
1. 總覽
本程式碼研究室將說明如何使用 Apache Spark 和 Dataproc,在 Google Cloud Platform 上建立資料處理管道。在資料科學和資料工程中,從一個儲存位置讀取資料、對資料執行轉換,然後將資料寫入另一個儲存位置,是常見的用途。常見的轉換包括變更資料內容、移除不必要的資訊,以及變更檔案類型。
在本程式碼實驗室中,您將瞭解 Apache Spark,並使用 Dataproc 和 PySpark (Apache Spark 的 Python API)、BigQuery、Google Cloud Storage 和 Reddit 的資料,執行範例管道。
2. Apache Spark 簡介 (選用)
根據該網站,「Apache Spark 是用於大規模資料處理的整合數據分析引擎」。可讓您平行分析及處理資料,並將資料儲存在記憶體中,在多部不同的機器和節點上進行大規模平行運算。Spark 最初於 2014 年發布,是傳統 MapReduce 的升級版,至今仍是執行大規模運算最熱門的架構之一。Apache Spark 是以 Scala 編寫,因此具有 Scala、Java、Python 和 R 的 API。其中包含大量程式庫,例如用於對資料執行 SQL 查詢的 Spark SQL、用於串流資料的 Spark Streaming、用於機器學習的 MLlib,以及用於圖形處理的 GraphX,這些程式庫全都在 Apache Spark 引擎上執行。
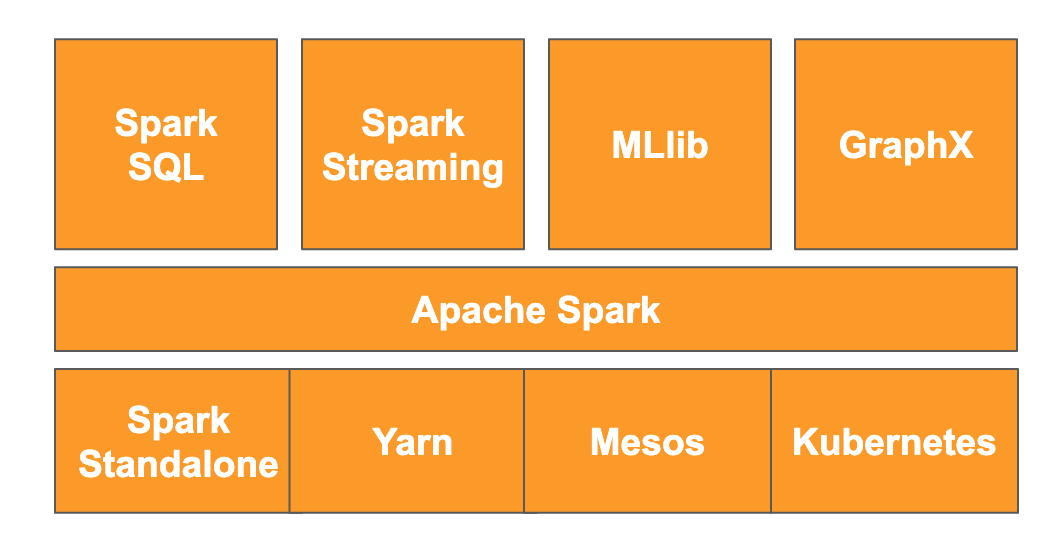
Spark 可以自行執行,也可以利用 Yarn、Mesos 或 Kubernetes 等資源管理服務進行資源調度。在本程式碼研究室中,您將使用 Dataproc,這項服務會運用 Yarn。
Spark 中的資料原本會載入記憶體,稱為 RDD 或彈性分散式資料集。Spark 的開發作業隨後新增了兩種新的資料類型 (直欄樣式):Dataset (已輸入型別) 和 DataFrame (未輸入型別)。廣義來說,RDD 適用於任何類型的資料,而資料集和資料框架則經過最佳化調整,適合用於表格資料。由於資料集僅適用於 Java 和 Scala API,因此我們將繼續使用 PySpark DataFrame API 進行本程式碼研究室。詳情請參閱 Apache Spark 說明文件。
3. 應用實例
資料工程師通常需要讓資料科學家輕鬆存取資料。不過,資料一開始通常會很雜亂 (目前狀態難以用於數據分析),因此需要先經過清理才能發揮作用。舉例來說,從網路上擷取的資料可能含有奇怪的編碼或多餘的 HTML 標記。
在本實驗室中,您會將一組 BigQuery 資料 (Reddit 貼文) 載入 Dataproc 代管的 Spark 叢集,擷取實用資訊,並將處理後的資料以壓縮的 CSV 檔案形式儲存在 Google Cloud Storage 中。
貴公司首席資料科學家希望團隊處理不同的自然語言處理問題。具體來說,他們想分析「r/food」子論壇中的資料。您將建立資料傾印管道,首先從 2017 年 1 月到 2019 年 8 月進行回填。
4. 透過 BigQuery Storage API 存取 BigQuery
使用 tabledata.list API 方法從 BigQuery 提取資料時,如果資料量很大,可能會耗費大量時間,效率也不高。這個方法會傳回 JSON 物件清單,且需要依序讀取一頁,才能讀取整個資料集。
BigQuery Storage API 採用 RPC 架構的通訊協定,可大幅提升 BigQuery 資料存取效能。支援平行讀取和寫入資料,以及各種序列化格式,例如 Apache Avro 和 Apache Arrow。整體而言,這代表效能大幅提升,尤其是在較大的資料集上。
在本程式碼研究室中,您將使用 spark-bigquery-connector 在 BigQuery 和 Spark 之間讀取及寫入資料。
5. 建立專案
前往 console.cloud.google.com 登入 Google Cloud Platform 控制台,然後建立新專案:



接著,您需要在 Cloud 控制台中啟用帳單,才能使用 Google Cloud 資源。
完成這項程式碼研究室的費用不應超過數美元,但如果您決定使用更多資源,或是將資源繼續執行,則可能會增加費用。本程式碼研究室的最後一節將逐步說明如何清除專案。
Google Cloud Platform 新使用者享有價值 $300 美元的免費試用期。
6. 設定環境
現在請按照下列步驟設定環境:
- 啟用 Compute Engine、Dataproc 和 BigQuery Storage API
- 設定專案設定
- 建立 Dataproc 叢集
- 建立 Google Cloud Storage bucket
啟用 API 並設定環境
按下 Cloud 控制台右上角的按鈕,開啟 Cloud Shell。
Cloud Shell 載入後,請執行下列指令,啟用 Compute Engine、Dataproc 和 BigQuery Storage API:
gcloud services enable compute.googleapis.com \
dataproc.googleapis.com \
bigquerystorage.googleapis.com
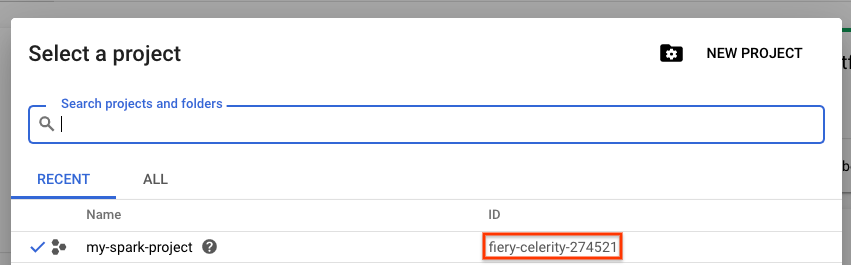
設定專案的專案 ID。前往專案選取頁面並搜尋專案,即可找到專案 ID。這可能與專案名稱不同。

執行下列指令來設定您的專案 ID:
gcloud config set project <project_id>
從這裡的清單中選擇一個,設定專案的區域。例如 us-central1。
gcloud config set dataproc/region <region>
為 Dataproc 叢集選擇名稱,並為該名稱建立環境變數。
CLUSTER_NAME=<cluster_name>
建立 Dataproc 叢集
執行下列指令來建立 Dataproc 叢集:
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--worker-machine-type n1-standard-8 \
--num-workers 8 \
--image-version 1.5-debian \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--metadata 'PIP_PACKAGES=google-cloud-storage' \
--optional-components=ANACONDA \
--enable-component-gateway
這個指令會在幾分鐘內執行完畢。指令說明:
系統會開始建立 Dataproc 叢集,並使用您先前提供的名稱。使用 beta API 可啟用 Dataproc 的 Beta 版功能,例如元件閘道。
gcloud beta dataproc clusters create ${CLUSTER_NAME}
這會設定要用於工作站的機器類型。
--worker-machine-type n1-standard-8
這會設定叢集的工作站數量。
--num-workers 8
這會設定 Dataproc 的映像檔版本。
--image-version 1.5-debian
這會設定要在叢集上使用的初始化動作。您在此納入 pip 初始化動作。
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh
這是要納入叢集的中繼資料。您在這裡提供 pip 初始化動作的中繼資料。
--metadata 'PIP_PACKAGES=google-cloud-storage'
這會設定要安裝在叢集上的「Optional Components」(選用元件)。
--optional-components=ANACONDA
這會啟用元件閘道,讓您使用 Dataproc 的元件閘道查看常見的 UI,例如 Zeppelin、Jupyter 或 Spark 記錄
--enable-component-gateway
如需 Dataproc 的深入介紹,請參閱這個程式碼研究室。
建立 Google Cloud Storage bucket
您需要 Google Cloud Storage 值區來存放工作輸出內容。決定 bucket 的專屬名稱,然後執行下列指令來建立新 bucket。所有使用者的所有 Google Cloud 專案,值區名稱皆不得重複,因此您可能需要嘗試使用不同名稱幾次。如果沒有收到 ServiceException,表示 bucket 已成功建立。
BUCKET_NAME=<bucket_name>
gsutil mb gs://${BUCKET_NAME}
7. 探索性資料分析
執行前處理作業前,請先進一步瞭解您要處理的資料性質。為此,您將瞭解兩種資料探索方法。首先,您會使用 BigQuery 網頁版 UI 查看一些原始資料,然後使用 PySpark 和 Dataproc 計算每個子論壇的貼文數量。
使用 BigQuery 網頁版 UI
首先,請使用 BigQuery 網頁版 UI 查看資料。在 Cloud Console 中,向下捲動並按下選單圖示中的「BigQuery」,開啟 BigQuery 網頁版 UI。
接著,在 BigQuery 網頁版 UI 查詢編輯器中執行下列指令。這會傳回 2017 年 1 月的 10 個完整資料列:
select * from fh-bigquery.reddit_posts.2017_01 limit 10;
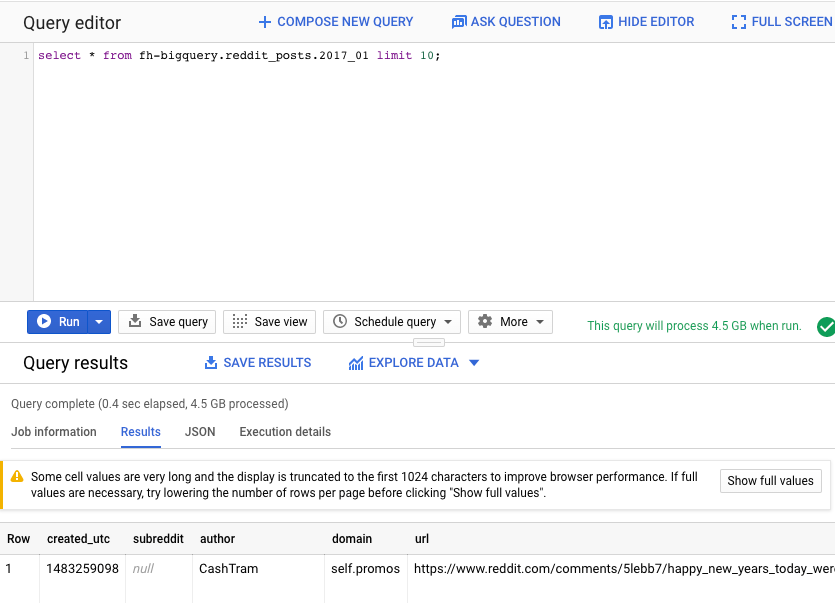
捲動瀏覽頁面,即可查看所有可用的資料欄和一些範例。具體來說,你會看到代表每則貼文文字內容的兩欄:「title」和「selftext」,後者是貼文內文。此外,請注意其他資料欄,例如「created_utc」(貼文發布的 UTC 時間) 和「subreddit」(貼文所在的子論壇)。
執行 PySpark 工作
在 Cloud Shell 中執行下列指令,複製存放區中的程式碼範例,並 cd 到正確的目錄:
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
您可以使用 PySpark 判斷每個子論壇的貼文數量。您可以開啟 Cloud Editor 並讀取指令碼 cloud-dataproc/codelabs/spark-bigquery,然後在下一個步驟中執行:
在 Cloud Editor 中按一下「Open Terminal」按鈕,切換回 Cloud Shell,然後執行下列指令來執行第一個 PySpark 工作:
cd ~/cloud-dataproc/codelabs/spark-bigquery
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME} \
--jars gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar \
--driver-log-levels root=FATAL \
counts_by_subreddit.py
您可以使用這項指令,透過 Jobs API 將工作提交至 Dataproc。這裡表示工作類型為 pyspark。您可以提供叢集名稱、選用參數 ,以及包含工作的檔案名稱。您在此提供 --jars 參數,以便在工作中加入 spark-bigquery-connector。您也可以使用 --driver-log-levels root=FATAL 設定記錄輸出層級,這樣系統就會抑制所有記錄輸出,只顯示錯誤。Spark 記錄通常相當雜亂。
這項作業需要幾分鐘才能完成,最終輸出內容應如下所示:
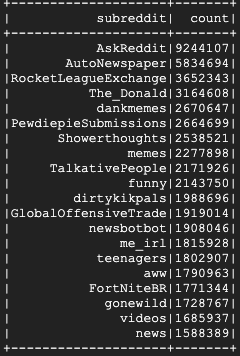
8. 探索 Dataproc 和 Spark 使用者介面
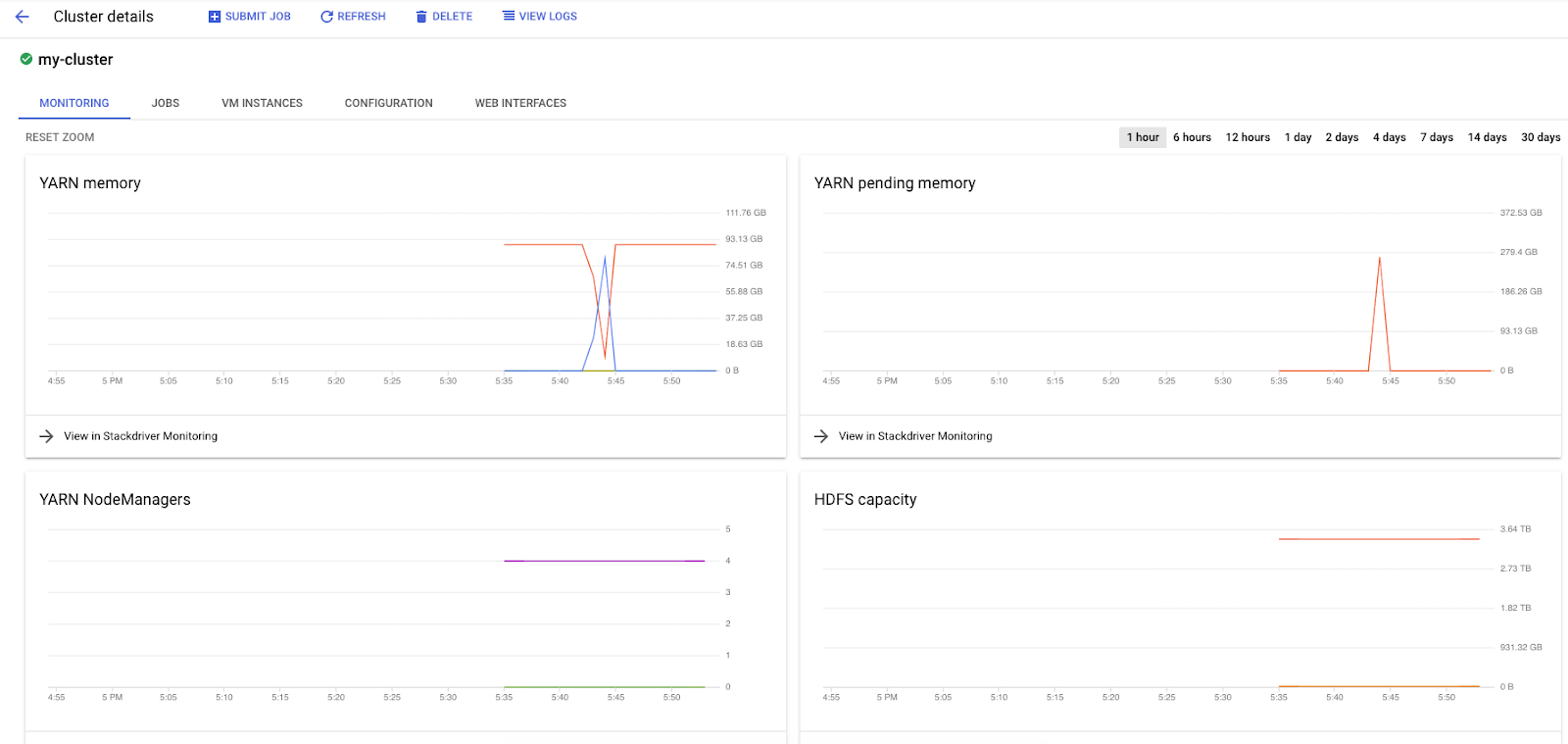
在 Dataproc 上執行 Spark 工作時,您可以使用兩個 UI 檢查工作 / 叢集的狀態。第一個是 Dataproc UI,點選選單圖示並向下捲動至 Dataproc 即可找到。您可以在這裡查看目前可用的記憶體、待處理的記憶體和工作站數量。
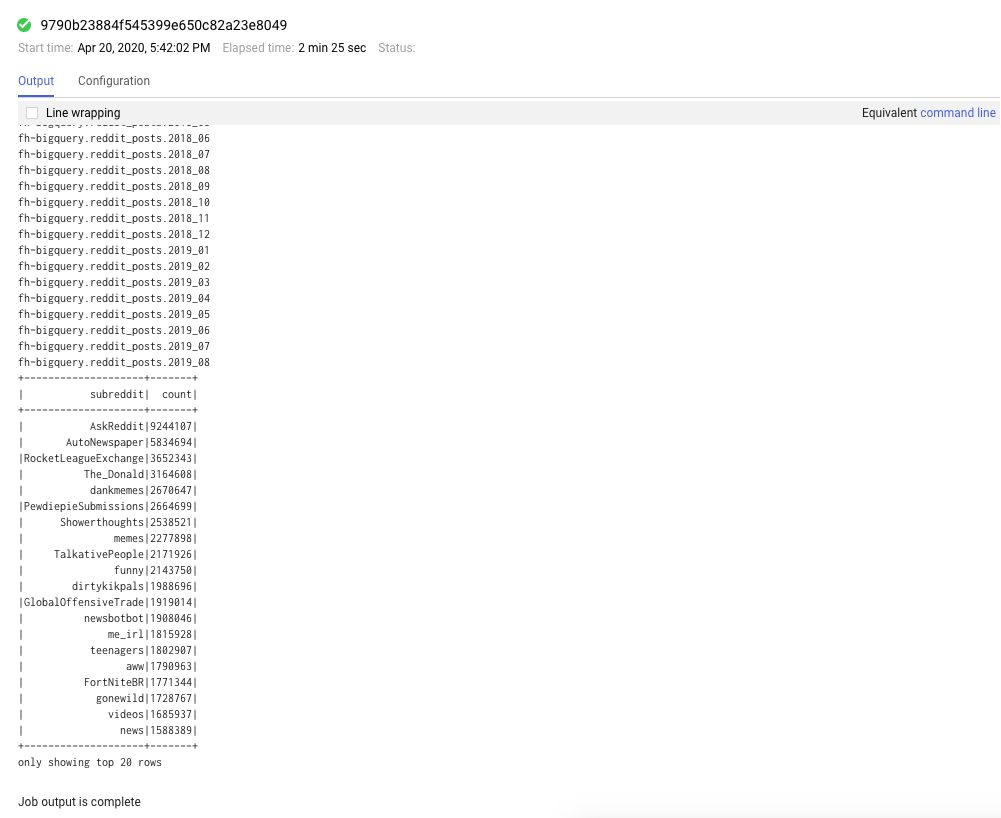
您也可以點選「工作」分頁標籤,查看已完成的工作。按一下特定工作的「工作 ID」,即可查看工作詳細資料,例如記錄和輸出內容。
您也可以查看 Spark UI。在工作頁面中,按一下返回箭頭,然後按一下「Web Interfaces」(網頁介面)。元件閘道下方應會顯示多個選項。設定叢集時,您可以透過「選用元件」啟用許多這類元件。在本實驗室中,請點按「Spark History Server」。

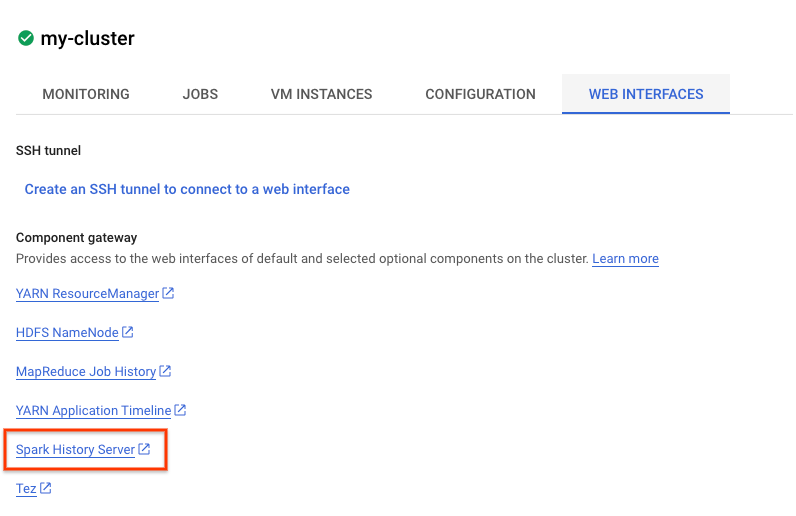
系統應會開啟下列視窗:

所有已完成的工作都會顯示在這裡,您可以點選任何 application_id,進一步瞭解工作資訊。同樣地,您也可以按一下到達網頁最底部的「顯示未完成的申請」,查看目前正在執行的所有工作。
9. 執行回填工作
現在要執行工作,將資料載入記憶體、擷取必要資訊,並將輸出內容傾印至 Google Cloud Storage 值區。您將為每則 Reddit 留言擷取「標題」、「內文」(原始文字) 和「建立時間戳記」。接著,請將這項資料轉換為 CSV 檔、壓縮成 ZIP 檔,然後載入至 URI 為 gs://${BUCKET_NAME}/reddit_posts/YYYY/MM/food.csv.gz 的值區。
您可以再次參閱 Cloud Editor,通讀 cloud-dataproc/codelabs/spark-bigquery/backfill.sh 的程式碼,這是用來執行 cloud-dataproc/codelabs/spark-bigquery/backfill.py 中程式碼的包裝函式指令碼。
cd ~/cloud-dataproc/codelabs/spark-bigquery
bash backfill.sh ${CLUSTER_NAME} ${BUCKET_NAME}
不久後,您應該會看到許多工作完成訊息。這項工作最多可能需要 15 分鐘才能完成。您也可以使用 gsutil 再次檢查儲存空間值區,確認資料是否已成功輸出。所有工作完成後,請執行下列指令:
gsutil ls gs://${BUCKET_NAME}/reddit_posts/*/*/food.csv.gz
您應該會看到以下的輸出內容:
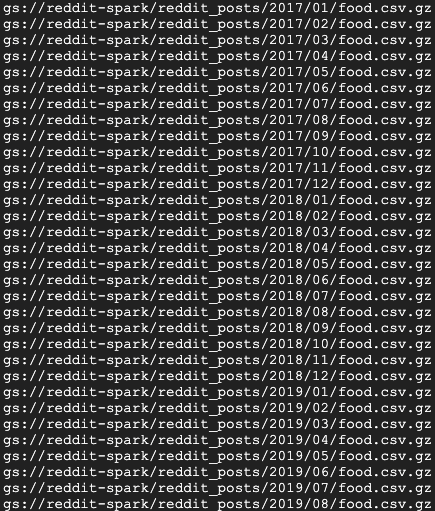
恭喜!您已成功完成 Reddit 留言資料的回填作業。如要瞭解如何根據這項資料建構模型,請繼續進行 Spark-NLP 程式碼研究室。
10. 清除
完成本快速入門導覽課程後,如要避免系統向您的 GCP 帳戶收取不必要的費用,請按照下列步驟操作:
如果您專為本程式碼研究室建立了專案,也可以選擇刪除該專案:
- 前往 GCP 主控台的「Projects」(專案) 頁面。
- 在專案清單中選取要刪除的專案,然後點按「Delete」(刪除)。
- 在方塊中輸入專案 ID,然後按一下「Shut down」(關閉) 刪除專案。
授權
這項內容採用的授權為創用 CC 姓名標示 3.0 通用授權和 Apache 2.0 授權。