
1. 개요
이 Codelab에서는 Apache Spark를 Dataproc과 함께 사용하여 Google Cloud Platform에서 데이터 처리 파이프라인을 만드는 방법을 설명합니다. 하나의 스토리지 위치에서 데이터를 읽고, 변환을 수행하며, 다른 스토리지 위치에 쓰는 것이 데이터 과학 및 데이터 엔지니어링에서 일반적인 사용 사례입니다. 일반적인 변환에는 데이터 콘텐츠 변경, 불필요한 정보 삭제, 파일 유형 변경이 포함됩니다.
이 Codelab에서는 Apache Spark에 대해 알아보고, PySpark (Apache Spark의 Python API), BigQuery, Google Cloud Storage, Reddit의 데이터를 사용하여 Dataproc으로 샘플 파이프라인을 실행합니다.
2. Apache Spark 소개 (선택사항)
웹사이트에 따르면 " Apache Spark는 대규모 데이터 처리를 위한 통합 분석 엔진"입니다. 데이터를 병렬로, 메모리 내에서 분석하고 처리할 수 있으므로 여러 머신과 노드에서 대규모 병렬 컴퓨팅이 가능합니다. 원래 2014년에 기존 MapReduce의 업그레이드로 출시되었으며, 여전히 대규모 컴퓨팅을 실행하는 데 가장 인기 있는 프레임워크 중 하나입니다. Apache Spark는 Scala로 작성되었으며, 이후 Scala, Java, Python, R에서 API를 제공합니다. 데이터에 SQL 쿼리를 실행하는 Spark SQL, 데이터 스트리밍을 위한 Spark Streaming, 머신러닝을 위한 MLlib, 그래프 처리를 위한 GraphX 와 같은 다양한 라이브러리가 포함되어 있으며, 이 모든 라이브러리는 Apache Spark 엔진에서 실행됩니다.

Spark는 자체적으로 실행되거나 확장하기 위해 Yarn, Mesos, Kubernetes와 같은 리소스 관리 서비스를 활용할 수 있습니다. 이 Codelab에서는 Yarn을 사용하는 Dataproc을 사용합니다.
Spark의 데이터는 원래 RDD(Resilient Distributed Dataset)라고 하는 메모리에 로드되었습니다. 이후 Spark 개발에는 유형이 지정된 데이터 세트와 유형이 지정되지 않은 데이터 프레임이라는 두 가지 새로운 열 형식 데이터 유형이 추가되었습니다. 대략적으로 말하면 RDD는 모든 유형의 데이터에 적합한 반면 데이터 세트와 데이터 프레임은 표 형식 데이터에 최적화되어 있습니다. 데이터 세트는 Java 및 Scala API에서만 사용할 수 있으므로 이 Codelab에서는 PySpark 데이터 프레임 API를 사용합니다. 자세한 내용은 Apache Spark 문서를 참고하세요.
3. 사용 사례
데이터 엔지니어는 데이터 과학자가 데이터에 쉽게 액세스할 수 있도록 해야 하는 경우가 많습니다. 하지만 데이터는 종종 처음에는 정리되지 않은 상태 (현재 상태에서 분석에 사용하기 어려움)이며 유용하게 사용하려면 정리해야 합니다. 예를 들어 웹에서 스크랩한 데이터에는 이상한 인코딩이나 불필요한 HTML 태그가 포함될 수 있습니다.
이 실습에서는 Reddit 게시물 형식으로 BigQuery에서 데이터 세트를 로드하여 Dataproc에서 호스팅되는 Spark 클러스터에 로드하고, 유용한 정보를 추출하고, 처리된 데이터를 Google Cloud Storage에 압축된 CSV 파일로 저장합니다.

회사의 최고 데이터 과학자는 팀이 다양한 자연어 처리 문제를 해결하는 데 관심이 있습니다. 특히 'r/food' 서브레딧의 데이터를 분석하는 데 관심이 있습니다. 2017년 1월부터 2019년 8월까지의 백필로 시작하는 데이터 덤프 파이프라인을 만듭니다.
4. BigQuery Storage API를 통해 BigQuery에 액세스
tabledata.list API 메서드를 사용하여 BigQuery에서 데이터를 가져오는 것은 데이터 양이 확장됨에 따라 시간이 오래 걸리고 효율적이지 않을 수 있습니다. 이 메서드는 JSON 객체 목록을 반환하며 전체 데이터 세트를 읽으려면 한 번에 한 페이지씩 순차적으로 읽어야 합니다.
BigQuery Storage API는 RPC 기반 프로토콜을 사용하여 BigQuery의 데이터 액세스를 크게 개선합니다. 데이터 읽기 및 쓰기를 병렬로 지원하며 Apache Avro 및 Apache Arrow와 같은 다양한 직렬화 형식을 지원합니다. 대략적으로 말하면 특히 대규모 데이터 세트에서 성능이 크게 개선됩니다.
이 Codelab에서는 spark-bigquery-connector를 사용하여 BigQuery와 Spark 간에 데이터를 읽고 씁니다.
5. 프로젝트 만들기
console.cloud.google.com에서 Google Cloud Platform 콘솔에 로그인하고 새 프로젝트를 만듭니다.



그런 후 Google Cloud 리소스를 사용할 수 있도록 Cloud Console에서 결제를 사용 설정해야 합니다.
이 Codelab을 실행하는 과정에는 많은 비용이 들지 않지만 더 많은 리소스를 사용하려고 하거나 실행 중일 경우 비용이 더 들 수 있습니다. 이 Codelab의 마지막 섹션에서는 프로젝트를 삭제하는 방법을 안내합니다.
Google Cloud Platform 신규 사용자는 $300 상당의 무료 체험판을 사용할 수 있습니다.
6. 환경 설정하기
이제 다음을 수행하여 환경을 설정합니다.
- Compute Engine, Dataproc, BigQuery Storage API 사용 설정
- 프로젝트 설정 구성
- Dataproc 클러스터 만들기
- Google Cloud Storage 버킷 만들기
API 사용 설정 및 환경 구성
Cloud Console의 오른쪽 상단에 있는 버튼을 눌러 Cloud Shell을 엽니다.

Cloud Shell이 로드되면 다음 명령어를 실행하여 Compute Engine, Dataproc, BigQuery Storage API를 사용 설정합니다.
gcloud services enable compute.googleapis.com \
dataproc.googleapis.com \
bigquerystorage.googleapis.com
프로젝트의 프로젝트 ID 를 설정합니다. 프로젝트 선택 페이지로 이동하여 프로젝트를 검색하면 찾을 수 있습니다. 프로젝트 이름과 동일하지 않을 수 있습니다.


다음 명령어를 실행하여 프로젝트 ID를 설정합니다.
gcloud config set project <project_id>
여기 목록에서 하나를 선택하여 프로젝트의 리전 을 설정합니다 여기. 예를 들어 us-central1일 수 있습니다.
gcloud config set dataproc/region <region>
Dataproc 클러스터의 이름을 선택하고 환경 변수를 만듭니다.
CLUSTER_NAME=<cluster_name>
Dataproc 클러스터 만들기
다음 명령어를 실행하여 Dataproc 클러스터를 만듭니다.
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--worker-machine-type n1-standard-8 \
--num-workers 8 \
--image-version 1.5-debian \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--metadata 'PIP_PACKAGES=google-cloud-storage' \
--optional-components=ANACONDA \
--enable-component-gateway
이 명령어는 완료하는 데 몇 분 정도 걸립니다. 명령어를 분석하려면 다음 단계를 따르세요.
그러면 이전에 제공한 이름으로 Dataproc 클러스터 생성이 시작됩니다. beta API를 사용하면 구성요소 게이트웨이와 같은 Dataproc의 베타 기능을 사용할 수 있습니다.
gcloud beta dataproc clusters create ${CLUSTER_NAME}
그러면 작업자에 사용할 유형의 머신이 설정됩니다.
--worker-machine-type n1-standard-8
그러면 클러스터에 포함될 작업자 수가 설정됩니다.
--num-workers 8
그러면 Dataproc의 이미지 버전이 설정됩니다.
--image-version 1.5-debian
그러면 클러스터에서 사용할 초기화 작업이 구성됩니다. 여기서는 pip 초기화 작업을 포함합니다.
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh
클러스터에 포함할 메타데이터입니다. 여기서는 pip 초기화 작업의 메타데이터를 제공합니다.
--metadata 'PIP_PACKAGES=google-cloud-storage'
그러면 클러스터에 설치할 선택적 구성요소가 설정됩니다.
--optional-components=ANACONDA
그러면 구성요소 게이트웨이가 사용 설정되어 Dataproc의 구성요소 게이트웨이를 사용하여 Zeppelin, Jupyter, Spark 기록과 같은 일반적인 UI를 볼 수 있습니다.
--enable-component-gateway
Dataproc에 대한 자세한 소개는 이 Codelab을 참고하세요.
Google Cloud Storage 버킷 만들기
작업 출력에는 Google Cloud Storage 버킷이 필요합니다. 버킷의 고유한 이름을 결정하고 다음 명령어를 실행하여 새 버킷을 만듭니다. 버킷 이름은 모든 사용자의 모든 Google Cloud 프로젝트에서 고유하므로 다른 이름으로 여러 번 시도해야 할 수 있습니다. ServiceException이 발생하지 않으면 버킷이 생성됩니다.
BUCKET_NAME=<bucket_name>
gsutil mb gs://${BUCKET_NAME}
7. 탐색적 데이터 분석
전처리를 실행하기 전에 처리할 데이터의 특성을 자세히 알아야 합니다. 이렇게 하려면 두 가지 데이터 탐색 방법을 살펴봅니다. 먼저 BigQuery 웹 UI를 사용하여 원시 데이터를 보고, 그런 다음 PySpark 및 Dataproc을 사용하여 서브레딧당 게시물 수를 계산합니다.
BigQuery 웹 UI 사용
BigQuery 웹 UI를 사용하여 데이터를 봅니다. Cloud Console의 메뉴 아이콘에서 아래로 스크롤하고 'BigQuery'를 눌러 BigQuery 웹 UI를 엽니다.
그런 다음 BigQuery 웹 UI 쿼리 편집기에서 다음 명령어를 실행합니다. 그러면 2017년 1월의 데이터에서 전체 행 10개가 반환됩니다.
select * from fh-bigquery.reddit_posts.2017_01 limit 10;

페이지를 스크롤하여 사용 가능한 모든 열과 몇 가지 예를 볼 수 있습니다. 특히 각 게시물의 텍스트 콘텐츠를 나타내는 두 개의 열('title' 및 'selftext')이 표시되며, 후자는 게시물의 본문입니다. 또한 게시물이 작성된 UTC 시간인 'created_utc'와 게시물이 있는 서브레딧인 'subreddit'와 같은 다른 열도 확인합니다.
PySpark 작업 실행
Cloud Shell에서 다음 명령어를 실행하여 샘플 코드가 포함된 저장소를 클론하고 올바른 디렉터리로 cd합니다.
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
PySpark를 사용하여 각 서브레딧에 있는 게시물 수를 확인할 수 있습니다. Cloud Editor를 열고 다음 단계에서 실행하기 전에 스크립트 cloud-dataproc/codelabs/spark-bigquery를 읽을 수 있습니다.

Cloud Editor에서 '터미널 열기' 버튼을 클릭하여 Cloud Shell로 다시 전환하고 다음 명령어를 실행하여 첫 번째 PySpark 작업을 실행합니다.
cd ~/cloud-dataproc/codelabs/spark-bigquery
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME} \
--jars gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar \
--driver-log-levels root=FATAL \
counts_by_subreddit.py
이 명령어를 사용하면 Jobs API를 통해 Dataproc에 작업을 제출할 수 있습니다. 여기서는 작업 유형을 pyspark로 나타냅니다. 클러스터 이름, 선택적 매개변수 및 작업이 포함된 파일 이름을 제공할 수 있습니다. 여기서는 작업에 spark-bigquery-connector를 포함할 수 있는 --jars 매개변수를 제공합니다. 오류를 제외한 모든 로그 출력을 표시하지 않는 --driver-log-levels root=FATAL을 사용하여 로그 출력 수준을 설정할 수도 있습니다. Spark 로그는 다소 시끄러운 경향이 있습니다.
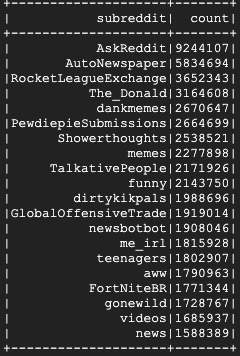
실행하는 데 몇 분 정도 걸리며 최종 출력은 다음과 같이 표시됩니다.
8. Dataproc 및 Spark UI 살펴보기
Dataproc에서 Spark 작업을 실행할 때 작업 / 클러스터의 상태를 확인하기 위한 두 가지 UI에 액세스할 수 있습니다. 첫 번째는 Dataproc UI로, 메뉴 아이콘을 클릭하고 Dataproc으로 스크롤하여 찾을 수 있습니다. 여기서는 사용 가능한 현재 메모리와 보류 중인 메모리, 작업자 수를 확인할 수 있습니다.

작업 탭을 클릭하여 완료된 작업을 볼 수도 있습니다. 특정 작업의 작업 ID를 클릭하면 해당 작업의 로그 및 출력과 같은 작업 세부정보를 볼 수 있습니다. 
Spark UI를 볼 수도 있습니다. 작업 페이지에서 뒤로 화살표를 클릭한 후 웹 인터페이스를 클릭합니다. 구성요소 게이트웨이에 여러 옵션이 표시됩니다. 이러한 옵션은 클러스터를 설정할 때 선택적 구성요소를 통해 사용 설정할 수 있습니다. 이 실습에서는 'Spark 기록 서버'를 클릭합니다.



그러면 다음 창이 열립니다.

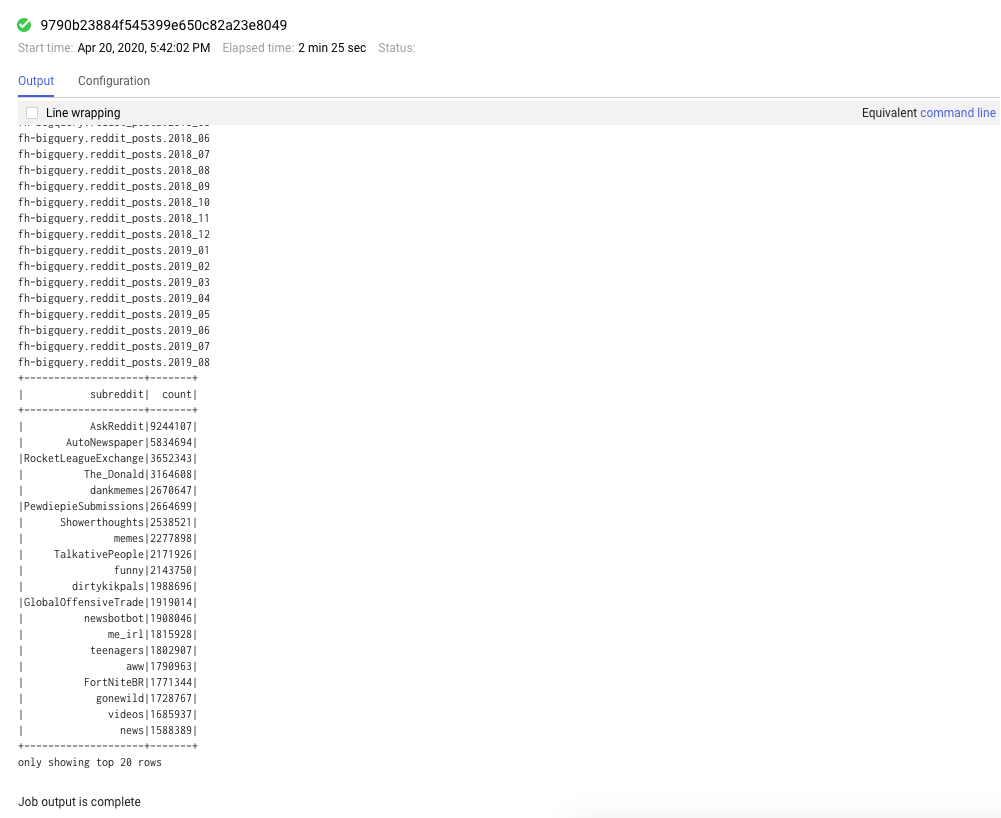
완료된 모든 작업이 여기에 표시되며 application_id를 클릭하여 작업에 대한 자세한 정보를 확인할 수 있습니다. 마찬가지로 방문 페이지의 맨 아래에 있는 '완료되지 않은 애플리케이션 표시'를 클릭하여 현재 실행 중인 모든 작업을 볼 수 있습니다.
9. 백필 작업 실행
이제 데이터를 메모리에 로드하고, 필요한 정보를 추출하고, 출력을 Google Cloud Storage 버킷에 덤프하는 작업을 실행합니다. 각 Reddit 댓글의 'title', 'body'(원시 텍스트), 'timestamp created'를 추출합니다. 그런 다음 이 데이터를 가져와서 CSV로 변환하고, 압축하고, gs://${BUCKET_NAME}/reddit_posts/YYYY/MM/food.csv.gz URI가 있는 버킷에 로드합니다.
Cloud Editor를 다시 참조하여 cloud-dataproc/codelabs/spark-bigquery/backfill.py에서 코드를 실행하는 래퍼 스크립트인 cloud-dataproc/codelabs/spark-bigquery/backfill.sh의 코드를 읽을 수 있습니다.
cd ~/cloud-dataproc/codelabs/spark-bigquery
bash backfill.sh ${CLUSTER_NAME} ${BUCKET_NAME}
곧 여러 작업 완료 메시지가 표시됩니다. 작업이 완료되는 데 최대 15분이 걸릴 수 있습니다. gsutil을 사용하여 스토리지 버킷을 다시 확인하여 데이터 출력이 성공했는지 확인할 수도 있습니다. 모든 작업이 완료되면 다음 명령어를 실행합니다.
gsutil ls gs://${BUCKET_NAME}/reddit_posts/*/*/food.csv.gz
다음과 같은 출력이 표시됩니다.

축하합니다. Reddit 댓글 데이터의 백필을 완료했습니다. 이 데이터를 기반으로 모델을 빌드하는 방법에 관심이 있다면 Spark-NLP Codelab을 계속 진행하세요.
10. 삭제
이 빠른 시작을 완료한 후 GCP 계정에 불필요한 요금이 청구되지 않도록 하려면 다음 단계를 따르세요.
이 Codelab만을 위한 프로젝트를 생성한 경우 선택적으로 프로젝트를 삭제할 수도 있습니다.
- GCP 콘솔에서 프로젝트 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제 를 클릭합니다.
- 상자에 프로젝트 ID를 입력하고 종료 를 클릭하여 프로젝트를 삭제합니다.
라이선스
이 작업물은 크리에이티브 커먼즈 저작자표시 3.0 일반 라이선스 및 Apache 2.0 라이선스에 따라 이용할 수 있습니다.