
1. Introduction

Dernière mise à jour : 15/07/2022
Observabilité de l'application
Observabilité et OpenTelemetry
L'observabilité est un terme utilisé pour décrire un attribut d'un système. Un système avec observabilité permet aux équipes de déboguer activement leur système. Dans ce contexte, les trois piliers de l'observabilité (journaux, métriques et traces) sont l'instrumentation fondamentale permettant au système d'acquérir l'observabilité.
OpenTelemetry est un ensemble de spécifications, de bibliothèques et d'agents qui accélèrent l'instrumentation et l'exportation des données de télémétrie (journaux, métriques et traces) requises par l'observabilité. OpenTelemetry est une norme ouverte et un projet communautaire sous CNCF. En utilisant les bibliothèques fournies par le projet et son écosystème, les développeurs peuvent instrumenter leurs applications de manière neutre vis-à-vis du fournisseur et sur plusieurs architectures.
En plus des trois piliers de l'observabilité, le profilage continu est un autre élément clé de l'observabilité et élargit la base d'utilisateurs dans le secteur. Cloud Profiler est l'un des outils d'origine et fournit une interface simple pour examiner en détail les métriques de performances dans les piles d'appels d'application.
Cet atelier de programmation est la première partie d'une série. Il explique comment instrumenter les traces distribuées dans les microservices avec OpenTelemetry et Cloud Trace. La partie 2 abordera le profilage continu avec Cloud Profiler.
Trace distribuée
Parmi les journaux, les métriques et les traces, la trace est la télémétrie qui indique la latence d'une partie spécifique du processus dans le système. Surtout à l'ère des microservices, le traçage distribué est un outil puissant pour identifier les goulots d'étranglement de latence dans l'ensemble du système distribué.
Lorsque vous analysez des traces distribuées, la visualisation des données de trace est essentielle pour comprendre les latences globales du système en un coup d'œil. Dans la trace distribuée, nous gérons un ensemble d'appels pour traiter une seule requête au point d'entrée du système sous la forme d'une trace contenant plusieurs spans.
Une portée représente une unité de travail individuelle effectuée dans un système distribué, en enregistrant les heures de début et de fin. Les spans ont souvent des relations hiérarchiques entre eux. Dans l'image ci-dessous, tous les spans plus petits sont des spans enfants d'un grand span "/messages" et sont assemblés en une trace qui montre le chemin de travail dans un système.

Google Cloud Trace est l'une des options de backend de trace distribuée. Il est bien intégré aux autres produits de Google Cloud.
Objectifs de l'atelier
Dans cet atelier de programmation, vous allez instrumenter des informations de trace dans les services appelés "application Shakespeare " (ou Shakesapp) qui s'exécutent sur un cluster Google Kubernetes Engine. L'architecture de Shakesapp est décrite ci-dessous :

- Loadgen envoie une chaîne de requête au client en HTTP.
- Les clients transmettent la requête du générateur de charge au serveur dans gRPC.
- Le serveur accepte la requête du client, récupère toutes les œuvres de Shakespeare au format texte à partir de Google Cloud Storage, recherche les lignes contenant la requête et renvoie au client le numéro de la ligne correspondante.
Vous instrumenterez les informations de trace dans la requête. Après cela, vous intégrerez un agent de profileur dans le serveur et examinerez le goulot d'étranglement.
Points abordés
- Premiers pas avec les bibliothèques de trace OpenTelemetry dans un projet Go
- Créer un délai avec la bibliothèque
- Propager les contextes de portée sur le réseau entre les composants de l'application
- Envoyer des données de trace à Cloud Trace
- Analyser la trace sur Cloud Trace
Cet atelier de programmation explique comment instrumenter vos microservices. Pour faciliter la compréhension, cet exemple ne contient que trois composants (générateur de charge, client et serveur). Toutefois, vous pouvez appliquer le même processus expliqué dans cet atelier de programmation à des systèmes plus complexes et plus volumineux.
Prérequis
- Connaissances de base de Go
- Connaissances de base de Kubernetes
2. Préparation
Configuration de l'environnement au rythme de chacun
Si vous ne possédez pas encore de compte Google (Gmail ou Google Apps), vous devez en créer un. Connectez-vous à la console Google Cloud Platform (console.cloud.google.com) et créez un projet.
Si vous avez déjà un projet, cliquez sur le menu déroulant de sélection du projet dans l'angle supérieur gauche de la console :

Cliquez ensuite sur le bouton "NEW PROJECT" (NOUVEAU PROJET) dans la boîte de dialogue qui s'affiche pour créer un projet :

Si vous n'avez pas encore de projet, une boîte de dialogue semblable à celle-ci apparaîtra pour vous permettre d'en créer un :
La boîte de dialogue de création de projet suivante vous permet de saisir les détails de votre nouveau projet :

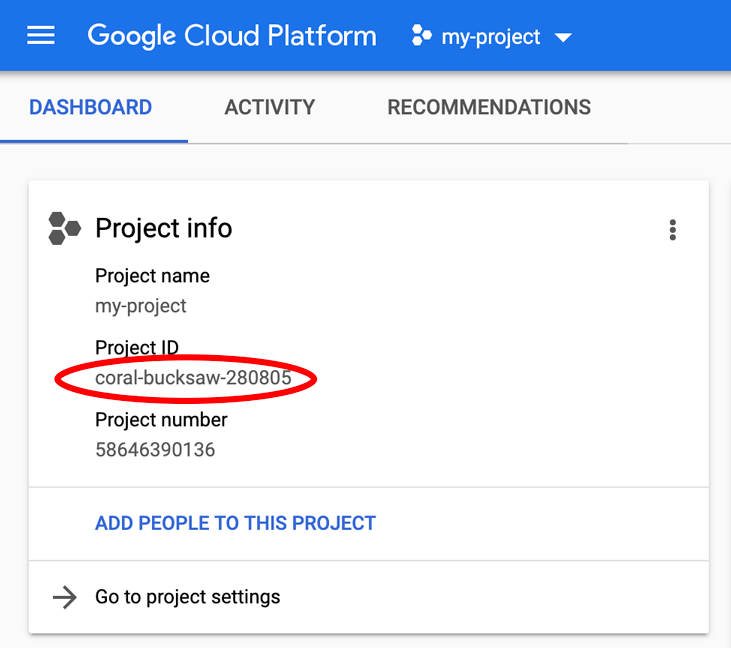
Notez l'ID du projet. Il s'agit d'un nom unique pour tous les projets Google Cloud, ce qui implique que le nom ci-dessus n'est plus disponible pour vous… Désolé ! Il sera désigné par le nom PROJECT_ID tout au long de cet atelier de programmation.
Ensuite, si ce n'est pas déjà fait, vous devez activer la facturation dans la console Développeurs afin de pouvoir utiliser les ressources Google Cloud, puis activer l'API Cloud Trace.

Suivre cet atelier de programmation ne devrait pas vous coûter plus d'un euro. Cependant, cela peut s'avérer plus coûteux si vous décidez d'utiliser davantage de ressources ou si vous n'interrompez pas les ressources (voir la section "Effectuer un nettoyage" à la fin du présent document). Les tarifs de Google Cloud Trace, Google Kubernetes Engine et Google Artifact Registry sont indiqués dans la documentation officielle.
- Tarifs de la suite Google Cloud Operations | Suite Operations
- Tarifs | Documentation Kubernetes Engine
- Tarifs d'Artifact Registry | Documentation Artifact Registry
Les nouveaux utilisateurs de Google Cloud Platform peuvent bénéficier d'un essai sans frais avec 300$de crédits afin de suivre sans frais le présent atelier.
Configuration de Google Cloud Shell
Bien que Google Cloud et Google Cloud Trace puissent être utilisés à distance depuis votre ordinateur portable, nous allons utiliser Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Cette machine virtuelle basée sur Debian contient tous les outils de développement dont vous aurez besoin. Elle intègre un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Cela signifie que tout ce dont vous avez besoin pour cet atelier de programmation est un navigateur (oui, tout fonctionne sur un Chromebook).
Pour activer Cloud Shell à partir de la console Cloud, cliquez simplement sur Activer Cloud Shell  (le provisionnement de l'environnement et la connexion ne devraient prendre que quelques minutes).
(le provisionnement de l'environnement et la connexion ne devraient prendre que quelques minutes).


Une fois connecté à Cloud Shell, vous êtes normalement déjà authentifié et le projet PROJECT_ID est sélectionné :
gcloud auth list
Résultat de la commande
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Résultat de la commande
[core] project = <PROJECT_ID>
Si, pour une raison quelconque, le projet n'est pas défini, exécutez simplement la commande suivante :
gcloud config set project <PROJECT_ID>
Vous recherchez votre PROJECT_ID ? Vérifiez l'ID que vous avez utilisé pendant les étapes de configuration ou recherchez-le dans le tableau de bord Cloud Console :
Par défaut, Cloud Shell définit certaines variables d'environnement qui pourront s'avérer utiles pour exécuter certaines commandes dans le futur.
echo $GOOGLE_CLOUD_PROJECT
Résultat de la commande
<PROJECT_ID>
Pour finir, définissez la configuration du projet et de la zone par défaut :
gcloud config set compute/zone us-central1-f
Vous pouvez choisir parmi différentes zones. Pour en savoir plus, consultez la page Régions et zones.
Configurer le langage Go
Dans cet atelier de programmation, nous utilisons Go pour tout le code source. Exécutez la commande suivante dans Cloud Shell et vérifiez si la version de Go est 1.17 ou ultérieure.
go version
Résultat de la commande
go version go1.18.3 linux/amd64
Configurer un cluster Google Kubernetes
Dans cet atelier de programmation, vous allez exécuter un cluster de microservices sur Google Kubernetes Engine (GKE). Voici le processus de cet atelier de programmation :
- Télécharger le projet de référence dans Cloud Shell
- Créer des microservices dans des conteneurs
- Importer des conteneurs dans Google Artifact Registry (GAR)
- Déployer des conteneurs sur GKE
- Modifier le code source des services pour l'instrumentation de trace
- Passez à l'étape 2.
Activer Kubernetes Engine
Nous allons d'abord configurer un cluster Kubernetes sur lequel Shakesapp s'exécute sur GKE. Nous devons donc activer GKE. Accédez au menu "Kubernetes Engine", puis cliquez sur le bouton "ACTIVER".
Vous êtes maintenant prêt à créer un cluster Kubernetes.
Créer un cluster Kubernetes
Dans Cloud Shell, exécutez la commande suivante pour créer un cluster Kubernetes. Veuillez confirmer que la valeur de la zone se trouve dans la région que vous utiliserez pour créer le dépôt Artifact Registry. Modifiez la valeur de la zone us-central1-f si la région de votre dépôt ne couvre pas la zone.
gcloud container clusters create otel-trace-codelab2 \ --zone us-central1-f \ --release-channel rapid \ --preemptible \ --enable-autoscaling \ --max-nodes 8 \ --no-enable-ip-alias \ --scopes cloud-platform
Résultat de la commande
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s). Creating cluster otel-trace-codelab2 in us-central1-f... Cluster is being health-checked (master is healthy)...done. Created [https://container.googleapis.com/v1/projects/development-215403/zones/us-central1-f/clusters/otel-trace-codelab2]. To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/us-central1-f/otel-trace-codelab2?project=development-215403 kubeconfig entry generated for otel-trace-codelab2. NAME: otel-trace-codelab2 LOCATION: us-central1-f MASTER_VERSION: 1.23.6-gke.1501 MASTER_IP: 104.154.76.89 MACHINE_TYPE: e2-medium NODE_VERSION: 1.23.6-gke.1501 NUM_NODES: 3 STATUS: RUNNING
Configurer Artifact Registry et Skaffold
Nous disposons maintenant d'un cluster Kubernetes prêt pour le déploiement. Nous allons ensuite préparer un registre de conteneurs pour transférer et déployer des conteneurs. Pour ces étapes, nous devons configurer un registre d'artefacts (GAR) et skaffold pour l'utiliser.
Configurer Artifact Registry
Accédez au menu "Artifact Registry" et appuyez sur le bouton "ENABLE" (ACTIVER).

Au bout de quelques instants, le navigateur de dépôt de GAR s'affiche. Cliquez sur le bouton "CRÉER UN DÉPÔT", puis saisissez le nom du dépôt.

Dans cet atelier de programmation, je nomme le nouveau dépôt trace-codelab. Le format de l'artefact est "Docker" et le type d'emplacement est "Région". Choisissez la région proche de celle que vous avez définie pour la zone Google Compute Engine par défaut. Par exemple, l'exemple ci-dessus a choisi "us-central1-f", nous choisissons donc "us-central1 (Iowa)". Cliquez ensuite sur le bouton "CRÉER".
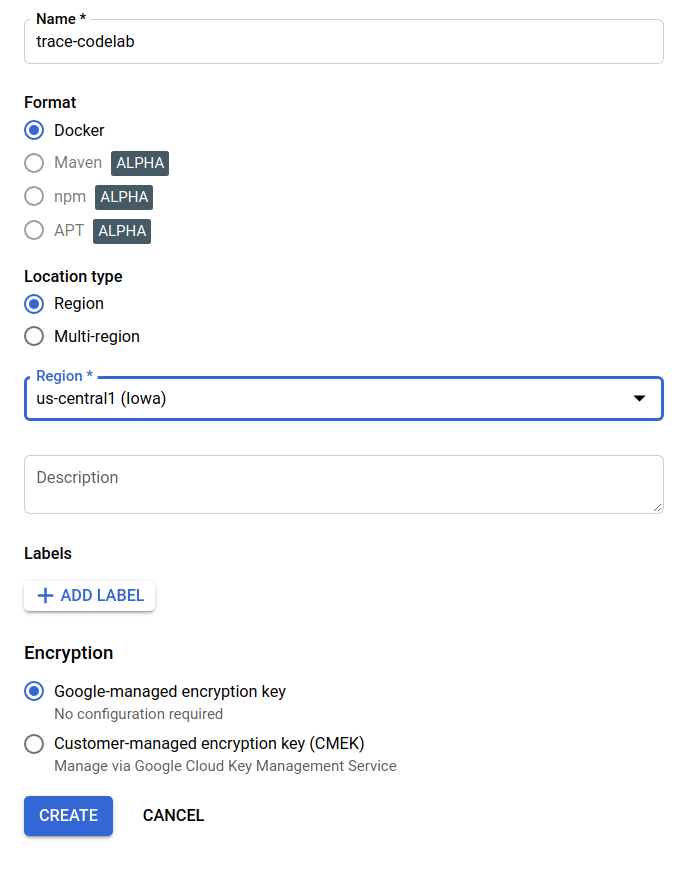
Vous voyez maintenant "trace-codelab" dans l'explorateur de dépôt.

Nous reviendrons ici plus tard pour vérifier le chemin d'accès au registre.
Configuration de Skaffold
Skaffold est un outil pratique lorsque vous créez des microservices qui s'exécutent sur Kubernetes. Il gère le workflow de création, de transfert et de déploiement des conteneurs d'applications avec un petit ensemble de commandes. Par défaut, Skaffold utilise Docker Registry comme registre de conteneurs. Vous devez donc configurer Skaffold pour qu'il reconnaisse GAR lors du transfert de conteneurs.
Ouvrez à nouveau Cloud Shell et vérifiez si Skaffold est installé. (Cloud Shell installe Skaffold dans l'environnement par défaut.) Exécutez la commande suivante pour afficher la version de Skaffold.
skaffold version
Résultat de la commande
v1.38.0
Vous pouvez maintenant enregistrer le dépôt par défaut que Skaffold doit utiliser. Pour obtenir le chemin d'accès au registre, accédez au tableau de bord Artifact Registry et cliquez sur le nom du dépôt que vous venez de configurer à l'étape précédente.
Des breadcrumbs s'affichent en haut de la page. Cliquez sur l'icône  pour copier le chemin d'accès au registre dans le presse-papiers.
pour copier le chemin d'accès au registre dans le presse-papiers.

Lorsque vous cliquez sur le bouton "Copier", la boîte de dialogue s'affiche en bas du navigateur avec un message semblable à celui-ci :
"us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab" a été copié
Revenez à Cloud Shell. Exécutez la commande skaffold config set default-repo avec la valeur que vous venez de copier depuis le tableau de bord.
skaffold config set default-repo us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab
Résultat de la commande
set value default-repo to us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab for context gke_stackdriver-sandbox-3438851889_us-central1-b_stackdriver-sandbox
Vous devez également configurer le registre pour la configuration Docker. Exécutez la commande suivante :
gcloud auth configure-docker us-central1-docker.pkg.dev --quiet
Résultat de la commande
{
"credHelpers": {
"gcr.io": "gcloud",
"us.gcr.io": "gcloud",
"eu.gcr.io": "gcloud",
"asia.gcr.io": "gcloud",
"staging-k8s.gcr.io": "gcloud",
"marketplace.gcr.io": "gcloud",
"us-central1-docker.pkg.dev": "gcloud"
}
}
Adding credentials for: us-central1-docker.pkg.dev
Vous êtes maintenant prêt à passer à l'étape suivante pour configurer un conteneur Kubernetes sur GKE.
Résumé
Dans cette étape, vous allez configurer votre environnement d'atelier de programmation :
- Configurer Cloud Shell
- Création d'un dépôt Artifact Registry pour le registre de conteneurs
- Configurer Skaffold pour utiliser le registre de conteneurs
- Création d'un cluster Kubernetes dans lequel s'exécutent les microservices de l'atelier de programmation
Étape suivante
Dans l'étape suivante, vous allez créer, transférer et déployer vos microservices sur le cluster.
3. Créer, transférer et déployer les microservices
Télécharger le matériel de l'atelier de programmation
À l'étape précédente, nous avons configuré tous les prérequis pour cet atelier de programmation. Vous êtes maintenant prêt à exécuter des microservices entiers par-dessus. Le contenu de l'atelier de programmation est hébergé sur GitHub. Téléchargez-le dans l'environnement Cloud Shell à l'aide de la commande git suivante.
cd ~ git clone https://github.com/ymotongpoo/opentelemetry-trace-codelab-go.git cd opentelemetry-trace-codelab-go
La structure de répertoire du projet est la suivante :
.
├── README.md
├── step0
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step1
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step2
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step3
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step4
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step5
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
└── step6
├── manifests
├── proto
├── skaffold.yaml
└── src
- manifests : fichiers manifestes Kubernetes
- proto : définition proto pour la communication entre le client et le serveur
- src : répertoires du code source de chaque service
- skaffold.yaml : fichier de configuration pour Skaffold
Dans cet atelier de programmation, vous allez mettre à jour le code source situé dans le dossier step0. Vous pouvez également vous référer au code source dans les dossiers step[1-6] pour obtenir les réponses aux étapes suivantes. (La partie 1 couvre les étapes 0 à 4, et la partie 2 couvre les étapes 5 et 6.)
Exécuter la commande skaffold
Vous êtes enfin prêt à créer, transférer et déployer l'intégralité du contenu sur le cluster Kubernetes que vous venez de créer. Cela semble contenir plusieurs étapes, mais en réalité, Skaffold fait tout pour vous. Essayons avec la commande suivante :
cd step0 skaffold dev
Dès que vous exécutez la commande, vous voyez le résultat du journal docker build et pouvez confirmer qu'ils ont bien été envoyés au registre.
Résultat de la commande
... ---> Running in c39b3ea8692b ---> 90932a583ab6 Successfully built 90932a583ab6 Successfully tagged us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step1 The push refers to repository [us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice] cc8f5a05df4a: Preparing 5bf719419ee2: Preparing 2901929ad341: Preparing 88d9943798ba: Preparing b0fdf826a39a: Preparing 3c9c1e0b1647: Preparing f3427ce9393d: Preparing 14a1ca976738: Preparing f3427ce9393d: Waiting 14a1ca976738: Waiting 3c9c1e0b1647: Waiting b0fdf826a39a: Layer already exists 88d9943798ba: Layer already exists f3427ce9393d: Layer already exists 3c9c1e0b1647: Layer already exists 14a1ca976738: Layer already exists 2901929ad341: Pushed 5bf719419ee2: Pushed cc8f5a05df4a: Pushed step1: digest: sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe size: 2001
Une fois tous les conteneurs de service transférés, les déploiements Kubernetes démarrent automatiquement.
Résultat de la commande
sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 size: 1997 Tags used in deployment: - serverservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step4@sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe - clientservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/clientservice:step4@sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 - loadgen -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/loadgen:step4@sha256:eea2e5bc8463ecf886f958a86906cab896e9e2e380a0eb143deaeaca40f7888a Starting deploy... - deployment.apps/clientservice created - service/clientservice created - deployment.apps/loadgen created - deployment.apps/serverservice created - service/serverservice created
Une fois le déploiement effectué, les journaux d'application réels émis sur stdout s'affichent dans chaque conteneur, comme suit :
Résultat de la commande
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:16 {"match_count":3040}
[loadgen] 2022/07/14 06:33:16 query 'love': matched 3040
[client] 2022/07/14 06:33:19 {"match_count":463}
[loadgen] 2022/07/14 06:33:19 query 'tear': matched 463
[loadgen] 2022/07/14 06:33:20 query 'world': matched 728
[client] 2022/07/14 06:33:20 {"match_count":728}
[client] 2022/07/14 06:33:22 {"match_count":463}
[loadgen] 2022/07/14 06:33:22 query 'tear': matched 463
Notez qu'à ce stade, vous souhaitez voir tous les messages du serveur. Vous êtes enfin prêt à instrumenter votre application avec OpenTelemetry pour le traçage distribué des services.
Avant de commencer à instrumenter le service, veuillez arrêter votre cluster avec Ctrl+C.
Résultat de la commande
...
[client] 2022/07/14 06:34:57 {"match_count":1}
[loadgen] 2022/07/14 06:34:57 query 'what's past is prologue': matched 1
^CCleaning up...
- W0714 06:34:58.464305 28078 gcp.go:120] WARNING: the gcp auth plugin is deprecated in v1.22+, unavailable in v1.25+; use gcloud instead.
- To learn more, consult https://cloud.google.com/blog/products/containers-kubernetes/kubectl-auth-changes-in-gke
- deployment.apps "clientservice" deleted
- service "clientservice" deleted
- deployment.apps "loadgen" deleted
- deployment.apps "serverservice" deleted
- service "serverservice" deleted
Résumé
Dans cette étape, vous avez préparé le contenu de l'atelier de programmation dans votre environnement et vérifié que Skaffold s'exécute comme prévu.
Étape suivante
À l'étape suivante, vous allez modifier le code source du service loadgen pour instrumenter les informations de trace.
4. Instrumentation pour HTTP
Concept d'instrumentation et de propagation des traces
Avant de modifier le code source, je vais vous expliquer brièvement le fonctionnement des traces distribuées à l'aide d'un diagramme simple.

Dans cet exemple, nous instrumentons le code pour exporter les informations de trace et de span vers Cloud Trace, et pour propager le contexte de trace dans la requête du service loadgen au service de serveur.
Les applications doivent envoyer des métadonnées de trace telles que l'ID de trace et l'ID de span pour que Cloud Trace puisse regrouper tous les spans ayant le même ID de trace en une seule trace. L'application doit également propager les contextes de trace (combinaison de l'ID de trace et de l'ID de portée de la portée parente) lors de la demande de services en aval, afin qu'ils puissent savoir quel contexte de trace ils gèrent.
OpenTelemetry vous aide à :
- pour générer un ID de trace et un ID de portée uniques.
- Exporter l'ID de trace et l'ID de span vers le backend
- pour propager les contextes de trace à d'autres services.
- pour intégrer des métadonnées supplémentaires qui aident à analyser les traces.
Composants dans OpenTelemetry Trace
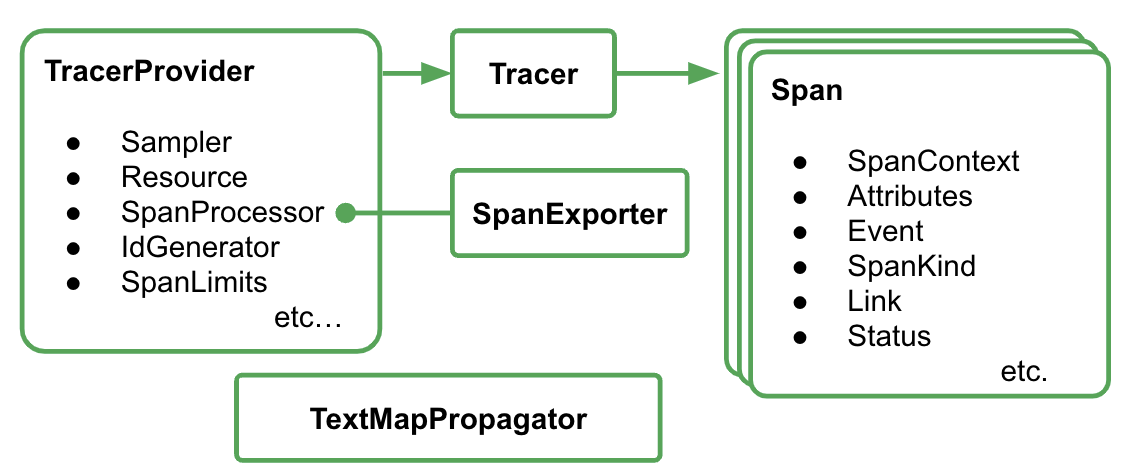
Pour instrumenter les traces d'application avec OpenTelemetry, procédez comme suit :
- Créer un exportateur
- Créez une liaison TracerProvider qui lie l'exportateur dans 1 et définissez-la comme globale.
- Définissez TextMapPropagaror pour définir la méthode de propagation.
- Obtenir le traceur à partir du TracerProvider
- Générer une portée à partir du traceur
Pour le moment, vous n'avez pas besoin de comprendre les propriétés détaillées de chaque composant. Toutefois, voici les points les plus importants à retenir :
- L'exportateur est ici enfichable à TracerProvider.
- TracerProvider contient toute la configuration concernant l'échantillonnage et l'exportation des traces.
- Toutes les traces sont regroupées dans l'objet Tracer.
Maintenant que vous avez compris cela, passons au codage proprement dit.
Instrumenter la première étendue
Service de générateur de charge d'instrument
Ouvrez l'éditeur Cloud Shell en cliquant sur le bouton  en haut à droite de Cloud Shell. Ouvrez
en haut à droite de Cloud Shell. Ouvrez step0/src/loadgen/main.go à partir de l'explorateur dans le volet de gauche, puis recherchez la fonction principale.
step0/src/loadgen/main.go
func main() {
...
for range t.C {
log.Printf("simulating client requests, round %d", i)
if err := run(numWorkers, numConcurrency); err != nil {
log.Printf("aborted round with error: %v", err)
}
log.Printf("simulated %d requests", numWorkers)
if numRounds != 0 && i > numRounds {
break
}
i++
}
}
Dans la fonction principale, vous voyez la boucle qui appelle la fonction run. Dans l'implémentation actuelle, la section comporte deux lignes de journal qui enregistrent le début et la fin de l'appel de fonction. Instrumentons maintenant les informations de Span pour suivre la latence de l'appel de fonction.
Tout d'abord, comme indiqué dans la section précédente, configurons OpenTelemetry. Ajoutez les packages OpenTelemetry comme suit :
step0/src/loadgen/main.go
import (
"context" // step1. add packages
"encoding/json"
"fmt"
"io"
"log"
"math/rand"
"net/http"
"net/url"
"time"
// step1. add packages
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/attribute"
stdout "go.opentelemetry.io/otel/exporters/stdout/stdouttrace"
"go.opentelemetry.io/otel/propagation"
sdktrace "go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.10.0"
"go.opentelemetry.io/otel/trace"
// step1. end add packages
)
Pour plus de lisibilité, nous créons une fonction de configuration appelée initTracer et l'appelons dans la fonction main.
step0/src/loadgen/main.go
// step1. add OpenTelemetry initialization function
func initTracer() (*sdktrace.TracerProvider, error) {
// create a stdout exporter to show collected spans out to stdout.
exporter, err := stdout.New(stdout.WithPrettyPrint())
if err != nil {
return nil, err
}
// for the demonstration, we use AlwaysSmaple sampler to take all spans.
// do not use this option in production.
tp := sdktrace.NewTracerProvider(
sdktrace.WithSampler(sdktrace.AlwaysSample()),
sdktrace.WithBatcher(exporter),
)
otel.SetTracerProvider(tp)
otel.SetTextMapPropagator(propagation.TraceContext{})
return tp, nil
}
Vous constaterez que la procédure de configuration d'OpenTelemetry est identique à celle décrite dans la section précédente. Dans cette implémentation, nous utilisons un exportateur stdout qui exporte toutes les informations de trace dans stdout dans un format structuré.
Vous l'appelez ensuite à partir de la fonction principale. Appelez initTracer() et assurez-vous d'appeler TracerProvider.Shutdown() lorsque vous fermez l'application.
step0/src/loadgen/main.go
func main() {
// step1. setup OpenTelemetry
tp, err := initTracer()
if err != nil {
log.Fatalf("failed to initialize TracerProvider: %v", err)
}
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step1. end setup
log.Printf("starting worder with %d workers in %d concurrency", numWorkers, numConcurrency)
log.Printf("number of rounds: %d (0 is inifinite)", numRounds)
...
Une fois la configuration terminée, vous devez créer un span avec un ID de trace et un ID de span uniques. OpenTelemetry fournit une bibliothèque pratique pour cela. Ajoutez des packages au client HTTP de l'instrument.
step0/src/loadgen/main.go
import (
"context"
"encoding/json"
"fmt"
"io"
"log"
"math/rand"
"net/http"
"net/http/httptrace" // step1. add packages
"net/url"
"time"
// step1. add packages
"go.opentelemetry.io/contrib/instrumentation/net/http/httptrace/otelhttptrace"
"go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp"
// step1. end add packages
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/attribute"
stdout "go.opentelemetry.io/otel/exporters/stdout/stdouttrace"
"go.opentelemetry.io/otel/propagation"
sdktrace "go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.10.0"
"go.opentelemetry.io/otel/trace"
)
Étant donné que le générateur de charge appelle le service client en HTTP avec net/http dans la fonction runQuery, nous utilisons le package contrib pour net/http et activons l'instrumentation avec l'extension du package httptrace et otelhttp.
Commencez par ajouter une variable globale de package httpClient pour appeler les requêtes HTTP via le client instrumenté.
step0/src/loadgen/main.go
var httpClient = http.Client{
Transport: otelhttp.NewTransport(http.DefaultTransport)
}
Ajoutez ensuite l'instrumentation dans la fonction runQuery pour créer le segment personnalisé à l'aide d'OpenTelemetry et du segment généré automatiquement à partir du client HTTP personnalisé. Voici ce que vous allez faire :
- Obtenir un traceur auprès d'un
TracerProvidermondial avecotel.Tracer() - Créer une portée racine avec la méthode
Tracer.Start() - Mettez fin à la portée racine à un moment arbitraire (dans ce cas, à la fin de la fonction
runQuery).
step0/src/loadgen/main.go
reqURL.RawQuery = v.Encode()
// step1. replace http.Get() with custom client call
// resp, err := http.Get(reqURL.String())
// step1. instrument trace
ctx := context.Background()
tr := otel.Tracer("loadgen")
ctx, span := tr.Start(ctx, "query.request", trace.WithAttributes(
semconv.TelemetrySDKLanguageGo,
semconv.ServiceNameKey.String("loadgen.runQuery"),
attribute.Key("query").String(s),
))
defer span.End()
ctx = httptrace.WithClientTrace(ctx, otelhttptrace.NewClientTrace(ctx))
req, err := http.NewRequestWithContext(ctx, "GET", reqURL.String(), nil)
if err != nil {
return -1, fmt.Errorf("error creating HTTP request object: %v", err)
}
resp, err := httpClient.Do(req)
// step1. end instrumentation
if err != nil {
return -1, fmt.Errorf("error sending request to %v: %v", reqURL.String(), err)
}
Vous avez terminé l'instrumentation dans loadgen (application cliente HTTP). Veillez à mettre à jour vos go.mod et go.sum avec la commande go mod.
go mod tidy
Service client pour les instruments
Dans la section précédente, nous avons instrumenté la partie entourée du rectangle rouge dans le schéma ci-dessous. Nous avons instrumenté les informations de portée dans le service de générateur de charge. Comme pour le service de génération de charge, nous devons maintenant instrumenter le service client. La différence avec le service de génération de charge est que le service client doit extraire les informations d'ID de trace propagées à partir du service de génération de charge dans l'en-tête HTTP et utiliser l'ID pour générer des Spans.

Ouvrez l'éditeur Cloud Shell et ajoutez les packages requis, comme nous l'avons fait pour le service de générateur de charge.
step0/src/client/main.go
import (
"context"
"encoding/json"
"fmt"
"io"
"log"
"net/http"
"net/url"
"os"
"time"
"opentelemetry-trace-codelab-go/client/shakesapp"
// step1. add new import
"go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/attribute"
stdout "go.opentelemetry.io/otel/exporters/stdout/stdouttrace"
"go.opentelemetry.io/otel/propagation"
sdktrace "go.opentelemetry.io/otel/sdk/trace"
"go.opentelemetry.io/otel/trace"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
// step1. end new import
)
Là encore, nous devons configurer OpenTelemetry. Il vous suffit de copier et coller la fonction initTracer de loadgen et de l'appeler également dans la fonction main du service client.
step0/src/client/main.go
// step1. add OpenTelemetry initialization function
func initTracer() (*sdktrace.TracerProvider, error) {
// create a stdout exporter to show collected spans out to stdout.
exporter, err := stdout.New(stdout.WithPrettyPrint())
if err != nil {
return nil, err
}
// for the demonstration, we use AlwaysSmaple sampler to take all spans.
// do not use this option in production.
tp := sdktrace.NewTracerProvider(
sdktrace.WithSampler(sdktrace.AlwaysSample()),
sdktrace.WithBatcher(exporter),
)
otel.SetTracerProvider(tp)
otel.SetTextMapPropagator(propagation.TraceContext{})
return tp, nil
}
Il est maintenant temps d'instrumenter les spans. Étant donné que le service client doit accepter les requêtes HTTP du service loadgen, il doit instrumenter le gestionnaire. Le serveur HTTP du service client est implémenté avec net/http. Vous pouvez utiliser le package otelhttp comme nous l'avons fait dans loadgen.
Tout d'abord, nous remplaçons l'enregistrement du gestionnaire par le gestionnaire otelhttp. Dans la fonction main, recherchez les lignes où le gestionnaire HTTP est enregistré avec http.HandleFunc().
step0/src/client/main.go
// step1. change handler to intercept OpenTelemetry related headers
// http.HandleFunc("/", svc.handler)
otelHandler := otelhttp.NewHandler(http.HandlerFunc(svc.handler), "client.handler")
http.Handle("/", otelHandler)
// step1. end intercepter setting
http.HandleFunc("/_genki", svc.health)
Ensuite, nous instrumentons la portée réelle à l'intérieur du gestionnaire. Recherchez le gestionnaire func (*clientService) handler(), puis ajoutez l'instrumentation de portée avec trace.SpanFromContext().
step0/src/client/main.go
func (cs *clientService) handler(w http.ResponseWriter, r *http.Request) {
...
ctx := r.Context()
ctx, cancel := context.WithCancel(ctx)
defer cancel()
// step1. instrument trace
span := trace.SpanFromContext(ctx)
defer span.End()
// step1. end instrument
...
Grâce à cette instrumentation, vous obtenez les spans du début à la fin de la méthode handler. Pour faciliter l'analyse des spans, ajoutez un attribut supplémentaire qui stocke le nombre de correspondances à la requête. Juste avant la ligne de journal, ajoutez le code suivant.
func (cs *clientService) handler(w http.ResponseWriter, r *http.Request) {
...
// step1. add span specific attribute
span.SetAttributes(attribute.Key("matched").Int64(resp.MatchCount))
// step1. end adding attribute
log.Println(string(ret))
...
Avec toute l'instrumentation ci-dessus, vous avez terminé l'instrumentation de trace entre le générateur de charge et le client. Voyons comment cela fonctionne. Exécutez à nouveau le code avec Skaffold.
skaffold dev
Après un certain temps d'exécution des services sur le cluster GKE, vous verrez une grande quantité de messages de journaux comme celui-ci :
Résultat de la commande
[loadgen] {
[loadgen] "Name": "query.request",
[loadgen] "SpanContext": {
[loadgen] "TraceID": "cfa22247a542beeb55a3434392d46b89",
[loadgen] "SpanID": "18b06404b10c418b",
[loadgen] "TraceFlags": "01",
[loadgen] "TraceState": "",
[loadgen] "Remote": false
[loadgen] },
[loadgen] "Parent": {
[loadgen] "TraceID": "00000000000000000000000000000000",
[loadgen] "SpanID": "0000000000000000",
[loadgen] "TraceFlags": "00",
[loadgen] "TraceState": "",
[loadgen] "Remote": false
[loadgen] },
[loadgen] "SpanKind": 1,
[loadgen] "StartTime": "2022-07-14T13:13:36.686751087Z",
[loadgen] "EndTime": "2022-07-14T13:14:31.849601964Z",
[loadgen] "Attributes": [
[loadgen] {
[loadgen] "Key": "telemetry.sdk.language",
[loadgen] "Value": {
[loadgen] "Type": "STRING",
[loadgen] "Value": "go"
[loadgen] }
[loadgen] },
[loadgen] {
[loadgen] "Key": "service.name",
[loadgen] "Value": {
[loadgen] "Type": "STRING",
[loadgen] "Value": "loadgen.runQuery"
[loadgen] }
[loadgen] },
[loadgen] {
[loadgen] "Key": "query",
[loadgen] "Value": {
[loadgen] "Type": "STRING",
[loadgen] "Value": "faith"
[loadgen] }
[loadgen] }
[loadgen] ],
[loadgen] "Events": null,
[loadgen] "Links": null,
[loadgen] "Status": {
[loadgen] "Code": "Unset",
[loadgen] "Description": ""
[loadgen] },
[loadgen] "DroppedAttributes": 0,
[loadgen] "DroppedEvents": 0,
[loadgen] "DroppedLinks": 0,
[loadgen] "ChildSpanCount": 5,
[loadgen] "Resource": [
[loadgen] {
[loadgen] "Key": "service.name",
[loadgen] "Value": {
[loadgen] "Type": "STRING",
[loadgen] "Value": "unknown_service:loadgen"
...
L'exportateur stdout émet ces messages. Vous remarquerez que les parents de toutes les portées par loadgen ont TraceID: 00000000000000000000000000000000, car il s'agit de la portée racine, c'est-à-dire de la première portée de la trace. Vous constaterez également que l'attribut d'intégration "query" contient la chaîne de requête transmise au service client.
Résumé
À cette étape, vous avez instrumenté le service de générateur de charge et le service client qui communiquent en HTTP, et vous avez confirmé que vous pouviez propager le contexte de trace entre les services et exporter les informations de portée des deux services vers stdout.
Étape suivante
À l'étape suivante, vous instrumenterez le service client et le service serveur pour confirmer comment propager le contexte de trace via gRPC.
5. Instrumentation pour gRPC
À l'étape précédente, nous avons instrumenté la première moitié de la requête dans ces microservices. Dans cette étape, nous allons essayer d'instrumenter la communication gRPC entre le service client et le service serveur. (rectangle vert et violet sur l'image ci-dessous)

Instrumentation précompilée pour le client gRPC
L'écosystème OpenTelemetry propose de nombreuses bibliothèques pratiques qui aident les développeurs à instrumenter les applications. À l'étape précédente, nous avons utilisé l'instrumentation prédéfinie pour le package net/http. Dans cette étape, comme nous essayons de propager le contexte de trace via gRPC, nous utilisons la bibliothèque à cet effet.
Vous allez d'abord importer le package gRPC prédéfini appelé otelgrpc.
step0/src/client/main.go
import (
"context"
"encoding/json"
"fmt"
"io"
"log"
"net/http"
"net/url"
"os"
"time"
"opentelemetry-trace-codelab-go/client/shakesapp"
// step2. add prebuilt gRPC package (otelgrpc)
"go.opentelemetry.io/contrib/instrumentation/google.golang.org/grpc/otelgrpc"
"go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/attribute"
stdout "go.opentelemetry.io/otel/exporters/stdout/stdouttrace"
"go.opentelemetry.io/otel/propagation"
sdktrace "go.opentelemetry.io/otel/sdk/trace"
"go.opentelemetry.io/otel/trace"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
)
Cette fois, le service client est un client gRPC par rapport au service serveur. Vous devez donc instrumenter le client gRPC. Recherchez la fonction mustConnGRPC et ajoutez des intercepteurs gRPC qui instrumentent de nouvelles portées chaque fois que le client envoie des requêtes au serveur.
step0/src/client/main.go
// Helper function for gRPC connections: Dial and create client once, reuse.
func mustConnGRPC(ctx context.Context, conn **grpc.ClientConn, addr string) {
var err error
// step2. add gRPC interceptor
interceptorOpt := otelgrpc.WithTracerProvider(otel.GetTracerProvider())
*conn, err = grpc.DialContext(ctx, addr,
grpc.WithTransportCredentials(insecure.NewCredentials()),
grpc.WithUnaryInterceptor(otelgrpc.UnaryClientInterceptor(interceptorOpt)),
grpc.WithStreamInterceptor(otelgrpc.StreamClientInterceptor(interceptorOpt)),
grpc.WithTimeout(time.Second*3),
)
// step2: end adding interceptor
if err != nil {
panic(fmt.Sprintf("Error %s grpc: failed to connect %s", err, addr))
}
}
Comme vous avez déjà configuré OpenTelemetry dans la section précédente, vous n'avez pas besoin de le faire.
Instrumentation prédéfinie pour le serveur gRPC
Comme nous l'avons fait pour le client gRPC, nous appelons l'instrumentation prédéfinie pour le serveur gRPC. Ajoutez le nouveau package à la section d'importation, comme suit :
step0/src/server/main.go
import (
"context"
"fmt"
"io/ioutil"
"log"
"net"
"os"
"regexp"
"strings"
"opentelemetry-trace-codelab-go/server/shakesapp"
"cloud.google.com/go/storage"
// step2. add OpenTelemetry packages including otelgrpc
"go.opentelemetry.io/contrib/instrumentation/google.golang.org/grpc/otelgrpc"
"go.opentelemetry.io/otel"
stdout "go.opentelemetry.io/otel/exporters/stdout/stdouttrace"
"go.opentelemetry.io/otel/propagation"
sdktrace "go.opentelemetry.io/otel/sdk/trace"
"google.golang.org/api/iterator"
"google.golang.org/api/option"
"google.golang.org/grpc"
healthpb "google.golang.org/grpc/health/grpc_health_v1"
)
Comme il s'agit de la première instrumentation du serveur, vous devez d'abord configurer OpenTelemetry, comme nous l'avons fait pour les services loadgen et client.
step0/src/server/main.go
// step2. add OpenTelemetry initialization function
func initTracer() (*sdktrace.TracerProvider, error) {
// create a stdout exporter to show collected spans out to stdout.
exporter, err := stdout.New(stdout.WithPrettyPrint())
if err != nil {
return nil, err
}
// for the demonstration, we use AlwaysSmaple sampler to take all spans.
// do not use this option in production.
tp := sdktrace.NewTracerProvider(
sdktrace.WithSampler(sdktrace.AlwaysSample()),
sdktrace.WithBatcher(exporter),
)
otel.SetTracerProvider(tp)
otel.SetTextMapPropagator(propagation.TraceContext{})
return tp, nil
}
func main() {
...
// step2. setup OpenTelemetry
tp, err := initTracer()
if err != nil {
log.Fatalf("failed to initialize TracerProvider: %v", err)
}
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
...
Ensuite, vous devez ajouter des intercepteurs de serveur. Dans la fonction main, recherchez l'endroit où grpc.NewServer() est appelé et ajoutez des intercepteurs à la fonction.
step0/src/server/main.go
func main() {
...
svc := NewServerService()
// step2: add interceptor
interceptorOpt := otelgrpc.WithTracerProvider(otel.GetTracerProvider())
srv := grpc.NewServer(
grpc.UnaryInterceptor(otelgrpc.UnaryServerInterceptor(interceptorOpt)),
grpc.StreamInterceptor(otelgrpc.StreamServerInterceptor(interceptorOpt)),
)
// step2: end adding interceptor
shakesapp.RegisterShakespeareServiceServer(srv, svc)
...
Exécuter le microservice et confirmer la trace
Exécutez ensuite votre code modifié avec la commande skaffold.
skaffold dev
Là encore, vous voyez un certain nombre d'informations sur les spans dans stdout.
Résultat de la commande
...
[server] {
[server] "Name": "shakesapp.ShakespeareService/GetMatchCount",
[server] "SpanContext": {
[server] "TraceID": "89b472f213a400cf975e0a0041649667",
[server] "SpanID": "96030dbad0061b3f",
[server] "TraceFlags": "01",
[server] "TraceState": "",
[server] "Remote": false
[server] },
[server] "Parent": {
[server] "TraceID": "89b472f213a400cf975e0a0041649667",
[server] "SpanID": "cd90cc3859b73890",
[server] "TraceFlags": "01",
[server] "TraceState": "",
[server] "Remote": true
[server] },
[server] "SpanKind": 2,
[server] "StartTime": "2022-07-14T14:05:55.74822525Z",
[server] "EndTime": "2022-07-14T14:06:03.449258891Z",
[server] "Attributes": [
...
[server] ],
[server] "Events": [
[server] {
[server] "Name": "message",
[server] "Attributes": [
...
[server] ],
[server] "DroppedAttributeCount": 0,
[server] "Time": "2022-07-14T14:05:55.748235489Z"
[server] },
[server] {
[server] "Name": "message",
[server] "Attributes": [
...
[server] ],
[server] "DroppedAttributeCount": 0,
[server] "Time": "2022-07-14T14:06:03.449255889Z"
[server] }
[server] ],
[server] "Links": null,
[server] "Status": {
[server] "Code": "Unset",
[server] "Description": ""
[server] },
[server] "DroppedAttributes": 0,
[server] "DroppedEvents": 0,
[server] "DroppedLinks": 0,
[server] "ChildSpanCount": 0,
[server] "Resource": [
[server] {
...
[server] ],
[server] "InstrumentationLibrary": {
[server] "Name": "go.opentelemetry.io/contrib/instrumentation/google.golang.org/grpc/otelgrpc",
[server] "Version": "semver:0.33.0",
[server] "SchemaURL": ""
[server] }
[server] }
...
Vous remarquez que vous n'avez intégré aucun nom de portée et que vous avez créé manuellement des portées avec trace.Start() ou span.SpanFromContext(). Vous obtenez tout de même un grand nombre de spans, car les intercepteurs gRPC les ont générés.
Résumé
Dans cette étape, vous avez instrumenté la communication basée sur gRPC avec l'aide des bibliothèques de l'écosystème OpenTelemetry.
Étape suivante
À l'étape suivante, vous allez enfin visualiser la trace avec Cloud Trace et apprendre à analyser les spans collectés.
6. Visualiser une trace avec Cloud Trace
Vous avez instrumenté les traces dans l'ensemble du système avec OpenTelemetry. Jusqu'à présent, vous avez appris à instrumenter les services HTTP et gRPC. Vous avez appris à les instrumenter, mais pas encore à les analyser. Dans cette section, vous allez remplacer les exportateurs stdout par des exportateurs Cloud Trace et apprendre à analyser vos traces.
Utiliser l'exportateur Cloud Trace
L'une des caractéristiques les plus intéressantes d'OpenTelemetry est sa modularité. Pour visualiser tous les spans collectés par votre instrumentation, il vous suffit de remplacer l'exportateur stdout par l'exportateur Cloud Trace.
Ouvrez les fichiers main.go de chaque service et recherchez la fonction initTracer(). Supprimez la ligne pour générer un exportateur stdout et créez un exportateur Cloud Trace à la place.
step0/src/loadgen/main.go
import (
...
// step3. add OpenTelemetry for Cloud Trace package
cloudtrace "github.com/GoogleCloudPlatform/opentelemetry-operations-go/exporter/trace"
)
// step1. add OpenTelemetry initialization function
func initTracer() (*sdktrace.TracerProvider, error) {
// step3. replace stdout exporter with Cloud Trace exporter
// cloudtrace.New() finds the credentials to Cloud Trace automatically following the
// rules defined by golang.org/x/oauth2/google.findDefaultCredentailsWithParams.
// https://pkg.go.dev/golang.org/x/oauth2/google#FindDefaultCredentialsWithParams
exporter, err := cloudtrace.New()
// step3. end replacing exporter
if err != nil {
return nil, err
}
// for the demonstration, we use AlwaysSmaple sampler to take all spans.
// do not use this option in production.
tp := sdktrace.NewTracerProvider(
sdktrace.WithSampler(sdktrace.AlwaysSample()),
sdktrace.WithBatcher(exporter),
)
otel.SetTracerProvider(tp)
otel.SetTextMapPropagator(propagation.TraceContext{})
return tp, nil
}
Vous devez également modifier la même fonction dans le service client et serveur.
Exécuter le microservice et confirmer la trace
Après la modification, exécutez le cluster comme d'habitude avec la commande skaffold.
skaffold dev
Vous ne voyez pas beaucoup d'informations sur les spans au format des journaux structurés sur stdout, car vous avez remplacé l'exportateur par celui de Cloud Trace.
Résultat de la commande
[loadgen] 2022/07/14 15:01:07 simulated 20 requests
[loadgen] 2022/07/14 15:01:07 simulating client requests, round 37
[loadgen] 2022/07/14 15:01:14 query 'sweet': matched 958
[client] 2022/07/14 15:01:14 {"match_count":958}
[client] 2022/07/14 15:01:14 {"match_count":3040}
[loadgen] 2022/07/14 15:01:14 query 'love': matched 3040
[client] 2022/07/14 15:01:15 {"match_count":349}
[loadgen] 2022/07/14 15:01:15 query 'hello': matched 349
[client] 2022/07/14 15:01:15 {"match_count":484}
[loadgen] 2022/07/14 15:01:15 query 'faith': matched 484
[loadgen] 2022/07/14 15:01:15 query 'insolence': matched 14
[client] 2022/07/14 15:01:15 {"match_count":14}
[client] 2022/07/14 15:01:21 {"match_count":484}
[loadgen] 2022/07/14 15:01:21 query 'faith': matched 484
[client] 2022/07/14 15:01:21 {"match_count":728}
[loadgen] 2022/07/14 15:01:21 query 'world': matched 728
[client] 2022/07/14 15:01:22 {"match_count":484}
[loadgen] 2022/07/14 15:01:22 query 'faith': matched 484
[loadgen] 2022/07/14 15:01:22 query 'hello': matched 349
[client] 2022/07/14 15:01:22 {"match_count":349}
[client] 2022/07/14 15:01:23 {"match_count":1036}
[loadgen] 2022/07/14 15:01:23 query 'friend': matched 1036
[loadgen] 2022/07/14 15:01:28 query 'tear': matched 463
...
Vérifions maintenant si tous les spans sont correctement envoyés à Cloud Trace. Accédez à la console Cloud, puis accédez à "Liste de traces". Vous pouvez y accéder facilement depuis le champ de recherche. Sinon, vous pouvez cliquer sur le menu dans le volet de gauche. 
Vous verrez alors de nombreux points bleus répartis sur le graphique de latence. Chaque point représente une seule trace.

Cliquez sur l'un d'eux pour afficher les détails de la trace. 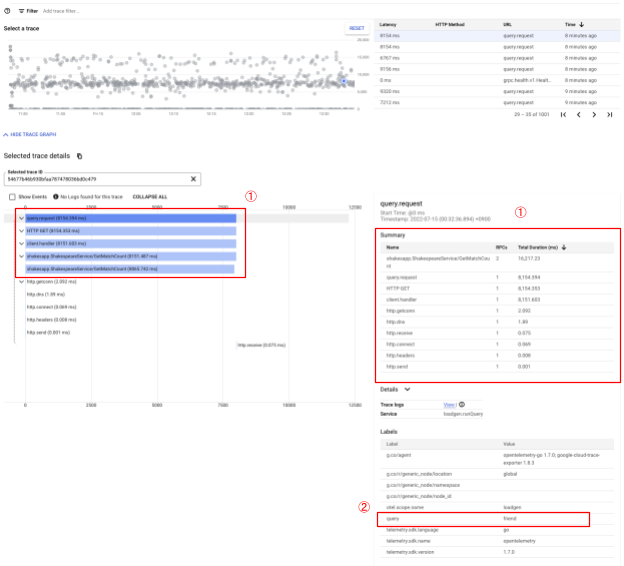
Même avec ce simple aperçu, vous avez déjà beaucoup d'informations. Par exemple, à partir du graphique en cascade, vous pouvez voir que la latence est principalement due à la portée nommée shakesapp.ShakespeareService/GetMatchCount. (Voir 1 dans l'image ci-dessus) Vous pouvez le vérifier dans le tableau récapitulatif. (La colonne la plus à droite indique la durée de chaque span.) De plus, cette trace concernait la requête "ami". (voir 2 dans l'image ci-dessus).
Compte tenu de ces brèves analyses, vous pouvez vous rendre compte que vous avez besoin de connaître des étendues plus précises dans la méthode GetMatchCount. La visualisation est plus efficace que les informations stdout. Pour en savoir plus sur les détails de Cloud Trace, consultez notre documentation officielle.
Résumé
Au cours de cette étape, vous avez remplacé l'exportateur stdout par un exportateur Cloud Trace et visualisé les traces sur Cloud Trace. Vous avez également appris à analyser les traces.
Étape suivante
À l'étape suivante, vous allez modifier le code source du service de serveur pour ajouter une sous-étendue dans GetMatchCount.
7. Ajouter des sous-couvertures pour une meilleure analyse
À l'étape précédente, vous avez constaté que la cause du temps d'aller-retour observé à partir de loadgen est principalement le processus à l'intérieur de la méthode GetMatchCount, le gestionnaire gRPC, dans le service de serveur. Toutefois, comme nous n'avons instrumenté que le gestionnaire, nous ne pouvons pas obtenir d'autres insights à partir du graphique en cascade. Il s'agit d'un cas courant lorsque nous commençons à instrumenter des microservices.

Dans cette section, nous allons instrumenter une sous-étendue dans laquelle le serveur appelle Google Cloud Storage, car il est courant que certaines E/S réseau externes prennent beaucoup de temps dans le processus. Il est important d'identifier si l'appel en est la cause.
Instrumenter une sous-étendue dans le serveur
Ouvrez main.go sur le serveur et recherchez la fonction readFiles. Cette fonction appelle une requête à Google Cloud Storage pour extraire tous les fichiers texte des œuvres de Shakespeare. Dans cette fonction, vous pouvez créer une sous-étendue, comme vous l'avez fait pour l'instrumentation du serveur HTTP dans le service client.
step0/src/server/main.go
func readFiles(ctx context.Context, bucketName, prefix string) ([]string, error) {
type resp struct {
s string
err error
}
// step4: add an extra span
span := trace.SpanFromContext(ctx)
span.SetName("server.readFiles")
span.SetAttributes(attribute.Key("bucketname").String(bucketName))
defer span.End()
// step4: end add span
...
Voilà, vous savez comment ajouter une étendue. Voyons ce que cela donne en exécutant l'application.
Exécuter le microservice et confirmer la trace
Après la modification, exécutez le cluster comme d'habitude avec la commande skaffold.
skaffold dev
Sélectionnez une trace nommée query.request dans la liste des traces. Vous verrez un graphique en cascade de trace semblable, à l'exception d'une nouvelle étendue sous shakesapp.ShakespeareService/GetMatchCount. (Portée encadrée par le rectangle rouge ci-dessous)

Ce graphique vous permet de constater que l'appel externe à Google Cloud Storage occupe une grande partie de la latence, mais que d'autres éléments sont responsables de la majorité de la latence.
Vous avez déjà obtenu de nombreux insights à partir de quelques looks du graphique en cascade des traces. Comment obtenir plus de détails sur les performances dans votre application ? C'est là que le profileur entre en jeu, mais pour l'instant, nous allons arrêter cet atelier de programmation ici et déléguer tous les tutoriels sur le profileur à la partie 2.
Résumé
Au cours de cette étape, vous avez instrumenté une autre portée dans le service de serveur et obtenu des informations supplémentaires sur la latence du système.
8. Félicitations
Vous avez créé des traces distribuées avec OpenTelemetry et confirmé les latences des requêtes dans le microservice sur Google Cloud Trace.
Pour des exercices plus complets, vous pouvez essayer les thèmes suivants par vous-même.
- L'implémentation actuelle envoie toutes les portées générées par la vérification de l'état. (
grpc.health.v1.Health/Check) Comment filtrer ces spans dans Cloud Trace ? Cliquez ici pour obtenir un indice. - Corrélez les journaux d'événements avec les spans et découvrez comment cela fonctionne dans Google Cloud Trace et Google Cloud Logging. Cliquez ici pour obtenir un indice.
- Remplacez un service par celui d'une autre langue et essayez de l'instrumenter avec OpenTelemetry pour cette langue.
Si vous souhaitez en savoir plus sur le profileur après cela, passez à la partie 2. Dans ce cas, vous pouvez ignorer la section sur le nettoyage ci-dessous.
Nettoyage
Après cet atelier de programmation, veuillez arrêter le cluster Kubernetes et veillez à supprimer le projet afin d'éviter des frais inattendus sur Google Kubernetes Engine, Google Cloud Trace et Google Artifact Registry.
Commencez par supprimer le cluster. Si vous exécutez le cluster avec skaffold dev, il vous suffit d'appuyer sur Ctrl+C. Si vous exécutez le cluster avec skaffold run, exécutez la commande suivante :
skaffold delete
Résultat de la commande
Cleaning up... - deployment.apps "clientservice" deleted - service "clientservice" deleted - deployment.apps "loadgen" deleted - deployment.apps "serverservice" deleted - service "serverservice" deleted
Après avoir supprimé le cluster, dans le volet de menu, sélectionnez "IAM et administration" > "Paramètres", puis cliquez sur le bouton "ARRÊTER".

Saisissez ensuite l'ID du projet (et non son nom) dans le formulaire de la boîte de dialogue, puis confirmez l'arrêt.