
1. Introduction
Dans cet atelier de programmation, vous apprendrez à utiliser l'intégration Cloud SQL pour MySQL Vertex AI en combinant la recherche vectorielle avec les embeddings Vertex AI.

Prérequis
- Connaissances de base concernant la console Google Cloud
- Compétences de base concernant l'interface de ligne de commande et Cloud Shell
Points abordés
- Déployer une instance Cloud SQL pour PostgreSQL
- Créer une base de données et activer l'intégration de l'IA Cloud SQL
- Charger des données dans la base de données
- Utiliser Cloud SQL Studio
- Utiliser le modèle d'embedding Vertex AI dans Cloud SQL
- Utiliser Vertex AI Studio
- Enrichir les résultats à l'aide du modèle génératif Vertex AI
- Améliorer les performances à l'aide de l'index vectoriel
Prérequis
- Un compte Google Cloud et un projet Google Cloud
- Un navigateur Web tel que Chrome, compatible avec la console Google Cloud et Cloud Shell
2. Préparation
Configuration du projet
- Connectez-vous à la console Google Cloud. (Si vous ne possédez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.)
Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire.
- Créez un projet ou réutilisez-en un existant. Pour créer un projet dans la console Google Cloud, cliquez sur le bouton "Sélectionner un projet" dans l'en-tête pour ouvrir une fenêtre pop-up.

Dans la fenêtre "Sélectionner un projet", cliquez sur le bouton "Nouveau projet" pour ouvrir une boîte de dialogue pour le nouveau projet.
Dans la boîte de dialogue, saisissez le nom de projet de votre choix et sélectionnez l'emplacement.
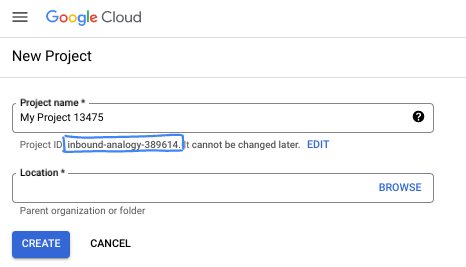
- Le nom du projet est le nom à afficher pour les participants au projet. Le nom de projet n'est utilisé par aucune API Google et peut être modifié à tout moment.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Google Cloud génère automatiquement un ID unique, mais vous pouvez le personnaliser. Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire ou en fournir un pour vérifier sa disponibilité. Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet, généralement identifié par l'espace réservé PROJECT_ID.
- Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
Activer la facturation
Pour activer la facturation, vous avez deux options. Vous pouvez utiliser votre compte de facturation personnel ou suivre les étapes ci-dessous pour utiliser des crédits.
Utiliser des crédits Google Cloud (facultatif)
Pour suivre cet atelier, vous avez besoin d'un compte de facturation avec un certain crédit. Utilisez les crédits de la bannière en haut de cet atelier de programmation pour commencer. Si vous êtes déjà associé à un compte de facturation, vous pouvez ignorer cette étape.
Configurer un compte de facturation personnel
Si vous configurez la facturation à l'aide de crédits Google Cloud, vous pouvez ignorer cette étape.
Pour configurer un compte de facturation personnel, cliquez ici pour activer la facturation dans la console Cloud.
Remarques :
- Cet atelier devrait vous coûter moins de 3 USD en ressources Cloud.
- Vous pouvez suivre les étapes à la fin de cet atelier pour supprimer les ressources et éviter ainsi des frais supplémentaires.
- Les nouveaux utilisateurs peuvent bénéficier d'un essai sans frais pour un crédit de 300 $.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :
Vous pouvez également appuyer sur G, puis sur S. Cette séquence activera Cloud Shell si vous êtes dans la console Google Cloud ou si vous utilisez ce lien.
Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
3. Avant de commencer
Activer l'API
Pour utiliser Cloud SQL, Compute Engine, les services réseau et Vertex AI, vous devez activer leurs API respectives dans votre projet Google Cloud.
Dans le terminal Cloud Shell, assurez-vous que l'ID de votre projet est configuré :
gcloud config set project [YOUR-PROJECT-ID]
Définissez la variable d'environnement PROJECT_ID :
PROJECT_ID=$(gcloud config get-value project)
Activez tous les services nécessaires :
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Résultat attendu
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Présentation des API
- L'API Cloud SQL Admin (
sqladmin.googleapis.com) vous permet de créer, de configurer et de gérer des instances Cloud SQL de manière programmatique. Il fournit le plan de contrôle du service de base de données relationnelle entièrement géré de Google (compatible avec MySQL, PostgreSQL et SQL Server), qui gère des tâches telles que le provisionnement, les sauvegardes, la haute disponibilité et le scaling. - L'API Compute Engine (
compute.googleapis.com) vous permet de créer et de gérer des machines virtuelles (VM), des disques persistants et des paramètres réseau. Elle fournit les bases IaaS (Infrastructure as a Service) nécessaires pour exécuter vos charges de travail et héberger l'infrastructure sous-jacente de nombreux services gérés. - L'API Cloud Resource Manager (
cloudresourcemanager.googleapis.com) vous permet de gérer de façon programmatique les métadonnées et la configuration de votre projet Google Cloud. Il vous permet d'organiser les ressources, de gérer les stratégies IAM (Identity and Access Management) et de valider les autorisations dans la hiérarchie des projets. - L'API Service Networking (
servicenetworking.googleapis.com) vous permet d'automatiser la configuration de la connectivité privée entre votre réseau Virtual Private Cloud (VPC) et les services gérés de Google. Il est spécifiquement requis pour établir un accès par adresse IP privée pour des services tels qu'AlloyDB, afin qu'ils puissent communiquer de manière sécurisée avec vos autres ressources. - L'API Vertex AI (
aiplatform.googleapis.com) permet à vos applications de créer, de déployer et de mettre à l'échelle des modèles de machine learning. Elle fournit une interface unifiée pour tous les services d'IA de Google Cloud, y compris l'accès aux modèles d'IA générative (comme Gemini) et l'entraînement de modèles personnalisés.
4. Créer une instance Cloud SQL
Créez une instance Cloud SQL avec l'intégration de la base de données à Vertex AI.
Créer un mot de passe pour la base de données
Définissez le mot de passe de l'utilisateur de base de données par défaut. Vous pouvez définir votre propre mot de passe ou utiliser une fonction aléatoire pour en générer un :
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
Notez la valeur générée pour le mot de passe :
echo $CLOUDSQL_PASSWORD
Créer une instance Cloud SQL pour MySQL
L'indicateur cloudsql_vector peut être activé lors de la création d'une instance. La prise en charge des vecteurs est actuellement disponible pour MySQL 8.0 R20241208.01_00 ou version ultérieure.
Dans la session Cloud Shell, exécutez :
gcloud sql instances create my-cloudsql-instance \
--database-version=MYSQL_8_4 \
--tier=db-custom-2-8192 \
--region=us-central1 \
--enable-google-ml-integration \
--edition=ENTERPRISE \
--root-password=$CLOUDSQL_PASSWORD
Nous pouvons vérifier notre connexion en exécutant la commande depuis Cloud Shell.
gcloud sql connect my-cloudsql-instance --user=root
Exécutez la commande et saisissez votre mot de passe dans l'invite lorsqu'il est prêt à se connecter.
Résultat attendu :
$gcloud sql connect my-cloudsql-instance --user=root Allowlisting your IP for incoming connection for 5 minutes...done. Connecting to database with SQL user [root].Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 71 Server version: 8.4.4-google (Google) Copyright (c) 2000, 2025, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
Quittez la session MySQL pour le moment en utilisant le raccourci clavier Ctrl+d ou en exécutant la commande exit.
exit
Activer l'intégration à Vertex AI
Accordez les droits d'accès nécessaires au compte de service Cloud SQL interne pour pouvoir utiliser l'intégration Vertex AI.
Recherchez l'adresse e-mail du compte de service interne Cloud SQL et exportez-la en tant que variable.
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
Accordez l'accès à Vertex AI au compte de service Cloud SQL :
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Pour en savoir plus sur la création et la configuration d'instances, consultez la documentation Cloud SQL ici.
5. Préparer la base de données
Nous devons maintenant créer une base de données et activer la prise en charge des vecteurs.
Créer une base de données
Créez une base de données nommée quickstart_db .Pour ce faire, vous disposez de différentes options, comme les clients de base de données en ligne de commande (mysql pour MySQL, par exemple), le SDK ou Cloud SQL Studio. Nous utiliserons le SDK (gcloud) pour créer la base de données.
Dans Cloud Shell, exécutez la commande pour créer la base de données.
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
6. Charger des données
Nous devons maintenant créer des objets dans la base de données et charger des données. Nous allons utiliser des données fictives de Cymbal Store. Les données sont disponibles aux formats SQL (pour le schéma) et CSV (pour les données).
Cloud Shell sera notre environnement principal pour nous connecter à une base de données, créer tous les objets et charger les données.
Nous devons d'abord ajouter l'adresse IP publique de notre Cloud Shell à la liste des réseaux autorisés pour notre instance Cloud SQL. Dans Cloud Shell, exécutez :
gcloud sql instances patch my-cloudsql-instance --authorized-networks=$(curl ifconfig.me)
Si votre session a été perdue ou réinitialisée, ou si vous travaillez à partir d'un autre outil, exportez à nouveau votre variable CLOUDSQL_PASSWORD :
export CLOUDSQL_PASSWORD=...your password defined for the instance...
Nous pouvons maintenant créer tous les objets requis dans notre base de données. Pour ce faire, nous allons utiliser l'utilitaire MySQL mysql en combinaison avec l'utilitaire curl, qui récupère les données à partir de la source publique.
Dans Cloud Shell, exécutez :
export INSTANCE_IP=$(gcloud sql instances describe my-cloudsql-instance --format="value(ipAddresses.ipAddress)")
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_mysql_schema.sql | mysql --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db
Qu'avons-nous fait exactement dans la commande précédente ? Nous nous sommes connectés à notre base de données et avons exécuté le code SQL téléchargé, ce qui a créé des tables, des index et des séquences.
L'étape suivante consiste à charger les données cymbal_products. Nous utilisons les mêmes utilitaires curl et mysql.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_products.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_products FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
Nous continuons ensuite avec cymbal_stores.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_stores.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_stores FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
et cymbal_inventory, qui indique le nombre de chaque produit dans chaque magasin.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_inventory.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_inventory FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
Si vous disposez de vos propres exemples de données et de fichiers CSV compatibles avec l'outil d'importation Cloud SQL disponible dans la console Cloud, vous pouvez les utiliser à la place de l'approche présentée.
7. Créer des embeddings
L'étape suivante consiste à créer des embeddings pour nos descriptions de produits à l'aide du modèle textembedding-005 de Google Vertex AI et à les stocker dans la nouvelle colonne du tableau cymbal_products.
Pour stocker les données vectorielles, nous devons activer la fonctionnalité vectorielle dans notre instance Cloud SQL. Exécutez la commande suivante dans Cloud Shell :
gcloud sql instances patch my-cloudsql-instance \
--database-flags=cloudsql_vector=on
Connectez-vous à la base de données :
mysql --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db
Créez une colonne embedding dans la table cymbal_products à l'aide de la fonction d'embedding. Cette nouvelle colonne contiendra les embeddings vectoriels basés sur le texte de la colonne product_description.
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) using varbinary;
UPDATE cymbal_products SET embedding = mysql.ml_embedding('text-embedding-005', product_description);
La génération d'embeddings vectoriels pour 2 000 lignes prend généralement moins de cinq minutes, mais peut parfois prendre un peu plus de temps et se termine souvent beaucoup plus rapidement.
8. Exécuter une recherche de similarités
Nous pouvons maintenant exécuter notre recherche à l'aide de la recherche par similarité basée sur les valeurs vectorielles calculées pour les descriptions et la valeur vectorielle que nous générons pour notre requête à l'aide du même modèle d'embedding.
La requête SQL peut être exécutée à partir de la même interface de ligne de commande ou, en alternative, à partir de Cloud SQL Studio. Il est préférable de gérer les requêtes complexes et comportant plusieurs lignes dans Cloud SQL Studio.
Créer un utilisateur
Nous avons besoin d'un nouvel utilisateur qui peut utiliser Cloud SQL Studio. Nous allons créer un élève utilisateur de type intégré avec le même mot de passe que celui utilisé pour l'utilisateur racine.
Dans Cloud Shell, exécutez :
gcloud sql users create student --instance=my-cloudsql-instance --password=$CLOUDSQL_PASSWORD --host=%
Démarrer Cloud SQL Studio
Dans la console, cliquez sur l'instance Cloud SQL que nous avons créée précédemment.
Lorsque le panneau de droite est ouvert, Cloud SQL Studio s'affiche. Cliquez dessus.
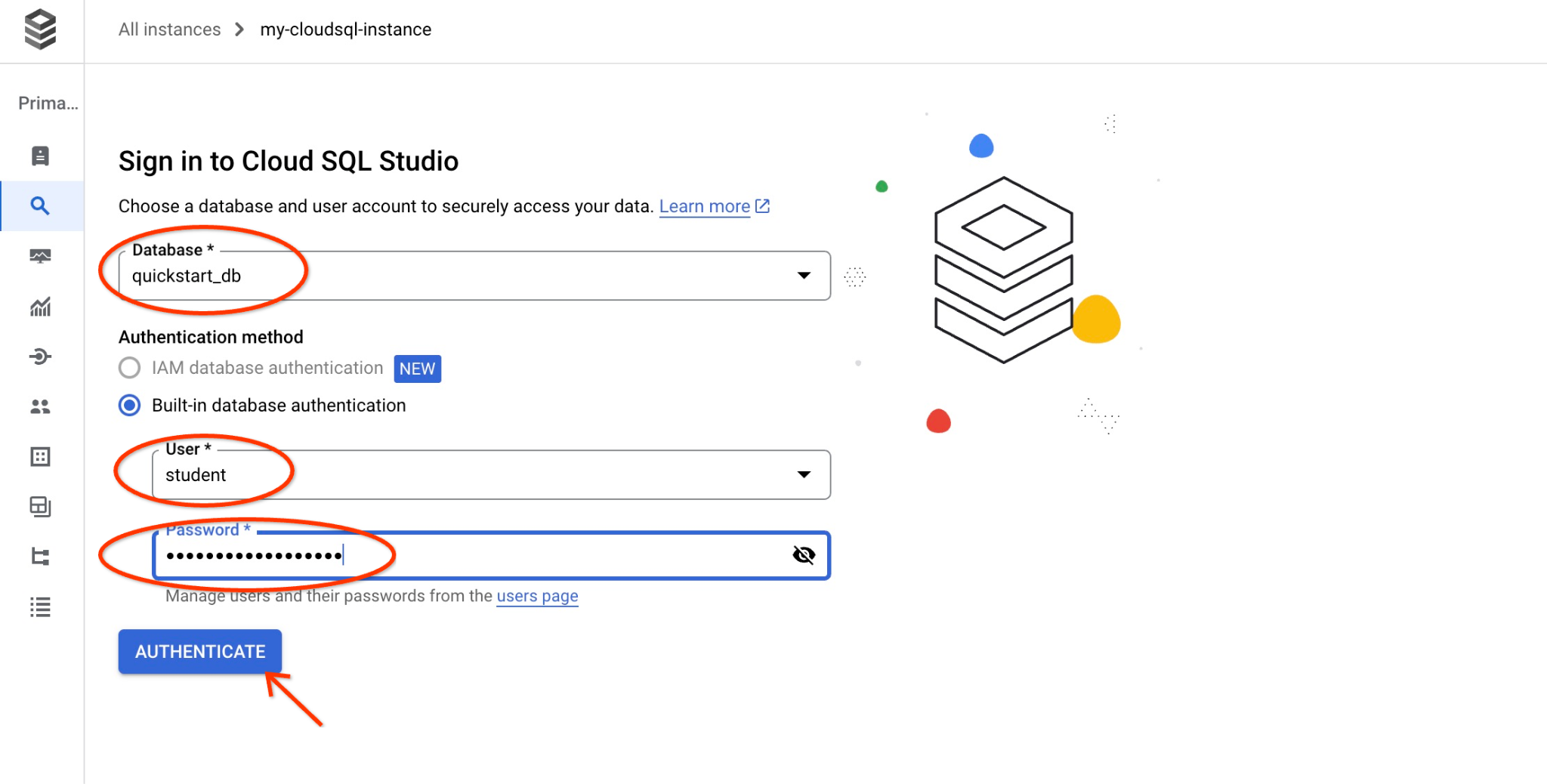
Une boîte de dialogue s'ouvre, dans laquelle vous devez indiquer le nom de la base de données et vos identifiants :
- Base de données : quickstart_db
- Utilisateur : student
- Mot de passe : le mot de passe que vous avez noté pour l'utilisateur
Cliquez ensuite sur le bouton "AUTHENTICATE" (AUTHENTIFIER).
La fenêtre suivante s'ouvre. Cliquez sur l'onglet "Editor" (Éditeur) sur la droite pour ouvrir l'éditeur SQL.
Nous sommes maintenant prêts à exécuter nos requêtes.
Exécuter la requête
Exécutez une requête pour obtenir la liste des produits disponibles qui correspondent le mieux à la demande d'un client. La requête que nous allons transmettre à Vertex AI pour obtenir la valeur vectorielle ressemble à "Quels types d'arbres fruitiers poussent bien ici ?"
Exécuter une requête avec cosine_distance pour la recherche vectorielle KNN (exacte)
Voici la requête que vous pouvez exécuter pour choisir les cinq premiers éléments les plus adaptés à notre demande à l'aide de la fonction cosine_distance :
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cosine_distance(cp.embedding ,@query_vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Copiez et collez la requête dans l'éditeur Cloud SQL Studio, puis cliquez sur le bouton "EXÉCUTER". Vous pouvez également la coller dans votre session de ligne de commande connectée à la base de données quickstart_db.
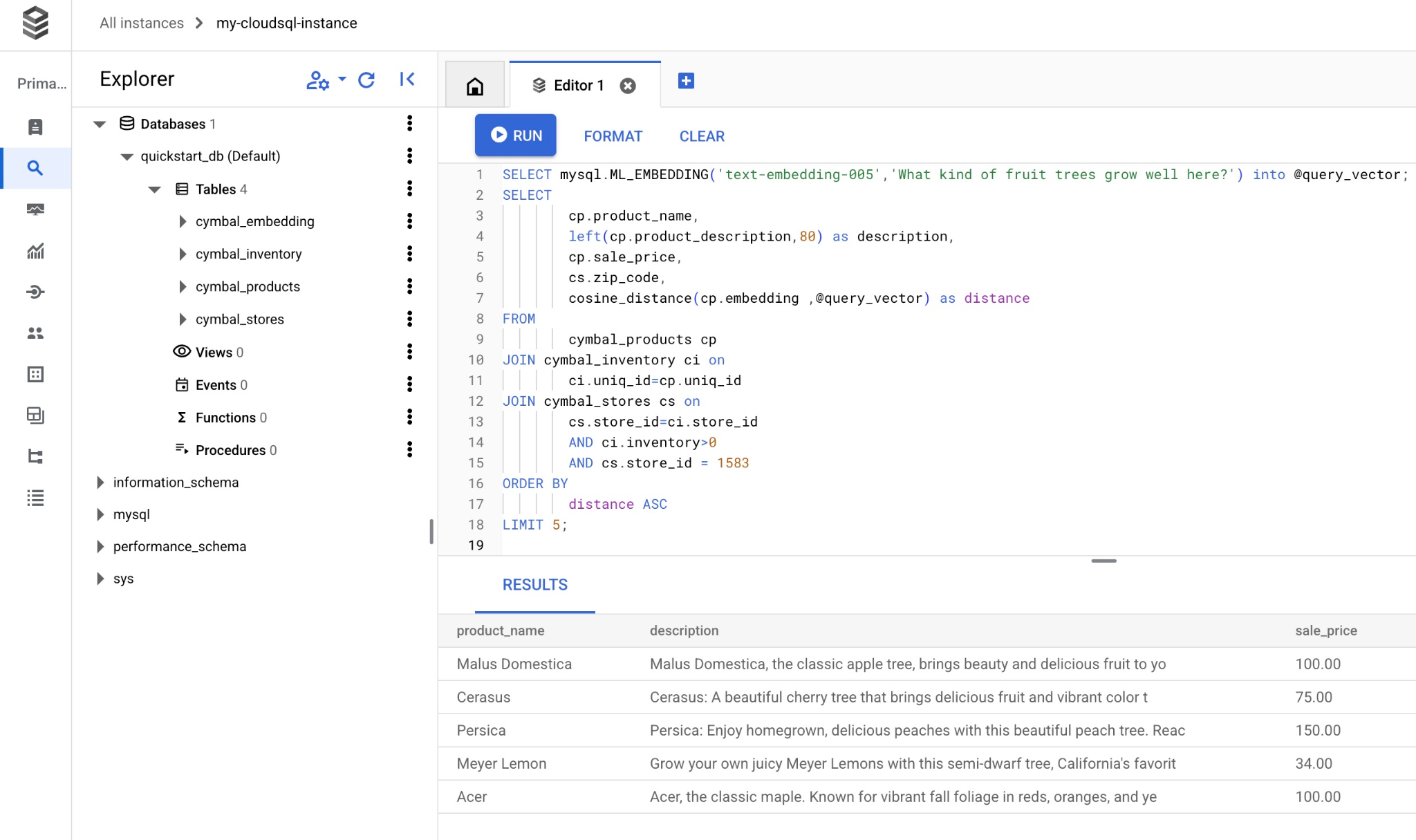
Voici une liste de produits sélectionnés correspondant à la requête.
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| product_name | description | sale_price | zip_code | distance |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 |
| Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 |
| Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 |
| Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 |
| Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
5 rows in set (0.13 sec)
L'exécution de la requête a pris 0,13 s avec la fonction cosine_distance.
Exécuter une requête avec approx_distance pour la recherche vectorielle KNN (exacte)
Nous exécutons maintenant la même requête, mais en utilisant la recherche KNN avec la fonction approx_distance. Si nous ne disposons pas d'index ANN pour nos embeddings, nous revenons automatiquement à la recherche exacte en coulisses :
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Voici une liste de produits renvoyés par la requête.
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| product_name | description | sale_price | zip_code | distance |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 |
| Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 |
| Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 |
| Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 |
| Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
5 rows in set, 1 warning (0.12 sec)
L'exécution de la requête n'a pris que 0,12 seconde. Nous avons obtenu les mêmes résultats que pour la fonction cosine_distance.
9. Améliorer la réponse du LLM à l'aide des données récupérées
Nous pouvons améliorer la réponse du LLM d'IA générative à une application cliente en utilisant le résultat de la requête exécutée et en préparant une sortie pertinente à l'aide des résultats de requête fournis dans le cadre du prompt à un modèle de langage de fondation génératif Vertex AI.
Pour ce faire, nous devons générer un fichier JSON avec les résultats de notre recherche vectorielle, puis utiliser ce fichier JSON généré en plus d'un prompt pour un modèle LLM dans Vertex AI afin de créer un résultat pertinent. Dans la première étape, nous générons le JSON, puis nous le testons dans Vertex AI Studio. Dans la dernière étape, nous l'intégrons à une instruction SQL qui peut être utilisée dans une application.
Générer la sortie au format JSON
Modifiez la requête pour générer la sortie au format JSON et ne renvoyer qu'une seule ligne à transmettre à Vertex AI.
Voici un exemple de requête utilisant la recherche ANN :
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine')) ASC
LIMIT 1)
SELECT json_arrayagg(json_object('product_name',product_name,'description',description,'sale_price',sale_price,'zip_code',zip_code,'product_id',product_id)) FROM trees;
Voici le JSON attendu dans le résultat :
[{"zip_code": 93230, "product_id": "23e41a71d63d8bbc9bdfa1d118cfddc5", "sale_price": 100.00, "description": "Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo", "product_name": "Malus Domestica"}]
Exécuter le prompt dans Vertex AI Studio
Nous pouvons utiliser le fichier JSON généré pour l'inclure dans le prompt du modèle de texte d'IA générative dans Vertex AI Studio.
Ouvrez l'invite Vertex AI Studio dans la console cloud.
Il peut vous demander d'activer d'autres API, mais vous pouvez ignorer la demande. Nous n'avons besoin d'aucune API supplémentaire pour terminer notre atelier.
Saisissez une requête dans Studio.
Voici le prompt que nous allons utiliser :
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
Voici à quoi cela ressemble lorsque nous remplaçons l'espace réservé JSON par la réponse à la requête :
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
{"zip_code": 93230, "product_id": "23e41a71d63d8bbc9bdfa1d118cfddc5", "sale_price": 100.00, "description": "Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo", "product_name": "Malus Domestica"}
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
Voici le résultat lorsque nous exécutons la requête avec nos valeurs JSON et en utilisant le modèle gemini-2.5-flash :
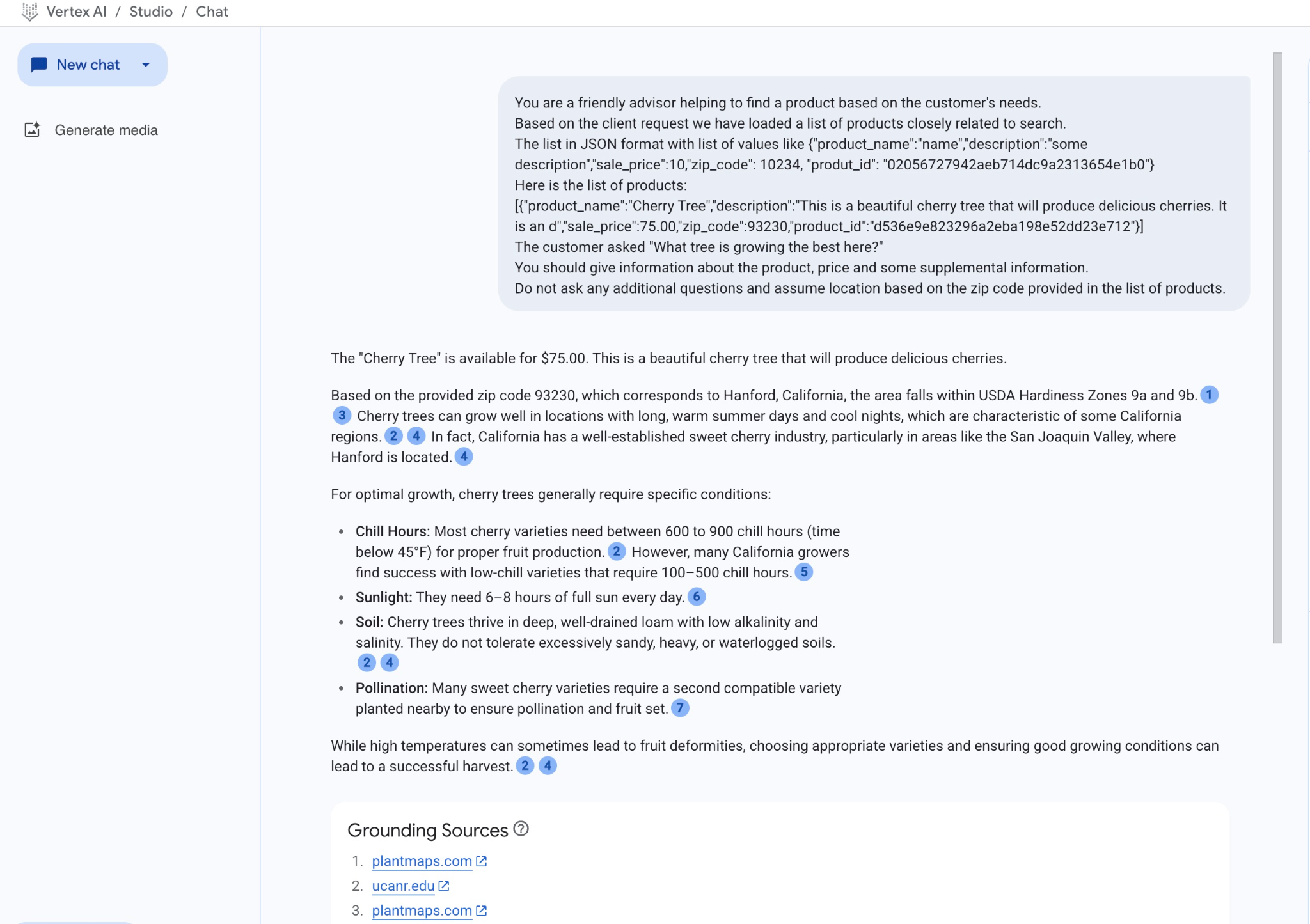
La réponse que nous avons obtenue du modèle dans cet exemple utilise les résultats de la recherche sémantique et le produit le plus adapté disponible dans le code postal mentionné.
Exécuter la requête en SQL
Nous pouvons également utiliser l'intégration de l'IA Cloud SQL à Vertex AI pour obtenir une réponse similaire à partir d'un modèle génératif à l'aide de SQL directement dans la base de données.
Nous pouvons maintenant utiliser les résultats JSON générés dans une sous-requête pour les fournir dans le prompt au modèle de texte d'IA générative à l'aide de SQL.
Dans la session MySQL ou Cloud SQL Studio de la base de données, exécutez la requête.
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine')) ASC
LIMIT 1),
prompt AS (
SELECT
CONCAT( 'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:', json_arrayagg(json_object('product_name',trees.product_name,'description',trees.description,'sale_price',trees.sale_price,'zip_code',trees.zip_code,'product_id',trees.product_id)) , 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information') AS prompt_text
FROM
trees),
response AS (
SELECT
mysql.ML_PREDICT_ROW('publishers/google/models/gemini-2.0-flash-001:generateContent',
json_object('contents',
json_object('role',
'user',
'parts',
json_array(
json_object('text',
prompt_text))))) AS resp
FROM
prompt)
SELECT
JSON_EXTRACT(resp, '$.candidates[0].content.parts[0].text')
FROM
response;
Voici un exemple de résultat. Votre résultat peut être différent selon la version et les paramètres du modèle :
"Okay, I see you're looking for fruit trees that grow well in your area. Based on the available product, the **Malus Domestica** (Apple Tree) is a great option to consider!\n\n* **Product:** Malus Domestica (Apple Tree)\n* **Description:** This classic apple tree grows to about 30 feet tall and provides beautiful seasonal color with green leaves in summer and fiery colors in the fall. It's known for its strength and provides good shade. Most importantly, it produces delicious apples!\n* **Price:** \\$100.00\n* **Growing Zones:** This particular apple tree is well-suited for USDA zones 4-8. Since your zip code is 93230, you are likely in USDA zone 9a or 9b. While this specific tree is rated for zones 4-8, with proper care and variety selection, apple trees can still thrive in slightly warmer climates. You may need to provide extra care during heat waves.\n\n**Recommendation:** I would recommend investigating varieties of Malus Domestica suited to slightly warmer climates or contacting a local nursery/arborist to verify if it is a good fit for your local climate conditions.\n"
Le résultat est fourni au format Markdown.
10. Créer un index des plus proches voisins
Notre ensemble de données est relativement petit et le temps de réponse dépend principalement des interactions avec les modèles d'IA. Toutefois, lorsque vous avez des millions de vecteurs, la recherche vectorielle peut prendre une part importante de notre temps de réponse et exercer une forte charge sur le système. Pour améliorer cela, nous pouvons créer un index sur nos vecteurs.
Créer un index ScaNN
Nous allons essayer le type d'index ScaNN pour notre test.
Pour créer l'index de notre colonne d'intégration, nous devons définir notre mesure de distance pour la colonne d'intégration. Pour en savoir plus sur les paramètres, consultez la documentation.
CREATE VECTOR INDEX cymbal_products_embedding_idx ON cymbal_products(embedding) USING SCANN DISTANCE_MEASURE=COSINE;
Comparer la réponse
Nous pouvons maintenant exécuter à nouveau la requête de recherche vectorielle et voir les résultats.
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Résultat attendu :
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ | product_name | description | sale_price | zip_code | distance | +-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ | Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 | | Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 | | Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 | | Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 | | Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 | +-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ 5 rows in set (0.08 sec)
Nous pouvons constater que le temps d'exécution n'a que légèrement changé, ce qui est normal pour un ensemble de données aussi petit. Cela devrait être beaucoup plus visible pour les grands ensembles de données comportant des millions de vecteurs.
Nous pouvons examiner le plan d'exécution à l'aide de la commande EXPLAIN :
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
EXPLAIN ANALYZE SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Plan d'exécution (extrait) :
...
-> Nested loop inner join (cost=443 rows=5) (actual time=1.14..1.18 rows=5 loops=1)
-> Vector index scan on cp (cost=441 rows=5) (actual time=1.1..1.1 rows=5 loops=1)
-> Single-row index lookup on cp using PRIMARY (uniq_id=cp.uniq_id) (cost=0.25 rows=1) (actual time=0.0152..0.0152 rows=1 loops=5)
...
Nous pouvons voir qu'il utilisait l'analyse d'index vectoriel sur cp (alias de la table cymbal_products).
Vous pouvez tester différentes requêtes de recherche pour voir comment fonctionne la recherche sémantique dans MySQL.
11. Nettoyer l'environnement
Supprimez l'instance Cloud SQL.
Supprimez l'instance Cloud SQL lorsque vous avez terminé l'atelier.
Dans Cloud Shell, définissez le projet et les variables d'environnement si vous avez été déconnecté et que tous les paramètres précédents sont perdus :
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
Supprimez l'instance :
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
Résultat attendu sur la console :
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
12. Félicitations
Bravo ! Vous avez terminé cet atelier de programmation.
Parcours de formation Google Cloud
Cet atelier fait partie du parcours de formation "L'IA prête pour la production avec Google Cloud".
- Explorez le programme complet pour combler le fossé entre le prototype et la production.
- Partagez votre progression avec le hashtag
#ProductionReadyAI.
Points abordés
- Déployer une instance Cloud SQL pour PostgreSQL
- Créer une base de données et activer l'intégration de l'IA Cloud SQL
- Charger des données dans la base de données
- Utiliser Cloud SQL Studio
- Utiliser le modèle d'embedding Vertex AI dans Cloud SQL
- Utiliser Vertex AI Studio
- Enrichir les résultats à l'aide du modèle génératif Vertex AI
- Améliorer les performances à l'aide de l'index vectoriel
Essayez un atelier de programmation similaire pour AlloyDB ou un atelier de programmation pour Cloud SQL pour PostgreSQL.
13. Enquête
Résultat :