
1. परिचय
खास जानकारी
यह लैब, ADK की मदद से मल्टी-एजेंट सिस्टम बनाना लैब का फ़ॉलो-अप है.
उस लैब में, आपने कोर्स बनाने का एक सिस्टम तैयार किया था. इसमें ये शामिल थे:
- रिसर्चर एजेंट: ताज़ा जानकारी पाने के लिए, google_search का इस्तेमाल करना.
- जज एजेंट: रिसर्च की क्वालिटी और पूरी जानकारी के लिए उसकी आलोचना करना.
- कॉन्टेंट बिल्डर एजेंट: रिसर्च को व्यवस्थित कोर्स में बदलना.
- ऑर्केस्ट्रेटर एजेंट: यह एजेंट, वर्कफ़्लो और इन विशेषज्ञों के बीच बातचीत को मैनेज करता है.
इसमें एक वेब ऐप्लिकेशन भी शामिल था. इसकी मदद से, उपयोगकर्ता कोर्स बनाने का अनुरोध सबमिट कर सकते थे और उन्हें जवाब के तौर पर कोर्स मिल जाता था.
रिसर्चर, जज, और कॉन्टेंट बिल्डर को अलग-अलग Cloud Run सेवाओं में A2A एजेंट के तौर पर डिप्लॉय किया जाता है. Orchestrator, ADK Service API के साथ काम करने वाली एक और Cloud Run सेवा है.
इस लैब के लिए, हमने रिसर्चर एजेंट में बदलाव किया है, ताकि वह Gemini की Google Search सुविधा के बजाय Wikipedia Search टूल का इस्तेमाल कर सके. इससे हमें यह देखने में मदद मिलती है कि कस्टम टूल कॉल को कैसे ट्रैक और उनका आकलन किया जाता है.
इसलिए, हमने डिस्ट्रिब्यूट किया गया मल्टी-एजेंट सिस्टम बनाया है. हालांकि, हमें कैसे पता चलेगा कि यह वाकई अच्छी तरह से काम कर रहा है? क्या रिसर्चर को हमेशा काम की जानकारी मिलती है? क्या जज ने खराब रिसर्च की पहचान सही तरीके से की है?
इस लैब में, Vertex AI Gen AI Evaluation Service का इस्तेमाल करके, डेटा के आधार पर आकलन करने के बारे में बताया गया है. आपको Lab 1 में बनाए गए डिसट्रीब्यूटेड मल्टी-एजेंट सिस्टम का आकलन करने के लिए, अडैप्टिव रूब्रिक और टूल इस्तेमाल करने की क्वालिटी से जुड़ी मेट्रिक लागू करनी होंगी. आखिर में, इस प्रोसेस को सीआई/सीडी पाइपलाइन में ऑटोमेट किया जाएगा. इससे यह पक्का किया जा सकेगा कि हर डिप्लॉयमेंट, आपके प्रोडक्शन एजेंट की भरोसेमंदता और सटीकता को बनाए रखे.
आपको अपने एजेंट के लिए, लगातार होने वाली इवैलुएशन की पाइपलाइन बनानी होगी. आपको इनके बारे में जानकारी मिलेगी:
- अपने एजेंट को Google Cloud Run में, टैग किए गए प्राइवेट वर्शन पर डिप्लॉय करें (शैडो डिप्लॉयमेंट).
- Vertex AI Gen AI Evaluation Service का इस्तेमाल करके, उस खास वर्शन के लिए अपने-आप होने वाली जांच की सुविधा चालू करें.
- नतीजों को विज़ुअलाइज़ करना और उनका विश्लेषण करना.
- जांच के नतीजों का इस्तेमाल, CI/CD पाइपलाइन के हिस्से के तौर पर करें.
2. मुख्य सिद्धांत: एजेंट के परफ़ॉर्मेंस का आकलन करने की थ्योरी
एआई एजेंट डेवलप और रन करते समय, हम दो तरह के आकलन करते हैं: ऑफ़लाइन एक्सपेरिमेंट और ऑटोमेटेड रिग्रेशन टेस्टिंग के साथ लगातार आकलन. पहला, डेवलपमेंट प्रोसेस का क्रिएटिव इंजन है. इसमें हम ऐड-हॉक एक्सपेरिमेंट करते हैं, प्रॉम्प्ट को बेहतर बनाते हैं, और नई सुविधाओं को अनलॉक करने के लिए तेज़ी से दोहराते हैं. दूसरा, हमारी CI/CD पाइपलाइन में डिफ़ेंसिव लेयर होती है. इसमें हम "गोल्डन" डेटासेट के ख़िलाफ़ लगातार आकलन करते हैं. इससे यह पक्का किया जाता है कि कोड में किसी भी बदलाव की वजह से, एजेंट की क्वालिटी में कोई गिरावट न आए.
इन दोनों के बीच मुख्य अंतर, खोज और सुरक्षा में है:
- ऑफ़लाइन एक्सपेरिमेंटेशन, ऑप्टिमाइज़ेशन की एक प्रोसेस है. यह ओपन-एंडेड और वैरिएबल है. स्कोर को ज़्यादा से ज़्यादा करने या किसी समस्या को हल करने के लिए, इनपुट (प्रॉम्प्ट, मॉडल, पैरामीटर) में लगातार बदलाव किया जा रहा हो. इसका मकसद, एजेंट की क्षमताओं को बढ़ाना है.
- लगातार आकलन (अपने-आप होने वाली रिग्रेशन टेस्टिंग), पुष्टि करने की एक प्रोसेस है. यह एक जैसा और दोहराव वाला है. इनपुट को स्थिर रखा जाता है ("गोल्डन" डेटासेट), ताकि आउटपुट स्थिर रहें. इसका मकसद, परफ़ॉर्मेंस को "फ़्लोर" से नीचे गिरने से रोकना है.
इस लैब में, हम लगातार होने वाले इवैलुएशन पर फ़ोकस करेंगे. हम एक ऑटोमेटेड रिग्रेशन टेस्टिंग पाइपलाइन तैयार करेंगे. यह पाइपलाइन, यूनिट टेस्ट की तरह ही हर बार तब चलेगी, जब कोई व्यक्ति एआई एजेंट में बदलाव करेगा.
कोड लिखने से पहले, यह समझना ज़रूरी है कि हम क्या मेज़र कर रहे हैं.
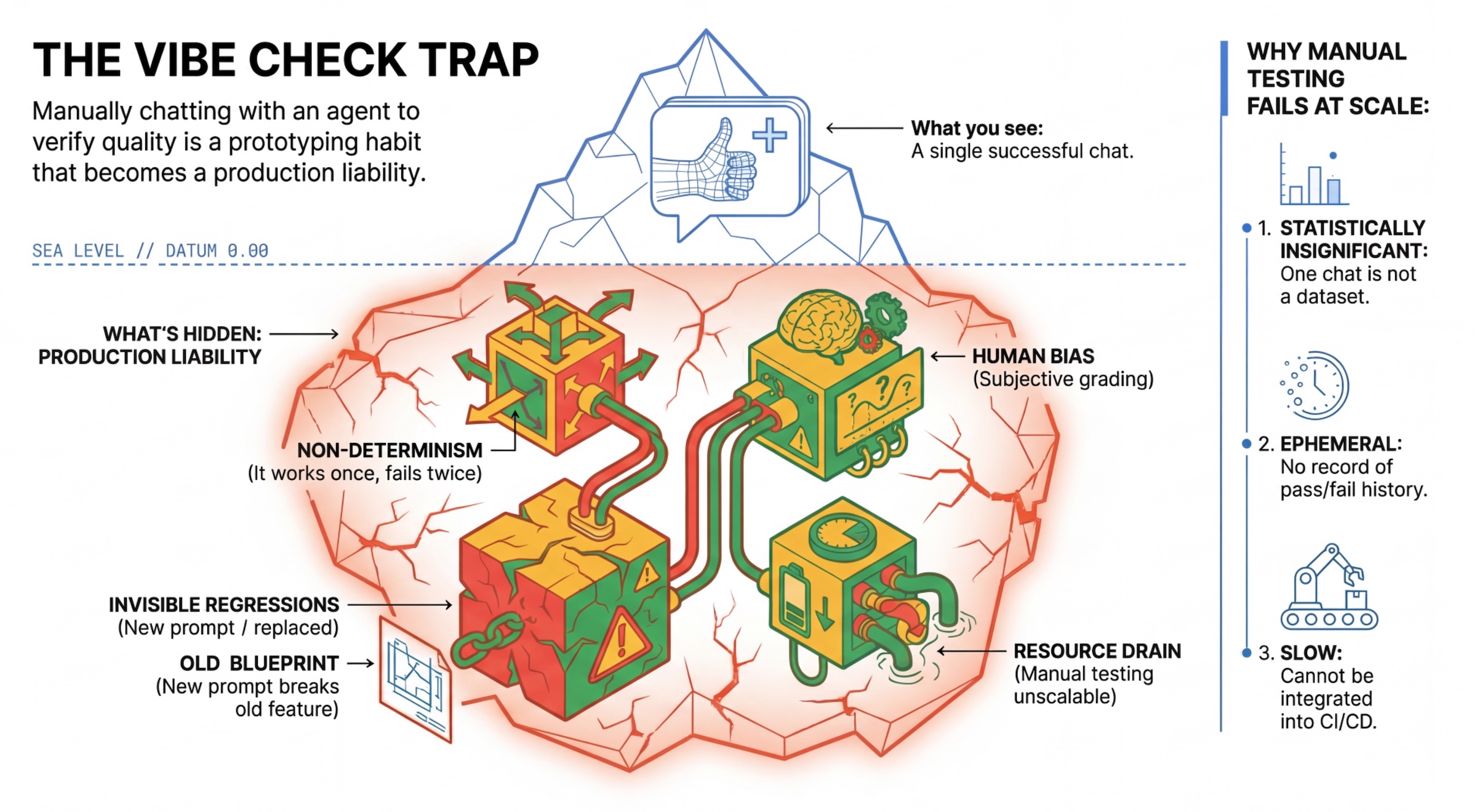
"वाइब चेक" ट्रैप
कई डेवलपर, एजेंटों के साथ मैन्युअल तरीके से चैट करके उनकी जांच करते हैं. इसे "वाइब चेकिंग" कहा जाता है. प्रोटोटाइपिंग के लिए यह तरीका काम का है. हालांकि, प्रोडक्शन में यह काम नहीं करता, क्योंकि:
- नॉन-डिटरमिनिज़्म: एजेंट हर बार अलग-अलग जवाब दे सकते हैं. आपको आंकड़ों के हिसाब से ज़रूरी सैंपल साइज़ की ज़रूरत होती है.
- अचानक होने वाले बदलाव: किसी एक प्रॉम्प्ट को बेहतर बनाने से, इस्तेमाल का कोई दूसरा उदाहरण काम करना बंद कर सकता है.
- लोगों की सोच के आधार पर फ़ैसले लेना: "यह अच्छा लग रहा है" की परिभाषा हर विषय के लिए अलग होती है.
- ज़्यादा समय लगने वाला काम: हर कमिट के साथ, मैन्युअल तरीके से कई स्थितियों की जांच करने में समय लगता है.
एजेंट की परफ़ॉर्मेंस को ग्रेड देने के दो तरीके
बेहतर पाइपलाइन बनाने के लिए, हम अलग-अलग तरह के ग्रेडर का इस्तेमाल करते हैं:
- कोड के आधार पर ग्रेड देने वाले सिस्टम (डिटरमिनिस्टिक):
- ये क्या मेज़र करते हैं: सख्त शर्तें (जैसे, "क्या इसने मान्य JSON दिखाया?", "क्या इसने
searchटूल को कॉल किया?"). - फ़ायदे: तेज़, सस्ता, और 100% सटीक.
- कमियां: इससे बारीकियों या क्वालिटी का पता नहीं चलता.
- ये क्या मेज़र करते हैं: सख्त शर्तें (जैसे, "क्या इसने मान्य JSON दिखाया?", "क्या इसने
- मॉडल पर आधारित ग्रेडर (संभावित):
- इसे "एलएलएम-एज़-अ-जज" के नाम से भी जाना जाता है. हम एजेंट के आउटपुट का आकलन करने के लिए, Gemini 3 Pro जैसे बेहतर मॉडल का इस्तेमाल करते हैं.
- ये किस आधार पर जवाब का आकलन करते हैं: बारीकी, तर्क, मददगार होना, और सुरक्षित होना.
- फ़ायदे: यह मुश्किल और ओपन-एंडेड टास्क का आकलन कर सकता है.
- नुकसान: यह तरीका धीमा और महंगा है. साथ ही, जज के लिए प्रॉम्प्ट इंजीनियरिंग की ज़रूरत होती है.
Vertex AI की परफ़ॉर्मेंस का आकलन करने वाली मेट्रिक
इस लैब में, हम Vertex AI Gen AI Evaluation Service का इस्तेमाल करते हैं. यह सेवा, मैनेज की गई मेट्रिक उपलब्ध कराती है, ताकि आपको हर जज को शुरू से न लिखना पड़े.
एजेंट के परफ़ॉर्मेंस का आकलन करने के लिए, मेट्रिक को ग्रुप करने के कई तरीके हैं:
- रूब्रिक के आधार पर मेट्रिक: एलएलएम को आकलन के वर्कफ़्लो में शामिल करें.
- अडैप्टिव रूब्रिक: हर प्रॉम्प्ट के लिए, रूब्रिक डाइनैमिक तौर पर जनरेट किए जाते हैं. जवाबों का आकलन, पास या फ़ेल होने के बारे में ज़्यादा जानकारी देने वाले फ़ीडबैक के आधार पर किया जाता है. यह फ़ीडबैक, प्रॉम्प्ट के हिसाब से दिया जाता है.
- स्टैटिक रूब्रिक: रूब्रिक साफ़ तौर पर तय किए जाते हैं और सभी प्रॉम्प्ट पर एक ही रूब्रिक लागू होता है. जवाबों का आकलन, स्कोरिंग पर आधारित आकलन करने वालों के एक ही सेट से किया जाता है. हर प्रॉम्प्ट के लिए, एक संख्यात्मक स्कोर (जैसे कि 1 से 5 तक). जब किसी खास डाइमेंशन के आधार पर आकलन करना हो या जब सभी प्रॉम्प्ट के लिए एक ही रूब्रिक की ज़रूरत हो.
- कैलकुलेशन पर आधारित मेट्रिक: डिटरमिनिस्टिक एल्गोरिदम का इस्तेमाल करके जवाबों का आकलन करें. आम तौर पर, इसमें ग्राउंड ट्रुथ का इस्तेमाल किया जाता है. हर प्रॉम्प्ट के लिए, संख्यात्मक स्कोर (जैसे कि 0.0-1.0). जब ज़मीनी हकीकत उपलब्ध हो और उसे किसी तय तरीके से मैच किया जा सकता हो.
- कस्टम फ़ंक्शन मेट्रिक: Python फ़ंक्शन के ज़रिए अपनी मेट्रिक तय करें.
हम इन मेट्रिक का इस्तेमाल करेंगे:
Final Response Match: (रेफ़रंस के आधार पर) क्या जवाब, हमारे "गोल्डन आंसर" से मेल खाता है?Tool Use Quality: (बिना रेफ़रंस के) क्या एजेंट ने सही टूल का सही तरीके से इस्तेमाल किया?Hallucination: (बिना किसी संदर्भ के) क्या जवाब में किए गए दावों के लिए, खोजे गए कॉन्टेक्स्ट में मौजूद जानकारी का इस्तेमाल किया गया है?Tool Trajectory PrecisionऔरTool Trajectory Recall(रेफ़रंस पर आधारित) क्या एजेंट ने सही टूल चुना और मान्य तर्क दिए?Tool Use Qualityके उलट, ये कस्टम मेट्रिक रेफ़रंस ट्रैजेक्ट्री का इस्तेमाल करती हैं. यह टूल कॉल और आर्ग्युमेंट का एक क्रम होता है.
3. सेटअप
कॉन्फ़िगरेशन
- Cloud Shell खोलें: Google Cloud Console में सबसे ऊपर दाईं ओर मौजूद, Cloud Shell चालू करें आइकॉन पर क्लिक करें.
- साइन इन करने की प्रोसेस को रीफ़्रेश करने और ऐप्लिकेशन के डिफ़ॉल्ट क्रेडेंशियल (एडीसी) को अपडेट करने के लिए, यह कमांड चलाएं:
gcloud auth login --update-adc - gcloud CLI के लिए कोई एक्टिव प्रोजेक्ट सेट करें.gcloud के मौजूदा प्रोजेक्ट की जानकारी पाने के लिए, यह कमांड चलाएं:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDकी जगह अपने प्रोजेक्ट का आईडी डालें. - वह डिफ़ॉल्ट क्षेत्र सेट करें जहां आपकी Cloud Run सेवाओं को डिप्लॉय किया जाएगा.
gcloud config set run/region us-west1us-west1के बजाय, अपने आस-पास के किसी भी Cloud Run क्षेत्र का इस्तेमाल किया जा सकता है.
कोड और डिपेंडेंसी
- स्टार्टर कोड को क्लोन करें और डायरेक्ट्री को प्रोजेक्ट के रूट में बदलें.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab .envफ़ाइल बनाएं:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env- टर्मिनल विंडो में यह कमांड चलाकर, ज़रूरी सॉफ़्टवेयर इंस्टॉल करें:
uv sync
4. सुरक्षित तरीके से डिप्लॉयमेंट करने के बारे में जानकारी
हमारा आकलन करने से पहले, हमें डिप्लॉय करना होगा. हालांकि, अगर हमारा नया कोड सही नहीं है, तो हम लाइव ऐप्लिकेशन को बंद नहीं करना चाहते.
टैग में बदलाव करना और शैडो डिप्लॉयमेंट
Google Cloud Run, Revisions के साथ काम करता है. हर बार डिप्लॉय करने पर, एक नया अपरिवर्तनीय वर्शन बनाया जाता है. इन वर्शन को टैग असाइन किए जा सकते हैं, ताकि किसी खास यूआरएल के ज़रिए इन्हें ऐक्सेस किया जा सके. भले ही, इन्हें सार्वजनिक ट्रैफ़िक का 0% हिस्सा मिल रहा हो.
सिर्फ़ स्थानीय तौर पर आकलन क्यों नहीं किए जाते?
ADK, लोकल इवैलुएशन की सुविधा देता है. हालांकि, छिपे हुए वर्शन को डिप्लॉय करने से, प्रोडक्शन सिस्टम को अहम फ़ायदे मिलते हैं. इससे सिस्टम-लेवल के आकलन (हम क्या कर रहे हैं) और यूनिट टेस्टिंग के बीच अंतर पता चलता है:
- एनवायरमेंट पैरिटी: लोकल एनवायरमेंट अलग-अलग होते हैं (अलग नेटवर्क, अलग सीपीयू/मेमोरी, अलग सीक्रेट). क्लाउड में टेस्टिंग करने से यह पक्का होता है कि आपका एजेंट, असल रनटाइम एनवायरमेंट (सिस्टम टेस्ट) में काम करता है.
- मल्टी-एजेंट इंटरैक्शन: डिस्ट्रिब्यूटेड सिस्टम में, एजेंट एचटीटीपी पर बातचीत करते हैं. "लोकल" टेस्ट में अक्सर इन कनेक्शन का मज़ाक उड़ाया जाता है. शैडो डिप्लॉयमेंट से, आपकी माइक्रोसेवाओं के बीच असल नेटवर्क कम्यूनिकेशन में होने वाली देरी, टाइमआउट कॉन्फ़िगरेशन, और पुष्टि की जांच की जाती है.
- सीक्रेट और अनुमतियां: यह पुष्टि करता है कि आपके सेवा खाते के पास वे अनुमतियां हैं जिनकी उसे ज़रूरत है. उदाहरण के लिए, Vertex AI को कॉल करने या Firestore से डेटा पढ़ने की अनुमति.
ध्यान दें: यह पहले से ही जांच करने की सुविधा है. इसका मतलब है कि उपयोगकर्ताओं को कॉन्टेंट दिखने से पहले ही उसकी जांच कर ली जाती है. इसे डिप्लॉय करने के बाद, रीऐक्टिव मॉनिटरिंग (ऑब्ज़र्वेबिलिटी) का इस्तेमाल करके, समस्याओं का पता लगाया जा सकता है.
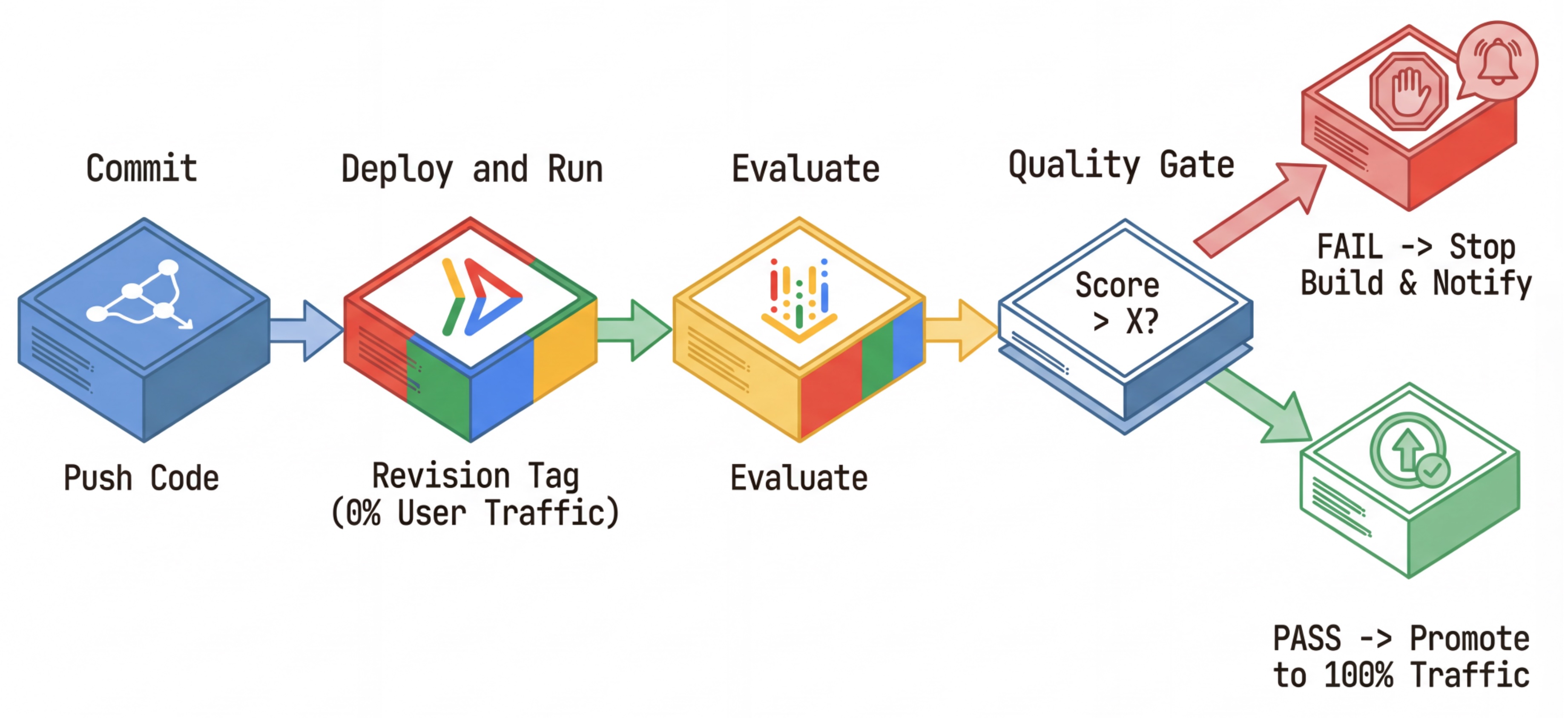
सीआई/सीडी वर्कफ़्लो: डिप्लॉय करना, आकलन करना, और प्रमोट करना
हम इसका इस्तेमाल, लगातार डिप्लॉयमेंट की मज़बूत पाइपलाइन के लिए करते हैं:
- कमिट करें: एजेंट के प्रॉम्प्ट में बदलाव करें और उसे रिपॉज़िटरी में पुश करें.
- डिप्लॉय (छिपा हुआ): यह कमिट हैश (जैसे,
c-abc1234) के साथ टैग किए गए नए वर्शन को डिप्लॉय करने की प्रोसेस को ट्रिगर करता है. इस वर्शन को 0% सार्वजनिक ट्रैफ़िक मिलता है. - आकलन करें: आकलन करने वाली स्क्रिप्ट, खास तौर पर यूआरएल
https://c-abc1234---researcher-xyz.run.appके वर्शन को टारगेट करती है. - प्रमोट करें: अगर (और सिर्फ़ अगर) आकलन पास हो जाता है और अन्य टेस्ट सफल हो जाते हैं, तो इस नए वर्शन पर ट्रैफ़िक माइग्रेट करें.
- रोलबैक: अगर रोलबैक नहीं होता है, तो उपयोगकर्ताओं को कभी भी खराब वर्शन नहीं दिखेगा. साथ ही, आपके पास खराब वर्शन को अनदेखा करने या मिटाने का विकल्प होगा.
इस रणनीति की मदद से, ग्राहकों पर असर डाले बिना प्रोडक्शन में टेस्ट किया जा सकता है.
evaluate.sh का विश्लेषण करें
evaluate.sh खोलें. यह स्क्रिप्ट, प्रोसेस को अपने-आप पूरा करती है.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
deploy.sh, --no-traffic और --tag विकल्पों की मदद से, वर्शन को डिप्लॉय करने की प्रोसेस को मैनेज करता है. अगर कोई सेवा पहले से चल रही है, तो उस पर इसका असर नहीं पड़ेगा. "छिपा हुआ" नया वर्शन तब तक कोई ट्रैफ़िक नहीं पाएगा, जब तक कि आप उसे खास यूआरएल के साथ कॉल नहीं करते. इस यूआरएल में वर्शन टैग (जैसे, https://c-abc1234---researcher-xyz.run.app) शामिल होता है
5. इवैलुएशन स्क्रिप्ट लागू करना
अब, हम ऐसा कोड लिखेंगे जो असल में टेस्ट चलाता है.
evaluator/evaluate_agent.pyखोलें.- आपको इंपोर्ट और सेटअप दिखेगा, लेकिन मेट्रिक और एक्ज़ीक्यूशन लॉजिक नहीं दिखेगा.
मेट्रिक तय करना
रिसर्चर एजेंट के लिए, हमारे पास "गोल्डन आंसर"/"ग्राउंड ट्रुथ" के साथ-साथ अनुमानित जवाब भी हैं. यह क्षमता का आकलन है: हम यह मेज़र कर रहे हैं कि एजेंट, काम को सही तरीके से कर सकता है या नहीं.
हमें इन चीज़ों को मेज़र करना है:
- फ़ाइनल जवाब का मेल खाना: (क्षमता) क्या जवाब, अनुमानित जवाब से मेल खाता है? यह रेफ़रंस पर आधारित मेट्रिक है. यह जज एलएलएम का इस्तेमाल करके, एजेंट के आउटपुट की तुलना अनुमानित जवाब से करता है. यह ज़रूरी नहीं है कि जवाब बिलकुल एक जैसा हो. हालांकि, यह ज़रूरी है कि जवाब का मतलब और उसमें दिए गए तथ्य मिलते-जुलते हों.
- टूल इस्तेमाल करने की क्वालिटी: (क्वालिटी) यह अडैप्टिव रूब्रिक मेट्रिक है. यह सही टूल चुनने, पैरामीटर का सही तरीके से इस्तेमाल करने, और तय किए गए क्रम में कार्रवाइयां करने का आकलन करती है.
- टूल इस्तेमाल करने का तरीका: (ट्रेस) दो कस्टम मेट्रिक, जो अनुमानित तरीकों के मुकाबले एजेंट के टूल इस्तेमाल करने के तरीके (सटीकता और रिकॉल) को मेज़र करती हैं. इन मेट्रिक को
shared/evaluation/tool_metrics.pyमें कस्टम फ़ंक्शन के तौर पर लागू किया जाता है. टूल इस्तेमाल करने की क्वालिटी से अलग, यह मेट्रिक रेफ़रंस पर आधारित मेट्रिक है. इसमें यह देखा जाता है कि टूल कॉल, रेफ़रंस डेटा (आकलन के डेटा मेंreference_trajectory) से मेल खाते हैं या नहीं.
कस्टम टूल के इस्तेमाल की ट्रैजेक्ट्री मेट्रिक
कस्टम टूल इस्तेमाल करने की ट्रैजेक्ट्री मेट्रिक के लिए, हमने shared/evaluation/tool_metrics.py में Python फ़ंक्शन का एक सेट बनाया है. Vertex AI Gen AI Evaluation Service को इन फ़ंक्शन को लागू करने की अनुमति देने के लिए, हमें Python कोड को पास करना होगा.
इसके लिए, UnifiedMetric और CustomCodeExecutionSpec कॉन्फ़िगरेशन के साथ EvaluationRunMetric ऑब्जेक्ट को तय किया जाता है. पैरामीटर remote_custom_function एक स्ट्रिंग है, जिसमें फ़ंक्शन का Python कोड शामिल होता है. फ़ंक्शन का नाम evaluate होना चाहिए:
def evaluate(
instance: dict
) -> float:
...
हमने get_custom_function_metric हेल्पर (shared/evaluation/evaluate.py में) बनाया है. यह Python फ़ंक्शन को कस्टम कोड के आकलन की मेट्रिक में बदलता है.
यह फ़ंक्शन के मॉड्यूल का कोड (स्थानीय डिपेंडेंसी कैप्चर करने के लिए) पाता है. साथ ही, एक अतिरिक्त evaluate फ़ंक्शन बनाता है, जो ओरिजनल फ़ंक्शन को कॉल करता है. इसके बाद, यह CustomCodeExecutionSpec के साथ EvaluationRunMetric ऑब्जेक्ट दिखाता है.
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
Gen AI Evaluation Service, उस कोड को सैंडबॉक्स एक्ज़ीक्यूशन एनवायरमेंट में चलाएगी. साथ ही, इसमें आकलन का डेटा पास करेगी.
मेट्रिक और आकलन कोड जोड़ना
evaluator/evaluate_agent.py लाइन के बाद, evaluator/evaluate_agent.py में यह कोड जोड़ें.if __name__ == "__main__":
यह रिसर्चर एजेंट के लिए मेट्रिक की सूची तय करता है और आकलन करता है.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
असल प्रोडक्शन पाइपलाइन में, आपको आकलन के लिए सफलता के मानदंड की ज़रूरत होती है. समीक्षा पूरी होने और मेट्रिक तैयार होने के बाद. यहां आपको Gating Step दिखेगा. उदाहरण के लिए: "अगर Final Response Match स्कोर 0.75 से कम है, तो बिल्ड को फ़ेल करें." इससे खराब वर्शन को कभी ट्रैफ़िक नहीं मिलता.
evaluator/evaluate_agent.py में यह कोड जोड़ें:
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
जब भी किसी भी आकलन मेट्रिक की mean वैल्यू, थ्रेशोल्ड (0.75) से कम हो, तो डिप्लॉयमेंट पूरा नहीं होना चाहिए.
[ज़रूरी नहीं] ऑर्केस्ट्रेटर के लिए, बिना रेफ़रंस वाली मेट्रिक का इस्तेमाल करके आकलन जोड़ना
ऑर्केस्ट्रेटर एजेंट के लिए, इंटरैक्शन ज़्यादा मुश्किल होते हैं. इसलिए, ऐसा हो सकता है कि हमारे पास हमेशा एक "सही" जवाब न हो. इसके बजाय, हम रेफ़रंस-फ़्री मेट्रिक में से किसी एक का इस्तेमाल करके, सामान्य व्यवहार का आकलन करते हैं.
- भरोसेमंद स्रोतों से जानकारी न लेना: यह स्कोर के आधार पर तय होने वाली मेट्रिक है. यह जवाब में दिए गए तथ्यों के सही होने और जवाब के एक जैसा होने की जांच करती है. इसके लिए, जवाब को छोटे-छोटे दावों में बांटा जाता है. यह पुष्टि करता है कि इंटरमीडिएट इवेंट में टूल के इस्तेमाल के आधार पर, हर दावे की पुष्टि हुई है या नहीं. यह ओपन-एंडेड एजेंट के लिए ज़रूरी है. इनमें "सही जानकारी" देना ज़रूरी नहीं होता, लेकिन "भरोसेमंद जानकारी" देना ज़रूरी होता है. स्कोर का हिसाब, सोर्स कॉन्टेंट में मौजूद जानकारी के आधार पर किए गए दावों के प्रतिशत के तौर पर लगाया जाता है. हमारे मामले में, हम उम्मीद करते हैं कि Orchestrator (जिसे Content Builder ने बनाया है) से मिला जवाब, तथ्यों के हिसाब से सही हो. साथ ही, यह उस कॉन्टेंट पर आधारित हो जिसे Researcher ने Wikipedia Search टूल का इस्तेमाल करके खोजा है.
ऑर्केस्ट्रेटर के लिए आकलन का लॉजिक जोड़ें:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
इवैलुएशन डेटा की जांच करना
evaluator/ डायरेक्ट्री खोलें. आपको दो डेटा फ़ाइलें दिखेंगी:
eval_data_researcher.json: रिसर्चर के लिए प्रॉम्प्ट और गोल्डन/ग्राउंड-ट्रुथ रेफ़रंस.eval_data_orchestrator.json: Orchestrator के लिए प्रॉम्प्ट (हम Orchestrator के लिए, सिर्फ़ बिना किसी रेफ़रंस के आकलन करते हैं).
हर एंट्री में आम तौर पर यह जानकारी शामिल होती है:
prompt: एजेंट के लिए प्रॉम्प्ट.reference: अगर लागू हो, तो सही जवाब (ग्राउंड ट्रुथ).reference_trajectory: टूल कॉल का अनुमानित क्रम.
6. आकलन कोड के बारे में जानकारी
shared/evaluation/evaluate.py खोलें. इस मॉड्यूल में, आकलन करने के लिए मुख्य लॉजिक शामिल होता है. मुख्य फ़ंक्शन evaluate_agent है.
यह इन चरणों को पूरा करता है:
- डेटा लोड करना: यह फ़ाइल से, आकलन के लिए इस्तेमाल किए जाने वाले डेटासेट (प्रॉम्प्ट और रेफ़रंस) को पढ़ता है.
- पैरलल इन्फ़रेंस: यह सुविधा, डेटासेट के साथ-साथ एजेंट को भी चलाती है. यह सेशन बनाने, प्रॉम्प्ट भेजने, और फ़ाइनल जवाब के साथ-साथ टूल के एक्ज़ीक्यूशन का इंटरमीडिएट ट्रेस को कैप्चर करने का काम करता है.
- Vertex AI Evaluation: यह ओरिजनल आकलन डेटा को फ़ाइनल जवाबों और इंटरमीडिएट टूल के एक्ज़ीक्यूशन ट्रेस के साथ मर्ज करता है. साथ ही, Vertex AI SDK में GenAI Client के साथ Vertex AI Evaluation Service को नतीजे सबमिट करता है. यह सेवा, कॉन्फ़िगर की गई मेट्रिक के आधार पर एजेंट की परफ़ॉर्मेंस का आकलन करती है.
आखिरी चरण का मुख्य काम, Gen AI SDK के eval मॉड्यूल के create_evaluation_run फ़ंक्शन को कॉल करना है:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
हम ऐसा evaluate_agent फ़ंक्शन में करते हैं.shared/evaluation/evaluate.py
इसे मर्ज किया गया आकलन डेटासेट, एजेंट के बारे में जानकारी, इस्तेमाल की जाने वाली मेट्रिक, और डेस्टिनेशन स्टोरेज यूआरआई मिलता है. यह फ़ंक्शन, Vertex AI Evaluation Service में आकलन रन बनाता है और आकलन रन ऑब्जेक्ट दिखाता है.
Agent Info API
सटीक आकलन करने के लिए, Evaluation Service को एजेंट के कॉन्फ़िगरेशन (सिस्टम के निर्देश, ब्यौरा, और उपलब्ध टूल) के बारे में पता होना चाहिए. हम इसे create_evaluation_run को agent_info पैरामीटर के तौर पर पास करते हैं.
हालांकि, हमें यह जानकारी कैसे मिलती है? हम इसे ADK Service API का हिस्सा बनाते हैं.
shared/adk_app.py खोलें और def agent_info खोजें. आपको दिखेगा कि ADK ऐप्लिकेशन, हेल्पर एंडपॉइंट को दिखाता है:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
इस एंडपॉइंट (--publish_agent_info फ़्लैग के ज़रिए चालू किया गया) की मदद से, आकलन करने वाली स्क्रिप्ट, एजेंट के रनटाइम कॉन्फ़िगरेशन को डाइनैमिक तौर पर फ़ेच कर सकती है. यह उन मेट्रिक के लिए ज़रूरी है जो टूल के इस्तेमाल का आकलन करती हैं. ऐसा इसलिए, क्योंकि अगर जज मॉडल को खास तौर पर यह पता हो कि बातचीत के दौरान एजेंट के लिए कौनसे टूल उपलब्ध थे, तो वह एजेंट के टूल के इस्तेमाल का बेहतर तरीके से आकलन कर सकता है.
7. इवैलुएशन चलाना
अब जब आपने आकलन करने वाले टूल को लागू कर दिया है, तो चलिए इसे चलाते हैं!
- रिपॉज़िटरी के रूट से, आकलन करने वाली स्क्रिप्ट चलाएं:
./evaluate.sh- यह आपकी मौजूदा Git कमिट का हैश पाता है.
- यह
deploy.shको चालू करता है, ताकि कमिट हैश के आधार पर टैग के साथ बदलाव लागू किया जा सके. - इसे डिप्लॉय करने के बाद, यह
evaluator.evaluate_agentशुरू हो जाता है. - जब यह आपकी क्लाउड सेवा के ख़िलाफ़ टेस्ट केस चलाता है, तब आपको प्रोग्रेस बार दिखेंगे.
- आखिर में, यह नतीजों का JSON फ़ॉर्मैट में खास जानकारी प्रिंट करता है.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
ध्यान दें: पहली बार सेवाओं को डिप्लॉय करने में कुछ मिनट लग सकते हैं.
8. Notebook में नतीजों को विज़ुअलाइज़ करना
रॉ JSON आउटपुट को पढ़ना मुश्किल होता है. Vertex AI SDK में मौजूद Gen AI Client, समय के साथ इन रन को ट्रैक करने का तरीका उपलब्ध कराता है. हम नतीजों को विज़ुअलाइज़ करने के लिए, Colab notebook का इस्तेमाल करेंगे.
evaluator/show_evaluation_run.ipynbको Google Colab में इस लिंक का इस्तेमाल करके खोलें.GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGION, औरEVAL_RUN_IDवैरिएबल को अपने प्रोजेक्ट आईडी, क्षेत्र, और रन आईडी पर सेट करें.
- डिपेंडेंसी इंस्टॉल करें और पुष्टि करें.
समीक्षा के रन को वापस पाना और नतीजे दिखाना
हमें Vertex AI से, इवैलुएशन रन का डेटा फ़ेच करना होगा. Retrieve Evaluation Run and Display Results सेक्शन में मौजूद सेल ढूंढें. इसके बाद, # TODO लाइन की जगह यह कोड ब्लॉक डालें:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
नतीजों को समझना
नतीजे देखते समय, इन बातों का ध्यान रखें:
- रिग्रेशन बनाम क्षमता:
- रिग्रेशन: क्या पुराने टेस्ट में स्कोर कम हुआ है? (यह अच्छा नहीं है, इसकी जांच करना ज़रूरी है).
- क्षमता: क्या नए टेस्ट में स्कोर बेहतर हुआ? (बहुत बढ़िया, यह प्रोग्रेस है).
- गड़बड़ी का विश्लेषण: सिर्फ़ स्कोर पर ध्यान न दें.
- ट्रेस देखें. क्या इसने गलत टूल को कॉल किया? क्या आउटपुट को पार्स नहीं किया जा सका? यहां आपको गड़बड़ियां दिखेंगी.
- जज एलएलएम की ओर से दी गई जानकारी और फ़ैसले देखें. इनसे आपको अक्सर यह पता चल जाता है कि टेस्ट क्यों पास नहीं हुआ.
Pass@1 बनाम Pass@k: किसी टेस्ट को एक बार चलाने पर, हमें Pass@1 स्कोर मिलता है. अगर कोई एजेंट फ़ेल हो जाता है, तो इसकी वजह नॉन-डिटरमिनिज़्म हो सकती है. ज़्यादा बेहतर सेटअप में, हर टेस्ट को k बार (जैसे, पांच बार) चलाया जा सकता है. इसके बाद, pass@k (क्या यह कम से कम एक बार सफल हुआ?) या pass^k (क्या यह हर बार सफल हुआ?) का हिसाब लगाया जा सकता है. कई मेट्रिक पहले से ही ऐसा करती हैं. उदाहरण के लिए, types.RubricMetric.FINAL_RESPONSE_MATCH (फ़ाइनल जवाब मैच), फ़ाइनल जवाब मैच का स्कोर तय करने के लिए, जज एलएलएम को पांच कॉल करता है.
9. लगातार इंटिग्रेशन और डिप्लॉयमेंट (सीआई/सीडी)
प्रोडक्शन सिस्टम में, एजेंट के परफ़ॉर्मेंस का आकलन, सीआई/सीडी पाइपलाइन के हिस्से के तौर पर किया जाना चाहिए. इसके लिए, Cloud Build एक अच्छा विकल्प है.
एजेंट की कोड रिपॉज़िटरी में पुश किए गए हर कमिट के लिए, अन्य टेस्ट के साथ-साथ आकलन भी किया जाएगा. अगर वे पास हो जाते हैं, तो डिप्लॉयमेंट को उपयोगकर्ता के अनुरोधों को पूरा करने के लिए "प्रमोट" किया जा सकता है. अगर ये जांचें पूरी नहीं होती हैं, तो कुछ भी नहीं बदलता. हालांकि, डेवलपर यह देख सकता है कि क्या गड़बड़ी हुई है.
Cloud Build कॉन्फ़िगरेशन
अब, Cloud Run डिप्लॉयमेंट कॉन्फ़िगरेशन स्क्रिप्ट बनाते हैं. यह स्क्रिप्ट, यहां दिए गए काम करती है:
- निजी वर्शन में सेवाएं डिप्लॉय करता है.
- यह एजेंट की परफ़ॉर्मेंस की जांच करता है.
- अगर समीक्षा में बदलाव सही पाए जाते हैं, तो उन्हें 100% ट्रैफ़िक के लिए "प्रमोट" किया जाता है.
cloudbuild.yaml बनाएं:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
पाइपलाइन चलाना
आखिर में, हम आकलन पाइपलाइन चला सकते हैं.
Cloud Run सेवाओं से अनुरोध करने वाली मूल्यांकन पाइपलाइन को चलाने से पहले, हमें कई अनुमतियों वाला एक अलग सेवा खाता चाहिए. चलिए, एक ऐसी स्क्रिप्ट लिखते हैं जो ऐसा करती है और पाइपलाइन लॉन्च करती है.
- स्क्रिप्ट बनाएं
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- यह एक खास सेवा खाता
agent-eval-build-saबनाता है. - इससे ज़रूरी भूमिकाएं (
roles/run.admin,roles/aiplatform.userवगैरह) असाइन की जाती हैं. *. यह Cloud Build को बिल्ड सबमिट करता है.
- यह एक खास सेवा खाता
- पाइपलाइन चलाएं:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
टर्मिनल में, बिल्ड की प्रोसेस देखी जा सकती है. इसके अलावा, Cloud Console के लिंक पर क्लिक करके भी प्रोसेस देखी जा सकती है.
ध्यान दें: प्रोडक्शन एनवायरमेंट में, आपको हर git push पर इसे अपने-आप चलाने के लिए, Cloud Build ट्रिगर सेट अप करना होगा. वर्कफ़्लो एक जैसा होता है: ट्रिगर cloudbuild.yaml को एक्ज़ीक्यूट करेगा. इससे यह पक्का होगा कि हर कमिट का आकलन किया गया है.
10. खास जानकारी
आपने इवैलुएशन पाइपलाइन बना ली है!
- डिप्लॉयमेंट: आपने git कमिट हैश के साथ रिवीजन टैग का इस्तेमाल किया. इससे, प्रोडक्शन डिप्लॉयमेंट पर असर डाले बिना, एजेंट को टेस्टिंग के लिए असली एनवायरमेंट में सुरक्षित तरीके से डिप्लॉय किया जा सकता है.
- आकलन: आपने आकलन की मेट्रिक तय की हैं. साथ ही, Vertex AI Gen AI Evaluation Service का इस्तेमाल करके, आकलन की प्रोसेस को ऑटोमेट किया है.
- विश्लेषण: आपने Colab Notebook का इस्तेमाल करके, आकलन के नतीजों को विज़ुअलाइज़ किया और अपने एजेंट को बेहतर बनाया.
- रोलआउट: आपने Cloud Build का इस्तेमाल करके, अपने-आप काम करने वाली पाइपलाइन को लागू किया. साथ ही, सबसे अच्छे वर्शन को प्रमोट किया, ताकि 100% ट्रैफ़िक को दिखाया जा सके.
यह साइकल कोड में बदलाव करना -> टैग डिप्लॉय करना-> आकलन और जांच करना -> विश्लेषण करना -> लॉन्च करना -> दोहराना, प्रोडक्शन-ग्रेड एजेंटिक इंजीनियरिंग का मुख्य हिस्सा है.