
1. Introduzione
Panoramica
Questo lab è il seguito di Crea sistemi multi-agente con ADK.
In quel lab hai creato un sistema di creazione di corsi composto da:
- Agente ricercatore: utilizza google_search per trovare informazioni aggiornate.
- Giudice: valuta la qualità e la completezza della ricerca.
- Agente Content Builder: trasforma la ricerca in un corso strutturato.
- Agente orchestratore: gestione del flusso di lavoro e della comunicazione tra questi specialisti.
Includeva anche un'app web che consentiva agli utenti di inviare una richiesta di creazione di un corso e ricevere un corso come risposta.
Ricercatore, Giudice e Generatore di contenuti vengono implementati come agenti A2A in servizi Cloud Run separati. Orchestrator è un altro servizio Cloud Run con l'API ADK Service.
Per questo lab, abbiamo modificato l'agente Researcher in modo che utilizzi lo strumento Ricerca su Wikipedia anziché la funzionalità Ricerca Google di Gemini. Ci consente di esaminare il modo in cui vengono tracciate e valutate le chiamate di strumenti personalizzati.
Per questo motivo, abbiamo creato un sistema multi-agente distribuito. Ma come facciamo a sapere se funziona davvero bene? Il ricercatore trova sempre informazioni pertinenti? Il giudice identifica correttamente la ricerca di scarsa qualità?
In questo lab, scambierai i "controlli dell'atmosfera" soggettivi con una valutazione basata sui dati utilizzando Vertex AI Gen AI Evaluation Service. Implementerai le metriche di qualità dell'utilizzo degli strumenti e delle griglie adattive per valutare rigorosamente il sistema multi-agente distribuito creato nel Lab 1. Infine, automatizzerai questo processo all'interno di una pipeline CI/CD, assicurandoti che ogni deployment mantenga l'affidabilità e l'accuratezza degli agenti di produzione.
Creerai una pipeline di valutazione continua per i tuoi agenti. Imparerai come:
- Esegui il deployment degli agenti in una revisione con tag privata in Google Cloud Run (deployment shadow).
- Esegui una suite di valutazione automatizzata su quella revisione specifica utilizzando Vertex AI Gen AI Evaluation Service.
- Visualizza e analizza i risultati.
- Utilizza la valutazione come parte della tua pipeline CI/CD.
2. Concetti di base: teoria della valutazione degli agenti
Durante lo sviluppo e l'esecuzione degli AI Agent, eseguiamo due tipi di valutazione: sperimentazione offline e valutazione continua con test di regressione automatizzati. Il primo è il motore creativo del processo di sviluppo, in cui eseguiamo esperimenti ad hoc, perfezioniamo i prompt e iteriamo rapidamente per sbloccare nuove funzionalità. Il secondo è il livello difensivo all'interno della nostra pipeline CI/CD, in cui eseguiamo valutazioni continue rispetto a un set di dati "golden" per garantire che nessuna modifica del codice peggiori inavvertitamente la qualità comprovata dell'agente.
La differenza fondamentale sta nella scoperta rispetto alla difesa:
- L'ottimizzazione offline è un processo di ottimizzazione. È aperto e variabile. Stai modificando attivamente gli input (prompt, modelli, parametri) per massimizzare un punteggio o risolvere un problema specifico. L'obiettivo è aumentare il "tetto" di ciò che l'agente può fare.
- La valutazione continua (test di regressione automatizzati) è un processo di verifica. È rigido e ripetitivo. Mantieni costanti gli input (il set di dati "golden") per garantire la stabilità degli output. L'obiettivo è impedire il crollo del "minimo" del rendimento.
In questo lab ci concentreremo sulla valutazione continua. Svilupperemo una pipeline di test di regressione automatizzati che dovrebbe essere eseguita ogni volta che qualcuno apporta una modifica all'agente AI, proprio come i test delle unità.
Prima di scrivere il codice, è fondamentale capire cosa stiamo misurando.
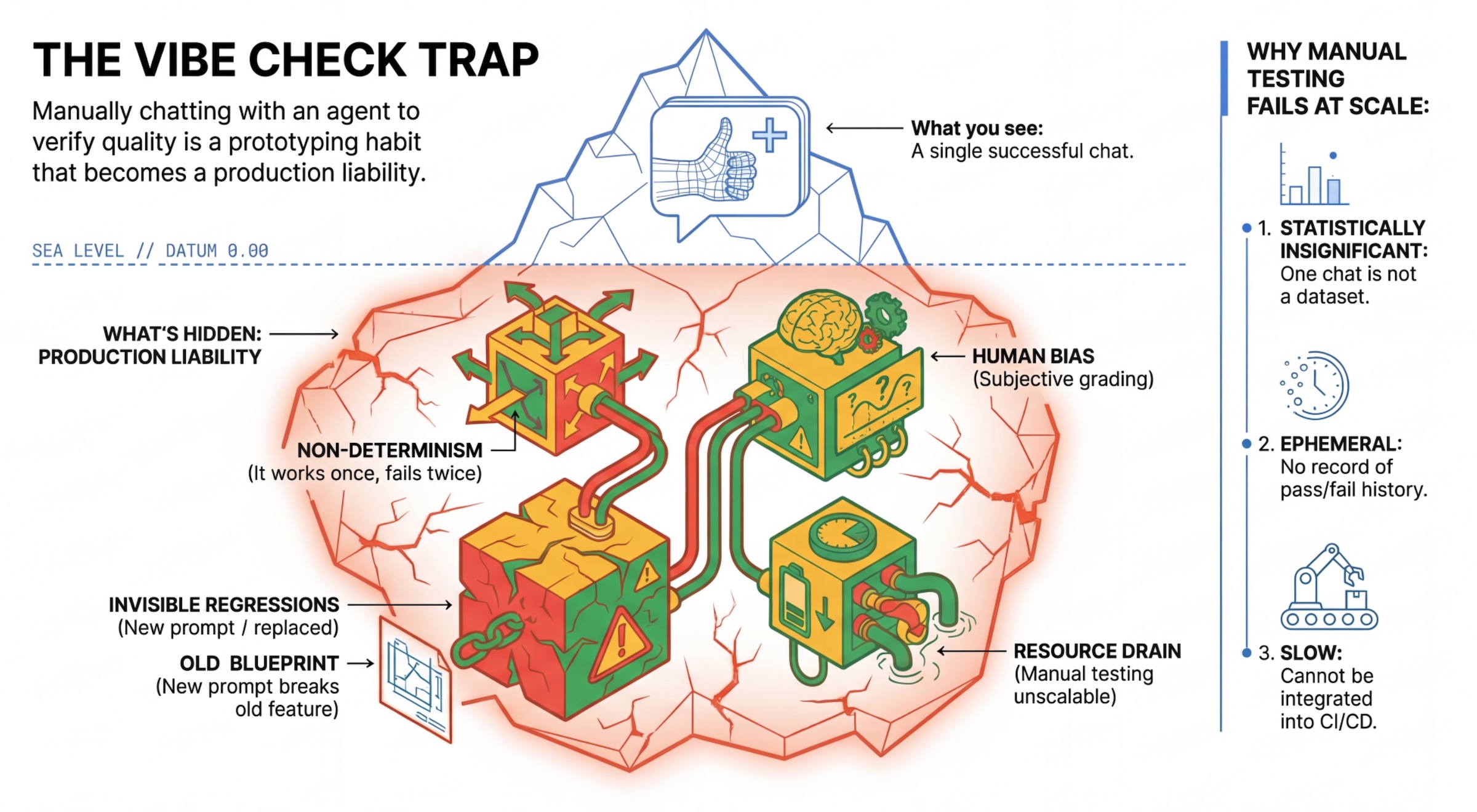
La trappola "Vibe Check"
Molti sviluppatori testano gli agenti chattando manualmente con loro. Questa operazione è nota come "vibe checking". Sebbene sia utile per la prototipazione, non funziona in produzione perché:
- Non determinismo: gli agenti possono rispondere in modo diverso ogni volta. Devi avere dimensioni del campione statisticamente significative.
- Regressioni invisibili: il miglioramento di un prompt potrebbe interrompere un caso d'uso diverso.
- Bias umano: "Sembra buono" è soggettivo.
- Lavoro che richiede tempo: è lento testare manualmente decine di scenari a ogni commit.
Due modi per valutare il rendimento dell'agente
Per creare una pipeline solida, combiniamo diversi tipi di valutatori:
- Correttori basati su codice (deterministici):
- Cosa misurano: vincoli rigorosi (ad es. "Ha restituito un JSON valido?", Ha chiamato lo strumento
search?"). - Vantaggi: veloce, economico, 100% accurato.
- Svantaggi: non è in grado di valutare le sfumature o la qualità.
- Cosa misurano: vincoli rigorosi (ad es. "Ha restituito un JSON valido?", Ha chiamato lo strumento
- Correttori basati su modelli (probabilistici):
- Conosciuto anche come "LLM-as-a-Judge". Utilizziamo un modello efficace (come Gemini 3 Pro) per valutare l'output dell'agente.
- Cosa misurano: sfumature, ragionamento, utilità, sicurezza.
- Vantaggi: può valutare attività complesse e aperte.
- Svantaggi: più lento, più costoso, richiede un'attenta ingegneria dei prompt per il giudice.
Metriche di valutazione di Vertex AI
In questo lab utilizziamo Vertex AI Gen AI Evaluation Service, che fornisce metriche gestite in modo da non dover scrivere ogni giudice da zero.
Esistono diversi modi per raggruppare le metriche per la valutazione degli agenti:
- Metriche basate su griglie di valutazione: incorporano i LLM nei workflow di valutazione.
- Rubriche adattive: le rubriche vengono generate dinamicamente per ogni prompt. Le risposte vengono valutate con un feedback granulare e spiegabile di superamento o mancato superamento specifico per il prompt.
- Rubriche statiche: le rubriche sono definite in modo esplicito e la stessa rubrica si applica a tutti i prompt. Le risposte vengono valutate con lo stesso insieme di valutatori basati su un sistema di punteggio numerico. Un unico punteggio numerico (ad esempio da 1 a 5) per prompt. Quando è necessaria una valutazione su una dimensione molto specifica o quando è richiesta la stessa rubrica esatta per tutti i prompt.
- Metriche basate su calcolo: valuta le risposte con algoritmi deterministici, in genere utilizzando dati di riferimento. Un punteggio numerico (ad esempio 0,0-1,0) per prompt. Quando i dati empirici reali sono disponibili e possono essere abbinati a un metodo deterministico.
- Metriche personalizzate delle funzioni: definisci la tua metrica tramite una funzione Python.
Metriche specifiche che utilizzeremo:
Final Response Match: (basato sul riferimento) La risposta corrisponde alla nostra "risposta ideale"?Tool Use Quality: (senza riferimenti) L'agente ha utilizzato gli strumenti pertinenti in modo corretto?Hallucination: (senza riferimenti) Le affermazioni nella risposta sono supportate dal contesto recuperato?Tool Trajectory PrecisioneTool Trajectory Recall(basato su riferimenti) L'agente ha selezionato lo strumento giusto e fornito argomentazioni valide? A differenza diTool Use Quality, queste metriche personalizzate utilizzano una traiettoria di riferimento, ovvero una sequenza di chiamate e argomenti degli strumenti previsti.
3. Configurazione
Configurazione
- Apri Cloud Shell: fai clic sull'icona Attiva Cloud Shell in alto a destra nella console Google Cloud.
- Esegui il comando seguente per aggiornare l'accesso e aggiornare le credenziali predefinite dell'applicazione (ADC):
gcloud auth login --update-adc - Imposta un progetto attivo per gcloud CLI.Esegui questo comando per ottenere il progetto gcloud corrente:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDcon l'ID del tuo progetto. - Imposta la regione predefinita in cui verranno implementati i tuoi servizi Cloud Run.
gcloud config set run/region us-west1us-west1, puoi utilizzare qualsiasi regione Cloud Run più vicina a te.
Codice e dipendenze
- Clona il codice di avvio e passa alla directory principale del progetto.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab - Crea il file
.env:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env - Installa le dipendenze eseguendo questo comando nella finestra del terminale:
uv sync
4. Informazioni sul deployment sicuro
Prima di valutare, dobbiamo eseguire il deployment. ma non vogliamo interrompere l'applicazione live se il nostro nuovo codice non funziona.
Tag di revisione e deployment shadow
Google Cloud Run supporta le revisioni. Ogni volta che esegui il deployment, viene creata una nuova revisione immutabile. Puoi assegnare tag a queste revisioni per accedervi tramite un URL specifico, anche se ricevono lo 0% del traffico pubblico.
Perché non eseguire i test in locale?
Sebbene l'ADK supporti la valutazione locale, il deployment in una revisione nascosta offre vantaggi fondamentali per i sistemi di produzione. In questo modo, la valutazione a livello di sistema (quella che stiamo eseguendo) si distingue dai test unitari:
- Parità dell'ambiente: gli ambienti locali sono diversi (rete diversa, CPU/memoria diverse, secret diversi). Il test nel cloud garantisce che l'agente funzioni nell'ambiente di runtime effettivo (test di sistema).
- Interazione multi-agente: in un sistema distribuito, gli agenti comunicano tramite HTTP. I test "locali" spesso simulano queste connessioni. Il deployment shadow testa la latenza di rete effettiva, le configurazioni di timeout e l'autenticazione tra i microservizi.
- Secret e autorizzazioni: verifica che il service account disponga effettivamente delle autorizzazioni necessarie (ad esempio per chiamare Vertex AI o leggere da Firestore).
Nota:si tratta di una valutazione proattiva (controllo prima che gli utenti lo vedano). Una volta eseguito il deployment, utilizzerai il monitoraggio reattivo (osservabilità) per rilevare i problemi in produzione.
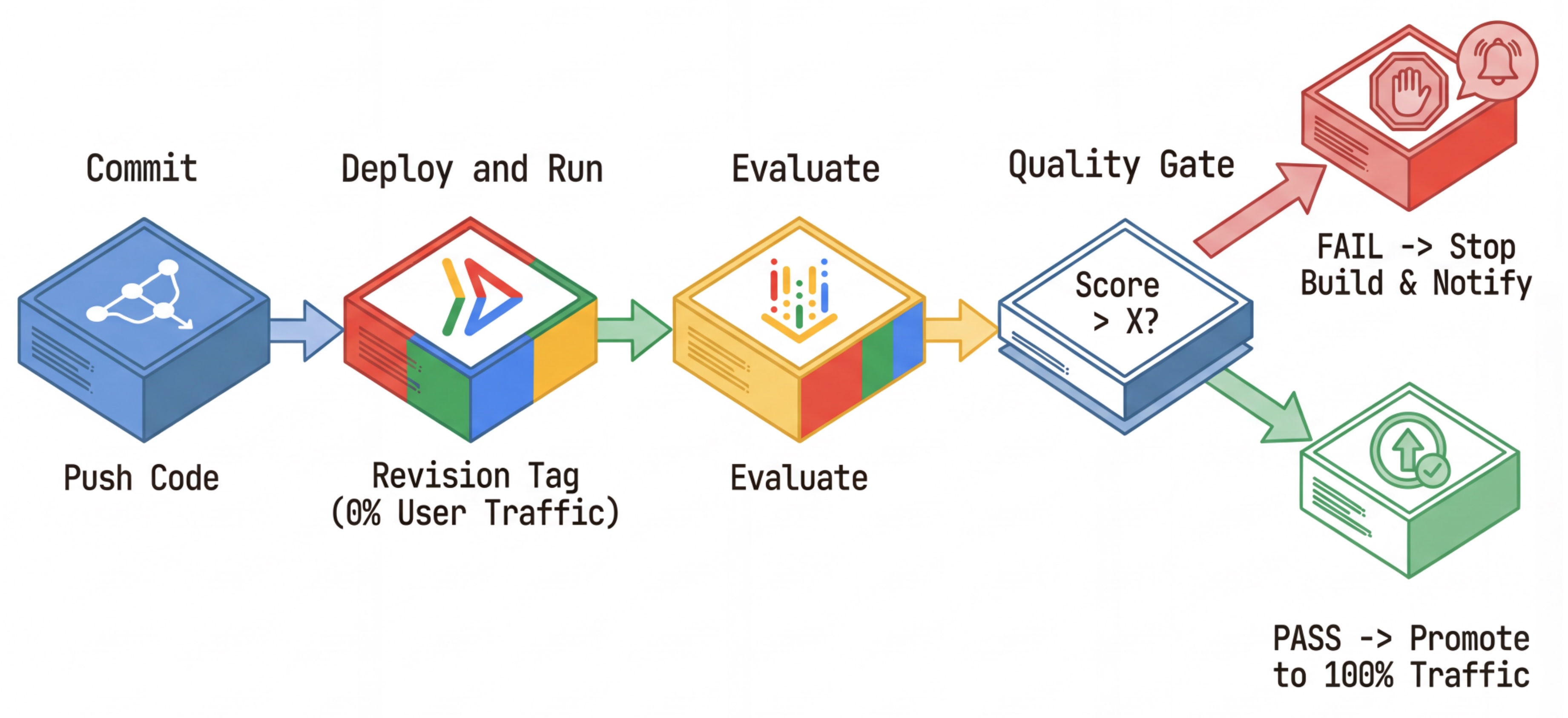
Il flusso di lavoro CI/CD: deployment, valutazione, promozione
Lo utilizziamo per una pipeline di deployment continuo solida:
- Commit: modifichi il prompt dell'agente ed esegui il push nel repository.
- Deploy (Hidden): attiva il deployment di una nuova revisione taggata con l'hash del commit (ad es.
c-abc1234). Questa revisione riceve lo 0% del traffico pubblico. - Valuta: lo script di valutazione ha come target l'URL di revisione specifico
https://c-abc1234---researcher-xyz.run.app. - Promuovi: se (e solo se) la valutazione viene superata e gli altri test hanno esito positivo, esegui la migrazione del traffico a questa nuova revisione.
- Rollback: se non va a buon fine, gli utenti non hanno mai visto la versione errata e puoi semplicemente ignorare o eliminare la revisione errata.
Questa strategia ti consente di eseguire test in produzione senza influire sui clienti.
Analizza evaluate.sh
Apri evaluate.sh. Questo script automatizza il processo.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
deploy.sh si occupa del deployment delle revisioni con le opzioni --no-traffic e --tag. Se è già in esecuzione un servizio, questo non verrà interessato. La nuova revisione "nascosta" non riceverà traffico, a meno che non la chiami esplicitamente con un URL speciale contenente il tag di revisione (ad es. https://c-abc1234---researcher-xyz.run.app)
5. Implementare lo script di valutazione
Ora scriviamo il codice che esegue effettivamente i test.
- Apri
evaluator/evaluate_agent.py. - Vedrai le importazioni e la configurazione, ma mancano le metriche e la logica di esecuzione.
Definisci le metriche
Per l'agente ricercatore, abbiamo una "risposta ideale"/"verità di riferimento" con le risposte previste. Si tratta di una valutazione delle funzionalità: stiamo misurando se l'agente può svolgere correttamente il lavoro.
Vogliamo misurare:
- Corrispondenza della risposta finale: (funzionalità) La risposta corrisponde a quella prevista? Si tratta di una metrica basata sul riferimento. Utilizza un LLM di valutazione per confrontare l'output dell'agente con la risposta prevista. Non si aspetta che la risposta sia esattamente la stessa, ma simile dal punto di vista semantico e fattuale.
- Qualità dell'utilizzo degli strumenti: (qualità) una metrica di griglie adattive mirata che valuta la selezione degli strumenti appropriati, l'utilizzo corretto dei parametri e il rispetto della sequenza di operazioni specificata.
- Traiettoria di utilizzo degli strumenti: (Traccia) 2 metriche personalizzate che misurano la traiettoria di utilizzo degli strumenti dell'agente (precisione e richiamo) rispetto alle traiettorie previste. Queste metriche sono implementate in
shared/evaluation/tool_metrics.pycome funzioni personalizzate. A differenza di Qualità dell'utilizzo degli strumenti, questa metrica è deterministica e basata su riferimenti: il codice verifica letteralmente se le chiamate effettive agli strumenti corrispondono ai dati di riferimento (reference_trajectorynei dati di valutazione).
Metriche della traiettoria di utilizzo degli strumenti personalizzati
Per le metriche personalizzate della traiettoria di utilizzo degli strumenti, abbiamo creato un insieme di funzioni Python in shared/evaluation/tool_metrics.py. Per consentire a Vertex AI Gen AI Evaluation Service di eseguire queste funzioni, dobbiamo trasmettergli il codice Python.
A questo scopo, definisci un oggetto EvaluationRunMetric con una configurazione UnifiedMetric e CustomCodeExecutionSpec. Il parametro remote_custom_function è una stringa che contiene il codice Python della funzione. La funzione deve essere denominata evaluate:
def evaluate(
instance: dict
) -> float:
...
Abbiamo creato l'helper get_custom_function_metric (in shared/evaluation/evaluate.py) che converte una funzione Python in una metrica di valutazione del codice personalizzato.
Recupera il codice del modulo della funzione (per acquisire le dipendenze locali), crea una funzione evaluate aggiuntiva che chiama la funzione originale e restituisce un oggetto EvaluationRunMetric con un CustomCodeExecutionSpec.
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
Gen AI Evaluation Service eseguirà il codice in un ambiente di esecuzione sandbox e gli trasmetterà i dati di valutazione.
Aggiungi le metriche e il codice di valutazione
Aggiungi il seguente codice a evaluator/evaluate_agent.py dopo la riga if __name__ == "__main__":.
Definisce l'elenco delle metriche per l'agente Researcher ed esegue la valutazione.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
In una pipeline di produzione reale, è necessario un criterio di successo della valutazione. Una volta completata la valutazione e quando le metriche sono pronte. Qui avresti un passaggio di controllo. Ad esempio: "Se il punteggio Final Response Match è inferiore a 0,75, la build non viene superata". In questo modo si impedisce che le revisioni errate ricevano traffico.
Aggiungi il seguente codice a evaluator/evaluate_agent.py:
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
Il deployment deve non riuscire ogni volta che il valore medio di una delle metriche di valutazione è inferiore a una soglia (0.75).
[Facoltativo] Aggiungi la valutazione con metriche senza riferimenti per Orchestrator
Per l'agente orchestratore, le interazioni sono più complesse e potrebbe non esserci sempre una singola risposta "corretta". Valutiamo invece il comportamento generale utilizzando una delle metriche senza riferimento.
- Allucinazione: una metrica basata sul punteggio che verifica l'oggettività e la coerenza delle risposte di testo segmentando la risposta in attestazioni atomiche. Verifica se ogni attestazione è fondata o meno in base all'utilizzo degli strumenti negli eventi intermedi. Ciò è fondamentale per gli agenti open-ended in cui la "correttezza" è soggettiva, ma la "veridicità" è non negoziabile. Il punteggio viene calcolato come percentuale delle affermazioni basate sui contenuti della fonte. Nel nostro caso, ci aspettiamo che la risposta finale dell'orchestratore (prodotta da Content Builder) sia oggettivamente fondata sui contenuti recuperati da Researcher utilizzando lo strumento di ricerca di Wikipedia.
Aggiungi la logica di valutazione per l'orchestratore:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
Ispeziona i dati di valutazione
Apri la directory evaluator/. Vedrai due file di dati:
eval_data_researcher.json: prompt e riferimenti Golden/Ground-Truth per il ricercatore.eval_data_orchestrator.json: prompt per l'orchestratore (eseguiamo solo la valutazione senza riferimenti per l'orchestratore).
Ogni voce in genere contiene:
prompt: Il prompt per l'agente.reference: la risposta ideale (verità di riferimento), se applicabile.reference_trajectory: La sequenza prevista di chiamate agli strumenti.
6. Informazioni sul codice di valutazione
Apri shared/evaluation/evaluate.py. Questo modulo contiene la logica di base per l'esecuzione delle valutazioni. La funzione chiave è evaluate_agent.
Esegue i seguenti passaggi:
- Caricamento dei dati: legge il set di dati di valutazione (prompt e riferimenti) da un file.
- Inferenza parallela: esegue l'agente sul set di dati in parallelo. Gestisce la creazione della sessione, invia i prompt e acquisisce sia la risposta finale sia la traccia di esecuzione dello strumento intermedio.
- Vertex AI Evaluation: unisce i dati di valutazione originali alle risposte finali e alla traccia di esecuzione dello strumento intermedio e invia i risultati a Vertex AI Evaluation Service con GenAI Client nell'SDK Vertex AI. Questo servizio esegue le metriche configurate per valutare le prestazioni dell'agente.
Il momento chiave dell'ultimo passaggio è la chiamata alla funzione create_evaluation_run del modulo eval dell'SDK Gen AI:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
Lo facciamo nella funzione evaluate_agent in shared/evaluation/evaluate.py.
Riceve il set di dati di valutazione unito, le informazioni sull'agente, le metriche da utilizzare e l'URI di archiviazione di destinazione. La funzione crea un'esecuzione della valutazione nel servizio di valutazione Vertex AI e restituisce l'oggetto di esecuzione della valutazione.
API Agent Info
Per eseguire una valutazione accurata, il servizio di valutazione deve conoscere la configurazione dell'agente (istruzioni di sistema, descrizione e strumenti disponibili). Lo trasmettiamo a create_evaluation_run come parametro agent_info.
Ma come otteniamo queste informazioni? La includiamo nell'API ADK Service.
Apri shared/adk_app.py e cerca def agent_info. Vedrai che l'applicazione ADK espone un endpoint helper:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
Questo endpoint (attivato tramite il flag --publish_agent_info) consente allo script di valutazione di recuperare dinamicamente la configurazione di runtime dell'agente. Ciò è fondamentale per le metriche che valutano l'utilizzo degli strumenti, in quanto il modello di valutazione può valutare meglio l'utilizzo degli strumenti dell'agente se sa esattamente quali strumenti erano disponibili per l'agente durante la conversazione.
7. Esegui la valutazione
Ora che hai implementato il valutatore, eseguiamolo.
- Esegui lo script di valutazione dalla root del repository:
./evaluate.sh- Recupera l'hash del commit Git corrente.
- Invoca
deploy.shper eseguire il deployment di una revisione con un tag basato sull'hash del commit. - Una volta eseguito il deployment, inizia
evaluator.evaluate_agent. - Vedrai le barre di avanzamento mentre esegue gli scenari di test sul tuo servizio cloud.
- Infine, stampa un JSON di riepilogo dei risultati.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Nota: la prima esecuzione potrebbe richiedere alcuni minuti per il deployment dei servizi.
8. Visualizzare i risultati nel notebook
L'output JSON non elaborato è difficile da leggere. Il client Gen AI nell'SDK Vertex AI fornisce un modo per monitorare queste esecuzioni nel tempo. Utilizzeremo un notebook di Colab per visualizzare i risultati.
- Apri
evaluator/show_evaluation_run.ipynbin Google Colab utilizzando questo link. - Imposta le variabili
GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGIONeEVAL_RUN_IDsull'ID progetto, sulla regione e sull'ID esecuzione.
- Installa le dipendenze e autenticati.
Recupera l'esecuzione della valutazione e visualizza i risultati
Dobbiamo recuperare i dati dell'esecuzione della valutazione da Vertex AI. Trova la cella in Recupera esecuzione della valutazione e visualizza i risultati e sostituisci la riga # TODO con il seguente blocco di codice:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
Interpretare i risultati
Quando esamini i risultati, tieni presente quanto segue:
- Regressione e funzionalità:
- Regressione: il punteggio è diminuito nei test precedenti? (Non buono, richiede un'indagine).
- Capacità: il punteggio è migliorato nei test nuovi? (Bene, questo è un progresso).
- Analisi degli errori: non limitarti a guardare il punteggio.
- Esamina la traccia. Ha chiamato lo strumento sbagliato? L'analisi dell'output non è riuscita? Qui trovi gli insetti.
- Esamina la spiegazione e i verdetti forniti dal giudice LLM. Spesso forniscono un'idea chiara del motivo per cui il test non è riuscito.
Pass@1 vs Pass@k: quando eseguiamo un determinato test una volta, otteniamo il punteggio Pass@1. Se un agente non funziona, il problema potrebbe essere dovuto al non determinismo. In configurazioni sofisticate, potresti eseguire ogni test k volte (ad es. 5 volte) e calcolare pass@k (è riuscito almeno una volta?) o pass^k (è riuscito ogni volta?). È quello che fanno già molte metriche dietro le quinte. Ad esempio, types.RubricMetric.FINAL_RESPONSE_MATCH (corrispondenza della risposta finale) effettua 5 chiamate all'LLM giudice per determinare il punteggio di corrispondenza della risposta finale.
9. Integrazione e deployment continui (CI/CD)
In un sistema di produzione, la valutazione dell'agente deve essere eseguita nell'ambito della pipeline CI/CD. Cloud Build è una buona scelta.
Per ogni commit eseguito nel repository di codice dell'agente, la valutazione verrà eseguita insieme al resto dei test. Se vengono superati, il deployment può essere "promosso" per gestire le richieste degli utenti. In caso di esito negativo, tutto rimane invariato, ma lo sviluppatore può esaminare il problema.
Configurazione di Cloud Build
Ora creiamo uno script di configurazione del deployment di Cloud Run che esegue i seguenti passaggi:
- Esegue il deployment dei servizi in una revisione privata.
- Esegue la valutazione dell'agente.
- Se la valutazione viene superata, le implementazioni delle revisioni vengono "promosse" per la gestione del 100% del traffico.
Crea cloudbuild.yaml:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
Esecuzione della pipeline
Infine, possiamo eseguire la pipeline di valutazione.
Prima di eseguire la pipeline di valutazione che effettua richieste ai servizi Cloud Run, abbiamo bisogno di un service account separato con una serie di autorizzazioni. Scriviamo uno script che esegua questa operazione e avvii la pipeline.
- Crea script
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- Crea un service account dedicato
agent-eval-build-sa. - Concede i ruoli necessari (
roles/run.admin,roles/aiplatform.usere così via). *. Invia la build a Cloud Build.
- Crea un service account dedicato
- Esegui la pipeline:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
Puoi monitorare l'avanzamento della build nel terminale o fare clic sul link alla console Cloud.
Nota: in un ambiente di produzione reale, configureresti un trigger Cloud Build per eseguirlo automaticamente ogni git push. Il flusso di lavoro è lo stesso: il trigger eseguirà cloudbuild.yaml, garantendo la valutazione di ogni commit.
10. Riepilogo
Hai creato una pipeline di valutazione.
- Deployment: hai utilizzato i tag di revisione con l'hash di commit Git per eseguire il deployment degli agenti in modo sicuro nell'ambiente reale per i test senza influire sui deployment di produzione.
- Valutazione: hai definito le metriche di valutazione e automatizzato il processo di valutazione utilizzando Vertex AI Gen AI Evaluation Service.
- Analisi: hai utilizzato un blocco note Colab per visualizzare i risultati della valutazione e migliorare l'agente.
- Implementazione: hai utilizzato Cloud Build per eseguire automaticamente la pipeline di valutazione e promuovere la revisione migliore per gestire il 100% del traffico.
Questo ciclo Modifica codice -> Implementa tag -> Esegui valutazione e test -> Analizza -> Implementa -> Ripeti è il fulcro dell'ingegneria agentica di livello di produzione.