
1. Descripción general
Las TPU son muy rápidas, y la transmisión de datos de entrenamiento debe mantenerse a la par con su velocidad de entrenamiento. En este lab, aprenderás a cargar datos de GCS con la API de tf.data.Dataset para alimentar tu TPU.
Este lab es la parte 1 de la serie "Keras en TPU". Puedes realizarlas en el siguiente orden o de forma independiente.
- [ESTE LAB] Canalizaciones de datos con velocidades de TPU: tf.data.Dataset y TFRecords
- Tu primer modelo de Keras con aprendizaje por transferencia
- Redes neuronales convolucionales con Keras y TPUs
- Redes neuronales convolucionales modernas, squeezenet, Xception, con Keras y TPUs

Qué aprenderás
- Usar la API de tf.data.Dataset para cargar datos de entrenamiento
- Usar el formato TFRecord para cargar datos de entrenamiento de forma eficiente desde GCS
Comentarios
Si ves algo incorrecto en este codelab, infórmanos. Los comentarios se pueden proporcionar a través de los problemas de GitHub [vínculo de comentarios].
2. Guía de inicio rápido de Google Colaboratory
En este lab, se usa Google Colaboratory y no se requiere ninguna configuración de tu parte. Colaboratory es una plataforma de notebooks en línea con fines educativos. Ofrece entrenamiento gratuito con CPU, GPU y TPU.

Puedes abrir este notebook de ejemplo y ejecutar algunas celdas para familiarizarte con Colaboratory.
Selecciona un backend de TPU

En el menú de Colab, selecciona Entorno de ejecución > Cambiar tipo de entorno de ejecución y, luego, selecciona TPU. En este lab de código, usarás una potente TPU (unidad de procesamiento tensorial) compatible con el entrenamiento acelerado por hardware. La conexión con el tiempo de ejecución se realizará automáticamente en la primera ejecución, o bien puedes usar el botón "Conectar" en la esquina superior derecha.
Ejecución de notebooks

Ejecuta las celdas una por una haciendo clic en una celda y usando Mayúsculas + INTRO. También puedes ejecutar todo el notebook con Runtime > Run all.
Índice

Todos los notebooks tienen un índice. Puedes abrirlo con la flecha negra que se encuentra a la izquierda.
Celdas ocultas

Algunas celdas solo mostrarán su título. Esta es una función del notebook específica de Colab. Puedes hacer doble clic en ellos para ver el código que contienen, pero, por lo general, no es muy interesante. Por lo general, son funciones de asistencia o visualización. Aún debes ejecutar estas celdas para que se definan las funciones que contienen.
Autenticación

Colab puede acceder a tus buckets privados de Google Cloud Storage si te autenticas con una cuenta autorizada. El fragmento de código anterior activará un proceso de autenticación.
3. [INFO] ¿Qué son las unidades de procesamiento tensorial (TPUs)?
En pocas palabras

El código para entrenar un modelo en una TPU con Keras (y recurrir a la GPU o la CPU si no hay una TPU disponible) es el siguiente:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Hoy usaremos las TPU para compilar y optimizar un clasificador de flores a velocidades interactivas (minutos por ejecución de entrenamiento).
¿Por qué usar TPUs?
Las GPUs modernas se organizan en torno a "núcleos" programables, una arquitectura muy flexible que les permite manejar una variedad de tareas, como la renderización 3D, el aprendizaje profundo, las simulaciones físicas, etcétera. Por otro lado, las TPU combinan un procesador de vectores clásico con una unidad de multiplicación de matrices dedicada y se destacan en cualquier tarea en la que predominan las multiplicaciones de matrices grandes, como las redes neuronales.

Ilustración: Una capa de red neuronal densa como una multiplicación de matrices, con un lote de ocho imágenes procesadas a través de la red neuronal a la vez. Realiza una multiplicación de una línea por una columna para verificar que, de hecho, se realiza una suma ponderada de todos los valores de píxeles de una imagen. Las capas convolucionales también se pueden representar como multiplicaciones de matrices, aunque es un poco más complicado ( explicación aquí, en la sección 1).
El hardware
MXU y VPU
Un núcleo de TPU v2 está compuesto por una unidad de multiplicación de matrices (MXU) que ejecuta multiplicaciones de matrices y una unidad de procesamiento vectorial (VPU) para todas las demás tareas, como activaciones, softmax, etcétera. La VPU controla los cálculos de float32 y int32. Por otro lado, la MXU opera en un formato de punto flotante de precisión mixta de 16 a 32 bits.

Punto flotante de precisión mixta y bfloat16
La MXU calcula las multiplicaciones de matrices con entradas bfloat16 y salidas float32. Las acumulaciones intermedias se realizan con una precisión de float32.
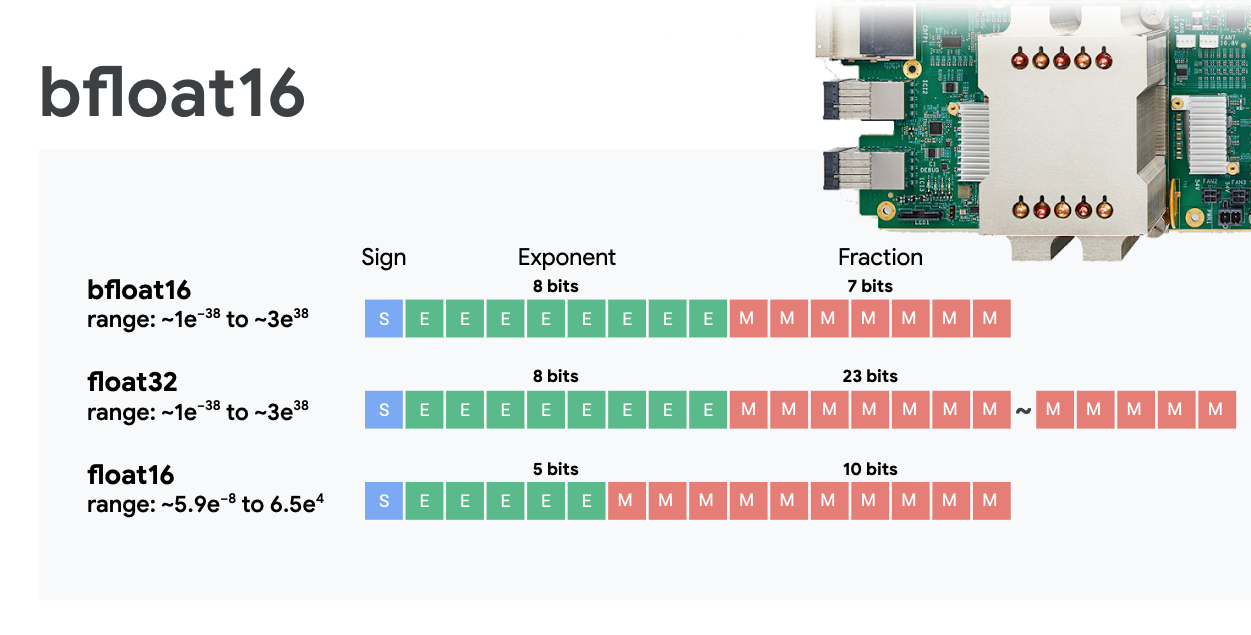
Por lo general, el entrenamiento de redes neuronales es resistente al ruido que introduce una precisión de punto flotante reducida. Hay casos en los que el ruido incluso ayuda al optimizador a converger. La precisión de punto flotante de 16 bits se usó tradicionalmente para acelerar los cálculos, pero los formatos float16 y float32 tienen rangos muy diferentes. Por lo general, reducir la precisión de float32 a float16 genera desbordamientos superiores e inferiores. Existen soluciones, pero, por lo general, se requiere trabajo adicional para que float16 funcione.
Por eso, Google introdujo el formato bfloat16 en las TPU. bfloat16 es un float32 truncado con exactamente los mismos bits y rango de exponente que float32. Esto, sumado al hecho de que las TPU calculan las multiplicaciones de matrices en precisión mixta con entradas de bfloat16, pero salidas de float32, significa que, por lo general, no es necesario realizar cambios en el código para aprovechar las mejoras de rendimiento de la precisión reducida.
Matriz sistólica
La MXU implementa multiplicaciones de matrices en hardware con una arquitectura denominada "array sistólico", en la que los elementos de datos fluyen a través de un array de unidades de procesamiento de hardware. (En medicina, “sistólica” se refiere a las contracciones cardíacas y al flujo sanguíneo; aquí, al flujo de datos).
El elemento básico de una multiplicación de matrices es un producto escalar entre una fila de una matriz y una columna de la otra matriz (consulta la ilustración en la parte superior de esta sección). Para una multiplicación de matrices Y=X*W, un elemento del resultado sería el siguiente:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
En una GPU, se programaría este producto escalar en un "núcleo" de la GPU y, luego, se ejecutaría en tantos "núcleos" como estén disponibles en paralelo para intentar calcular cada valor de la matriz resultante de una sola vez. Si la matriz resultante es de 128 x 128, se requerirían 128 x 128=16 000 "núcleos" disponibles, lo que no suele ser posible. Las GPU más grandes tienen alrededor de 4,000 núcleos. Por otro lado, una TPU usa el mínimo hardware necesario para las unidades de procesamiento en la MXU: solo bfloat16 x bfloat16 => float32 acumuladores de multiplicación, nada más. Son tan pequeñas que una TPU puede implementar 16,000 de ellas en una MXU de 128 x 128 y procesar esta multiplicación de matrices de una sola vez.

Ilustración: El arreglo sistólico de la MXU. Los elementos de procesamiento son acumuladores multiplicadores. Los valores de una matriz se cargan en el array (puntos rojos). Los valores de la otra matriz fluyen a través del array (puntos grises). Las líneas verticales propagan los valores hacia arriba. Las líneas horizontales propagan las sumas parciales. El usuario debe verificar que, a medida que los datos fluyen a través del array, se obtiene el resultado de la multiplicación de matrices en el lado derecho.
Además, mientras se calculan los productos punto en una MXU, las sumas intermedias simplemente fluyen entre las unidades de procesamiento adyacentes. No es necesario almacenarlos ni recuperarlos de la memoria o incluso de un archivo de registro. El resultado final es que la arquitectura de la matriz sistólica de la TPU tiene una ventaja significativa en cuanto a densidad y potencia, así como una ventaja de velocidad no despreciable sobre una GPU, cuando se calculan multiplicaciones de matrices.
Cloud TPU
Cuando solicitas una "Cloud TPU v2" en Google Cloud Platform, obtienes una máquina virtual (VM) que tiene una placa de TPU conectada a PCI. La placa de TPU tiene cuatro chips de TPU de doble núcleo. Cada núcleo de TPU incluye una VPU (unidad de procesamiento vectorial) y una MXU (unidad de multiplicación de matrices) de 128 x 128. Luego, esta "Cloud TPU" suele conectarse a través de la red a la VM que la solicitó. Por lo tanto, la imagen completa se ve de la siguiente manera:

Ilustración: Tu VM con un acelerador "Cloud TPU" conectado a la red. "La Cloud TPU" en sí está compuesta por una VM con una placa de TPU conectada a PCI que tiene cuatro chips de TPU de doble núcleo.
Pods de TPU
En los centros de datos de Google, las TPU están conectadas a una interconexión de computación de alto rendimiento (HPC) que puede hacer que parezcan un acelerador muy grande. Google los llama pods y pueden abarcar hasta 512 núcleos de TPU v2 o 2,048 núcleos de TPU v3.

Ilustración: Un pod de TPU v3. Paneles y racks de TPU conectados a través de interconexión de HPC.
Durante el entrenamiento, los gradientes se intercambian entre los núcleos de TPU con el algoritmo de reducción total ( aquí se ofrece una buena explicación de la reducción total). El modelo que se entrena puede aprovechar el hardware entrenando con tamaños de lote grandes.

Ilustración: Sincronización de gradientes durante el entrenamiento con el algoritmo de reducción total en la red de HPC de malla toroidal bidimensional de la TPU de Google.
El software
Entrenamiento con un tamaño de lote grande
El tamaño de lote ideal para las TPU es de 128 elementos de datos por núcleo de TPU, pero el hardware ya puede mostrar una buena utilización a partir de 8 elementos de datos por núcleo de TPU. Recuerda que una Cloud TPU tiene 8 núcleos.
En este codelab, usaremos la API de Keras. En Keras, el lote que especificas es el tamaño de lote global para toda la TPU. Tus lotes se dividirán automáticamente en 8 y se ejecutarán en los 8 núcleos de la TPU.

Para obtener más sugerencias sobre el rendimiento, consulta la Guía de rendimiento de las TPU. Para tamaños de lote muy grandes, es posible que se necesite un cuidado especial en algunos modelos. Consulta LARSOptimizer para obtener más detalles.
Detrás de escena: XLA
Los programas de TensorFlow definen grafos de procesamiento. La TPU no ejecuta directamente el código de Python, sino el grafo de procesamiento definido por tu programa de TensorFlow. En segundo plano, un compilador llamado XLA (compilador de álgebra lineal acelerada) transforma el grafo de nodos de procesamiento de TensorFlow en código máquina de la TPU. Este compilador también realiza muchas optimizaciones avanzadas en tu código y en el diseño de la memoria. La compilación se realiza automáticamente a medida que se envía trabajo a la TPU. No es necesario que incluyas XLA en tu cadena de compilación de forma explícita.

Ilustración: Para ejecutarse en la TPU, el grafo de procesamiento definido por tu programa de TensorFlow primero se traduce a una representación de XLA (compilador de álgebra lineal acelerada) y, luego, XLA lo compila en código máquina de la TPU.
Usa TPU en Keras
Las TPU se admiten a través de la API de Keras a partir de TensorFlow 2.1. La compatibilidad con Keras funciona en las TPU y los pods de TPU. Este es un ejemplo que funciona en TPU, GPU y CPU:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
En este fragmento de código:
TPUClusterResolver().connect()encuentra la TPU en la red. Funciona sin parámetros en la mayoría de los sistemas de Google Cloud (trabajos de AI Platform, Colaboratory, Kubeflow, VMs de aprendizaje profundo creadas a través de la utilidad "ctpu up"). Estos sistemas saben dónde está su TPU gracias a una variable de entorno TPU_NAME. Si creas una TPU de forma manual, configura la variable de entorno TPU_NAME en la VM desde la que la usas o llama aTPUClusterResolvercon parámetros explícitos:TPUClusterResolver(tp_uname, zone, project)TPUStrategyes la parte que implementa la distribución y el algoritmo de sincronización de gradientes "all-reduce".- La estrategia se aplica a través de un alcance. El modelo debe definirse dentro del método scope() de la estrategia.
- La función
tpu_model.fitespera un objeto tf.data.Dataset como entrada para el entrenamiento en TPU.
Tareas comunes de adaptación de TPU
- Si bien hay muchas formas de cargar datos en un modelo de TensorFlow, para las TPU se requiere el uso de la API de
tf.data.Dataset. - Las TPU son muy rápidas, y la transferencia de datos suele convertirse en el cuello de botella cuando se ejecutan en ellas. En la Guía de rendimiento de TPU, encontrarás herramientas que puedes usar para detectar cuellos de botella de datos y otras sugerencias de rendimiento.
- Los números int8 o int16 se tratan como int32. La TPU no tiene hardware de números enteros que opere con menos de 32 bits.
- No se admiten algunas operaciones de TensorFlow. La lista está aquí. La buena noticia es que esta limitación solo se aplica al código de entrenamiento, es decir, el pase hacia adelante y hacia atrás a través de tu modelo. Aun así, puedes usar todas las operaciones de TensorFlow en tu canalización de entrada de datos, ya que se ejecutará en la CPU.
tf.py_funcno es compatible con las TPU.
4. Cargar datos






Trabajaremos con un conjunto de datos de imágenes de flores. El objetivo es aprender a clasificarlas en 5 tipos de flores. La carga de datos se realiza con la API de tf.data.Dataset. Primero, conozcamos la API.
Práctica
Abre el siguiente notebook, ejecuta las celdas (MAYÚSCULAS + INTRO) y sigue las instrucciones donde veas la etiqueta "WORK REQUIRED".

Fun with tf.data.Dataset (playground).ipynb
Información adicional
Acerca del conjunto de datos "flores"
El conjunto de datos se organiza en 5 carpetas. Cada carpeta contiene flores de un solo tipo. Las carpetas se llaman sunflowers, daisy, dandelion, tulips y roses. Los datos se alojan en un bucket público de Google Cloud Storage. Extracto:
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
¿Por qué tf.data.Dataset?
Keras y TensorFlow aceptan conjuntos de datos en todas sus funciones de entrenamiento y evaluación. Una vez que cargas datos en un Dataset, la API ofrece todas las funcionalidades comunes que son útiles para los datos de entrenamiento de redes neuronales:
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
Puedes encontrar sugerencias de rendimiento y prácticas recomendadas para los conjuntos de datos en este artículo. La documentación de referencia se encuentra aquí.
Conceptos básicos de tf.data.Dataset
Por lo general, los datos se presentan en varios archivos, como imágenes en este caso. Puedes crear un conjunto de datos de nombres de archivos llamando a:
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
Luego, "asignas" una función a cada nombre de archivo que, por lo general, cargará y decodificará el archivo en datos reales en la memoria:
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
Para iterar en un Dataset, haz lo siguiente:
for data in my_dataset:
print(data)
Conjuntos de datos de tuplas
En el aprendizaje supervisado, un conjunto de datos de entrenamiento suele estar compuesto por pares de datos de entrenamiento y respuestas correctas. Para permitir esto, la función de decodificación puede devolver tuplas. Luego, tendrás un conjunto de datos de tuplas, y se devolverán tuplas cuando iteres sobre él. Los valores que se muestran son tensores de TensorFlow listos para que los use tu modelo. Puedes llamar a .numpy() en ellos para ver los valores sin procesar:
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
Conclusión:Cargar imágenes una por una es lento.
A medida que iteres en este conjunto de datos, verás que puedes cargar entre 1 y 2 imágenes por segundo. ¡Es demasiado lento! Los aceleradores de hardware que usaremos para el entrenamiento pueden mantener muchas veces esta tasa. Ve a la siguiente sección para ver cómo lo lograremos.
Solución
Aquí está el notebook de solución. Puedes usarlo si no puedes avanzar.
Fun with tf.data.Dataset (solution).ipynb
Temas abordados
- 🤔 tf.data.Dataset.list_files
- 🤔 tf.data.Dataset.map
- 🤔 Conjuntos de datos de tuplas
- 😀 Iterar a través de conjuntos de datos
Tómate un momento para revisar esta lista de tareas mentalmente.
5. Carga de datos rápida
Los aceleradores de hardware de la unidad de procesamiento tensorial (TPU) que usaremos en este lab son muy rápidos. El desafío suele ser proporcionarles datos con la suficiente rapidez para mantenerlos ocupados. Google Cloud Storage (GCS) puede mantener un rendimiento muy alto, pero, como sucede con todos los sistemas de almacenamiento en la nube, iniciar una conexión genera un costo de ida y vuelta de la red. Por lo tanto, no es ideal tener nuestros datos almacenados como miles de archivos individuales. Los agruparemos en lotes en una cantidad menor de archivos y usaremos la potencia de tf.data.Dataset para leer desde varios archivos en paralelo.
Lectura
El código que carga archivos de imágenes, los cambia de tamaño a un tamaño común y, luego, los almacena en 16 archivos TFRecord se encuentra en el siguiente notebook. Léelo rápidamente. No es necesario ejecutarlo, ya que se proporcionarán datos con el formato TFRecord adecuado para el resto del codelab.
Flower pictures to TFRecords.ipynb
Diseño de datos ideal para un rendimiento óptimo de GCS
El formato de archivo TFRecord
El formato de archivo preferido de TensorFlow para almacenar datos es el formato TFRecord basado en protobuf. Otros formatos de serialización también funcionarían, pero puedes cargar un conjunto de datos desde archivos TFRecord directamente escribiendo lo siguiente:
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
Para obtener un rendimiento óptimo, se recomienda usar el siguiente código más complejo para leer varios archivos TFRecord a la vez. Este código leerá N archivos en paralelo y no tendrá en cuenta el orden de los datos en favor de la velocidad de lectura.
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
Hoja de referencia de TFRecord
En los TFRecords, se pueden almacenar tres tipos de datos: cadenas de bytes (lista de bytes), números enteros de 64 bits y números de punto flotante de 32 bits. Siempre se almacenan como listas, y un solo elemento de datos será una lista de tamaño 1. Puedes usar las siguientes funciones auxiliares para almacenar datos en TFRecords.
cómo escribir cadenas de bytes
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
escribir números enteros
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
Flotantes de escritura
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
Cómo escribir un TFRecord con los asistentes anteriores
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
Para leer datos de TFRecords, primero debes declarar el diseño de los registros que almacenaste. En la declaración, puedes acceder a cualquier campo con nombre como una lista de longitud fija o una lista de longitud variable:
lectura de TFRecords
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
Fragmentos de código útiles:
lectura de elementos de datos individuales
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
leer listas de elementos de tamaño fijo
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
leer una cantidad variable de elementos de datos
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
Un VarLenFeature devuelve un vector disperso, y se requiere un paso adicional después de decodificar el TFRecord:
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
También es posible tener campos opcionales en los registros de TF. Si especificas un valor predeterminado cuando lees un campo, se devolverá el valor predeterminado en lugar de un error si falta el campo.
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
Temas abordados
- 🤔 Cómo fragmentar archivos de datos para un acceso rápido desde GCS
- 😓 cómo escribir TFRecords (¿Ya olvidaste la sintaxis? No hay problema, agrega esta página a tus favoritos como hoja de referencia).
- 🤔 Cómo cargar un Dataset desde TFRecords con TFRecordDataset
Tómate un momento para revisar esta lista de tareas mentalmente.
6. ¡Felicitaciones!
Ahora puedes alimentar una TPU con datos. Continúa con el siguiente lab
- [ESTE LAB] Canalizaciones de datos con velocidades de TPU: tf.data.Dataset y TFRecords
- Tu primer modelo de Keras con aprendizaje por transferencia
- Redes neuronales convolucionales con Keras y TPUs
- Redes neuronales convolucionales modernas, squeezenet, Xception, con Keras y TPUs
TPUs en la práctica
Las TPU y las GPU están disponibles en Cloud AI Platform:
- En las VMs de aprendizaje profundo
- En AI Platform Notebooks
- En los trabajos de AI Platform Training
Por último, nos encanta recibir comentarios. Avísanos si ves algo incorrecto en este lab o si crees que se debería mejorar. Los comentarios se pueden proporcionar a través de los problemas de GitHub [vínculo de comentarios].

|
|

