
1. Übersicht
In diesem Codelab wird beschrieben, wie Sie eine Datenverarbeitungspipeline mit Apache Spark mit Dataproc auf der Google Cloud Platform erstellen. Im Bereich von Data Science und Data Engineering werden Daten häufig von einem Speicherort gelesen, dann werden sie transformiert und in einen anderen Speicherort geschrieben. Zu den gängigen Transformationen gehören das Ändern des Inhalts der Daten, das Entfernen unnötiger Informationen und das Ändern von Dateitypen.
In diesem Codelab lernen Sie Apache Spark kennen und führen eine Beispielpipeline mit Dataproc mit PySpark (der Python-API von Apache Spark), BigQuery, Google Cloud Storage und Daten von Reddit aus.
2. Einführung in Apache Spark (optional)
Auf der Website heißt es: „Apache Spark ist eine einheitliche Analyse-Engine für die Verarbeitung großer Datenmengen.“ Sie können Daten parallel und im Arbeitsspeicher analysieren und verarbeiten. Das ermöglicht massive parallele Berechnungen auf mehreren verschiedenen Computern und Knoten. Es wurde ursprünglich 2014 als Upgrade für das herkömmliche MapReduce veröffentlicht und ist nach wie vor eines der beliebtesten Frameworks für die Durchführung umfangreicher Berechnungen. Apache Spark ist in Scala geschrieben und bietet daher APIs in Scala, Java, Python und R. Es enthält eine Vielzahl von Bibliotheken wie Spark SQL zum Ausführen von SQL-Abfragen für die Daten, Spark Streaming für das Streamen von Daten, MLlib für maschinelles Lernen und GraphX für die Graphverarbeitung. Alle diese Bibliotheken werden in der Apache Spark-Engine ausgeführt.

Spark kann eigenständig ausgeführt werden oder einen Dienst zur Ressourcenverwaltung wie Yarn, Mesos oder Kubernetes zur Skalierung nutzen. In diesem Codelab verwenden Sie Dataproc, das Yarn nutzt.
Daten in Spark wurden ursprünglich in den Arbeitsspeicher geladen, und zwar in ein sogenanntes RDD (Resilient Distributed Dataset). Die Entwicklung von Spark umfasste seitdem die Einführung von zwei neuen spaltenorientierten Datentypen: das Dataset, das typisiert ist, und der Dataframe, der nicht typisiert ist. RDDs eignen sich im Allgemeinen für alle Arten von Daten, während Datasets und DataFrames für tabellarische Daten optimiert sind. Da Datasets nur mit den Java- und Scala-APIs verfügbar sind, verwenden wir für dieses Codelab die PySpark Dataframe API. Weitere Informationen finden Sie in der Apache Spark-Dokumentation.
3. Anwendungsfall
Data Engineers müssen oft dafür sorgen, dass Data Scientists problemlos auf Daten zugreifen können. Daten sind jedoch oft anfangs unsauber (in ihrem aktuellen Zustand schwer für Analysen zu verwenden) und müssen bereinigt werden, bevor sie wirklich nützlich sind. Ein Beispiel hierfür sind Daten, die aus dem Web gescraped wurden und möglicherweise seltsame Codierungen oder zusätzliche HTML-Tags enthalten.
In diesem Lab laden Sie eine Reihe von Daten aus BigQuery in Form von Reddit-Beiträgen in einen in Dataproc gehosteten Spark-Cluster, extrahieren nützliche Informationen und speichern die verarbeiteten Daten als gezippte CSV-Dateien in Google Cloud Storage.

Der Chief Data Scientist Ihres Unternehmens möchte, dass seine Teams an verschiedenen Problemen im Bereich der Verarbeitung natürlicher Sprache arbeiten. Konkret möchten sie die Daten im Subreddit „r/food“ analysieren. Sie erstellen eine Pipeline für einen Datenexport, der mit einem Backfill von Januar 2017 bis August 2019 beginnt.
4. Über die BigQuery Storage API auf BigQuery zugreifen
Das Abrufen von Daten aus BigQuery mit der API-Methode „tabledata.list“ kann zeitaufwendig und ineffizient sein, wenn die Datenmenge zunimmt. Diese Methode gibt eine Liste von JSON-Objekten zurück und erfordert das sequenzielle Lesen einer Seite nach der anderen, um ein gesamtes Dataset zu lesen.
Die BigQuery Storage API bietet erhebliche Verbesserungen beim Zugriff auf Daten in BigQuery durch die Verwendung eines RPC-basierten Protokolls. Es unterstützt paralleles Lesen und Schreiben von Daten sowie verschiedene Serialisierungsformate wie Apache Avro und Apache Arrow. Das führt zu einer deutlich verbesserten Leistung, insbesondere bei größeren Datasets.
In diesem Codelab verwenden Sie den spark-bigquery-connector zum Lesen und Schreiben von Daten zwischen BigQuery und Spark.
5. Projekt erstellen
Melden Sie sich in der Google Cloud Console unter console.cloud.google.com an und erstellen Sie ein neues Projekt:



Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Google Cloud-Ressourcen verwenden zu können.
Dieses Codelab sollte Sie nicht mehr als ein paar Dollar kosten, aber es könnte mehr sein, wenn Sie sich für mehr Ressourcen entscheiden oder wenn Sie sie laufen lassen. Im letzten Abschnitt dieses Codelabs erfahren Sie, wie Sie Ihr Projekt bereinigen.
Neuen Nutzern der Google Cloud Platform steht eine kostenlose Testversion mit einem Guthaben von 300$ zur Verfügung.
6. Umgebung einrichten
Als Nächstes richten Sie Ihre Umgebung ein. Dazu müssen Sie:
- Compute Engine API, Dataproc API und BigQuery Storage API aktivieren
- Projekteinstellungen konfigurieren
- Dataproc-Cluster erstellen
- Google Cloud Storage-Bucket erstellen
APIs aktivieren und Umgebung konfigurieren
Öffnen Sie die Cloud Shell, indem Sie oben rechts in der Cloud Console auf die Schaltfläche klicken.

Nachdem Cloud Shell geladen wurde, führen Sie die folgenden Befehle aus, um die Compute Engine API, die Dataproc API und die BigQuery Storage API zu aktivieren:
gcloud services enable compute.googleapis.com \
dataproc.googleapis.com \
bigquerystorage.googleapis.com
Legen Sie die Projekt-ID Ihres Projekts fest. Sie finden sie, indem Sie zur Projektauswahlseite wechseln und nach Ihrem Projekt suchen. Dieser muss nicht mit Ihrem Projektnamen übereinstimmen.


Führen Sie den folgenden Befehl aus, um Ihre Projekt-ID festzulegen:
gcloud config set project <project_id>
Legen Sie die Region Ihres Projekts fest, indem Sie eine aus der Liste auswählen. Ein Beispiel dafür ist us-central1.
gcloud config set dataproc/region <region>
Wählen Sie einen Namen für Ihren Dataproc-Cluster aus und erstellen Sie eine Umgebungsvariable dafür.
CLUSTER_NAME=<cluster_name>
Dataproc-Clusters erstellen
Erstellen Sie mit dem folgenden Befehl einen Dataproc-Cluster:
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--worker-machine-type n1-standard-8 \
--num-workers 8 \
--image-version 1.5-debian \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--metadata 'PIP_PACKAGES=google-cloud-storage' \
--optional-components=ANACONDA \
--enable-component-gateway
Es dauert einige Minuten, bis dieser Befehl abgeschlossen ist. So wird der Befehl aufgeschlüsselt:
Damit wird die Erstellung eines Dataproc-Clusters mit dem Namen, den Sie zuvor angegeben haben, gestartet. Wenn Sie die beta API verwenden, können Sie Betafunktionen von Dataproc wie das Component Gateway nutzen.
gcloud beta dataproc clusters create ${CLUSTER_NAME}
Damit wird der Typ der Maschine festgelegt, die für Ihre Worker verwendet werden soll.
--worker-machine-type n1-standard-8
Dadurch wird die Anzahl der Worker festgelegt, die Ihr Cluster haben wird.
--num-workers 8
Dadurch wird die Image-Version von Dataproc festgelegt.
--image-version 1.5-debian
Dadurch werden die Initialisierungsaktionen konfiguriert, die für den Cluster verwendet werden sollen. Hier binden Sie die Initialisierungsaktion pip ein.
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh
Dies sind die Metadaten, die im Cluster enthalten sein sollen. Hier geben Sie Metadaten für die Initialisierungsaktion pip an.
--metadata 'PIP_PACKAGES=google-cloud-storage'
Dadurch werden die optionalen Komponenten festgelegt, die im Cluster installiert werden sollen.
--optional-components=ANACONDA
Dadurch wird das Component Gateway aktiviert, sodass Sie das Component Gateway von Dataproc verwenden können, um gängige UIs wie Zeppelin, Jupyter oder den Spark-Verlauf aufzurufen.
--enable-component-gateway
Eine ausführlichere Einführung in Dataproc finden Sie in diesem Codelab.
Google Cloud Storage-Bucket erstellen
Sie benötigen einen Google Cloud Storage-Bucket für die Ausgabe Ihres Jobs. Legen Sie einen eindeutigen Namen für Ihren Bucket fest und führen Sie den folgenden Befehl aus, um einen neuen Bucket zu erstellen. Bucket-Namen sind für alle Nutzer in allen Google Cloud-Projekten eindeutig. Möglicherweise müssen Sie es also einige Male mit verschiedenen Namen versuchen. Ein Bucket wurde erfolgreich erstellt, wenn Sie keine ServiceException erhalten.
BUCKET_NAME=<bucket_name>
gsutil mb gs://${BUCKET_NAME}
7. Explorative Datenanalyse
Bevor Sie die Vorverarbeitung durchführen, sollten Sie mehr über die Art der Daten erfahren, mit denen Sie es zu tun haben. Dazu werden Sie zwei Methoden zur Datenexploration kennenlernen. Zuerst sehen Sie sich einige Rohdaten in der BigQuery-Web-UI an. Anschließend berechnen Sie die Anzahl der Beiträge pro Subreddit mit PySpark und Dataproc.
BigQuery-Web-UI verwenden
Sehen Sie sich Ihre Daten zuerst in der BigQuery-Web-UI an. Scrollen Sie in der Cloud Console im Menü nach unten und klicken Sie auf „BigQuery“, um die BigQuery-Web-UI zu öffnen.
Führen Sie als Nächstes den folgenden Befehl im Abfrageeditor der BigQuery-Web-UI aus. Dadurch werden 10 vollständige Zeilen der Daten aus dem Januar 2017 zurückgegeben:
select * from fh-bigquery.reddit_posts.2017_01 limit 10;
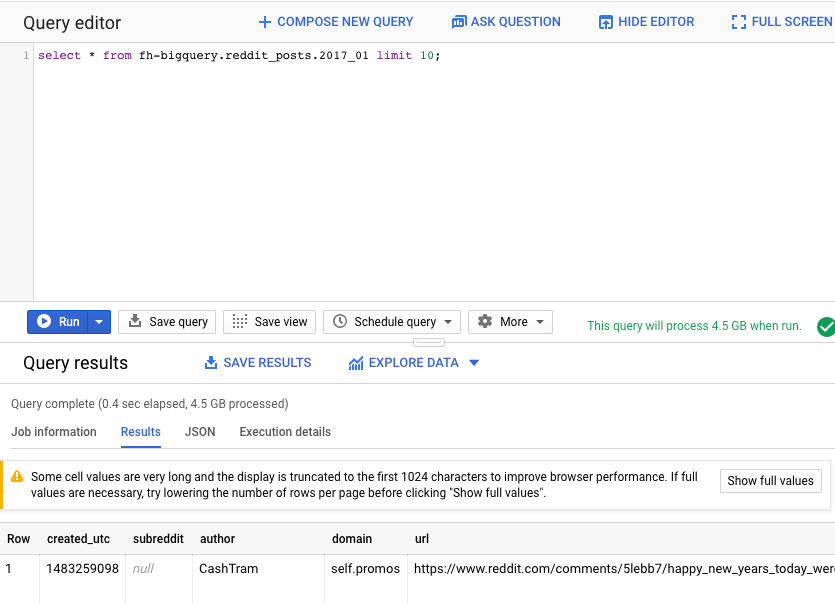
Scrollen Sie auf der Seite, um alle verfügbaren Spalten sowie einige Beispiele zu sehen. Sie sehen insbesondere zwei Spalten, die den Textinhalt der einzelnen Beiträge darstellen: „title“ (Titel) und „selftext“ (Selbsttext), wobei letztere den Haupttext des Beitrags enthält. Beachten Sie auch andere Spalten wie „created_utc“, die die UTC-Zeit angibt, zu der ein Beitrag erstellt wurde, und „subreddit“, die das Subreddit angibt, in dem der Beitrag vorhanden ist.
PySpark-Job ausführen
Führen Sie die folgenden Befehle in Cloud Shell aus, um das Repository mit dem Beispielcode zu klonen und in das richtige Verzeichnis zu wechseln:
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
Mit PySpark können Sie die Anzahl der Beiträge für jedes Subreddit ermitteln. Sie können den Cloud Editor öffnen und das Skript cloud-dataproc/codelabs/spark-bigquery lesen, bevor Sie es im nächsten Schritt ausführen:


Klicken Sie im Cloud Editor auf die Schaltfläche „Terminal öffnen“, um zu Cloud Shell zurückzukehren, und führen Sie den folgenden Befehl aus, um Ihren ersten PySpark-Job auszuführen:
cd ~/cloud-dataproc/codelabs/spark-bigquery
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME} \
--jars gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar \
--driver-log-levels root=FATAL \
counts_by_subreddit.py
Mit diesem Befehl können Sie Jobs über die Jobs API an Dataproc senden. Hier geben Sie den Jobtyp als pyspark an. Sie können den Clusternamen, optionale Parameter und den Namen der Datei mit dem Job angeben. Hier geben Sie den Parameter --jars an, mit dem Sie die spark-bigquery-connector in Ihren Job einbeziehen können. Sie können die Logausgabe auch mit --driver-log-levels root=FATAL festlegen. Dadurch wird die gesamte Logausgabe mit Ausnahme von Fehlern unterdrückt. Spark-Logs sind in der Regel ziemlich umfangreich.
Das sollte einige Minuten dauern. Die endgültige Ausgabe sollte in etwa so aussehen:

8. Dataproc- und Spark-Benutzeroberflächen kennenlernen
Wenn Sie Spark-Jobs in Dataproc ausführen, haben Sie Zugriff auf zwei Benutzeroberflächen, um den Status Ihrer Jobs / Cluster zu prüfen. Die erste ist die Dataproc-UI. Sie finden sie, indem Sie auf das Menüsymbol klicken und zu Dataproc scrollen. Hier sehen Sie den aktuell verfügbaren Arbeitsspeicher sowie den ausstehenden Arbeitsspeicher und die Anzahl der Worker.

Sie können auch auf den Tab „Jobs“ klicken, um abgeschlossene Jobs aufzurufen. Wenn Sie die Jobdetails wie die Logs und die Ausgabe dieser Jobs aufrufen möchten, klicken Sie auf die Job-ID eines bestimmten Jobs. 

Sie können sich auch die Spark-Benutzeroberfläche ansehen. Klicken Sie auf der Jobseite auf den Zurück-Pfeil und dann auf „Weboberflächen“. Unter „Component Gateway“ sollten mehrere Optionen angezeigt werden. Viele dieser Komponenten können beim Einrichten des Clusters über Optionale Komponenten aktiviert werden. Klicken Sie für dieses Lab auf „Spark History Server“.


Dadurch sollte das folgende Fenster geöffnet werden:

Alle abgeschlossenen Jobs werden hier angezeigt. Sie können auf eine beliebige application_id klicken, um weitere Informationen zum Job zu erhalten. Sie können auch ganz unten auf der Landingpage auf „Unvollständige Bewerbungen anzeigen“ klicken, um alle derzeit laufenden Jobs aufzurufen.
9. Backfill-Job ausführen
Sie führen jetzt einen Job aus, der Daten in den Arbeitsspeicher lädt, die erforderlichen Informationen extrahiert und die Ausgabe in einen Google Cloud Storage-Bucket schreibt. Sie extrahieren für jeden Reddit-Kommentar den „Titel“, den „Text“ (Rohtext) und den „Zeitstempel der Erstellung“. Anschließend konvertieren Sie diese Daten in eine CSV-Datei, zippen sie und laden sie in einen Bucket mit dem URI gs://${BUCKET_NAME}/reddit_posts/YYYY/MM/food.csv.gz hoch.
Sie können sich noch einmal den Cloud Editor ansehen, um den Code für cloud-dataproc/codelabs/spark-bigquery/backfill.sh zu lesen. Dabei handelt es sich um ein Wrapper-Skript zum Ausführen des -Codes in cloud-dataproc/codelabs/spark-bigquery/backfill.py.
cd ~/cloud-dataproc/codelabs/spark-bigquery
bash backfill.sh ${CLUSTER_NAME} ${BUCKET_NAME}
Kurz darauf sollten mehrere Meldungen zum Abschluss von Jobs angezeigt werden. Die Ausführung des Jobs kann bis zu 15 Minuten dauern. Sie können auch mit gsutil prüfen, ob die Datenausgabe in Ihrem Speicher-Bucket erfolgreich war. Wenn alle Jobs abgeschlossen sind, führen Sie den folgenden Befehl aus:
gsutil ls gs://${BUCKET_NAME}/reddit_posts/*/*/food.csv.gz
Es sollte folgende Ausgabe angezeigt werden:
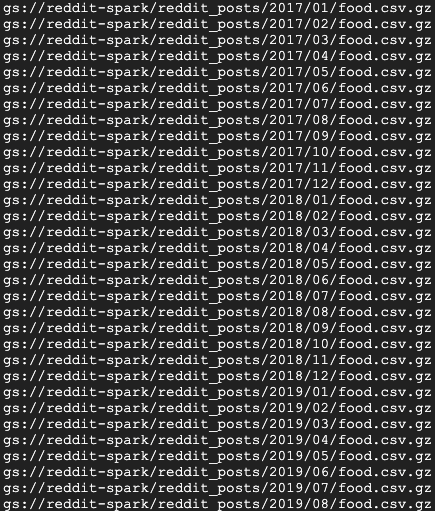
Herzlichen Glückwunsch! Sie haben erfolgreich einen Backfill für Ihre Reddit-Kommentardaten durchgeführt. Wenn Sie wissen möchten, wie Sie Modelle auf Grundlage dieser Daten erstellen können, lesen Sie das Spark-NLP-Codelab.
10. Bereinigen
So vermeiden Sie, dass Ihrem GCP-Konto nach Abschluss dieser Kurzanleitung unnötige Gebühren in Rechnung gestellt werden:
- Löschen Sie den Cloud Storage-Bucket für die Umgebung, die Sie erstellt haben.
- Dataproc-Umgebung löschen
Wenn Sie ein Projekt nur für dieses Codelab erstellt haben, können Sie es optional auch löschen:
- Rufen Sie in der GCP Console die Seite Projekte auf.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Feld die Projekt-ID ein und klicken Sie auf Beenden, um das Projekt zu löschen.
Lizenz
Dieses Werk ist unter einer Creative Commons Attribution 3.0 Generic License und einer Apache 2.0-Lizenz lizenziert.