
1. 简介
概览
本实验是使用 ADK 构建多智能体系统的后续实验。
在该实验中,您构建了一个课程创建系统,该系统包含:
- 研究员智能体:使用 google_search 查找最新信息。
- Judge Agent:批判性地评估研究的质量和完整性。
- Content Builder Agent:将研究转化为结构化课程。
- Orchestrator Agent:管理这些专家之间的工作流和通信。
它还包含一个 Web 应用,可让用户提交课程创建请求,并获得课程作为响应。
研究员、评判员和内容构建器作为单独 Cloud Run 服务中的 A2A 代理进行部署。编排器是另一个具有 ADK 服务 API 的 Cloud Run 服务。
在本实验中,我们修改了 Researcher 代理,使其使用 Wikipedia Search 工具,而不是 Gemini 的 Google 搜索 功能。它使我们能够检查自定义工具调用的跟踪和评估方式。
因此,我们构建了一个分布式多智能体系统。但我们如何知道它是否真的有效呢?研究者是否总能找到相关信息?法官是否正确识别了不良研究?
在本实验中,您将使用 Vertex AI Gen AI Evaluation Service,以数据驱动的评估取代主观的“氛围检查”。您将实现自适应评分准则和工具使用质量指标,以严格评估在实验 1 中构建的分布式多智能体系统。最后,您将在 CI/CD 流水线中自动执行此流程,确保每次部署都能保持生产环境代理的可靠性和准确性。
您将为智能体构建一个持续评估流水线。您将学习如何:
- 将代理部署到 Google Cloud Run 中的私有已标记的修订版本(影子部署)。
- 使用 Vertex AI Gen AI Evaluation Service 针对该特定修订版本运行自动化评估套件。
- 直观呈现和分析结果。
- 将评估作为 CI/CD 流水线的一部分。
2. 核心概念:智能体评估理论
在开发和运行 AI Agent 时,我们会进行两种评估:离线实验和通过自动化回归测试进行持续评估。第一个是开发过程的创意引擎,我们在这里运行临时实验、优化提示并快速迭代,以解锁新功能。第二层是 CI/CD 流水线中的防御层,我们针对“黄金”数据集执行持续评估,以确保任何代码更改都不会无意中降低代理的既有质量。
根本区别在于发现与防御:
- 线下实验是一个优化过程。它是开放式且可变的。您正在积极更改输入内容(提示、模型、参数),以最大限度地提高得分或解决特定问题。目标是提高智能体可执行操作的“上限”。
- 持续评估(自动化回归测试)是一种验证流程。它僵硬且重复。您将输入保持不变(“黄金”数据集),以确保输出保持稳定。目的是防止效果“下限”崩溃。
在本实验中,我们将重点介绍持续评估。我们将开发一个自动化回归测试流水线,该流水线应在每次有人更改 AI 代理时运行,就像那些单元测试一样。
在编写代码之前,务必要了解我们要衡量什么。
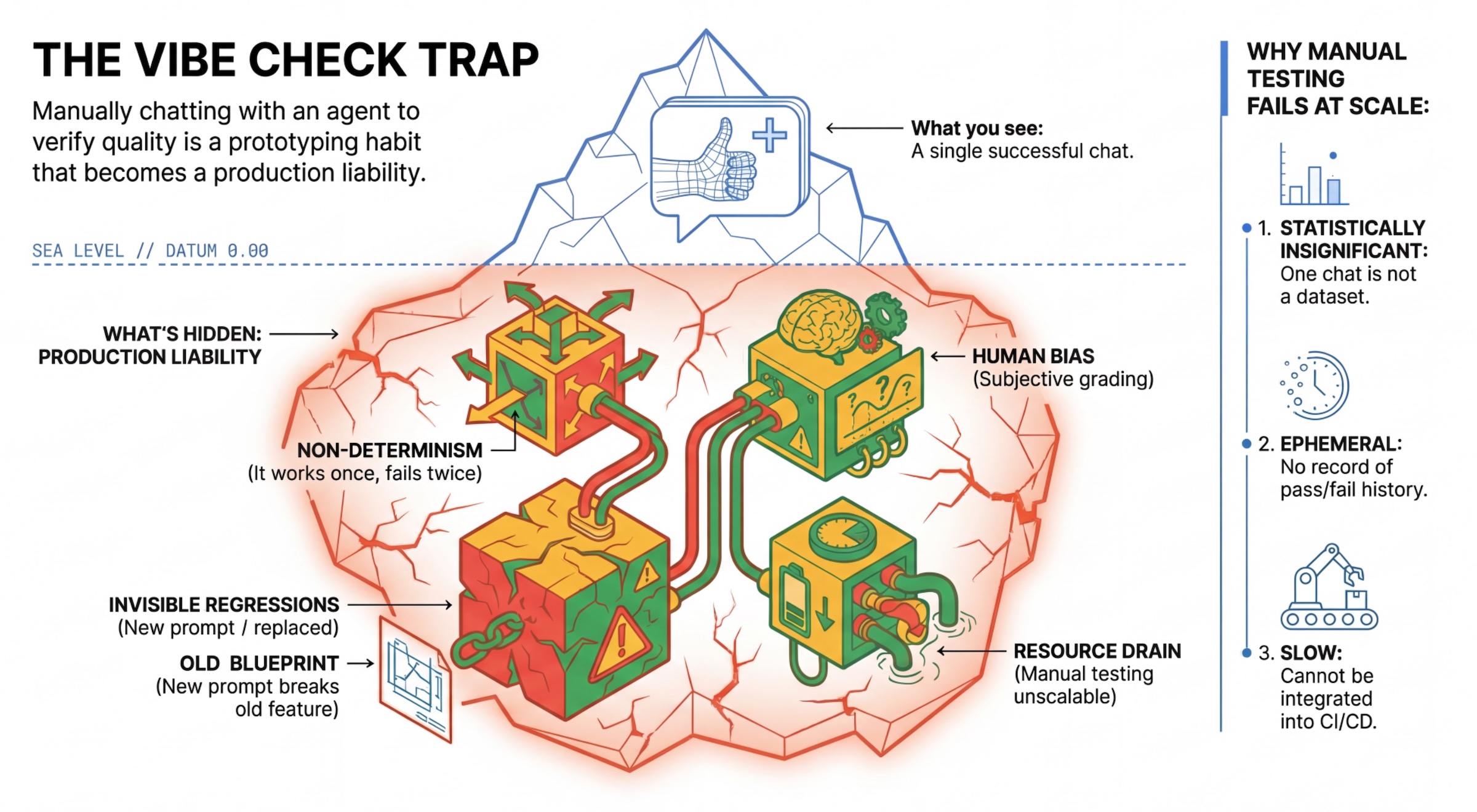
“氛围检查”陷阱
许多开发者通过手动与智能体对话来测试智能体。这称为“氛围检查”。虽然此方法对于原型设计很有用,但在生产环境中会失败,因为:
- 不确定性:智能体每次的回答可能都不一样。您需要具有统计显著性的样本规模。
- 隐形回归:改进一个提示可能会破坏另一个使用情形。
- 人为偏差:“看起来不错”是主观判断。
- 耗时的工作:每次提交代码时手动测试数十个场景非常缓慢。
评估代理表现的两种方法
为了构建稳健的流水线,我们结合了不同类型的评分器:
- 基于代码的评分器(确定性):
- 衡量指标:严格的限制条件(例如“是否返回了有效的 JSON?”、“它是否调用了
search工具?”)。 - 优点:快速、便宜、100% 准确。
- 缺点:无法判断细微差别或质量。
- 衡量指标:严格的限制条件(例如“是否返回了有效的 JSON?”、“它是否调用了
- 基于模型的评分器(概率性):
- 也称为“LLM-as-a-Judge”。我们使用强大的模型(例如 Gemini 3 Pro)来评估智能体的输出。
- 衡量指标:细致性、推理能力、实用性、安全性。
- 优点:可以评估复杂的开放式任务。
- 缺点:速度较慢,成本较高,需要针对评判模型进行仔细的提示工程。
Vertex AI 评估指标
在本实验中,我们将使用 Vertex AI Gen AI Evaluation Service,该服务提供受管指标,因此您不必从头开始编写每个评判器。
您可以通过多种方式对用于评估智能体的指标进行分组:
- 基于评分准则的指标:将 LLM 纳入评估工作流。
- 自适应评分准则:系统会针对每个提示动态生成评分准则。系统会使用特定于提示的精细且可解释的通过或未通过反馈,对回答进行评估。
- 静态评分准则:明确定义评分准则,并对所有提示应用相同的评分准则。系统会使用同一组基于数值评分的评估器来评估回答。每个提示会获得单一的数值得分(例如 1-5)。这适用于需要针对非常具体的维度进行评估,或者需要对所有提示使用完全相同的评分准则的情况。
- 基于计算的指标:使用确定性算法评估回答(通常使用标准答案)。每个提示会获得一个数值得分(例如 0.0-1.0)。这适用于有标准答案可用且可以通过确定性方法进行匹配的情况。
- 自定义函数指标:通过 Python 函数定义您自己的指标。
我们将使用的具体指标:
Final Response Match:(基于参考答案)回答是否与我们的“标准答案”一致?Tool Use Quality:(无参考)智能体是否以适当的方式使用了相关工具?Hallucination:(无参考)回答中的声明是否得到检索到的上下文的支持?Tool Trajectory Precision和Tool Trajectory Recall(基于参考答案)智能体是否选择了正确的工具并提供了有效的实参?与Tool Use Quality不同,这些自定义指标使用参考轨迹(一系列预期工具调用和参数)。
3. 设置
配置
- 打开 Cloud Shell:点击 Google Cloud 控制台右上角的激活 Cloud Shell 图标。
- 运行以下命令以刷新登录信息并更新应用默认凭证 (ADC):
gcloud auth login --update-adc - 为 gcloud CLI 设置有效项目。运行以下命令以获取当前的 gcloud 项目:
gcloud config get-value projectgcloud config set project YOUR_PROJECT_IDYOUR_PROJECT_ID替换为您的项目 ID。 - 设置 Cloud Run 服务将部署到的默认区域。
gcloud config set run/region us-west1us-west1。
代码和依赖项
- 克隆起始代码并将目录更改为项目的根目录。
cd ~ git clone https://github.com/vladkol/agent-evaluation-lab -b starter cd agent-evaluation-lab - 创建
.env文件:echo "GOOGLE_GENAI_USE_VERTEXAI=true" > .env echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> .env echo "GOOGLE_CLOUD_REGION=$(gcloud config get-value run/region -q)" >> .env echo "GOOGLE_CLOUD_LOCATION=global" >> .env - 在终端窗口中运行以下命令,以安装依赖项:
uv sync
4. 了解安全部署
在评估之前,我们需要进行部署。但我们不希望新代码出现问题时,导致正在运行的应用崩溃。
修订版本标记和影子部署
Google Cloud Run 支持修订版本。每次部署时,系统都会创建一个新的不可变的修订版本。您可以为这些修订版本分配标记,以便通过特定网址访问它们,即使它们接收的公开流量为 0%。
为什么不直接在本地运行评估?
虽然 ADK 支持本地评估,但部署到隐藏修订版本可为生产系统带来关键优势。这使得系统级评估(我们正在做的事情)与单元测试区分开来:
- 环境对等性:本地环境不同(不同的网络、不同的 CPU/内存、不同的 Secret)。在云端进行测试可确保您的代理在实际的运行时环境(系统测试)中正常运行。
- 多智能体交互:在分布式系统中,智能体通过 HTTP 进行通信。“本地”测试通常会模拟这些连接。影子部署会测试微服务之间的实际网络延迟时间、超时配置和身份验证。
- Secret 和权限:它会验证您的服务账号是否确实拥有所需的权限(例如,调用 Vertex AI 或从 Firestore 读取数据的权限)。
注意:这是主动评估(在用户看到之前进行检查)。部署后,您可以使用被动监控(可观测性)来捕获实际存在的问题。
CI/CD 工作流:部署、评估、升级
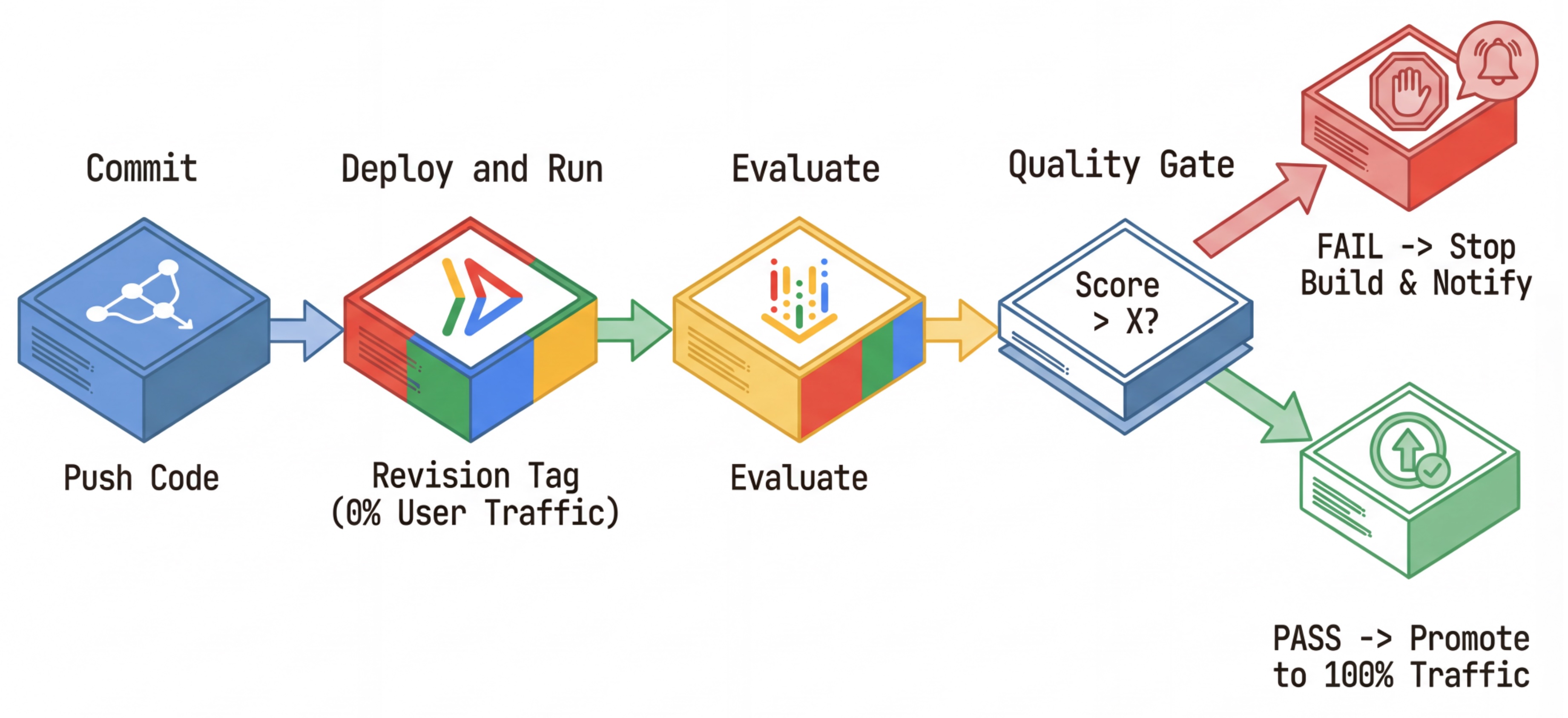
我们使用此功能来构建强大的持续部署流水线:
- 提交:您更改了代理的提示,并将其推送到代码库。
- 部署(隐藏):触发部署标记有提交哈希(例如
c-abc1234)的新修订版本。此修订版本接收 0% 的公开流量。 - 评估:评估脚本以特定修订版本网址
https://c-abc1234---researcher-xyz.run.app为目标。 - 升级:如果(且仅当)评估通过且其他测试成功,您才能将流量迁移到此新修订版本。
- 回滚:如果回滚失败,用户从未看到过错误版本,您可以直接忽略或删除错误修订版本。
借助此策略,您可以在生产环境中进行测试,而不会影响客户。
分析 evaluate.sh
打开 evaluate.sh。此脚本可自动执行该流程。
export COMMIT_SHORT_HASH=$(git rev-parse --short HEAD)
export COMMIT_REVISION_TAG="c-${COMMIT_SHORT_HASH}"
# ...
# Deploy services with a revision tag and NO traffic
source ./deploy.sh --revision-tag $COMMIT_REVISION_TAG --no-redeploy
# Run the evaluation against that specific tag
uv run -m evaluator.evaluate_agent
deploy.sh 会使用 --no-traffic 和 --tag 选项处理修订版本部署。如果已有正在运行的服务,则不会受到影响。除非您使用包含修订版本标记(例如 https://c-abc1234---researcher-xyz.run.app)的特殊网址明确调用新的“隐藏”修订版本,否则该修订版本不会接收任何流量
5. 实现评估脚本
现在,我们来编写实际运行测试的代码。
- 打开
evaluator/evaluate_agent.py。 - 您会看到导入和设置,但缺少指标和执行逻辑。
定义指标
对于 Researcher Agent,我们有包含预期答案的“标准答案”/“评估依据答案”。这是能力评估:我们正在衡量代理是否能正确完成工作。
我们希望衡量:
- 最终回答匹配:(能力)回答是否与预期回答一致?这是一个基于参考的指标。它使用评判 LLM 将智能体的输出与预期答案进行比较。它并不要求答案完全相同,但要求在语义和事实上相似。
- 工具使用质量:(质量)一项针对性自适应评分准则指标,用于评估工具选择的恰当性、参数使用的正确性,以及是否遵循了指定的操作顺序。
- 工具使用轨迹:(轨迹)2 个自定义指标,用于衡量智能体的工具使用轨迹(精确率和召回率)与预期轨迹的对比情况。这些指标在
shared/evaluation/tool_metrics.py中以自定义函数的形式实现。与工具使用质量不同,此指标是确定性的基于参考的指标 - 代码实际上会检查实际的工具调用是否与参考数据(评估数据中的reference_trajectory)匹配。
自定义工具使用轨迹指标
对于自定义的“工具使用轨迹”指标,我们在 shared/evaluation/tool_metrics.py 中创建了一组 Python 函数。为了让 Vertex AI Gen AI Evaluation Service 执行这些函数,我们需要将该 Python 代码传递给它。
为此,请定义一个包含 UnifiedMetric 和 CustomCodeExecutionSpec 配置的 EvaluationRunMetric 对象。形参 remote_custom_function 是一个包含函数 Python 代码的字符串。该函数必须命名为 evaluate:
def evaluate(
instance: dict
) -> float:
...
我们创建了一个 get_custom_function_metric 辅助函数(位于 shared/evaluation/evaluate.py 中),用于将 Python 函数转换为自定义代码评估指标。
它会获取函数模块的代码(以捕获本地依赖项),创建一个调用原始函数的额外 evaluate 函数,并返回一个包含 CustomCodeExecutionSpec 的 EvaluationRunMetric 对象。
import inspect
module_source = inspect.getsource(
inspect.getmodule(metrics_function)
)
module_source += (
"\n\ndef evaluate(instance: dict) -> float:\n"
f" return {metrics_function.__name__}(instance)\n"
)
return types.EvaluationRunMetric(
metric=metric_name,
metric_config=types.UnifiedMetric(
custom_code_execution_spec=types.CustomCodeExecutionSpec(
remote_custom_function=module_source
)
)
)
Gen AI Evaluation Service 将在沙盒执行环境中执行该代码,并将评估数据传递给该代码。
添加指标和评估代码
在 if __name__ == "__main__": 行之后,将以下代码添加到 evaluator/evaluate_agent.py。
它定义了 Researcher 代理的指标列表,并运行评估。
eval_data_researcher = os.path.dirname(__file__) + "/eval_data_researcher.json"
metrics=[
# Compares the agent's output against a "Golden Answer"
types.RubricMetric.FINAL_RESPONSE_MATCH,
# Did the agent use the tools effectively?
types.RubricMetric.TOOL_USE_QUALITY,
# Custom metrics for tools trajectory analysis
get_custom_function_metric("trajectory_precision", trajectory_precision_func),
get_custom_function_metric("trajectory_recall", trajectory_recall_func)
]
print("🧪 Running Researcher Evaluation...")
eval_results = asyncio.run(
# Run the evaluation and retrieve the results.
evaluate_agent(
agent_api_server=RESEARCHER_URL, # Agent Service URL (in Cloud Run).
agent_name="agent", # Agent name as it's exposed by the server.
evaluation_data_file=eval_data_researcher, # Evaluation data file.
# GCS location for the Evaluation Service to store the result to.
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics, # Metrics to use when evaluating the agent.
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
)
)
print(f"\n🧪 Researcher Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
在实际的生产流水线中,您需要评估成功标准。评估完成后,指标即可使用。您可以在此处添加门控步骤。例如:“如果 Final Response Match 得分低于 0.75,则构建失败。”这样可以防止不良修订版本接收流量。
将以下代码附加到 evaluator/evaluate_agent.py:
METRIC_THRESHOLD = 0.75
researcher_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Researcher Evaluation failed with state {eval_results.state}.")
researcher_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Researcher Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
researcher_eval_failed = True
if researcher_eval_failed:
exit(1)
只要任何评估指标的平均值低于某个阈值 (0.75),部署就应失败。
[可选] 为编排器添加使用无参考指标的评估
对于 Orchestrator Agent,互动会更复杂,我们可能并不总能找到唯一的“正确”答案。相反,我们会使用无参考指标之一来评估一般行为。
- 幻觉:一种基于得分的指标,可将文本回答拆解为最基本的“原子声明”,以检查文本回答的真实性和一致性。它会根据中间事件中的工具使用情况,验证每项声明是否有据可依。对于开放式智能体而言,这一点至关重要,因为“正确性”是主观的,但“真实性”是不可妥协的。得分的计算方式为:基于来源内容的声明所占的百分比。在我们的示例中,我们希望 Orchestrator(由 Content Builder 生成)的最终回答在事实上基于 Researcher 使用 Wikipedia Search 工具检索到的内容。
为 Orchestrator 添加评估逻辑:
eval_data_orchestrator = os.path.dirname(__file__) + "/eval_data_orchestrator.json"
metrics=[
types.RubricMetric.HALLUCINATION,
]
print("🧪 Running Orchestrator Evaluation...")
eval_results = asyncio.run(evaluate_agent(
agent_api_server=ORCHESTRATOR_URL,
agent_name="agent",
evaluation_data_file=eval_data_orchestrator,
evaluation_storage_uri=f"gs://{GOOGLE_CLOUD_PROJECT}-agents/evaluation",
metrics=metrics,
project_id=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION
))
print(f"\n🧪 Orchestrator Evaluation results:\n{eval_results}")
print(f"Evaluation Run ID: {eval_results.run_id}")
METRIC_THRESHOLD = 0.75
orchestrator_eval_failed = False
if eval_results.state != types.EvaluationRunState.SUCCEEDED:
print(f"🛑 Orchestrator Evaluation failed with state {eval_results.state}.")
orchestrator_eval_failed = True
else:
for metric_name, metric_values in eval_results.metrics.items():
if metric_values["mean"] < METRIC_THRESHOLD:
print(f"🛑 Orchestrator Evaluation failed with metric `{metric_name}` below {METRIC_THRESHOLD} threshold.")
orchestrator_eval_failed = True
if orchestrator_eval_failed:
exit(1)
检查评估数据
打开 evaluator/ 目录。您会看到两个数据文件:
eval_data_researcher.json:研究人员的提示和黄金/标准答案。eval_data_orchestrator.json:Orchestrator 的提示(我们仅对 Orchestrator 执行无参考评估)。
每个条目通常包含以下内容:
prompt:代理的提示。reference:理想答案(实际情况),如果适用。reference_trajectory:预期工具调用序列。
6. 了解评估代码
打开 shared/evaluation/evaluate.py。此模块包含用于运行评估的核心逻辑。关键函数是 evaluate_agent。
它会执行以下步骤:
- 数据加载:从文件中读取评估数据集(提示和参考)。
- 并行推理:针对数据集并行运行代理。它负责处理会话创建、发送提示,并捕获最终回答和中间工具执行轨迹。
- Vertex AI Evaluation:它会将原始评估数据与最终回答和中间工具执行轨迹合并,并通过 Vertex AI SDK 中的 GenAI 客户端将结果提交给 Vertex AI Evaluation Service。此服务会运行配置的指标来评定代理的性能。
最后一步的关键时刻是调用 Gen AI SDK 的评估模块的 create_evaluation_run 函数:
evaluation_run = client.evals.create_evaluation_run(
dataset=agent_dataset_with_inference,
agent_info=agent_info,
metrics=metrics,
dest=evaluation_storage_uri
)
我们在 shared/evaluation/evaluate.py 中的 evaluate_agent 函数中执行此操作。
它会获取合并的评估数据集、有关代理的信息、要使用的指标以及目标存储 URI。该函数会在 Vertex AI Evaluation Service 中创建评估运行,并返回评估运行对象。
Agent Info API
为了进行准确的评估,评估服务需要了解智能体的配置(系统指令、说明和可用工具)。我们将其作为 agent_info 参数传递给 create_evaluation_run。
但我们如何获取这些信息呢?我们将其纳入 ADK 服务 API。
打开 shared/adk_app.py 并搜索 def agent_info。您会看到 ADK 应用公开了一个辅助端点:
@app.get("/apps/{agent_name}/agent-info")
async def agent_info(agent_name: str) -> typing.Dict[str, typing.Any]:
# ...
return {
"name": agent.name,
"instruction": str(getattr(agent, "instruction", None)),
"tool_declarations": tools_dict_list
}
此端点(通过 --publish_agent_info 标志启用)允许评估脚本动态提取代理的运行时配置。这对于评估工具使用情况的指标至关重要,因为如果评判模型明确知道在对话期间代理可以使用哪些工具,就可以更好地评估代理的工具使用情况。
7. 运行评估
现在,您已实现评估器,接下来我们来运行它!
- 从代码库的根目录运行评估脚本:
./evaluate.sh- 它会获取您当前的 Git 提交哈希值。
- 它会调用
deploy.sh来部署具有基于提交哈希的标记的修订版本。 - 部署完成后,它会启动
evaluator.evaluate_agent。 - 系统针对您的云服务运行测试用例时,您会看到进度条。
- 最后,它会打印结果的 JSON 摘要。
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
注意:首次运行可能需要几分钟时间来部署服务。
8. 在笔记本中直观呈现结果
原始 JSON 输出难以解读。Vertex AI SDK 中的生成式 AI 客户端提供了一种随时间推移跟踪这些运行的方法。我们将使用 Colab 笔记本直观呈现结果。
- 使用此链接在 Google Colab 中打开
evaluator/show_evaluation_run.ipynb。 - 将
GOOGLE_CLOUD_PROJECT、GOOGLE_CLOUD_REGION和EVAL_RUN_ID变量设置为您的项目 ID、区域和运行 ID。
- 安装依赖项并进行身份验证。
检索评估运行并显示结果
我们需要从 Vertex AI 获取评估运行数据。找到 Retrieve Evaluation Run and Display Results 下方的单元格,并将 # TODO 行替换为以下代码块:
from google.genai import types as genai_types
from vertexai import Client
# Initialize SDK
client = Client(
project=GOOGLE_CLOUD_PROJECT,
location=GOOGLE_CLOUD_REGION,
http_options=genai_types.HttpOptions(api_version="v1beta1"),
)
evaluation_run = client.evals.get_evaluation_run(
name=EVAL_RUN_ID,
include_evaluation_items=True
)
evaluation_run.show()
解读结果
查看结果时,请注意以下几点:
- 回归与功能:
- 回归:旧版测试的得分是否有所下降?(不理想,需要调查)。
- 能力:新测试的分数是否有所提高?(很好,这是进步)。
- 失败分析:不要只关注得分。
- 查看 trace。它是否调用了错误的工具?是否未能解析输出?您可以在此处查找 bug。
- 查看法官 LLM 提供的说明和判决。它们通常能让您大致了解测试失败的原因。
Pass@1 与 Pass@k:运行一次特定测试时,我们会获得 Pass@1 分数。如果代理失败,可能是由于不确定性。在复杂的设置中,您可能需要运行每项测试 k 次(例如 5 次),并计算 pass@k(是否至少成功一次?)或 pass^k(是否每次都成功?)。许多指标在后台已经实现了这一点。例如,types.RubricMetric.FINAL_RESPONSE_MATCH(最终回答匹配)会调用 5 次评判 LLM 来确定最终回答匹配得分。
9. 持续集成和部署 (CI/CD)
在生产系统中,应将智能体评估作为 CI/CD 流水线的一部分来运行。Cloud Build 是一个不错的选择。
对于推送到代理的代码库的每次提交,评估将与其余测试一起运行。如果通过,则可将部署“升级”为用于处理用户请求。如果失败,一切都会保持原样,但开发者可以查看出了什么问题。
Cloud Build 配置
现在,我们来创建一个 Cloud Run 部署配置脚本,该脚本会执行以下步骤:
- 将服务部署到专用修订版本。
- 运行代理评估。
- 如果评估通过,则将修订版本部署“升级”为处理 100% 的流量。
创建 cloudbuild.yaml:
steps:
- name: gcr.io/google.com/cloudsdktool/google-cloud-cli:latest
entrypoint: /bin/bash
env:
- 'BUILD_ID=$BUILD_ID'
args:
- "-c"
- |
if [[ "$_COMMIT_SHORT_HASH" != "" ]]; then
export COMMIT_SHORT_HASH=$_COMMIT_SHORT_HASH
else
export COMMIT_SHORT_HASH=$SHORT_SHA
fi
export COMMIT_REVISION_TAG="c-$${COMMIT_SHORT_HASH}"
echo "Deploying with revision tag: $$COMMIT_REVISION_TAG"
set -e
# Install uv and sync dependencies.
curl -LsSf https://astral.sh/uv/install.sh | sh
source $$HOME/.local/bin/env
uv sync
# Deploy services with the revision tag.
source ./deploy.sh --revision-tag $$COMMIT_REVISION_TAG --no-redeploy
# Run evaluation.
uv run -m evaluator.evaluate_agent
# If evaluation fails, the deployment will stop here.
# If evaluation passes, it will continue with promoting the revisions to serve 100% of traffic.
echo "Promoting revisions $$COMMIT_REVISION_TAG to serve 100% of traffic."
gcloud run services update-traffic researcher --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic judge --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic content-builder --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic orchestrator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
gcloud run services update-traffic course-creator --to-tags $$COMMIT_REVISION_TAG=100 --region $$GOOGLE_CLOUD_REGION --project $$GOOGLE_CLOUD_PROJECT
options:
substitutionOption: 'ALLOW_LOOSE'
defaultLogsBucketBehavior: REGIONAL_USER_OWNED_BUCKET
运行流水线
最后,我们可以运行评估流水线。
在运行向 Cloud Run 服务发出请求的评估流水线之前,我们需要一个具有多项权限的单独服务账号。我们来编写一个执行此操作并启动流水线的脚本。
- 创建脚本
run_cloud_build.sh:#!/bin/bash set -e source .env BUILD_SA_NAME="agent-eval-build-sa" BUILD_SA_EMAIL="${BUILD_SA_NAME}@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" COMMIT_SHORT_HASH=$(git rev-parse --short HEAD) # Creating service account for Cloud Build. Granting necessary roles to it. if ! gcloud iam service-accounts describe "${BUILD_SA_EMAIL}" --project "${GOOGLE_CLOUD_PROJECT}" &> /dev/null; then echo "Creating service account ${BUILD_SA_NAME} for Cloud Build." gcloud iam service-accounts create ${BUILD_SA_NAME} --project "${GOOGLE_CLOUD_PROJECT}" --display-name "Agent Build Service Account" echo "Granting roles to service account ${BUILD_SA_NAME}..." sleep 10 ROLES=( "roles/cloudbuild.builds.builder" "roles/run.admin" "roles/run.invoker" "roles/iam.serviceAccountOpenIdTokenCreator" "roles/iam.serviceAccountUser" "roles/serviceusage.serviceUsageAdmin" "roles/serviceusage.serviceUsageConsumer" "roles/aiplatform.user" "roles/logging.logWriter" "roles/storage.admin" "roles/artifactregistry.writer" ) # Loop through and grant each role for ROLE in "${ROLES[@]}"; do gcloud projects add-iam-policy-binding "$GOOGLE_CLOUD_PROJECT" \ --member="serviceAccount:$BUILD_SA_EMAIL" \ --role="$ROLE" \ --condition=None \ --quiet done echo "Waiting for 60 seconds for the permission changes to propagate..." sleep 60 fi gcloud builds submit --config cloudbuild.yaml \ --service-account="projects/${GOOGLE_CLOUD_PROJECT}/serviceAccounts/${BUILD_SA_EMAIL}" \ --machine-type=e2-highcpu-32 \ --timeout=120m \ --substitutions _COMMIT_SHORT_HASH=$COMMIT_SHORT_HASH,_GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,_GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION,_GOOGLE_CLOUD_REGION=$GOOGLE_CLOUD_REGION- 创建专用服务账号
agent-eval-build-sa。 - 授予其必要的角色(
roles/run.admin、roles/aiplatform.user等)。*. 将构建提交到 Cloud Build。
- 创建专用服务账号
- 运行流水线:
chmod +x run_cloud_build.sh ./run_cloud_build.sh
您可以在终端中观看构建进度,也可以点击指向 Cloud 控制台的链接。
注意:在实际的生产环境中,您需要设置 Cloud Build 触发器,以便在每次 git push 时自动运行此命令。工作流是相同的:触发器会执行 cloudbuild.yaml,确保每个提交都会得到评估。
10. 总结
您已成功构建评估流水线!
- 部署:您使用带有 Git 提交哈希的修订版本标记,将代理安全地部署到实际环境中进行测试,而不会影响生产部署。
- 评估:您定义了评估指标,并使用 Vertex AI Gen AI Evaluation Service 自动执行评估流程。
- 分析:您使用 Colab 笔记本直观呈现评估结果并改进了代理。
- 发布:您使用 Cloud Build 自动执行评估流水线,并将最佳修订版本提升为处理 100% 的流量。
编辑代码 -> 部署代码 -> 运行评估和测试 -> 分析 -> 发布 -> 重复这一循环是生产级智能体工程的核心。