
1. บทนำ
ภาพรวม
Lab นี้เป็นการต่อยอดจาก Build Multi-Agent Systems with ADK
ใน Lab นั้น คุณได้สร้างระบบการสร้างหลักสูตรซึ่งประกอบด้วย
- Researcher Agent: ใช้ google_search เพื่อค้นหาข้อมูลล่าสุด
- ผู้ตัดสิน Agent: วิจารณ์งานวิจัยเพื่อดูคุณภาพและความสมบูรณ์
- เอเจนต์ตัวสร้างเนื้อหา: เปลี่ยนงานวิจัยให้เป็นหลักสูตรที่มีโครงสร้าง
- Orchestrator Agent: จัดการเวิร์กโฟลว์และการสื่อสารระหว่างผู้เชี่ยวชาญเหล่านี้
นอกจากนี้ ยังมีเว็บแอปที่อนุญาตให้ผู้ใช้ส่งคำขอสร้างหลักสูตรและรับหลักสูตรเป็นคำตอบ
ผู้ค้นคว้า ผู้ตัดสิน และผู้สร้างเนื้อหาได้รับการติดตั้งใช้งานเป็นเอเจนต์ A2A ในบริการ Cloud Run แยกกัน Orchestrator เป็นอีกหนึ่งบริการ Cloud Run ที่มี ADK Service API
สำหรับห้องทดลองนี้ เราได้แก้ไขตัวแทน Researcher ให้ใช้เครื่องมือ Wikipedia Search แทนความสามารถ Google Search ของ Gemini ซึ่งช่วยให้เราตรวจสอบได้ว่ามีการติดตามและประเมินการเรียกใช้เครื่องมือที่กำหนดเองอย่างไร
เราจึงสร้างระบบแบบหลายเอเจนต์แบบกระจาย แต่เราจะรู้ได้อย่างไรว่าการทดสอบนั้นได้ผลดีจริง โปรแกรมค้นคว้าจะค้นหาข้อมูลที่เกี่ยวข้องได้เสมอไหม ผู้พิพากษาระบุการวิจัยที่ไม่ดีได้อย่างถูกต้องหรือไม่
ในแล็บนี้ คุณจะเปลี่ยนจากการประเมินแบบใช้ความรู้สึกที่เรียกว่า "Vibe Checks" ไปเป็นการประเมินที่อิงข้อมูลโดยใช้บริการประเมิน Gen AI ของ Vertex AI คุณจะใช้เมตริกรูบริกแบบปรับได้และคุณภาพการใช้เครื่องมือเพื่อประเมินระบบแบบหลาย Agent ที่กระจายอยู่ซึ่งสร้างขึ้นใน Lab 1 อย่างเข้มงวด สุดท้าย คุณจะทำให้กระบวนการนี้เป็นแบบอัตโนมัติภายในไปป์ไลน์ CI/CD เพื่อให้มั่นใจว่าการติดตั้งใช้งานทุกครั้งจะรักษาความน่าเชื่อถือและความแม่นยำของเอเจนต์เวอร์ชันที่ใช้งานจริง
คุณจะสร้างไปป์ไลน์การประเมินอย่างต่อเนื่องสำหรับ Agent คุณจะได้เรียนรู้วิธีต่อไปนี้
- ติดตั้งใช้งาน Agent ในรีวิชันที่ติดแท็กส่วนตัวใน Google Cloud Run (การติดตั้งใช้งานแบบเงา)
- เรียกใช้ชุดการประเมินอัตโนมัติกับรีวิชันที่เฉพาะเจาะจงนั้นโดยใช้บริการประเมิน Gen AI ของ Vertex AI
- แสดงภาพและวิเคราะห์ผลลัพธ์
- ใช้การประเมินเป็นส่วนหนึ่งของไปป์ไลน์ CI/CD
2. แนวคิดหลัก: ทฤษฎีการประเมินเอเจนต์
เมื่อพัฒนาและเรียกใช้ AI Agent เราจะทำการประเมิน 2 ชนิด ได้แก่ การทดสอบแบบออฟไลน์และการประเมินอย่างต่อเนื่องด้วยการทดสอบการถดถอยอัตโนมัติ ประการแรกคือเครื่องมือสร้างสรรค์ในกระบวนการพัฒนา ซึ่งเราจะทำการทดสอบเฉพาะกิจ ปรับแต่งพรอมต์ และทำซ้ำอย่างรวดเร็วเพื่อปลดล็อกความสามารถใหม่ๆ ส่วนที่ 2 คือเลเยอร์ป้องกันภายในไปป์ไลน์ CI/CD ซึ่งเราจะทำการประเมินอย่างต่อเนื่องกับชุดข้อมูล "โกลเด้น" เพื่อให้มั่นใจว่าการเปลี่ยนแปลงโค้ดจะไม่ทำให้คุณภาพที่ได้รับการพิสูจน์แล้วของเอเจนต์ลดลงโดยไม่ตั้งใจ
ความแตกต่างพื้นฐานอยู่ที่การค้นพบเทียบกับการป้องกัน ดังนี้
- การทดสอบแบบออฟไลน์เป็นกระบวนการเพิ่มประสิทธิภาพ โดยเป็นคำถามปลายเปิดและมีตัวแปร คุณกำลังเปลี่ยนอินพุต (พรอมต์ โมเดล พารามิเตอร์) อย่างต่อเนื่องเพื่อเพิ่มคะแนนสูงสุดหรือแก้ปัญหาที่เฉพาะเจาะจง เป้าหมายคือการเพิ่ม "ขีดจำกัด" ของสิ่งที่เอเจนต์ทำได้
- การประเมินอย่างต่อเนื่อง (การทดสอบการถดถอยอัตโนมัติ) เป็นกระบวนการตรวจสอบ มีความแข็งทื่อและซ้ำซาก คุณจะคงค่าอินพุตไว้ (ชุดข้อมูล "โกลเด้น") เพื่อให้เอาต์พุตยังคงเสถียร เป้าหมายคือการป้องกันไม่ให้ "พื้น" ของประสิทธิภาพพังทลายลง
ในแล็บนี้ เราจะมุ่งเน้นที่การประเมินอย่างต่อเนื่อง เราจะพัฒนากระบวนการทดสอบถดถอยอัตโนมัติซึ่งควรจะทำงานทุกครั้งที่มีการเปลี่ยนแปลงใน AI Agent เช่นเดียวกับการทำ Unit Test
ก่อนเขียนโค้ด คุณต้องเข้าใจสิ่งที่เรากำลังวัด
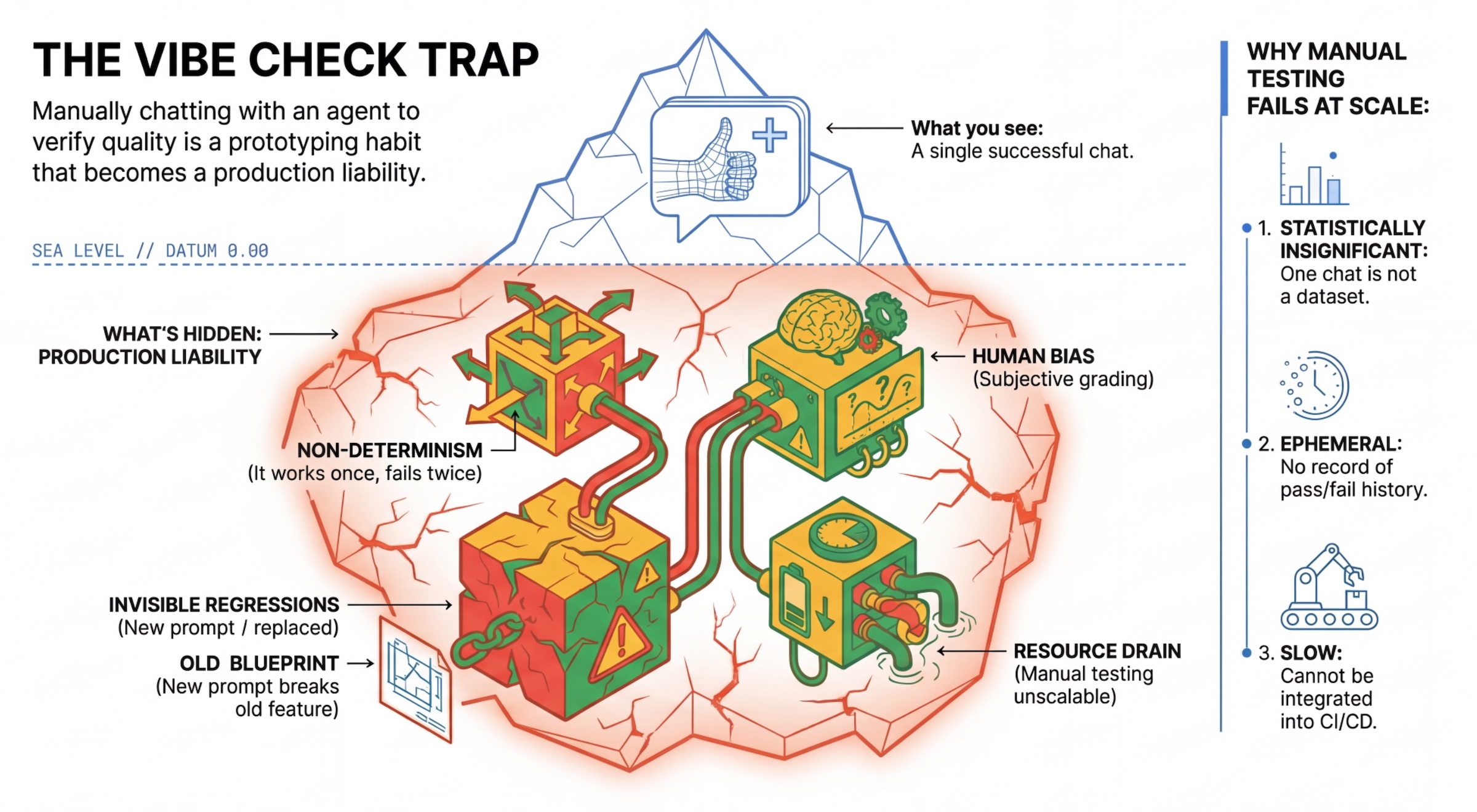
กับดัก "เช็กไวบ์"
นักพัฒนาแอปจำนวนมากทดสอบเอเจนต์ด้วยการแชทกับเอเจนต์ด้วยตนเอง ซึ่งเรียกว่า "การดูฟีล" แม้จะมีประโยชน์ในการสร้างต้นแบบ แต่ก็ใช้งานจริงไม่ได้เนื่องจากเหตุผลต่อไปนี้
- ความไม่แน่นอน: เอเจนต์สามารถตอบคำถามได้แตกต่างกันในแต่ละครั้ง คุณต้องมีขนาดตัวอย่างที่มีนัยสำคัญทางสถิติ
- การถดถอยที่มองไม่เห็น: การปรับปรุงพรอมต์หนึ่งอาจทำให้กรณีการใช้งานอื่นใช้งานไม่ได้
- อคติของมนุษย์: "ดูดี" เป็นความคิดเห็นส่วนบุคคล
- งานที่ใช้เวลานาน: การทดสอบสถานการณ์หลายสิบรายการด้วยตนเองในทุกการคอมมิตนั้นช้า
2 วิธีในการให้คะแนนประสิทธิภาพของตัวแทน
เราใช้เครื่องมือให้คะแนนหลายประเภทเพื่อสร้างไปป์ไลน์ที่แข็งแกร่ง
- โปรแกรมตรวจที่อิงตามโค้ด (แน่นอน):
- สิ่งที่วัด: ข้อจำกัดที่เข้มงวด (เช่น "ฟังก์ชันแสดงผล JSON ที่ถูกต้องไหม" "โมเดลเรียกใช้เครื่องมือ
searchไหม") - ข้อดี: รวดเร็ว ราคาถูก แม่นยำ 100%
- ข้อเสีย: ไม่สามารถตัดสินความแตกต่างเล็กๆ น้อยๆ หรือคุณภาพได้
- สิ่งที่วัด: ข้อจำกัดที่เข้มงวด (เช่น "ฟังก์ชันแสดงผล JSON ที่ถูกต้องไหม" "โมเดลเรียกใช้เครื่องมือ
- ผู้ให้คะแนนตามโมเดล (เชิงความน่าจะเป็น):
- หรือที่เรียกว่า "LLM-as-a-Judge" เราใช้โมเดลที่มีประสิทธิภาพ (เช่น Gemini 3 Pro) เพื่อประเมินเอาต์พุตของเอเจนต์
- สิ่งที่วัด: ความแตกต่าง การให้เหตุผล ประโยชน์ ความปลอดภัย
- ข้อดี: ประเมินงานที่ซับซ้อนและไม่มีคำตอบที่ตายตัวได้
- ข้อเสีย: ช้าลง แพงขึ้น ต้องมีการออกแบบพรอมต์อย่างรอบคอบสำหรับผู้ตรวจสอบ
เมตริกการประเมิน Vertex AI
ใน Lab นี้ เราจะใช้บริการประเมิน Gen AI ของ Vertex AI ซึ่งมีเมตริกที่มีการจัดการเพื่อให้คุณไม่ต้องเขียนผู้ประเมินทุกรายตั้งแต่ต้น
คุณจัดกลุ่มเมตริกสำหรับการประเมินตัวแทนได้หลายวิธี ดังนี้
- เมตริกตามเกณฑ์การให้คะแนน: ผสานรวม LLM เข้ากับเวิร์กโฟลว์การประเมิน
- เกณฑ์การให้คะแนนแบบปรับเปลี่ยนได้: ระบบจะสร้างเกณฑ์การให้คะแนนแบบไดนามิกสำหรับแต่ละพรอมต์ การตอบกลับจะได้รับการประเมินด้วยความคิดเห็นแบบผ่านหรือไม่ผ่านที่อธิบายได้และละเอียด ซึ่งเฉพาะเจาะจงกับพรอมต์
- เกณฑ์การให้คะแนนแบบคงที่: มีการกำหนดเกณฑ์การให้คะแนนอย่างชัดเจนและใช้เกณฑ์การให้คะแนนเดียวกันกับพรอมต์ทั้งหมด ระบบจะประเมินคำตอบด้วยชุดผู้ประเมินที่อิงตามการให้คะแนนเชิงตัวเลขชุดเดียวกัน คะแนนตัวเลขเดียว (เช่น 1-5) ต่อพรอมต์ เมื่อต้องมีการประเมินในมิติข้อมูลที่เฉพาะเจาะจงมาก หรือเมื่อต้องใช้รูบริกเดียวกันทุกประการในพรอมต์ทั้งหมด
- เมตริกที่อิงตามการคำนวณ: ประเมินคำตอบด้วยอัลกอริทึมที่กำหนด โดยปกติจะใช้ความจริงพื้นฐาน คะแนนตัวเลข (เช่น 0.0-1.0) ต่อพรอมต์ เมื่อมีข้อมูลจากการสังเกตการณ์โดยตรงและสามารถจับคู่กับวิธีการที่แน่นอนได้
- เมตริกฟังก์ชันที่กำหนดเอง: กำหนดเมตริกของคุณเองผ่านฟังก์ชัน Python
เมตริกเฉพาะที่เราจะใช้
Final Response Match: (อิงตามข้อมูลอ้างอิง) คำตอบตรงกับ "คำตอบที่ถูกต้อง" ของเราไหมTool Use Quality: (ไม่มีการอ้างอิง) ตัวแทนใช้เครื่องมือที่เกี่ยวข้องอย่างเหมาะสมหรือไม่Hallucination: (ไม่มีการอ้างอิง) การกล่าวอ้างในคำตอบได้รับการสนับสนุนจากบริบทที่ดึงมาหรือไม่Tool Trajectory PrecisionและTool Trajectory Recall(อิงตามการอ้างอิง) เจ้าหน้าที่เลือกเครื่องมือที่เหมาะสมและให้เหตุผลที่ถูกต้องหรือไม่ เมตริกที่กำหนดเองเหล่านี้ใช้เส้นทางการอ้างอิง ซึ่งเป็นลำดับของการเรียกเครื่องมือและอาร์กิวเมนต์ที่คาดไว้ ซึ่งแตกต่างจากTool Use Quality
3. ตั้งค่า
การกำหนดค่า
- เปิด Cloud Shell: คลิกไอคอนเปิดใช้งาน Cloud Shell ที่ด้านขวาบนของคอนโซล Google Cloud
- เรียกใช้คำสั่งต่อไปนี้เพื่อรีเฟรชการลงชื่อเข้าใช้และอัปเดตข้อมูลเข้าสู่ระบบเริ่มต้นของแอปพลิเคชัน (ADC)
gcloud auth login --update-adc - ตั้งค่าโปรเจ็กต์ที่ใช้งานอยู่สำหรับ gcloud CLI เรียกใช้คำสั่งต่อไปนี้เพื่อรับโปรเจ็กต์ gcloud ปัจจุบัน
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_IDด้วยรหัสของโปรเจ็กต์ - ตั้งค่าภูมิภาคเริ่มต้นที่จะทำให้บริการ Cloud Run ใช้งานได้
gcloud config set run/region us-west1us-west1ได้
โค้ดและการอ้างอิง
- โคลนโค้ดเริ่มต้นและเปลี่ยนไดเรกทอรีไปยังรูทของโปรเจ็กต์
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab - สร้างไฟล์
.envecho "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env - ติดตั้งส่วนที่ใช้อ้างอิงโดยเรียกใช้คำสั่งต่อไปนี้ในหน้าต่างเทอร์มินัล
uv sync
4. ทำความเข้าใจการติดตั้งใช้งานที่ปลอดภัย
เราต้องติดตั้งใช้งานก่อนจึงจะประเมินได้ แต่เราไม่ต้องการให้แอปพลิเคชันที่ใช้งานจริงหยุดทำงานหากโค้ดใหม่ของเราไม่ดี
แท็กการแก้ไขและการติดตั้งใช้งานแบบเงา
Google Cloud Run รองรับการแก้ไข ทุกครั้งที่คุณทําการติดตั้งใช้งาน ระบบจะสร้างการแก้ไขใหม่ที่เปลี่ยนแปลงไม่ได้ คุณกำหนดแท็กให้กับการแก้ไขเหล่านี้เพื่อเข้าถึงผ่าน URL ที่เฉพาะเจาะจงได้ แม้ว่าการแก้ไขดังกล่าวจะได้รับการเข้าชมจากสาธารณะ 0% ก็ตาม
ทำไมไม่ทำการประเมินในพื้นที่
แม้ว่า ADK จะรองรับการประเมินในเครื่อง แต่การติดตั้งใช้งานในการแก้ไขที่ซ่อนอยู่ก็มีข้อดีที่สำคัญสำหรับระบบการผลิต ซึ่งจะทำให้การประเมินระดับระบบ (สิ่งที่เรากำลังทำ) แตกต่างจากการทดสอบหน่วย
- ความเท่าเทียมของสภาพแวดล้อม: สภาพแวดล้อมในเครื่องแตกต่างกัน (เครือข่ายต่างกัน, CPU/หน่วยความจำต่างกัน, Secret ต่างกัน) การทดสอบในระบบคลาวด์ช่วยให้มั่นใจได้ว่าเอเจนต์จะทำงานในสภาพแวดล้อมรันไทม์จริง (การทดสอบระบบ)
- การโต้ตอบแบบหลาย Agent: ในระบบแบบกระจาย Agent จะสื่อสารผ่าน HTTP การทดสอบ "ในเครื่อง" มักจะจำลองการเชื่อมต่อเหล่านี้ การทดสอบการติดตั้งใช้งานแบบเงาจะทดสอบเวลาในการตอบสนองของเครือข่ายจริง การกำหนดค่าการหมดเวลา และการตรวจสอบสิทธิ์ระหว่างไมโครเซอร์วิส
- ข้อมูลลับและสิทธิ์: ตรวจสอบว่าบัญชีบริการของคุณมีสิทธิ์ที่จำเป็นจริง (เช่น เพื่อเรียกใช้ Vertex AI หรืออ่านจาก Firestore)
หมายเหตุ: นี่คือการประเมินเชิงรุก (การตรวจสอบก่อนที่ผู้ใช้จะเห็น) เมื่อทำให้ใช้งานได้แล้ว คุณจะใช้การตรวจสอบเชิงโต้ตอบ (ความสามารถในการสังเกต) เพื่อตรวจหาปัญหาในสภาพแวดล้อมจริง
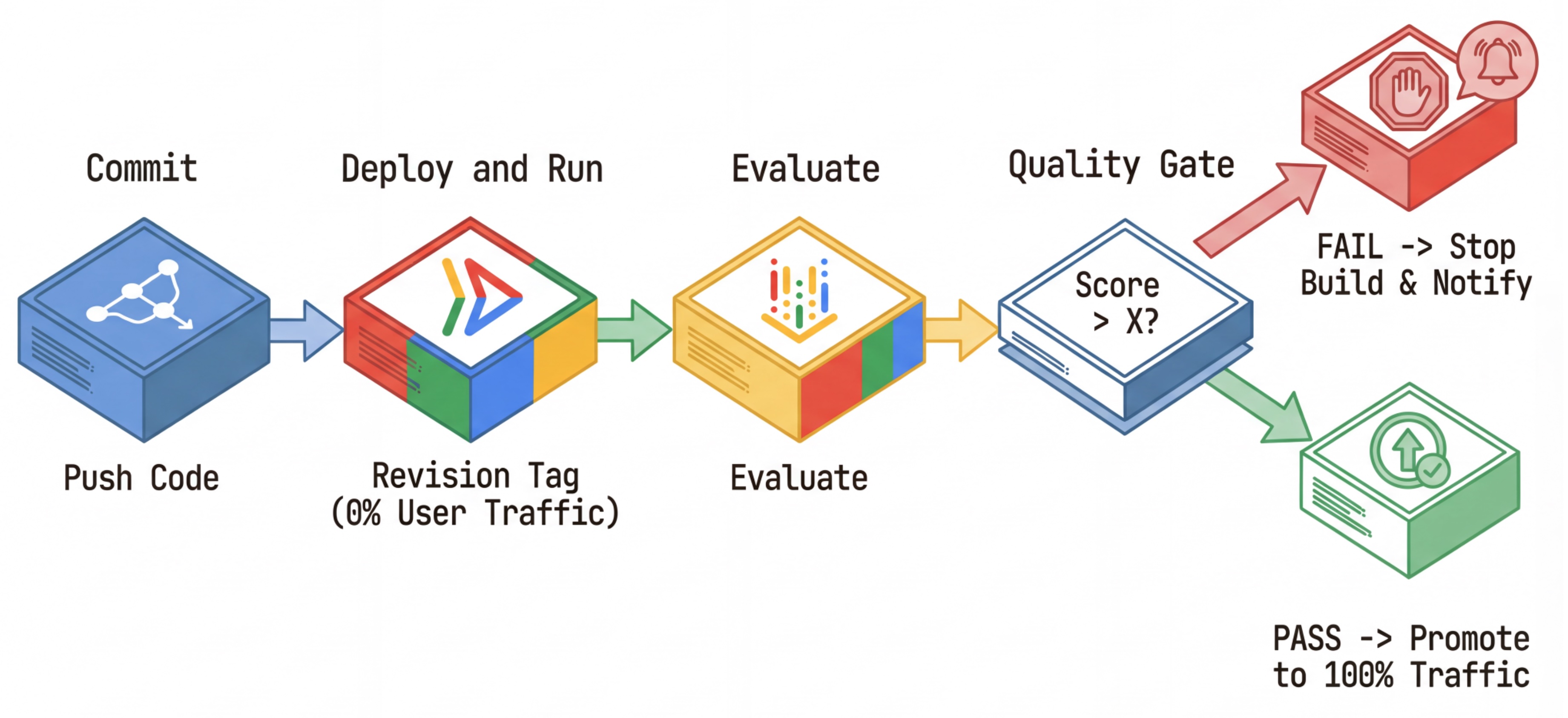
เวิร์กโฟลว์ CI/CD: ติดตั้งใช้งาน ประเมิน เลื่อนระดับ
เราใช้สิ่งนี้สำหรับไปป์ไลน์การทำให้ใช้งานได้อย่างต่อเนื่องที่แข็งแกร่ง
- คอมมิต: คุณเปลี่ยนพรอมต์ของเอเจนต์และพุชไปยังที่เก็บ
- ทําให้ใช้งานได้ (ซ่อนอยู่): ทริกเกอร์การทําให้การแก้ไขใหม่ที่ติดแท็กด้วยแฮชของคอมมิตใช้งานได้ (เช่น
c-abc1234) การแก้ไขนี้จะได้รับการเข้าชมแบบสาธารณะ 0% - ประเมิน: สคริปต์การประเมินกำหนดเป้าหมายไปยัง URL ของการแก้ไขที่เฉพาะเจาะจง
https://c-abc1234---researcher-xyz.run.app - โปรโมต: หากการประเมินผ่านและทดสอบอื่นๆ สำเร็จ (และในกรณีนี้เท่านั้น) ให้ย้ายข้อมูลการเข้าชมไปยังการแก้ไขใหม่นี้
- ย้อนกลับ: หากไม่สำเร็จ ผู้ใช้จะไม่เห็นเวอร์ชันที่ไม่ดี และคุณสามารถเพิกเฉยหรือลบการแก้ไขที่ไม่ดีได้
กลยุทธ์นี้ช่วยให้คุณทดสอบในเวอร์ชันที่ใช้งานจริงได้โดยไม่ส่งผลกระทบต่อลูกค้า
วิเคราะห์ evaluate.sh
เปิด evaluate.sh สคริปต์นี้จะทำให้กระบวนการเป็นไปโดยอัตโนมัติ
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
deploy.sh จะดูแลการติดตั้งใช้งานรีวิชันด้วยตัวเลือก --no-traffic และ --tag หากมีบริการที่ทำงานอยู่แล้ว บริการดังกล่าวจะไม่ได้รับผลกระทบ การแก้ไขใหม่ที่ "ซ่อน" จะไม่ได้รับการเข้าชมใดๆ เว้นแต่คุณจะเรียกใช้การแก้ไขอย่างชัดเจนด้วย URL พิเศษที่มีแท็กการแก้ไข (เช่น https://c-abc1234---researcher-xyz.run.app)
5. ติดตั้งใช้งานสคริปต์การประเมิน
ตอนนี้มาเขียนโค้ดที่เรียกใช้การทดสอบจริงกัน
- เปิด
evaluator/evaluate_agent.py - คุณจะเห็นการนําเข้าและการตั้งค่า แต่จะไม่มีเมตริกและตรรกะการดําเนินการ
กำหนดเมตริก
สำหรับเอเจนต์นักวิจัย เรามี "คำตอบที่ถูกต้อง"/"ข้อมูลจากการสังเกตการณ์โดยตรง" พร้อมคำตอบที่คาดไว้ นี่คือการประเมินความสามารถ: เรากำลังวัดว่าเอเจนต์ทำงานได้อย่างถูกต้องหรือไม่
เราต้องการวัดผลสิ่งต่อไปนี้
- การจับคู่คำตอบสุดท้าย: (ความสามารถ) คำตอบตรงกับคำตอบที่คาดไว้หรือไม่ เมตริกนี้อิงตามการอ้างอิง โดยจะใช้ LLM ผู้ตัดสินเพื่อเปรียบเทียบเอาต์พุตของเอเจนต์กับคำตอบที่คาดไว้ โดยไม่คาดหวังว่าคำตอบจะเหมือนกันทุกประการ แต่มีความคล้ายคลึงกันในเชิงความหมายและข้อเท็จจริง
- คุณภาพการใช้เครื่องมือ: (คุณภาพ) เมตริกรูบริกแบบปรับได้ที่กำหนดเป้าหมายซึ่งประเมินการเลือกเครื่องมือที่เหมาะสม การใช้พารามิเตอร์ที่ถูกต้อง และการปฏิบัติตามลำดับการดำเนินการที่ระบุ
- วิถีการใช้เครื่องมือ: (ติดตาม) เมตริกที่กําหนดเอง 2 รายการที่วัดวิถีการใช้เครื่องมือของเอเจนต์ (ความแม่นยําและความสามารถในการเรียกคืน) เทียบกับวิถีที่คาดไว้ เมตริกเหล่านี้จะใช้ใน
shared/evaluation/tool_metrics.pyเป็นฟังก์ชันที่กำหนดเอง เมตริกนี้แตกต่างจากคุณภาพการใช้เครื่องมือตรงที่เป็นเมตริกอิงตามการอ้างอิงที่กำหนดได้ ซึ่งโค้ดจะดูว่าการเรียกใช้เครื่องมือจริงตรงกับข้อมูลอ้างอิง (reference_trajectoryในข้อมูลการประเมิน) หรือไม่
เมตริกวิถีการใช้เครื่องมือที่กำหนดเอง
สําหรับเมตริกเส้นทางการใช้เครื่องมือที่กําหนดเอง เราได้สร้างชุดฟังก์ชัน Python ใน shared/evaluation/tool_metrics.py หากต้องการอนุญาตให้ Vertex AI Gen AI Evaluation Service เรียกใช้ฟังก์ชันเหล่านี้ เราต้องส่งโค้ด Python นั้นไปยังบริการ
โดยทำได้ด้วยการกำหนดออบเจ็กต์ EvaluationRunMetric ที่มีการกำหนดค่า UnifiedMetric และ CustomCodeExecutionSpec พารามิเตอร์ remote_custom_function คือสตริงที่มีโค้ด Python ของฟังก์ชัน ฟังก์ชันต้องมีชื่อว่า evaluate
def evaluate(
instance: dict
) -> float:
...
เราได้สร้างget_custom_function_metricฟังก์ชันช่วย (ใน shared/evaluation/evaluate.py) ที่แปลงฟังก์ชัน Python เป็นเมตริกการประเมินโค้ดที่กำหนดเอง
โดยจะรับโค้ดของโมดูลฟังก์ชัน (เพื่อบันทึกการอ้างอิงในเครื่อง) สร้างevaluate ฟังก์ชันเพิ่มเติมที่เรียกฟังก์ชันเดิม และแสดงผลออบเจ็กต์ EvaluationRunMetric ที่มี CustomCodeExecutionSpec
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
บริการประเมิน Gen AI จะเรียกใช้โค้ดนั้นในสภาพแวดล้อมการดำเนินการแบบแซนด์บ็อกซ์ และจะส่งข้อมูลการประเมินไปยังสภาพแวดล้อมดังกล่าว
เพิ่มเมตริกและโค้ดการประเมิน
เพิ่มโค้ดต่อไปนี้ลงใน evaluator/evaluate_agent.py หลังบรรทัด if __name__ == "__main__":
โดยจะกำหนดรายการเมตริกสำหรับเอเจนต์ Researcher และเรียกใช้การประเมิน
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
ในไปป์ไลน์การผลิตจริง คุณต้องมีเกณฑ์ความสำเร็จในการประเมิน เมื่อการประเมินเสร็จสิ้นและเมตริกพร้อมใช้งาน คุณจะมีขั้นตอนการควบคุมที่นี่ เช่น "หากคะแนน Final Response Match น้อยกว่า 0.75 ให้สร้างไม่สำเร็จ" ซึ่งจะช่วยป้องกันไม่ให้เวอร์ชันที่ไม่ดีได้รับการเข้าชม
เพิ่มโค้ดต่อไปนี้ใน evaluator/evaluate_agent.py
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
เมื่อใดก็ตามที่ค่าเฉลี่ยของเมตริกการประเมินใดก็ตามต่ำกว่าเกณฑ์ (0.75) การติดตั้งใช้งานควรล้มเหลว
[ไม่บังคับ] เพิ่มการประเมินด้วยเมตริกแบบไม่ต้องอ้างอิงสำหรับ Orchestrator
สำหรับตัวแทน Orchestrator การโต้ตอบจะซับซ้อนกว่า และเราอาจไม่มีคำตอบที่ "ถูกต้อง" เพียงคำตอบเดียวเสมอไป แต่เราจะประเมินพฤติกรรมทั่วไปโดยใช้เมตริกที่ไม่ต้องอ้างอิงอย่างใดอย่างหนึ่งแทน
- การหลอน: เมตริกตามคะแนนที่ตรวจสอบความถูกต้องและความสอดคล้องของคำตอบที่เป็นข้อความโดยการแบ่งคำตอบออกเป็นข้อกล่าวอ้างย่อยๆ โดยจะตรวจสอบว่าคำกล่าวอ้างแต่ละรายการมีมูลความจริงหรือไม่โดยอิงตามการใช้เครื่องมือในเหตุการณ์ระดับกลาง ซึ่งเป็นสิ่งสำคัญสำหรับเอเจนต์แบบปลายเปิดที่ "ความถูกต้อง" เป็นเรื่องอัตวิสัย แต่ "ความจริง" เป็นสิ่งที่ต่อรองไม่ได้ คะแนนจะคำนวณเป็นเปอร์เซ็นต์ของการอ้างสิทธิ์ที่อิงตามเนื้อหาต้นฉบับ ในกรณีของเรา เราคาดหวังว่าคำตอบสุดท้ายจาก Orchestrator (ที่ Content Builder สร้างขึ้น) จะอิงตามข้อเท็จจริงในเนื้อหาที่ Researcher ดึงข้อมูลโดยใช้เครื่องมือค้นหาของ Wikipedia
เพิ่มตรรกะการประเมินสำหรับ Orchestrator
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
ตรวจสอบข้อมูลการประเมิน
เปิดไดเรกทอรี evaluator/ คุณจะเห็นไฟล์ข้อมูล 2 ไฟล์ ได้แก่
eval_data_researcher.json: พรอมต์และข้อมูลอ้างอิงที่ถูกต้อง/ข้อมูลอ้างอิงภาคพื้นสำหรับนักวิจัยeval_data_orchestrator.json: พรอมต์สำหรับ Orchestrator (เราจะทำการประเมินแบบไม่มีการอ้างอิงสำหรับ Orchestrator เท่านั้น)
โดยปกติแล้วแต่ละรายการจะมีข้อมูลต่อไปนี้
prompt: พรอมต์สำหรับตัวแทนreference: คำตอบที่เหมาะสม (ความจริงพื้นฐาน) หากมีreference_trajectory: ลำดับการเรียกใช้เครื่องมือที่คาดไว้
6. ทำความเข้าใจรหัสการประเมิน
เปิด shared/evaluation/evaluate.py โมดูลนี้มีตรรกะหลักสำหรับการเรียกใช้การประเมิน ฟังก์ชันหลักคือ evaluate_agent
โดยจะดำเนินการตามขั้นตอนต่อไปนี้
- การโหลดข้อมูล: อ่านชุดข้อมูลการประเมิน (พรอมต์และข้อมูลอ้างอิง) จากไฟล์
- การอนุมานแบบขนาน: เรียกใช้เอเจนต์กับชุดข้อมูลแบบขนาน โดยจะจัดการการสร้างเซสชัน ส่งพรอมต์ และบันทึกทั้งคำตอบสุดท้ายและการติดตามการดำเนินการเครื่องมือระดับกลาง
- การประเมิน Vertex AI: ผสานข้อมูลการประเมินเดิมเข้ากับคำตอบสุดท้ายและร่องรอยการดำเนินการเครื่องมือระดับกลาง แล้วส่งผลลัพธ์ไปยังบริการประเมิน Vertex AI ด้วยไคลเอ็นต์ GenAI ใน Vertex AI SDK บริการนี้จะเรียกใช้เมตริกที่กำหนดค่าไว้เพื่อประเมินประสิทธิภาพของตัวแทน
ช่วงเวลาสำคัญของขั้นตอนสุดท้ายคือการเรียกใช้create_evaluation_runฟังก์ชันของโมดูล eval ของ Gen AI SDK
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
โดยเราจะทำเช่นนี้ในฟังก์ชัน evaluate_agent ใน shared/evaluation/evaluate.py
โดยจะรับชุดข้อมูลการประเมินที่ผสาน ข้อมูลเกี่ยวกับเอเจนต์ เมตริกที่จะใช้ และ URI ของที่เก็บข้อมูลปลายทาง ฟังก์ชันจะสร้างการเรียกใช้การประเมินในบริการประเมินของ Vertex AI และแสดงผลออบเจ็กต์การเรียกใช้การประเมิน
Agent Info API
บริการประเมินต้องทราบการกำหนดค่าของเอเจนต์ (คำสั่งของระบบ คำอธิบาย และเครื่องมือที่พร้อมใช้งาน) เพื่อทำการประเมินได้อย่างถูกต้อง เราจะส่งไปยัง create_evaluation_run เป็นพารามิเตอร์ agent_info
แต่เราจะรับข้อมูลนี้ได้อย่างไร เราจะรวมไว้ใน ADK Service API
เปิด shared/adk_app.py แล้วค้นหา def agent_info คุณจะเห็นว่าแอปพลิเคชัน ADK แสดงปลายทางผู้ช่วย
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
ปลายทางนี้ (เปิดใช้ผ่านแฟล็ก --publish_agent_info) ช่วยให้สคริปต์การประเมินดึงข้อมูลการกำหนดค่ารันไทม์ของ Agent แบบไดนามิกได้ ซึ่งเป็นสิ่งสำคัญสำหรับเมตริกที่ประเมินการใช้เครื่องมือ เนื่องจากโมเดลผู้ตัดสินจะประเมินการใช้เครื่องมือของเอเจนต์ได้ดีขึ้นหากทราบว่าเครื่องมือใดบ้างที่เอเจนต์ใช้ได้ระหว่างการสนทนาโดยเฉพาะ
7. ทำการประเมิน
เมื่อติดตั้งใช้งานเครื่องมือประเมินแล้ว ก็มาดำเนินการกันเลย
- เรียกใช้สคริปต์การประเมินจากรูทของที่เก็บโดยใช้คำสั่งต่อไปนี้
./evaluate.sh- ซึ่งจะรับแฮชคอมมิต Git ปัจจุบัน
- ซึ่งจะเรียกใช้
deploy.shเพื่อติดตั้งใช้งานรีวิชันที่มีแท็กตามแฮชการคอมมิต - เมื่อติดตั้งใช้งานแล้ว ระบบจะเริ่ม
evaluator.evaluate_agent - คุณจะเห็นแถบความคืบหน้าขณะที่ระบบเรียกใช้กรณีทดสอบกับบริการระบบคลาวด์
- สุดท้ายจะพิมพ์ JSON สรุปของผลลัพธ์
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
หมายเหตุ: การเรียกใช้ครั้งแรกอาจใช้เวลา 2-3 นาทีในการติดตั้งใช้งานบริการ
8. แสดงภาพผลลัพธ์ใน Notebook
เอาต์พุต JSON แบบดิบอ่านยาก ไคลเอ็นต์ Gen AI ใน Vertex AI SDK มีวิธีติดตามการเรียกใช้เหล่านี้เมื่อเวลาผ่านไป เราจะใช้ Colab Notebook เพื่อแสดงผลลัพธ์เป็นภาพ
- เปิด
evaluator/show_evaluation_run.ipynbใน Google Colab โดยใช้ลิงก์นี้ - ตั้งค่าตัวแปร
GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_REGIONและEVAL_RUN_IDเป็นรหัสโปรเจ็กต์ ภูมิภาค และรหัสการเรียกใช้
- ติดตั้งการอ้างอิงและตรวจสอบสิทธิ์
เรียกใช้การประเมินและแสดงผลลัพธ์
เราต้องดึงข้อมูลการเรียกใช้การประเมินจาก Vertex AI ค้นหาเซลล์ในส่วนเรียกใช้การประเมินและแสดงผลลัพธ์ แล้วแทนที่บรรทัด # TODO ด้วยโค้ดบล็อกต่อไปนี้
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
การตีความผลลัพธ์
เมื่อดูผลลัพธ์ โปรดคำนึงถึงสิ่งต่อไปนี้
- การเกิดปัญหาซ้ำเทียบกับความสามารถ:
- การถดถอย: คะแนนลดลงในการทดสอบเก่าหรือไม่ (ไม่ดี ต้องตรวจสอบ)
- ความสามารถ: คะแนนในการทดสอบใหม่ดีขึ้นไหม (ดี นี่คือความคืบหน้า)
- การวิเคราะห์ความล้มเหลว: อย่าดูแค่คะแนน
- ดูการติดตาม Assistant เรียกใช้เครื่องมือผิดหรือไม่ แยกวิเคราะห์เอาต์พุตไม่สำเร็จใช่ไหม คุณจะดูข้อบกพร่องได้ที่นี่
- ดูคำอธิบายและผลการตัดสินที่ LLM ผู้ตัดสินให้ไว้ ซึ่งมักจะช่วยให้คุณทราบสาเหตุที่การทดสอบไม่สำเร็จ
Pass@1 เทียบกับ Pass@k: เมื่อเรียกใช้การทดสอบหนึ่งๆ 1 ครั้ง เราจะได้คะแนน Pass@1 หากตัวแทนทำงานไม่สำเร็จ อาจเป็นเพราะการทำงานแบบไม่แน่นอน ในการตั้งค่าที่ซับซ้อน คุณอาจเรียกใช้การทดสอบแต่ละครั้ง k ครั้ง (เช่น 5 ครั้ง) และคำนวณ pass@k (สำเร็จอย่างน้อย 1 ครั้งไหม) หรือ pass^k (สำเร็จทุกครั้งไหม) ซึ่งเป็นสิ่งที่เมตริกจำนวนมากทำอยู่แล้วเบื้องหลัง เช่น types.RubricMetric.FINAL_RESPONSE_MATCH (การจับคู่คำตอบสุดท้าย) จะเรียกใช้ LLM ผู้ตัดสิน 5 ครั้งเพื่อกำหนดคะแนนการจับคู่คำตอบสุดท้าย
9. การรวมและการติดตั้งใช้งานอย่างต่อเนื่อง (CI/CD)
ในระบบการใช้งานจริง การประเมินเอเจนต์ควรทำงานเป็นส่วนหนึ่งของไปป์ไลน์ CI/CD Cloud Build เป็นตัวเลือกที่ดีสำหรับกรณีนี้
สำหรับการคอมมิตทุกรายการที่พุชไปยังที่เก็บโค้ดของ Agent ระบบจะเรียกใช้การประเมินพร้อมกับการทดสอบอื่นๆ หากผ่าน การติดตั้งใช้งานจะ "ได้รับการเลื่อนขั้น" ให้บริการคำขอของผู้ใช้ หากการทดสอบล้มเหลว ทุกอย่างจะยังคงเหมือนเดิม แต่ผู้พัฒนาจะดูได้ว่าเกิดข้อผิดพลาดตรงไหน
การกำหนดค่า Cloud Build
ตอนนี้มาสร้างสคริปต์การกำหนดค่าการติดตั้งใช้งาน Cloud Run ที่ทำตามขั้นตอนต่อไปนี้กัน
- Deploy Services ไปยังรีวิชันส่วนตัว
- เรียกใช้การประเมิน Agent
- หากการประเมินผ่าน ระบบจะ "เลื่อนระดับ" การติดตั้งใช้งานรีวิชันให้แสดงการรับส่งข้อมูล 100%
สร้าง cloudbuild.yaml:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
การเรียกใช้ไปป์ไลน์
สุดท้าย เราจะเรียกใช้ไปป์ไลน์การประเมิน
ก่อนที่จะเรียกใช้ไปป์ไลน์การประเมินที่ส่งคำขอไปยังบริการ Cloud Run เราต้องมีบัญชีบริการแยกต่างหากที่มีสิทธิ์หลายอย่าง มาเขียนสคริปต์ที่ทำเช่นนั้นและเปิดใช้ไปป์ไลน์กัน
- สร้างสคริปต์
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- สร้างบัญชีบริการเฉพาะ
agent-eval-build-sa - มอบบทบาทที่จำเป็น (
roles/run.admin,roles/aiplatform.userและอื่นๆ) * ส่งบิลด์ไปยัง Cloud Build
- สร้างบัญชีบริการเฉพาะ
- เรียกใช้ไปป์ไลน์
chmod +x run_cloud_build.sh ./run_cloud_build.sh
คุณดูความคืบหน้าในการสร้างได้ในเทอร์มินัลหรือคลิกลิงก์ไปยัง Cloud Console
หมายเหตุ: ในสภาพแวดล้อมการใช้งานจริง คุณจะต้องตั้งค่าทริกเกอร์ Cloud Build เพื่อเรียกใช้โดยอัตโนมัติในทุก git push เวิร์กโฟลว์จะเหมือนเดิม โดยทริกเกอร์จะเรียกใช้ cloudbuild.yaml เพื่อให้มั่นใจว่าทุกการคอมมิตจะได้รับการประเมิน
10. สรุป
คุณสร้างไปป์ไลน์การประเมินเรียบร้อยแล้ว
- การติดตั้งใช้งาน: คุณใช้แท็กการแก้ไขที่มีแฮชการคอมมิต Git เพื่อติดตั้งใช้งานเอเจนต์ในสภาพแวดล้อมจริงอย่างปลอดภัยสำหรับการทดสอบโดยไม่ส่งผลกระทบต่อการติดตั้งใช้งานจริง
- การประเมิน: คุณกำหนดเมตริกการประเมินและทำให้กระบวนการประเมินเป็นแบบอัตโนมัติโดยใช้บริการ Gen AI Evaluation ของ Vertex AI
- การวิเคราะห์: คุณใช้สมุดบันทึก Colab เพื่อแสดงผลลัพธ์การประเมินและปรับปรุงเอเจนต์
- การเปิดตัว: คุณใช้ Cloud Build เพื่อเรียกใช้ไปป์ไลน์การประเมินโดยอัตโนมัติ และโปรโมตรีวิชันที่ดีที่สุดเพื่อแสดงต่อการเข้าชม 100%
วงจรแก้ไขโค้ด -> ติดตั้งใช้งานแท็ก -> เรียกใช้การประเมินและการทดสอบ -> วิเคราะห์ -> เปิดตัว -> ทำซ้ำนี้เป็นหัวใจสำคัญของการสร้างเอเจนต์ระดับโปรดักชัน