
1. परिचय
पिछले अपडेट की तारीख: 27-11-2023
जनरेटिव एआई क्या है
जनरेटिव एआई या जनरेटिव आर्टिफ़िशियल इंटेलिजेंस का मतलब है, एआई का इस्तेमाल करके नया कॉन्टेंट बनाना. जैसे, टेक्स्ट, इमेज, संगीत, ऑडियो, और वीडियो.
जनरेटिव एआई, फ़ाउंडेशन मॉडल (बड़े एआई मॉडल) की मदद से काम करता है. ये मॉडल एक साथ कई टास्क पूरे कर सकते हैं. साथ ही, ये अलग-अलग तरह के काम कर सकते हैं. जैसे- बड़े लेख की खास जानकारी लिखना, सवालों के जवाब देना, अलग-अलग कैटगरी बनाना वगैरह. इसके अलावा, फ़ाउंडेशन मॉडल को कम ट्रेनिंग की ज़रूरत होती है. इसलिए, इन्हें उदाहरण के तौर पर दिए गए बहुत कम डेटा के साथ, खास इस्तेमाल के मामलों के लिए अडैप्ट किया जा सकता है.
जनरेटिव एआई कैसे काम करता है?
जनरेटिव एआई, एमएल (मशीन लर्निंग) मॉडल का इस्तेमाल करके काम करता है. यह मॉडल, इंसानों के बनाए गए कॉन्टेंट के डेटासेट में मौजूद पैटर्न और संबंधों के बारे में जानकारी इकट्ठा करता है. इसके बाद, यह सीखे गए पैटर्न का इस्तेमाल करके नया कॉन्टेंट जनरेट करता है.
जनरेटिव एआई मॉडल को ट्रेन करने का सबसे सामान्य तरीका, सुपरवाइज़्ड लर्निंग का इस्तेमाल करना है. इसमें मॉडल को इंसानों के बनाए गए कॉन्टेंट का एक सेट और उससे जुड़े लेबल दिए जाते हैं. इसके बाद, यह लोगों के बनाए गए कॉन्टेंट के जैसा कॉन्टेंट जनरेट करना सीखता है. साथ ही, यह कॉन्टेंट को उसी तरह के लेबल से लेबल करता है.
जनरेटिव एआई के सामान्य इस्तेमाल क्या हैं?
जनरेटिव एआई, बहुत ज़्यादा कॉन्टेंट को प्रोसेस करता है. इसके बाद, टेक्स्ट, इमेज, और इस्तेमाल में आसान फ़ॉर्मैट में जवाब और अहम जानकारी देता है. जनरेटिव एआई का इस्तेमाल इन कामों के लिए किया जा सकता है:
- बेहतर चैट और खोज के अनुभव के ज़रिए, ग्राहकों से बातचीत को बेहतर बनाना
- बातचीत वाले इंटरफ़ेस और खास जानकारी की मदद से, स्ट्रक्चर नहीं किए गए डेटा के बड़े हिस्से को एक्सप्लोर करें
- बार-बार किए जाने वाले कामों में मदद करना. जैसे, प्रस्ताव के अनुरोधों (आरएफ़पी) का जवाब देना, मार्केटिंग कॉन्टेंट को पांच भाषाओं में स्थानीय भाषा के हिसाब से तैयार करना, और ग्राहकों के कानूनी समझौतों की जांच करना, ताकि यह पता चल सके कि वे नियमों का पालन कर रहे हैं या नहीं. इसके अलावा, और भी कई काम
Google Cloud में जनरेटिव एआई की कौनसी सुविधाएं उपलब्ध हैं?
Vertex AI की मदद से, अपने ऐप्लिकेशन में फ़ाउंडेशन मॉडल को इंटरैक्ट किया जा सकता है, उन्हें पसंद के मुताबिक बनाया जा सकता है, और एम्बेड किया जा सकता है. इसके लिए, मशीन लर्निंग के बारे में ज़्यादा जानकारी होने की ज़रूरत नहीं होती. Model Garden पर फ़ाउंडेशन मॉडल ऐक्सेस करें, Generative AI Studio पर आसान यूज़र इंटरफ़ेस (यूआई) की मदद से मॉडल को ट्यून करें या डेटा साइंस नोटबुक में मॉडल का इस्तेमाल करें.
Vertex AI Search and Conversation की मदद से, डेवलपर जनरेटिव एआई की मदद से काम करने वाले सर्च इंजन और चैटबॉट तेज़ी से बना सकते हैं.
साथ ही, Duet AI, एआई की मदद से काम करने वाला आपका सहयोगी है. यह Google Cloud और IDE में उपलब्ध है, ताकि आप ज़्यादा काम तेज़ी से कर सकें.
यह कोडलैब किस चीज़ पर फ़ोकस कर रहा है?
यह कोडलैब, Google Cloud Vertex AI पर होस्ट किए गए PaLM 2 लार्ज लैंग्वेज मॉडल (एलएलएम) पर फ़ोकस करता है. इसमें मशीन लर्निंग के सभी प्रॉडक्ट और सेवाएं शामिल हैं.
PaLM API के साथ इंटरैक्ट करने के लिए, Java का इस्तेमाल किया जाएगा. साथ ही, LangChain4J LLM फ़्रेमवर्क ऑर्केस्ट्रेटर का इस्तेमाल किया जाएगा. आपको कई उदाहरणों के बारे में बताया जाएगा, ताकि सवालों के जवाब पाने, आइडिया जनरेट करने, इकाई और स्ट्रक्चर्ड कॉन्टेंट निकालने, और खास जानकारी पाने के लिए एलएलएम का फ़ायदा उठाया जा सके.
LangChain4J फ़्रेमवर्क के बारे में मुझे ज़्यादा जानकारी दो!
LangChain4J फ़्रेमवर्क, ओपन सोर्स लाइब्रेरी है. इसका इस्तेमाल, Java ऐप्लिकेशन में लार्ज लैंग्वेज मॉडल को इंटिग्रेट करने के लिए किया जाता है. इसके लिए, यह एलएलएम के साथ-साथ वेक्टर डेटाबेस (सिमेंटिक सर्च के लिए), दस्तावेज़ लोडर और स्प्लिटर (दस्तावेज़ों का विश्लेषण करने और उनसे सीखने के लिए), आउटपुट पार्सर जैसे कई कॉम्पोनेंट को व्यवस्थित करता है.

आपको क्या सीखने को मिलेगा
- PaLM और LangChain4J का इस्तेमाल करने के लिए, Java प्रोजेक्ट को कैसे सेट अप करें
- कॉन्टेंट जनरेट करने और सवालों के जवाब पाने के लिए, PaLM टेक्स्ट मॉडल को पहली बार कॉल करने का तरीका
- अनस्ट्रक्चर्ड कॉन्टेंट से काम की जानकारी निकालने का तरीका (इकाई या कीवर्ड निकालना, JSON फ़ॉर्मैट में आउटपुट)
- कुछ प्रॉम्प्ट का इस्तेमाल करके, कॉन्टेंट को कैटगरी में बांटने या उसके बारे में लोगों की राय का विश्लेषण करने का तरीका
आपको इन चीज़ों की ज़रूरत होगी
- Java प्रोग्रामिंग लैंग्वेज की जानकारी
- Google Cloud प्रोजेक्ट
- Chrome या Firefox जैसे ब्राउज़र
2. सेटअप और ज़रूरी शर्तें
अपने हिसाब से एनवायरमेंट सेट अप करना
- Google Cloud Console में साइन इन करें और नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. अगर आपके पास पहले से कोई Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.


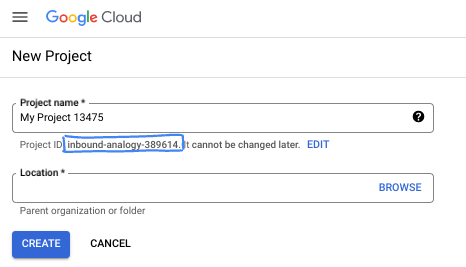
- प्रोजेक्ट का नाम, इस प्रोजेक्ट में हिस्सा लेने वाले लोगों के लिए डिसप्ले नेम होता है. यह एक वर्ण स्ट्रिंग है, जिसका इस्तेमाल Google API नहीं करते. इसे कभी भी अपडेट किया जा सकता है.
- प्रोजेक्ट आईडी, सभी Google Cloud प्रोजेक्ट के लिए यूनीक होता है. साथ ही, इसे बदला नहीं जा सकता. Cloud Console, यूनीक स्ट्रिंग को अपने-आप जनरेट करता है. आम तौर पर, आपको इससे कोई फ़र्क़ नहीं पड़ता कि यह क्या है. ज़्यादातर कोडलैब में, आपको अपने प्रोजेक्ट आईडी (आम तौर पर
PROJECT_IDके तौर पर पहचाना जाता है) का रेफ़रंस देना होगा. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा रैंडम आईडी जनरेट किया जा सकता है. इसके अलावा, आपके पास अपना नाम आज़माने का विकल्प भी है. इससे आपको पता चलेगा कि वह नाम उपलब्ध है या नहीं. इस चरण के बाद, इसे बदला नहीं जा सकता. यह प्रोजेक्ट की अवधि तक बना रहता है. - आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जिसे प्रोजेक्ट नंबर कहते हैं. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
- इसके बाद, आपको Cloud Console में बिलिंग चालू करनी होगी, ताकि Cloud संसाधनों/एपीआई का इस्तेमाल किया जा सके. इस कोडलैब को पूरा करने में ज़्यादा समय नहीं लगेगा. इस ट्यूटोरियल के बाद बिलिंग से बचने के लिए, संसाधनों को बंद किया जा सकता है. इसके लिए, बनाए गए संसाधनों को मिटाएं या प्रोजेक्ट को मिटाएं. Google Cloud के नए उपयोगकर्ताओं को, 300 डॉलर का क्रेडिट मिलेगा. वे इसे मुफ़्त में आज़मा सकते हैं.
Cloud Shell शुरू करें
Google Cloud को अपने लैपटॉप से रिमोटली ऑपरेट किया जा सकता है. हालांकि, इस कोडलैब में Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Cloud Shell चालू करें
- Cloud Console में, Cloud Shell चालू करें
 पर क्लिक करें.
पर क्लिक करें.

अगर आपने Cloud Shell को पहली बार शुरू किया है, तो आपको एक इंटरमीडिएट स्क्रीन दिखेगी. इसमें Cloud Shell के बारे में जानकारी दी गई होगी. अगर आपको इंटरमीडिएट स्क्रीन दिखती है, तो जारी रखें पर क्लिक करें.

Cloud Shell से कनेक्ट होने में कुछ ही सेकंड लगेंगे.

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है, जो हमेशा बनी रहती है. साथ ही, यह Google Cloud में काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में ज़्यादातर काम ब्राउज़र से किया जा सकता है.
Cloud Shell से कनेक्ट होने के बाद, आपको दिखेगा कि आपकी पुष्टि हो गई है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर सेट कर दिया गया है.
- पुष्टि करें कि आपने Cloud Shell में पुष्टि कर ली है. इसके लिए, यह कमांड चलाएं:
gcloud auth list
कमांड आउटपुट
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं:
gcloud config list project
कमांड आउटपुट
[core] project = <PROJECT_ID>
अगर ऐसा नहीं है, तो इस कमांड का इस्तेमाल करके इसे सेट किया जा सकता है:
gcloud config set project <PROJECT_ID>
कमांड आउटपुट
Updated property [core/project].
3. आपका डेवलपमेंट एनवायरमेंट तैयार किया जा रहा है
इस कोडलैब में, Java प्रोग्राम डेवलप करने के लिए Cloud Shell टर्मिनल और कोड एडिटर का इस्तेमाल किया जाएगा.
Vertex AI API चालू करना
- Google Cloud Console में, पक्का करें कि आपके प्रोजेक्ट का नाम, Google Cloud Console में सबसे ऊपर दिख रहा हो. अगर ऐसा नहीं है, तो प्रोजेक्ट चुनने वाला टूल खोलने के लिए, कोई प्रोजेक्ट चुनें पर क्लिक करें. इसके बाद, अपना पसंदीदा प्रोजेक्ट चुनें.
- अगर आप Google Cloud Console के Vertex AI सेक्शन में नहीं हैं, तो यह तरीका अपनाएं:
- Search में, Vertex AI डालें. इसके बाद, वापस जाएं
- खोज के नतीजों में, Vertex AI पर क्लिक करें. इसके बाद, Vertex AI डैशबोर्ड दिखेगा.
- Vertex AI डैशबोर्ड में, सुझाए गए सभी एपीआई चालू करें पर क्लिक करें.
इससे कई एपीआई चालू हो जाएंगे. हालांकि, कोडलैब के लिए सबसे ज़रूरी एपीआई aiplatform.googleapis.com है. इसे कमांड-लाइन पर भी चालू किया जा सकता है. इसके लिए, Cloud Shell टर्मिनल में जाकर यह कमांड चलाएं:
$ gcloud services enable aiplatform.googleapis.com
Gradle की मदद से प्रोजेक्ट स्ट्रक्चर बनाना
Java कोड के उदाहरण बनाने के लिए, Gradle बिल्ड टूल और Java के वर्शन 17 का इस्तेमाल किया जाएगा. Gradle की मदद से अपना प्रोजेक्ट सेट अप करने के लिए, Cloud Shell टर्मिनल में एक डायरेक्ट्री (यहां, palm-workshop) बनाएं. इसके बाद, उस डायरेक्ट्री में gradle init कमांड चलाएं:
$ mkdir palm-workshop $ cd palm-workshop $ gradle init Select type of project to generate: 1: basic 2: application 3: library 4: Gradle plugin Enter selection (default: basic) [1..4] 2 Select implementation language: 1: C++ 2: Groovy 3: Java 4: Kotlin 5: Scala 6: Swift Enter selection (default: Java) [1..6] 3 Split functionality across multiple subprojects?: 1: no - only one application project 2: yes - application and library projects Enter selection (default: no - only one application project) [1..2] 1 Select build script DSL: 1: Groovy 2: Kotlin Enter selection (default: Groovy) [1..2] 1 Generate build using new APIs and behavior (some features may change in the next minor release)? (default: no) [yes, no] Select test framework: 1: JUnit 4 2: TestNG 3: Spock 4: JUnit Jupiter Enter selection (default: JUnit Jupiter) [1..4] 4 Project name (default: palm-workshop): Source package (default: palm.workshop): > Task :init Get more help with your project: https://docs.gradle.org/7.4/samples/sample_building_java_applications.html BUILD SUCCESSFUL in 51s 2 actionable tasks: 2 executed
आपको ऐप्लिकेशन (विकल्प 2) बनाना है. इसके लिए, Java भाषा (विकल्प 3) का इस्तेमाल करना है. साथ ही, सबप्रोजेक्ट का इस्तेमाल नहीं करना है (विकल्प 1). इसके अलावा, बिल्ड फ़ाइल के लिए Groovy सिंटैक्स (विकल्प 1) का इस्तेमाल करना है. साथ ही, बिल्ड की नई सुविधाओं का इस्तेमाल नहीं करना है (विकल्प नहीं). इसके अलावा, JUnit Jupiter (विकल्प 4) की मदद से टेस्ट जनरेट करने हैं. प्रोजेक्ट के नाम के लिए, palm-workshop का इस्तेमाल किया जा सकता है. इसी तरह, सोर्स पैकेज के लिए palm.workshop का इस्तेमाल किया जा सकता है.
प्रोजेक्ट का स्ट्रक्चर इस तरह दिखेगा:
├── gradle
│ └── ...
├── gradlew
├── gradlew.bat
├── settings.gradle
└── app
├── build.gradle
└── src
├── main
│ └── java
│ └── palm
│ └── workshop
│ └── App.java
└── test
└── ...
आइए, कुछ ज़रूरी डिपेंडेंसी जोड़ने के लिए app/build.gradle फ़ाइल को अपडेट करें. अगर guava मौजूद है, तो उसे हटाया जा सकता है. इसके बाद, उसे LangChain4J प्रोजेक्ट और लॉगिंग लाइब्रेरी की डिपेंडेंसी से बदला जा सकता है. इससे, लॉगिंग से जुड़े मैसेज नहीं दिखेंगे:
dependencies {
// Use JUnit Jupiter for testing.
testImplementation 'org.junit.jupiter:junit-jupiter:5.8.1'
// Logging library
implementation 'org.slf4j:slf4j-jdk14:2.0.9'
// This dependency is used by the application.
implementation 'dev.langchain4j:langchain4j-vertex-ai:0.24.0'
implementation 'dev.langchain4j:langchain4j:0.24.0'
}
LangChain4J के लिए दो डिपेंडेंसी हैं:
- एक मुख्य प्रोजेक्ट पर,
- और एक Vertex AI के लिए.
हमारे प्रोग्राम को कंपाइल और चलाने के लिए Java 17 का इस्तेमाल करने के लिए, plugins {} ब्लॉक के नीचे यह ब्लॉक जोड़ें:
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
एक और बदलाव करना है: app/build.gradle के application ब्लॉक को अपडेट करें, ताकि उपयोगकर्ता बिल्ड टूल को शुरू करते समय कमांड-लाइन पर चलने वाली मुख्य क्लास को बदल सकें:
application {
mainClass = providers.systemProperty('javaMainClass')
.orElse('palm.workshop.App')
}
यह देखने के लिए कि आपकी बिल्ड फ़ाइल, ऐप्लिकेशन चलाने के लिए तैयार है या नहीं, डिफ़ॉल्ट मुख्य क्लास चलाएं. इससे एक सामान्य Hello World! मैसेज प्रिंट होता है:
$ ./gradlew run -DjavaMainClass=palm.workshop.App > Task :app:run Hello World! BUILD SUCCESSFUL in 3s 2 actionable tasks: 2 executed
अब LangChain4J प्रोजेक्ट का इस्तेमाल करके, PaLM लार्ज लैंग्वेज टेक्स्ट मॉडल के साथ प्रोग्रामिंग की जा सकती है!
रेफ़रंस के लिए, यहां बताया गया है कि अब पूरी app/build.gradle बिल्ड फ़ाइल कैसी दिखनी चाहिए:
plugins {
// Apply the application plugin to add support for building a CLI application in Java.
id 'application'
}
java {
toolchain {
// Ensure we compile and run on Java 17
languageVersion = JavaLanguageVersion.of(17)
}
}
repositories {
// Use Maven Central for resolving dependencies.
mavenCentral()
}
dependencies {
// Use JUnit Jupiter for testing.
testImplementation 'org.junit.jupiter:junit-jupiter:5.8.1'
// This dependency is used by the application.
implementation 'dev.langchain4j:langchain4j-vertex-ai:0.24.0'
implementation 'dev.langchain4j:langchain4j:0.24.0'
implementation 'org.slf4j:slf4j-jdk14:2.0.9'
}
application {
mainClass = providers.systemProperty('javaMainClass').orElse('palm.workshop.App')
}
tasks.named('test') {
// Use JUnit Platform for unit tests.
useJUnitPlatform()
}
4. PaLM के टेक्स्ट मॉडल को पहली बार कॉल करना
प्रोजेक्ट को सही तरीके से सेट अप करने के बाद, अब PaLM API को कॉल करने का समय है.
app/src/main/java/palm/workshop डायरेक्ट्री में TextPrompts.java नाम की नई क्लास बनाएं. यह क्लास, डिफ़ॉल्ट App.java क्लास के साथ होगी. इसके बाद, यह कॉन्टेंट टाइप करें:
package palm.workshop;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.model.vertexai.VertexAiLanguageModel;
public class TextPrompts {
public static void main(String[] args) {
VertexAiLanguageModel model = VertexAiLanguageModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("text-bison@001")
.maxOutputTokens(500)
.build();
Response<String> response = model.generate("What are large language models?");
System.out.println(response.content());
}
}
इस पहले उदाहरण में, आपको Response क्लास और PaLM के लिए Vertex AI भाषा मॉडल इंपोर्ट करना होगा.
इसके बाद, main तरीके में, आपको भाषा मॉडल को कॉन्फ़िगर करना होगा. इसके लिए, VertexAiLanguageModel के बिल्डर का इस्तेमाल करके यह तय करें कि:
- एंडपॉइंट,
- प्रोजेक्ट,
- क्षेत्र,
- पब्लिशर,
- और मॉडल का नाम (
text-bison@001) शामिल होना चाहिए.
अब भाषा मॉडल तैयार है. इसलिए, generate() तरीके को कॉल किया जा सकता है. साथ ही, "प्रॉम्प्ट" (यानी कि एलएलएम को भेजने के लिए आपका सवाल या निर्देश) पास किया जा सकता है. यहां, एलएलएम के बारे में एक आसान सवाल पूछा गया है. हालांकि, अलग-अलग सवालों या टास्क के लिए, इस प्रॉम्प्ट को बदला जा सकता है.
इस क्लास को चलाने के लिए, Cloud Shell टर्मिनल में यह कमांड चलाएं:
./gradlew run -DjavaMainClass=palm.workshop.TextPrompts
आपको इससे मिलता-जुलता आउटपुट दिखेगा:
Large language models (LLMs) are artificial intelligence systems that can understand and generate human language. They are trained on massive datasets of text and code, and can learn to perform a wide variety of tasks, such as translating languages, writing different kinds of creative content, and answering your questions in an informative way. LLMs are still under development, but they have the potential to revolutionize many industries. For example, they could be used to create more accurate and personalized customer service experiences, to help doctors diagnose and treat diseases, and to develop new forms of creative expression. However, LLMs also raise a number of ethical concerns. For example, they could be used to create fake news and propaganda, to manipulate people's behavior, and to invade people's privacy. It is important to carefully consider the potential risks and benefits of LLMs before they are widely used. Here are some of the key features of LLMs: * They are trained on massive datasets of text and code. * They can learn to perform a wide variety of tasks, such as translating languages, writing different kinds of creative content, and answering your questions in an informative way. * They are still under development, but they have the potential to revolutionize many industries. * They raise a number of ethical concerns, such as the potential for fake news, propaganda, and invasion of privacy.
VertexAILanguageModel बिल्डर की मदद से, ऐसे वैकल्पिक पैरामीटर तय किए जा सकते हैं जिनकी कुछ डिफ़ॉल्ट वैल्यू पहले से मौजूद होती हैं. इन वैल्यू को बदला जा सकता है. यहां कुछ उदाहरण दिए गए हैं:
.temperature(0.2)— इससे यह तय किया जाता है कि आपको जवाब कितना क्रिएटिव चाहिए. 0 का मतलब है कि जवाब कम क्रिएटिव और ज़्यादातर तथ्यों पर आधारित होगा, जबकि 1 का मतलब है कि जवाब ज़्यादा क्रिएटिव होगा.maxOutputTokens(50)— उदाहरण में, 500 टोकन का अनुरोध किया गया था. तीन टोकन, करीब-करीब चार शब्दों के बराबर होते हैं. यह इस बात पर निर्भर करता है कि आपको जनरेट किया गया जवाब कितना लंबा चाहिए.topK(20)— इसका इस्तेमाल, टेक्स्ट पूरा करने के लिए, संभावित शब्दों में से किसी एक शब्द को चुनने के लिए किया जाता है. इसकी वैल्यू 1 से 40 तक होती है.topP(0.95)— उन संभावित शब्दों को चुनने के लिए जिनकी कुल संभावना, फ़्लोटिंग पॉइंट नंबर (0 से 1 के बीच) के बराबर होती है.maxRetries(3)— अगर आपने तय समय में अनुरोधों की संख्या से ज़्यादा अनुरोध किए हैं, तो मॉडल को कॉल करने के लिए तीन बार फिर से कोशिश करने का निर्देश दिया जा सकता है.
लार्ज लैंग्वेज मॉडल बहुत शक्तिशाली होते हैं. ये मुश्किल सवालों के जवाब दे सकते हैं और कई तरह के दिलचस्प काम कर सकते हैं. अगले सेक्शन में, हम एक ज़रूरी टास्क के बारे में जानेंगे: टेक्स्ट से स्ट्रक्चर्ड डेटा निकालना.
5. अनस्ट्रक्चर्ड टेक्स्ट से जानकारी निकालना
पिछले सेक्शन में, आपने कुछ टेक्स्ट आउटपुट जनरेट किया था. अगर आपको यह आउटपुट सीधे तौर पर अपने उपयोगकर्ताओं को दिखाना है, तो यह ठीक है. हालांकि, अगर आपको इस आउटपुट में मौजूद डेटा को वापस पाना है, तो बिना किसी स्ट्रक्चर वाले टेक्स्ट से उस जानकारी को कैसे एक्सट्रैक्ट किया जा सकता है?
मान लें कि आपको किसी व्यक्ति की जीवनी या उसके बारे में दी गई जानकारी से उसका नाम और उम्र निकालनी है. बड़े भाषा मॉडल को JSON डेटा स्ट्रक्चर जनरेट करने के लिए कहा जा सकता है. इसके लिए, प्रॉम्प्ट में बदलाव करें. इसे आम तौर पर "प्रॉम्प्ट इंजीनियरिंग" कहा जाता है:
Extract the name and age of the person described below.
Return a JSON document with a "name" and an "age" property,
following this structure: {"name": "John Doe", "age": 34}
Return only JSON, without any markdown markup surrounding it.
Here is the document describing the person:
---
Anna is a 23 year old artist based in Brooklyn, New York. She was
born and raised in the suburbs of Chicago, where she developed a
love for art at a young age. She attended the School of the Art
Institute of Chicago, where she studied painting and drawing.
After graduating, she moved to New York City to pursue her art career.
Anna's work is inspired by her personal experiences and observations
of the world around her. She often uses bright colors and bold lines
to create vibrant and energetic paintings. Her work has been
exhibited in galleries and museums in New York City and Chicago.
---
JSON:
ऊपर दिए गए पूरे टेक्स्ट प्रॉम्प्ट को पास करने के लिए, TextPrompts क्लास में model.generate() कॉल में बदलाव करें:
Response<String> response = model.generate("""
Extract the name and age of the person described below.
Return a JSON document with a "name" and an "age" property, \
following this structure: {"name": "John Doe", "age": 34}
Return only JSON, without any markdown markup surrounding it.
Here is the document describing the person:
---
Anna is a 23 year old artist based in Brooklyn, New York. She was born and
raised in the suburbs of Chicago, where she developed a love for art at a
young age. She attended the School of the Art Institute of Chicago, where
she studied painting and drawing. After graduating, she moved to New York
City to pursue her art career. Anna's work is inspired by her personal
experiences and observations of the world around her. She often uses bright
colors and bold lines to create vibrant and energetic paintings. Her work
has been exhibited in galleries and museums in New York City and Chicago.
---
JSON:
"""
);
अगर इस प्रॉम्प्ट को हमारी TextPrompts क्लास में चलाया जाता है, तो यह नीचे दी गई JSON स्ट्रिंग को वापस करेगा. इसे GSON लाइब्रेरी जैसे JSON पार्सर की मदद से पार्स किया जा सकता है:
$ ./gradlew run -DjavaMainClass=palm.workshop.TextPrompts
> Task :app:run
{"name": "Anna", "age": 23}
BUILD SUCCESSFUL in 24s
2 actionable tasks: 1 executed, 1 up-to-date
हां! ऐना 23 साल की है!
6. प्रॉम्प्ट टेंप्लेट और स्ट्रक्चर्ड प्रॉम्प्ट
सवाल के जवाब देने के अलावा अन्य काम
PaLM जैसे लार्ज लैंग्वेज मॉडल, सवालों के जवाब देने में बहुत मददगार होते हैं. हालाँकि, इनका इस्तेमाल कई अन्य कामों के लिए भी किया जा सकता है! उदाहरण के लिए, Generative AI Studio में इन प्रॉम्प्ट को आज़माएं या TextPrompts क्लास में बदलाव करके देखें. कैपिटल लेटर में लिखे गए शब्दों को अपने आइडिया से बदलें और देखें कि इससे क्या नतीजे मिलते हैं:
- अनुवाद — "इस वाक्य का फ़्रेंच में अनुवाद करो: YOUR_SENTENCE_HERE"
- खास जानकारी — "इस दस्तावेज़ की खास जानकारी दो: PASTE_YOUR_DOC"
- क्रिएटिव कॉन्टेंट जनरेट करना — "TOPIC_OF_THE_POEM के बारे में एक कविता लिखो"
- प्रोग्रामिंग — "PROGRAMMING_LANGUAGE में फ़िबोनाची फ़ंक्शन कैसे लिखें?"
प्रॉम्प्ट टेंप्लेट
अगर आपने अनुवाद, खास जानकारी, क्रिएटिव जनरेट करने या प्रोग्रामिंग से जुड़े टास्क के लिए ऊपर दिए गए प्रॉम्प्ट का इस्तेमाल किया है, तो आपने प्लेसहोल्डर वैल्यू को अपने आइडिया से बदल दिया होगा. हालांकि, स्ट्रिंग में बदलाव करने के बजाय, "प्रॉम्प्ट टेंप्लेट" का इस्तेमाल भी किया जा सकता है. इनकी मदद से, प्लेसहोल्डर वैल्यू तय की जा सकती हैं. इसके बाद, अपने डेटा के हिसाब से खाली जगहें भरी जा सकती हैं.
आइए, main() तरीके के पूरे कॉन्टेंट को इस कोड से बदलकर, एक शानदार और क्रिएटिव प्रॉम्प्ट देखें:
VertexAiLanguageModel model = VertexAiLanguageModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("text-bison@001")
.maxOutputTokens(300)
.build();
PromptTemplate promptTemplate = PromptTemplate.from("""
Create a recipe for a {{dish}} with the following ingredients: \
{{ingredients}}, and give it a name.
"""
);
Map<String, Object> variables = new HashMap<>();
variables.put("dish", "dessert");
variables.put("ingredients", "strawberries, chocolate, whipped cream");
Prompt prompt = promptTemplate.apply(variables);
Response<String> response = model.generate(prompt);
System.out.println(response.content());
साथ ही, यहां दिए गए इंपोर्ट जोड़कर:
import dev.langchain4j.model.input.Prompt;
import dev.langchain4j.model.input.PromptTemplate;
import java.util.HashMap;
import java.util.Map;
इसके बाद, ऐप्लिकेशन को फिर से चलाएं. आउटपुट कुछ ऐसा दिखना चाहिए:
$ ./gradlew run -DjavaMainClass=palm.workshop.TextPrompts > Task :app:run **Strawberry Shortcake** Ingredients: * 1 pint strawberries, hulled and sliced * 1/2 cup sugar * 1/4 cup cornstarch * 1/4 cup water * 1 tablespoon lemon juice * 1/2 cup heavy cream, whipped * 1/4 cup confectioners' sugar * 1/4 teaspoon vanilla extract * 6 graham cracker squares, crushed Instructions: 1. In a medium saucepan, combine the strawberries, sugar, cornstarch, water, and lemon juice. Bring to a boil over medium heat, stirring constantly. Reduce heat and simmer for 5 minutes, or until the sauce has thickened. 2. Remove from heat and let cool slightly. 3. In a large bowl, combine the whipped cream, confectioners' sugar, and vanilla extract. Beat until soft peaks form. 4. To assemble the shortcakes, place a graham cracker square on each of 6 dessert plates. Top with a scoop of whipped cream, then a spoonful of strawberry sauce. Repeat layers, ending with a graham cracker square. 5. Serve immediately. **Tips:** * For a more elegant presentation, you can use fresh strawberries instead of sliced strawberries. * If you don't have time to make your own whipped cream, you can use store-bought whipped cream.
बहुत स्वादिष्ट!
प्रॉम्प्ट टेंप्लेट की मदद से, टेक्स्ट जनरेट करने के तरीके को कॉल करने से पहले, ज़रूरी पैरामीटर दिए जा सकते हैं. यह डेटा पास करने और उपयोगकर्ताओं की ओर से दी गई अलग-अलग वैल्यू के लिए प्रॉम्प्ट को पसंद के मुताबिक बनाने का एक शानदार तरीका है.
क्लास के नाम से पता चलता है कि PromptTemplate क्लास, टेंप्लेट प्रॉम्प्ट बनाती है. साथ ही, प्लेसहोल्डर के नाम और वैल्यू का मैप लागू करके, प्लेसहोल्डर एलिमेंट को वैल्यू असाइन की जा सकती हैं.
स्ट्रक्चर्ड प्रॉम्प्ट (ज़रूरी नहीं)
अगर आपको ऑब्जेक्ट ओरिएंटेड अप्रोच का इस्तेमाल करना है, तो अपने प्रॉम्प्ट को @StructuredPrompt एनोटेशन के साथ स्ट्रक्चर किया जा सकता है. इस एनोटेशन का इस्तेमाल करके किसी क्लास को एनोटेट किया जाता है. इसके फ़ील्ड, प्रॉम्प्ट में तय किए गए प्लेसहोल्डर से मेल खाते हैं. चलिए, इसे काम करते हुए देखते हैं.
सबसे पहले, हमें कुछ नए इंपोर्ट की ज़रूरत होगी:
import java.util.Arrays;
import java.util.List;
import dev.langchain4j.model.input.structured.StructuredPrompt;
import dev.langchain4j.model.input.structured.StructuredPromptProcessor;
इसके बाद, हम अपनी TextPrompts क्लास में एक इनर स्टैटिक क्लास बना सकते हैं. यह क्लास, @StructuredPrompt एनोटेशन में बताए गए प्रॉम्प्ट में प्लेसहोल्डर पास करने के लिए ज़रूरी डेटा इकट्ठा करती है:
@StructuredPrompt("Create a recipe of a {{dish}} that can be prepared using only {{ingredients}}")
static class RecipeCreationPrompt {
String dish;
List<String> ingredients;
}
इसके बाद, उस नई क्लास को इंस्टैंशिएट करें और उसे हमारी रेसिपी का पकवान और सामग्री दें. साथ ही, प्रॉम्प्ट बनाएं और उसे पहले की तरह generate() तरीके से पास करें:
RecipeCreationPrompt createRecipePrompt = new RecipeCreationPrompt();
createRecipePrompt.dish = "salad";
createRecipePrompt.ingredients = Arrays.asList("cucumber", "tomato", "feta", "onion", "olives");
Prompt prompt = StructuredPromptProcessor.toPrompt(createRecipePrompt);
Response<String> response = model.generate(prompt);
मैप के ज़रिए वैल्यू भरने के बजाय, Java ऑब्जेक्ट का इस्तेमाल किया जा सकता है. इसमें ऐसे फ़ील्ड होते हैं जिन्हें आपका IDE, टाइप-सेफ़ तरीके से अपने-आप पूरा कर सकता है.
अगर आपको उन बदलावों को अपनी TextPrompts क्लास में आसानी से चिपकाना है, तो यहां पूरा कोड दिया गया है:
package palm.workshop;
import java.util.Arrays;
import java.util.List;
import dev.langchain4j.model.input.Prompt;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.model.vertexai.VertexAiLanguageModel;
import dev.langchain4j.model.input.structured.StructuredPrompt;
import dev.langchain4j.model.input.structured.StructuredPromptProcessor;
public class TextPrompts {
@StructuredPrompt("Create a recipe of a {{dish}} that can be prepared using only {{ingredients}}")
static class RecipeCreationPrompt {
String dish;
List<String> ingredients;
}
public static void main(String[] args) {
VertexAiLanguageModel model = VertexAiLanguageModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("text-bison@001")
.maxOutputTokens(300)
.build();
RecipeCreationPrompt createRecipePrompt = new RecipeCreationPrompt();
createRecipePrompt.dish = "salad";
createRecipePrompt.ingredients = Arrays.asList("cucumber", "tomato", "feta", "onion", "olives");
Prompt prompt = StructuredPromptProcessor.toPrompt(createRecipePrompt);
Response<String> response = model.generate(prompt);
System.out.println(response.content());
}
}
7. टेक्स्ट को कैटगरी में बांटना और भावनाओं का विश्लेषण करना
पिछले सेक्शन में आपने जो सीखा था उसी तरह, आपको "प्रॉम्प्ट इंजीनियरिंग" की एक और तकनीक के बारे में पता चलेगा. इससे PaLM मॉडल, टेक्स्ट को कैटगरी में बांट सकता है या भावनाओं का विश्लेषण कर सकता है. आइए, "फ़्यू-शॉट प्रॉम्प्टिंग" के बारे में बात करते हैं. यह कुछ उदाहरणों की मदद से, अपने प्रॉम्प्ट को बेहतर बनाने का तरीका है. इससे भाषा मॉडल को आपकी पसंद के मुताबिक काम करने में मदद मिलेगी. साथ ही, वह आपके इंटेंट को बेहतर तरीके से समझ पाएगा.
प्रॉम्प्ट टेंप्लेट का फ़ायदा पाने के लिए, आइए हम अपनी TextPrompts क्लास को फिर से बनाते हैं:
package palm.workshop;
import java.util.Map;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.model.vertexai.VertexAiLanguageModel;
import dev.langchain4j.model.input.Prompt;
import dev.langchain4j.model.input.PromptTemplate;
public class TextPrompts {
public static void main(String[] args) {
VertexAiLanguageModel model = VertexAiLanguageModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("text-bison@001")
.maxOutputTokens(10)
.build();
PromptTemplate promptTemplate = PromptTemplate.from("""
Analyze the sentiment of the text below. Respond only with one word to describe the sentiment.
INPUT: This is fantastic news!
OUTPUT: POSITIVE
INPUT: Pi is roughly equal to 3.14
OUTPUT: NEUTRAL
INPUT: I really disliked the pizza. Who would use pineapples as a pizza topping?
OUTPUT: NEGATIVE
INPUT: {{text}}
OUTPUT:
""");
Prompt prompt = promptTemplate.apply(
Map.of("text", "I love strawberries!"));
Response<String> response = model.generate(prompt);
System.out.println(response.content());
}
}
ध्यान दें कि प्रॉम्प्ट में, इनपुट और आउटपुट के कुछ उदाहरण दिए गए हैं. ये "कुछ उदाहरण" हैं, जिनसे एलएलएम को एक ही स्ट्रक्चर को फ़ॉलो करने में मदद मिलती है. इसके बाद, जब मॉडल को कोई इनपुट मिलता है, तो वह इनपुट/आउटपुट पैटर्न से मैच करने वाला आउटपुट देगा.
प्रोग्राम चलाने पर, सिर्फ़ POSITIVE शब्द दिखना चाहिए, क्योंकि स्ट्रॉबेरी भी स्वादिष्ट होती हैं!
$ ./gradlew run -DjavaMainClass=palm.workshop.TextPrompts
> Task :app:run
POSITIVE
भावनाओं का विश्लेषण भी कॉन्टेंट की कैटगरी तय करने का एक तरीका है. अलग-अलग दस्तावेज़ों को अलग-अलग कैटगरी बकेट में बांटने के लिए, "कुछ उदाहरणों के साथ प्रॉम्प्ट करना" तरीका इस्तेमाल किया जा सकता है.
8. बधाई हो
बधाई हो, आपने LangChain4J और PaLM API का इस्तेमाल करके, Java में अपना पहला जनरेटिव एआई ऐप्लिकेशन बना लिया है! आपको यह पता चला कि लार्ज लैंग्वेज मॉडल काफ़ी दमदार होते हैं. ये सवाल/जवाब देने, डेटा निकालने, खास जानकारी देने, टेक्स्ट को कैटगरी में बांटने, और भावनाओं का विश्लेषण करने जैसे कई काम कर सकते हैं.
आगे क्या करना है?
Java में PaLM का इस्तेमाल करने के बारे में ज़्यादा जानने के लिए, यहां दिए गए कुछ कोडलैब देखें:
इस बारे में और पढ़ें
- जनरेटिव एआई के इस्तेमाल के सामान्य उदाहरण
- जनरेटिव एआई के बारे में ट्रेनिंग के संसाधन
- Generative AI Studio के ज़रिए PaLM से इंटरैक्ट करना
- ज़िम्मेदारी के साथ एआई का इस्तेमाल