
О практической работе
1. Прежде чем вы начнете
За последнее десятилетие веб-приложения стали еще более социальными и интерактивными, с поддержкой мультимедиа, комментариев и т. д. Все это происходит в реальном времени потенциально десятками тысяч людей даже на умеренно популярном веб-сайте.
Это также предоставило спамерам возможность злоупотреблять такими системами и ассоциировать менее пикантный контент со статьями, видео и сообщениями, написанными другими, в попытке получить большую известность.
Старые методы обнаружения спама, такие как список заблокированных слов, можно легко обойти, и они просто не подходят для продвинутых спам-ботов, сложность которых постоянно растет. Перенесемся в сегодняшний день, и теперь вы можете использовать модели машинного обучения, обученные обнаруживать такой спам.
Традиционно запуск модели машинного обучения для предварительной фильтрации комментариев выполнялся бы на стороне сервера, но с TensorFlow.js теперь вы можете выполнять модели машинного обучения на стороне клиента в браузере через JavaScript. Вы можете остановить спам еще до того, как он коснется серверной части, потенциально экономя дорогостоящие ресурсы на стороне сервера.
Как вы, возможно, знаете, машинное обучение в наши дни стало довольно модным словом, затрагивающим почти все отрасли, но как вы можете сделать свои первые шаги, чтобы использовать эти возможности в качестве веб-разработчика?
Эта лабораторная работа покажет вам, как с чистого листа создать веб-приложение, которое решает реальную проблему спама в комментариях, используя обработку естественного языка (искусство понимания человеческого языка с помощью компьютера). Многие веб-разработчики столкнутся с этой проблемой, когда будут работать над одним из постоянно растущего числа популярных веб-приложений, существующих сегодня, и эта лаборатория кода позволит вам эффективно решать такие проблемы.
Предпосылки
Эта лаборатория кода была написана для веб-разработчиков, которые плохо знакомы с машинным обучением и хотят начать использовать предварительно обученные модели с TensorFlow.js.
Для этой лабораторной работы предполагается знание HTML5, CSS и JavaScript.
Что вы узнаете
Ты сможешь:
- Узнайте больше о том, что такое TensorFlow.js и какие модели существуют для обработки естественного языка.
- Создайте простую веб-страницу HTML/CSS/JS для вымышленного видеоблога с разделом комментариев в реальном времени.
- Используйте TensorFlow.js, чтобы загрузить предварительно обученную модель машинного обучения, способную предсказывать, является ли введенное предложение спамом, и если это так, предупреждать пользователя о том, что его комментарий находится на модерации.
- Кодируйте предложения комментариев таким образом, чтобы модель машинного обучения могла их затем классифицировать.
- Интерпретируйте выходные данные модели машинного обучения, чтобы решить, хотите ли вы автоматически помечать комментарий или нет. Этот гипотетический UX можно повторно использовать на любом веб-сайте, над которым вы работаете, и адаптировать к любому варианту использования клиента — может быть, это обычный блог, форум или какая-то форма CMS, такая как Drupal.
Довольно аккуратно. Это трудно сделать? Неа. Итак, приступим к взлому...
Что вам понадобится
- предпочтительна учетная запись Glitch.com, или вы можете использовать среду веб-обслуживания, которую вам удобно редактировать и запускать самостоятельно.
2. Что такое TensorFlow.js?

TensorFlow.js — это библиотека машинного обучения с открытым исходным кодом, которая может работать везде, где может работать JavaScript. Он основан на оригинальной библиотеке TensorFlow, написанной на Python , и призван воссоздать этот опыт разработчиков и набор API-интерфейсов для экосистемы JavaScript.
Где его можно использовать?
Учитывая переносимость JavaScript, теперь вы можете писать на одном языке и с легкостью выполнять машинное обучение на всех следующих платформах:
- Клиентская сторона в веб-браузере с использованием ванильного JavaScript
- Серверная часть и даже устройства IoT, такие как Raspberry Pi, использующие Node.js
- Настольные приложения, использующие Electron
- Нативные мобильные приложения с использованием React Native
TensorFlow.js также поддерживает несколько бэкэндов в каждой из этих сред (фактические аппаратные среды, в которых он может выполняться, например, ЦП или WebGL). «Бэкэнд» в этом контексте не означает серверную среду — бэкэнд для выполнения. может быть, например, на стороне клиента в WebGL), чтобы обеспечить совместимость, а также ускорить работу. В настоящее время TensorFlow.js поддерживает:
- Выполнение WebGL на графической карте устройства (GPU) — это самый быстрый способ запуска больших моделей (размером более 3 МБ) с ускорением GPU.
- Выполнение веб-сборки (WASM) на ЦП — для повышения производительности ЦП на устройствах, включая, например, мобильные телефоны старого поколения. Это лучше подходит для небольших моделей (размером менее 3 МБ), которые на самом деле могут работать быстрее на ЦП с WASM, чем с WebGL, из-за накладных расходов на загрузку контента в графический процессор.
- Выполнение ЦП — запасной вариант, если ни одна из других сред недоступна. Это самый медленный из трех, но всегда рядом с вами.
Примечание. Вы можете принудительно включить один из этих бэкендов , если знаете, на каком устройстве будете выполнять выполнение, или вы можете просто позволить TensorFlow.js решить за вас, если вы не укажете это.
Сверхспособности на стороне клиента
Запуск TensorFlow.js в веб-браузере на клиентском компьютере может дать несколько преимуществ, которые стоит учитывать.
Конфиденциальность
Вы можете обучать и классифицировать данные на клиентском компьютере, даже не отправляя данные на сторонний веб-сервер. Могут быть случаи, когда это может быть требованием соблюдения местных законов, таких как GDPR, например, или при обработке любых данных, которые пользователь может захотеть сохранить на своем компьютере и не отправлять третьей стороне.
Скорость
Поскольку вам не нужно отправлять данные на удаленный сервер, вывод (акт классификации данных) может быть быстрее. Более того, у вас есть прямой доступ к датчикам устройства, таким как камера, микрофон, GPS, акселерометр и т. д., если пользователь предоставит вам доступ.
Охват и масштабирование
Одним щелчком мыши любой человек в мире может щелкнуть ссылку, которую вы ему отправляете, открыть веб-страницу в своем браузере и использовать то, что вы сделали. Нет необходимости в сложной настройке Linux на стороне сервера с драйверами CUDA и многое другое, просто чтобы использовать систему машинного обучения.
Расходы
Отсутствие серверов означает, что единственное, за что вам нужно платить, — это CDN для размещения файлов HTML, CSS, JS и моделей. Стоимость CDN намного дешевле, чем поддержка сервера (возможно, с подключенной видеокартой), работающего круглосуточно и без выходных.
Возможности на стороне сервера
Использование реализации TensorFlow.js в Node.js обеспечивает следующие функции.
Полная поддержка CUDA
На стороне сервера для ускорения видеокарты необходимо установить драйверы NVIDIA CUDA, чтобы TensorFlow мог работать с видеокартой (в отличие от браузера, использующего WebGL — установка не требуется). Однако с полной поддержкой CUDA вы можете в полной мере использовать возможности графической карты более низкого уровня, что приводит к более быстрому обучению и времени вывода. Производительность находится на одном уровне с реализацией Python TensorFlow, поскольку обе они используют один и тот же серверный код C++.
Размер модели
Для передовых моделей из исследований вы можете работать с очень большими моделями, возможно, размером в гигабайты. Эти модели в настоящее время не могут быть запущены в веб-браузере из-за ограничений использования памяти для каждой вкладки браузера. Для запуска этих более крупных моделей вы можете использовать Node.js на своем собственном сервере с аппаратными характеристиками, необходимыми для эффективной работы такой модели.
Интернет вещей
Node.js поддерживается на популярных одноплатных компьютерах, таких как Raspberry Pi , что, в свою очередь, означает, что вы можете запускать модели TensorFlow.js и на таких устройствах.
Скорость
Node.js написан на JavaScript, а это значит, что он выигрывает от своевременной компиляции. Это означает, что вы часто можете увидеть прирост производительности при использовании Node.js, поскольку он будет оптимизирован во время выполнения, особенно для любой предварительной обработки, которую вы можете выполнять. Отличный пример этого можно увидеть в этом тематическом исследовании , которое показывает, как Hugging Face использовала Node.js для двукратного повышения производительности своей модели обработки естественного языка.
Теперь вы понимаете основы TensorFlow.js, где он может работать и некоторые преимущества, давайте начнем делать с ним полезные вещи!
3. Предварительно обученные модели
Зачем мне использовать предварительно обученную модель?
Есть ряд преимуществ в том, чтобы начать с популярной предварительно обученной модели, если она соответствует желаемому варианту использования, например:
- Не нужно собирать данные для тренировок самостоятельно. Подготовка данных в правильном формате и их маркировка, чтобы система машинного обучения могла использовать их для обучения, может занять очень много времени и средств.
- Возможность быстро прототипировать идею с меньшими затратами и временем.
Нет смысла «изобретать велосипед», когда предварительно обученная модель может быть достаточно хороша, чтобы делать то, что вам нужно, позволяя вам сосредоточиться на использовании знаний, предоставляемых моделью, для реализации ваших творческих идей. - Использование современных исследований. Предварительно обученные модели часто основаны на популярных исследованиях, что дает вам представление о таких моделях, а также понимание их эффективности в реальном мире.
- Простота использования и обширная документация. В связи с популярностью таких моделей.
- Передать способности к обучению. Некоторые предварительно обученные модели предлагают возможности переноса обучения, что, по сути, является практикой переноса информации, полученной из одной задачи машинного обучения, в другой аналогичный пример. Например, модель, которая изначально была обучена распознавать кошек, может быть переобучена для распознавания собак, если дать ей новые обучающие данные. Это будет быстрее, так как вы не будете начинать с чистого листа. Модель может использовать то, чему она уже научилась распознавать кошек, чтобы затем распознать новую вещь — в конце концов, у собак тоже есть глаза и уши, поэтому, если она уже знает, как находить эти признаки, мы на полпути. Переобучите модель на собственных данных гораздо быстрее.
Предварительно обученная модель обнаружения спама в комментариях
Вы будете использовать архитектуру модели Average Word Embedding для своих потребностей в обнаружении спама в комментариях, однако, если вы попытаетесь использовать необученную модель, это не будет лучше, чем случайный шанс угадать, являются ли предложения спамом или нет.
Чтобы сделать модель полезной, ее необходимо обучить на пользовательских данных, в данном случае, чтобы позволить ей узнать, как выглядят спамовые и не спамовые комментарии. Благодаря этому обучению у него будет больше шансов правильно классифицировать вещи в будущем.
К счастью, кто-то уже обучил эту точную архитектуру модели для этой задачи классификации спама в комментариях, поэтому вы можете использовать ее в качестве отправной точки. Вы можете найти другие предварительно обученные модели, использующие ту же архитектуру модели, чтобы делать разные вещи, например определять, на каком языке был написан комментарий, или прогнозировать, должны ли данные контактной формы веб-сайта автоматически направляться определенной команде компании на основе написанного текста. например, продажи (запрос продукта) или проектирование (техническая ошибка или обратная связь). При наличии достаточного количества обучающих данных такая модель может научиться классифицировать такой текст в каждом случае, чтобы дать вашему веб-приложению сверхвозможности и повысить эффективность вашей организации.
В будущем лабораторном коде вы узнаете, как использовать Model Maker для переобучения этой предварительно обученной модели спама в комментариях и дальнейшего повышения ее производительности на ваших собственных данных комментариев. На данный момент вы будете использовать существующую модель обнаружения спама в комментариях в качестве отправной точки, чтобы заставить исходное веб-приложение работать в качестве первого прототипа.
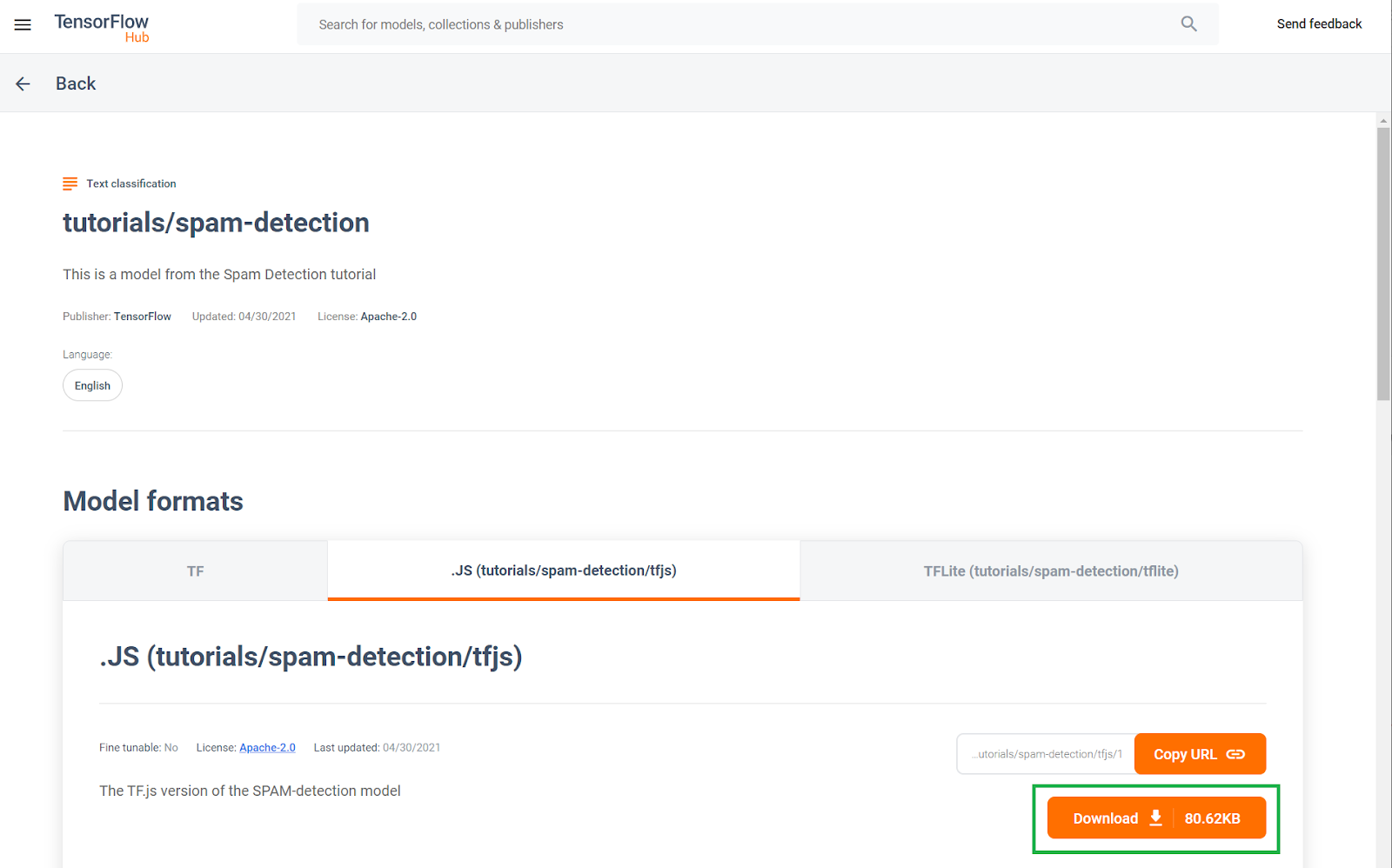
Эта предварительно обученная модель обнаружения спама в комментариях была опубликована на веб-сайте, известном как TF Hub, хранилище моделей машинного обучения, поддерживаемое Google, где инженеры машинного обучения могут публиковать свои готовые модели для многих распространенных случаев использования (таких как текст, зрение, звук и многое другое для конкретных случаев использования в каждой из этих категорий). Идите вперед и загрузите файлы модели, чтобы использовать их в веб-приложении позже в этой кодовой лаборатории.
Нажмите кнопку загрузки модели JS, как показано ниже:
4. Настройтесь на код
Что вам понадобится
- Современный веб-браузер.
- Базовые знания HTML, CSS, JavaScript и Chrome DevTools (просмотр вывода консоли).
Приступаем к кодированию.
Мы создали стандартный шаблон Glitch.com Node.js Express , который вы можете просто клонировать в качестве базового состояния для этой лаборатории кода всего одним щелчком мыши.
В Glitch просто нажмите кнопку «создать ремикс» , чтобы разветвить его и создать новый набор файлов, которые вы сможете редактировать.
Этот очень простой скелет предоставляет нам следующие файлы в папке www :
- HTML-страница (index.html)
- Таблица стилей (style.css)
- Файл для написания нашего кода JavaScript (script.js)
Для вашего удобства мы также добавили в HTML-файл импорт для библиотеки TensorFlow.js, который выглядит так:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
Затем мы обслуживаем эту папку www через простой сервер Node Express через package.json и server.js
5. HTML-шаблон приложения
Какова ваша отправная точка?
Все прототипы требуют некоторых базовых HTML-шаблонов, на которых вы можете визуализировать свои выводы. Установите это сейчас. Вы собираетесь добавить:
- Название для страницы
- Какой-то описательный текст
- Видео-заполнитель, представляющий запись видеоблога
- Область для просмотра и ввода комментариев
Откройте index.html и вставьте поверх существующего кода следующий код, чтобы настроить вышеуказанные функции:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>My Pretend Video Blog</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<header>
<h1>MooTube</h1>
<a id="login" href="#">Login</a>
</header>
<h2>Check out the TensorFlow.js rap for the show and tell!</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur ipsum quam, tincidunt et tempor in, pulvinar vel urna. Nunc eget erat pulvinar, lacinia nisl in, rhoncus est. Morbi molestie vestibulum nunc. Integer non ipsum dolor. Curabitur condimentum sem eget odio dapibus, nec bibendum augue ultricies. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia curae; Sed iaculis ut ligula sed tempor. Phasellus ac dictum felis. Integer arcu dui, facilisis sit amet placerat sagittis, blandit sit amet risus.</p>
<iframe width="100%" height="500" src="https://www.youtube.com/embed/RhVs7ijB17c" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<section id="comments" class="comments">
<div id="comment" class="comment" contenteditable></div>
<button id="post" type="button">Comment</button>
<ul id="commentsList">
<li>
<span class="username">NotASpammer</span>
<span class="timestamp">3/18/2021, 6:52:16 PM</span>
<p>I am not a spammer, I am a good boy.</p>
</li>
<li>
<span class="username">SomeUser</span>
<span class="timestamp">2/11/2021, 3:10:00 PM</span>
<p>Wow, I love this video, so many amazing demos!</p>
</li>
</ul>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
Разрушая это
Давайте разберем часть приведенного выше HTML-кода, чтобы выделить некоторые ключевые вещи, которые вы добавили.
- Вы добавили
<h1>для заголовка страницы вместе с тегом<a>для кнопки входа в систему, все они содержатся в<header>. Затем вы добавили<h2>для названия статьи и<p>для описания видео. Здесь нет ничего особенного. - Вы добавили тег
iframe, который встраивает произвольное видео YouTube. На данный момент вы используете могучий рэп TensorFlow.js в качестве заполнителя, но вы можете поместить сюда любое видео, просто изменив URL-адрес iframe. Фактически, на рабочем веб-сайте все эти значения будут отображаться серверной частью динамически, в зависимости от просматриваемой страницы. - Наконец, вы добавили
sectionс идентификатором и классом «комментариев», который содержит элементdivс возможностью редактирования контента для написания новых комментариев, а такжеbuttonдля отправки нового комментария, который вы хотите добавить, вместе с неупорядоченным списком комментариев. У вас есть имя пользователя и время публикации в тегеspanвнутри каждого элемента списка, а затем, наконец, сам комментарий в тегеp. 2 примера комментариев пока жестко запрограммированы в качестве заполнителя.
Если вы просматриваете вывод прямо сейчас, он должен выглядеть примерно так:
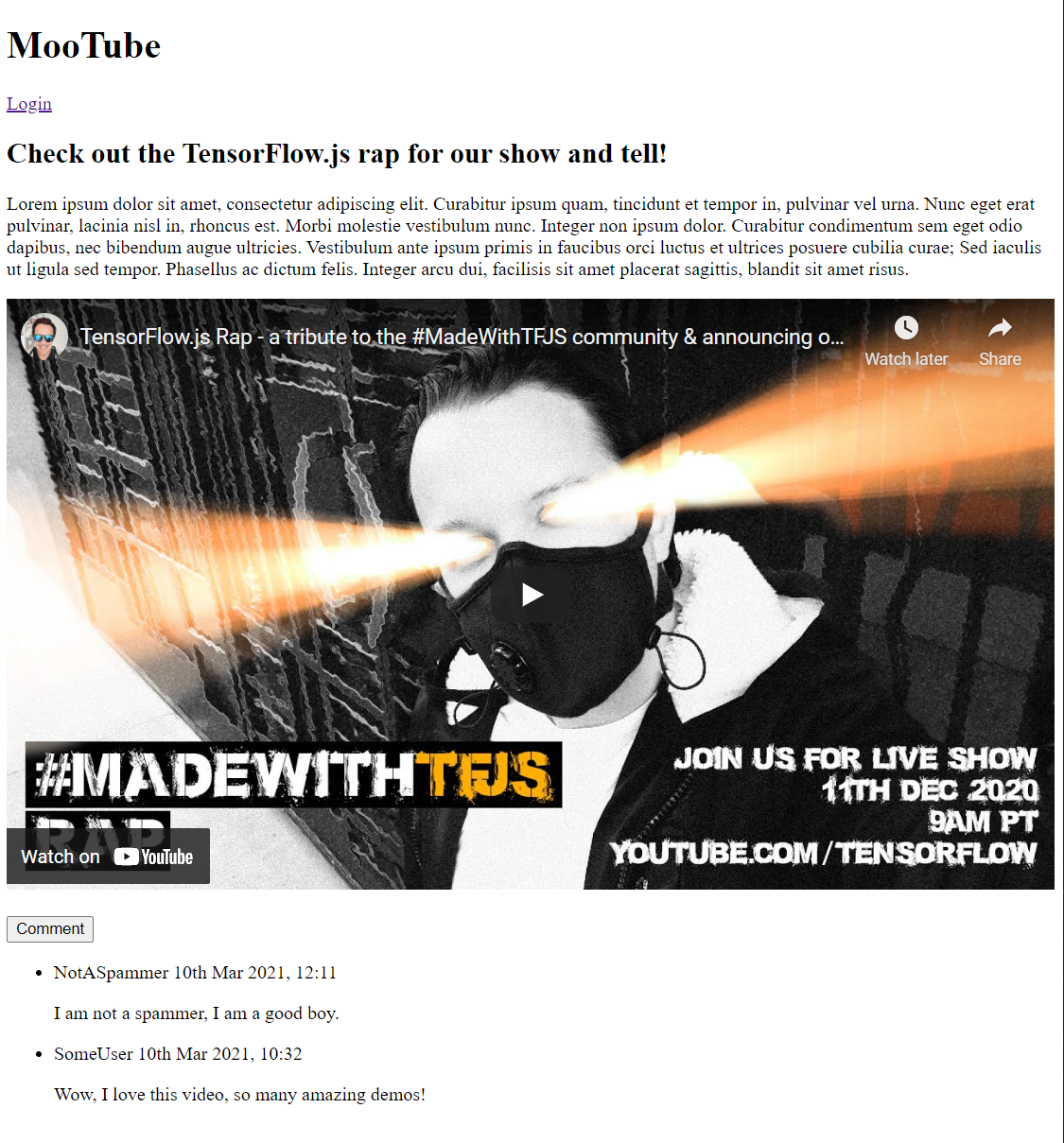
Ну, это выглядит довольно ужасно, так что пришло время добавить немного стиля...
6. Добавить стиль
Элементы по умолчанию
Во-первых, добавьте стили для только что добавленных HTML-элементов, чтобы убедиться, что они правильно отображаются.
Начните с применения сброса CSS, чтобы иметь начальную точку комментария во всех браузерах и ОС. Перезапишите содержимое style.css следующим образом:
стиль.css
/* http://meyerweb.com/eric/tools/css/reset/
v2.0 | 20110126
License: none (public domain)
*/
a,abbr,acronym,address,applet,article,aside,audio,b,big,blockquote,body,canvas,caption,center,cite,code,dd,del,details,dfn,div,dl,dt,em,embed,fieldset,figcaption,figure,footer,form,h1,h2,h3,h4,h5,h6,header,hgroup,html,i,iframe,img,ins,kbd,label,legend,li,mark,menu,nav,object,ol,output,p,pre,q,ruby,s,samp,section,small,span,strike,strong,sub,summary,sup,table,tbody,td,tfoot,th,thead,time,tr,tt,u,ul,var,video{margin:0;padding:0;border:0;font-size:100%;font:inherit;vertical-align:baseline}article,aside,details,figcaption,figure,footer,header,hgroup,menu,nav,section{display:block}body{line-height:1}ol,ul{list-style:none}blockquote,q{quotes:none}blockquote:after,blockquote:before,q:after,q:before{content:'';content:none}table{border-collapse:collapse;border-spacing:0}
Затем добавьте к этому полезный CSS, чтобы оживить пользовательский интерфейс.
Добавьте следующее в конец style.css под кодом сброса CSS, который вы добавили выше:
стиль.css
/* CSS files add styling rules to your content */
body {
background: #212121;
color: #fff;
font-family: helvetica, arial, sans-serif;
}
header {
background: linear-gradient(0deg, rgba(7,7,7,1) 0%, rgba(7,7,7,1) 85%, rgba(55,52,54,1) 100%);
min-height: 30px;
overflow: hidden;
}
h1 {
color: #f0821b;
font-size: 24pt;
padding: 15px 25px;
display: inline-block;
float: left;
}
h2, p, section, iframe {
background: #212121;
padding: 10px 25px;
}
h2 {
font-size: 16pt;
padding-top: 25px;
}
p {
color: #cdcdcd;
}
iframe {
display: block;
padding: 15px 0;
}
header a, button {
color: #222;
padding: 7px;
min-width: 100px;
background: rgb(240, 130, 30);
border-radius: 3px;
border: 1px solid #3d3d3d;
text-transform: uppercase;
font-weight: bold;
cursor: pointer;
transition: background 300ms ease-in-out;
}
header a {
background: #efefef;
float: right;
margin: 15px 25px;
text-decoration: none;
text-align: center;
}
button:focus, button:hover, header a:hover {
background: rgb(260, 150, 50);
}
.comment {
background: #212121;
border: none;
border-bottom: 1px solid #888;
color: #fff;
min-height: 25px;
display: block;
padding: 5px;
}
.comments button {
float: right;
margin: 5px 0;
}
.comments button, .comment {
transition: opacity 500ms ease-in-out;
}
.comments ul {
clear: both;
margin-top: 60px;
}
.comments ul li {
margin-top: 5px;
padding: 10px;
transition: background 500ms ease-in-out;
}
.comments ul li * {
background: transparent;
}
.comments ul li:nth-child(1) {
background: #313131;
}
.comments ul li:hover {
background: rgb(70, 60, 10);
}
.username, .timestamp {
font-size: 80%;
margin-right: 5px;
}
.username {
font-weight: bold;
}
.processing {
opacity: 0.3;
filter: grayscale(1);
}
.comments ul li.spam {
background-color: #d32f2f;
}
.comments ul li.spam::after {
content: "⚠";
margin: -17px 2px;
zoom: 3;
float: right;
}
Большой! Это все, что вам нужно. Если вы успешно перезаписали свои стили двумя приведенными выше фрагментами кода, предварительный просмотр в реальном времени должен выглядеть следующим образом:
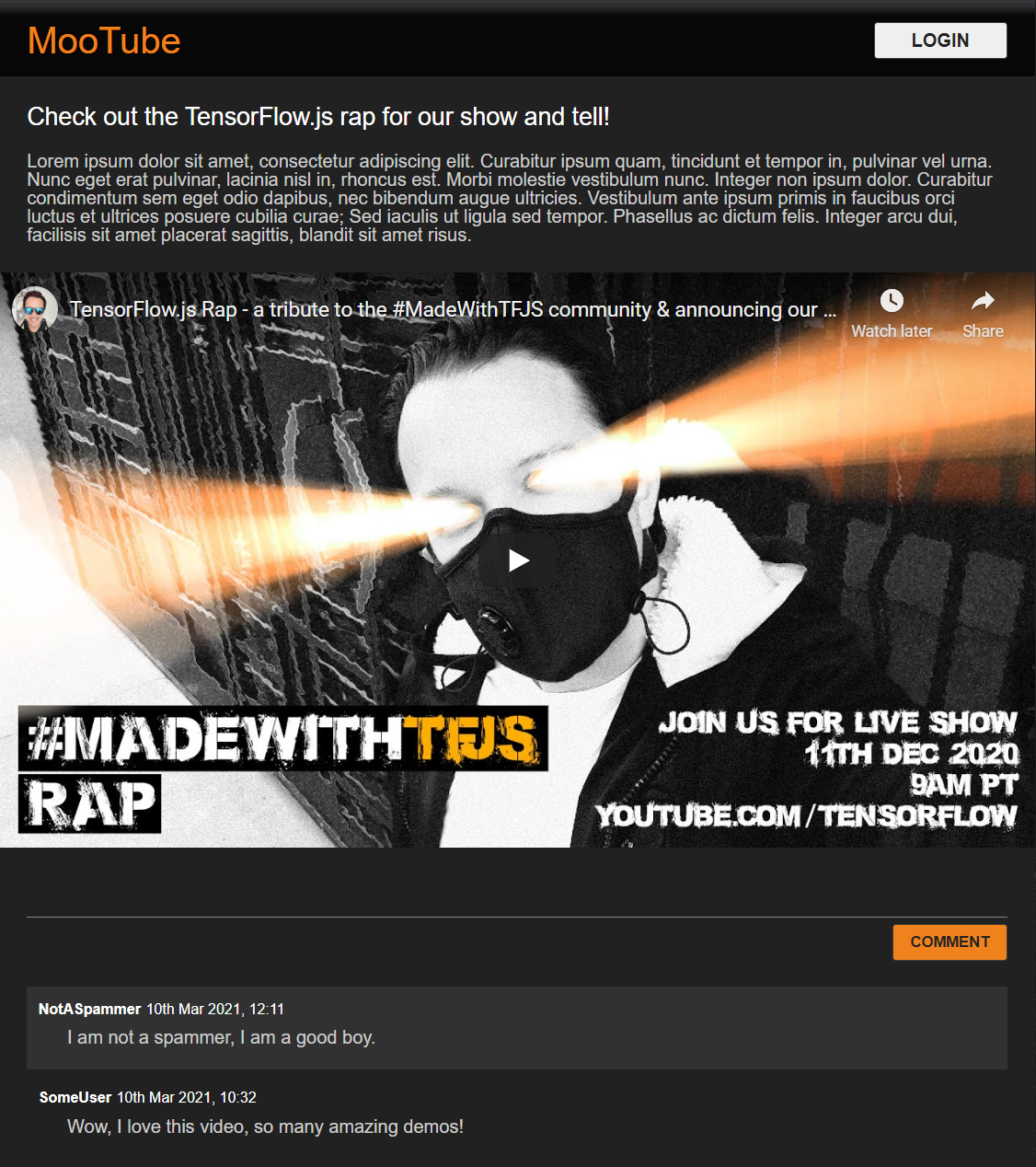
Приятный ночной режим по умолчанию и очаровательные переходы CSS для эффектов наведения на ключевые элементы. Хорошо смотритесь. Теперь интегрируйте некоторую поведенческую логику с помощью JavaScript.
7. JavaScript: манипулирование DOM и обработчики событий
Ссылки на ключевые элементы DOM
Во-первых, убедитесь, что вы можете получить доступ к ключевым частям страницы, которыми вам нужно будет управлять, или получить доступ позже в коде, а также определить некоторые константы класса CSS для стилей.
Начните с замены содержимого script.js следующими константами:
script.js
const POST_COMMENT_BTN = document.getElementById('post');
const COMMENT_TEXT = document.getElementById('comment');
const COMMENTS_LIST = document.getElementById('commentsList');
// CSS styling class to indicate comment is being processed when
// posting to provide visual feedback to users.
const PROCESSING_CLASS = 'processing';
// Store username of logged in user. Right now you have no auth
// so default to Anonymous until known.
var currentUserName = 'Anonymous';
Обработка публикации комментариев
Затем добавьте прослушиватель событий и функцию обработки в POST_COMMENT_BTN , чтобы он имел возможность захватывать написанный текст комментария и задавать класс CSS, чтобы указать, что обработка началась. Обратите внимание, что вы проверяете, не нажали ли вы кнопку, если обработка уже выполняется.
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
let currentComment = COMMENT_TEXT.innerText;
console.log(currentComment);
// TODO: Fill out the rest of this function later.
}
}
POST_COMMENT_BTN.addEventListener('click', handleCommentPost);
Большой! Если вы обновите веб-страницу и попробуете опубликовать комментарий, вы должны увидеть кнопку комментария и текст в оттенках серого, а в консоли вы должны увидеть комментарий, напечатанный следующим образом:
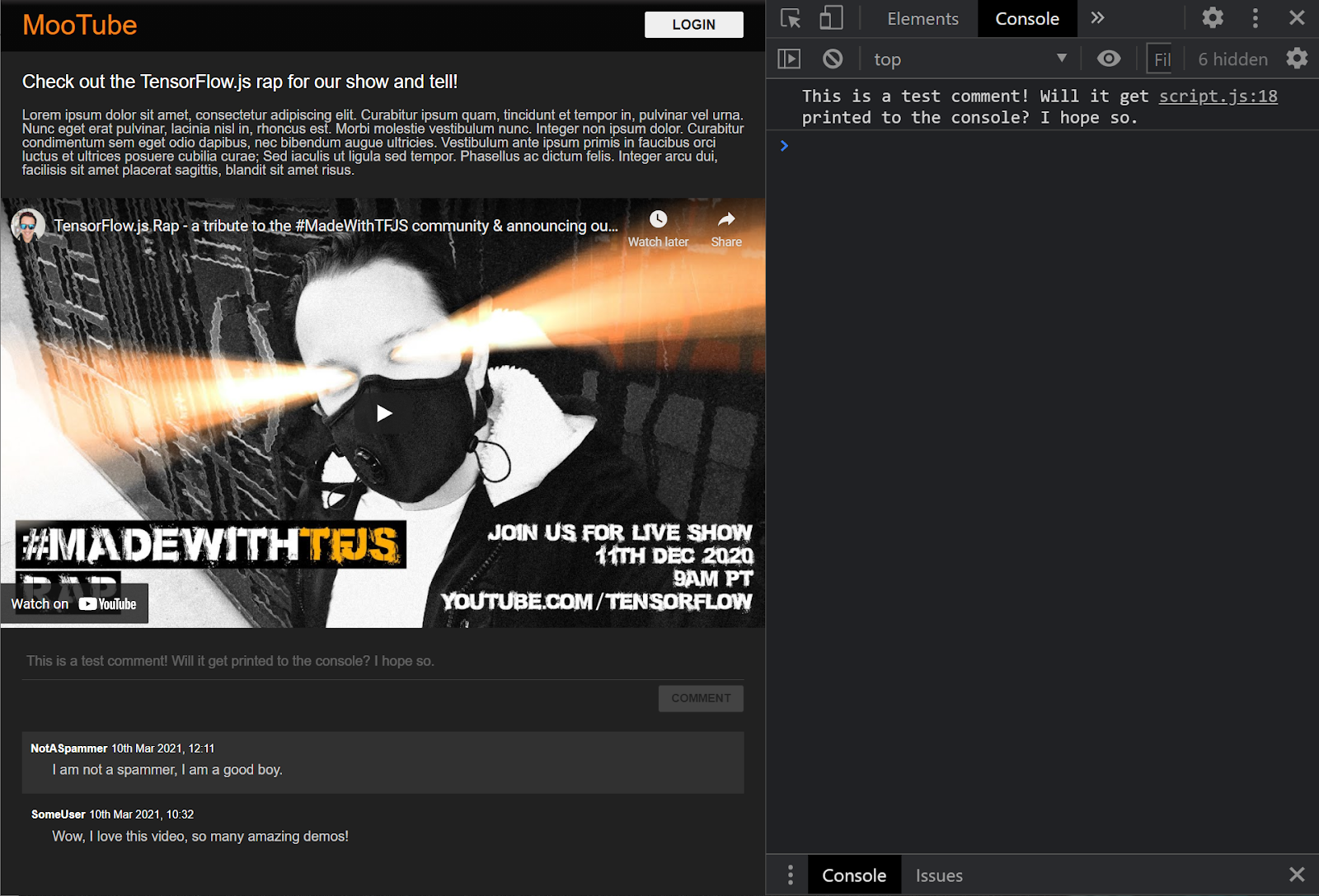
Теперь у вас есть базовый скелет HTML/CSS/JS, пришло время снова обратить внимание на модель машинного обучения, чтобы вы могли интегрировать ее с красивой веб-страницей.
8. Служите модели машинного обучения
Вы почти готовы загрузить модель. Прежде чем вы сможете это сделать, вы должны загрузить файлы моделей, загруженные ранее в лаборатории кода, на свой веб-сайт, чтобы они были размещены и могли использоваться в коде.
Во-первых, если вы еще этого не сделали, разархивируйте файлы, загруженные для модели в начале этой лаборатории кода. Вы должны увидеть каталог со следующими файлами, содержащимися внутри:
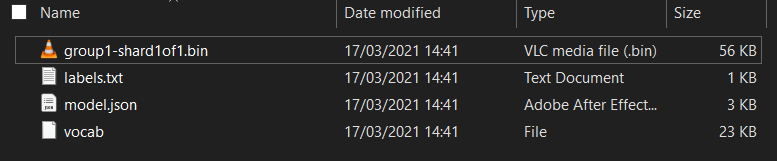
Что у вас здесь?
-
model.json— это один из файлов, составляющих обученную модель TensorFlow.js. Вы фактически будете ссылаться на этот конкретный файл позже в своем коде TensorFlow.js. -
group1-shard1of1.bin— это двоичный файл, содержащий обученные веса (по сути, набор чисел, которые он научился хорошо выполнять свою задачу классификации) модели TensorFlow.js, и его необходимо разместить где-то на вашем сервере для загрузки. -
vocab— этот странный файл без расширения создан в Model Maker и показывает нам, как кодировать слова в предложениях, чтобы модель понимала, как их использовать. Вы углубитесь в это в следующем разделе. -
labels.txt— просто содержит результирующие имена классов, которые будет предсказывать модель. Для этой модели, если вы откроете этот файл в своем текстовом редакторе, в нем просто будут указаны «ложь» и «истина», указывающие «не спам» или «спам» в качестве вывода прогноза.
Размещение файлов модели TensorFlow.js
Сначала поместите model.json и *.bin , созданные на веб-сервере, чтобы вы могли получить к ним доступ через веб-страницу.
Загрузить файлы в Glitch
- Щелкните папку активов на левой панели вашего проекта Glitch.
- Нажмите загрузить ресурс и выберите
group1-shard1of1.binдля загрузки в эту папку. Теперь он должен выглядеть так после загрузки:
- Большой! Теперь сделайте то же самое для файла
model.json. 2 файла должны быть в вашей папке с ресурсами , например:
- Щелкните только что загруженный файл
group1-shard1of1.bin. Вы сможете скопировать URL-адрес в его местоположение. Скопируйте этот путь сейчас, как показано:
- Теперь в левом нижнем углу экрана нажмите « Инструменты » > « Терминал ». Дождитесь загрузки окна терминала. После загрузки введите следующее, а затем нажмите Enter, чтобы изменить каталог на папку
www:
Терминал:
cd www
- Затем используйте
wgetдля загрузки 2 только что загруженных файлов, заменив приведенные ниже URL-адреса URL-адресами, которые вы создали для файлов в папке ресурсов на Glitch (проверьте папку ресурсов для каждого пользовательского URL-адреса файла). Обратите внимание на пробел между двумя URL-адресами и на то, что URL-адреса, которые вам нужно будет использовать, будут отличаться от приведенных ниже, но будут выглядеть одинаково:
Терминал
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Супер, теперь вы сделали копию файлов, загруженных в папку www , но сейчас они будут загружены со странными именами.
- Введите
lsв терминале и нажмите Enter. Вы увидите что-то вроде этого:

- С помощью команды
mvвы можете переименовать файлы. Введите в консоль следующее и нажимайте <kbd>Enter</kbd> или <kbd>return</kbd> после каждой строки:
Терминал:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Наконец, обновите проект Glitch, введя в терминале команду
refreshи нажав <kbd>Enter</kbd>:
Терминал:
refresh
- После обновления вы должны увидеть
model.jsonиgroup1-shard1of1.binв папкеwwwпользовательского интерфейса:
Большой! Теперь вы готовы использовать загруженные файлы моделей с реальным кодом в браузере.
9. Загрузите и используйте размещенную модель TensorFlow.js
Теперь вы находитесь в точке, где вы можете протестировать загрузку загруженной модели TensorFlow.js с некоторыми данными, чтобы проверить, работает ли она.
Прямо сейчас пример входных данных, который вы увидите ниже, будет выглядеть довольно загадочно (массив чисел), и как они были сгенерированы, будет объяснено в следующем разделе. Просто просмотрите его как массив чисел на данный момент. На этом этапе важно просто проверить, что модель дает нам ответ без ошибок.
Добавьте следующий код в конец файла script.js и обязательно замените строковое значение MODEL_JSON_URL на путь к файлу model.json , созданному при загрузке файла в папку ресурсов Glitch на предыдущем шаге. (Помните, вы можете просто щелкнуть файл в папке ресурсов на Glitch, чтобы найти его URL-адрес).
Прочитайте комментарии к новому коду ниже, чтобы понять, что делает каждая строка:
script.js
// Set the URL below to the path of the model.json file you uploaded.
const MODEL_JSON_URL = 'model.json';
// Set the minimum confidence for spam comments to be flagged.
// Remember this is a number from 0 to 1, representing a percentage
// So here 0.75 == 75% sure it is spam.
const SPAM_THRESHOLD = 0.75;
// Create a variable to store the loaded model once it is ready so
// you can use it elsewhere in the program later.
var model = undefined;
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
// TODO: Add extra logic here later to do something useful
}
loadAndPredict(tf.tensor([[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]));
Если проект настроен правильно, вы должны теперь увидеть что-то вроде следующего, напечатанного в окне консоли, когда вы используете загруженную модель для прогнозирования результата на основе переданного ей ввода:
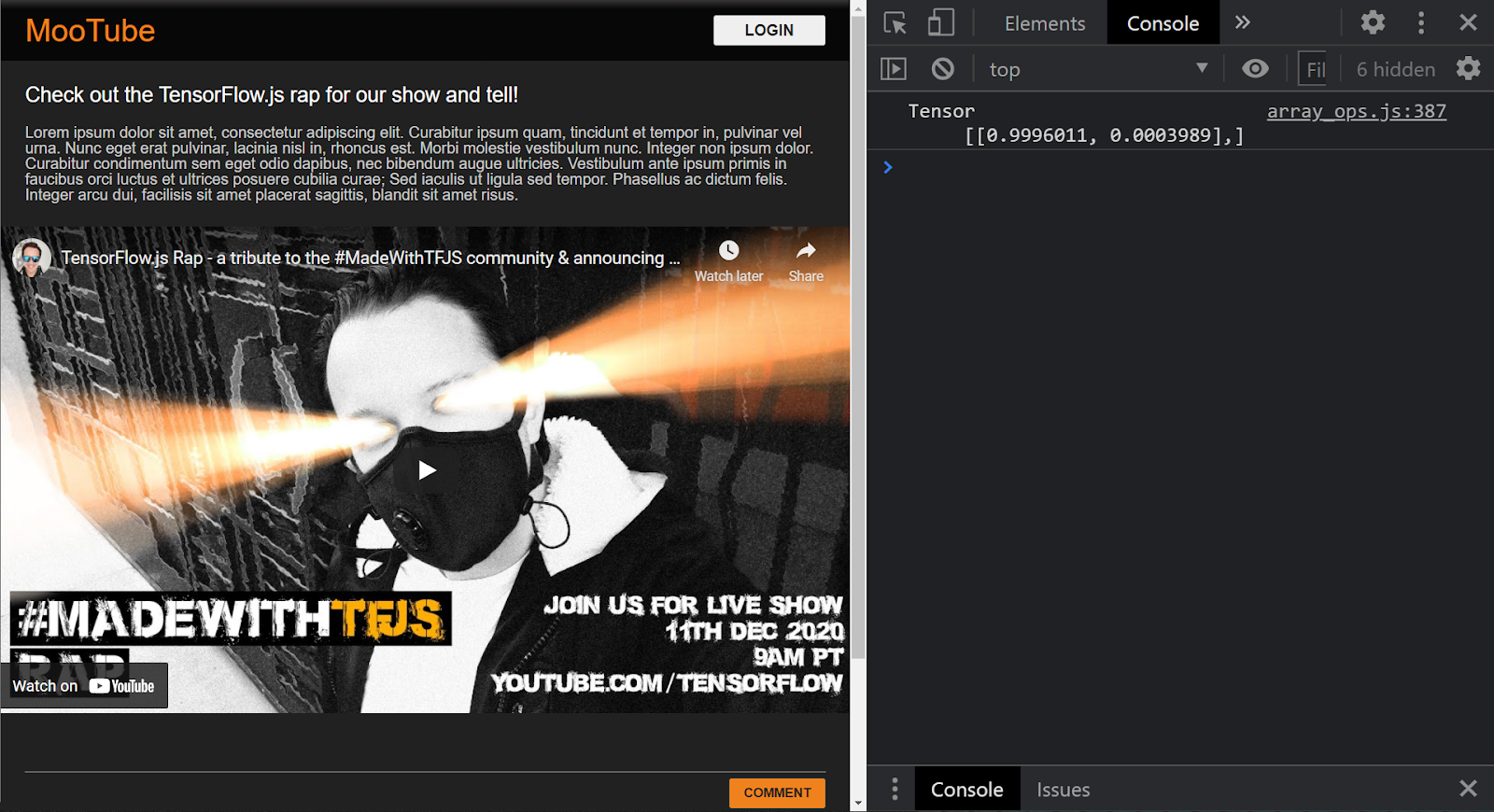
В консоли вы видите 2 напечатанных числа:
- 0,9996011
- 0,0003989
Хотя это может показаться загадочным, эти числа на самом деле представляют собой вероятности того, что модель считает классификацией для введенных вами данных. Но что они представляют?
Если вы откроете файл labels.txt из загруженных файлов модели, которые есть на вашем локальном компьютере, вы увидите, что он также имеет 2 поля:
- ЛОЖЬ
- Истинный
Таким образом, модель в этом случае говорит, что она на 99,96011% уверена (показано в объекте результата как 0,9996011), что введенные вами данные (которые были [1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] НЕ было спамом (т.е. ложью).
Обратите внимание, что false была первой меткой в labels.txt и представлена первым выводом в консоли print, благодаря которому вы узнаете, к чему относится прогноз вывода.
Итак, теперь вы знаете, как интерпретировать выходные данные, но что именно представляла собой эта большая группа чисел, заданная в качестве входных данных, и как преобразовать предложения в этот формат для использования в модели? Для этого вам нужно узнать о токенизации и тензорах. Читать дальше!
10. Токенизация и тензоры
Токенизация
Получается, что модели машинного обучения могут принимать только набор чисел в качестве входных данных. Почему? По сути, это потому, что модель машинного обучения — это, по сути, набор связанных математических операций, поэтому, если вы передадите ей что-то, что не является числом, ей будет трудно с этим справиться. Итак, теперь возникает вопрос, как преобразовать предложения в числа для использования с загруженной вами моделью?
Ну, точный процесс отличается от модели к модели, но для этого есть еще один файл в загруженных вами файлах модели, который называется vocab, и это ключ к тому, как вы кодируете данные.
Откройте vocab в локальном текстовом редакторе на своем компьютере, и вы увидите что-то вроде этого:
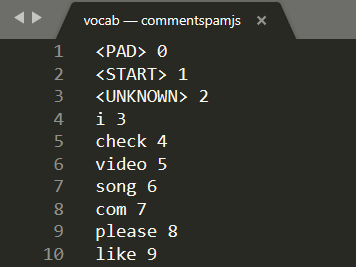
По сути, это справочная таблица того, как преобразовать значимые слова, которые выучила модель, в числа, которые она может понять. Есть также несколько особых случаев в начале файла <PAD> , <START> и <UNKNOWN> :
-
<PAD>— сокращение от «padding». Оказывается, модели машинного обучения любят иметь фиксированное количество входных данных, независимо от того, насколько длинным может быть ваше предложение. Используемая модель предполагает, что для ввода всегда будет 20 чисел (это было определено создателем модели и может быть изменено при повторном обучении модели). Поэтому, если у вас есть фраза типа «Мне нравится видео», вы должны заполнить оставшиеся пробелы в массиве нулями, которые представляют токен<PAD>. Если предложение состоит более чем из 20 слов, вам нужно будет разделить его, чтобы оно соответствовало этому требованию, и вместо этого выполнить несколько классификаций для множества небольших предложений. -
<START>— это просто всегда первая лексема, указывающая начало предложения. Вы заметите, что в примере, введенном на предыдущих шагах, массив чисел начинался с «1» — это представляло токен<START>. -
<UNKNOWN>— как вы могли догадаться, если слово не существует в этом поиске слов, вы просто используете токен<UNKNOWN>(обозначенный цифрой «2») в качестве числа.
Для любого другого слова оно либо существует в поиске и имеет связанный с ним специальный номер, поэтому вы должны использовать его, либо оно не существует, и в этом случае вместо этого вы используете номер токена <UNKNOWN> .
Take another look at the input used in the prior code you ran:
[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
Теперь вы можете видеть, что это было предложение с 4 словами, так как остальные являются токенами <START> или <PAD> , а в массиве 20 чисел. Хорошо, начинаю понимать немного больше.
Предложение, которое я на самом деле написал для этого, было «Я люблю свою собаку». Вы можете видеть на скриншоте выше, что «I» преобразуется в цифру «3», что правильно. Если бы вы искали другие слова, вы бы также нашли соответствующие им номера.
Тензоры
Есть еще одно препятствие, прежде чем модель машинного обучения примет ваши числовые данные. Вы должны преобразовать массив чисел в нечто, известное как тензор, и да, как вы уже догадались, TensorFlow назван в честь этих вещей — по сути, поток тензоров через модель.
Что такое тензор?
Официальное определение от TensorFlow.org гласит:
«Тензоры — это многомерные массивы с единым типом. Все тензоры неизменяемы: вы никогда не сможете обновить содержимое тензора, только создайте новый».
Проще говоря, это просто причудливое математическое имя для массива любой размерности, у которого есть некоторые другие функции, встроенные в Tensor Object, которые полезны нам как разработчикам машинного обучения. Однако следует отметить, что тензоры хранят данные только одного типа, например, все целые числа или все числа с плавающей запятой, и после создания вы никогда не сможете изменить содержимое тензора — таким образом, вы можете думать о нем как о постоянном хранилище для чисел!
Пока не слишком беспокойтесь об этом. По крайней мере, думайте об этом как о многомерном механизме хранения для моделей машинного обучения, с которым можно работать, пока вы не погрузитесь глубже в хорошую книгу , подобную этой — настоятельно рекомендуется, если вы хотите узнать больше о тензорах и о том, как их использовать.
Соедините все вместе: тензоры кодирования и токенизация
Итак, как вы используете этот файл vocab в коде? Отличный вопрос!
Этот файл сам по себе совершенно бесполезен для вас как разработчика JS. Было бы намного лучше, если бы это был объект JavaScript, который можно было бы просто импортировать и использовать. Можно увидеть, как было бы довольно просто преобразовать данные в этом файле в формат, более похожий на этот:
// Special cases. Export as constants.
export const PAD = 0;
export const START = 1;
export const UNKNOWN = 2;
// Export a lookup object.
export const LOOKUP = {
"i": 3,
"check": 4,
"video": 5,
"song": 6,
"com": 7,
"please": 8,
"like": 9
// and all the other words...
}
Используя ваш любимый текстовый редактор, вы можете легко преобразовать файл vocab в такой формат с помощью поиска и замены. Однако вы также можете использовать этот готовый инструмент, чтобы упростить эту задачу.
Выполнив эту работу заранее и сохранив файл vocab в правильном формате, вам не придется выполнять это преобразование и синтаксический анализ при каждой загрузке страницы, что является пустой тратой ресурсов ЦП. Более того, объекты JavaScript имеют следующие свойства:
«Именем свойства объекта может быть любая допустимая строка JavaScript или что-либо, что может быть преобразовано в строку, включая пустую строку. Однако любое имя свойства, которое не является допустимым идентификатором JavaScript (например, имя свойства, содержащее пробел или дефис, или начинающийся с цифры) можно получить только с помощью обозначения квадратных скобок».
Таким образом, пока вы используете нотацию с квадратными скобками, вы можете создать довольно эффективную таблицу поиска с помощью этого простого преобразования.
Преобразование в более удобный формат
Преобразуйте файл vocab в формат, указанный выше, либо вручную с помощью текстового редактора, либо с помощью этого инструмента здесь . Сохраните полученный результат как dictionary.js в вашей папке www .
В Glitch вы можете просто создать новый файл в этом месте и вставить результат преобразования, чтобы сохранить его, как показано ниже:
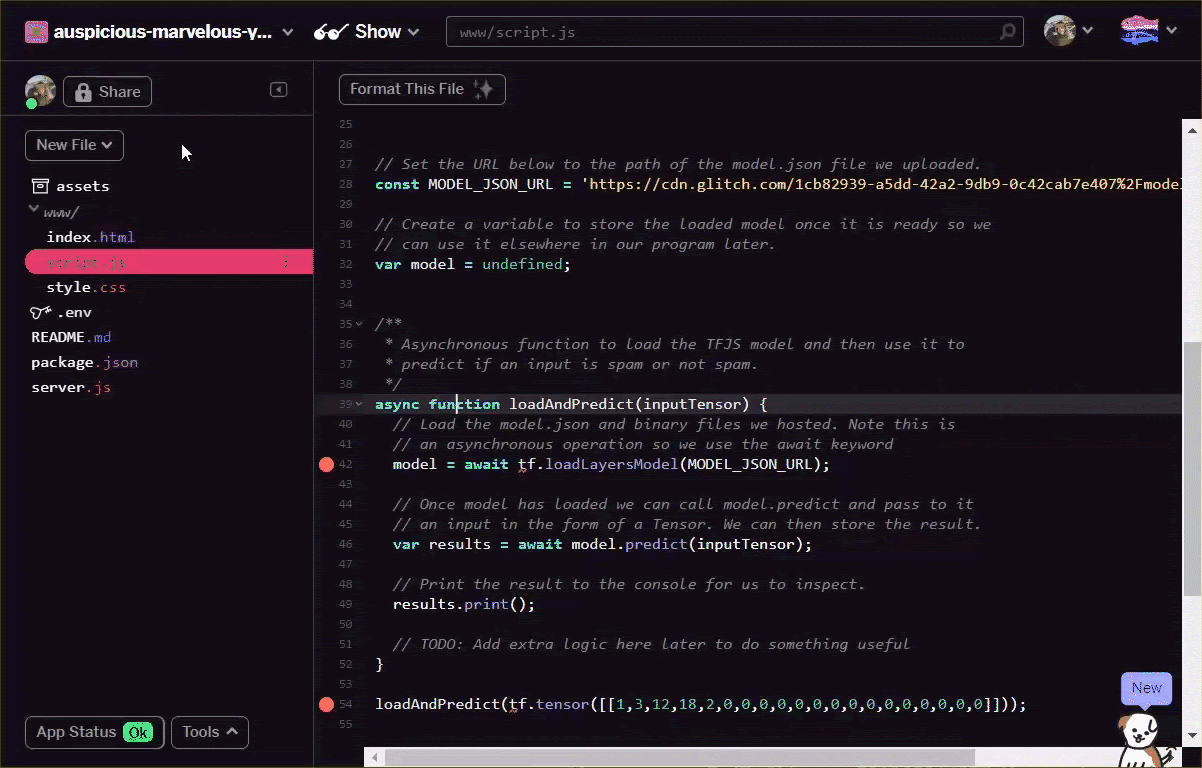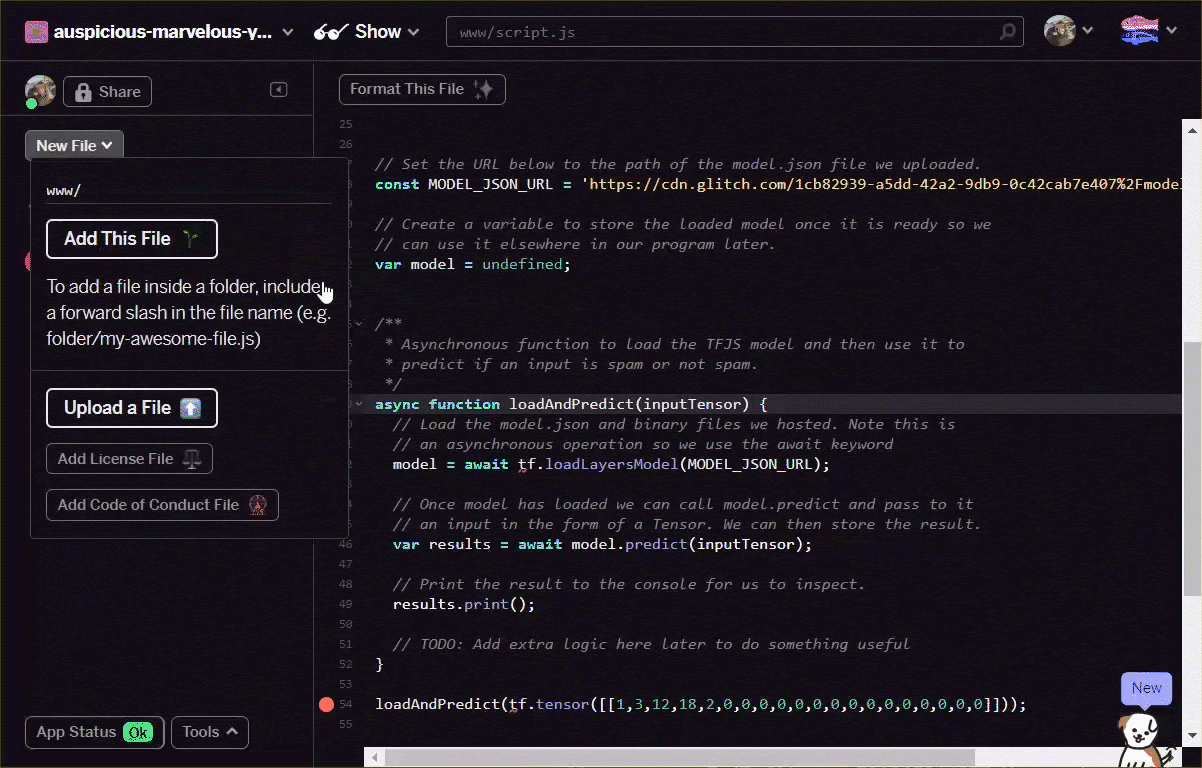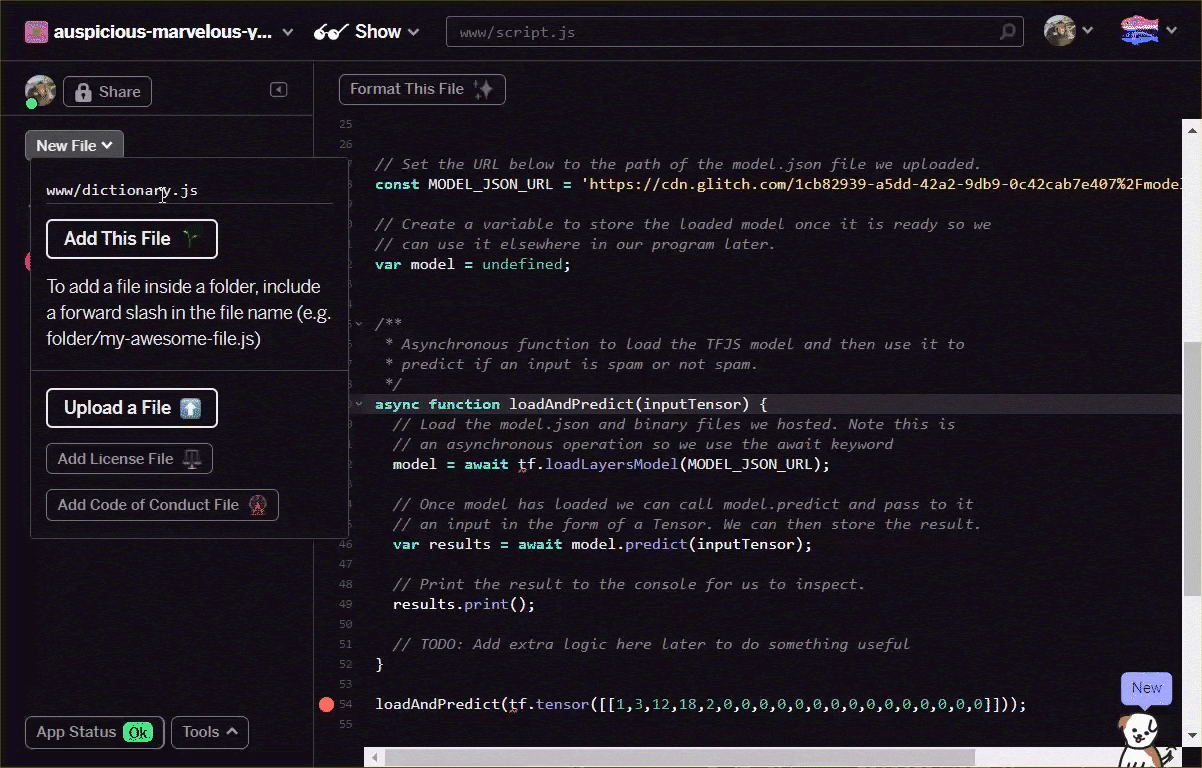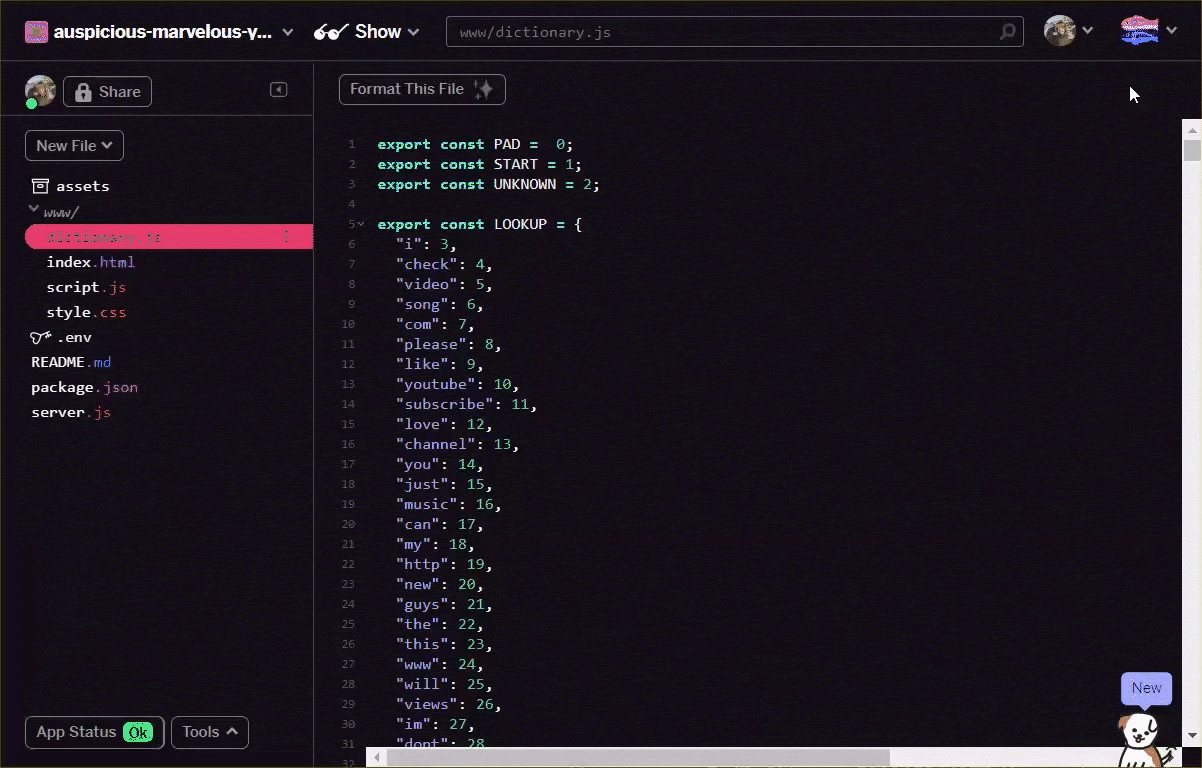
Когда у вас есть сохраненный dictionary.js Dictionary.js в формате, описанном выше, вы можете добавить следующий код в начало файла script.js , чтобы импортировать только что dictionary.js модуль Dictionary.js. Здесь вы также определяете дополнительную константу ENCODING_LENGTH , чтобы вы знали, сколько нужно добавить позже в коде, а также функцию tokenize , которую вы будете использовать для преобразования массива слов в подходящий тензор, который можно использовать в качестве входных данных для модели.
Посмотрите комментарии в приведенном ниже коде, чтобы узнать больше о том, что делает каждая строка:
script.js
import * as DICTIONARY from '/dictionary.js';
// The number of input elements the ML Model is expecting.
const ENCODING_LENGTH = 20;
/**
* Function that takes an array of words, converts words to tokens,
* and then returns a Tensor representation of the tokenization that
* can be used as input to the machine learning model.
*/
function tokenize(wordArray) {
// Always start with the START token.
let returnArray = [DICTIONARY.START];
// Loop through the words in the sentence you want to encode.
// If word is found in dictionary, add that number else
// you add the UNKNOWN token.
for (var i = 0; i < wordArray.length; i++) {
let encoding = DICTIONARY.LOOKUP[wordArray[i]];
returnArray.push(encoding === undefined ? DICTIONARY.UNKNOWN : encoding);
}
// Finally if the number of words was < the minimum encoding length
// minus 1 (due to the start token), fill the rest with PAD tokens.
while (i < ENCODING_LENGTH - 1) {
returnArray.push(DICTIONARY.PAD);
i++;
}
// Log the result to see what you made.
console.log([returnArray]);
// Convert to a TensorFlow Tensor and return that.
return tf.tensor([returnArray]);
}
Отлично, теперь вернитесь к функции handleCommentPost() и замените ее этой новой версией функции.
См. код для комментариев к тому, что вы добавили:
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
// Set styles to show processing in case it takes a long time.
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
// Grab the comment text from DOM.
let currentComment = COMMENT_TEXT.innerText;
// Convert sentence to lower case which ML Model expects
// Strip all characters that are not alphanumeric or spaces
// Then split on spaces to create a word array.
let lowercaseSentenceArray = currentComment.toLowerCase().replace(/[^\w\s]/g, ' ').split(' ');
// Create a list item DOM element in memory.
let li = document.createElement('li');
// Remember loadAndPredict is asynchronous so you use the then
// keyword to await a result before continuing.
loadAndPredict(tokenize(lowercaseSentenceArray), li).then(function() {
// Reset class styles ready for the next comment.
POST_COMMENT_BTN.classList.remove(PROCESSING_CLASS);
COMMENT_TEXT.classList.remove(PROCESSING_CLASS);
let p = document.createElement('p');
p.innerText = COMMENT_TEXT.innerText;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = currentUserName;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
let curDate = new Date();
spanDate.innerText = curDate.toLocaleString();
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
// Reset comment text.
COMMENT_TEXT.innerText = '';
});
}
}
Наконец, обновите loadAndPredict() , чтобы установить стиль, если комментарий определяется как спам.
For now you will simply change the style, but later you can choose to hold the comment in some sort of moderation queue or stop it from sending.
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
}
})
}
11. Real-time updates: Node.js + Websockets
Now you have a working frontend with spam detection, the final piece of the puzzle is to use Node.js with some websockets for real-time communication and update in real time any comments that are added that are not spam.
Socket.io
Socket.io is one of the most popular ways (at time of writing) to use websockets with Node.js. Go ahead and tell Glitch you want to include the Socket.io library in the build by editing package.json in the top level directory (in the parent folder of www folder) to include socket.io as one of the dependencies:
package. json
{
"name": "tfjs-with-backend",
"version": "0.0.1",
"description": "A TFJS front end with thin Node.js backend",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"dependencies": {
"express": "^4.17.1",
"socket.io": "^4.0.1"
},
"engines": {
"node": "12.x"
}
}
Great! Once updated, next update index.html within the www folder to include the socket.io library.
Simply place this line of code above the HTML script tag import for script.js near the end of the index.html file:
index.html
<script src="/socket.io/socket.io.js"></script>
You should now have 3 script tags in your index.html file:
- the first importing the TensorFlow.js library
- the 2nd importing socket.io that you just added
- and the last should be importing the script.js code.
Next, edit server.js to setup socket.io within node and create a simple backend to relay messages received to all connected clients.
See code comments below for an explanation of what the Node.js code is doing:
server.js
const http = require('http');
const express = require("express");
const app = express();
const server = http.createServer(app);
// Require socket.io and then make it use the http server above.
// This allows us to expose correct socket.io library JS for use
// in the client side JS.
var io = require('socket.io')(server);
// Serve all the files in 'www'.
app.use(express.static("www"));
// If no file specified in a request, default to index.html
app.get("/", (request, response) => {
response.sendFile(__dirname + "/www/index.html");
});
// Handle socket.io client connect event.
io.on('connect', socket => {
console.log('Client connected');
// If you wanted you could emit existing comments from some DB
// to client to render upon connect.
// socket.emit('storedComments', commentObjectArray);
// Listen for "comment" event from a connected client.
socket.on('comment', (data) => {
// Relay this comment data to all other connected clients
// upon receiving.
socket.broadcast.emit('remoteComment', data);
});
});
// Start the web server.
const listener = server.listen(process.env.PORT, () => {
console.log("Your app is listening on port " + listener.address().port);
});
Great! You now have a web server that is listening for socket.io events. Namely you have a comment event when a new comment comes in from a client, and the server emits remoteComment events which the client side code will listen for to know to render a remote comment. So the last thing to do is to add the socket.io logic to the client side code to emit and handle these events.
First, add the following code to the end of script.js to connect to the socket.io server and listen out / handle remoteComment events received:
script.js
// Connect to Socket.io on the Node.js backend.
var socket = io.connect();
function handleRemoteComments(data) {
// Render a new comment to DOM from a remote client.
let li = document.createElement('li');
let p = document.createElement('p');
p.innerText = data.comment;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = data.username;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
spanDate.innerText = data.timestamp;
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
}
// Add event listener to receive remote comments that passed
// spam check.
socket.on('remoteComment', handleRemoteComments);
Finally, add some code to the loadAndPredict function to emit a socket.io event if a comment is not spam. This allows you to update the other connected clients with this new comment as the content of this message will be relayed to them via the server.js code you wrote above.
Simply replace your existing loadAndPredict function with the following code that adds an else statement to the final spam check where if the comment is not spam, you call socket.emit() to send all the comment data:
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam. The 2nd parameter
* allows us to specify the DOM element list item you are currently
* classifying so you can change it+s style if it is spam!
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
} else {
// Emit socket.io comment event for server to handle containing
// all the comment data you would need to render the comment on
// a remote client's front end.
socket.emit('comment', {
username: currentUserName,
timestamp: domComment.querySelectorAll('span')[1].innerText,
comment: domComment.querySelectorAll('p')[0].innerText
});
}
})
}
Отличная работа! If you followed along correctly, you should now be able to open up 2 instances of your index.html page.
As you post comments that are not spam, you should see them rendered on the other client almost instantly. If the comment is spam, it simply will never be sent and instead be marked as spam on the frontend that generated it only like this:
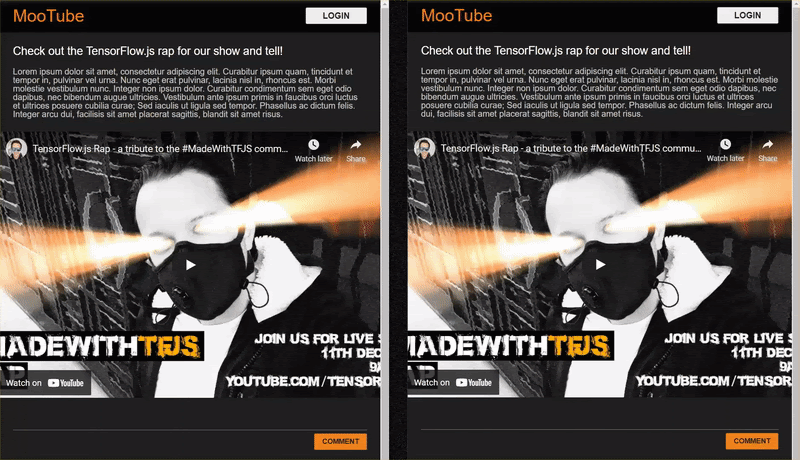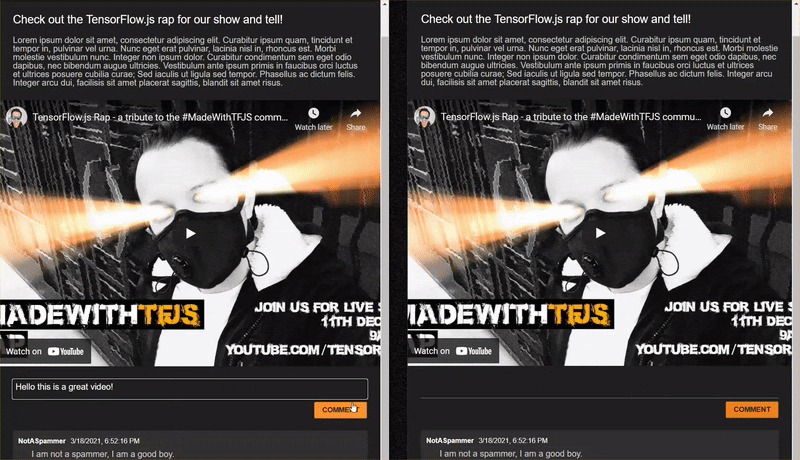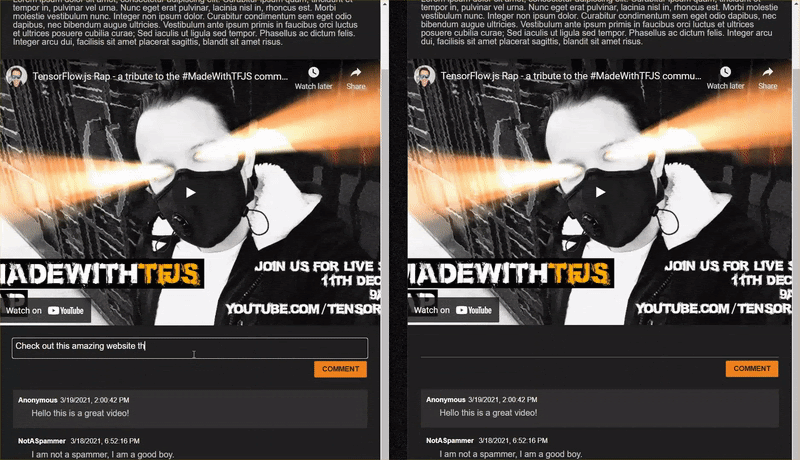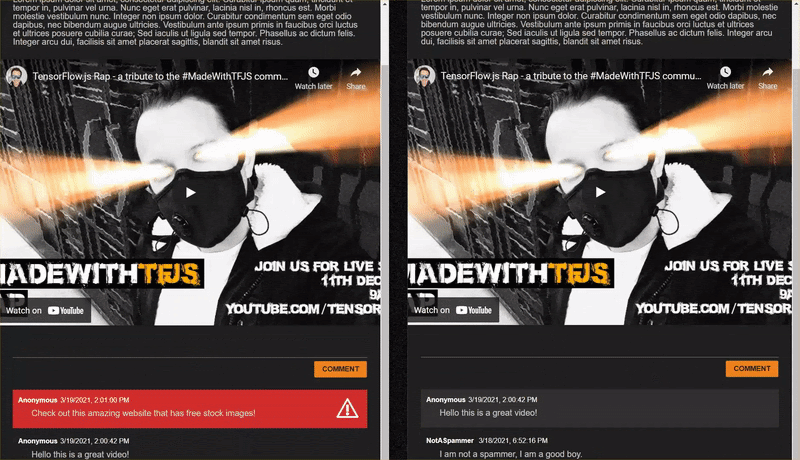
12. Поздравления
Congratulations, you have taken your first steps in using machine learning with TensorFlow.js in the web browser for a real world application - to detect comment spam!
Try it out, test it on a variety of comments, you may notice some things still get through. You will also notice that if you enter a sentence that is longer than 20 words, it will currently fail as the model expects 20 words as input.
In that case you may need to break long sentences into groups of 20 words and then take the spam likelihood of each sub sentence into consideration to determine if to show or not. We will leave this as an optional extra task for you to experiment with as there are many approaches you could take for this.
In the next codelab we will show you how to retrain this model with your custom comment data for edge cases it does not currently detect, or even to change the input expectation of the model so it can handle sentences that are larger than 20 words, and then export and use that model with TensorFlow.js.
If for some reason you are having issues, compare your code to this completed version available here , and check if you missed anything.
Резюме
In this codelab you:
- Learned what TensorFlow.js is and what models exist for natural language processing
- Created a fictitious website that allows real time comments for an example website.
- Loaded a pre-trained machine learning model suitable for comment spam detection via TensorFlow.js on the web page.
- Learned how to encode sentences for use with the loaded machine learning model and encapsulate that encoding inside a Tensor.
- Interpreted the output of the machine learning model to decide if you want to hold the comment for review, and if not, sent to the server to relay to other connected clients in real time.
What's next?
Now that you have a working base to start from, what creative ideas can you come up with to extend this machine learning model boilerplate for a real world use case you may be working on?
Share what you make with us
You can easily extend what you made today for other creative use cases too and we encourage you to think outside the box and keep hacking.
Remember to tag us on social media using the #MadeWithTFJS hashtag for a chance for your project to be featured on our TensorFlow blog or even future events . We would love to see what you make.
More TensorFlow.js codelabs to go deeper
- Check out part 2 of this series to learn how to retrain the comment spam model to account for edge cases that it does not currently detect as spam.
- Use Firebase hosting to deploy and host a TensorFlow.js model at scale.
- Make a smart webcam using a pre-made object detection model with TensorFlow.js
Websites to check out
- TensorFlow.js official website
- TensorFlow.js pre-made models
- TensorFlow.js API
- TensorFlow.js Show & Tell — get inspired and see what others have made.