
1. Introduction
Présentation
Cet atelier fait suite à Créer des systèmes multi-agents avec ADK.
Dans cet atelier, vous avez créé un système de création de cours composé des éléments suivants :
- Agent de recherche : utilise google_search pour trouver des informations à jour.
- Agent évaluateur : évalue la qualité et l'exhaustivité de la recherche.
- Agent Content Builder : transformer les recherches en cours structuré.
- Agent d'orchestration : il gère le workflow et la communication entre ces spécialistes.
Il comprenait également une application Web qui permettait aux utilisateurs d'envoyer une demande de création de cours et d'obtenir un cours en réponse.
Researcher, Judge et Content Builder sont déployés en tant qu'agents A2A dans des services Cloud Run distincts. Orchestrator est un autre service Cloud Run avec l'API ADK Service.
Pour cet atelier, nous avons modifié l'agent Researcher afin qu'il utilise l'outil Wikipedia Search au lieu de la fonctionnalité Recherche Google de Gemini. Il nous permet d'inspecter la façon dont les appels d'outils personnalisés sont suivis et évalués.
Nous avons donc créé un système multi-agents distribué. Mais comment savoir si elle fonctionne vraiment bien ? Le chercheur trouve-t-il toujours des informations pertinentes ? Le Juge identifie-t-il correctement les recherches de mauvaise qualité ?
Dans cet atelier, vous allez remplacer les "vérifications d'ambiance" subjectives par une évaluation basée sur les données à l'aide de Gen AI Evaluation Service de Vertex AI. Vous allez implémenter des métriques de qualité d'utilisation des outils et de rubriques adaptatives pour évaluer rigoureusement le système multi-agents distribué créé dans l'atelier 1. Enfin, vous automatiserez ce processus dans un pipeline CI/CD, en veillant à ce que chaque déploiement maintienne la fiabilité et la précision de vos agents de production.
Vous allez créer un pipeline d'évaluation continue pour vos agents. Vous allez apprendre à effectuer les tâches suivantes :
- Déployez vos agents sur une révision taguée privée dans Google Cloud Run (déploiement fantôme).
- Exécutez une suite d'évaluation automatisée sur cette révision spécifique à l'aide de Vertex AI Gen AI Evaluation Service.
- Visualisez et analysez les résultats.
- Utilisez l'évaluation dans votre pipeline CI/CD.
2. Concepts fondamentaux : théorie de l'évaluation des agents
Lorsque nous développons et exécutons des agents d'IA, nous effectuons deux types d'évaluation : l'expérimentation hors connexion et l'évaluation continue avec tests de régression automatisés. La première est le moteur créatif du processus de développement, où nous effectuons des tests ponctuels, affinons les requêtes et itérons rapidement pour débloquer de nouvelles fonctionnalités. La seconde est la couche défensive de notre pipeline CI/CD, où nous effectuons des évaluations continues par rapport à un ensemble de données "golden" pour nous assurer qu'aucune modification du code ne dégrade involontairement la qualité éprouvée de l'agent.
La différence fondamentale réside dans la découverte par rapport à la défense :
- L'expérimentation hors connexion est un processus d'optimisation. Elle est ouverte et variable. Vous modifiez activement les entrées (requêtes, modèles, paramètres) pour maximiser un score ou résoudre un problème spécifique. L'objectif est d'augmenter le "plafond" de ce que l'agent peut faire.
- L'évaluation continue (tests de régression automatisés) est un processus de vérification. Il est rigide et répétitif. Vous conservez les entrées constantes (l'ensemble de données "golden") pour vous assurer que les sorties restent stables. L'objectif est d'empêcher l'effondrement du "plancher" des performances.
Dans cet atelier, nous allons nous concentrer sur l'évaluation continue. Nous allons développer un pipeline de tests de régression automatisés qui est censé s'exécuter chaque fois que quelqu'un apporte une modification à l'agent d'IA, tout comme ces tests unitaires.
Avant d'écrire du code, il est essentiel de comprendre ce que nous mesurons.
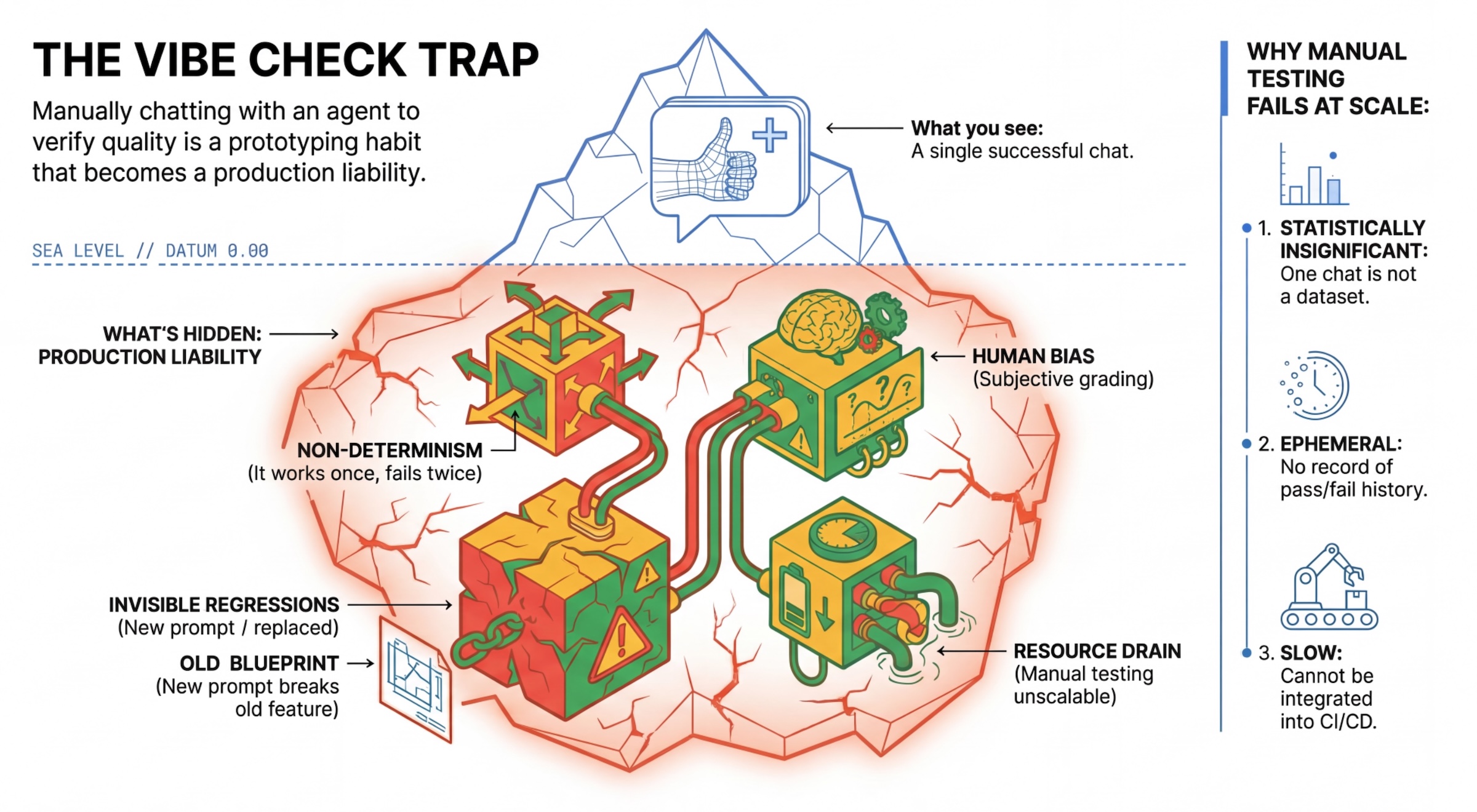
Le piège du "vibe check"
De nombreux développeurs testent les agents en discutant manuellement avec eux. C'est ce qu'on appelle le "vibe checking". Bien qu'utile pour le prototypage, il échoue en production pour les raisons suivantes :
- Non-déterminisme : les agents peuvent répondre différemment à chaque fois. Vous avez besoin de tailles d'échantillon statistiquement significatives.
- Régression invisible : l'amélioration d'une requête peut entraîner la défaillance d'un autre cas d'utilisation.
- Biais humain : "C'est super" est subjectif.
- Travail chronophage : tester manuellement des dizaines de scénarios à chaque commit est lent.
Deux façons d'évaluer les performances de l'agent
Pour créer un pipeline robuste, nous combinons différents types de correcteurs :
- Correcteurs basés sur le code (déterministes) :
- Ce qu'ils mesurent : contraintes strictes (par exemple, "A-t-il renvoyé un JSON valide ?", "A-t-il appelé l'outil
search?"). - Avantages : rapide, économique et 100% précis.
- Inconvénients : il ne peut pas évaluer les nuances ni la qualité.
- Ce qu'ils mesurent : contraintes strictes (par exemple, "A-t-il renvoyé un JSON valide ?", "A-t-il appelé l'outil
- Correcteurs basés sur des modèles (probabilistes) :
- Également connu sous le nom de "LLM-as-a-Judge". Nous utilisons un modèle puissant (comme Gemini 3 Pro) pour évaluer la sortie de l'agent.
- Ce qu'ils mesurent : nuance, raisonnement, utilité, sécurité.
- Avantages : permet d'évaluer des tâches complexes et ouvertes.
- Inconvénients : plus lent, plus coûteux, nécessite une ingénierie des requêtes minutieuse pour le juge.
Métriques d'évaluation Vertex AI
Dans cet atelier, nous utilisons Gen AI Evaluation Service de Vertex AI, qui fournit des métriques gérées pour que vous n'ayez pas à écrire chaque juge à partir de zéro.
Il existe plusieurs façons de regrouper les métriques pour l'évaluation des agents :
- Métriques basées sur des rubriques : intègrent des LLM dans les workflows d'évaluation.
- Rubriques adaptatives : les rubriques sont générées de manière dynamique pour chaque requête. Les réponses sont évaluées avec des commentaires précis et explicables (réussite ou échec) spécifiques à la requête.
- Rubriques statiques : les rubriques sont définies de manière explicite et la même rubrique s'applique à toutes les requêtes. Les réponses sont évaluées avec le même ensemble d'évaluateurs basés sur des scores numériques. Un seul score numérique (par exemple, de 1 à 5) par requête. Lorsqu'une évaluation est requise sur une dimension très spécifique ou lorsque la même grille d'évaluation est requise pour toutes les requêtes.
- Métriques issues de calculs : évaluent les réponses à l'aide d'algorithmes déterministes, généralement en utilisant la vérité terrain. Score numérique (par exemple, de 0,0 à 1,0) par requête. Lorsque la vérité terrain est disponible et peut être mise en correspondance avec une méthode déterministe.
- Métriques de fonction personnalisées : définissez votre propre métrique à l'aide d'une fonction Python.
Métriques spécifiques que nous allons utiliser :
Final Response Match: (basé sur une référence) La réponse correspond-elle à notre "réponse idéale" ?Tool Use Quality: (sans référence) L'agent a-t-il utilisé les outils appropriés de manière adéquate ?Hallucination: (sans référence) Les affirmations contenues dans la réponse sont-elles étayées par le contexte récupéré ?Tool Trajectory PrecisionetTool Trajectory Recall(basé sur des références) : l'agent a-t-il sélectionné le bon outil et fourni des arguments valides ? Contrairement àTool Use Quality, ces métriques personnalisées utilisent une trajectoire de référence, c'est-à-dire une séquence d'appels et d'arguments d'outils attendus.
3. Configuration
Configuration
- Ouvrez Cloud Shell : cliquez sur l'icône Activer Cloud Shell en haut à droite de la console Google Cloud.
- Exécutez la commande suivante pour actualiser la connexion et mettre à jour les identifiants par défaut de l'application (ADC) :
gcloud auth login --update-adc - Définissez un projet actif pour gcloud CLI.Exécutez la commande suivante pour obtenir le projet gcloud actuel :
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDpar l'ID de votre projet. - Définissez la région par défaut dans laquelle vos services Cloud Run seront déployés.
gcloud config set run/region us-west1us-west1, vous pouvez utiliser n'importe quelle région Cloud Run plus proche de vous.
Code et dépendances
- Clonez le code de démarrage et accédez au répertoire racine du projet.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab - Créez le fichier
.env:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env - Installez les dépendances en exécutant la commande suivante dans la fenêtre de terminal :
uv sync
4. Comprendre le déploiement sécurisé
Avant d'évaluer, nous devons déployer. Mais nous ne voulons pas casser l'application en direct si notre nouveau code est mauvais.
Tags de révision et déploiement fantôme
Google Cloud Run est compatible avec les révisions. Chaque fois que vous déployez une application, une révision immuable est créée. Vous pouvez attribuer des tags à ces révisions pour y accéder via une URL spécifique, même si elles ne reçoivent aucun trafic public.
Pourquoi ne pas simplement exécuter les évaluations en local ?
Bien que l'ADK soit compatible avec l'évaluation locale, le déploiement dans une révision masquée offre des avantages essentiels pour les systèmes de production. Cela distingue l'évaluation au niveau du système (ce que nous faisons) des tests unitaires :
- Parité des environnements : les environnements locaux sont différents (réseau, processeur/mémoire et secrets différents). Les tests dans le cloud permettent de s'assurer que votre agent fonctionne dans l'environnement d'exécution réel (test système).
- Interaction multi-agents : dans un système distribué, les agents communiquent via HTTP. Les tests "locaux" simulent souvent ces connexions. Le déploiement fantôme teste la latence réseau réelle, les configurations de délai avant expiration et l'authentification entre vos microservices.
- Secrets et autorisations : vérifie que votre compte de service dispose bien des autorisations dont il a besoin (par exemple, pour appeler Vertex AI ou lire des données depuis Firestore).
Remarque : Il s'agit d'une évaluation proactive (vérification avant que les utilisateurs ne le voient). Une fois déployé, vous utiliserez la surveillance réactive (observabilité) pour détecter les problèmes en production.
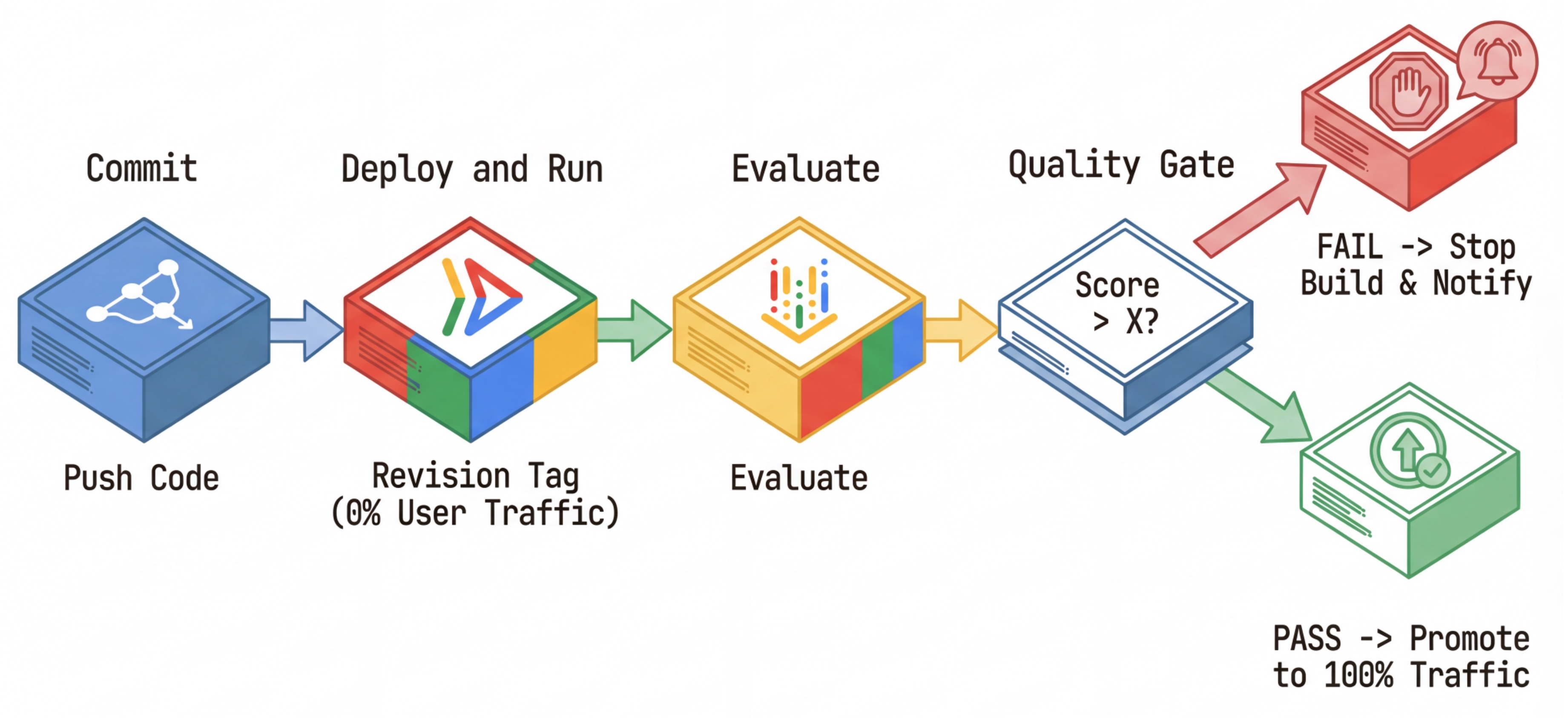
Workflow CI/CD : déployer, évaluer, promouvoir
Nous l'utilisons pour un pipeline de déploiement continu robuste :
- Commit : vous modifiez le prompt de l'agent et le transférez vers le dépôt.
- Déployer (masqué) : déclenche le déploiement d'une nouvelle révision taguée avec le hachage du commit (par exemple,
c-abc1234). Cette révision reçoit 0% du trafic public. - Évaluer : le script d'évaluation cible l'URL de révision spécifique
https://c-abc1234---researcher-xyz.run.app. - Promouvoir : si (et seulement si) l'évaluation est réussie et que les autres tests sont concluants, vous migrez le trafic vers cette nouvelle révision.
- Rétablir : si l'opération échoue, les utilisateurs n'ont jamais vu la mauvaise version. Vous pouvez simplement ignorer ou supprimer la mauvaise révision.
Cette stratégie vous permet de tester en production sans affecter les clients.
Analyser evaluate.sh
Ouvrez evaluate.sh. Ce script automatise le processus.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
deploy.sh gère le déploiement des révisions avec les options --no-traffic et --tag. Si un service est déjà en cours d'exécution, il ne sera pas affecté. La nouvelle révision "masquée" ne recevra aucun trafic, sauf si vous l'appelez explicitement avec une URL spéciale contenant le tag de révision (par exemple, https://c-abc1234---researcher-xyz.run.app).
5. Implémenter le script d'évaluation
Écrivons maintenant le code qui exécute réellement les tests.
- Ouvrez
evaluator/evaluate_agent.py. - Vous verrez les importations et la configuration, mais les métriques et la logique d'exécution seront manquantes.
Définir les métriques
Pour l'agent de recherche, nous disposons de "réponses d'or"/"vérité terrain" avec les réponses attendues. Il s'agit d'une évaluation des capacités : nous mesurons si l'agent peut effectuer correctement la tâche.
Nous voulons mesurer :
- Correspondance de la réponse finale : (Capacité) La réponse correspond-elle à la réponse attendue ? Il s'agit d'une métrique basée sur une référence. Il utilise un LLM de juge pour comparer la sortie de l'agent à la réponse attendue. Il ne s'attend pas à ce que la réponse soit exactement la même, mais qu'elle soit sémantiquement et factuellement similaire.
- Qualité de l'utilisation des outils : (qualité) métrique de rubriques adaptatives ciblée qui évalue la sélection d'outils appropriés, l'utilisation correcte des paramètres et le respect de la séquence d'opérations spécifiée.
- Trajectoire d'utilisation des outils : (trace) deux métriques personnalisées qui mesurent la trajectoire d'utilisation des outils par l'agent (précision et rappel) par rapport aux trajectoires attendues. Ces métriques sont implémentées dans
shared/evaluation/tool_metrics.pyen tant que fonctions personnalisées. Contrairement à Qualité de l'utilisation des outils, cette métrique est une métrique déterministe basée sur des références. Le code vérifie littéralement si les appels d'outils réels correspondent aux données de référence (reference_trajectorydans les données d'évaluation).
Métriques de trajectoire d'utilisation d'outils personnalisés
Pour les métriques personnalisées sur la trajectoire d'utilisation des outils, nous avons créé un ensemble de fonctions Python dans shared/evaluation/tool_metrics.py. Pour permettre à Vertex AI Gen AI Evaluation Service d'exécuter ces fonctions, nous devons lui transmettre ce code Python.
Pour ce faire, définissez un objet EvaluationRunMetric avec une configuration UnifiedMetric et CustomCodeExecutionSpec. Le paramètre remote_custom_function est une chaîne contenant le code Python de la fonction. La fonction doit être nommée evaluate :
def evaluate(
instance: dict
) -> float:
...
Nous avons créé l'assistant get_custom_function_metric (dans shared/evaluation/evaluate.py) qui convertit une fonction Python en métrique d'évaluation de code personnalisé.
Il obtient le code du module de la fonction (pour capturer les dépendances locales), crée une fonction evaluate supplémentaire qui appelle la fonction d'origine et renvoie un objet EvaluationRunMetric avec un CustomCodeExecutionSpec.
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
Le service d'évaluation de l'IA générative exécutera ce code dans un environnement d'exécution de bac à sable et lui transmettra les données d'évaluation.
Ajouter les métriques et le code d'évaluation
Ajoutez le code suivant à evaluator/evaluate_agent.py après la ligne if __name__ == "__main__":.
Il définit la liste des métriques pour l'agent Researcher et exécute l'évaluation.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
Dans un véritable pipeline de production, vous avez besoin de critères de réussite de l'évaluation. Une fois l'évaluation terminée et les métriques disponibles. Vous aurez une étape de gating ici. Par exemple : "Si le score Final Response Match est inférieur à 0,75, l'opération de compilation échoue." Cela empêche les mauvaises révisions de recevoir du trafic.
Ajoutez le code suivant à evaluator/evaluate_agent.py :
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
Chaque fois que la valeur moyenne de l'une des métriques d'évaluation est inférieure à un seuil (0.75), le déploiement doit échouer.
[Facultatif] Ajouter une évaluation avec des métriques sans référence pour l'orchestrateur
Pour l'agent Orchestrator, les interactions sont plus complexes et il n'y a pas toujours une seule réponse "correcte". Nous évaluons plutôt le comportement général à l'aide de l'une des métriques sans référence.
- Hallucination : métrique basée sur un score qui vérifie la factualité et la cohérence des réponses textuelles en segmentant la réponse en affirmations atomiques. Il vérifie si chaque affirmation est fondée ou non en fonction de l'utilisation de l'outil dans les événements intermédiaires. C'est essentiel pour les agents ouverts, où la "justesse" est subjective, mais la "véracité" est non négociable. Le score est calculé en pourcentage des affirmations ancrées dans le contenu source. Dans notre cas, nous nous attendons à ce que la réponse finale de l'orchestrateur (produite par Content Builder) soit factuellement ancrée dans le contenu récupéré par Researcher à l'aide de l'outil de recherche Wikipédia.
Ajoutez la logique d'évaluation pour l'orchestrateur :
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
Inspecter les données d'évaluation
Ouvrez le répertoire evaluator/. Deux fichiers de données s'affichent :
eval_data_researcher.json: requêtes et références clés/de vérité terrain pour le chercheur.eval_data_orchestrator.json: requêtes pour l'outil d'orchestration (nous n'effectuons que des évaluations sans référence pour l'outil d'orchestration).
Chaque entrée contient généralement les éléments suivants :
prompt: le prompt pour l'agent.reference: réponse idéale (vérité de référence), le cas échéant.reference_trajectory: séquence attendue d'appels d'outils.
6. Comprendre le code d'évaluation
Ouvrez shared/evaluation/evaluate.py. Ce module contient la logique principale pour exécuter les évaluations. La fonction clé est evaluate_agent.
Il effectue les étapes suivantes :
- Chargement des données : lit l'ensemble de données d'évaluation (requêtes et références) à partir d'un fichier.
- Inférence parallèle : exécute l'agent sur l'ensemble de données en parallèle. Il gère la création de sessions, envoie des requêtes et capture à la fois la réponse finale et la trace d'exécution des outils intermédiaires.
- Vertex AI Evaluation : fusionne les données d'évaluation d'origine avec les réponses finales et la trace d'exécution de l'outil intermédiaire, puis envoie les résultats à Vertex AI Evaluation Service avec le client GenAI dans le SDK Vertex AI. Ce service exécute les métriques configurées pour évaluer les performances de l'agent.
Le moment clé de la dernière étape consiste à appeler la fonction create_evaluation_run du module d'évaluation du SDK Gen AI :
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
Pour ce faire, nous utilisons la fonction evaluate_agent dans shared/evaluation/evaluate.py.
Il obtient l'ensemble de données d'évaluation fusionné, les informations sur l'agent, les métriques à utiliser et l'URI de stockage de destination. La fonction crée une exécution d'évaluation dans le service d'évaluation Vertex AI et renvoie l'objet d'exécution d'évaluation.
API Agent Info
Pour effectuer une évaluation précise, le service d'évaluation doit connaître la configuration de l'agent (instructions système, description et outils disponibles). Nous le transmettons à create_evaluation_run en tant que paramètre agent_info.
Mais comment obtenir ces informations ? Nous l'intégrons à l'API ADK Service.
Ouvrez shared/adk_app.py et recherchez def agent_info. Vous verrez que l'application ADK expose un point de terminaison d'assistance :
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
Ce point de terminaison (activé par le flag --publish_agent_info) permet au script d'évaluation d'extraire dynamiquement la configuration d'exécution de l'agent. C'est essentiel pour les métriques qui évaluent l'utilisation des outils, car le modèle de juge peut mieux évaluer l'utilisation des outils par l'agent s'il sait précisément quels outils étaient à sa disposition pendant la conversation.
7. Exécuter l'évaluation
Maintenant que vous avez implémenté l'évaluateur, exécutons-le !
- Exécutez le script d'évaluation à partir de la racine du dépôt :
./evaluate.sh- Il récupère le hachage de commit Git actuel.
- Il appelle
deploy.shpour déployer une révision avec un tag basé sur le hachage de commit. - Une fois déployé, il démarre
evaluator.evaluate_agent. - Des barres de progression s'affichent pendant l'exécution des cas de test sur votre service cloud.
- Enfin, il affiche un résumé JSON des résultats.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Remarque : La première exécution peut prendre quelques minutes pour déployer les services.
8. Visualiser les résultats dans un notebook
La sortie JSON brute est difficile à lire. Le client Gen AI du SDK Vertex AI permet de suivre ces exécutions au fil du temps. Nous allons utiliser un notebook Colab pour visualiser les résultats.
- Ouvrez
evaluator/show_evaluation_run.ipynbdans Google Colab en cliquant sur ce lien. - Définissez les variables
GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGIONetEVAL_RUN_IDsur l'ID de votre projet, votre région et l'ID de votre exécution.
- Installez les dépendances et authentifiez-vous.
Récupérer l'exécution de l'évaluation et afficher les résultats
Nous devons récupérer les données d'exécution de l'évaluation depuis Vertex AI. Recherchez la cellule sous Récupérer l'exécution de l'évaluation et afficher les résultats, puis remplacez la ligne # TODO par le bloc de code suivant :
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
Interpréter les résultats
Lorsque vous examinez les résultats, tenez compte des points suivants :
- Régression vs capacité :
- Régression : le score a-t-il baissé lors des anciens tests ? (Mauvais, nécessite une investigation)
- Capacité : le score s'est-il amélioré lors des nouveaux tests ? (Bien, vous progressez.)
- Analyse des échecs : ne vous contentez pas de regarder le score.
- Examinez la trace. A-t-il appelé le mauvais outil ? L'analyse de la sortie a-t-elle échoué ? C'est là que vous trouverez les bugs.
- Examinez l'explication et les verdicts fournis par le LLM juge. Ils vous donnent souvent une bonne idée de la raison de l'échec du test.
Pass@1 vs Pass@k : lorsque vous exécutez un test donné une seule fois, vous obtenez un score Pass@1. Si un agent échoue, cela peut être dû au non-déterminisme. Dans les configurations sophistiquées, vous pouvez exécuter chaque test k fois (par exemple, cinq fois) et calculer pass@k (a-t-il réussi au moins une fois ?) ou pass^k (a-t-il réussi à chaque fois ?). C'est ce que font déjà de nombreuses métriques en arrière-plan. Par exemple, types.RubricMetric.FINAL_RESPONSE_MATCH (Correspondance de la réponse finale) effectue cinq appels au LLM évaluateur pour déterminer le score de correspondance de la réponse finale.
9. Intégration et déploiement continus (CI/CD)
Dans un système de production, l'évaluation de l'agent doit être exécutée dans le cadre du pipeline CI/CD. Cloud Build est un bon choix pour cela.
Pour chaque commit envoyé au dépôt de code de l'agent, l'évaluation s'exécute avec le reste des tests. Si le déploiement réussit, il peut être "promu" pour répondre aux requêtes des utilisateurs. En cas d'échec, rien ne change, mais le développeur peut examiner ce qui n'a pas fonctionné.
Configuration Cloud Build
À présent, créons un script de configuration de déploiement Cloud Run qui effectue les étapes suivantes :
- Déploie des services dans une révision privée.
- Exécute l'évaluation de l'agent.
- Si l'évaluation est réussie, elle "propose" les déploiements de révision pour diffuser 100% du trafic.
Créez cloudbuild.yaml :
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
Exécuter le pipeline
Enfin, nous pouvons exécuter le pipeline d'évaluation.
Avant d'exécuter le pipeline d'évaluation qui envoie des requêtes aux services Cloud Run, nous avons besoin d'un compte de service distinct avec plusieurs autorisations. Écrivons un script qui effectue cette opération et lance le pipeline.
- Créez un script
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- Crée un compte de service dédié
agent-eval-build-sa. - Attribuez-lui les rôles nécessaires (
roles/run.admin,roles/aiplatform.user, etc.). *. Envoie la compilation à Cloud Build.
- Crée un compte de service dédié
- Exécutez le pipeline :
chmod +x run_cloud_build.sh ./run_cloud_build.sh
Vous pouvez suivre la progression de la compilation dans le terminal ou cliquer sur le lien vers la console Cloud.
Remarque : Dans un environnement de production réel, vous configurerez un déclencheur Cloud Build pour exécuter cette opération automatiquement à chaque git push. Le workflow est le même : le déclencheur exécuterait cloudbuild.yaml, ce qui garantit que chaque commit est évalué.
10. Résumé
Vous avez créé un pipeline d'évaluation.
- Déploiement : vous avez utilisé des tags de révision avec le hachage de commit Git pour déployer des agents en toute sécurité dans un environnement réel à des fins de test, sans affecter les déploiements de production.
- Évaluation : vous avez défini des métriques d'évaluation et automatisé le processus d'évaluation à l'aide de Vertex AI Gen AI Evaluation Service.
- Analyse : vous avez utilisé un notebook Colab pour visualiser les résultats de l'évaluation et améliorer votre agent.
- Déploiement : vous avez utilisé Cloud Build pour exécuter automatiquement le pipeline d'évaluation et promouvoir la meilleure révision afin qu'elle diffuse 100% du trafic.
Ce cycle Modifier le code > Déployer le tag > Exécuter l'évaluation et les tests > Analyser > Déployer > Répéter est au cœur de l'ingénierie agentique de qualité production.