
1. 소개
개요
이 실습의 목표는 Google Cloud에서 엔드 투 엔드 에이전트 검색 증강 생성 (RAG) 애플리케이션을 개발하는 방법을 배우는 것입니다. 이 실습에서는 비구조적 문서 (Alphabet의 분기별 SEC 제출 서류 - 미국의 모든 공개 기업이 증권거래위원회에 제출하는 재무제표 및 운영 세부정보)와 구조적 데이터 (이전 주가)라는 두 가지 서로 다른 소스의 정보를 결합하여 질문에 답변할 수 있는 재무 분석 에이전트를 빌드합니다.
Vertex AI Search를 사용하여 구조화되지 않은 재무 보고서를 위한 강력한 시맨틱 검색엔진을 빌드합니다. 구조화된 데이터의 경우 맞춤 Python 도구를 만듭니다. 마지막으로 에이전트 개발 키트 (ADK)를 사용하여 사용자의 질문을 추론하고, 사용할 도구를 결정하고, 정보를 종합하여 일관된 답변을 생성할 수 있는 지능형 에이전트를 빌드합니다.
실습할 내용
- 비공개 문서에 대한 시맨틱 검색을 위해 Vertex AI Search 데이터 스토어를 설정합니다.
- 에이전트의 도구로 맞춤 Python 함수를 만듭니다.
- 에이전트 개발 키트 (ADK)를 사용하여 멀티 도구 에이전트를 빌드합니다.
- 구조화되지 않은 데이터 소스와 구조화된 데이터 소스에서 검색을 결합하여 복잡한 질문에 답변합니다.
- 추론 기능을 보여주는 에이전트를 테스트하고 상호작용합니다.
학습할 내용
이 실습에서는 다음 내용을 알아봅니다.
- 검색 증강 생성 (RAG) 및 에이전트 RAG의 핵심 개념
- Vertex AI Search를 사용하여 문서에 대한 시맨틱 검색을 구현하는 방법
- 맞춤 도구를 만들어 구조화된 데이터를 에이전트에 노출하는 방법
- 에이전트 개발 키트 (ADK)로 멀티 도구 에이전트를 빌드하고 오케스트레이션하는 방법
- 에이전트가 추론 및 계획을 사용하여 여러 데이터 소스를 통해 복잡한 질문에 답변하는 방법
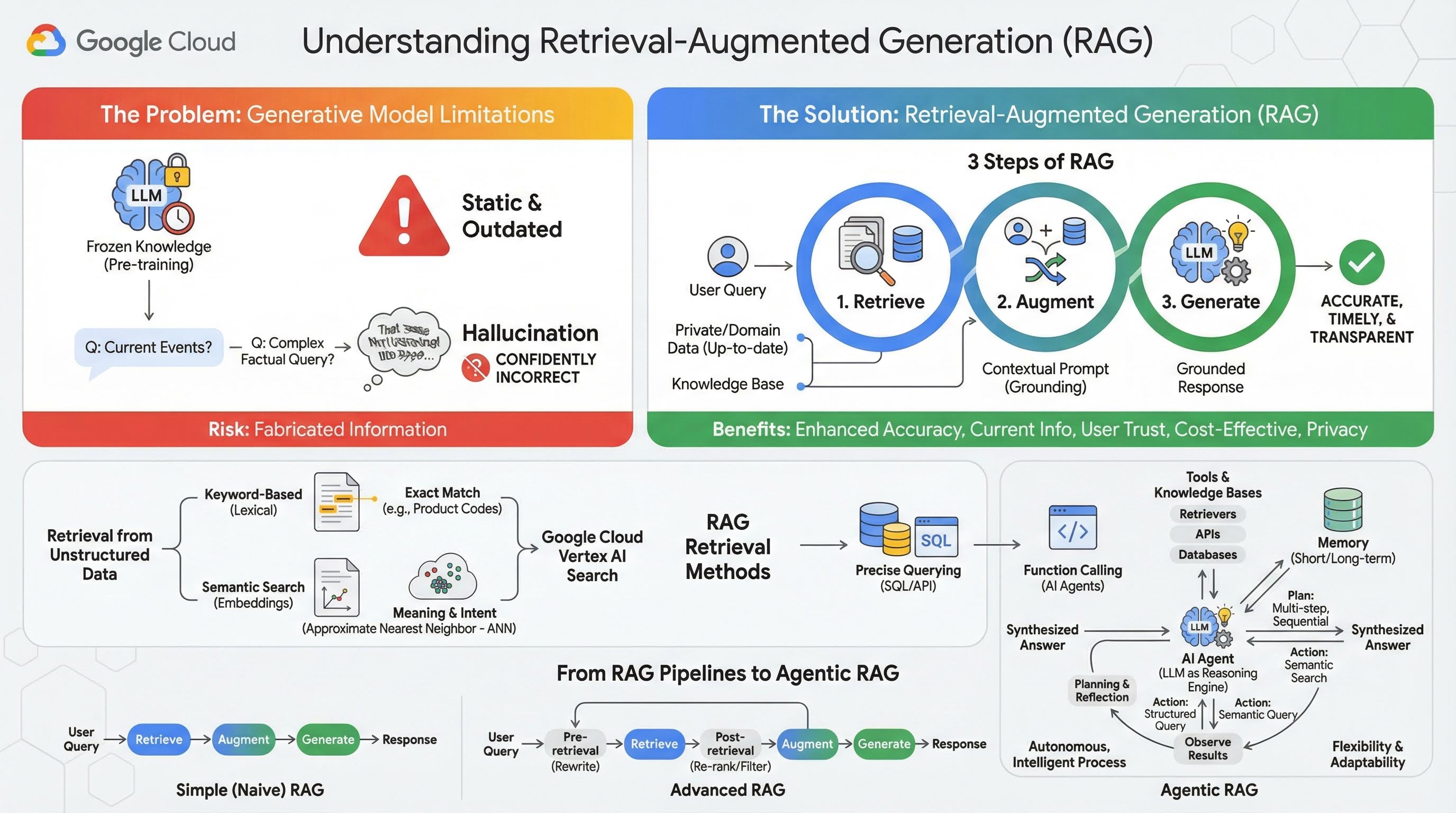
2. 검색 증강 생성 이해
대규모 생성형 모델(대규모 언어 모델(LLM), 비전-언어 모델 등)은 매우 강력하지만 고유한 한계가 있습니다. 사전 학습 시점에 지식이 고정되어 정적이고 즉시 오래된 정보가 됩니다. 미세 조정 후에도 모델의 지식이 훨씬 더 최신이 되지는 않습니다. 이는 학습 후 단계의 목표가 아니기 때문입니다.
대규모 언어 모델, 특히 '사고' 모델은 모델 자체에 이러한 답변을 뒷받침하는 사실 정보가 없더라도 일부 답변을 제공하면 '보상'을 받습니다. 이때 모델이 '할루시네이션'을 일으킨다고 말합니다. 그럴듯하게 들리지만 사실적으로는 잘못된 정보를 자신감 있게 생성하는 것입니다.
검색 증강 생성은 이러한 문제를 해결하기 위해 설계된 강력한 아키텍처 패턴입니다. 대규모 언어 모델을 외부의 신뢰할 수 있는 지식 소스에 실시간으로 연결하여 대규모 언어 모델의 기능을 향상하는 아키텍처 프레임워크입니다. RAG 시스템의 LLM은 정적이고 사전 학습된 지식에만 의존하는 대신 먼저 사용자의 질문과 관련된 정보를 검색한 다음 해당 정보를 사용하여 더 정확하고 시기적절하며 맥락을 인식하는 대답을 생성합니다.
이 접근 방식은 생성형 모델의 가장 심각한 약점인 지식이 특정 시점에 고정되어 있고 부정확한 정보, 즉 '할루시네이션'을 생성하기 쉽다는 점을 직접적으로 해결합니다. RAG는 LLM에 '오픈북 시험'을 제공합니다. 여기서 '책'은 비공개 도메인별 최신 데이터입니다. LLM에 사실적인 컨텍스트를 제공하는 이 프로세스를 '그라운딩'이라고 합니다.
RAG의 3단계
표준 검색 증강 생성 프로세스는 다음과 같은 세 가지 간단한 단계로 나눌 수 있습니다.
- 검색: 사용자가 질문을 제출하면 시스템은 먼저 문서 저장소, 데이터베이스, 웹사이트와 같은 외부 기술 자료를 검색하여 질문과 관련된 정보를 찾습니다.
- 증강: 검색된 정보는 원래 사용자 쿼리와 결합되어 확장된 프롬프트가 됩니다. 이 기법은 사실적 맥락으로 프롬프트를 풍부하게 하므로 '프롬프트 스터핑'이라고도 합니다.
- 생성: 이 증강된 프롬프트가 LLM에 입력되고 LLM은 대답을 생성합니다. 모델에 관련성이 있고 사실적인 데이터가 제공되었으므로 출력의 '근거'가 있으며 부정확하거나 오래될 가능성이 훨씬 적습니다.
RAG의 이점
RAG 프레임워크의 도입은 실용적이고 신뢰할 수 있는 AI 애플리케이션을 빌드하는 데 혁신적인 변화를 가져왔습니다. 주요 혜택은 다음과 같습니다.
- 정확성 향상 및 할루시네이션 감소: 검증 가능한 외부 사실에 기반하여 응답을 생성함으로써 RAG는 LLM이 정보를 날조할 위험을 크게 줄입니다.
- 최신 정보 액세스: RAG 시스템은 지속적으로 업데이트되는 기술 자료에 연결할 수 있으므로 정적으로 학습된 LLM에서는 불가능한 최신 정보를 기반으로 응답을 제공할 수 있습니다.
- 사용자 신뢰도 및 투명성 향상: LLM의 대답은 검색된 문서를 기반으로 하므로 시스템에서 소스에 대한 인용과 링크를 제공할 수 있습니다. 이를 통해 사용자는 정보를 직접 확인할 수 있으므로 애플리케이션에 대한 신뢰를 쌓을 수 있습니다.
- 비용 효율성: 새로운 데이터로 LLM을 지속적으로 미세 조정하거나 재학습시키는 데는 계산 비용과 재정적 비용이 많이 듭니다. RAG를 사용하면 모델의 지식을 업데이트하는 것이 외부 데이터 소스를 업데이트하는 것만큼 간단하므로 훨씬 효율적입니다.
- 도메인 전문화 및 개인 정보 보호: RAG를 사용하면 개인 및 조직이 모델의 학습 세트에 민감한 정보를 포함하지 않고도 쿼리 시점에 LLM에서 비공개 독점 데이터를 사용할 수 있습니다. 이를 통해 데이터 개인 정보 보호 및 보안을 유지하면서 강력한 도메인별 애플리케이션을 사용할 수 있습니다.
검색
'검색' 단계는 모든 RAG 시스템의 핵심입니다. 검색된 정보의 품질과 관련성은 최종 생성된 답변의 품질과 관련성을 직접적으로 결정합니다. 효과적인 RAG 애플리케이션은 다양한 기법을 사용하여 여러 유형의 데이터 소스에서 정보를 가져와야 하는 경우가 많습니다. 기본 검색 방법은 키워드 기반, 시맨틱, 구조화된 세 가지 카테고리로 분류됩니다.
구조화되지 않은 데이터에서 검색
이전에는 비구조화된 데이터 검색을 기존 검색이라고도 했습니다. 여러 변환을 거쳤으며 두 가지 주요 접근 방식을 모두 활용할 수 있습니다.
시맨틱 검색은 최첨단 성능과 높은 수준의 제어 기능을 갖춘 Google Cloud에서 대규모로 실행할 수 있는 가장 효율적인 기술입니다.
- 키워드 기반 (어휘) 검색: 1970년대 초기의 정보 검색 시스템으로 거슬러 올라가는 기존 검색 방식입니다. 어휘 검색은 사용자 쿼리의 단어 (또는 '토큰')를 기술 자료 내 문서의 정확히 동일한 단어와 일치시켜 작동합니다. 제품 코드, 법적 조항, 고유 이름과 같은 특정 용어의 정확성이 중요한 쿼리에 매우 효과적입니다.
- 시맨틱 검색: 시맨틱 검색 또는 '의미를 통한 검색'은 문자 그대로의 키워드뿐만 아니라 사용자의 의도와 질문의 맥락적 의미를 이해하는 것을 목표로 하는 최신 접근 방식입니다. 최신 시맨틱 검색은 복잡한 고차원 데이터를 숫자 벡터의 저차원 벡터 공간으로 매핑하는 머신러닝 기법인 임베딩을 기반으로 합니다. 이러한 벡터는 의미가 비슷한 텍스트가 벡터 공간에서 서로 가까이 위치하도록 설계되었습니다. '가족에게 가장 적합한 견종은 무엇인가요?'라는 검색어가 벡터로 변환되고 시스템은 해당 공간에서 '최근접 이웃'인 문서 벡터를 검색합니다. 따라서 'dog'이라는 단어가 정확히 포함되어 있지 않더라도 'golden retrievers' 또는 'friendly canines'에 대해 설명하는 문서를 찾을 수 있습니다. 이 고차원 검색은 근사 최근접 이웃 (ANN) 알고리즘을 통해 효율적으로 이루어집니다. ANN 알고리즘은 쿼리 벡터를 모든 단일 문서 벡터와 비교하는 대신 (대규모 데이터 세트에는 너무 느림) 영리한 색인 구조를 사용하여 가장 가까울 가능성이 있는 벡터를 빠르게 찾습니다.
구조화된 데이터에서 검색
중요한 지식이 모두 비구조적 문서에 저장되어 있는 것은 아닙니다. 가장 정확하고 유용한 정보는 관계형 데이터베이스, NoSQL 데이터베이스 또는 날씨 데이터나 주가에 대한 REST API와 같은 API와 같은 구조화된 형식으로 제공되는 경우가 많습니다.
구조화된 데이터에서 검색하는 것이 일반적으로 비구조화된 텍스트를 검색하는 것보다 더 직접적이고 정확합니다. 시맨틱 유사성을 검색하는 대신 언어 모델에 데이터베이스에 대한 SQL 쿼리 또는 특정 위치와 날짜에 대한 날씨 API에 대한 API 호출과 같은 정확한 쿼리를 공식화하고 실행하는 기능을 부여할 수 있습니다.
AI 에이전트를 지원하는 것과 동일한 기법인 함수 호출을 통해 구현되며, 언어 모델이 실행 가능한 코드 및 외부 시스템과 결정론적 구조 방식으로 상호작용할 수 있습니다.
3. RAG 파이프라인에서 에이전트 RAG로
RAG의 개념 자체가 발전해 온 것처럼 이를 구현하는 아키텍처도 발전해 왔습니다. 단순한 선형 파이프라인으로 시작한 것이 AI 에이전트가 오케스트레이션하는 동적이고 지능적인 시스템으로 발전했습니다.
- 단순 (또는 순진한) RAG: 지금까지 설명한 기본 아키텍처로, 검색, 보강, 생성의 선형 3단계 프로세스입니다. 반응형입니다. 모든 질문에 대해 고정된 경로를 따르며 간단한 Q&A 작업에 매우 효과적입니다.
- 고급 RAG: 검색된 컨텍스트의 품질을 개선하기 위해 파이프라인에 추가 단계가 추가된 진화된 형태를 나타냅니다. 이러한 개선사항은 검색 단계 전후에 발생할 수 있습니다.
- 사전 검색: 쿼리 다시 작성 또는 확장과 같은 기술을 사용할 수 있습니다. 시스템에서 초기 질문을 분석하고 검색 시스템에 더 효과적이도록 다시 표현할 수 있습니다.
- 검색 후: 초기 문서 집합을 검색한 후 재정렬 모델을 적용하여 관련성 점수를 매기고 가장 적합한 문서를 상단으로 푸시할 수 있습니다. 이는 하이브리드 검색에서 특히 중요합니다. 검색 후 단계의 또 다른 예는 검색된 컨텍스트를 필터링하거나 압축하여 가장 중요한 정보만 LLM에 전달되도록 하는 것입니다.
- 에이전트 RAG: RAG 아키텍처의 최첨단으로, 고정된 파이프라인에서 자율적이고 지능적인 프로세스로의 패러다임 전환을 나타냅니다. 에이전트 RAG 시스템에서는 추론하고, 계획하고, 동적으로 작업을 선택할 수 있는 하나 이상의 AI 에이전트가 전체 워크플로를 관리합니다.
에이전트 기반 RAG를 이해하려면 먼저 AI 에이전트의 구성 요소를 이해해야 합니다. 에이전트는 단순한 LLM이 아닙니다. 다음과 같은 몇 가지 주요 구성요소로 이루어진 시스템입니다.
- LLM을 추론 엔진으로 사용: 에이전트는 Gemini와 같은 강력한 LLM을 텍스트를 생성하는 데뿐만 아니라 계획, 의사 결정, 복잡한 작업 분해를 위한 중앙 '두뇌'로 사용합니다.
- 도구 세트: 에이전트에게 목표 달성을 위해 사용할 수 있는 함수 툴킷에 대한 액세스 권한이 부여됩니다. 이러한 도구는 계산기, 웹 검색 API, 이메일 전송 함수, 이 실습에서 가장 중요한 다양한 지식 기반의 리트리버 등 무엇이든 될 수 있습니다.
- 메모리: 에이전트는 단기 메모리 (현재 대화의 컨텍스트를 기억)와 장기 메모리 (과거 상호작용의 정보를 기억)를 모두 사용하여 설계할 수 있으므로 더 개인화되고 일관된 경험을 제공할 수 있습니다.
- 계획 및 반영: 가장 고급 에이전트는 정교한 추론 패턴을 보여줍니다. 복잡한 목표를 받아 이를 달성하기 위한 다단계 계획을 세울 수 있습니다. 그런 다음 이 계획을 실행하고, 작업 결과를 반성하며, 오류를 파악하고, 접근 방식을 자체적으로 수정하여 최종 결과를 개선할 수 있습니다.
에이전트형 RAG는 정적 파이프라인에는 없는 자율성과 지능을 도입하므로 획기적인 기술입니다.
- 유연성 및 적응성: 에이전트가 단일 검색 경로에 고정되지 않습니다. 사용자 질문이 주어지면 최적의 정보 소스를 추론할 수 있습니다. 먼저 구조화된 데이터베이스를 쿼리한 다음 비구조화된 문서에 대해 시맨틱 검색을 실행하고, 그래도 답을 찾을 수 없는 경우 Google 검색 도구를 사용하여 공개 웹을 검색하는 등 단일 사용자 요청의 컨텍스트 내에서 다양한 작업을 수행할 수 있습니다.
- 복잡한 다단계 추론: 이 아키텍처는 여러 순차적 검색 및 처리 단계가 필요한 복잡한 쿼리를 처리하는 데 탁월합니다.
'크리스토퍼 놀런이 감독한 SF 영화 상위 3개를 찾아 각 영화의 간단한 줄거리 요약을 제공해 줘'라는 질문을 생각해 보세요. 간단한 RAG 파이프라인은 실패합니다.
하지만 에이전트는 다음과 같이 세부적으로 분류할 수 있습니다.
- 계획: 먼저 영화를 찾아야 해. 그런 다음 각 영화의 줄거리를 찾아야 합니다.
- 작업 1: 구조화된 데이터 도구를 사용하여 영화 데이터베이스에서 놀란의 SF 영화를 쿼리합니다. 평점순으로 내림차순으로 정렬된 상위 3개 영화를 쿼리합니다.
- 관찰 1: 도구가 '인셉션', '인터스텔라', '테넷'을 반환합니다.
- 액션 2: 비정형 데이터 도구 (시맨틱 검색)를 사용하여 '인셉션'의 줄거리를 찾습니다.
- 관찰 2: 줄거리가 검색됩니다.
- 3단계: '인터스텔라'에 대해 반복합니다.
- 4단계: '테넷'에 대해 반복합니다.
- 최종 종합: 검색된 모든 정보를 하나의 일관된 답변으로 결합합니다.
4. 프로젝트 설정
Google 계정
아직 개인 Google 계정이 없다면 Google 계정을 만들어야 합니다.
직장 또는 학교 계정 대신 개인 계정을 사용합니다.
Google Cloud 콘솔에 로그인
개인 Google 계정을 사용하여 Google Cloud 콘솔에 로그인합니다.
결제 사용 설정
무료 체험 결제 계정 사용 (선택사항)
이 워크숍을 진행하려면 크레딧이 있는 결제 계정이 필요합니다. 이 Codelab 상단의 배너에 있는 크레딧을 사용하여 시작하세요. 이미 결제 계정에 연결되어 있다면 이 단계를 건너뛰어도 됩니다.
개인 결제 계정 설정
Google Cloud 크레딧을 사용하여 결제를 설정한 경우 이 단계를 건너뛸 수 있습니다.
개인 결제 계정을 설정하려면 Cloud 콘솔에서 여기에서 결제를 사용 설정하세요.
참고 사항:
- 이 실습을 완료하는 데 드는 Cloud 리소스 비용은 1달러 미만입니다.
- 이 실습이 끝나면 단계에 따라 리소스를 삭제하여 추가 요금이 발생하지 않도록 할 수 있습니다.
- 신규 사용자는 미화$300 상당의 무료 체험판을 사용할 수 있습니다.
프로젝트 만들기(선택사항)
이 실습에 사용할 현재 프로젝트가 없는 경우 여기에서 새 프로젝트를 만드세요.
5. Cloud Shell 편집기 열기
- 이 링크를 클릭하여 Cloud Shell 편집기로 바로 이동합니다.
- 오늘 언제든지 승인하라는 메시지가 표시되면 승인을 클릭하여 계속합니다.
- 터미널이 화면 하단에 표시되지 않으면 다음 단계에 따라 엽니다.
- 보기를 클릭합니다.
- 터미널을 클릭합니다.
- 터미널에서 다음 명령어를 사용하여 프로젝트를 설정합니다.
gcloud config set project [PROJECT_ID]- 예:
gcloud config set project lab-project-id-example - 프로젝트 ID가 기억나지 않는 경우 다음을 사용하여 모든 프로젝트 ID를 나열할 수 있습니다.
gcloud projects list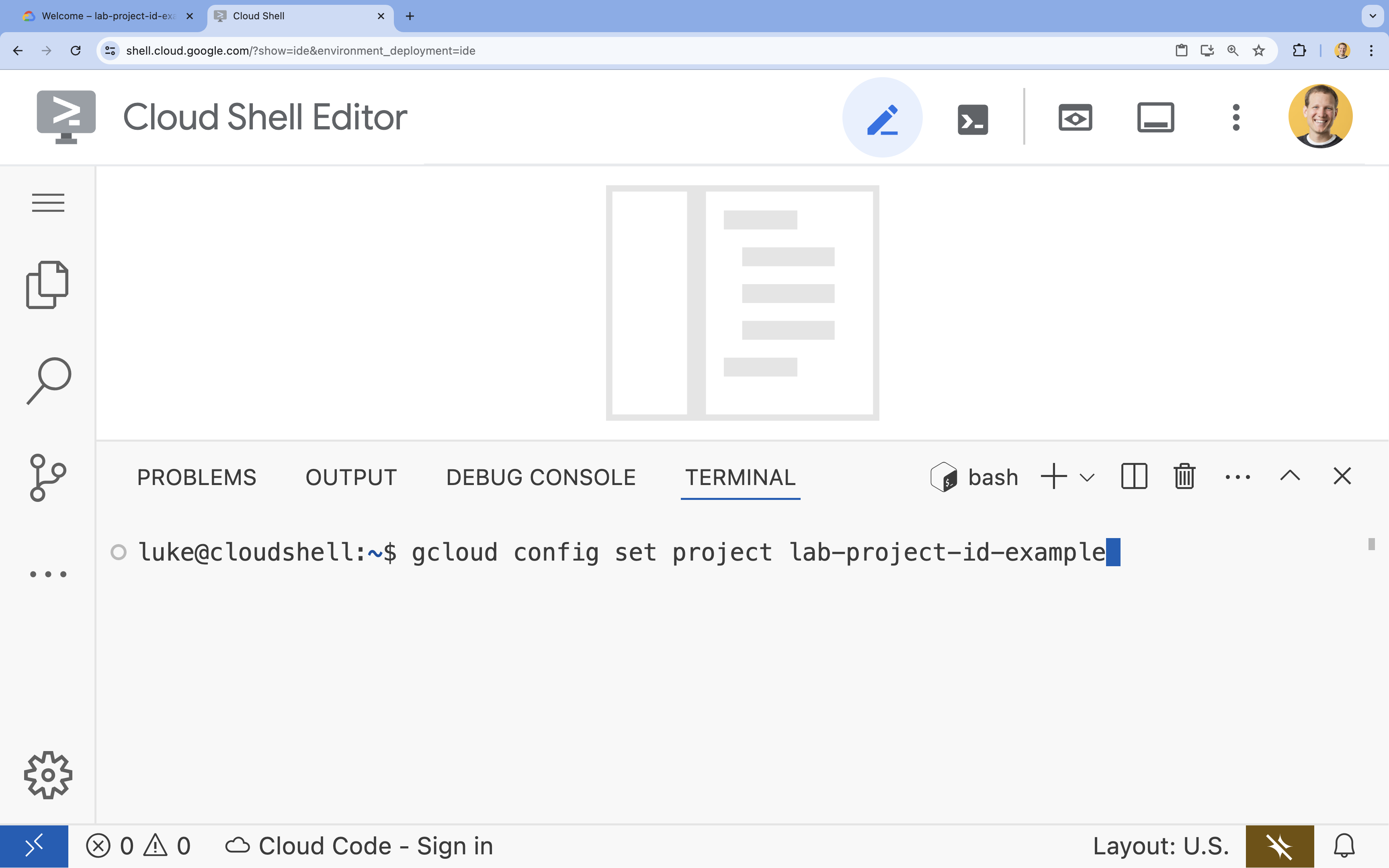
- 예:
- 다음 메시지가 표시되어야 합니다.
Updated property [core/project].
6. API 사용 설정
에이전트 개발 키트와 Vertex AI Search를 사용하려면 Google Cloud 프로젝트에서 필요한 API를 사용 설정해야 합니다.
- 터미널에서 API를 사용 설정합니다.
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
API 소개
- Vertex AI API (
aiplatform.googleapis.com)를 사용하면 에이전트가 Gemini 모델과 통신하여 추론하고 생성할 수 있습니다. - Discovery Engine API (
discoveryengine.googleapis.com)는 Vertex AI Search를 지원하므로 데이터 스토어를 만들고 구조화되지 않은 문서에 대해 시맨틱 검색을 실행할 수 있습니다.
7. 환경 설정
AI 에이전트 코딩을 시작하기 전에 개발 환경을 준비하고, 필요한 라이브러리를 설치하고, 필수 데이터 파일을 만들어야 합니다.
가상 환경 생성 및 종속 항목 설치
- 에이전트의 디렉터리를 만들고 해당 디렉터리로 이동합니다. 터미널에서 다음 코드를 실행합니다.
mkdir financial_agent cd financial_agent - 가상 환경을 만듭니다.
uv venv --python 3.12 - 가상 환경을 활성화합니다.
source .venv/bin/activate - 에이전트 개발 키트 (ADK)와 pandas를 설치합니다.
uv pip install google-adk pandas
주가 데이터 만들기
실습에서는 에이전트가 구조화된 도구를 사용하는 기능을 보여주기 위해 특정 과거 주식 데이터가 필요하므로 이 데이터가 포함된 CSV 파일을 만듭니다.
financial_agent디렉터리에서 터미널에 다음 명령어를 실행하여goog.csv파일을 만듭니다.cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
환경 변수 구성
financial_agent디렉터리에서.env파일을 만들어 에이전트의 환경 변수를 구성합니다. 이렇게 하면 ADK에 사용할 프로젝트, 위치, 모델이 표시됩니다. 터미널에서 다음 코드를 실행합니다.# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
참고: 실습 후반에 .env 파일을 수정해야 하는데 financial_agent 디렉터리에 표시되지 않으면 '보기 / 숨은 파일 전환' 메뉴 항목을 사용하여 Cloud Shell 편집기에서 숨은 파일 표시 상태를 전환해 보세요.
8. Vertex AI Search 데이터 스토어 만들기
에이전트가 Alphabet의 재무 보고서에 관한 질문에 답변할 수 있도록 공개 SEC 서류가 포함된 Vertex AI Search 데이터 스토어를 만듭니다.
- 새 브라우저 탭에서 Cloud 콘솔 (console.cloud.google.com)을 열고 상단의 검색창을 사용하여 AI Applications로 이동합니다.
- 메시지가 표시되면 이용약관 체크박스를 선택하고 계속 및 API 활성화를 클릭합니다.
- 왼쪽 탐색 메뉴에서 데이터 스토어를 선택합니다.
- + 데이터 스토어 만들기를 클릭합니다.
- Cloud Storage 카드를 찾아 선택을 클릭합니다.
- 데이터 소스로 구조화되지 않은 문서를 선택합니다.

- 가져오기 소스 (가져올 폴더 또는 파일 선택)에 Google Cloud Storage 경로
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings를 입력합니다. - 계속을 클릭합니다.
- 위치를 전역으로 설정된 상태로 둡니다.
- 데이터 스토어 이름에 다음을 입력합니다.
alphabet-sec-filings - 문서 처리 옵션 섹션을 펼칩니다.

- 기본 문서 파서 드롭다운 목록에서 레이아웃 파서를 선택합니다.
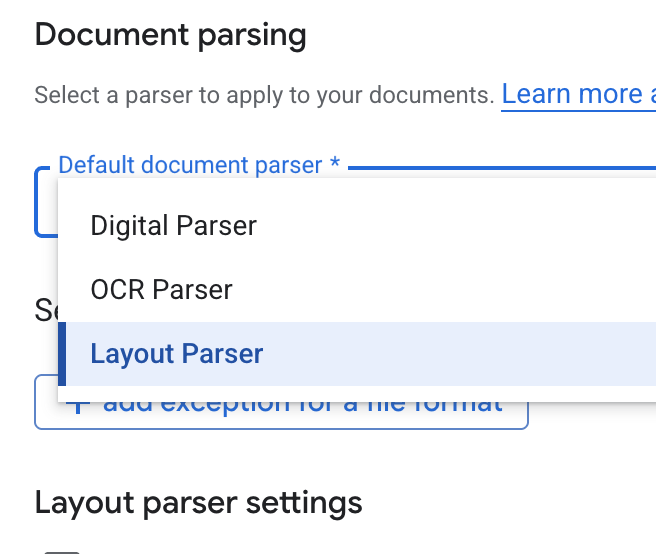
- 레이아웃 파서 설정 옵션에서 표 주석 사용 설정 및 이미지 주석 사용 설정을 선택합니다.
- 계속을 클릭합니다.
- 가격 모델로 일반 가격 책정 (사용한 만큼만 지불하는 소비 기반 모델)을 선택하고 만들기를 클릭합니다.
- 데이터 스토어에서 문서를 가져오기 시작합니다.
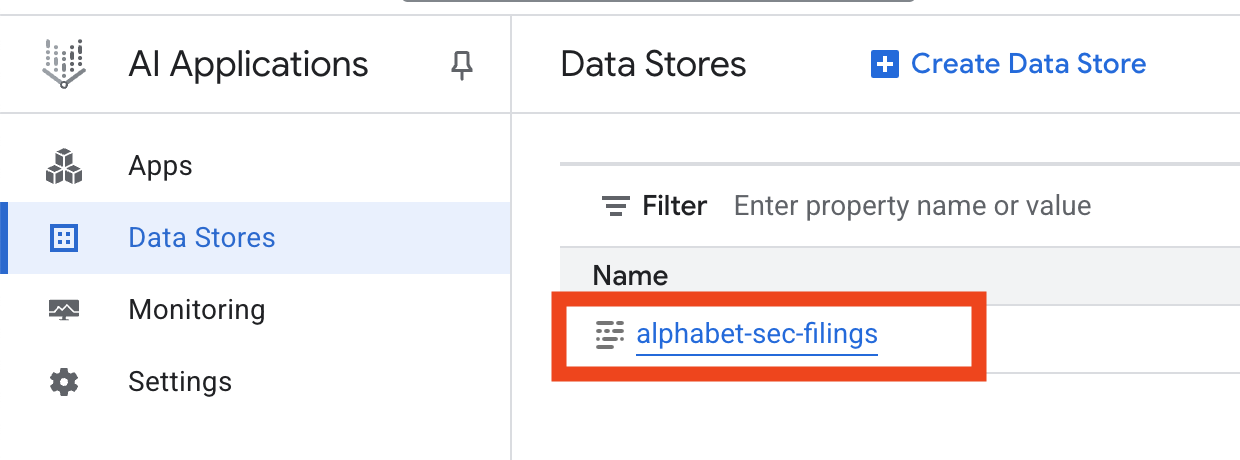
- 데이터 스토어 이름을 클릭하고 데이터 스토어 표에서 ID를 복사합니다. 다음 단계에 필요합니다.
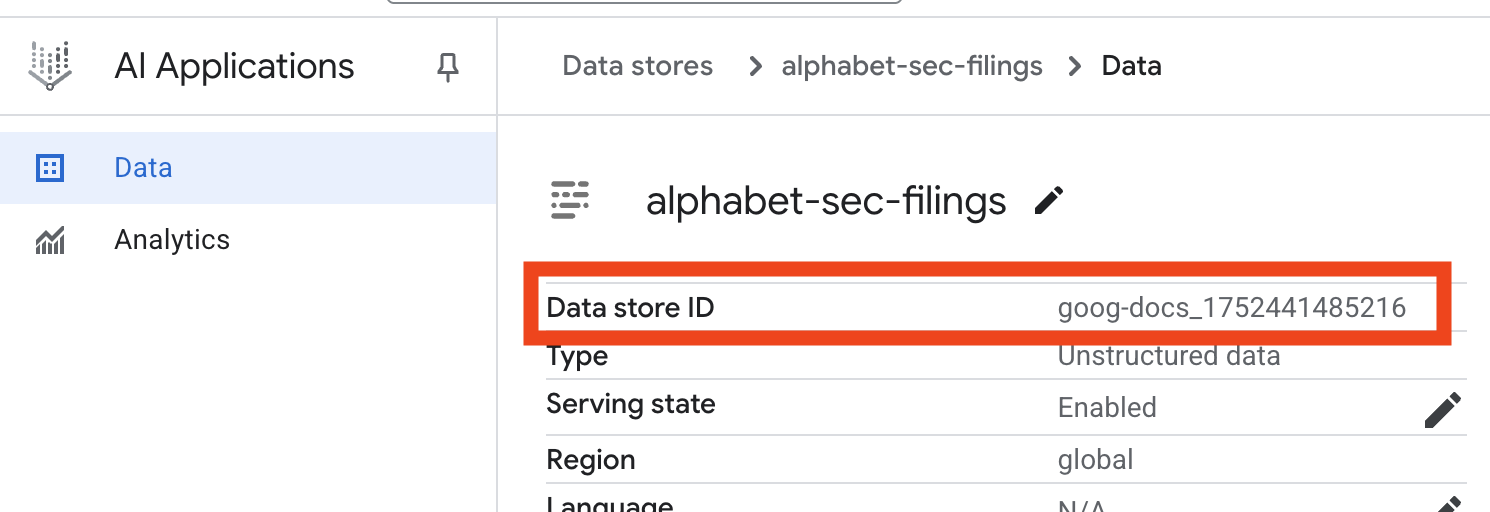
- Cloud Shell 편집기에서
.env파일을 열고 데이터 스토어 ID를DATA_STORE_ID="YOUR_DATA_STORE_ID"로 추가합니다 (YOUR_DATA_STORE_ID를 이전 단계의 실제 ID로 바꿈).참고: 데이터 스토어에서 데이터를 가져오고, 파싱하고, 색인을 생성하는 데 몇 분 정도 걸립니다. 프로세스를 확인하려면 데이터 스토어 이름을 클릭하여 속성을 연 다음 활동 탭을 엽니다. 상태가 '가져오기 완료됨'이 될 때까지 기다립니다.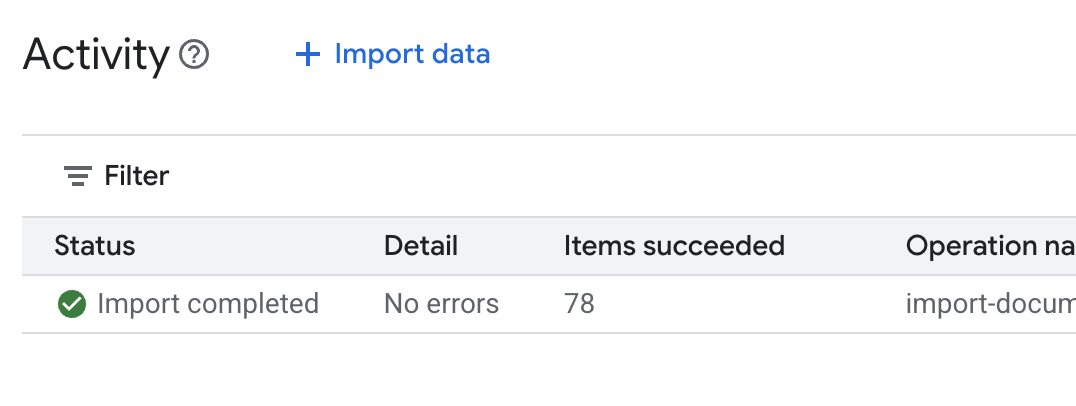
9. 구조화된 데이터용 맞춤 도구 만들기
다음으로 에이전트의 도구 역할을 하는 Python 함수를 만듭니다. 이 도구는 goog.csv 파일을 읽어 특정 날짜의 과거 주가를 가져옵니다.
financial_agent디렉터리에agent.py이라는 새 파일을 만듭니다. 터미널에서 다음 명령어를 실행합니다.cloudshell edit agent.py- 다음 Python 코드를
agent.py에 추가합니다. 이 코드는 종속 항목을 가져오고get_stock_price함수를 정의합니다.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
함수의 자세한 docstring을 확인하세요. 함수의 기능, 매개변수 (Args), 반환 값 (Returns)을 설명합니다. ADK는 이 docstring을 사용하여 에이전트에게 이 도구를 언제 어떻게 사용해야 하는지 알려줍니다.
10. RAG 에이전트 빌드 및 실행
이제 에이전트를 어셈블할 차례입니다. 구조화되지 않은 데이터용 Vertex AI Search 도구와 구조화된 데이터용 맞춤 get_stock_price 도구를 결합합니다.
agent.py파일에 다음 코드를 추가합니다. 이 코드는 필요한 ADK 클래스를 가져오고, 도구의 인스턴스를 만들고, 에이전트를 정의합니다.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" )- 터미널의
financial_agent디렉터리에서 ADK 웹 인터페이스를 실행하여 에이전트와 상호작용합니다.adk web ~ - 터미널 출력에 제공된 링크 (일반적으로
http://127.0.0.1:8000)를 클릭하여 브라우저에서 ADK 개발 UI를 엽니다.
11. 에이전트 테스트
이제 에이전트의 추론 능력과 도구 사용 능력을 테스트하여 복잡한 질문에 답할 수 있습니다.
- ADK 개발 UI의 드롭다운 메뉴에서
financial_agent가 선택되어 있는지 확인합니다. - SEC 서류 (비정형 데이터)의 정보가 필요한 질문을 해 보세요. 채팅에 다음 쿼리를 입력합니다.
What were the total revenues for the quarter ending on March 31, 2023?VertexAiSearchTool를 사용하여 금융 문서에서 답을 찾는search_and_qna_agent를 호출해야 합니다. - 그런 다음 맞춤 도구 (구조화된 데이터)를 사용해야 하는 질문을 합니다. 프롬프트의 날짜 형식이 함수에 필요한 형식과 정확히 일치하지 않아도 됩니다. LLM이 이를 다시 포맷할 수 있습니다.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_price도구를 호출해야 합니다. 채팅에서 도구 아이콘을 클릭하여 함수 호출과 그 결과를 검사할 수 있습니다. - 마지막으로 에이전트가 두 가지 도구를 모두 사용하고 결과를 종합해야 하는 복잡한 질문을 합니다.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- 먼저
VertexAiSearchTool을 사용하여 SEC 제출 서류에서 현금 흐름 정보를 찾습니다. - 그런 다음 주가가 필요함을 인식하고 날짜
2023-03-31로get_stock_price함수를 호출합니다. - 마지막으로 두 정보를 결합하여 하나의 포괄적인 답변을 제공합니다.
- 먼저
- 작업이 끝나면 브라우저 탭을 닫고 터미널에서
CTRL+C를 눌러 ADK 서버를 중지합니다.
12. 작업에 사용할 서비스 선택
Vertex AI Search는 사용할 수 있는 유일한 벡터 검색 서비스가 아닙니다. 검색 증강 생성의 전체 흐름을 자동화하는 관리형 서비스인 Vertex AI RAG Engine을 사용할 수도 있습니다.
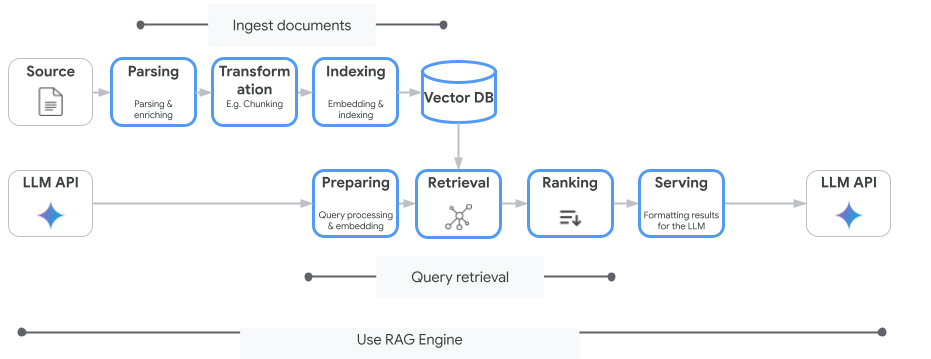
문서 수집부터 검색, 재정렬까지 모든 작업을 처리합니다. RAG Engine은 Pinecone, Weaviate를 비롯한 여러 벡터 스토어를 지원합니다.
또한 많은 전문 벡터 데이터베이스를 자체 호스팅하거나 PostgreSQL 서비스 (예: AlloyDB 또는 BigQuery 벡터 검색)의 pgvector와 같은 데이터베이스 엔진에서 벡터 색인 기능을 활용할 수 있습니다.
벡터 검색을 지원하는 기타 서비스는 다음과 같습니다.
Google Cloud에서 특정 서비스를 선택하는 일반적인 가이드는 다음과 같습니다.
- 이미 작동하고 확장성이 뛰어난 벡터 검색 DIY 인프라가 있는 경우 Weaviate 또는 DIY PostgreSQL과 같은 Google Kubernetes Engine에 배포합니다.
- 데이터가 BigQuery, AlloyDB, Firestore 또는 기타 데이터베이스에 있는 경우 해당 데이터베이스에서 더 큰 쿼리의 일부로 대규모 시맨틱 검색을 실행할 수 있다면 벡터 검색 기능을 사용하는 것이 좋습니다. 예를 들어 BigQuery 테이블에 제품 설명이나 이미지가 있는 경우 텍스트 또는 이미지 임베딩 열을 추가하면 대규모로 유사성 검색을 사용할 수 있습니다. ScANN 검색이 포함된 벡터 색인은 색인에서 수십억 개의 항목을 지원합니다.
- 관리형 플랫폼에서 최소한의 노력으로 빠르게 시작해야 하는 경우 Vertex AI Search를 선택하세요. Vertex AI Search는 복잡한 엔터프라이즈 사용 사례에 적합한 완전 관리형 검색 엔진 및 리트리버 API로, 즉시 사용 가능한 고품질, 확장성, 세부적인 액세스 제어가 필요합니다. 다양한 엔터프라이즈 데이터 소스에 대한 연결을 간소화하고 여러 소스에서 검색할 수 있습니다.
- 사용 편의성과 맞춤설정 간의 균형을 원하는 개발자에게 적합한 솔루션을 찾고 있다면 Vertex AI RAG Engine을 사용하세요. 유연성을 희생하지 않고도 신속한 프로토타입 제작 및 개발이 가능합니다.
- 검색 증강 생성을 위한 참조 아키텍처를 살펴봅니다.
13. 결론
축하합니다. 검색 증강 생성을 사용하여 AI 에이전트를 빌드하고 테스트했습니다. 지금까지 배운 내용은 다음과 같습니다.
- Vertex AI Search의 강력한 시맨틱 검색 기능을 사용하여 구조화되지 않은 문서의 기술 자료를 만듭니다.
- 구조화된 데이터를 가져오는 도구 역할을 하는 맞춤 Python 함수를 개발합니다.
- 에이전트 개발 키트 (ADK)를 사용하여 Gemini 기반의 멀티 도구 에이전트를 만드세요.
- 여러 소스의 정보를 종합해야 하는 질문에 답변하기 위해 복잡한 다단계 추론이 가능한 에이전트를 빌드합니다.
이 실습에서는 Google Cloud에서 지능적이고 정확하며 컨텍스트 인식 AI 애플리케이션을 빌드하기 위한 강력한 아키텍처인 에이전트 RAG의 핵심 원칙을 보여줍니다.
프로토타입에서 프로덕션으로
이 실습은 Google Cloud를 사용한 프로덕션 레디 AI 학습 과정의 일부입니다.
- 전체 커리큘럼 살펴보기를 통해 프로토타입에서 프로덕션으로 전환하는 데 필요한 지식을 쌓으세요.
- #ProductionReadyAI 해시태그를 사용하여 진행 상황을 공유하세요.