
১. সংক্ষিপ্ত বিবরণ
এই ল্যাবে, আপনি শিখবেন কীভাবে ফুল শনাক্ত করতে সক্ষম একটি নিউরাল নেটওয়ার্ক মডেলে কনভল্যুশনাল লেয়ার যুক্ত করতে হয়। এবার, আপনি নিজেই একেবারে গোড়া থেকে মডেলটি তৈরি করবেন এবং টিপিইউ (TPU)-এর শক্তি ব্যবহার করে কয়েক সেকেন্ডের মধ্যে এটিকে প্রশিক্ষণ দেবেন ও এর নকশার উন্নতি সাধন করবেন।
এই ল্যাবটিতে কনভল্যুশনাল নিউরাল নেটওয়ার্ক সম্পর্কে প্রয়োজনীয় তাত্ত্বিক ব্যাখ্যা রয়েছে এবং এটি ডেভেলপারদের ডিপ লার্নিং শেখার জন্য একটি ভালো সূচনা।
এই ল্যাবটি 'Keras on TPU' সিরিজের পার্ট ৩। আপনি এগুলো নিম্নলিখিত ক্রমানুসারে অথবা আলাদাভাবে করতে পারেন।
- TPU-গতির ডেটা পাইপলাইন: tf.data.Dataset এবং TFRecords
- ট্রান্সফার লার্নিং সহ আপনার প্রথম কেরাস মডেল
- [এই ল্যাব] কেরাস এবং টিপিইউ ব্যবহার করে কনভল্যুশনাল নিউরাল নেটওয়ার্ক
- আধুনিক কনভনেট, স্কুইজনেট, এক্সসেপশন, কেরাস এবং টিপিইউ সহ

আপনি যা শিখবেন
- কেরাস সিকোয়েনশিয়াল মডেল ব্যবহার করে একটি কনভল্যুশনাল ইমেজ ক্লাসিফায়ার তৈরি করা।
- TPU-তে আপনার Keras মডেলকে প্রশিক্ষণ দিতে
- সঠিক কনভল্যুশনাল লেয়ার নির্বাচনের মাধ্যমে আপনার মডেলকে নিখুঁত করতে।
প্রতিক্রিয়া
এই কোড ল্যাবে কোনো ভুল দেখলে, অনুগ্রহ করে আমাদের জানান। GitHub ইস্যুর মাধ্যমে মতামত জানানো যাবে [ মতামত লিঙ্ক ]।
২. গুগল কোলাবোরেটরি কুইক স্টার্ট
এই ল্যাবটি গুগল কোলাবোরেটরি ব্যবহার করে এবং এর জন্য আপনার পক্ষ থেকে কোনো সেটআপের প্রয়োজন নেই। কোলাবোরেটরি হলো শিক্ষামূলক উদ্দেশ্যে ব্যবহৃত একটি অনলাইন নোটবুক প্ল্যাটফর্ম। এটি বিনামূল্যে সিপিইউ, জিপিইউ এবং টিপিইউ প্রশিক্ষণের সুযোগ দেয়।

Colaboratory-র সাথে পরিচিত হওয়ার জন্য আপনি এই নমুনা নোটবুকটি খুলে কয়েকটি সেল চালিয়ে দেখতে পারেন।
একটি টিপিইউ ব্যাকএন্ড নির্বাচন করুন

Colab মেনুতে, Runtime > Change runtime type নির্বাচন করুন এবং তারপর TPU নির্বাচন করুন। এই কোড ল্যাবে আপনি হার্ডওয়্যার-ত্বরিত প্রশিক্ষণের জন্য একটি শক্তিশালী TPU (টেনসর প্রসেসিং ইউনিট) ব্যবহার করবেন। প্রথমবার চালানোর সময় রানটাইমের সাথে সংযোগ স্বয়ংক্রিয়ভাবে হয়ে যাবে, অথবা আপনি উপরের-ডান কোণায় থাকা "Connect" বোতামটি ব্যবহার করতে পারেন।
নোটবুক সম্পাদন

একটি সেলে ক্লিক করে Shift-ENTER ব্যবহার করে সেলগুলো এক এক করে চালান। এছাড়াও, আপনি Runtime > Run all ব্যবহার করে সম্পূর্ণ নোটবুকটি চালাতে পারেন।
সূচিপত্র

সব নোটবুকেই একটি সূচিপত্র থাকে। বামদিকের কালো তীরচিহ্নটি ব্যবহার করে আপনি সেটি খুলতে পারেন।
লুকানো কোষ

কিছু সেলে শুধুমাত্র তাদের শিরোনাম দেখা যাবে। এটি কোলাব-এর একটি নোটবুক বৈশিষ্ট্য। ভেতরের কোড দেখার জন্য আপনি এগুলোর উপর ডাবল ক্লিক করতে পারেন, কিন্তু তা সাধারণত খুব একটা আকর্ষণীয় হয় না। এগুলো সাধারণত সাপোর্ট বা ভিজ্যুয়ালাইজেশন ফাংশন। ভেতরের ফাংশনগুলো সংজ্ঞায়িত করার জন্য আপনাকে এই সেলগুলো রান করতে হবে।
প্রমাণীকরণ

একটি অনুমোদিত অ্যাকাউন্ট দিয়ে প্রমাণীকরণ করলে কোলাব আপনার ব্যক্তিগত গুগল ক্লাউড স্টোরেজ বাকেটগুলো অ্যাক্সেস করতে পারবে। উপরের কোড স্নিপেটটি একটি প্রমাণীকরণ প্রক্রিয়া চালু করবে।
৩. [তথ্য] টেনসর প্রসেসিং ইউনিট (টিপিইউ) কী?
সংক্ষেপে

Keras-এ TPU-তে একটি মডেল প্রশিক্ষণের জন্য কোড (এবং TPU উপলব্ধ না থাকলে GPU বা CPU-তে ফিরে যাওয়ার জন্য):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
আজ আমরা টিপিইউ ব্যবহার করে ইন্টারেক্টিভ গতিতে (প্রতি ট্রেনিং রানে কয়েক মিনিট) একটি ফ্লাওয়ার ক্লাসিফায়ার তৈরি ও অপ্টিমাইজ করব।
টিপিইউ কেন?
আধুনিক জিপিইউগুলো প্রোগ্রামযোগ্য 'কোর'-এর উপর ভিত্তি করে গঠিত, যা একটি অত্যন্ত নমনীয় আর্কিটেকচার এবং এর ফলে এগুলো থ্রিডি রেন্ডারিং, ডিপ লার্নিং, ফিজিক্যাল সিমুলেশন ইত্যাদির মতো বিভিন্ন ধরনের কাজ সামলাতে পারে। অন্যদিকে, টিপিইউগুলো একটি ক্লাসিক ভেক্টর প্রসেসরের সাথে একটি ডেডিকেটেড ম্যাট্রিক্স মাল্টিপ্লাই ইউনিটকে যুক্ত করে এবং নিউরাল নেটওয়ার্কের মতো যেকোনো কাজে পারদর্শী, যেখানে বড় ম্যাট্রিক্সের গুণন প্রাধান্য পায়।

উদাহরণ: একটি ডেন্স নিউরাল নেটওয়ার্ক লেয়ারকে ম্যাট্রিক্স গুণন হিসেবে দেখানো হয়েছে, যেখানে নিউরাল নেটওয়ার্কের মাধ্যমে একবারে আটটি ছবির একটি ব্যাচ প্রসেস করা হয়। এটি যে সত্যিই একটি ছবির সমস্ত পিক্সেল মানের ওয়েটেড সাম (weighted sum) করছে, তা যাচাই করার জন্য অনুগ্রহ করে একটি লাইন x কলাম গুণন প্রক্রিয়াটি চালিয়ে দেখুন। কনভল্যুশনাল লেয়ারগুলোকেও ম্যাট্রিক্স গুণন হিসেবে উপস্থাপন করা যায়, যদিও বিষয়টি কিছুটা বেশি জটিল (এর ব্যাখ্যা এখানে, সেকশন ১-এ দেওয়া আছে )।
হার্ডওয়্যার
MXU এবং VPU
একটি TPU v2 কোর একটি ম্যাট্রিক্স মাল্টিপ্লাই ইউনিট (MXU) দ্বারা গঠিত, যা ম্যাট্রিক্স গুণন সম্পাদন করে, এবং একটি ভেক্টর প্রসেসিং ইউনিট (VPU) দ্বারা গঠিত, যা অ্যাক্টিভেশন, সফটম্যাক্স ইত্যাদির মতো অন্যান্য সমস্ত কাজ করে। VPU ফ্লোট৩২ এবং ইন্ট৩২ গণনা পরিচালনা করে। অন্যদিকে, MXU একটি মিশ্র প্রিসিশন ১৬-৩২ বিট ফ্লোটিং পয়েন্ট ফরম্যাটে কাজ করে।

মিশ্র প্রিসিশন ফ্লোটিং পয়েন্ট এবং বিফ্লোট১৬
এমএক্সইউ (MXU) বিফ্লোট১৬ (bfloat16) ইনপুট এবং ফ্লোট৩২ (float32) আউটপুট ব্যবহার করে ম্যাট্রিক্স গুণন গণনা করে। মধ্যবর্তী সঞ্চয়নগুলো ফ্লোট৩২ (float32) প্রিসিশনে সম্পাদিত হয়।

নিউরাল নেটওয়ার্ক প্রশিক্ষণ সাধারণত হ্রাসকৃত ফ্লোটিং পয়েন্ট প্রিসিশনের কারণে সৃষ্ট নয়েজের বিরুদ্ধে প্রতিরোধী। এমনও ক্ষেত্র আছে যেখানে নয়েজ এমনকি অপটিমাইজারকে কনভার্জ করতে সাহায্য করে। গণনার গতি বাড়ানোর জন্য ঐতিহ্যগতভাবে ১৬-বিট ফ্লোটিং পয়েন্ট প্রিসিশন ব্যবহার করা হয়েছে, কিন্তু float16 এবং float32 ফরম্যাটের রেঞ্জ খুব আলাদা। float32 থেকে float16-এ প্রিসিশন কমালে সাধারণত ওভারফ্লো এবং আন্ডারফ্লো হয়। এর সমাধান আছে, কিন্তু float16-কে কার্যকর করতে সাধারণত অতিরিক্ত কাজ করার প্রয়োজন হয়।
এই কারণেই গুগল টিপিইউ-তে বিফ্লোট১৬ (bfloat16) ফরম্যাট চালু করেছে। বিফ্লোট১৬ হলো ফ্লোট৩২-এর একটি সংক্ষিপ্ত রূপ, যার এক্সপোনেন্ট বিট এবং রেঞ্জ হুবহু ফ্লোট৩২-এর সমান। এর সাথে এই বিষয়টিও যুক্ত যে, টিপিইউ-গুলো বিফ্লোট১৬ ইনপুট কিন্তু ফ্লোট৩২ আউটপুট ব্যবহার করে মিক্সড প্রিসিশনে ম্যাট্রিক্স গুণন গণনা করে। এর ফলে, কম প্রিসিশনের কারণে প্রাপ্ত পারফরম্যান্সের সুবিধাগুলো পেতে সাধারণত কোডে কোনো পরিবর্তনের প্রয়োজন হয় না।
সিস্টোলিক অ্যারে
এমএক্সইউ (MXU) তথাকথিত "সিস্টোলিক অ্যারে" আর্কিটেকচার ব্যবহার করে হার্ডওয়্যারে ম্যাট্রিক্স গুণন বাস্তবায়ন করে, যেখানে ডেটা উপাদানগুলো হার্ডওয়্যার কম্পিউটেশন ইউনিটের একটি অ্যারের মধ্য দিয়ে প্রবাহিত হয়। (চিকিৎসাবিজ্ঞানে, "সিস্টোলিক" বলতে হৃৎপিণ্ডের সংকোচন এবং রক্ত প্রবাহকে বোঝায়, এবং এখানে এটি ডেটার প্রবাহকে বোঝায়।)
ম্যাট্রিক্স গুণনের মূল উপাদান হলো একটি ম্যাট্রিক্সের একটি সারি এবং অন্য ম্যাট্রিক্সের একটি কলামের মধ্যে ডট প্রোডাক্ট (এই বিভাগের শীর্ষে থাকা চিত্রটি দেখুন)। Y=X*W ম্যাট্রিক্স গুণনের ক্ষেত্রে, ফলাফলের একটি উপাদান হবে:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
একটি জিপিইউ-তে, এই ডট প্রোডাক্টটি একটি জিপিইউ "কোর"-এ প্রোগ্রাম করা হয় এবং তারপর ফলাফল ম্যাট্রিক্সের প্রতিটি মান একবারে গণনা করার জন্য উপলব্ধ যতগুলো "কোর" আছে, সেগুলোতে এটি চালানো হয়। যদি ফলাফল ম্যাট্রিক্সটি 128x128 আকারের হয়, তবে এর জন্য 128x128=16K "কোর" উপলব্ধ থাকার প্রয়োজন হবে, যা সাধারণত সম্ভব নয়। সবচেয়ে বড় জিপিইউ-গুলোতে প্রায় 4000 কোর থাকে। অন্যদিকে, একটি টিপিইউ তার এমএক্সইউ-এর কম্পিউট ইউনিটগুলোর জন্য ন্যূনতম হার্ডওয়্যার ব্যবহার করে: শুধু bfloat16 x bfloat16 => float32 মাল্টিপ্লাই-অ্যাকুমুলেটর, আর কিছু নয়। এগুলো এতটাই ছোট যে একটি টিপিইউ একটি 128x128 এমএক্সইউ-তে এগুলোর 16K ইমপ্লিমেন্ট করতে পারে এবং এই ম্যাট্রিক্স গুণনটি একবারে প্রক্রিয়া করতে পারে।

উদাহরণ: এমএক্সইউ সিস্টোলিক অ্যারে। এর কম্পিউট এলিমেন্টগুলো হলো মাল্টিপ্লাই-অ্যাকুমুলেটর। একটি ম্যাট্রিক্সের মানগুলো অ্যারেতে লোড করা হয় (লাল বিন্দু)। অন্য ম্যাট্রিক্সের মানগুলো অ্যারের মধ্য দিয়ে প্রবাহিত হয় (ধূসর বিন্দু)। উল্লম্ব রেখাগুলো মানগুলোকে উপরের দিকে সঞ্চারিত করে। আনুভূমিক রেখাগুলো আংশিক যোগফল সঞ্চারিত করে। ব্যবহারকারীর জন্য এটি একটি অনুশীলন হিসেবে রেখে দেওয়া হলো যে, ডেটা অ্যারের মধ্য দিয়ে প্রবাহিত হওয়ার সময় ম্যাট্রিক্স গুণফলের ফলাফলটি ডান দিক থেকে বেরিয়ে আসছে কি না, তা যাচাই করা।
এর পাশাপাশি, যখন একটি MXU-তে ডট প্রোডাক্ট গণনা করা হয়, তখন মধ্যবর্তী যোগফলগুলো কেবল পাশাপাশি থাকা কম্পিউট ইউনিটগুলোর মধ্যে প্রবাহিত হয়। এগুলোকে মেমোরি বা এমনকি কোনো রেজিস্টার ফাইলে সংরক্ষণ বা সেখান থেকে পুনরুদ্ধার করার প্রয়োজন হয় না। এর ফলে, ম্যাট্রিক্স গুণন গণনার ক্ষেত্রে TPU সিস্টোলিক অ্যারে আর্কিটেকচারটি GPU-এর তুলনায় ঘনত্ব ও শক্তির দিক থেকে উল্লেখযোগ্য সুবিধা দেয়, এবং সেই সাথে এর গতিও নগণ্য নয়।
ক্লাউড টিপিইউ
যখন আপনি গুগল ক্লাউড প্ল্যাটফর্মে একটি " ক্লাউড টিপিইউ ভি২" এর জন্য অনুরোধ করেন, তখন আপনি একটি ভার্চুয়াল মেশিন (ভিএম) পান, যেটিতে একটি পিসিআই-সংযুক্ত টিপিইউ বোর্ড থাকে। টিপিইউ বোর্ডটিতে চারটি ডুয়াল-কোর টিপিইউ চিপ থাকে। প্রতিটি টিপিইউ কোরে একটি ভিপিইউ (ভেক্টর প্রসেসিং ইউনিট) এবং একটি ১২৮x১২৮ এমএক্সইউ (ম্যাট্রিক্স মাল্টিপ্লাই ইউনিট) থাকে। এরপর এই "ক্লাউড টিপিইউ" সাধারণত নেটওয়ার্কের মাধ্যমে সেই ভিএম-এর সাথে সংযুক্ত হয়, যেটি এটির জন্য অনুরোধ করেছিল। সুতরাং, সম্পূর্ণ চিত্রটি দেখতে এইরকম:

উদাহরণ: নেটওয়ার্ক-সংযুক্ত 'ক্লাউড টিপিইউ' অ্যাক্সেলারেটরসহ আপনার ভিএম। 'ক্লাউড টিপিইউ' নিজেই একটি ভিএম দিয়ে তৈরি, যার সাথে একটি পিসিআই-সংযুক্ত টিপিইউ বোর্ড রয়েছে এবং এতে চারটি ডুয়াল-কোর টিপিইউ চিপ আছে।
টিপিইউ পড
গুগলের ডেটা সেন্টারগুলিতে, টিপিইউ-গুলি একটি হাই-পারফরম্যান্স কম্পিউটিং (এইচপিসি) ইন্টারকানেক্টের সাথে সংযুক্ত থাকে, যা সেগুলিকে একটি বিশাল অ্যাক্সিলারেটর হিসাবে উপস্থাপন করতে পারে। গুগল এগুলিকে 'পড' বলে এবং এগুলিতে সর্বোচ্চ ৫১২টি টিপিইউ ভি২ কোর বা ২০৪৮টি টিপিইউ ভি৩ কোর থাকতে পারে।

উদাহরণ: একটি TPU v3 পড। TPU বোর্ড এবং র্যাকগুলো HPC ইন্টারকানেক্টের মাধ্যমে সংযুক্ত।
প্রশিক্ষণের সময়, অল-রিডিউস অ্যালগরিদম ব্যবহার করে টিপিইউ কোরগুলোর মধ্যে গ্রেডিয়েন্ট বিনিময় করা হয় ( অল-রিডিউস সম্পর্কে এখানে একটি ভালো ব্যাখ্যা রয়েছে )। প্রশিক্ষণাধীন মডেলটি বড় ব্যাচ সাইজে প্রশিক্ষণ নিয়ে হার্ডওয়্যারের সুবিধা নিতে পারে।

দৃষ্টান্ত: গুগল টিপিইউ-এর দ্বি-মাত্রিক টরয়েডাল মেশ এইচপিসি নেটওয়ার্কে অল-রিডিউস অ্যালগরিদম ব্যবহার করে প্রশিক্ষণের সময় গ্রেডিয়েন্টের সিঙ্ক্রোনাইজেশন।
সফটওয়্যারটি
বড় ব্যাচের প্রশিক্ষণ
টিপিইউ-এর জন্য আদর্শ ব্যাচ সাইজ হলো প্রতি টিপিইউ কোরে ১২৮টি ডেটা আইটেম, কিন্তু হার্ডওয়্যারটি প্রতি টিপিইউ কোরে ৮টি ডেটা আইটেম থেকেই ভালো ইউটিলাইজেশন দেখাতে পারে। মনে রাখবেন যে একটি ক্লাউড টিপিইউ-তে ৮টি কোর থাকে।
এই কোড ল্যাবে আমরা কেরাস এপিআই (Keras API) ব্যবহার করব। কেরাসে, আপনার নির্দিষ্ট করা ব্যাচটি হলো পুরো টিপিইউ (TPU)-এর জন্য গ্লোবাল ব্যাচ সাইজ। আপনার ব্যাচগুলো স্বয়ংক্রিয়ভাবে ৮ ভাগে বিভক্ত হয়ে টিপিইউ-এর ৮টি কোরে রান করবে।

অতিরিক্ত পারফরম্যান্স টিপসের জন্য টিপিইউ পারফরম্যান্স গাইড দেখুন। খুব বড় ব্যাচ সাইজের ক্ষেত্রে, কিছু মডেলে বিশেষ যত্নের প্রয়োজন হতে পারে, আরও বিস্তারিত জানতে LARSOptimizer দেখুন।
ভেতরে: XLA
Tensorflow প্রোগ্রামগুলো কম্পিউটেশন গ্রাফ নির্ধারণ করে। TPU সরাসরি পাইথন কোড চালায় না, এটি আপনার Tensorflow প্রোগ্রাম দ্বারা নির্ধারিত কম্পিউটেশন গ্রাফটি চালায়। নেপথ্যে, XLA (অ্যাক্সিলারেটেড লিনিয়ার অ্যালজেব্রা কম্পাইলার) নামক একটি কম্পাইলার Tensorflow-এর কম্পিউটেশন নোডগুলোর গ্রাফকে TPU মেশিন কোডে রূপান্তরিত করে। এই কম্পাইলারটি আপনার কোড এবং মেমরি লেআউটের উপর অনেক উন্নত অপটিমাইজেশনও সম্পাদন করে। TPU-তে কাজ পাঠানোর সাথে সাথে কম্পাইলেশনটি স্বয়ংক্রিয়ভাবে সম্পন্ন হয়। আপনাকে আপনার বিল্ড চেইনে স্পষ্টভাবে XLA অন্তর্ভুক্ত করতে হবে না।

উদাহরণস্বরূপ: TPU-তে চালানোর জন্য, আপনার Tensorflow প্রোগ্রাম দ্বারা সংজ্ঞায়িত কম্পিউটেশন গ্রাফটিকে প্রথমে একটি XLA (অ্যাক্সিলারেটেড লিনিয়ার অ্যালজেব্রা কম্পাইলার) উপস্থাপনায় রূপান্তরিত করা হয়, এবং তারপর XLA দ্বারা কম্পাইল করে TPU মেশিন কোডে পরিণত করা হয়।
কেরাসে টিপিইউ ব্যবহার
Tensorflow 2.1 থেকে Keras API-এর মাধ্যমে TPU সমর্থিত। Keras সাপোর্ট TPU এবং TPU পড-এ কাজ করে। এখানে একটি উদাহরণ দেওয়া হলো যা TPU, GPU এবং CPU-তে কাজ করে:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
এই কোড স্নিপেটে:
-
TPUClusterResolver().connect()নেটওয়ার্কে TPU খুঁজে বের করে। এটি বেশিরভাগ গুগল ক্লাউড সিস্টেমে (এআই প্ল্যাটফর্ম জব, কোলাবোরেটরি, কুবেফ্লো, 'ctpu up' ইউটিলিটির মাধ্যমে তৈরি করা ডিপ লার্নিং ভিএম) প্যারামিটার ছাড়াই কাজ করে। এই সিস্টেমগুলো একটি TPU_NAME এনভায়রনমেন্ট ভেরিয়েবলের মাধ্যমে জানে তাদের TPU কোথায় আছে। আপনি যদি নিজে থেকে একটি TPU তৈরি করেন, তাহলে যে ভিএম থেকে এটি ব্যবহার করছেন সেখানে TPU_NAME এনভায়রনমেন্ট ভেরিয়েবলটি সেট করুন, অথবা সুস্পষ্ট প্যারামিটারসহTPUClusterResolverকল করুন:TPUClusterResolver(tp_uname, zone, project) -
TPUStrategyহলো সেই অংশ যা ডিস্ট্রিবিউশন এবং "অল-রিডিউস" গ্রেডিয়েন্ট সিনক্রোনাইজেশন অ্যালগরিদম বাস্তবায়ন করে। - কৌশলটি একটি স্কোপের মাধ্যমে প্রয়োগ করা হয়। মডেলটিকে অবশ্যই কৌশলের স্কোপ()-এর মধ্যে সংজ্ঞায়িত করতে হবে।
- TPU প্রশিক্ষণের জন্য ইনপুট হিসেবে
tpu_model.fitফাংশনটি একটি tf.data.Dataset অবজেক্ট গ্রহণ করে।
সাধারণ TPU পোর্টিং টাস্ক
- টেনসরফ্লো মডেলে ডেটা লোড করার অনেক উপায় থাকলেও, টিপিইউ-এর জন্য
tf.data.DatasetAPI-এর ব্যবহার আবশ্যক। - টিপিইউগুলো খুব দ্রুতগতির এবং এগুলোতে চলার সময় ডেটা গ্রহণ করা প্রায়শই একটি প্রতিবন্ধকতা হয়ে দাঁড়ায়। ডেটার প্রতিবন্ধকতা শনাক্ত করার জন্য আপনি বিভিন্ন টুল ব্যবহার করতে পারেন এবং টিপিইউ পারফরম্যান্স গাইডে অন্যান্য পারফরম্যান্স টিপসও রয়েছে।
- int8 বা int16 সংখ্যাগুলোকে int32 হিসেবে গণ্য করা হয়। TPU-তে ৩২ বিটের কম বিটে কাজ করার মতো কোনো ইন্টিজার হার্ডওয়্যার নেই।
- কিছু টেনসরফ্লো অপারেশন সমর্থিত নয়। তালিকাটি এখানে দেওয়া আছে । সুখবর হলো, এই সীমাবদ্ধতা শুধুমাত্র ট্রেনিং কোডের ক্ষেত্রে প্রযোজ্য, অর্থাৎ আপনার মডেলের ফরোয়ার্ড এবং ব্যাকওয়ার্ড পাসের ক্ষেত্রে। আপনি আপনার ডেটা ইনপুট পাইপলাইনে সমস্ত টেনসরফ্লো অপারেশন ব্যবহার করতে পারবেন, কারণ এটি সিপিইউ-তে এক্সিকিউট হবে।
-
tf.py_funcটিপিইউ-তে সমর্থিত নয়।
৪. [তথ্য] নিউরাল নেটওয়ার্ক ক্লাসিফায়ার ১০১
সংক্ষেপে
পরবর্তী অনুচ্ছেদে বোল্ড করা সমস্ত পরিভাষা যদি আপনার আগে থেকেই জানা থাকে, তাহলে আপনি পরবর্তী অনুশীলনীতে যেতে পারেন। আর আপনি যদি ডিপ লার্নিং সবে শুরু করে থাকেন, তাহলে আপনাকে স্বাগতম, এবং অনুগ্রহ করে পড়তে থাকুন।
ধারাবাহিকভাবে স্তর দিয়ে তৈরি মডেলের জন্য কেরাস সিকোয়েনশিয়াল এপিআই (Sequential API) প্রদান করে। উদাহরণস্বরূপ, তিনটি ডেন্স লেয়ার ব্যবহার করে একটি ইমেজ ক্লাসিফায়ার কেরাসে এভাবে লেখা যেতে পারে:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
ঘন নিউরাল নেটওয়ার্ক
এটি ছবি শ্রেণীবদ্ধ করার জন্য সবচেয়ে সরল নিউরাল নেটওয়ার্ক। এটি স্তরে স্তরে সাজানো "নিউরন" দিয়ে গঠিত। প্রথম স্তরটি ইনপুট ডেটা প্রক্রিয়াজাত করে এবং এর আউটপুট অন্যান্য স্তরে প্রেরণ করে। একে "ডেনস" বলা হয় কারণ প্রতিটি নিউরন পূর্ববর্তী স্তরের সমস্ত নিউরনের সাথে সংযুক্ত থাকে।

একটি ছবির সমস্ত পিক্সেলের RGB মানগুলিকে একটি দীর্ঘ ভেক্টরে পরিণত করে সেটিকে ইনপুট হিসাবে ব্যবহার করে এই ধরনের নেটওয়ার্কে ছবিটি পাঠানো যায়। এটি ছবি শনাক্তকরণের জন্য সেরা কৌশল নয়, তবে আমরা পরে এটিকে আরও উন্নত করব।
নিউরন, সক্রিয়করণ, RELU
একটি "নিউরন" তার সমস্ত ইনপুটের একটি ওয়েটেড সাম (ভারযুক্ত যোগফল) গণনা করে, এর সাথে "বায়াস" নামক একটি মান যোগ করে এবং ফলাফলটিকে একটি "অ্যাক্টিভেশন ফাংশন"-এর মধ্য দিয়ে পাঠায়। ওয়েট এবং বায়াস প্রথমে অজানা থাকে। এগুলোকে এলোমেলোভাবে প্রারম্ভিক মান দেওয়া হয় এবং প্রচুর জ্ঞাত ডেটার উপর নিউরাল নেটওয়ার্ককে প্রশিক্ষণ দিয়ে "শেখা" হয়।

সবচেয়ে জনপ্রিয় অ্যাক্টিভেশন ফাংশনটিকে RELU বা Rectified Linear Unit বলা হয়। এটি একটি খুব সহজ ফাংশন, যেমনটি আপনি উপরের গ্রাফটিতে দেখতে পাচ্ছেন।
সফটম্যাক্স অ্যাক্টিভেশন
উপরের নেটওয়ার্কটি একটি ৫-নিউরন লেয়ারে শেষ হয়েছে, কারণ আমরা ফুলগুলোকে ৫টি শ্রেণীতে (গোলাপ, টিউলিপ, ড্যান্ডেলিয়ন, ডেইজি, সূর্যমুখী) ভাগ করছি। মধ্যবর্তী লেয়ারগুলোর নিউরনগুলো ক্লাসিক RELU অ্যাক্টিভেশন ফাংশন ব্যবহার করে সক্রিয় করা হয়। তবে, শেষ লেয়ারে আমরা ০ থেকে ১-এর মধ্যে এমন সংখ্যা গণনা করতে চাই, যা এই ফুলটি গোলাপ, টিউলিপ ইত্যাদি হওয়ার সম্ভাবনাকে নির্দেশ করে। এর জন্য আমরা "softmax" নামক একটি অ্যাক্টিভেশন ফাংশন ব্যবহার করব।
একটি ভেক্টরের উপর সফটম্যাক্স প্রয়োগ করা হয় এর প্রতিটি উপাদানের এক্সপোনেনশিয়াল নিয়ে এবং তারপর ভেক্টরটিকে নর্মালাইজ করে, সাধারণত L1 নর্ম (পরম মানগুলোর যোগফল) ব্যবহার করে, যাতে মানগুলোর যোগফল ১ হয় এবং সেগুলোকে সম্ভাবনা হিসেবে ব্যাখ্যা করা যায়।
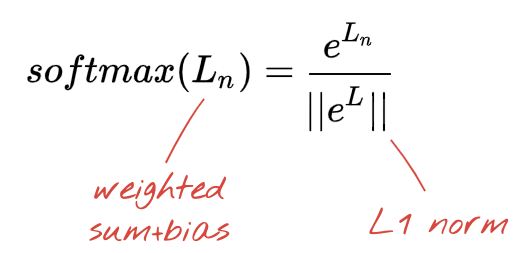

ক্রস-এনট্রপি হ্রাস
এখন যেহেতু আমাদের নিউরাল নেটওয়ার্ক ইনপুট ছবিগুলো থেকে পূর্বাভাস তৈরি করছে, আমাদের পরিমাপ করতে হবে সেগুলো কতটা ভালো, অর্থাৎ নেটওয়ার্ক যা বলছে এবং সঠিক উত্তরের (যাকে প্রায়শই 'লেবেল' বলা হয়) মধ্যেকার পার্থক্য। মনে রাখবেন যে ডেটাসেটের সমস্ত ছবির জন্যই আমাদের কাছে সঠিক লেবেল রয়েছে।
যেকোনো দূরত্বই কাজ করবে, কিন্তু ক্লাসিফিকেশন সমস্যার জন্য তথাকথিত 'ক্রস-এন্ট্রপি দূরত্ব' সবচেয়ে কার্যকর । আমরা একে আমাদের এরর বা 'লস' ফাংশন বলব:

গ্রেডিয়েন্ট অবতরণ
নিউরাল নেটওয়ার্ককে "প্রশিক্ষণ" দেওয়ার অর্থ হলো, প্রশিক্ষণ চিত্র এবং লেবেল ব্যবহার করে ওয়েট ও বায়াস এমনভাবে সমন্বয় করা, যাতে ক্রস-এন্ট্রপি লস ফাংশনটি সর্বনিম্ন হয়। এটি যেভাবে কাজ করে তা নিচে দেওয়া হলো।
ক্রস-এন্ট্রপি হলো ট্রেনিং ইমেজের ওয়েট, বায়াস, পিক্সেল এবং এর জ্ঞাত ক্লাসের একটি ফাংশন।
যদি আমরা সমস্ত ওয়েট এবং সমস্ত বায়াসের সাপেক্ষে ক্রস-এনট্রপির আংশিক ডেরিভেটিভ গণনা করি, তাহলে আমরা একটি "গ্রেডিয়েন্ট" পাই, যা একটি প্রদত্ত ইমেজ, লেবেল এবং ওয়েট ও বায়াসের বর্তমান মানের জন্য গণনা করা হয়। মনে রাখবেন যে আমাদের লক্ষ লক্ষ ওয়েট এবং বায়াস থাকতে পারে, তাই গ্রেডিয়েন্ট গণনা করা অনেক বড় কাজ বলে মনে হতে পারে। সৌভাগ্যবশত, টেনসরফ্লো আমাদের জন্য এটি করে দেয়। একটি গ্রেডিয়েন্টের গাণিতিক বৈশিষ্ট্য হলো এটি "উপরের দিকে" নির্দেশ করে। যেহেতু আমরা সেখানে যেতে চাই যেখানে ক্রস-এনট্রপি কম, তাই আমরা বিপরীত দিকে যাই। আমরা গ্রেডিয়েন্টের একটি ভগ্নাংশ দ্বারা ওয়েট এবং বায়াস আপডেট করি। তারপর আমরা একটি ট্রেনিং লুপের মধ্যে ট্রেনিং ইমেজ এবং লেবেলের পরবর্তী ব্যাচগুলো ব্যবহার করে একই কাজ বারবার করতে থাকি। আশা করা যায়, এটি এমন একটি জায়গায় পৌঁছাবে যেখানে ক্রস-এনট্রপি সর্বনিম্ন হবে, যদিও এই সর্বনিম্ন মানটি যে অনন্য হবে তার কোনো নিশ্চয়তা নেই।

মিনি-ব্যাচিং এবং গতি
আপনি শুধুমাত্র একটি উদাহরণ চিত্রের উপর আপনার গ্রেডিয়েন্ট গণনা করতে পারেন এবং অবিলম্বে ওয়েট ও বায়াস আপডেট করতে পারেন, কিন্তু উদাহরণস্বরূপ, ১২৮টি চিত্রের একটি ব্যাচের উপর এটি করলে এমন একটি গ্রেডিয়েন্ট পাওয়া যায় যা বিভিন্ন উদাহরণ চিত্র দ্বারা আরোপিত সীমাবদ্ধতাগুলিকে আরও ভালোভাবে উপস্থাপন করে এবং তাই সমাধানের দিকে দ্রুত অভিসারী হওয়ার সম্ভাবনা থাকে। মিনি-ব্যাচের আকার একটি পরিবর্তনযোগ্য প্যারামিটার।
এই কৌশলটি, যাকে কখনও কখনও 'স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট' বলা হয়, এর আরও একটি বাস্তবসম্মত সুবিধা রয়েছে: ব্যাচ পদ্ধতিতে কাজ করার অর্থ হলো আরও বড় ম্যাট্রিক্স নিয়ে কাজ করা, এবং এগুলো সাধারণত GPU ও TPU-তে অপ্টিমাইজ করা সহজ হয়।
তবে অভিসরণ প্রক্রিয়াটি তখনও কিছুটা বিশৃঙ্খল হতে পারে এবং গ্রেডিয়েন্ট ভেক্টরের সব উপাদান শূন্য হলে এটি থেমেও যেতে পারে। তার মানে কি আমরা একটি সর্বনিম্ন বিন্দু খুঁজে পেয়েছি? সবসময় না। একটি গ্রেডিয়েন্ট উপাংশ সর্বনিম্ন বা সর্বোচ্চ বিন্দুতেও শূন্য হতে পারে। লক্ষ লক্ষ উপাদানবিশিষ্ট একটি গ্রেডিয়েন্ট ভেক্টরের ক্ষেত্রে, যদি সবগুলোই শূন্য হয়, তবে প্রতিটি শূন্যই একটি সর্বনিম্ন বিন্দুর সাথে এবং কোনোটিই সর্বোচ্চ বিন্দুর সাথে সম্পর্কিত না হওয়ার সম্ভাবনা খুবই কম। বহু-মাত্রিক পরিসরে স্যাডল পয়েন্ট বেশ সাধারণ এবং আমরা সেখানে থেমে যেতে চাই না।

উদাহরণ: একটি স্যাডল পয়েন্ট। এর গ্রেডিয়েন্ট ০, কিন্তু এটি সব দিকেই সর্বনিম্ন নয়। (ছবির স্বত্ব উইকিমিডিয়া: নিকোগুয়ারোর নিজস্ব কাজ, সিসি বাই ৩.০ )
এর সমাধান হলো অপ্টিমাইজেশন অ্যালগরিদমে কিছুটা গতি যোগ করা, যাতে এটি না থেমে স্যাডল পয়েন্টগুলো অতিক্রম করতে পারে।
শব্দকোষ
ব্যাচ বা মিনি-ব্যাচ : প্রশিক্ষণ সর্বদা প্রশিক্ষণ ডেটা এবং লেবেলের ব্যাচের উপর সঞ্চালিত হয়। এটি অ্যালগরিদমকে অভিসৃত হতে সাহায্য করে। "ব্যাচ" ডাইমেনশনটি সাধারণত ডেটা টেনসরের প্রথম ডাইমেনশন হয়। উদাহরণস্বরূপ, [100, 192, 192, 3] আকারের একটি টেনসরে 192x192 পিক্সেলের 100টি ছবি থাকে, যেখানে প্রতি পিক্সেলে তিনটি মান (RGB) থাকে।
ক্রস-এন্ট্রপি লস : একটি বিশেষ লস ফাংশন যা প্রায়শই ক্লাসিফায়ারে ব্যবহৃত হয়।
ঘন স্তর : নিউরনের এমন একটি স্তর যেখানে প্রতিটি নিউরন পূর্ববর্তী স্তরের সমস্ত নিউরনের সাথে সংযুক্ত থাকে।
ফিচার : একটি নিউরাল নেটওয়ার্কের ইনপুটগুলোকে কখনও কখনও "ফিচার" বলা হয়। একটি ডেটাসেটের কোন অংশগুলো (বা অংশগুলোর সংমিশ্রণ) একটি নিউরাল নেটওয়ার্কে ইনপুট হিসেবে দিলে ভালো প্রেডিকশন পাওয়া যাবে, তা বের করার কৌশলকে "ফিচার ইঞ্জিনিয়ারিং" বলা হয়।
লেবেল : সুপারভাইজড ক্লাসিফিকেশন সমস্যায় 'ক্লাস' বা সঠিক উত্তরের অপর নাম।
লার্নিং রেট : গ্রেডিয়েন্টের সেই ভগ্নাংশ, যার দ্বারা ট্রেনিং লুপের প্রতিটি ইটারেশনে ওয়েট এবং বায়াস আপডেট করা হয়।
লজিটস : অ্যাক্টিভেশন ফাংশন প্রয়োগ করার আগে নিউরনের একটি স্তরের আউটপুটকে "লজিটস" বলা হয়। এই পরিভাষাটি "লজিস্টিক ফাংশন" বা "সিগময়েড ফাংশন" থেকে এসেছে, যা একসময় সবচেয়ে জনপ্রিয় অ্যাক্টিভেশন ফাংশন ছিল। "লজিস্টিক ফাংশনের আগে নিউরনের আউটপুট" কথাটিকে সংক্ষেপে "লজিটস" বলা হতো।
লস (loss) : নিউরাল নেটওয়ার্কের আউটপুটগুলোকে সঠিক উত্তরের সাথে তুলনা করার জন্য ব্যবহৃত এরর ফাংশন।
নিউরন : এর ইনপুটগুলোর ভারযুক্ত যোগফল গণনা করে, একটি বায়াস যোগ করে এবং ফলাফলটিকে একটি অ্যাক্টিভেশন ফাংশনের মাধ্যমে প্রেরণ করে।
ওয়ান-হট এনকোডিং : ৫টির মধ্যে ৩ নম্বর ক্লাসকে ৫টি উপাদানের একটি ভেক্টর হিসেবে এনকোড করা হয়, যেখানে ৩য় উপাদানটি (১) ছাড়া বাকি সব উপাদান শূন্য থাকে।
relu : রেক্টিফাইড লিনিয়ার ইউনিট। নিউরনের জন্য একটি জনপ্রিয় অ্যাক্টিভেশন ফাংশন।
সিগময়েড : আরেকটি অ্যাক্টিভেশন ফাংশন যা একসময় জনপ্রিয় ছিল এবং বিশেষ ক্ষেত্রে এখনও কাজে লাগে।
সফটম্যাক্স : একটি বিশেষ অ্যাক্টিভেশন ফাংশন যা একটি ভেক্টরের উপর কাজ করে, এর বৃহত্তম উপাদান এবং অন্য সব উপাদানের মধ্যে পার্থক্য বাড়িয়ে দেয় এবং ভেক্টরটিকে এমনভাবে স্বাভাবিক করে যাতে এর যোগফল ১ হয়, ফলে এটিকে সম্ভাবনার ভেক্টর হিসেবে ব্যাখ্যা করা যায়। ক্লাসিফায়ারের শেষ ধাপ হিসেবে এটি ব্যবহৃত হয়।
টেনসর : একটি "টেনসর" হলো ম্যাট্রিক্সের মতো, কিন্তু এর মাত্রা সংখ্যা ইচ্ছামত হতে পারে। ১-মাত্রার টেনসর হলো একটি ভেক্টর। ২-মাত্রার টেনসর হলো একটি ম্যাট্রিক্স। এছাড়াও ৩, ৪, ৫ বা তার বেশি মাত্রার টেনসরও থাকতে পারে।
৫. [নতুন তথ্য] কনভল্যুশনাল নিউরাল নেটওয়ার্ক
সংক্ষেপে
পরবর্তী অনুচ্ছেদে বোল্ড করা সমস্ত পরিভাষা যদি আপনার আগে থেকেই জানা থাকে, তাহলে আপনি পরবর্তী অনুশীলনীতে যেতে পারেন। আপনি যদি কনভোলিউশনাল নিউরাল নেটওয়ার্ক নিয়ে সবেমাত্র কাজ শুরু করে থাকেন, তাহলে অনুগ্রহ করে পড়তে থাকুন।
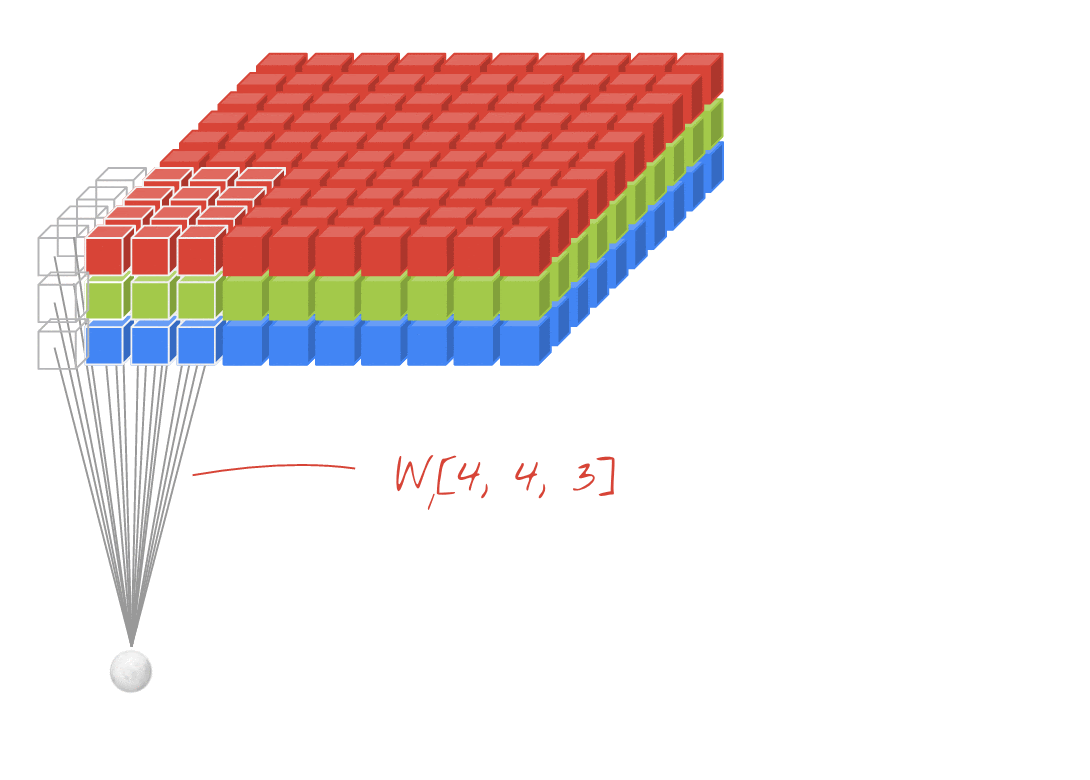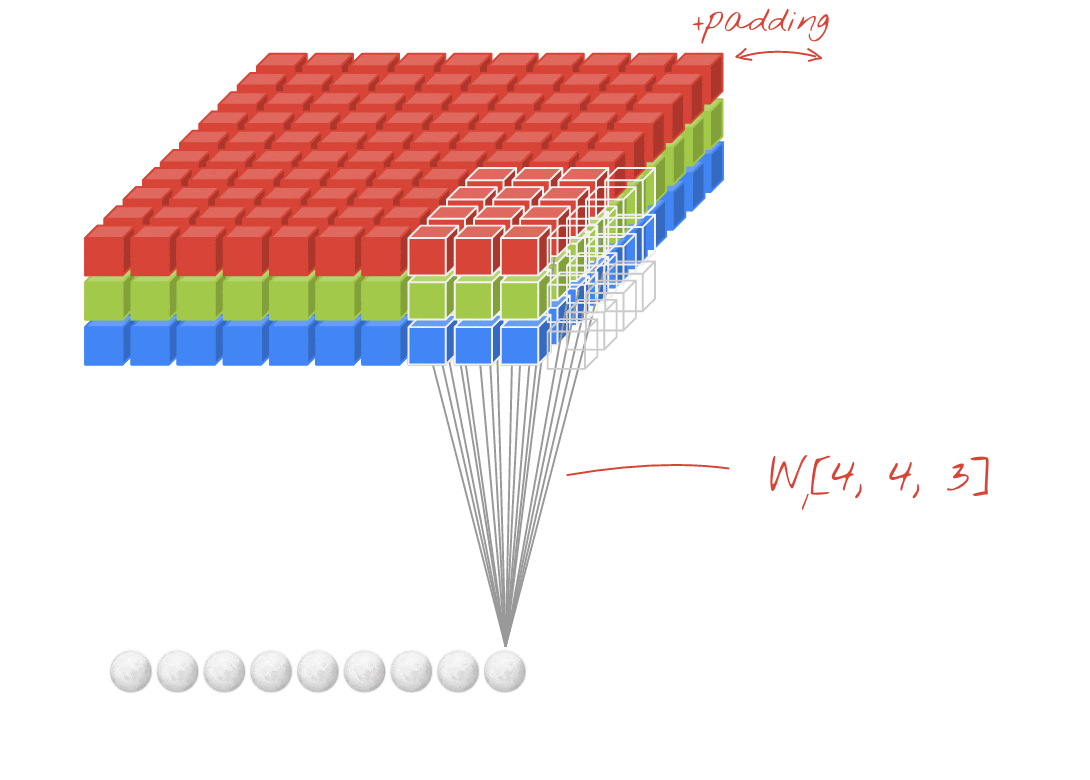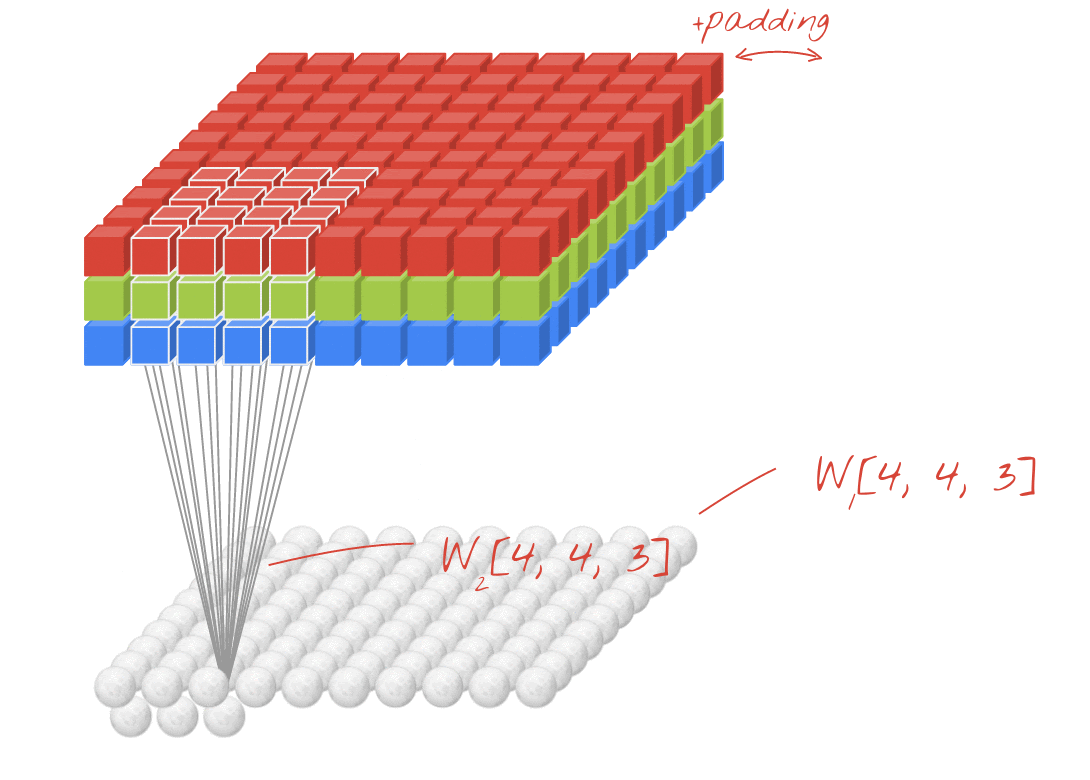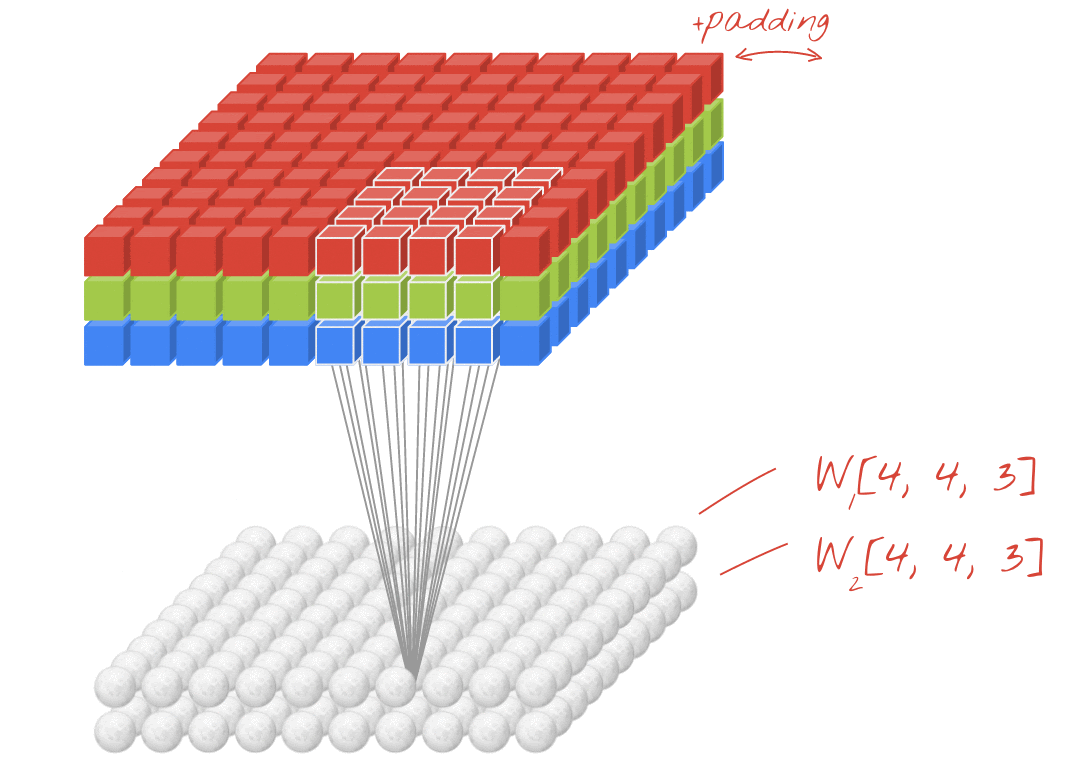
উদাহরণ: প্রতিটি 4x4x3=48টি শিখনীয় ওয়েট দিয়ে তৈরি দুটি পরপর ফিল্টার ব্যবহার করে একটি ছবিকে ফিল্টার করা।
কেরাসে একটি সাধারণ কনভল্যুশনাল নিউরাল নেটওয়ার্ক দেখতে এইরকম:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
কনভোলিউশনাল নিউরাল নেট ১০১
একটি কনভোলিউশনাল নেটওয়ার্কের একটি লেয়ারে, একটি "নিউরন" ছবির শুধুমাত্র একটি ছোট অঞ্চলের উপর তার ঠিক উপরের পিক্সেলগুলোর ওয়েটেড সাম (weighted sum) করে। এটি একটি বায়াস (bias) যোগ করে এবং যোগফলটিকে একটি অ্যাক্টিভেশন ফাংশনের মধ্যে দিয়ে পাঠায়, ঠিক যেমনটি একটি সাধারণ ডেন্স লেয়ারের নিউরন করে থাকে। এরপর এই প্রক্রিয়াটি একই ওয়েটগুলো ব্যবহার করে পুরো ছবি জুড়ে পুনরাবৃত্তি করা হয়। মনে রাখবেন যে ডেন্স লেয়ারগুলোতে প্রতিটি নিউরনের নিজস্ব ওয়েট থাকত। এখানে, ওয়েটের একটিমাত্র "প্যাচ" ছবির উপর দিয়ে উভয় দিকে স্লাইড করে (একটি "কনভোলিউশন")। আউটপুটে ছবিতে যতগুলো পিক্সেল আছে, ততগুলোই ভ্যালু থাকে (যদিও প্রান্তগুলোতে কিছু প্যাডিং প্রয়োজন হয়)। এটি একটি ফিল্টারিং প্রক্রিয়া, যেখানে 4x4x3=48টি ওয়েটের একটি ফিল্টার ব্যবহার করা হয়।
তবে, ৪৮টি ওয়েট যথেষ্ট হবে না। আরও বেশি স্বাধীনতা যোগ করার জন্য, আমরা নতুন এক সেট ওয়েট ব্যবহার করে একই প্রক্রিয়াটির পুনরাবৃত্তি করি। এর ফলে নতুন এক সেট ফিল্টার আউটপুট তৈরি হয়। ইনপুট ইমেজের R, G, B চ্যানেলের সাথে সাদৃশ্য রেখে, আমরা একে আউটপুটের একটি 'চ্যানেল' বলতে পারি।

একটি নতুন ডাইমেনশন যোগ করে দুই (বা ততোধিক) সেট ওয়েটকে একটি টেনসর হিসেবে যোগ করা যায়। এটি আমাদের একটি কনভোলিউশনাল লেয়ারের ওয়েট টেনসরের সাধারণ আকৃতি প্রদান করে। যেহেতু ইনপুট এবং আউটপুট চ্যানেলের সংখ্যা হলো প্যারামিটার, তাই আমরা কনভোলিউশনাল লেয়ারগুলোকে স্ট্যাকিং এবং চেইনিং শুরু করতে পারি।
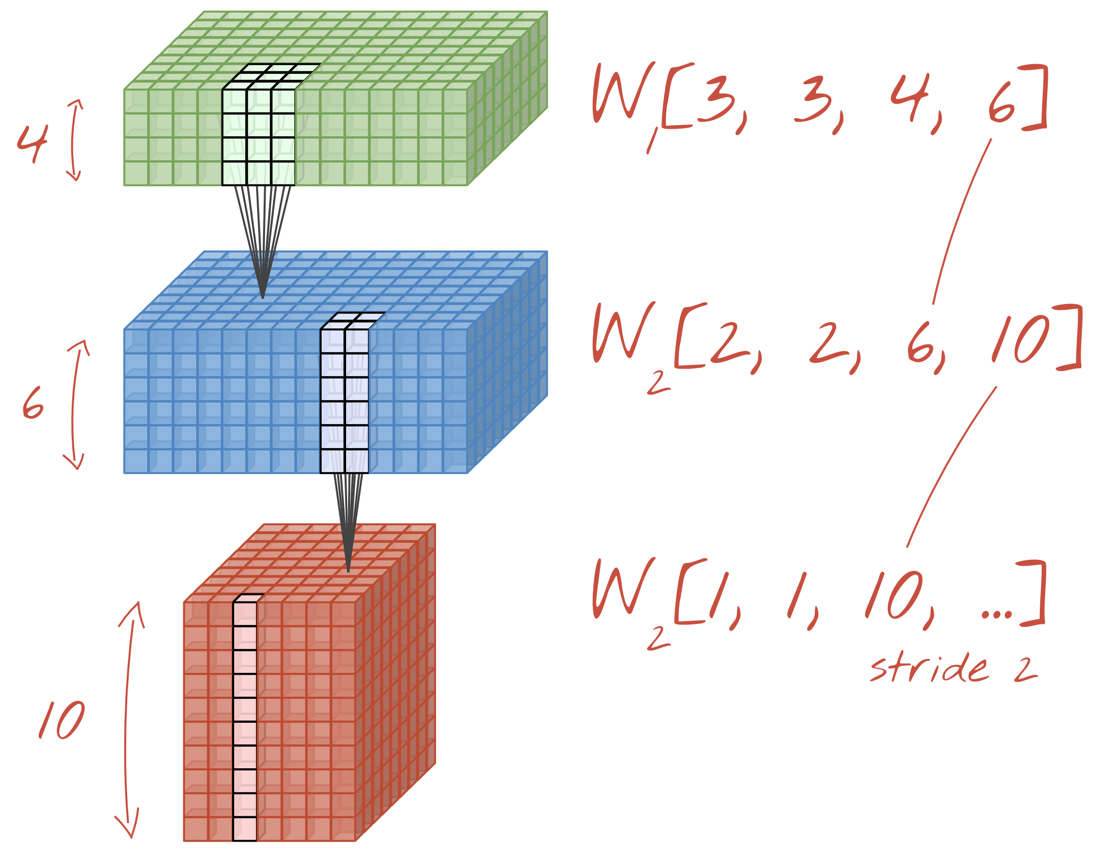
উদাহরণ: একটি কনভল্যুশনাল নিউরাল নেটওয়ার্ক ডেটার ‘কিউব’গুলোকে ডেটার অন্য ‘কিউব’-এ রূপান্তরিত করে।
স্ট্রাইডেড কনভোলিউশন, ম্যাক্স পুলিং
২ বা ৩ স্ট্রাইড ব্যবহার করে কনভোলিউশন করার মাধ্যমে আমরা প্রাপ্ত ডেটা কিউবটিকে এর আনুভূমিক দিকেও সংকুচিত করতে পারি। এটি করার দুটি প্রচলিত উপায় রয়েছে:
- স্ট্রাইডেড কনভোলিউশন: উপরেরটির মতো একটি স্লাইডিং ফিল্টার কিন্তু স্ট্রাইড >1 সহ।
- ম্যাক্স পুলিং: একটি স্লাইডিং উইন্ডো যা ম্যাক্স অপারেশন প্রয়োগ করে (সাধারণত ২x২ প্যাচের উপর, প্রতি ২ পিক্সেল পর পর পুনরাবৃত্তি করা হয়)।

উদাহরণস্বরূপ: কম্পিউটিং উইন্ডোকে ৩ পিক্সেল স্লাইড করলে আউটপুট মানের সংখ্যা কমে যায়। স্ট্রাইডেড কনভোলিউশন বা ম্যাক্স পুলিং (২ স্ট্রাইডে স্লাইড করা একটি ২x২ উইন্ডোতে ম্যাক্স অপারেশন) হলো ডেটা কিউবকে আনুভূমিক দিকে সংকুচিত করার একটি উপায়।
কনভোলিউশনাল ক্লাসিফায়ার
অবশেষে, আমরা শেষ ডেটা কিউবটিকে ফ্ল্যাট করে এবং একটি ডেন্স, সফটম্যাক্স-অ্যাক্টিভেটেড লেয়ারের মধ্য দিয়ে চালনা করে একটি ক্লাসিফিকেশন হেড সংযুক্ত করি। একটি সাধারণ কনভল্যুশনাল ক্লাসিফায়ার দেখতে এইরকম হতে পারে:

উদাহরণ: কনভল্যুশনাল এবং সফটম্যাক্স লেয়ার ব্যবহার করে একটি ইমেজ ক্লাসিফায়ার। এতে ৩x৩ এবং ১x১ ফিল্টার ব্যবহার করা হয়েছে। ম্যাক্সপুল লেয়ারগুলো ২x২ ডেটা পয়েন্টের গ্রুপগুলোর মধ্যে সর্বোচ্চ মানটি গ্রহণ করে। ক্লাসিফিকেশন হেডটি সফটম্যাক্স অ্যাক্টিভেশনসহ একটি ডেন্স লেয়ার দিয়ে বাস্তবায়ন করা হয়েছে।
কেরাসে
উপরে দেখানো কনভোলিউশনাল স্ট্যাকটি কেরাসে এইভাবে লেখা যেতে পারে:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=16, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=8, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
৬. আপনার কাস্টম কনভনেট
হাতে-কলমে
চলুন, আমরা একেবারে শুরু থেকে একটি কনভল্যুশনাল নিউরাল নেটওয়ার্ক তৈরি ও প্রশিক্ষণ দিই। একটি টিপিইউ (TPU) ব্যবহার করলে আমরা খুব দ্রুত পুনরাবৃত্তি করতে পারব। অনুগ্রহ করে নিম্নলিখিত নোটবুকটি খুলুন, সেলগুলো এক্সিকিউট করুন (Shift-ENTER) এবং যেখানেই "WORK REQUIRED" লেবেল দেখবেন, সেখানকার নির্দেশাবলী অনুসরণ করুন।

Keras_Flowers_TPU (playground).ipynb
লক্ষ্য হলো ট্রান্সফার লার্নিং মডেলের ৭৫% অ্যাকুরেসিকে ছাড়িয়ে যাওয়া। ঐ মডেলটির একটি সুবিধা ছিল, কারণ সেটি লক্ষ লক্ষ ছবির একটি ডেটাসেটের উপর প্রি-ট্রেইন করা হয়েছিল, যেখানে আমাদের কাছে এখানে মাত্র ৩৬৭০টি ছবি আছে। আপনি কি অন্তত এর সমকক্ষ হতে পারবেন?
অতিরিক্ত তথ্য
কয়টি স্তর, কত বড়?
লেয়ারের আকার নির্বাচন করা বিজ্ঞানের চেয়ে বেশি একটি শিল্প। আপনাকে খুব কম এবং খুব বেশি প্যারামিটারের (ওয়েট এবং বায়াস) মধ্যে সঠিক ভারসাম্য খুঁজে বের করতে হবে। খুব কম ওয়েট থাকলে, নিউরাল নেটওয়ার্ক ফুলের আকারের জটিলতাকে সঠিকভাবে উপস্থাপন করতে পারে না। খুব বেশি ওয়েট থাকলে, এটি "ওভারফিটিং"-এর ঝুঁকিতে পড়তে পারে, অর্থাৎ এটি ট্রেনিং ইমেজের উপর বিশেষায়িত হয়ে পড়ে এবং সাধারণীকরণ করতে পারে না। অনেক বেশি প্যারামিটার থাকলে, মডেলটি ট্রেইন হতেও ধীর হয়ে যাবে। Keras-এ, model.summary() ফাংশনটি আপনার মডেলের গঠন এবং প্যারামিটার সংখ্যা প্রদর্শন করে:
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 192, 192, 16) 448
_________________________________________________________________
conv2d_1 (Conv2D) (None, 192, 192, 30) 4350
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 96, 96, 30) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 96, 96, 60) 16260
_________________________________________________________________
...
_________________________________________________________________
global_average_pooling2d (Gl (None, 130) 0
_________________________________________________________________
dense (Dense) (None, 90) 11790
_________________________________________________________________
dense_1 (Dense) (None, 5) 455
=================================================================
Total params: 300,033
Trainable params: 300,033
Non-trainable params: 0
_________________________________________________________________
কয়েকটি পরামর্শ:
- একাধিক স্তর থাকাই ‘ডিপ’ নিউরাল নেটওয়ার্ককে কার্যকর করে তোলে। এই সাধারণ ফুল শনাক্তকরণের সমস্যার জন্য ৫ থেকে ১০টি স্তরই যথেষ্ট।
- ছোট ফিল্টার ব্যবহার করুন। সাধারণত ৩x৩ ফিল্টার সব জায়গায় ভালো কাজ করে।
- ১x১ ফিল্টারও ব্যবহার করা যায় এবং এগুলো সস্তা। এগুলো আসলে কোনো কিছু "ফিল্টার" করে না, বরং চ্যানেলগুলোর রৈখিক সমন্বয় গণনা করে। আসল ফিল্টারের সাথে পর্যায়ক্রমে এগুলো ব্যবহার করুন। (পরবর্তী বিভাগে "১x১ কনভোলিউশন" সম্পর্কে আরও আলোচনা করা হবে।)
- এই ধরনের ক্লাসিফিকেশন সমস্যার জন্য, ম্যাক্স-পুলিং লেয়ার (অথবা স্ট্রাইড >১ যুক্ত কনভোলিউশন) ব্যবহার করে ঘন ঘন ডাউনস্যাম্পল করুন। ফুলটি কোথায় আছে তা আপনার বিবেচ্য নয়, শুধু এটি গোলাপ না ড্যান্ডেলিয়ন, সেটাই যথেষ্ট; তাই x এবং y তথ্য হারিয়ে যাওয়াটা গুরুত্বপূর্ণ নয় এবং ছোট ছোট এলাকা ফিল্টার করা তুলনামূলকভাবে সাশ্রয়ী।
- নেটওয়ার্কের শেষের দিকে ফিল্টারের সংখ্যা সাধারণত ক্লাসের সংখ্যার সমান হয়ে যায় (কেন? নিচে 'গ্লোবাল অ্যাভারেজ পুলিং' কৌশলটি দেখুন)। যদি আপনি শত শত ক্লাসে শ্রেণীবদ্ধ করেন, তবে পরপর লেয়ারগুলোতে ক্রমান্বয়ে ফিল্টারের সংখ্যা বাড়ান। ৫টি ক্লাসযুক্ত ফুলের ডেটাসেটের জন্য, শুধুমাত্র ৫টি ফিল্টার দিয়ে ফিল্টারিং করা যথেষ্ট হবে না। আপনি বেশিরভাগ লেয়ারে একই সংখ্যক ফিল্টার ব্যবহার করতে পারেন, যেমন ৩২টি, এবং শেষের দিকে তা কমিয়ে আনতে পারেন।
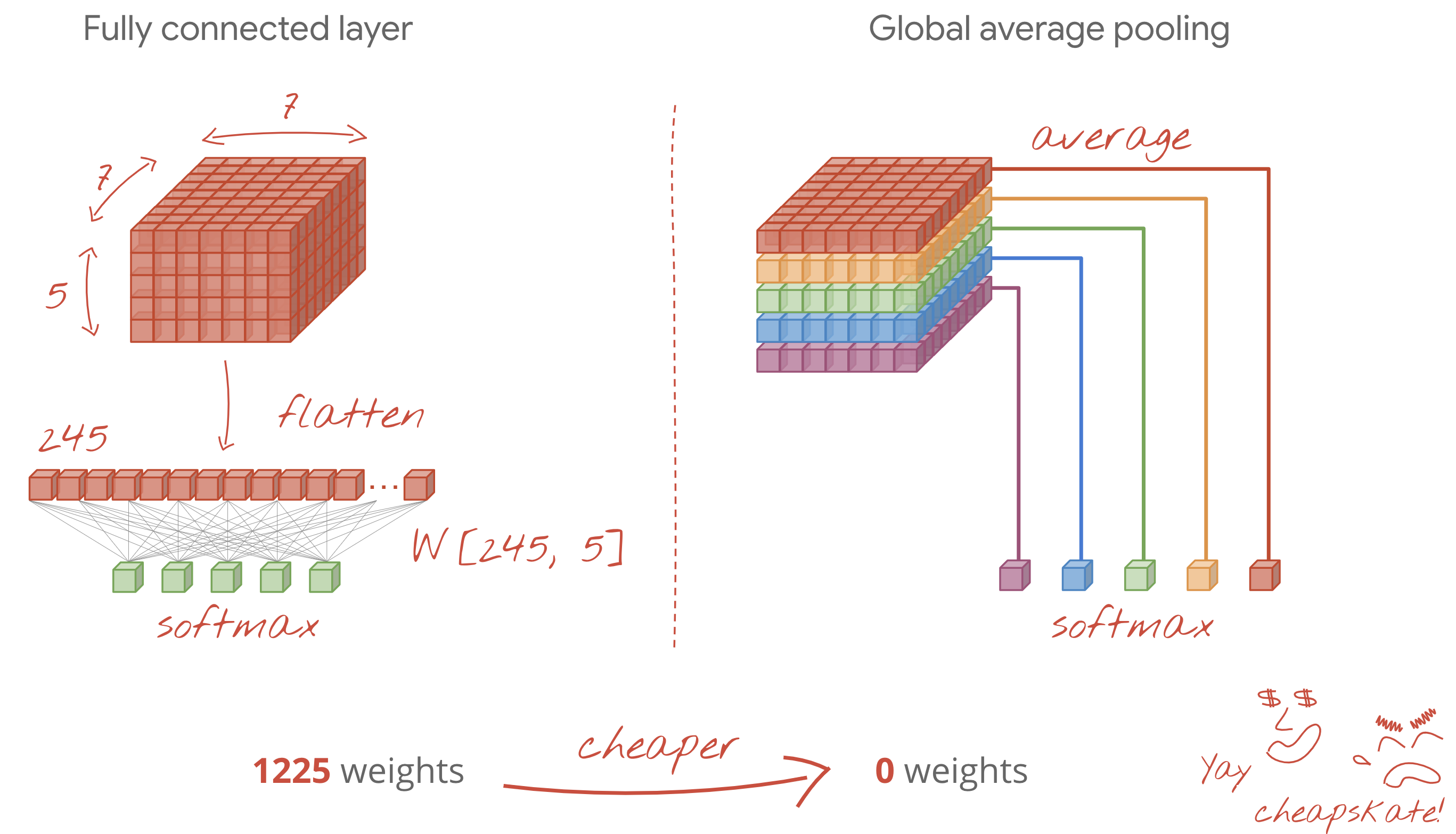
- চূড়ান্ত ডেন্স লেয়ারটি ব্যয়বহুল। এতে সমস্ত কনভোলিউশনাল লেয়ারের সম্মিলিত ওয়েটের চেয়েও বেশি ওয়েট থাকতে পারে। উদাহরণস্বরূপ, ২৪x২৪x১০ ডেটা পয়েন্টের শেষ ডেটা কিউব থেকে বেশ ভালো আউটপুট পেলেও, একটি ১০০ নিউরনের ডেন্স লেয়ারে ২৪x২৪x১০x১০০=৫৭৬,০০০ ওয়েট লাগবে!!! ভেবেচিন্তে কাজ করার চেষ্টা করুন, অথবা গ্লোবাল অ্যাভারেজ পুলিং ব্যবহার করে দেখুন (নিচে দেখুন)।
বৈশ্বিক গড় পুলিং
একটি কনভল্যুশনাল নিউরাল নেটওয়ার্কের শেষে একটি ব্যয়বহুল ডেন্স লেয়ার ব্যবহার করার পরিবর্তে, আপনি আগত ডেটা 'কিউব'-কে আপনার ক্লাসের সংখ্যা অনুযায়ী বিভিন্ন অংশে ভাগ করতে পারেন, তাদের মানগুলোর গড় করতে পারেন এবং এই গড়গুলোকে একটি সফটম্যাক্স অ্যাক্টিভেশন ফাংশনের মাধ্যমে চালনা করতে পারেন। ক্লাসিফিকেশন হেড তৈরির এই পদ্ধতিতে কোনো ওয়েটের প্রয়োজন হয় না। কেরাসে এর সিনট্যাক্স হলো tf.keras.layers.GlobalAveragePooling2D().
সমাধান
এই হলো সমাধান নোটবুক। কোথাও আটকে গেলে এটি ব্যবহার করতে পারেন।
Keras_Flowers_TPU (solution).ipynb
আমরা যা আলোচনা করেছি
- 🤔 কনভোলিউশনাল লেয়ার নিয়ে কাজ করা হয়েছে
- 🤓 ম্যাক্স পুলিং, স্ট্রাইডস, গ্লোবাল অ্যাভারেজ পুলিং নিয়ে পরীক্ষা-নিরীক্ষা করেছি...
- 😀 TPU-তে একটি বাস্তব মডেলের উপর দ্রুত পুনরাবৃত্তি করা হয়েছে।
অনুগ্রহ করে এক মুহূর্ত সময় নিয়ে মনে মনে এই চেকলিস্টটি একবার দেখে নিন।
৭. অভিনন্দন!
আপনি আপনার প্রথম আধুনিক কনভল্যুশনাল নিউরাল নেটওয়ার্ক তৈরি করেছেন এবং টিপিইউ-এর কল্যাণে মাত্র কয়েক মিনিটের মধ্যে এর আর্কিটেকচারে পুনরাবৃত্তি ঘটিয়ে এটিকে ৮০%+ নির্ভুলতায় প্রশিক্ষণ দিয়েছেন। আধুনিক কনভল্যুশনাল আর্কিটেকচার সম্পর্কে জানতে অনুগ্রহ করে পরবর্তী ল্যাবে যান:
- TPU-গতির ডেটা পাইপলাইন: tf.data.Dataset এবং TFRecords
- ট্রান্সফার লার্নিং সহ আপনার প্রথম কেরাস মডেল
- [THIS LAB] Convolutional neural networks, with Keras and TPUs
- Modern convnets, squeezenet, Xception, with Keras and TPUs
TPUs in practice
TPUs and GPUs are available on Cloud AI Platform :
- On Deep Learning VMs
- In AI Platform Notebooks
- In AI Platform Training jobs
Finally, we love feedback. Please tell us if you see something amiss in this lab or if you think it should be improved. Feedback can be provided through GitHub issues [ feedback link ].

|

