
1. Visão geral
O processamento de linguagem natural (PLN) é o estudo da derivação de insights e da análise de dados textuais. À medida que a quantidade de texto gerado na internet continua crescendo, agora mais do que nunca, as organizações buscam aproveitar o texto para obter informações relevantes para os negócios.
O PLN pode ser usado para tudo, desde a tradução de idiomas até a análise de sentimentos, a geração de frases do zero e muito mais. É uma área ativa de pesquisa que está transformando a maneira como trabalhamos com texto.
Vamos mostrar como usar o PLN em grandes quantidades de dados textuais em escala. Essa pode ser uma tarefa assustadora. Felizmente, vamos aproveitar bibliotecas como o Spark MLlib e o spark-nlp para facilitar.
2. Nosso caso de uso
O cientista de dados principal da nossa organização (fictícia), "FoodCorp", está interessado em saber mais sobre as tendências do setor alimentício. Temos acesso a um corpus de dados de texto na forma de posts do subreddit r/food do Reddit, que vamos usar para explorar sobre o que as pessoas estão falando.
Uma abordagem para fazer isso é usando um método de PLN conhecido como "modelagem de tópicos". A modelagem de tópicos é um método estatístico que pode identificar tendências nos significados semânticos de um grupo de documentos. Em outras palavras, podemos criar um modelo de tópico no nosso corpus de "postagens" do Reddit, que vai gerar uma lista de "tópicos" ou grupos de palavras que descrevem uma tendência.
Para criar nosso modelo, vamos usar um algoritmo chamado Latent Dirichlet Allocation (LDA), que geralmente é usado para agrupar texto. Uma excelente introdução ao LDA pode ser encontrada aqui.
3. Como criar um projeto
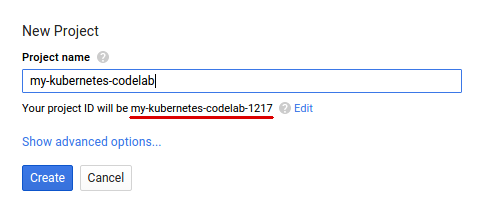
Se você ainda não tem uma Conta do Google (Gmail ou Google Apps), você deve criar uma. Faça login no Console do Google Cloud Platform ( console.cloud.google.com) e crie um novo projeto:


Em seguida, será necessário ativar o faturamento no Console do Cloud para usar os recursos do Google Cloud.
A execução deste codelab terá um custo baixo, mas poderá ser maior se você decidir usar mais recursos ou se deixá-los em execução. Os codelabs do PySpark-BigQuery e do Spark-NLP explicam a "limpeza" no final.
Novos usuários do Google Cloud Platform estão qualificados para um teste sem custo financeiro de US$300.
4. Como configurar nosso ambiente
Primeiro, precisamos ativar o Dataproc e as APIs Compute Engine.
Clique no ícone de menu no canto superior esquerdo da tela.

Selecione o Gerenciador de APIs no menu suspenso.
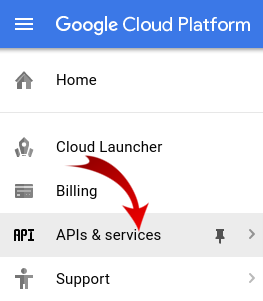
Clique em Ativar APIs e serviços.

Pesquise "Compute Engine" na caixa de pesquisa. Clique em "API Compute Engine" na lista de resultados que aparece.
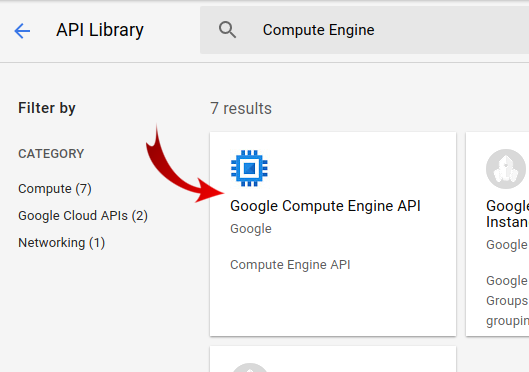
Na página do Google Compute Engine, clique em Ativar.

Depois de fazer a ativação, clique na seta apontando para a esquerda para voltar.
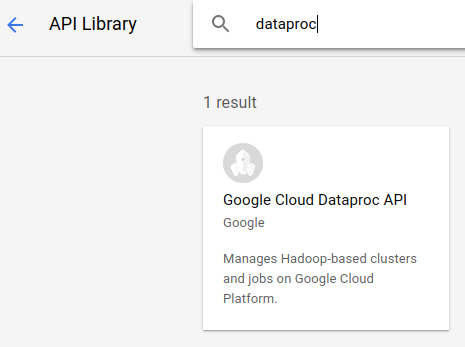
Agora pesquise "API Dataproc do Google" e ative-a também.
Em seguida, abra o Cloud Shell clicando no botão no canto superior direito do console do Cloud:
Vamos definir algumas variáveis de ambiente que podem ser referenciadas à medida que avançamos no codelab. Primeiro, escolha um nome para um cluster do Dataproc que vamos criar, como "my-cluster", e defina-o no seu ambiente. Use o nome que preferir.
CLUSTER_NAME=my-cluster
Em seguida, escolha uma zona entre as disponíveis aqui. Um exemplo pode ser us-east1-b.
REGION=us-east1
Por fim, precisamos definir o bucket de origem do qual nosso job vai ler os dados. Temos dados de amostra disponíveis no bucket bm_reddit, mas você pode usar os dados gerados pelo PySpark para pré-processamento de dados do BigQuery, se tiver concluído antes deste.
BUCKET_NAME=bm_reddit
Com as variáveis de ambiente configuradas, vamos executar o comando a seguir para criar nosso cluster do Dataproc:
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--region ${REGION} \
--metadata 'PIP_PACKAGES=google-cloud-storage spark-nlp==2.7.2' \
--worker-machine-type n1-standard-8 \
--num-workers 4 \
--image-version 1.4-debian10 \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--optional-components=JUPYTER,ANACONDA \
--enable-component-gateway
Vamos analisar cada um desses comandos:
gcloud beta dataproc clusters create ${CLUSTER_NAME}: inicia a criação de um cluster do Dataproc com o nome fornecido anteriormente. Incluímos beta aqui para ativar os recursos Beta do Dataproc, como o Gateway de componentes, que discutimos abaixo.
--zone=${ZONE}: define o local do cluster.
--worker-machine-type n1-standard-8: esse é o tipo de máquina a ser usado para nossos workers.
--num-workers 4: teremos quatro workers no nosso cluster.
--image-version 1.4-debian9: indica a versão da imagem do Dataproc que vamos usar.
--initialization-actions ...: As ações de inicialização são scripts personalizados executados ao criar clusters e workers. Eles podem ser criados pelo usuário e armazenados em um bucket do GCS ou referenciados no bucket público dataproc-initialization-actions. A ação de inicialização incluída aqui permite instalações de pacotes Python usando o Pip, conforme fornecido com a flag --metadata.
--metadata 'PIP_PACKAGES=google-cloud-storage spark-nlp': é uma lista de pacotes separados por espaço a serem instalados no Dataproc. Nesse caso, vamos instalar a biblioteca de cliente Python google-cloud-storage e spark-nlp.
--optional-components=ANACONDA: Os componentes opcionais são pacotes comuns usados com o Dataproc que são instalados automaticamente em clusters do Dataproc durante a criação. As vantagens de usar componentes opcionais em vez de ações de inicialização incluem tempos de inicialização mais rápidos e testes para versões específicas do Dataproc. No geral, eles são mais confiáveis.
--enable-component-gateway: essa flag permite aproveitar o Gateway de componentes do Dataproc para visualizar UIs comuns, como Zeppelin, Jupyter ou o histórico do Spark. Observação: alguns deles exigem o componente opcional associado.
Para uma introdução mais detalhada ao Dataproc, confira este codelab.
Em seguida, execute os comandos a seguir no Cloud Shell para clonar o repositório com o exemplo de código e cd no diretório correto:
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
cd cloud-dataproc/codelabs/spark-nlp
5. Spark MLlib
Spark MLlib é uma biblioteca de machine learning escalonável escrita no Apache Spark. Ao aproveitar a eficiência do Spark com um conjunto de algoritmos de machine learning ajustados, o MLlib pode analisar grandes quantidades de dados. Ele tem APIs em Java, Scala, Python e R. Neste codelab, vamos nos concentrar especificamente no Python.
O MLlib contém um grande conjunto de transformadores e estimadores. Um transformador é uma ferramenta que pode mutar ou alterar seus dados, normalmente com uma função transform(), enquanto um estimador é um algoritmo pré-criado que você pode treinar seus dados, normalmente com uma função fit().
Exemplos de transformadores incluem:
- tokenização (criação de um vetor de números a partir de uma string de palavras)
- codificação one-hot (criação de um vetor esparso de números que representam palavras presentes em uma string)
- removedor de palavras sem relevância (remoção de palavras que não adicionam valor semântico a uma string)
Exemplos de estimadores incluem:
- classificação (é uma maçã ou uma laranja?)
- regressão (quanto custa essa maçã?)
- clustering (quão semelhantes são todas as maçãs entre si?)
- árvores de decisão (se a cor for laranja, então é uma laranja. Caso contrário, é uma maçã)
- redução de dimensionalidade (podemos remover recursos do nosso conjunto de dados e ainda diferenciar uma maçã de uma laranja?).
O MLlib também contém ferramentas para outros métodos comuns em machine learning, como ajuste e seleção de hiperparâmetros, bem como validação cruzada.
Além disso, o MLlib contém a API Pipelines, que permite criar pipelines de transformação de dados usando diferentes transformadores que podem ser reexecutados.
6. Spark-NLP
O Spark-nlp é uma biblioteca criada pela John Snow Labs para realizar tarefas eficientes de processamento de linguagem natural usando o Spark. Ele contém ferramentas integradas chamadas anotadores para tarefas comuns, como:
- tokenização (criação de um vetor de números a partir de uma string de palavras)
- criação de embeddings de palavras (definição da relação entre palavras por vetores)
- tags de classe gramatical (quais palavras são substantivos? Quais são verbos?)
Embora fora do escopo deste codelab, o spark-nlp também se integra bem ao TensorFlow.
Talvez o mais importante seja que o Spark-NLP estende os recursos do Spark MLlib, fornecendo componentes que se encaixam facilmente nos pipelines do MLlib.
7. Práticas recomendadas para processamento de linguagem natural
Antes de extrair informações úteis dos nossos dados, precisamos cuidar de algumas tarefas. As etapas de pré-processamento que vamos seguir são as seguintes:
Tokenização
A primeira coisa que tradicionalmente queremos fazer é "tokenizar" os dados. Isso envolve a coleta dos dados e a divisão deles com base em "tokens" ou palavras. Geralmente, removemos a pontuação e definimos todas as palavras como minúsculas nesta etapa. Por exemplo, digamos que temos a seguinte string: What time is it? Após a tokenização, essa frase consistiria em quatro tokens: "what" , "time", "is", "it". Não queremos que o modelo trate a palavra what como duas palavras diferentes com duas capitalizações diferentes. Além disso, a pontuação normalmente não nos ajuda a aprender melhor a inferência das palavras, então também a removemos.
Normalização
Muitas vezes, queremos "normalizar" os dados. Isso vai substituir palavras de significado semelhante pela mesma coisa. Por exemplo, se as palavras "fought", "battled" e "dueled" forem identificadas no texto, a normalização poderá substituir "battled" e "dueled" pela palavra "fought".
Derivação
A derivação vai substituir palavras pelo significado raiz. Por exemplo, as palavras "car", "cars'" e "car's" seriam substituídas pela palavra "car", já que todas essas palavras implicam a mesma coisa na raiz.
Remoção de palavras sem relevância
Palavras sem relevância são palavras como "e" e "o" que normalmente não agregam valor ao significado semântico de uma frase. Normalmente, queremos remover essas palavras como um meio de reduzir o ruído nos nossos conjuntos de dados de texto.
8. Como executar o job
Vamos conferir o job que vamos executar. O código pode ser encontrado em cloud-dataproc/codelabs/spark-nlp/topic_model.py. Passe pelo menos alguns minutos lendo o código e os comentários associados para entender o que está acontecendo. Também vamos destacar algumas das seções abaixo:
# Python imports
import sys
# spark-nlp components. Each one is incorporated into our pipeline.
from sparknlp.annotator import Lemmatizer, Stemmer, Tokenizer, Normalizer
from sparknlp.base import DocumentAssembler, Finisher
# A Spark Session is how we interact with Spark SQL to create Dataframes
from pyspark.sql import SparkSession
# These allow us to create a schema for our data
from pyspark.sql.types import StructField, StructType, StringType, LongType
# Spark Pipelines allow us to sequentially add components such as transformers
from pyspark.ml import Pipeline
# These are components we will incorporate into our pipeline.
from pyspark.ml.feature import StopWordsRemover, CountVectorizer, IDF
# LDA is our model of choice for topic modeling
from pyspark.ml.clustering import LDA
# Some transformers require the usage of other Spark ML functions. We import them here
from pyspark.sql.functions import col, lit, concat
# This will help catch some PySpark errors
from pyspark.sql.utils import AnalysisException
# Assign bucket where the data lives
try:
bucket = sys.argv[1]
except IndexError:
print("Please provide a bucket name")
sys.exit(1)
# Create a SparkSession under the name "reddit". Viewable via the Spark UI
spark = SparkSession.builder.appName("reddit topic model").getOrCreate()
# Create a three column schema consisting of two strings and a long integer
fields = [StructField("title", StringType(), True),
StructField("body", StringType(), True),
StructField("created_at", LongType(), True)]
schema = StructType(fields)
# We'll attempt to process every year / month combination below.
years = ['2016', '2017', '2018', '2019']
months = ['01', '02', '03', '04', '05', '06',
'07', '08', '09', '10', '11', '12']
# This is the subreddit we're working with.
subreddit = "food"
# Create a base dataframe.
reddit_data = spark.createDataFrame([], schema)
# Keep a running list of all files that will be processed
files_read = []
for year in years:
for month in months:
# In the form of <project-id>.<dataset>.<table>
gs_uri = f"gs://{bucket}/reddit_posts/{year}/{month}/{subreddit}.csv.gz"
# If the table doesn't exist we will simply continue and not
# log it into our "tables_read" list
try:
reddit_data = (
spark.read.format('csv')
.options(codec="org.apache.hadoop.io.compress.GzipCodec")
.load(gs_uri, schema=schema)
.union(reddit_data)
)
files_read.append(gs_uri)
except AnalysisException:
continue
if len(files_read) == 0:
print('No files read')
sys.exit(1)
# Replacing null values with their respective typed-equivalent is usually
# easier to work with. In this case, we'll replace nulls with empty strings.
# Since some of our data doesn't have a body, we can combine all of the text
# for the titles and bodies so that every row has useful data.
df_train = (
reddit_data
# Replace null values with an empty string
.fillna("")
.select(
# Combine columns
concat(
# First column to concatenate. col() is used to specify that we're referencing a column
col("title"),
# Literal character that will be between the concatenated columns.
lit(" "),
# Second column to concatenate.
col("body")
# Change the name of the new column
).alias("text")
)
)
# Now, we begin assembling our pipeline. Each component here is used to some transformation to the data.
# The Document Assembler takes the raw text data and convert it into a format that can
# be tokenized. It becomes one of spark-nlp native object types, the "Document".
document_assembler = DocumentAssembler().setInputCol("text").setOutputCol("document")
# The Tokenizer takes data that is of the "Document" type and tokenizes it.
# While slightly more involved than this, this is effectively taking a string and splitting
# it along ths spaces, so each word is its own string. The data then becomes the
# spark-nlp native type "Token".
tokenizer = Tokenizer().setInputCols(["document"]).setOutputCol("token")
# The Normalizer will group words together based on similar semantic meaning.
normalizer = Normalizer().setInputCols(["token"]).setOutputCol("normalizer")
# The Stemmer takes objects of class "Token" and converts the words into their
# root meaning. For instance, the words "cars", "cars'" and "car's" would all be replaced
# with the word "car".
stemmer = Stemmer().setInputCols(["normalizer"]).setOutputCol("stem")
# The Finisher signals to spark-nlp allows us to access the data outside of spark-nlp
# components. For instance, we can now feed the data into components from Spark MLlib.
finisher = Finisher().setInputCols(["stem"]).setOutputCols(["to_spark"]).setValueSplitSymbol(" ")
# Stopwords are common words that generally don't add much detail to the meaning
# of a body of text. In English, these are mostly "articles" such as the words "the"
# and "of".
stopword_remover = StopWordsRemover(inputCol="to_spark", outputCol="filtered")
# Here we implement TF-IDF as an input to our LDA model. CountVectorizer (TF) keeps track
# of the vocabulary that's being created so we can map our topics back to their
# corresponding words.
# TF (term frequency) creates a matrix that counts how many times each word in the
# vocabulary appears in each body of text. This then gives each word a weight based
# on its frequency.
tf = CountVectorizer(inputCol="filtered", outputCol="raw_features")
# Here we implement the IDF portion. IDF (Inverse document frequency) reduces
# the weights of commonly-appearing words.
idf = IDF(inputCol="raw_features", outputCol="features")
# LDA creates a statistical representation of how frequently words appear
# together in order to create "topics" or groups of commonly appearing words.
lda = LDA(k=10, maxIter=10)
# We add all of the transformers into a Pipeline object. Each transformer
# will execute in the ordered provided to the "stages" parameter
pipeline = Pipeline(
stages = [
document_assembler,
tokenizer,
normalizer,
stemmer,
finisher,
stopword_remover,
tf,
idf,
lda
]
)
# We fit the data to the model.
model = pipeline.fit(df_train)
# Now that we have completed a pipeline, we want to output the topics as human-readable.
# To do this, we need to grab the vocabulary generated from our pipeline, grab the topic
# model and do the appropriate mapping. The output from each individual component lives
# in the model object. We can access them by referring to them by their position in
# the pipeline via model.stages[<ind>]
# Let's create a reference our vocabulary.
vocab = model.stages[-3].vocabulary
# Next, let's grab the topics generated by our LDA model via describeTopics(). Using collect(),
# we load the output into a Python array.
raw_topics = model.stages[-1].describeTopics().collect()
# Lastly, let's get the indices of the vocabulary terms from our topics
topic_inds = [ind.termIndices for ind in raw_topics]
# The indices we just grab directly map to the term at position <ind> from our vocabulary.
# Using the below code, we can generate the mappings from our topic indices to our vocabulary.
topics = []
for topic in topic_inds:
_topic = []
for ind in topic:
_topic.append(vocab[ind])
topics.append(_topic)
# Let's see our topics!
for i, topic in enumerate(topics, start=1):
print(f"topic {i}: {topic}")
Como executar o job
Agora, vamos executar nosso job. Execute o comando a seguir:
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME}\
--region ${REGION}\
--properties=spark.jars.packages=com.johnsnowlabs.nlp:spark-nlp_2.11:2.7.2\
--driver-log-levels root=FATAL \
topic_model.py \
-- ${BUCKET_NAME}
Esse comando permite aproveitar a API Jobs do Dataproc. Ao incluir o comando pyspark, estamos indicando ao cluster que esse é um job do PySpark. Fornecemos o nome do cluster, parâmetros opcionais dos disponíveis aqui e o nome do arquivo que contém o job. No nosso caso, estamos fornecendo o parâmetro --properties, que permite mudar várias propriedades do Spark, do Yarn ou do Dataproc. Estamos mudando a propriedade packages do Spark, que nos permite informar ao Spark que queremos incluir spark-nlp como empacotado com nosso job. Também estamos fornecendo os parâmetros --driver-log-levels root=FATAL, que vão suprimir a maior parte da saída de registro do PySpark, exceto erros. Em geral, os registros do Spark tendem a ser ruidosos.
Por fim, -- ${BUCKET} é um argumento de linha de comando para o próprio script Python que fornece o nome do bucket. Observe o espaço entre -- e ${BUCKET}.
Após alguns minutos de execução do job, vamos ver a saída contendo nossos modelos:

Maravilha!! Você consegue inferir tendências observando a saída do seu modelo? E o nosso?
Na saída acima, é possível inferir uma tendência do tópico 8 referente a alimentos para o café da manhã e sobremesas do tópico 9.
9. Revisão dos dados
Para evitar cobranças desnecessárias na sua conta do GCP após a conclusão deste guia de início rápido:
- Exclua o bucket do Cloud Storage do ambiente e que você criou.
- Exclua o ambiente do Dataproc.
Se você criou um projeto apenas para este codelab, também poderá excluir o projeto:
- No Console do GCP, acesse a página Projetos.
- Na lista de projetos, selecione um e clique em Excluir.
- Na caixa, insira o ID do projeto e clique em desligar para excluir o projeto.
Licença
Este trabalho está licenciado sob uma Licença Creative Commons Atribuição 3.0 genérica e uma licença Apache 2.0.