
1. Ringkasan
Natural Language Processing (NLP) adalah studi tentang memperoleh insight dan melakukan analisis pada data tekstual. Seiring terus bertambahnya jumlah tulisan yang dihasilkan di internet, kini lebih dari sebelumnya, organisasi berupaya memanfaatkan teks mereka untuk mendapatkan informasi yang relevan dengan bisnis mereka.
NLP dapat digunakan untuk berbagai hal, mulai dari menerjemahkan bahasa hingga menganalisis sentimen, membuat kalimat dari awal, dan banyak lagi. Ini adalah area penelitian aktif yang mengubah cara kita bekerja dengan teks.
Kita akan mempelajari cara menggunakan NLP pada data tekstual dalam jumlah besar secara terukur. Ini tentu bisa menjadi tugas yang sulit. Untungnya, kita akan memanfaatkan library seperti Spark MLlib dan spark-nlp untuk mempermudah hal ini.
2. Kasus Penggunaan Kami
Chief Data Scientist organisasi (fiktif) kami, "FoodCorp", tertarik untuk mempelajari lebih lanjut tren di industri makanan. Kita memiliki akses ke kumpulan data teks dalam bentuk postingan dari subreddit Reddit r/food yang akan kita gunakan untuk mempelajari apa yang dibicarakan orang.
Salah satu pendekatan untuk melakukannya adalah melalui metode NLP yang dikenal sebagai "pemodelan topik". Pemodelan topik adalah metode statistik yang dapat mengidentifikasi tren dalam makna semantik sekelompok dokumen. Dengan kata lain, kita dapat membuat model topik pada korpus "postingan" Reddit yang akan menghasilkan daftar "topik" atau kelompok kata yang menggambarkan tren.
Untuk membangun model, kita akan menggunakan algoritma yang disebut Latent Dirichlet Allocation (LDA), yang sering digunakan untuk mengelompokkan teks. Pengantar yang sangat baik untuk LDA dapat ditemukan di sini.
3. Membuat Project
Jika belum memiliki Akun Google (Gmail atau Google Apps), Anda harus membuatnya. Login ke Google Cloud Platform console ( console.cloud.google.com) dan buat project baru:


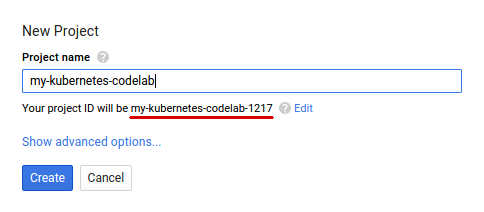
Selanjutnya, Anda harus mengaktifkan penagihan di Konsol Cloud untuk menggunakan resource Google Cloud.
Menjalankan operasi dalam codelab ini tidak akan menghabiskan biaya lebih dari beberapa dolar, tetapi bisa lebih jika Anda memutuskan untuk menggunakan lebih banyak resource atau jika Anda membiarkannya berjalan. Setiap codelab PySpark-BigQuery dan Spark-NLP menjelaskan "Pembersihan" di bagian akhir.
Pengguna baru Google Cloud Platform memenuhi syarat untuk mendapatkan uji coba gratis senilai$300.
4. Menyiapkan Lingkungan Kita
Pertama, kita perlu mengaktifkan Dataproc dan Compute Engine API.
Klik ikon menu di kiri atas layar.

Pilih API Manager dari menu drop-down.
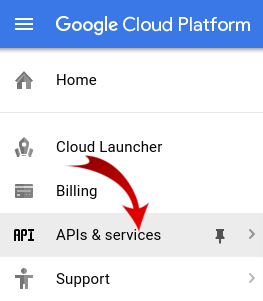
Klik Enable APIs and Services.

Telusuri "Compute Engine" di kotak penelusuran. Klik "Google Compute Engine API" dalam daftar hasil yang muncul.
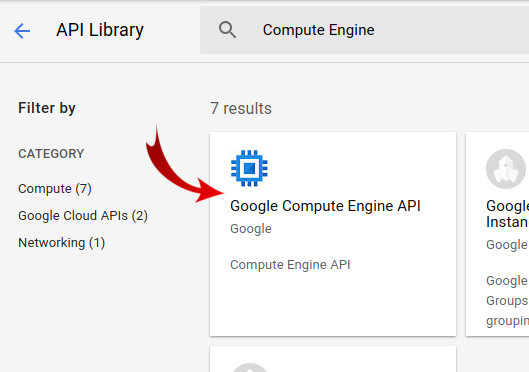
Di halaman Google Compute Engine, klik Enable

Setelah diaktifkan, klik panah yang mengarah ke kiri untuk kembali.
Sekarang telusuri "Google Dataproc API" dan aktifkan juga.
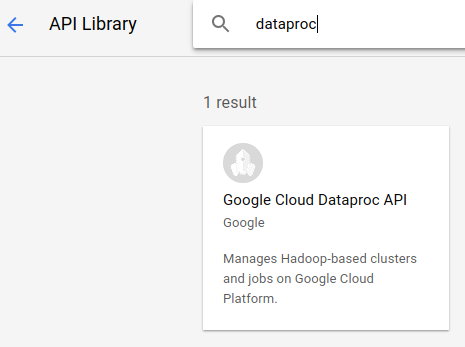
Selanjutnya, buka Cloud Shell dengan mengklik tombol di pojok kanan atas konsol cloud:
Kita akan menetapkan beberapa variabel lingkungan yang dapat kita rujuk saat melanjutkan codelab. Pertama, pilih nama untuk cluster Dataproc yang akan kita buat, seperti "my-cluster", lalu tetapkan di lingkungan Anda. Anda dapat menggunakan nama apa pun yang Anda sukai.
CLUSTER_NAME=my-cluster
Selanjutnya, pilih zona dari salah satu zona yang tersedia di sini. Contohnya mungkin us-east1-b.
REGION=us-east1
Terakhir, kita perlu menetapkan bucket sumber tempat tugas kita akan membaca data. Kami memiliki data contoh yang tersedia di bucket bm_reddit, tetapi Anda dapat menggunakan data yang dihasilkan dari PySpark untuk Memproses Data BigQuery jika Anda telah menyelesaikannya sebelum ini.
BUCKET_NAME=bm_reddit
Setelah variabel lingkungan dikonfigurasi, jalankan perintah berikut untuk membuat cluster Dataproc:
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--region ${REGION} \
--metadata 'PIP_PACKAGES=google-cloud-storage spark-nlp==2.7.2' \
--worker-machine-type n1-standard-8 \
--num-workers 4 \
--image-version 1.4-debian10 \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--optional-components=JUPYTER,ANACONDA \
--enable-component-gateway
Mari kita bahas setiap perintah ini:
gcloud beta dataproc clusters create ${CLUSTER_NAME}: akan memulai pembuatan cluster Dataproc dengan nama yang Anda berikan sebelumnya. Kami menyertakan beta di sini untuk mengaktifkan fitur beta Dataproc seperti Component Gateway, yang akan kita bahas di bawah.
--zone=${ZONE}: Ini menetapkan lokasi cluster.
--worker-machine-type n1-standard-8: Ini adalah jenis mesin yang akan digunakan untuk pekerja kita.
--num-workers 4: Kita akan memiliki empat pekerja di cluster.
--image-version 1.4-debian9: Ini menunjukkan versi image Dataproc yang akan kita gunakan.
--initialization-actions ...: Tindakan Inisialisasi adalah skrip kustom yang dijalankan saat membuat cluster dan pekerja. File tersebut dapat dibuat pengguna dan disimpan di bucket GCS atau dirujuk dari bucket publik dataproc-initialization-actions. Tindakan inisialisasi yang disertakan di sini akan memungkinkan penginstalan paket Python menggunakan Pip, seperti yang disediakan dengan tanda --metadata.
--metadata 'PIP_PACKAGES=google-cloud-storage spark-nlp': Ini adalah daftar paket yang dipisahkan spasi untuk diinstal ke Dataproc. Dalam hal ini, kita akan menginstal library klien Python google-cloud-storage dan spark-nlp.
--optional-components=ANACONDA: Komponen Opsional adalah paket umum yang digunakan dengan Dataproc yang otomatis diinstal di cluster Dataproc selama pembuatan. Keuntungan menggunakan Komponen Opsional dibandingkan Tindakan Inisialisasi mencakup waktu mulai yang lebih cepat dan diuji untuk versi Dataproc tertentu. Secara keseluruhan, mereka lebih dapat diandalkan.
--enable-component-gateway: Flag ini memungkinkan kita memanfaatkan Component Gateway Dataproc untuk melihat UI umum seperti Zeppelin, Jupyter, atau Spark History. Catatan: beberapa di antaranya memerlukan Komponen Opsional terkait.
Untuk pengantar yang lebih mendalam tentang Dataproc, lihat codelab ini.
Selanjutnya, jalankan perintah berikut di Cloud Shell Anda untuk meng-clone repositori dengan kode contoh dan beralih ke direktori yang benar:
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
cd cloud-dataproc/codelabs/spark-nlp
5. Spark MLlib
Spark MLlib adalah library machine learning yang skalabel dan ditulis dalam Apache Spark. Dengan memanfaatkan efisiensi Spark dan serangkaian algoritma machine learning yang dioptimalkan, MLlib dapat menganalisis data dalam jumlah besar. Spark memiliki API di Java, Scala, Python, dan R. Dalam codelab ini, kita akan berfokus secara khusus pada Python.
MLlib berisi serangkaian besar transformer dan estimator. Transformer adalah alat yang dapat mengubah atau memodifikasi data Anda, biasanya dengan fungsi transform(), sedangkan estimator adalah algoritma bawaan yang dapat Anda latih data Anda, biasanya dengan fungsi fit().
Contoh transformer meliputi:
- tokenisasi (membuat vektor angka dari string kata)
- enkode one-hot (membuat vektor angka renggang yang merepresentasikan kata-kata yang ada dalam string)
- penghapus stopword (menghapus kata yang tidak menambah nilai semantik pada string)
Contoh estimator mencakup:
- klasifikasi (apakah ini apel atau jeruk?)
- regresi (berapa harga apel ini?)
- pengelompokan (seberapa mirip semua apel satu sama lain?)
- pohon keputusan (jika warna == oranye, maka itu adalah jeruk. Jika tidak, itu adalah apel)
- pengurangan dimensi (dapatkah kita menghapus fitur dari set data dan tetap membedakan antara apel dan jeruk?).
MLlib juga berisi alat untuk metode umum lainnya dalam machine learning seperti penyesuaian dan pemilihan hyperparameter serta validasi silang.
Selain itu, MLlib berisi Pipelines API, yang memungkinkan Anda membuat pipeline transformasi data menggunakan berbagai transformer yang dapat dieksekusi ulang.
6. Spark-NLP
Spark-nlp adalah library yang dibuat oleh John Snow Labs untuk melakukan tugas pemrosesan bahasa alami yang efisien menggunakan Spark. Alat ini berisi alat bawaan yang disebut anotator untuk tugas umum seperti:
- tokenisasi (membuat vektor angka dari string kata)
- membuat embedding kata (menentukan hubungan antarkata melalui vektor)
- tag jenis kata (kata mana yang merupakan kata benda? Mana yang merupakan kata kerja?)
Meskipun di luar cakupan codelab ini, spark-nlp juga terintegrasi dengan baik dengan TensorFlow.
Yang paling penting, Spark-NLP memperluas kemampuan Spark MLlib dengan menyediakan komponen yang mudah dimasukkan ke dalam Pipeline MLlib.
7. Praktik Terbaik untuk Natural Language Processing
Sebelum dapat mengekstrak informasi yang berguna dari data, kita perlu melakukan beberapa persiapan. Langkah-langkah praproses yang akan kita lakukan adalah sebagai berikut:
Tokenisasi
Hal pertama yang biasanya ingin kita lakukan adalah "mentokenisasi" data. Hal ini melibatkan pengambilan data dan membaginya berdasarkan "token" atau kata. Umumnya, kita menghapus tanda baca dan menyetel semua kata menjadi huruf kecil pada langkah ini. Misalnya, kita memiliki string berikut: What time is it? Setelah tokenisasi, kalimat ini akan terdiri dari empat token: "what" , "time", "is", "it". Kita tidak ingin model memperlakukan kata what sebagai dua kata berbeda dengan dua kapitalisasi yang berbeda. Selain itu, tanda baca biasanya tidak membantu kami mempelajari inferensi dari kata-kata dengan lebih baik, jadi kami juga menghapusnya.
Normalisasi
Kita sering kali ingin "menormalisasi" data. Tindakan ini akan mengganti kata-kata dengan makna serupa dengan hal yang sama. Misalnya, jika kata "berkelahi", "bertarung", dan "berduel" diidentifikasi dalam teks, maka normalisasi dapat mengganti "bertarung" dan "berduel" dengan kata "berkelahi".
Stemming
Stemming akan mengganti kata dengan makna dasarnya. Misalnya, kata "mobil", "mobil-mobil", dan "mobilnya" akan diganti dengan kata "mobil", karena semua kata ini menyiratkan hal yang sama pada dasarnya.
Menghapus Stopword
Stopword adalah kata-kata seperti "dan" dan "itu" yang biasanya tidak menambah nilai pada makna semantik suatu kalimat. Biasanya, kita ingin menghapus karakter ini sebagai cara untuk mengurangi derau dalam set data teks.
8. Menjalankan Tugas
Mari kita lihat tugas yang akan kita jalankan. Kode dapat ditemukan di cloud-dataproc/codelabs/spark-nlp/topic_model.py. Luangkan waktu setidaknya beberapa menit untuk membaca kode dan komentar terkait guna memahami apa yang terjadi. Kami juga akan menyoroti beberapa bagian di bawah:
# Python imports
import sys
# spark-nlp components. Each one is incorporated into our pipeline.
from sparknlp.annotator import Lemmatizer, Stemmer, Tokenizer, Normalizer
from sparknlp.base import DocumentAssembler, Finisher
# A Spark Session is how we interact with Spark SQL to create Dataframes
from pyspark.sql import SparkSession
# These allow us to create a schema for our data
from pyspark.sql.types import StructField, StructType, StringType, LongType
# Spark Pipelines allow us to sequentially add components such as transformers
from pyspark.ml import Pipeline
# These are components we will incorporate into our pipeline.
from pyspark.ml.feature import StopWordsRemover, CountVectorizer, IDF
# LDA is our model of choice for topic modeling
from pyspark.ml.clustering import LDA
# Some transformers require the usage of other Spark ML functions. We import them here
from pyspark.sql.functions import col, lit, concat
# This will help catch some PySpark errors
from pyspark.sql.utils import AnalysisException
# Assign bucket where the data lives
try:
bucket = sys.argv[1]
except IndexError:
print("Please provide a bucket name")
sys.exit(1)
# Create a SparkSession under the name "reddit". Viewable via the Spark UI
spark = SparkSession.builder.appName("reddit topic model").getOrCreate()
# Create a three column schema consisting of two strings and a long integer
fields = [StructField("title", StringType(), True),
StructField("body", StringType(), True),
StructField("created_at", LongType(), True)]
schema = StructType(fields)
# We'll attempt to process every year / month combination below.
years = ['2016', '2017', '2018', '2019']
months = ['01', '02', '03', '04', '05', '06',
'07', '08', '09', '10', '11', '12']
# This is the subreddit we're working with.
subreddit = "food"
# Create a base dataframe.
reddit_data = spark.createDataFrame([], schema)
# Keep a running list of all files that will be processed
files_read = []
for year in years:
for month in months:
# In the form of <project-id>.<dataset>.<table>
gs_uri = f"gs://{bucket}/reddit_posts/{year}/{month}/{subreddit}.csv.gz"
# If the table doesn't exist we will simply continue and not
# log it into our "tables_read" list
try:
reddit_data = (
spark.read.format('csv')
.options(codec="org.apache.hadoop.io.compress.GzipCodec")
.load(gs_uri, schema=schema)
.union(reddit_data)
)
files_read.append(gs_uri)
except AnalysisException:
continue
if len(files_read) == 0:
print('No files read')
sys.exit(1)
# Replacing null values with their respective typed-equivalent is usually
# easier to work with. In this case, we'll replace nulls with empty strings.
# Since some of our data doesn't have a body, we can combine all of the text
# for the titles and bodies so that every row has useful data.
df_train = (
reddit_data
# Replace null values with an empty string
.fillna("")
.select(
# Combine columns
concat(
# First column to concatenate. col() is used to specify that we're referencing a column
col("title"),
# Literal character that will be between the concatenated columns.
lit(" "),
# Second column to concatenate.
col("body")
# Change the name of the new column
).alias("text")
)
)
# Now, we begin assembling our pipeline. Each component here is used to some transformation to the data.
# The Document Assembler takes the raw text data and convert it into a format that can
# be tokenized. It becomes one of spark-nlp native object types, the "Document".
document_assembler = DocumentAssembler().setInputCol("text").setOutputCol("document")
# The Tokenizer takes data that is of the "Document" type and tokenizes it.
# While slightly more involved than this, this is effectively taking a string and splitting
# it along ths spaces, so each word is its own string. The data then becomes the
# spark-nlp native type "Token".
tokenizer = Tokenizer().setInputCols(["document"]).setOutputCol("token")
# The Normalizer will group words together based on similar semantic meaning.
normalizer = Normalizer().setInputCols(["token"]).setOutputCol("normalizer")
# The Stemmer takes objects of class "Token" and converts the words into their
# root meaning. For instance, the words "cars", "cars'" and "car's" would all be replaced
# with the word "car".
stemmer = Stemmer().setInputCols(["normalizer"]).setOutputCol("stem")
# The Finisher signals to spark-nlp allows us to access the data outside of spark-nlp
# components. For instance, we can now feed the data into components from Spark MLlib.
finisher = Finisher().setInputCols(["stem"]).setOutputCols(["to_spark"]).setValueSplitSymbol(" ")
# Stopwords are common words that generally don't add much detail to the meaning
# of a body of text. In English, these are mostly "articles" such as the words "the"
# and "of".
stopword_remover = StopWordsRemover(inputCol="to_spark", outputCol="filtered")
# Here we implement TF-IDF as an input to our LDA model. CountVectorizer (TF) keeps track
# of the vocabulary that's being created so we can map our topics back to their
# corresponding words.
# TF (term frequency) creates a matrix that counts how many times each word in the
# vocabulary appears in each body of text. This then gives each word a weight based
# on its frequency.
tf = CountVectorizer(inputCol="filtered", outputCol="raw_features")
# Here we implement the IDF portion. IDF (Inverse document frequency) reduces
# the weights of commonly-appearing words.
idf = IDF(inputCol="raw_features", outputCol="features")
# LDA creates a statistical representation of how frequently words appear
# together in order to create "topics" or groups of commonly appearing words.
lda = LDA(k=10, maxIter=10)
# We add all of the transformers into a Pipeline object. Each transformer
# will execute in the ordered provided to the "stages" parameter
pipeline = Pipeline(
stages = [
document_assembler,
tokenizer,
normalizer,
stemmer,
finisher,
stopword_remover,
tf,
idf,
lda
]
)
# We fit the data to the model.
model = pipeline.fit(df_train)
# Now that we have completed a pipeline, we want to output the topics as human-readable.
# To do this, we need to grab the vocabulary generated from our pipeline, grab the topic
# model and do the appropriate mapping. The output from each individual component lives
# in the model object. We can access them by referring to them by their position in
# the pipeline via model.stages[<ind>]
# Let's create a reference our vocabulary.
vocab = model.stages[-3].vocabulary
# Next, let's grab the topics generated by our LDA model via describeTopics(). Using collect(),
# we load the output into a Python array.
raw_topics = model.stages[-1].describeTopics().collect()
# Lastly, let's get the indices of the vocabulary terms from our topics
topic_inds = [ind.termIndices for ind in raw_topics]
# The indices we just grab directly map to the term at position <ind> from our vocabulary.
# Using the below code, we can generate the mappings from our topic indices to our vocabulary.
topics = []
for topic in topic_inds:
_topic = []
for ind in topic:
_topic.append(vocab[ind])
topics.append(_topic)
# Let's see our topics!
for i, topic in enumerate(topics, start=1):
print(f"topic {i}: {topic}")
Menjalankan Tugas
Sekarang, mari kita lanjutkan dan jalankan tugas kita. Lanjutkan dan jalankan perintah berikut:
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME}\
--region ${REGION}\
--properties=spark.jars.packages=com.johnsnowlabs.nlp:spark-nlp_2.11:2.7.2\
--driver-log-levels root=FATAL \
topic_model.py \
-- ${BUCKET_NAME}
Perintah ini memungkinkan kita memanfaatkan Dataproc Jobs API. Dengan menyertakan perintah pyspark, kita menunjukkan kepada cluster bahwa ini adalah tugas PySpark. Kita memasukkan nama cluster, parameter opsional dari parameter yang tersedia di sini, dan nama file yang berisi tugas. Dalam kasus ini, kita memberikan parameter --properties yang memungkinkan kita mengubah berbagai properti untuk Spark, Yarn, atau Dataproc. Kita mengubah properti Spark packages yang memungkinkan kita memberi tahu Spark bahwa kita ingin menyertakan spark-nlp sebagai paket dengan tugas kita. Kita juga menyediakan parameter --driver-log-levels root=FATAL yang akan menyembunyikan sebagian besar output log dari PySpark, kecuali untuk Error. Secara umum, log Spark cenderung berisik.
Terakhir, -- ${BUCKET} adalah argumen command line untuk skrip Python itu sendiri yang menyediakan nama bucket. Perhatikan spasi antara -- dan ${BUCKET}.
Setelah menjalankan tugas selama beberapa menit, kita akan melihat output yang berisi model kita:

Luar biasa!! Dapatkah Anda menyimpulkan tren dengan melihat output dari model Anda? Bagaimana dengan milik kami?
Dari output di atas, orang dapat menyimpulkan tren dari topik 8 yang berkaitan dengan makanan sarapan, dan makanan penutup dari topik 9.
9. Pembersihan
Agar tidak menimbulkan biaya yang tidak perlu pada akun GCP Anda setelah menyelesaikan panduan memulai ini:
- Hapus bucket Cloud Storage untuk lingkungan dan yang Anda buat
- Hapus lingkungan Dataproc.
Jika membuat project hanya untuk codelab ini, Anda juga dapat menghapus project tersebut jika mau:
- Di Konsol GCP, buka halaman Projects.
- Dalam daftar project, pilih project yang ingin Anda hapus, lalu klik Hapus.
- Di kotak, ketik project ID, lalu klik Shut down untuk menghapus project.
Lisensi
Karya ini dilisensikan berdasarkan Lisensi Umum Creative Commons Attribution 3.0, dan lisensi Apache 2.0.