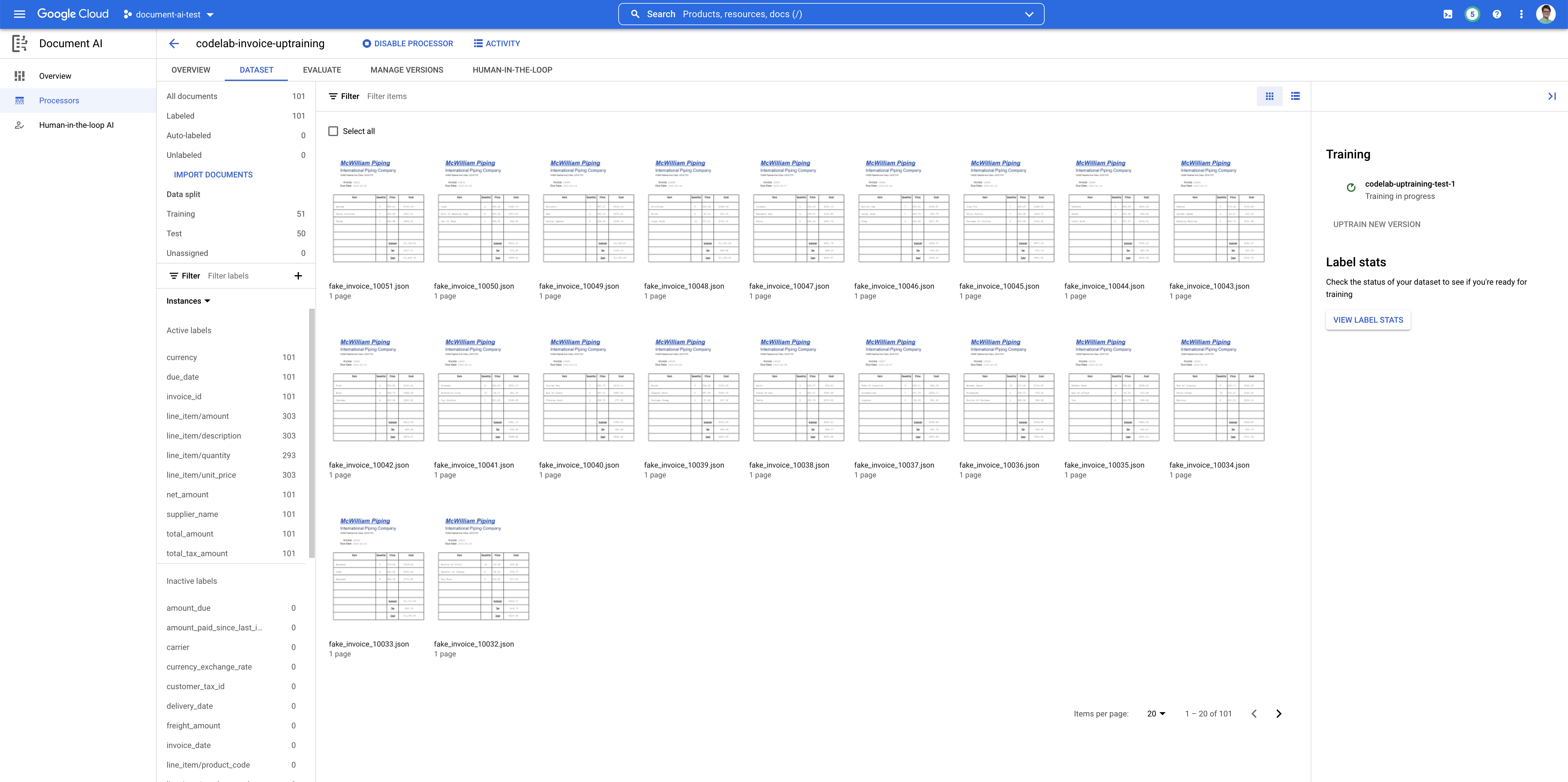
- אם תלחצו על שם הגרסה, תועברו לדף ניהול גרסאות, שבו מוצגים מזהה הגרסה והסטטוס הנוכחי של משימת האימון.
12. בדיקת הגרסה החדשה של המודל
אחרי שמשימת האימון מסתיימת (בתהליך הבדיקה שלי זה לקח כשעה), אפשר לבדוק את הגרסה החדשה של המודל ולהתחיל להשתמש בה לחיזויים.
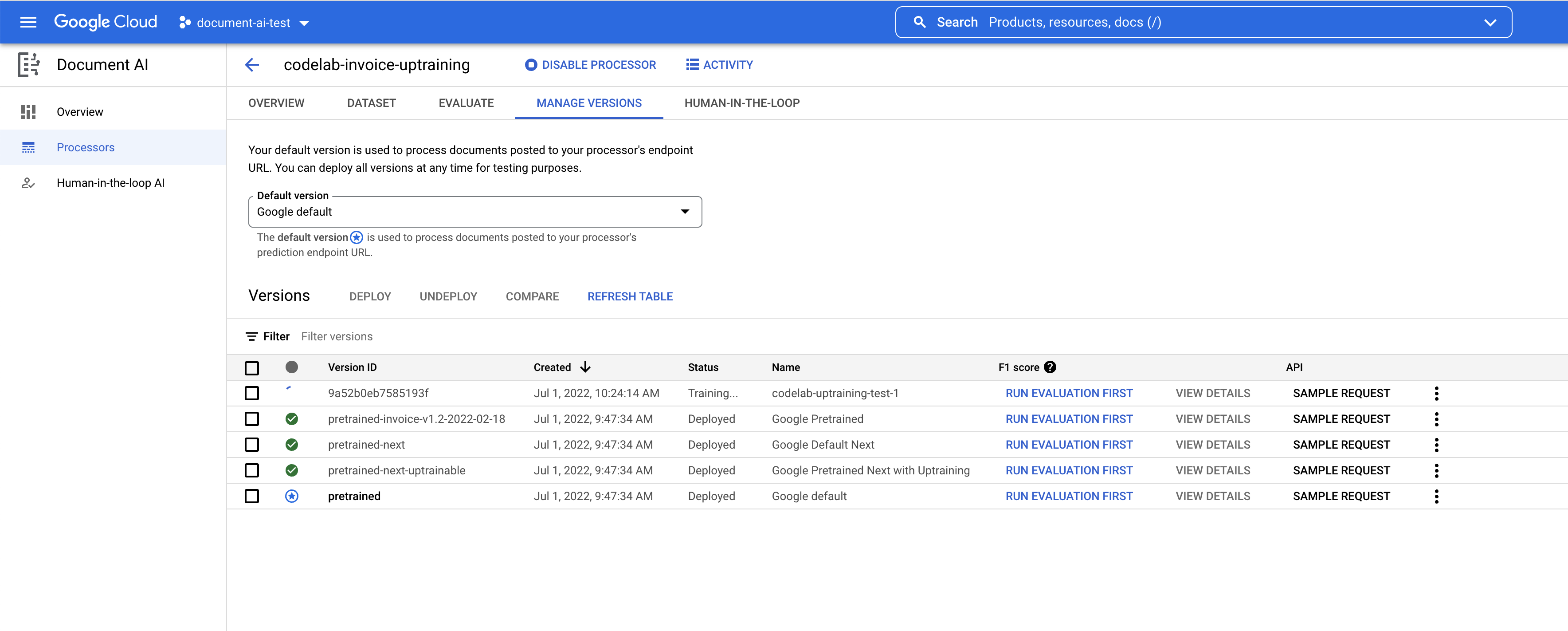
- עוברים לדף ניהול גרסאות. כאן אפשר לראות את הסטטוס הנוכחי ואת ציון ה-F1.

- נצטרך לפרוס את גרסת המודל הזו לפני שנוכל להשתמש בה. לוחצים על הנקודות האנכיות בצד שמאל ובוחרים באפשרות פריסת הגרסה.

- בחלון הקופץ, לוחצים על פריסה ומחכים עד שהגרסה תיפרס. הפעולה תימשך כמה דקות. אחרי הפריסה, אפשר גם להגדיר את הגרסה הזו כגרסת ברירת המחדל.

- אחרי שהפריסה מסתיימת, עוברים לכרטיסייה הערכה. אחר כך לוחצים על התפריט הנפתח 'גרסה' ובוחרים את הגרסה החדשה שיצרנו.
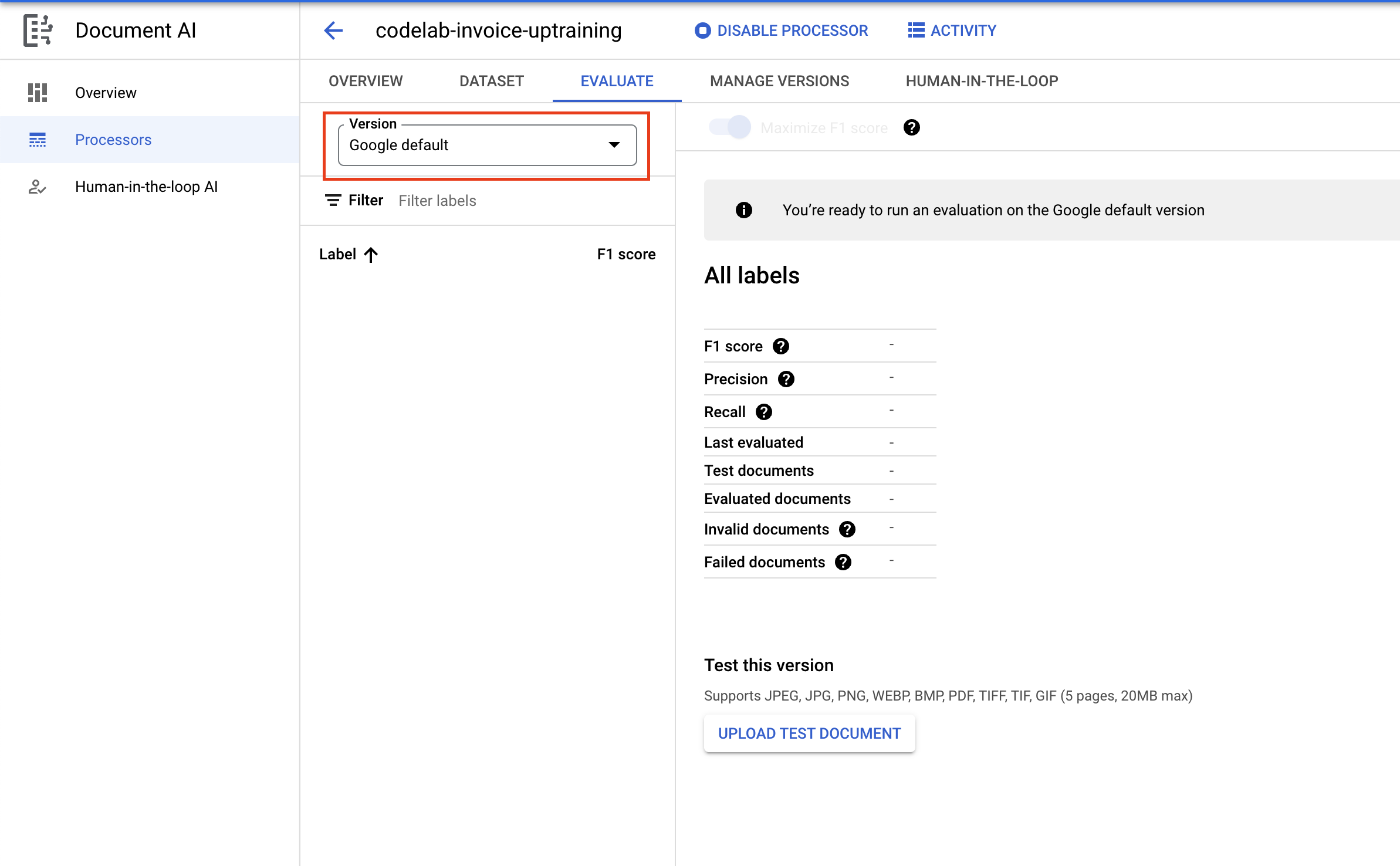
- בדף הזה אפשר לראות מדדי הערכה, כולל ציון F1, דיוק והחזרה של מסמך מלא ושל תוויות נפרדות. מידע נוסף על המדדים האלה זמין במסמכי התיעוד של AutoML.
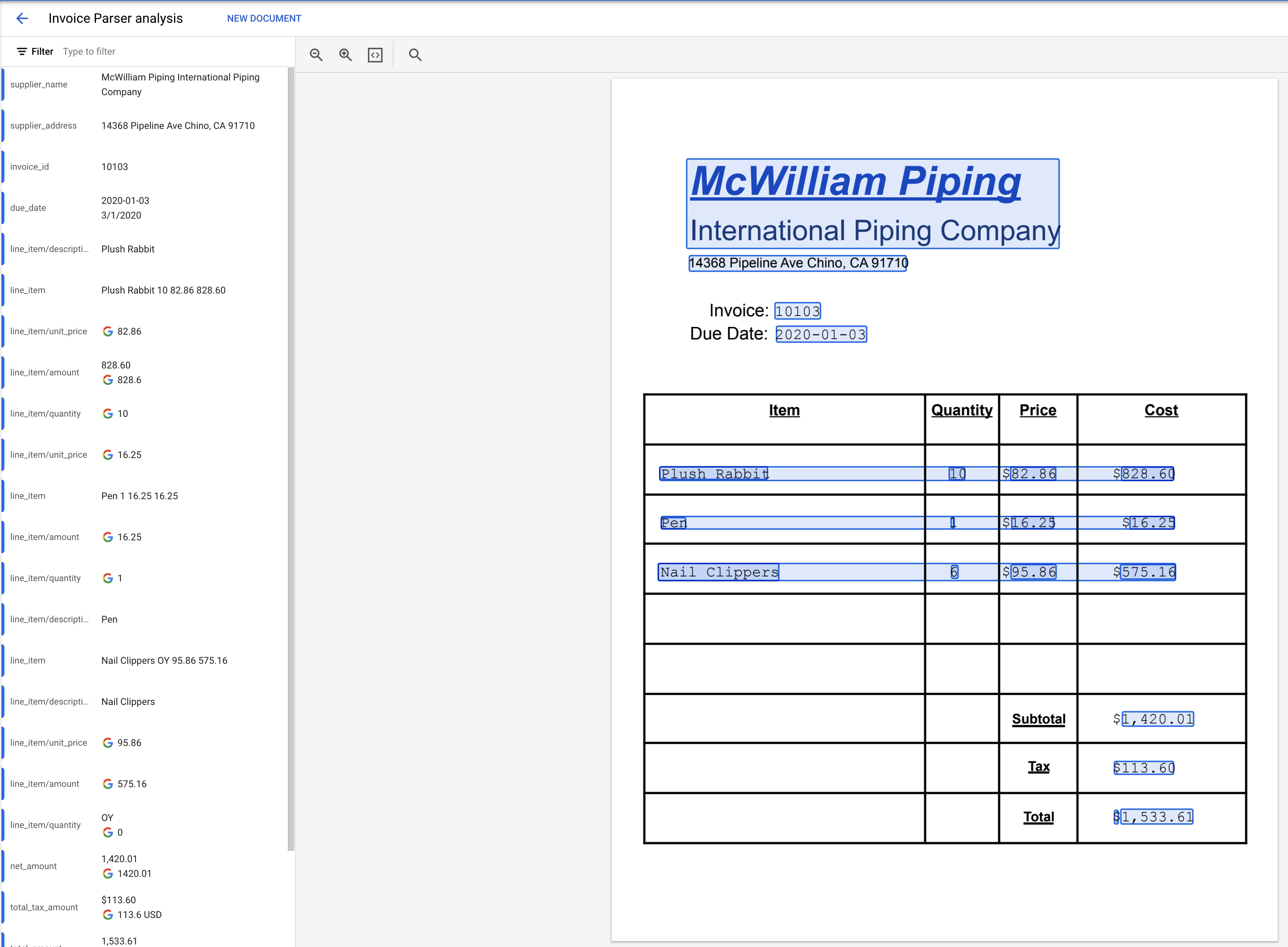
- מורידים את קובץ ה-PDF שמקושר למטה. זהו מסמך לדוגמה שלא נכלל במערך האימון או בקבוצת נתונים לבדיקה.
- לוחצים על העלאת מסמך בדיקה ובוחרים את קובץ ה-PDF.

- הישות שחולצה אמורה להיראות כך.
13. סיכום
כל הכבוד, השתמשת בהצלחה ב-Document AI כדי להמשיך אימון של מנתח חשבוניות. עכשיו אפשר להשתמש במעבד הזה כדי לנתח חשבוניות, בדיוק כמו שמשתמשים בכל מעבד ייעודי אחר.
ב-Codelab בנושא מעבדים ייעודיים מוסבר איך לטפל בתגובת העיבוד.
ניקוי
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה:
- במסוף Cloud, נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט ולוחצים על Delete (מחיקה).
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
מקורות מידע
- תיעוד של Document AI Workbench
- העתיד של מסמכים – פלייליסט ב-YouTube
- מסמכי תיעוד בנושא Document AI
- ספריית לקוח Python של Document AI
- דוגמאות לשימוש ב-Document AI
רישיון
עבודה זו מורשית תחת רישיון Creative Commons שמותנה בייחוס 2.0 כללי.