
1. Introdução
Visão geral
Este laboratório é uma continuação do Crie sistemas multiagentes com o ADK.
Nesse laboratório, você criou um sistema de criação de cursos que consiste em:
- Agente de pesquisa: usa o google_search para encontrar informações atualizadas.
- Agente de avaliação: critica a pesquisa em relação à qualidade e integridade.
- Agente do Content Builder: transformar a pesquisa em um curso estruturado.
- Agente de orquestração: gerencia o fluxo de trabalho e a comunicação entre esses especialistas.
Ele também incluía um app da Web que permitia aos usuários enviar uma solicitação de criação de curso e receber um curso como resposta.
O Pesquisador, o Juiz e o Criador de conteúdo são implantados como agentes A2A em serviços separados do Cloud Run. O Orchestrator é outro serviço do Cloud Run com a API de serviço do ADK.
Neste laboratório, modificamos o agente de pesquisa para usar a ferramenta Pesquisa na Wikipédia em vez da capacidade de Pesquisa Google do Gemini. Ele permite inspecionar como as chamadas de ferramentas personalizadas são rastreadas e avaliadas.
Por isso, criamos um sistema multiagente distribuído. Mas como saber se ele está funcionando bem? O pesquisador sempre encontra informações relevantes? O juiz identifica corretamente pesquisas ruins?
Neste laboratório, você vai trocar as "verificações de vibe" subjetivas por uma avaliação baseada em dados usando o Serviço de avaliação de IA generativa da Vertex AI. Você vai implementar métricas de instruções adaptáveis e de qualidade de uso de ferramentas para avaliar rigorosamente o sistema multiagente distribuído criado no laboratório 1. Por fim, você vai automatizar esse processo em um pipeline de CI/CD, garantindo que cada implantação mantenha a confiabilidade e a precisão dos seus agentes de produção.
Você vai criar um pipeline de avaliação contínua para seus agentes. Você aprenderá o seguinte:
- Implante seus agentes em uma revisão marcada particular no Google Cloud Run (implantação shadow).
- Execute um pacote de avaliação automatizada nessa revisão específica usando o Serviço de avaliação de IA generativa da Vertex AI.
- Visualize e analise os resultados.
- Use a avaliação como parte do seu pipeline de CI/CD.
2. Conceitos básicos: teoria de avaliação de agentes
Ao desenvolver e executar agentes de IA, realizamos dois tipos de avaliação: experimentos off-line e avaliação contínua com testes de regressão automatizados. O primeiro é o motor criativo do processo de desenvolvimento, em que fazemos experimentos ad hoc, refinamos comandos e iteramos rapidamente para desbloquear novas funcionalidades. A segunda é a camada de defesa no nosso pipeline de CI/CD, em que executamos avaliações contínuas em um conjunto de dados "ouro" para garantir que nenhuma mudança de código degrade inadvertidamente a qualidade comprovada do agente.
A diferença fundamental está em Descoberta versus Defesa:
- A experimentação off-line é um processo de otimização. Ela é aberta e variável. Você está mudando ativamente as entradas (comandos, modelos, parâmetros) para maximizar uma pontuação ou resolver um problema específico. O objetivo é aumentar o "teto" do que o agente pode fazer.
- A avaliação contínua (teste de regressão automatizado) é um processo de verificação. Ele é rígido e repetitivo. Você mantém as entradas constantes (o conjunto de dados "ouro") para garantir que as saídas permaneçam estáveis. O objetivo é evitar que o "piso" de desempenho entre em colapso.
Neste laboratório, vamos nos concentrar na avaliação contínua. Vamos desenvolver um pipeline de teste de regressão automatizado que deve ser executado sempre que alguém fizer uma mudança no agente de IA, assim como os testes de unidade.
Antes de escrever o código, é fundamental entender o que estamos medindo.
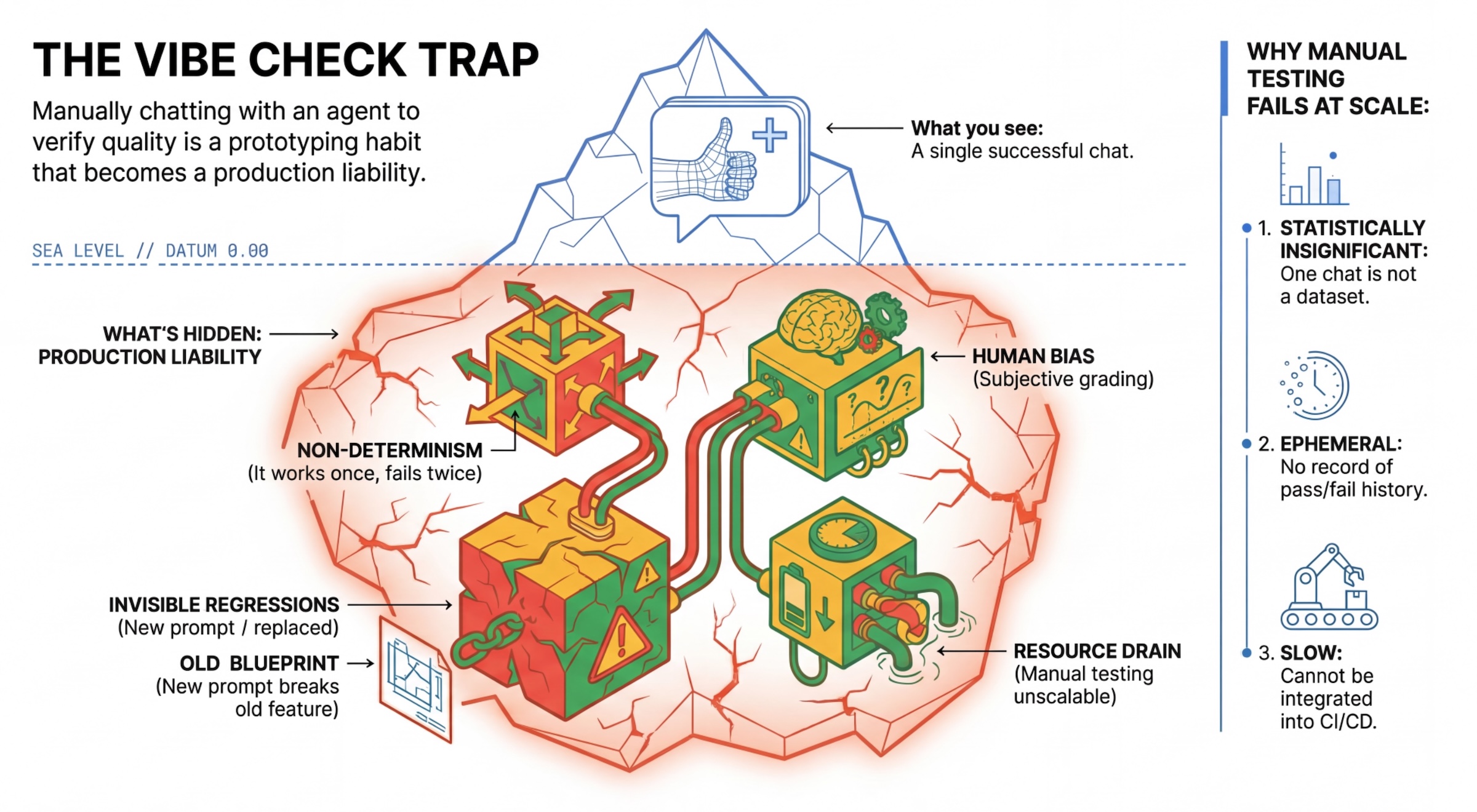
A armadilha da "Vibe Check"
Muitos desenvolvedores testam agentes conversando manualmente com eles. Isso é conhecido como "vibe checking". Embora seja útil para prototipagem, ele falha na produção porque:
- Não determinismo: os agentes podem responder de maneira diferente a cada vez. Você precisa de tamanhos de amostra estatisticamente significativos.
- Regressões invisíveis: melhorar um comando pode prejudicar um caso de uso diferente.
- Viés humano: "Parece bom" é subjetivo.
- Trabalho demorado: é lento testar manualmente dezenas de cenários a cada commit.
Duas maneiras de avaliar a performance do agente
Para criar um pipeline robusto, combinamos diferentes tipos de avaliadores:
- Classificadores baseados em código (determinísticos):
- O que eles medem: restrições rigorosas (por exemplo, "Ele retornou um JSON válido?", Ele chamou a ferramenta
search?"). - Prós: rápido, barato e 100% preciso.
- Desvantagens: não é possível julgar nuances ou qualidade.
- O que eles medem: restrições rigorosas (por exemplo, "Ele retornou um JSON válido?", Ele chamou a ferramenta
- Classificadores baseados em modelos (probabilísticos):
- Também conhecido como "LLM-as-a-Judge". Usamos um modelo avançado (como o Gemini 3 Pro) para avaliar a saída do agente.
- O que elas medem: nuance, raciocínio, utilidade e segurança.
- Prós: pode avaliar tarefas complexas e abertas.
- Desvantagens: mais lento, mais caro e exige uma engenharia de comando cuidadosa para o juiz.
Métricas de avaliação da Vertex AI
Neste laboratório, usamos o Serviço de avaliação de IA generativa da Vertex AI, que fornece métricas gerenciadas para que você não precise escrever cada juiz do zero.
Há várias maneiras de agrupar métricas para avaliação do agente:
- Métricas com base em instruções: incorporam LLMs aos fluxos de trabalho de avaliação.
- Rubricas adaptativas: as rubricas são geradas dinamicamente para cada comando. As respostas são avaliadas com feedback granular e explicável de aprovação ou reprovação específico para o comando.
- Rubricas estáticas: são definidas explicitamente e a mesma rubrica se aplica a todos os comandos. As respostas são avaliadas com o mesmo conjunto de avaliadores numéricos baseados em pontuação. Uma única pontuação numérica (como de 1 a 5) por solicitação. Quando uma avaliação é necessária em uma dimensão muito específica ou quando a mesma rubrica é necessária em todos os comandos.
- Métricas baseadas em computação: avaliam respostas com algoritmos determinísticos, geralmente usando informações empíricas. Uma pontuação numérica (como 0,0 a 1,0) por solicitação. Quando as informações empíricas estão disponíveis e podem ser combinadas com um método determinista.
- Métricas de função personalizadas: defina sua própria métrica usando uma função do Python.
Métricas específicas que vamos usar:
Final Response Match: (com base em referência) A resposta corresponde à nossa "Resposta de ouro"?Tool Use Quality: (sem referência) O agente usou ferramentas relevantes de maneira adequada?Hallucination: (sem referência) As declarações na resposta são apoiadas pelo contexto recuperado?Tool Trajectory PrecisioneTool Trajectory Recall(com base em referência): o agente selecionou a ferramenta certa e forneceu argumentos válidos? Ao contrário deTool Use Quality, essas métricas personalizadas usam uma trajetória de referência, que é uma sequência de chamadas de ferramentas e argumentos esperados.
3. Configuração
Configuração
- Abra o Cloud Shell: clique no ícone Ativar o Cloud Shell no canto superior direito do console do Google Cloud.
- Execute o comando a seguir para atualizar o login e atualizar as Application Default Credentials (ADC):
gcloud auth login --update-adc - Defina um projeto ativo para a CLI gcloud.Execute o seguinte comando para receber o projeto atual da gcloud:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDpelo ID do projeto. - Defina a região padrão em que os serviços do Cloud Run serão implantados.
gcloud config set run/region us-west1us-west1, use qualquer região do Cloud Run mais próxima de você.
Código e dependências
- Clone o código inicial e mude o diretório para a raiz do projeto.
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab - Crie o arquivo
.env:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env - Instale as dependências executando o seguinte comando na janela do terminal:
uv sync
4. Noções básicas sobre a implantação segura
Antes de avaliar, precisamos implantar. Mas não queremos interromper o aplicativo ativo se o novo código for ruim.
Tags de revisão e implantação shadow
O Google Cloud Run oferece suporte a revisões. Cada vez que você implanta, uma nova revisão imutável é criada. Você pode atribuir tags a essas revisões para acessá-las por um URL específico, mesmo que elas estejam recebendo 0% do tráfego público.
Por que não executar as avaliações localmente?
Embora o ADK ofereça suporte à avaliação local, a implantação em uma revisão oculta oferece vantagens importantes para sistemas de produção. Isso distingue a avaliação no nível do sistema (o que estamos fazendo) do teste de unidade:
- Paridade de ambiente: os ambientes locais são diferentes (rede, CPU/memória e segredos diferentes). O teste na nuvem garante que o agente funcione no ambiente de execução real (teste de sistema).
- Interação multiagente: em um sistema distribuído, os agentes se comunicam por HTTP. Os testes "locais" geralmente simulam essas conexões. A implantação shadow testa a latência de rede real, as configurações de tempo limite e a autenticação entre os microsserviços.
- Secrets e permissões: verifica se a conta de serviço tem as permissões necessárias, por exemplo, para chamar a Vertex AI ou ler do Firestore.
Observação:esta é a avaliação proativa (verificação antes que os usuários vejam). Depois da implantação, use o monitoramento reativo (observabilidade) para detectar problemas em produção.
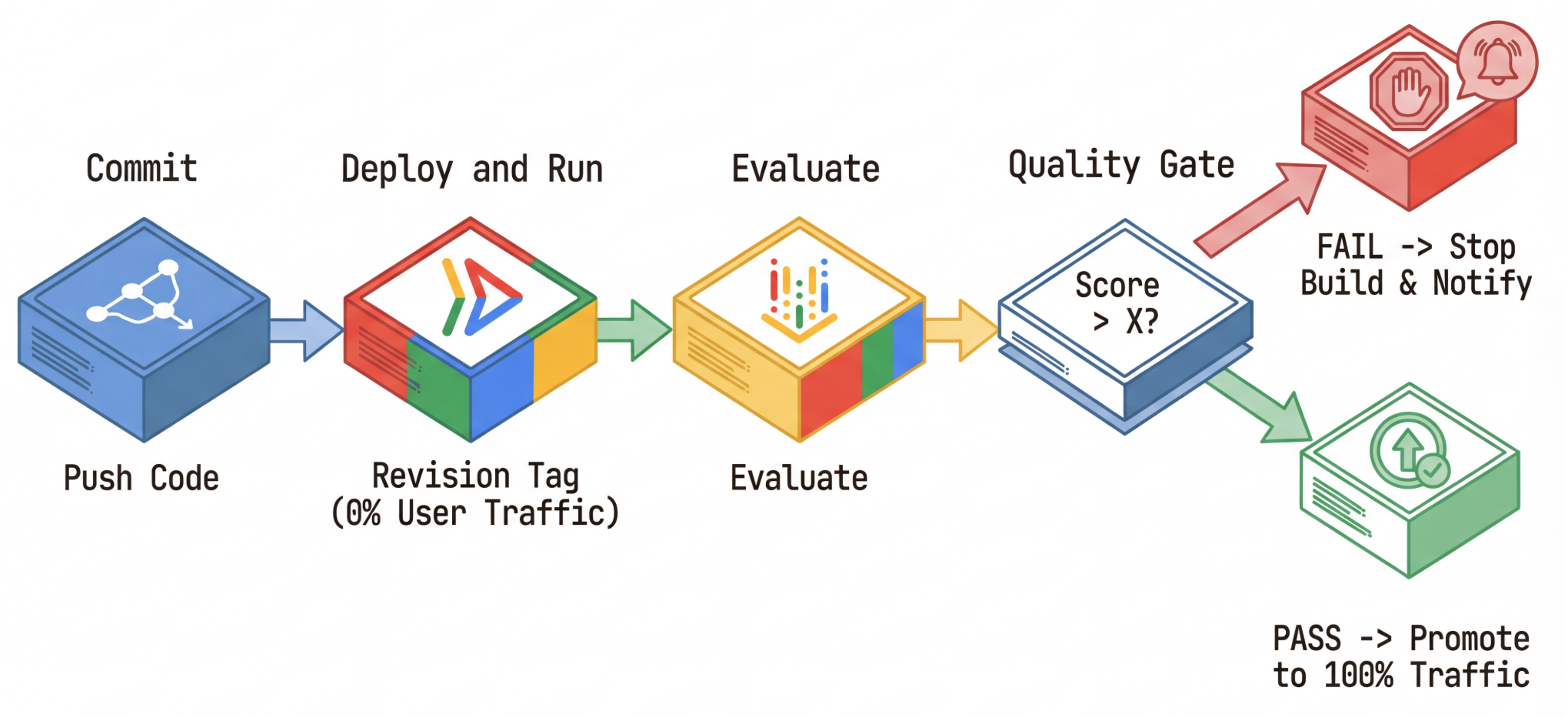
O fluxo de trabalho de CI/CD: implantação, avaliação e promoção
Usamos isso para um pipeline robusto de implantação contínua:
- Commit: você muda o comando do agente e envia para o repositório.
- Implantar (oculto): aciona a implantação de uma nova revisão marcada com o hash de commit (por exemplo,
c-abc1234). Essa revisão recebe 0% do tráfego público. - Avaliar: o script de avaliação tem como destino o URL de revisão específico
https://c-abc1234---researcher-xyz.run.app. - Promover: se (e somente se) a avaliação for aprovada e outros testes forem bem-sucedidos, migre o tráfego para essa nova revisão.
- Reversão: se a reversão falhar, os usuários nunca viram a versão ruim, e você pode simplesmente ignorar ou excluir a revisão ruim.
Essa estratégia permite testar em produção sem afetar os clientes.
Analisar evaluate.sh
Abra evaluate.sh. Esse script automatiza o processo.
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
O deploy.sh cuida da implantação de revisão com as opções --no-traffic e --tag. Se já houver um serviço em execução, ele não será afetado. A nova revisão "oculta" não vai receber tráfego, a menos que você a chame explicitamente com um URL especial que contenha a tag de revisão (por exemplo, https://c-abc1234---researcher-xyz.run.app).
5. Implementar o script de avaliação
Agora, vamos escrever o código que executa os testes.
- Abra
evaluator/evaluate_agent.py. - Você verá importações e configurações, mas as métricas e a lógica de execução não estarão presentes.
Definir as métricas
Para o agente pesquisador, temos um "Golden Answers"/"Ground Truth" com respostas esperadas. Esta é uma avaliação de capacidade: estamos medindo se o agente consegue fazer o trabalho corretamente.
Queremos medir:
- Correspondência da resposta final: (capacidade) a resposta corresponde à resposta esperada? Essa é uma métrica baseada em referência. Ele usa um LLM de avaliação para comparar a saída do agente com a resposta esperada. Ela não espera que a resposta seja exatamente igual, mas semanticamente e factualmente semelhante.
- Qualidade do uso de ferramentas: (qualidade) uma métrica direcionada de rubricas adaptáveis que avalia a seleção de ferramentas apropriadas, o uso correto de parâmetros e a adesão à sequência de operações especificada.
- Trajetória de uso de ferramentas: (trace) duas métricas personalizadas que medem a trajetória de uso de ferramentas do agente (precisão e recall) em comparação com as trajetórias esperadas. Essas métricas são implementadas em
shared/evaluation/tool_metrics.pycomo funções personalizadas. Ao contrário da Qualidade do uso de ferramentas, essa métrica é determinista e baseada em referência. O código verifica se as chamadas de ferramentas reais correspondem aos dados de referência (reference_trajectorynos dados de avaliação).
Métricas de trajetória de uso de ferramentas personalizadas
Para métricas personalizadas de trajetória de uso de ferramentas, criamos um conjunto de funções Python em shared/evaluation/tool_metrics.py. Para permitir que o serviço de avaliação de IA generativa da Vertex AI execute essas funções, precisamos transmitir esse código Python a ele.
Isso é feito definindo um objeto EvaluationRunMetric com uma configuração de UnifiedMetric e CustomCodeExecutionSpec. O parâmetro remote_custom_function é uma string que contém o código Python da função. A função precisa ser nomeada como evaluate:
def evaluate(
instance: dict
) -> float:
...
Criamos o auxiliar get_custom_function_metric (em shared/evaluation/evaluate.py) que converte uma função Python em uma métrica de avaliação de código personalizada.
Ele recebe o código do módulo da função (para capturar dependências locais), cria uma função evaluate extra que chama a função original e retorna um objeto EvaluationRunMetric com um CustomCodeExecutionSpec.
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
O serviço de avaliação de IA generativa vai executar esse código em um ambiente de execução de sandbox e transmitir os dados de avaliação para ele.
Adicionar o código de métricas e avaliação
Adicione o seguinte código a evaluator/evaluate_agent.py depois da linha if __name__ == "__main__":.
Ele define a lista de métricas para o agente pesquisador e executa a avaliação.
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
Em um pipeline de produção real, você precisa de um critério de sucesso da avaliação. Depois que a avaliação for concluída e as métricas estiverem prontas. Você teria uma etapa de controle aqui. Por exemplo: "Se a pontuação de Final Response Match for < 0,75, falhe o build". Isso impede que revisões ruins recebam tráfego.
Anexe o seguinte código a evaluator/evaluate_agent.py:
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
Sempre que o valor da média de qualquer uma das métricas de avaliação estiver abaixo de um limite (0.75), a implantação vai falhar.
[Opcional] Adicionar avaliação com métricas sem referência para o Orquestrador
Para o agente orquestrador, as interações são mais complexas, e nem sempre temos uma única resposta "correta". Em vez disso, avaliamos o comportamento geral usando uma das métricas sem referência.
- Alucinação: uma métrica baseada em pontuação que verifica a veracidade dos fatos e a consistência das respostas de texto segmentando a resposta em declarações menores. Ela verifica se as declarações têm embasamento ou não com base no uso de ferramentas nos eventos intermediários. Isso é fundamental para agentes abertos, em que a "correção" é subjetiva, mas a "veracidade" é inegociável. A pontuação é calculada como a porcentagem de declarações fundamentadas no conteúdo da fonte. No nosso caso, esperamos que a resposta final do Orchestrator (produzida pelo Content Builder) seja baseada no conteúdo que o Researcher recuperou usando a ferramenta de pesquisa da Wikipédia.
Adicione a lógica de avaliação para o Orchestrator:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
Inspecionar dados de avaliação
Abra o diretório evaluator/. Você vai encontrar dois arquivos de dados:
eval_data_researcher.json: comandos e referências de Golden/Ground-Truth para o pesquisador.eval_data_orchestrator.json: comandos para o Orchestrator. Só fazemos a avaliação sem referência para o Orchestrator.
Cada entrada normalmente contém:
prompt: o comando para o agente.reference: a resposta ideal (verdade fundamental), se aplicável.reference_trajectory: a sequência esperada de chamadas de função.
6. Entender o código de avaliação
Abra shared/evaluation/evaluate.py. Esse módulo contém a lógica principal para executar avaliações. A função principal é evaluate_agent.
Ele executa as seguintes etapas:
- Carregamento de dados: lê o conjunto de dados de avaliação (comandos e referências) de um arquivo.
- Inferência paralela: executa o agente no conjunto de dados em paralelo. Ele processa a criação de sessões, envia comandos e captura a resposta final e o rastreamento de execução da ferramenta intermediária.
- Avaliação da Vertex AI: mescla os dados de avaliação originais com as respostas finais e o rastreamento da execução da ferramenta intermediária e envia os resultados ao Serviço de avaliação da Vertex AI com o cliente de IA generativa no SDK da Vertex AI. Esse serviço executa as métricas configuradas para classificar a performance do agente.
O momento principal da última etapa é chamar a função create_evaluation_run do módulo de avaliação do SDK da IA generativa:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
Fazemos isso na função evaluate_agent em shared/evaluation/evaluate.py.
Ele recebe o conjunto de dados de avaliação mesclado, as informações sobre o agente, as métricas a serem usadas e o URI de armazenamento de destino. A função cria uma execução de avaliação no serviço de avaliação da Vertex AI e retorna o objeto de execução de avaliação.
API Agent Info
Para fazer uma avaliação precisa, o serviço de avaliação precisa saber a configuração do agente (instruções do sistema, descrição e ferramentas disponíveis). Vamos transmiti-lo para create_evaluation_run como parâmetro agent_info.
Mas como conseguimos essas informações? Ela faz parte da API de serviço do ADK.
Abra shared/adk_app.py e pesquise def agent_info. Você vai notar que o aplicativo ADK expõe um endpoint auxiliar:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
Esse endpoint (ativado pela flag --publish_agent_info) permite que o script de avaliação busque dinamicamente a configuração de tempo de execução do agente. Isso é crucial para métricas que avaliam o uso de ferramentas, já que o modelo de avaliação pode avaliar melhor o uso de ferramentas pelo agente se souber especificamente quais ferramentas estavam disponíveis para o agente durante a conversa.
7. Executar a avaliação
Agora que você implementou o avaliador, vamos executá-lo.
- Execute o script de avaliação na raiz do repositório:
./evaluate.sh- Ele recebe o hash de commit do Git atual.
- Ele invoca o
deploy.shpara implantar uma revisão com uma tag baseada no hash de commit. - Depois de implantado, ele inicia
evaluator.evaluate_agent. - Você verá barras de progresso enquanto ele executa os casos de teste no seu serviço de nuvem.
- Por fim, ele imprime um JSON de resumo dos resultados.
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Observação: a primeira execução pode levar alguns minutos para implantar os serviços.
8. Visualizar resultados no notebook
A saída JSON bruta é difícil de ler. O cliente de IA generativa no SDK da Vertex AI oferece uma maneira de acompanhar essas execuções ao longo do tempo. Vamos usar um notebook do Colab para visualizar os resultados.
- Abra
evaluator/show_evaluation_run.ipynbno Google Colab usando este link. - Defina as variáveis
GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGIONeEVAL_RUN_IDcomo o ID do projeto, a região e o ID da execução.
- Instale as dependências e faça a autenticação.
Recuperar a execução da avaliação e mostrar os resultados
Precisamos buscar os dados da execução da avaliação na Vertex AI. Encontre a célula em Recuperar execução da avaliação e mostrar resultados e substitua a linha # TODO pelo seguinte bloco de código:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
Como interpretar os resultados
Ao analisar os resultados, lembre-se do seguinte:
- Regressão x capacidade:
- Regressão: a pontuação caiu nos testes antigos? (Não é bom, requer investigação).
- Capacidade: a pontuação melhorou nos testes novos? (Bom, isso é um progresso).
- Análise de falhas: não olhe apenas a pontuação.
- Analise o trace. Ele chamou a ferramenta errada? Não foi possível analisar a saída? É aqui que você encontra os bugs.
- Leia a explicação e os veredictos fornecidos pelo LLM de juiz. Elas costumam dar uma boa ideia de por que o teste falhou.
Pass@1 x Pass@k: ao executar um determinado teste uma vez, recebemos a pontuação Pass@1. Se um agente falhar, isso pode ser devido a um comportamento não determinista. Em configurações sofisticadas, você pode executar cada teste k vezes (por exemplo, 5 vezes) e calcular pass@k (ele foi bem-sucedido pelo menos uma vez?) ou pass^k (ele foi bem-sucedido todas as vezes?). É isso que muitas métricas já fazem nos bastidores. Por exemplo, types.RubricMetric.FINAL_RESPONSE_MATCH (correspondência da resposta final) faz cinco chamadas para o LLM de avaliação para determinar a pontuação de correspondência da resposta final.
9. Integração e implantação contínuas (CI/CD)
Em um sistema de produção, a avaliação do agente precisa ser executada como parte do pipeline de CI/CD. O Cloud Build é uma boa opção para isso.
Para cada commit enviado ao repositório de código do agente, a avaliação será executada com o restante dos testes. Se forem aprovados, a implantação poderá ser "promovida" para atender às solicitações dos usuários. Se eles falharem, tudo vai permanecer no estado em que se encontra, mas o desenvolvedor pode verificar o que deu errado.
Configuração do Cloud Build
Agora, vamos criar um script de configuração de implantação do Cloud Run que executa as seguintes etapas:
- Implanta serviços em uma revisão particular.
- Executa a avaliação de agentes.
- Se a avaliação for aprovada, ela "promoverá" as implantações de revisão para veicular 100% do tráfego.
Crie cloudbuild.yaml:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
Como executar o pipeline
Por fim, podemos executar o pipeline de avaliação.
Antes de executar o pipeline de avaliação que faz solicitações aos serviços do Cloud Run, precisamos de uma conta de serviço separada com várias permissões. Vamos escrever um script que faça isso e inicie o pipeline.
- Criar script
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- Cria uma conta de serviço dedicada
agent-eval-build-sa. - Concede a ela os papéis necessários (
roles/run.admin,roles/aiplatform.useretc.). *. Envia o build para o Cloud Build.
- Cria uma conta de serviço dedicada
- Execute o canal:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
Você pode acompanhar o progresso da build no terminal ou clicar no link para o console do Cloud.
Observação: em um ambiente de produção real, você configuraria um gatilho do Cloud Build para executar isso automaticamente em cada git push. O fluxo de trabalho é o mesmo: o gatilho executaria cloudbuild.yaml, garantindo que todos os commits sejam avaliados.
10. Resumo
Você criou um pipeline de avaliação.
- Implantação: você usou tags de revisão com hash de commit do Git para implantar agentes com segurança em um ambiente real para testes sem afetar as implantações de produção.
- Avaliação: você definiu métricas de avaliação e automatizou o processo de avaliação usando o serviço de avaliação de IA generativa da Vertex AI.
- Análise: você usou um notebook do Colab para visualizar os resultados da avaliação e melhorar seu agente.
- Lançamento: você usou o Cloud Build para executar o pipeline de avaliação automaticamente e promover a melhor revisão para disponibilizar 100% do tráfego.
Esse ciclo Editar código -> Implantar tag -> Executar avaliação e testes -> Analisar -> Implantação -> Repetir é o núcleo da Engenharia de agentes de nível de produção.