
1. Giới thiệu
Các sản phẩm AI tạo sinh tương đối mới và hành vi của một ứng dụng có thể đa dạng hơn so với các dạng phần mềm trước đây. Điều này khiến việc kiểm tra các mô hình học máy đang được sử dụng, xem xét các ví dụ về hành vi của mô hình và điều tra những điểm bất ngờ trở nên quan trọng.
Công cụ diễn giải việc học (LIT; trang web, GitHub) là một nền tảng để gỡ lỗi và phân tích các mô hình học máy nhằm tìm hiểu lý do và cách thức các mô hình này hoạt động.
Trong lớp học lập trình này, bạn sẽ tìm hiểu cách sử dụng LIT để khai thác tối đa mô hình Gemma của Google. Lớp học lập trình này minh hoạ cách sử dụng mức độ nổi bật của chuỗi (một kỹ thuật diễn giải) để phân tích các phương pháp thiết kế câu lệnh khác nhau.
Mục tiêu học tập:
- Hiểu rõ mức độ nổi bật của chuỗi và cách sử dụng mức độ này trong phân tích mô hình.
- Thiết lập LIT cho Gemma để tính toán đầu ra của câu lệnh và mức độ nổi bật của chuỗi.
- Sử dụng mức độ nổi bật của chuỗi thông qua mô-đun LM Salience để hiểu tác động của thiết kế câu lệnh đối với kết quả đầu ra của mô hình.
- Thử nghiệm các điểm cải tiến được giả định về câu lệnh trong LIT và xem tác động của các điểm cải tiến đó.
Lưu ý: lớp học lập trình này sử dụng việc triển khai KerasNLP của Gemma và TensorFlow phiên bản 2 cho phần phụ trợ. Bạn nên sử dụng một nhân GPU để theo dõi.
2. Mức độ nổi bật của chuỗi và các cách sử dụng trong phân tích mô hình
Các mô hình tạo sinh chuyển văn bản thành văn bản (chẳng hạn như Gemma) sẽ lấy một chuỗi đầu vào dưới dạng văn bản được mã hoá thành mã thông báo và tạo ra các mã thông báo mới thường là phần tiếp theo hoặc phần hoàn chỉnh cho đầu vào đó. Quá trình tạo này diễn ra mỗi lần một mã thông báo, nối (trong một vòng lặp) từng mã thông báo mới được tạo vào dữ liệu đầu vào cộng với mọi thế hệ trước cho đến khi mô hình đạt đến một điều kiện dừng. Ví dụ: khi mô hình tạo ra một mã thông báo kết thúc chuỗi (EOS) hoặc đạt đến độ dài tối đa được xác định trước.
Phương pháp nổi bật là một lớp kỹ thuật AI có thể giải thích (XAI) có thể cho bạn biết những phần nào của dữ liệu đầu vào là quan trọng đối với mô hình cho các phần khác nhau của dữ liệu đầu ra. LIT hỗ trợ các phương pháp nổi bật cho nhiều nhiệm vụ phân loại, giúp giải thích mức độ tác động của một chuỗi mã thông báo đầu vào đối với nhãn được dự đoán. Mức độ nổi bật của chuỗi tổng quát hoá các phương thức này cho các mô hình tạo văn bản chuyển văn bản thành văn bản và giải thích tác động của các mã thông báo trước đó đối với các mã thông báo được tạo.
Bạn sẽ sử dụng phương thức Grad L2 Norm ở đây cho độ nổi bật của chuỗi. Phương thức này phân tích độ dốc của mô hình và cung cấp mức độ ảnh hưởng của mỗi mã thông báo trước đó đối với đầu ra. Phương pháp này đơn giản và hiệu quả, đồng thời đã được chứng minh là hoạt động hiệu quả trong việc phân loại và các chế độ cài đặt khác. Điểm nổi bật càng cao thì mức độ ảnh hưởng càng lớn. Phương pháp này được dùng trong LIT vì được hiểu rõ và sử dụng rộng rãi trong cộng đồng nghiên cứu khả năng diễn giải.
Các phương pháp nổi bật dựa trên độ dốc nâng cao hơn bao gồm Grad ⋅ Input và độ dốc tích hợp. Ngoài ra, còn có các phương pháp dựa trên việc loại bỏ, chẳng hạn như LIME và SHAP. Các phương pháp này có thể mạnh mẽ hơn nhưng tốn kém hơn đáng kể khi tính toán. Hãy tham khảo bài viết này để biết thông tin so sánh chi tiết về các phương pháp nổi bật.
Bạn có thể tìm hiểu thêm về khoa học của các phương pháp nổi bật trong phần giới thiệu tương tác này về mức độ nổi bật.
3. Nhập, Môi trường và Mã thiết lập khác
Bạn nên làm theo lớp học lập trình này trong Colab mới. Bạn nên sử dụng thời gian chạy của trình tăng tốc vì bạn sẽ tải một mô hình vào bộ nhớ. Tuy nhiên, hãy lưu ý rằng các lựa chọn về trình tăng tốc sẽ thay đổi theo thời gian và chịu các hạn chế. Colab cung cấp gói thuê bao có trả phí nếu bạn muốn sử dụng các bộ tăng tốc mạnh mẽ hơn. Ngoài ra, bạn có thể sử dụng thời gian chạy cục bộ nếu máy của bạn có GPU phù hợp.
Lưu ý: bạn có thể thấy một số cảnh báo dưới dạng
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
Bạn có thể bỏ qua những cảnh báo này.
Cài đặt LIT và Keras NLP
Đối với lớp học lập trình này, bạn sẽ cần phiên bản gần đây của keras (3) keras-nlp (0.14.) và lit-nlp (1.2), cũng như một tài khoản Kaggle để tải mô hình cơ sở xuống.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Quyền truy cập vào Kaggle
Để xác thực bằng Kaggle, bạn có thể:
- Lưu trữ thông tin đăng nhập của bạn trong một tệp, chẳng hạn như
~/.kaggle/kaggle.json; - Sử dụng các biến môi trường
KAGGLE_USERNAMEvàKAGGLE_KEY; hoặc - Chạy đoạn mã sau trong một môi trường Python tương tác, chẳng hạn như Google Colab.
import kagglehub
kagglehub.login()
Hãy xem tài liệu kagglehub để biết thêm thông tin chi tiết và nhớ chấp nhận thoả thuận cấp phép Gemma.
Định cấu hình Keras
Keras 3 hỗ trợ nhiều phần phụ trợ học sâu, bao gồm Tensorflow (mặc định), PyTorch và JAX. Phần phụ trợ được định cấu hình bằng biến môi trường KERAS_BACKEND. Bạn phải đặt biến này trước khi nhập thư viện Keras. Đoạn mã sau đây cho biết cách thiết lập biến này trong môi trường Python tương tác.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. Thiết lập LIT
Bạn có thể sử dụng LIT trong Sổ tay Python hoặc thông qua một máy chủ web. Lớp học lập trình này tập trung vào trường hợp sử dụng Sổ tay. Bạn nên làm theo hướng dẫn trong Google Colab.
Trong Lớp học lập trình này, bạn sẽ tải Gemma phiên bản 2 2B IT bằng chế độ cài đặt sẵn KerasNLP. Đoạn mã sau đây khởi tạo Gemma và tải một tập dữ liệu mẫu trong một tiện ích Sổ tay LIT.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
Bạn có thể định cấu hình tiện ích bằng cách thay đổi các giá trị được truyền đến 2 đối số vị trí bắt buộc:
datasets_config: Danh sách các chuỗi chứa tên tập dữ liệu và đường dẫn để tải, dưới dạng "tập dữ liệu:đường dẫn", trong đó đường dẫn có thể là URL hoặc đường dẫn tệp cục bộ. Ví dụ bên dưới sử dụng giá trị đặc biệtsample_promptsđể tải các câu lệnh mẫu có trong bản phân phối LIT.models_config: Danh sách các chuỗi chứa tên mô hình và đường dẫn để tải, dưới dạng "model:path", trong đó đường dẫn có thể là URL, đường dẫn tệp cục bộ hoặc tên của một chế độ cài đặt sẵn cho khung học sâu đã định cấu hình.
Sau khi bạn định cấu hình LIT để sử dụng mô hình mà bạn quan tâm, hãy chạy đoạn mã sau để kết xuất tiện ích trong Sổ tay.
lit_widget.render(open_in_new_tab=True)
Sử dụng dữ liệu của riêng bạn
Là một mô hình tạo sinh chuyển văn bản thành văn bản, Gemma nhận văn bản đầu vào và tạo văn bản đầu ra. LIT sử dụng một API có ý kiến để truyền đạt cấu trúc của các tập dữ liệu đã tải cho các mô hình. Các LLM trong LIT được thiết kế để hoạt động với những tập dữ liệu cung cấp 2 trường:
prompt: Đầu vào cho mô hình mà từ đó văn bản sẽ được tạo; vàtarget: Một chuỗi mục tiêu không bắt buộc, chẳng hạn như câu trả lời "sự thật khách quan" của người đánh giá hoặc câu trả lời được tạo sẵn từ một mô hình khác.
LIT bao gồm một nhóm nhỏ sample_prompts với các ví dụ từ những nguồn sau đây hỗ trợ Lớp học lập trình này và hướng dẫn gỡ lỗi bằng câu lệnh mở rộng của LIT.
- GSM8K: Giải toán tiểu học bằng một vài ví dụ.
- Gigaword Benchmark: Tạo dòng tiêu đề cho một bộ sưu tập các bài viết ngắn.
- Câu lệnh theo hiến pháp: Tạo ý tưởng mới về cách sử dụng các đối tượng theo nguyên tắc/ranh giới.
Bạn cũng có thể dễ dàng tải dữ liệu của riêng mình, dưới dạng tệp .jsonl chứa các bản ghi có trường prompt và tuỳ chọn target (ví dụ), hoặc từ bất kỳ định dạng nào bằng cách sử dụng Dataset API của LIT.
Chạy ô bên dưới để tải các câu lệnh mẫu.
5. Phân tích câu lệnh có ít ví dụ cho Gemma trong LIT
Ngày nay, việc đưa ra câu lệnh vừa là nghệ thuật vừa là khoa học, và LIT có thể giúp bạn cải thiện câu lệnh một cách thực nghiệm cho các mô hình ngôn ngữ lớn, chẳng hạn như Gemma. Tiếp theo, bạn sẽ thấy ví dụ về cách sử dụng LIT để khám phá hành vi của Gemma, dự đoán các vấn đề tiềm ẩn và cải thiện độ an toàn của mô hình này.
Xác định lỗi trong câu lệnh phức tạp
Hai kỹ thuật quan trọng nhất để tạo câu lệnh cho các nguyên mẫu và ứng dụng dựa trên LLM chất lượng cao là đặt câu lệnh dựa trên một vài ví dụ (bao gồm các ví dụ về hành vi mong muốn trong câu lệnh) và chuỗi suy luận (bao gồm một dạng giải thích hoặc lý luận trước khi LLM đưa ra kết quả cuối cùng). Tuy nhiên, việc tạo một câu lệnh hiệu quả thường vẫn là một thách thức.
Hãy xem xét ví dụ về việc giúp người dùng đánh giá xem họ có thích món ăn dựa trên khẩu vị của họ hay không. Một mẫu lời nhắc ban đầu theo chuỗi suy luận có thể trông như sau:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
Bạn có phát hiện ra vấn đề với câu lệnh này không? LIT sẽ giúp bạn kiểm tra câu lệnh bằng mô-đun Mức độ nổi bật của mô hình ngôn ngữ (LM).
6. Sử dụng độ nổi bật của chuỗi để gỡ lỗi
Độ nổi bật được tính ở cấp độ nhỏ nhất có thể (tức là cho mỗi mã thông báo đầu vào), nhưng LIT có thể tổng hợp độ nổi bật của mã thông báo thành các khoảng lớn hơn dễ diễn giải hơn, chẳng hạn như dòng, câu hoặc từ. Tìm hiểu thêm về độ nổi bật và cách sử dụng độ nổi bật để xác định những điểm thiên vị ngoài ý muốn trong Saliency Explorable (Công cụ khám phá độ nổi bật) của chúng tôi.
Hãy bắt đầu bằng cách cung cấp cho câu lệnh một ví dụ đầu vào mới cho các biến mẫu câu lệnh:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
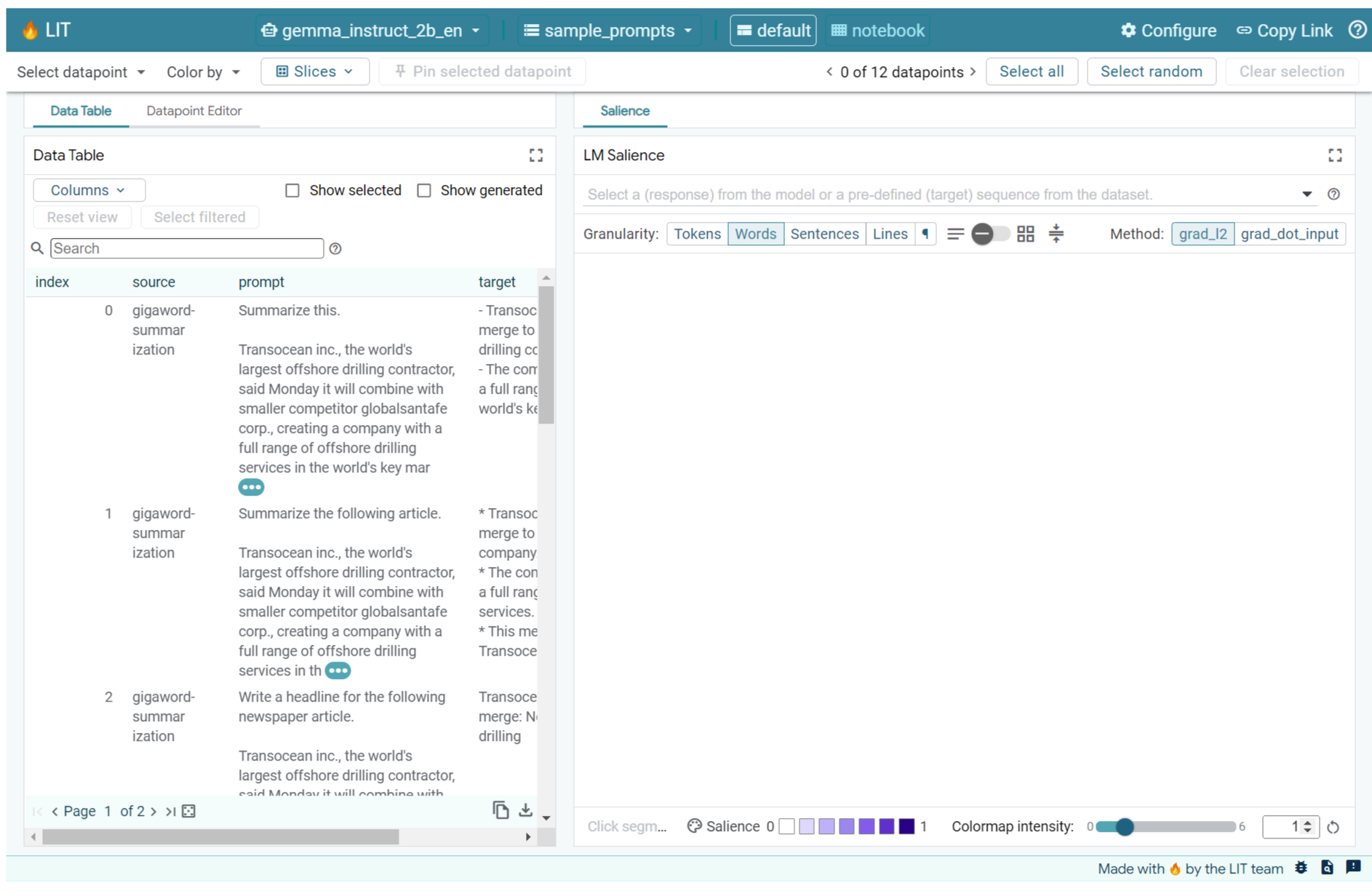
Nếu đã mở giao diện người dùng LIT trong ô ở trên hoặc trong một thẻ riêng biệt, bạn có thể sử dụng Trình chỉnh sửa điểm dữ liệu của LIT để thêm câu lệnh này:
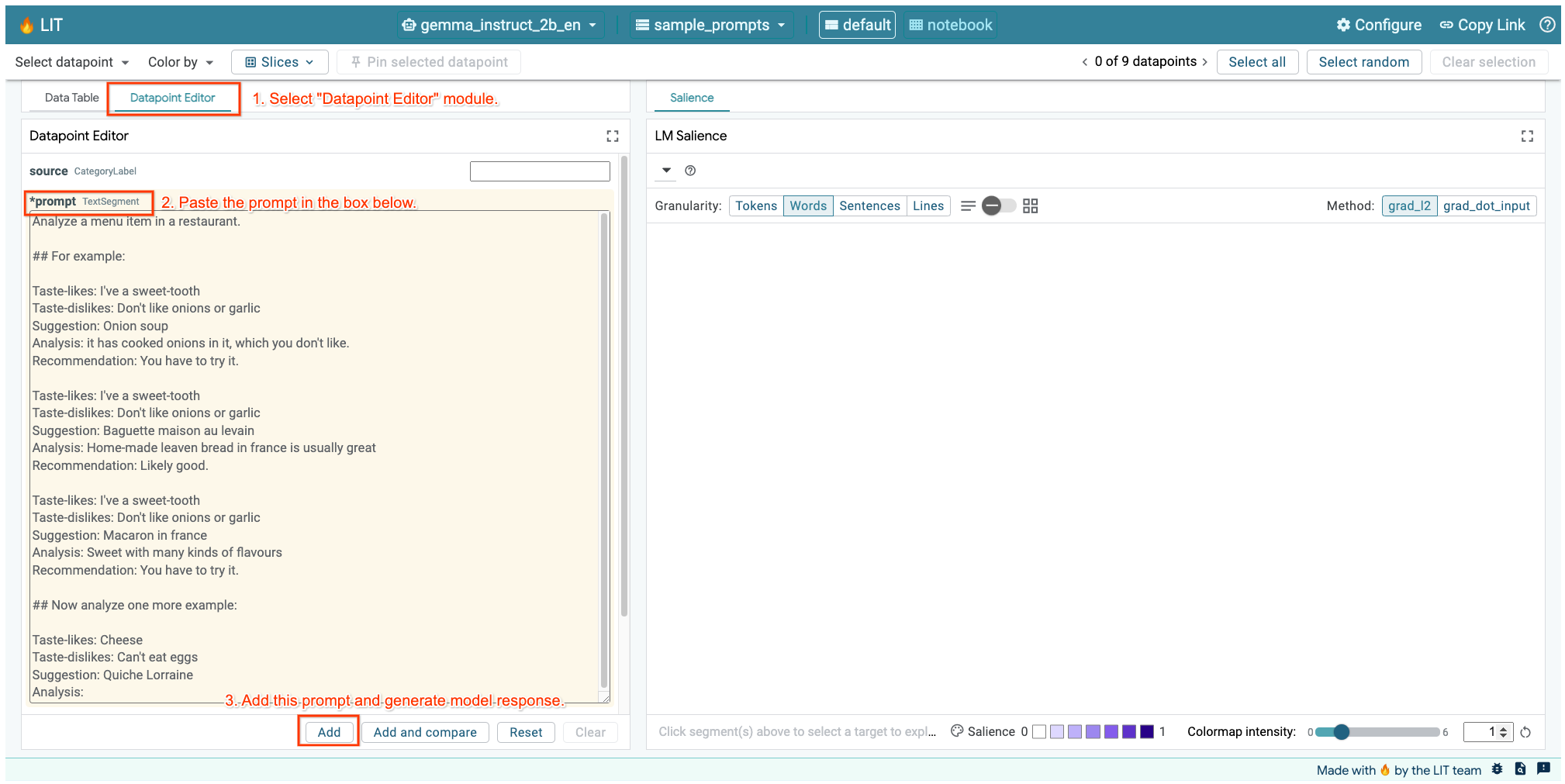
Một cách khác là kết xuất lại trực tiếp tiện ích bằng câu lệnh mà bạn quan tâm:
lit_widget.render(data=[fewshot_mistake_example])
Lưu ý phần hoàn thành mô hình đáng ngạc nhiên:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
Tại sao mô hình lại đề xuất bạn ăn một thứ mà bạn đã nói rõ là bạn không thể ăn?
Mức độ nổi bật của chuỗi có thể giúp làm nổi bật vấn đề gốc trong các ví dụ ít lần của chúng tôi. Trong ví dụ đầu tiên, lập luận theo chuỗi suy luận trong phần phân tích it has cooked onions in it, which you don't like không khớp với đề xuất cuối cùng You have to try it.
Trong mô-đun LM Salience, hãy chọn "Câu" rồi chọn dòng đề xuất. Giờ đây, giao diện người dùng sẽ có dạng như sau:
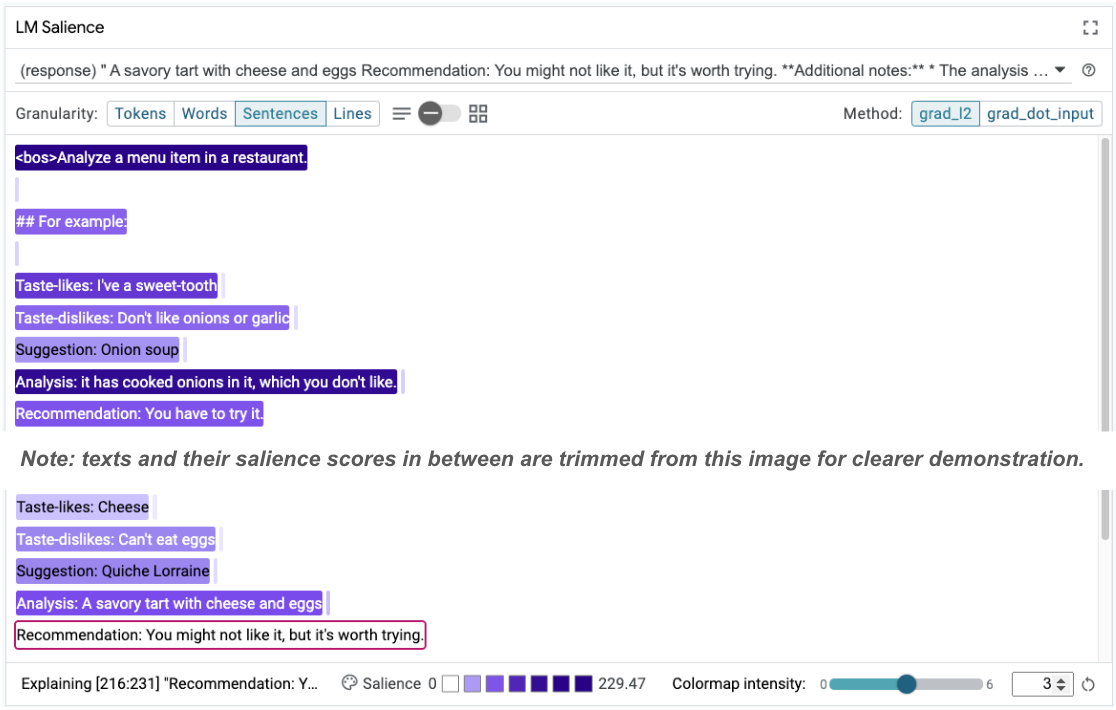
Điều này cho thấy một lỗi do con người gây ra: vô tình sao chép và dán phần đề xuất mà không cập nhật!
Bây giờ, hãy sửa "Đề xuất" trong ví dụ đầu tiên thành Avoid rồi thử lại. LIT đã tải sẵn ví dụ này trong các câu lệnh mẫu, vì vậy bạn có thể dùng hàm hiệu dụng nhỏ này để lấy ví dụ:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
Giờ đây, quá trình hoàn thành mô hình sẽ là:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
Một bài học quan trọng rút ra được từ việc này là: việc tạo mẫu sớm giúp bạn phát hiện những rủi ro mà bạn có thể không nghĩ đến trước đó, và bản chất dễ mắc lỗi của các mô hình ngôn ngữ có nghĩa là bạn phải chủ động thiết kế để xử lý lỗi. Bạn có thể xem thêm thông tin về vấn đề này trong Sách hướng dẫn People + AI của chúng tôi để thiết kế bằng AI.
Mặc dù câu lệnh đã được sửa đổi có độ chính xác cao hơn, nhưng vẫn chưa hoàn toàn chính xác: câu lệnh này cho người dùng biết rằng họ nên tránh trứng, nhưng lý do không chính xác, câu lệnh cho biết người dùng không thích trứng, trong khi thực tế là người dùng đã nói rằng họ không thể ăn trứng. Trong phần tiếp theo, bạn sẽ thấy cách cải thiện hiệu suất.
7. Kiểm thử giả thuyết để cải thiện hành vi của mô hình
LIT cho phép bạn kiểm thử các thay đổi đối với câu lệnh trong cùng một giao diện. Trong trường hợp này, bạn sẽ kiểm thử việc thêm một hiến pháp để cải thiện hành vi của mô hình. Hiến pháp là những câu lệnh thiết kế có các nguyên tắc giúp hướng dẫn quá trình tạo của mô hình. Các phương pháp gần đây thậm chí còn cho phép suy diễn tương tác các nguyên tắc hiến định.
Hãy sử dụng ý tưởng này để cải thiện thêm câu lệnh. Thêm một phần có các nguyên tắc tạo nội dung ở đầu câu lệnh của chúng tôi. Câu lệnh hiện bắt đầu như sau:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
Với nội dung cập nhật này, bạn có thể chạy lại ví dụ và quan sát một kết quả hoàn toàn khác:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
Sau đó, bạn có thể xem xét lại mức độ nổi bật của câu lệnh để hiểu rõ lý do dẫn đến thay đổi này:
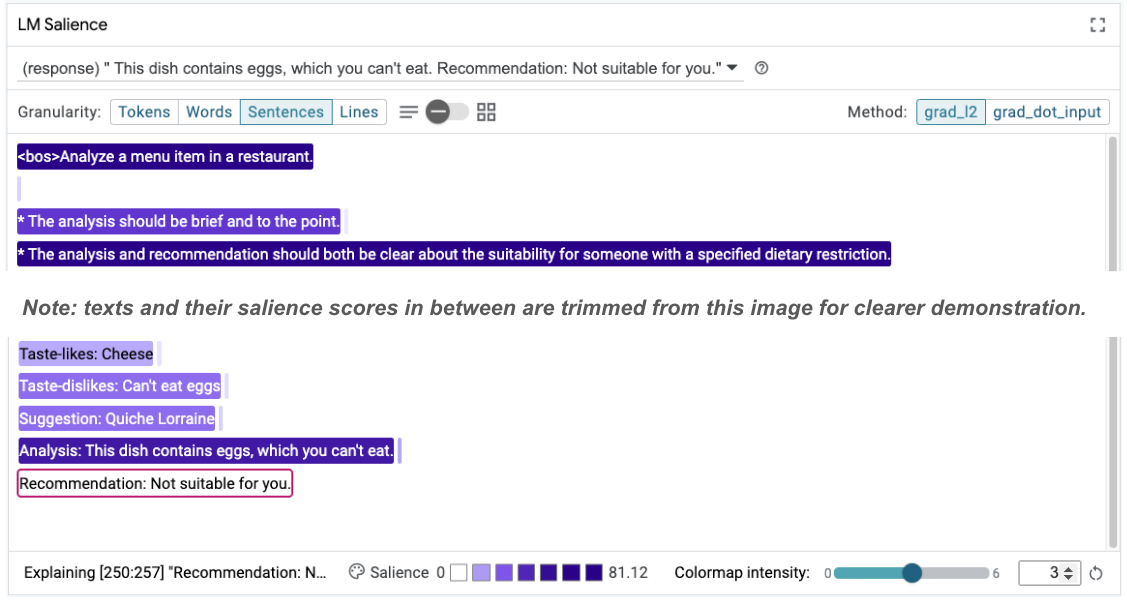
Lưu ý rằng đề xuất này an toàn hơn nhiều. Hơn nữa, kết quả "Không phù hợp với bạn" chịu ảnh hưởng của nguyên tắc nêu rõ mức độ phù hợp theo chế độ ăn kiêng, cùng với quy trình phân tích (còn gọi là chuỗi suy luận). Điều này giúp bạn tin tưởng hơn rằng kết quả được tạo ra là vì lý do chính đáng.
8. Đưa các nhóm không chuyên về kỹ thuật vào quá trình thăm dò và khám phá mô hình
Mức độ diễn giải là một nỗ lực của cả nhóm, bao gồm chuyên môn về XAI, chính sách, pháp lý và nhiều lĩnh vực khác.
Việc tương tác với các mô hình trong giai đoạn phát triển ban đầu thường đòi hỏi kiến thức chuyên môn kỹ thuật đáng kể, điều này khiến một số cộng tác viên khó truy cập và khám phá các mô hình hơn. Trước đây, không có công cụ nào cho phép các nhóm này tham gia vào giai đoạn tạo mẫu ban đầu.
Thông qua LIT, chúng tôi hy vọng rằng mô hình này có thể thay đổi. Như bạn đã thấy trong lớp học lập trình này, phương tiện trực quan và khả năng tương tác của LIT để kiểm tra mức độ nổi bật và khám phá các ví dụ có thể giúp nhiều bên liên quan chia sẻ và truyền đạt thông tin. Điều này có thể giúp bạn thu hút nhiều đồng đội đa dạng hơn để khám phá, thăm dò và gỡ lỗi mô hình. Việc cho họ tiếp xúc với những phương pháp kỹ thuật này có thể giúp họ hiểu rõ hơn về cách hoạt động của các mô hình. Ngoài ra, việc có nhiều chuyên gia hơn trong quá trình thử nghiệm mô hình ban đầu cũng có thể giúp phát hiện những kết quả không mong muốn cần được cải thiện.
9. Tóm tắt
Tóm lại:
- Giao diện người dùng của LIT cung cấp một giao diện để thực thi mô hình tương tác, cho phép người dùng trực tiếp tạo đầu ra và kiểm thử các tình huống "điều gì sẽ xảy ra nếu". Điều này đặc biệt hữu ích khi kiểm thử các biến thể câu lệnh khác nhau.
- Mô-đun Mức độ nổi bật của mô hình ngôn ngữ cung cấp một biểu diễn trực quan về mức độ nổi bật và cung cấp độ chi tiết dữ liệu có thể kiểm soát để bạn có thể giao tiếp về các cấu trúc lấy con người làm trung tâm (ví dụ: câu và từ) thay vì các cấu trúc lấy mô hình làm trung tâm (ví dụ: mã thông báo).
Khi bạn tìm thấy các ví dụ có vấn đề trong quá trình đánh giá mô hình, hãy đưa chúng vào LIT để gỡ lỗi. Bắt đầu bằng cách phân tích đơn vị nội dung lớn nhất hợp lý mà bạn có thể nghĩ đến có liên quan một cách logic đến nhiệm vụ mô hình hoá, sử dụng các hình ảnh trực quan để xem mô hình đang chú ý đến nội dung lời nhắc một cách chính xác hay không chính xác, sau đó truy sâu vào các đơn vị nội dung nhỏ hơn để mô tả thêm về hành vi không chính xác mà bạn đang thấy nhằm xác định các giải pháp có thể có.
Cuối cùng: Lit không ngừng cải thiện! Tìm hiểu thêm về các tính năng của chúng tôi và chia sẻ đề xuất của bạn tại đây.