
1. Descripción general
En este lab, aprenderás a compilar un clasificador de Keras. En lugar de intentar encontrar la combinación perfecta de capas de redes neuronales para reconocer flores, primero usaremos una técnica llamada aprendizaje por transferencia para adaptar un potente modelo previamente entrenado a nuestro conjunto de datos.
Este lab incluye las explicaciones teóricas necesarias sobre las redes neuronales y es un buen punto de partida para los desarrolladores que aprenden sobre el aprendizaje profundo.
Este lab es la parte 2 de la serie "Keras en TPU". Puedes realizarlas en el siguiente orden o de forma independiente.
- Canalizaciones de datos con velocidades de TPU: tf.data.Dataset y TFRecords
- [ESTE LAB] Tu primer modelo de Keras con aprendizaje por transferencia
- Redes neuronales convolucionales con Keras y TPUs
- Redes neuronales convolucionales modernas, squeezenet, Xception, con Keras y TPUs

Qué aprenderás
- Compilar tu propio clasificador de imágenes de Keras con una capa softmax y una pérdida de entropía cruzada
- Para hacer trampa 😈, usa el aprendizaje por transferencia en lugar de crear tus propios modelos.
Comentarios
Si ves algo incorrecto en este codelab, infórmanos. Los comentarios se pueden proporcionar a través de los problemas de GitHub [vínculo de comentarios].
2. Guía de inicio rápido de Google Colaboratory
En este lab, se usa Google Colaboratory y no se requiere ninguna configuración de tu parte. Colaboratory es una plataforma de notebooks en línea con fines educativos. Ofrece entrenamiento gratuito con CPU, GPU y TPU.

Puedes abrir este notebook de ejemplo y ejecutar algunas celdas para familiarizarte con Colaboratory.
Selecciona un backend de TPU

En el menú de Colab, selecciona Entorno de ejecución > Cambiar tipo de entorno de ejecución y, luego, selecciona TPU. En este lab de código, usarás una potente TPU (unidad de procesamiento tensorial) compatible con el entrenamiento acelerado por hardware. La conexión con el tiempo de ejecución se realizará automáticamente en la primera ejecución, o bien puedes usar el botón "Conectar" en la esquina superior derecha.
Ejecución de notebooks

Ejecuta las celdas una por una haciendo clic en una celda y usando Mayúsculas + INTRO. También puedes ejecutar todo el notebook con Runtime > Run all.
Índice

Todos los notebooks tienen un índice. Puedes abrirlo con la flecha negra que se encuentra a la izquierda.
Celdas ocultas

Algunas celdas solo mostrarán su título. Esta es una función del notebook específica de Colab. Puedes hacer doble clic en ellos para ver el código que contienen, pero, por lo general, no es muy interesante. Por lo general, son funciones de asistencia o visualización. Aún debes ejecutar estas celdas para que se definan las funciones que contienen.
Autenticación

Colab puede acceder a tus buckets privados de Google Cloud Storage si te autenticas con una cuenta autorizada. El fragmento de código anterior activará un proceso de autenticación.
3. [INFO] Clasificador de redes neuronales 101
En pocas palabras
Si ya conoces todos los términos en negrita del siguiente párrafo, puedes pasar al siguiente ejercicio. Si recién comienzas a aprender sobre el aprendizaje profundo, bienvenido y sigue leyendo.
Para los modelos creados como una secuencia de capas, Keras ofrece la API secuencial. Por ejemplo, un clasificador de imágenes que usa tres capas densas se puede escribir en Keras de la siguiente manera:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
Red neuronal densa
Esta es la red neuronal más simple para clasificar imágenes. Está compuesta por "neuronas" dispuestas en capas. La primera capa procesa los datos de entrada y envía sus resultados a otras capas. Se llama "densa" porque cada neurona está conectada a todas las neuronas de la capa anterior.

Puedes ingresar una imagen en una red de este tipo aplanando los valores RGB de todos sus píxeles en un vector largo y usándolo como entrada. No es la mejor técnica para el reconocimiento de imágenes, pero la mejoraremos más adelante.
Neuronas, activaciones y ReLU
Una "neurona" calcula una suma ponderada de todas sus entradas, agrega un valor llamado "sesgo" y alimenta el resultado a través de una "función de activación". Al principio, se desconocen los pesos y el sesgo. Se inicializarán de forma aleatoria y se "aprenderán" entrenando la red neuronal con muchos datos conocidos.

La función de activación más popular se llama ReLU, que significa unidad lineal rectificada. Es una función muy simple, como puedes ver en el gráfico anterior.
Activación Softmax
La red anterior termina con una capa de 5 neuronas porque clasificamos las flores en 5 categorías (rosa, tulipán, diente de león, margarita y girasol). Las neuronas de las capas intermedias se activan con la función de activación ReLU clásica. Sin embargo, en la última capa, queremos calcular números entre 0 y 1 que representen la probabilidad de que esta flor sea una rosa, un tulipán, etcétera. Para ello, usaremos una función de activación llamada "softmax".
Para aplicar softmax a un vector, se toma el exponencial de cada elemento y, luego, se normaliza el vector, por lo general, con la norma L1 (suma de valores absolutos) para que los valores sumen 1 y se puedan interpretar como probabilidades.


Pérdida de entropía cruzada
Ahora que nuestra red neuronal produce predicciones a partir de imágenes de entrada, debemos medir qué tan buenas son, es decir, la distancia entre lo que nos dice la red y las respuestas correctas, que a menudo se denominan "etiquetas". Recuerda que tenemos etiquetas correctas para todas las imágenes del conjunto de datos.
Cualquier distancia funcionaría, pero para los problemas de clasificación, la llamada "distancia de entropía cruzada" es la más eficaz. Llamaremos a esta nuestra función de error o "pérdida":
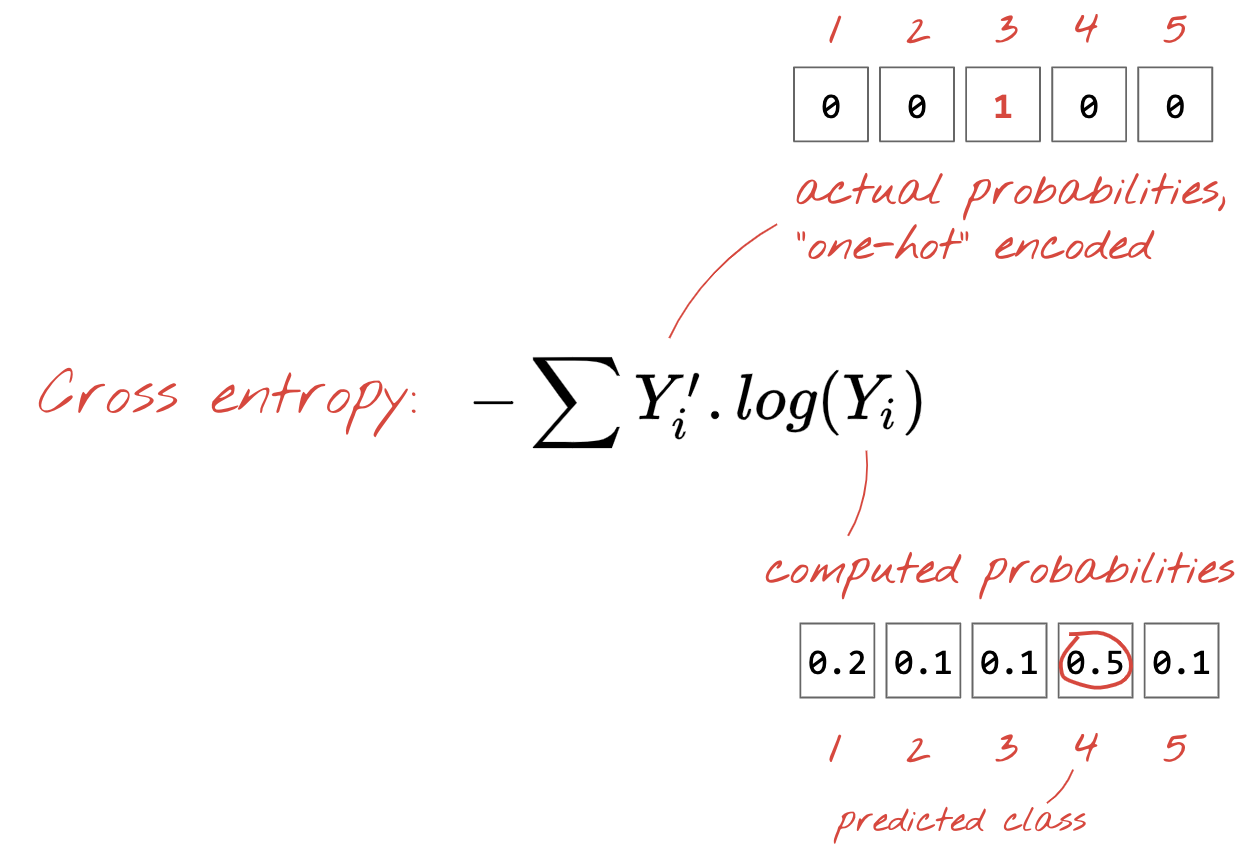
Descenso de gradientes
"Entrenar" la red neuronal en realidad significa usar imágenes y etiquetas de entrenamiento para ajustar los pesos y los sesgos de modo que se minimice la función de pérdida de entropía cruzada. Así es como funciona.
La entropía cruzada es una función de los pesos, las tendencias, los píxeles de la imagen de entrenamiento y su clase conocida.
Si calculamos las derivadas parciales de la entropía cruzada en relación con todos los pesos y todos los sesgos, obtenemos un "gradiente" que se calcula para una imagen, una etiqueta y un valor presente de pesos y sesgos determinados. Recuerda que podemos tener millones de pesos y sesgos, por lo que calcular el gradiente parece una tarea muy laboriosa. Afortunadamente, TensorFlow lo hace por nosotros. La propiedad matemática de un gradiente es que apunta "hacia arriba". Como queremos ir hacia donde la entropía cruzada es baja, vamos en la dirección opuesta. Actualizamos los pesos y las derivaciones en una fracción del gradiente. Luego, repetimos el mismo proceso una y otra vez con los siguientes lotes de imágenes y etiquetas de entrenamiento, en un bucle de entrenamiento. Esperamos que esto converja en un lugar donde la entropía cruzada sea mínima, aunque nada garantiza que este mínimo sea único.

Minilotes y momento
Puedes calcular tu gradiente en una sola imagen de ejemplo y actualizar los pesos y las tendencias de inmediato, pero hacerlo en un lote de, por ejemplo, 128 imágenes proporciona un gradiente que representa mejor las restricciones impuestas por diferentes imágenes de ejemplo y, por lo tanto, es probable que converja hacia la solución más rápido. El tamaño del minilote es un parámetro ajustable.
Esta técnica, a veces denominada "descenso de gradiente estocástico", tiene otro beneficio más pragmático: trabajar con lotes también significa trabajar con matrices más grandes, y estas suelen ser más fáciles de optimizar en las GPU y las TPU.
Sin embargo, la convergencia puede ser un poco caótica y hasta detenerse si el vector de gradiente es todo ceros. ¿Significa que encontramos un mínimo? No en todos los casos. Un componente de gradiente puede ser cero en un mínimo o un máximo. Con un vector de gradiente con millones de elementos, si todos son ceros, la probabilidad de que cada cero corresponda a un mínimo y ninguno a un punto máximo es bastante baja. En un espacio de muchas dimensiones, los puntos silla son bastante comunes y no queremos detenernos en ellos.

Ilustración: Un punto de silla. El gradiente es 0, pero no es un mínimo en todas las direcciones. (Atribución de la imagen: Wikimedia: De Nicoguaro - Trabajo propio, CC BY 3.0)
La solución es agregar algo de impulso al algoritmo de optimización para que pueda superar los puntos de silla sin detenerse.
Glosario
Lote o minilote: El entrenamiento siempre se realiza en lotes de datos y etiquetas de entrenamiento. Esto ayuda a que el algoritmo converja. La dimensión "lote" suele ser la primera dimensión de los tensores de datos. Por ejemplo, un tensor con la forma [100, 192, 192, 3] contiene 100 imágenes de 192 x 192 píxeles con tres valores por píxel (RGB).
Pérdida de entropía cruzada: Es una función de pérdida especial que se usa a menudo en los clasificadores.
Capa densa: Es una capa de neuronas en la que cada neurona está conectada a todas las neuronas de la capa anterior.
Atributos: Las entradas de una red neuronal a veces se denominan "atributos". El arte de determinar qué partes de un conjunto de datos (o combinaciones de partes) se deben ingresar en una red neuronal para obtener buenas predicciones se denomina "ingeniería de funciones".
etiquetas: Otro nombre para "clases" o respuestas correctas en un problema de clasificación supervisada
Tasa de aprendizaje: Es la fracción del gradiente por la que se actualizan los pesos y las tendencias en cada iteración del ciclo de entrenamiento.
logits: Los resultados de una capa de neuronas antes de que se aplique la función de activación se denominan "logits". El término proviene de la "función logística", también conocida como "función sigmoidea", que solía ser la función de activación más popular. "Salidas de neuronas antes de la función logística" se abrevió a "logits".
loss: Es la función de error que compara los resultados de la red neuronal con las respuestas correctas.
Neurona: Calcula la suma ponderada de sus entradas, agrega un sesgo y alimenta el resultado a través de una función de activación.
Codificación one-hot: La clase 3 de 5 se codifica como un vector de 5 elementos, todos ceros, excepto el 3º, que es 1.
relu: Unidad lineal rectificada. Es una función de activación popular para las neuronas.
sigmoid: Otra función de activación que solía ser popular y que sigue siendo útil en casos especiales.
softmax: Es una función de activación especial que actúa sobre un vector, aumenta la diferencia entre el componente más grande y todos los demás, y también normaliza el vector para que tenga una suma de 1 y se pueda interpretar como un vector de probabilidades. Se usa como el último paso en los clasificadores.
tensor: Un "tensor" es como una matriz, pero con una cantidad arbitraria de dimensiones. Un tensor unidimensional es un vector. Un tensor de 2 dimensiones es una matriz. Luego, puedes tener tensores con 3, 4, 5 o más dimensiones.
4. Aprendizaje por transferencia
Para un problema de clasificación de imágenes, es probable que las capas densas no sean suficientes. Tenemos que aprender sobre las capas convolucionales y las muchas formas en que puedes organizarlas.
Pero también podemos tomar un atajo. Hay redes neuronales convolucionales completamente entrenadas disponibles para descargar. Es posible cortar su última capa, el encabezado de clasificación softmax, y reemplazarlo por el tuyo. Todos los pesos y sesgos entrenados permanecen como están, solo vuelves a entrenar la capa softmax que agregas. Esta técnica se denomina aprendizaje por transferencia y, sorprendentemente, funciona siempre y cuando el conjunto de datos con el que se preentrena la red neuronal sea "lo suficientemente similar" al tuyo.
Práctico
Abre el siguiente notebook, ejecuta las celdas (MAYÚSCULAS + INTRO) y sigue las instrucciones donde veas la etiqueta "WORK REQUIRED".

Keras Flowers transfer learning (playground).ipynb
Información adicional
Con el aprendizaje por transferencia, te beneficias de las arquitecturas avanzadas de redes neuronales convolucionales desarrolladas por los mejores investigadores y del entrenamiento previo en un enorme conjunto de datos de imágenes. En nuestro caso, realizaremos una transferencia del aprendizaje a partir de una red entrenada en ImageNet, una base de datos de imágenes que contiene muchas plantas y escenas al aire libre, lo que es lo suficientemente cercano a las flores.

Ilustración: Se usa una red neuronal convolucional compleja, ya entrenada, como una caja negra, y se vuelve a entrenar solo el encabezado de clasificación. Esto es aprendizaje por transferencia. Más adelante, veremos cómo funcionan estos complicados arreglos de capas convolucionales. Por ahora, es problema de otra persona.
Aprendizaje por transferencia en Keras
En Keras, puedes crear una instancia de un modelo previamente entrenado desde la colección tf.keras.applications.*. Por ejemplo, MobileNet V2 es una muy buena arquitectura convolucional que mantiene un tamaño razonable. Si seleccionas include_top=False, obtendrás el modelo entrenado previamente sin su capa softmax final para que puedas agregar la tuya:
pretrained_model = tf.keras.applications.MobileNetV2(input_shape=[*IMAGE_SIZE, 3], include_top=False)
pretrained_model.trainable = False
model = tf.keras.Sequential([
pretrained_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(5, activation='softmax')
])
También observa el parámetro de configuración pretrained_model.trainable = False. Inmoviliza los pesos y las tendencias del modelo previamente entrenado para que solo entrenes tu capa softmax. Por lo general, esto implica relativamente pocos pesos y se puede hacer rápidamente sin necesidad de un conjunto de datos muy grande. Sin embargo, si tienes muchos datos, el aprendizaje por transferencia puede funcionar aún mejor con pretrained_model.trainable = True. Luego, los pesos previamente entrenados proporcionan excelentes valores iniciales y el entrenamiento los puede ajustar para que se adapten mejor a tu problema.
Por último, observa la capa Flatten() que se insertó antes de la capa softmax densa. Las capas densas funcionan con vectores de datos planos, pero no sabemos si eso es lo que devuelve el modelo previamente entrenado. Por eso, debemos aplanar la curva. En el próximo capítulo, a medida que nos adentremos en las arquitecturas convolucionales, explicaremos el formato de datos que devuelven las capas convolucionales.
Con este enfoque, deberías alcanzar una precisión cercana al 75%.
Solución
Aquí está el notebook de solución. Puedes usarlo si no puedes avanzar.
Keras Flowers transfer learning (solution).ipynb
Temas abordados
- 🤔 Cómo escribir un clasificador en Keras
- 🤓 configurado con una última capa de softmax y pérdida de entropía cruzada
- 😈 Aprendizaje por transferencia
- 🤔 Entrena tu primer modelo
- 🧐 Seguimiento de la pérdida y la exactitud durante el entrenamiento
Tómate un momento para revisar esta lista de tareas mentalmente.
5. ¡Felicitaciones!
Ahora puedes compilar un modelo de Keras. Continúa con el siguiente lab para aprender a ensamblar capas convolucionales.
- Canalizaciones de datos con velocidades de TPU: tf.data.Dataset y TFRecords
- [ESTE LAB] Tu primer modelo de Keras con aprendizaje por transferencia
- Redes neuronales convolucionales con Keras y TPUs
- Redes neuronales convolucionales modernas, squeezenet, Xception, con Keras y TPUs
TPUs en la práctica
Las TPU y las GPU están disponibles en Cloud AI Platform:
- En las VMs de aprendizaje profundo
- En AI Platform Notebooks
- En los trabajos de AI Platform Training
Por último, nos encanta recibir comentarios. Avísanos si ves algo incorrecto en este lab o si crees que se debería mejorar. Los comentarios se pueden proporcionar a través de los problemas de GitHub [vínculo de comentarios].

|

