
1. はじめに
この Codelab では、ベクトル検索と Vertex AI エンベディングを組み合わせて Cloud SQL for MySQL Vertex AI 統合を使用する方法を学びます。

前提条件
- Google Cloud とコンソールの基本的な知識
- コマンドライン インターフェースと Cloud Shell の基本的なスキル
学習内容
- PostgreSQL 用 Cloud SQL インスタンスをデプロイする方法
- データベースを作成して Cloud SQL AI 統合を有効にする方法
- データベースにデータを読み込む方法
- Cloud SQL Studio の使用方法
- Cloud SQL で Vertex AI エンベディング モデルを使用する方法
- Vertex AI Studio の使用方法
- Vertex AI 生成モデルを使用して結果を拡充する方法
- ベクトル インデックスを使用してパフォーマンスを改善する方法
必要なもの
- Google Cloud アカウントと Google Cloud プロジェクト
- Google Cloud コンソールと Cloud Shell をサポートするウェブブラウザ(Chrome など)
2. 設定と要件
プロジェクトのセットアップ
- Google Cloud コンソールにログインします。Gmail アカウントも Google Workspace アカウントもまだお持ちでない場合は、アカウントを作成してください。
仕事用または学校用アカウントではなく、個人用アカウントを使用します。
- 新しいプロジェクトを作成するか、既存のプロジェクトを再利用します。Google Cloud コンソールで新しいプロジェクトを作成するには、ヘッダーで [プロジェクトを選択] ボタンをクリックします。ポップアップ ウィンドウが開きます。

[プロジェクトを選択] ウィンドウで [新しいプロジェクト] ボタンを押すと、新しいプロジェクトのダイアログ ボックスが開きます。
ダイアログ ボックスで、任意のプロジェクト名を入力し、ロケーションを選択します。
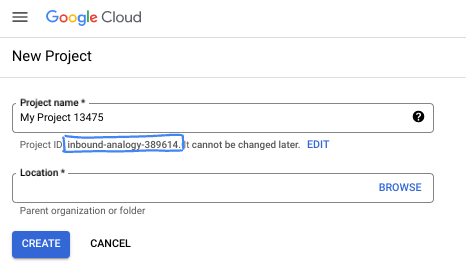
- プロジェクト名は、このプロジェクトの参加者に表示される名称です。プロジェクト名は Google API では使用されず、いつでも変更できます。
- プロジェクト ID は、すべての Google Cloud プロジェクトにおいて一意でなければならず、不変です(設定後は変更できません)。Google Cloud コンソールでは一意の ID が自動的に生成されますが、カスタマイズすることもできます。生成された ID が気に入らない場合は、別のランダムな ID を生成するか、独自の ID を指定してその可用性を確認できます。ほとんどの Codelab では、プロジェクト ID を参照する必要があります。通常、プロジェクト ID はプレースホルダ PROJECT_ID で識別されます。
- なお、3 つ目の値として、一部の API が使用するプロジェクト番号があります。これら 3 つの値について詳しくは、こちらのドキュメントをご覧ください。
課金を有効にする
課金を有効にするには、次の 2 つの方法があります。個人用の請求先アカウントを使用するか、次の手順でクレジットを利用できます。
Google Cloud クレジットを利用する(省略可)
このワークショップを実施するには、クレジットが設定された請求先アカウントが必要です。この Codelab の上部にあるバナーのクレジットを使用して、開始します。請求先アカウントにすでに接続している場合は、この手順をスキップできます。
個人用の請求先アカウントを設定する
Google Cloud クレジットを使用して課金を設定した場合は、この手順をスキップできます。
個人用の請求先アカウントを設定するには、Cloud コンソールでこちらに移動して課金を有効にします。
注意事項:
- このラボを完了するのにかかる Cloud リソースの費用は 3 米ドル未満です。
- このラボの最後の手順に沿ってリソースを削除すると、それ以上の料金は発生しません。
- 新規ユーザーは、300 米ドル分の無料トライアルをご利用いただけます。
Cloud Shell の起動
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Google Cloud コンソールで、右上のツールバーにある Cloud Shell アイコンをクリックします。
または、G キーを押してから S キーを押します。このシーケンスは、Google Cloud コンソール内からアクセスした場合、またはこのリンクを使用した場合に Cloud Shell をアクティブにします。
プロビジョニングと環境への接続にはそれほど時間はかかりません。完了すると、次のように表示されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。永続的なホーム ディレクトリが 5 GB 用意されており、Google Cloud で稼働します。そのため、ネットワークのパフォーマンスと認証機能が大幅に向上しています。この Codelab での作業はすべて、ブラウザ内から実行できます。インストールは不要です。
3. はじめに
API を有効にする
Cloud SQL、Compute Engine、ネットワーキング サービス、Vertex AI を使用するには、Google Cloud プロジェクトでそれぞれの API を有効にする必要があります。
Cloud Shell ターミナルで、プロジェクト ID が設定されていることを確認します。
gcloud config set project [YOUR-PROJECT-ID]
環境変数 PROJECT_ID を設定します。
PROJECT_ID=$(gcloud config get-value project)
必要なサービスをすべて有効にします。
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
想定される出力
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
API の概要
- Cloud SQL Admin API(
sqladmin.googleapis.com)を使用すると、Cloud SQL インスタンスをプログラムで作成、構成、管理できます。Google のフルマネージド リレーショナル データベース サービス(MySQL、PostgreSQL、SQL Server をサポート)のコントロール プレーンを提供し、プロビジョニング、バックアップ、高可用性、スケーリングなどのタスクを処理します。 - Compute Engine API(
compute.googleapis.com)を使用すると、仮想マシン(VM)、永続ディスク、ネットワーク設定を作成して管理できます。これは、ワークロードの実行と、多くのマネージド サービスの基盤となるインフラストラクチャのホストに必要な、Infrastructure-as-a-Service(IaaS)の基盤となるものです。 - Cloud Resource Manager API(
cloudresourcemanager.googleapis.com)を使用すると、Google Cloud プロジェクトのメタデータと構成をプログラムで管理できます。これにより、リソースの整理、Identity and Access Management(IAM)ポリシーの処理、プロジェクト階層全体での権限の検証が可能になります。 - Service Networking API(
servicenetworking.googleapis.com)を使用すると、Virtual Private Cloud(VPC)ネットワークと Google のマネージド サービス間のプライベート接続の設定を自動化できます。AlloyDB などのサービスが他のリソースと安全に通信できるように、プライベート IP アクセスを確立するために必要です。 - Vertex AI API(
aiplatform.googleapis.com)を使用すると、アプリケーションで ML モデルを構築、デプロイ、スケーリングできます。このサービスは、生成 AI モデル(Gemini など)へのアクセスやカスタムモデルのトレーニングなど、Google Cloud のすべての AI サービスに統合インターフェースを提供します。
4. Cloud SQL インスタンスを作成する
Vertex AI とのデータベース統合を使用して Cloud SQL インスタンスを作成します。
データベース パスワードを作成する
デフォルトのデータベース ユーザーのパスワードを定義します。独自のパスワードを定義することも、ランダム関数を使用してパスワードを生成することもできます。
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
生成されたパスワードの値をメモします。
echo $CLOUDSQL_PASSWORD
Cloud SQL for MySQL インスタンスを作成する
cloudsql_vector フラグは、インスタンスの作成時に有効にできます。ベクター サポートは現在、MySQL 8.0 R20241208.01_00 以降で利用可能です
Cloud Shell セッションで、次のコマンドを実行します。
gcloud sql instances create my-cloudsql-instance \
--database-version=MYSQL_8_4 \
--tier=db-custom-2-8192 \
--region=us-central1 \
--enable-google-ml-integration \
--edition=ENTERPRISE \
--root-password=$CLOUDSQL_PASSWORD
Cloud Shell から実行して接続を確認できます。
gcloud sql connect my-cloudsql-instance --user=root
コマンドを実行し、接続の準備ができたらプロンプトにパスワードを入力します。
想定される出力:
$gcloud sql connect my-cloudsql-instance --user=root Allowlisting your IP for incoming connection for 5 minutes...done. Connecting to database with SQL user [root].Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 71 Server version: 8.4.4-google (Google) Copyright (c) 2000, 2025, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
Ctrl+D キーボード ショートカットを使用するか、exit コマンドを実行して、mysql セッションを終了します。
exit
Vertex AI のインテグレーションを有効にする
Vertex AI 統合を使用できるように、内部 Cloud SQL サービス アカウントに必要な権限を付与します。
Cloud SQL 内部サービス アカウントのメールアドレスを確認し、変数としてエクスポートします。
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
Cloud SQL サービス アカウントに Vertex AI へのアクセス権を付与します。
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
インスタンスの作成と構成の詳細については、Cloud SQL ドキュメントのこちらをご覧ください。
5. データベースの準備
次に、データベースを作成してベクトル サポートを有効にする必要があります。
データベースを作成
quickstart_db という名前のデータベースを作成します。これを行うには、mySQL の mysql などのコマンドライン データベース クライアント、SDK、Cloud SQL Studio など、さまざまなオプションがあります。データベースの作成には SDK(gcloud)を使用します。
Cloud Shell でコマンドを実行してデータベースを作成する
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
6. データを読み込む
次に、データベースにオブジェクトを作成してデータを読み込む必要があります。架空の Cymbal Store のデータを使用します。データは SQL(スキーマ用)と CSV 形式(データ用)で利用できます。
Cloud Shell は、データベースに接続し、すべてのオブジェクトを作成してデータを読み込むためのメイン環境になります。
まず、Cloud Shell のパブリック IP を Cloud SQL インスタンスの承認済みネットワークのリストに追加する必要があります。Cloud Shell で、次のコマンドを実行します。
gcloud sql instances patch my-cloudsql-instance --authorized-networks=$(curl ifconfig.me)
セッションが失われた場合、リセットした場合、または別のツールから作業する場合は、CLOUDSQL_PASSWORD 変数を再度エクスポートします。
export CLOUDSQL_PASSWORD=...your password defined for the instance...
これで、データベースに必要なすべてのオブジェクトを作成できます。これを行うには、MySQL の mysql ユーティリティと、一般公開ソースからデータを取得する curl ユーティリティを組み合わせて使用します。
Cloud Shell で、次のコマンドを実行します。
export INSTANCE_IP=$(gcloud sql instances describe my-cloudsql-instance --format="value(ipAddresses.ipAddress)")
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_mysql_schema.sql | mysql --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db
前のコマンドでは具体的に何を行ったのでしょうか?データベースに接続し、ダウンロードした SQL コードを実行して、テーブル、インデックス、シーケンスを作成しました。
次のステップでは、cymbal_products データを読み込みます。同じ curl ユーティリティと mysql ユーティリティを使用します。
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_products.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_products FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
次に、cymbal_stores を続行します。
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_stores.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_stores FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
また、各ストアの各商品の数を表す cymbal_inventory も完成させます。
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_inventory.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_inventory FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
独自のサンプルデータと、Cloud コンソールから利用できる Cloud SQL インポート ツールと互換性のある CSV ファイルがある場合は、ここで説明した方法の代わりにそれらを使用できます。
7. エンベディングを作成する
次のステップでは、Google Vertex AI の textembedding-005 モデルを使用して商品説明のエンベディングを構築し、cymbal_products テーブルの新しい列に保存します。
ベクトル データを保存するには、Cloud SQL インスタンスでベクトル機能を有効にする必要があります。Cloud Shell で次のコマンドを実行します。
gcloud sql instances patch my-cloudsql-instance \
--database-flags=cloudsql_vector=on
データベースに接続します。
mysql --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db
また、エンベディング関数を使用して、cymbal_products テーブルに新しい列 embedding を作成します。この新しい列には、product_description 列のテキストに基づくベクトル エンベディングが格納されます。
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) using varbinary;
UPDATE cymbal_products SET embedding = mysql.ml_embedding('text-embedding-005', product_description);
通常、2,000 行のベクトル エンベディングの生成には 5 分未満かかりますが、若干時間がかかることもあります。多くの場合、はるかに早く完了します。
8. 類似性検索を実行する
これで、説明用に計算されたベクトル値と、同じエンベディング モデルを使用してリクエスト用に生成したベクトル値に基づいて、類似性検索を使用して検索を実行できます。
SQL クエリは、同じコマンドライン インターフェースから実行することも、Cloud SQL Studio から実行することもできます。複数行の複雑なクエリは、Cloud SQL Studio で管理することをおすすめします。
ユーザーを作成する
Cloud SQL Studio を使用できる新しいユーザーが必要です。ここでは、root ユーザーに使用したのと同じパスワードを使用して、組み込みタイプのユーザー student を作成します。
Cloud Shell で、次のコマンドを実行します。
gcloud sql users create student --instance=my-cloudsql-instance --password=$CLOUDSQL_PASSWORD --host=%
Cloud SQL Studio を起動する
コンソールで、先ほど作成した Cloud SQL インスタンスをクリックします。
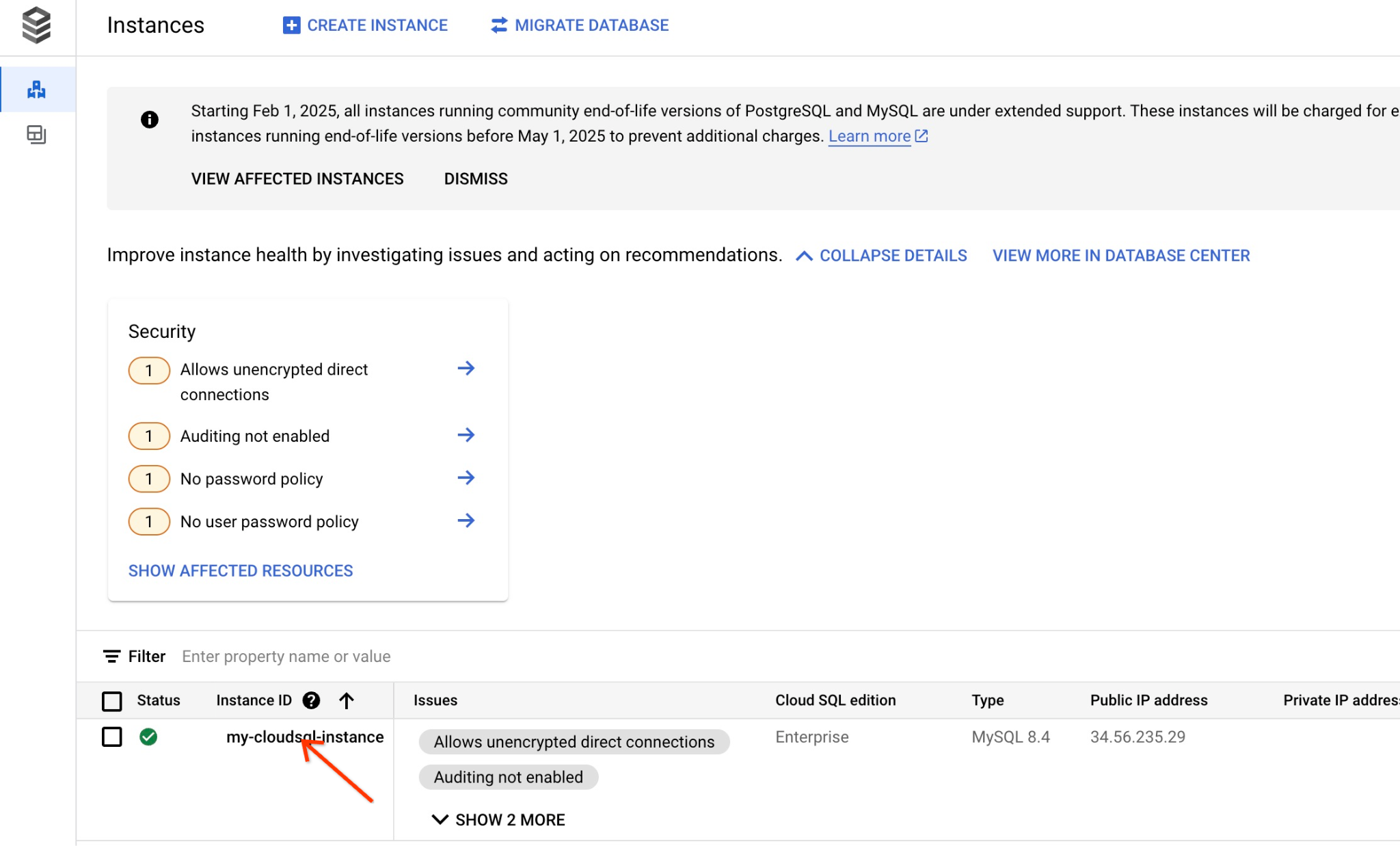
右側のパネルが開くと、Cloud SQL Studio が表示されます。クリックします。
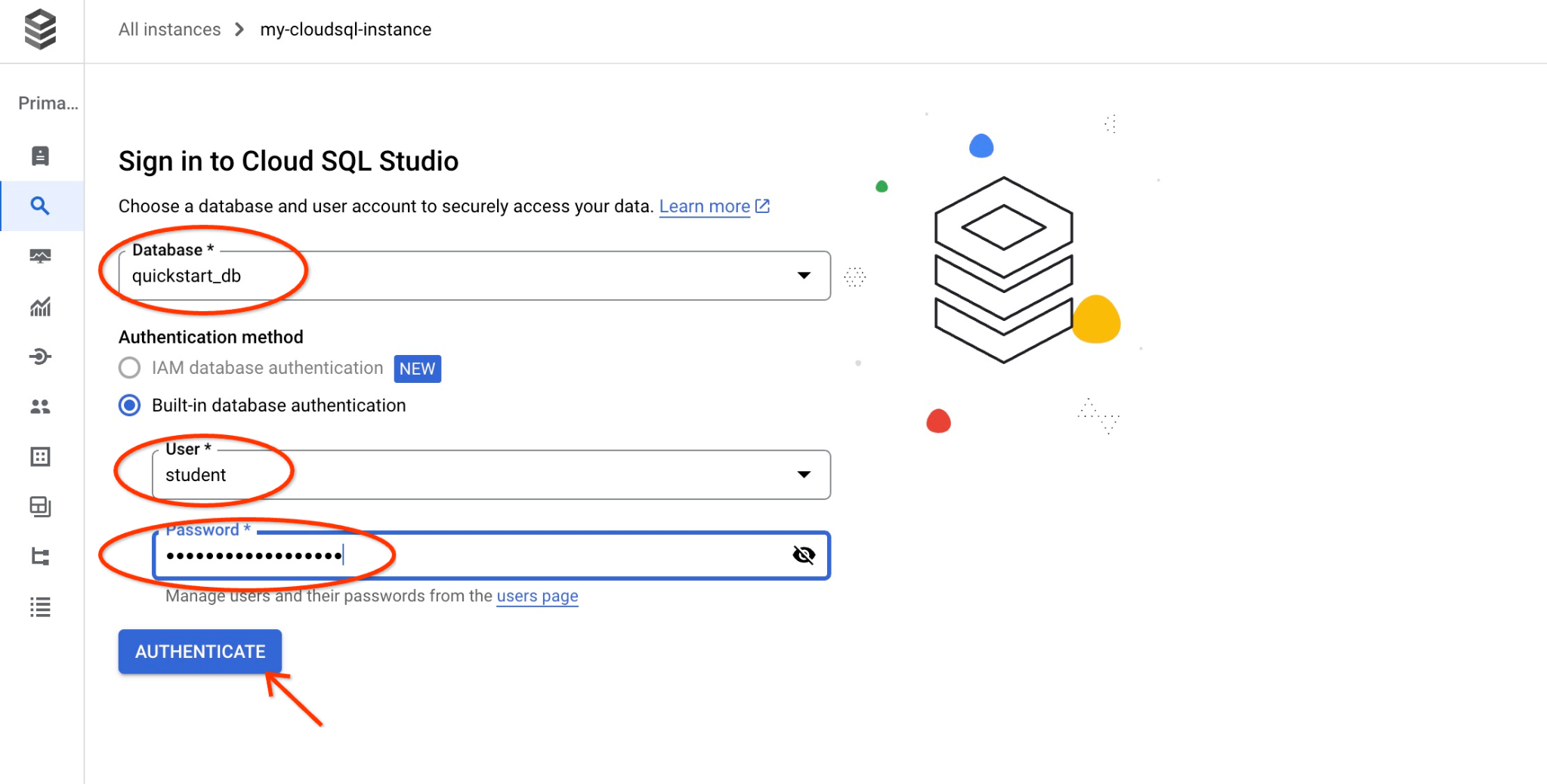
データベース名と認証情報を入力するダイアログが開きます。
- データベース: quickstart_db
- ユーザー: student
- パスワード: ユーザー用にメモしたパスワード
[AUTHENTICATE] ボタンをクリックします。
次のウィンドウが開きます。右側の [エディタ] タブをクリックして、SQL エディタを開きます。
これで、クエリを実行する準備が整いました。
クエリを実行
クエリを実行して、クライアントのリクエストに最も関連性の高い利用可能な商品のリストを取得します。ベクトル値を取得するために Vertex AI に渡すリクエストは、「この場所でよく育つ果樹は何ですか?」のようなものです。
KNN(完全一致)ベクトル検索で cosine_distance を使用してクエリを実行する
cosine_distance 関数を使用してリクエストに最も適した上位 5 つのアイテムを選択するために実行できるクエリは次のとおりです。
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cosine_distance(cp.embedding ,@query_vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
クエリをコピーして Cloud SQL Studio エディタに貼り付け、[実行] ボタンを押すか、quickstart_db データベースに接続しているコマンドライン セッションに貼り付けます。
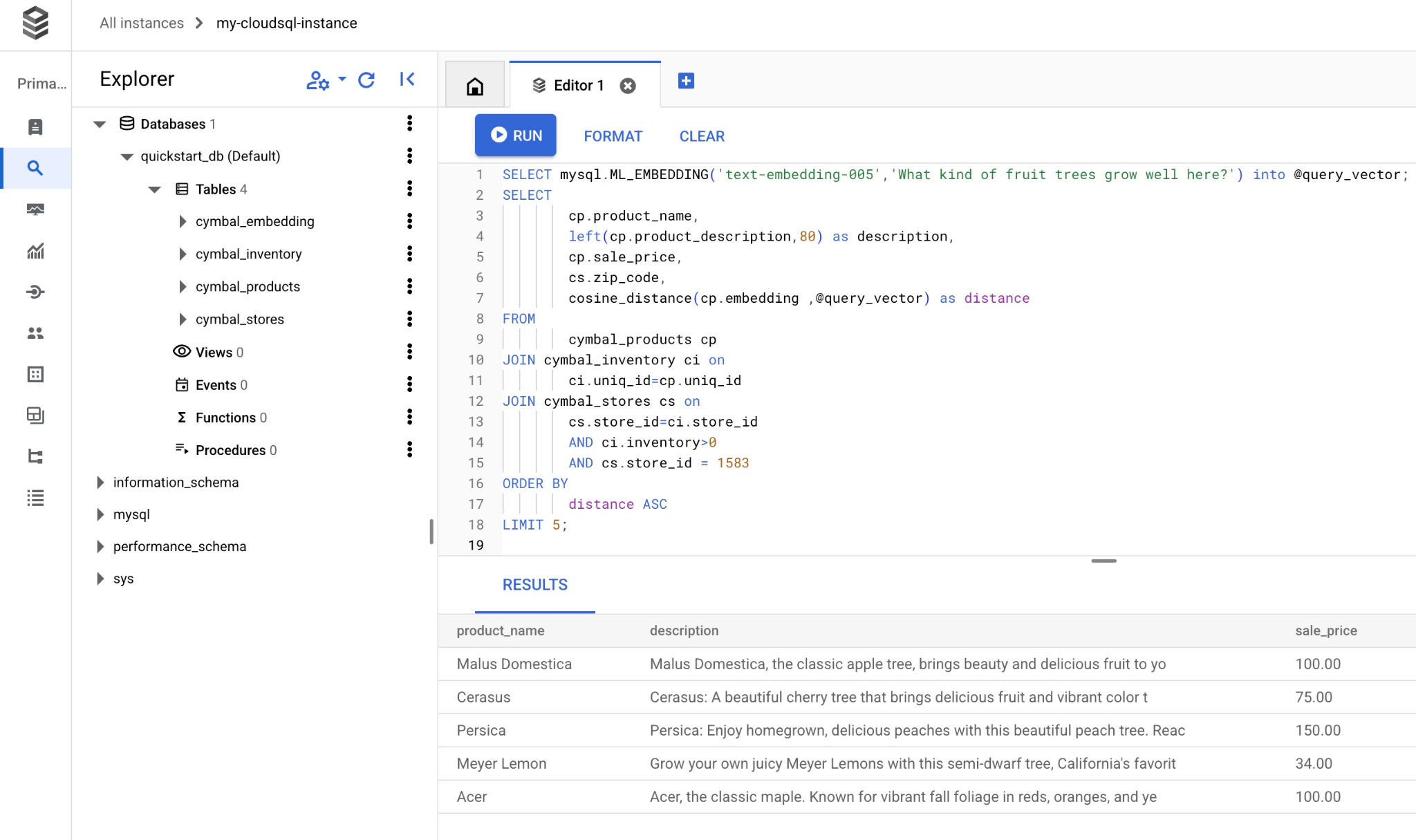
クエリに一致する選択された商品のリストは次のとおりです。
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| product_name | description | sale_price | zip_code | distance |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 |
| Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 |
| Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 |
| Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 |
| Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
5 rows in set (0.13 sec)
cosine_distance 関数を使用したクエリの実行時間は 0.13 秒でした。
KNN(正確な)ベクトル検索に approx_distance を使用してクエリを実行する
次に、approx_distance 関数を使用して KNN 検索を使用する同じクエリを実行します。エンベディングの ANN インデックスがない場合、バックグラウンドで自動的に完全一致検索に戻ります。
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
クエリによって返される商品のリストは次のとおりです。
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| product_name | description | sale_price | zip_code | distance |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 |
| Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 |
| Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 |
| Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 |
| Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
5 rows in set, 1 warning (0.12 sec)
クエリの実行には 0.12 秒しかかかりませんでした。cosine_distance 関数と同じ結果が得られました。
9. 取得したデータを使用して LLM のレスポンスを改善する
実行されたクエリの結果を使用して、クライアント アプリケーションに対する生成 AI LLM のレスポンスを改善し、提供されたクエリ結果を Vertex AI 生成基盤言語モデルへのプロンプトの一部として使用して、意味のある出力を準備できます。
そのためには、ベクトル検索の結果を含む JSON を生成し、その生成された JSON を Vertex AI の LLM モデルのプロンプトに追加して、意味のある出力を生成する必要があります。最初の手順で JSON を生成し、次の手順で Vertex AI Studio でテストします。最後の手順で、アプリケーションで使用できる SQL ステートメントに組み込みます。
JSON 形式で出力を生成する
クエリを変更して、JSON 形式で出力を生成し、Vertex AI に渡す行を 1 つだけ返します。
ANN 検索を使用したクエリの例を次に示します。
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine')) ASC
LIMIT 1)
SELECT json_arrayagg(json_object('product_name',product_name,'description',description,'sale_price',sale_price,'zip_code',zip_code,'product_id',product_id)) FROM trees;
出力で想定される JSON は次のとおりです。
[{"zip_code": 93230, "product_id": "23e41a71d63d8bbc9bdfa1d118cfddc5", "sale_price": 100.00, "description": "Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo", "product_name": "Malus Domestica"}]
Vertex AI Studio でプロンプトを実行する
生成された JSON を使用して、Vertex AI Studio の生成 AI テキストモデルのプロンプトの一部として指定できます。
Cloud コンソールで Vertex AI Studio プロンプトを開きます。
追加の API を有効にするよう求められることがありますが、このリクエストは無視してかまいません。ラボを完了するために追加の API は必要ありません。
Studio にプロンプトを配置します。
使用するプロンプトは次のとおりです。
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
JSON プレースホルダをクエリのレスポンスに置き換えると、次のようになります。
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
{"zip_code": 93230, "product_id": "23e41a71d63d8bbc9bdfa1d118cfddc5", "sale_price": 100.00, "description": "Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo", "product_name": "Malus Domestica"}
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
JSON 値を使用して gemini-2.5-flash モデルでプロンプトを実行した結果は次のとおりです。
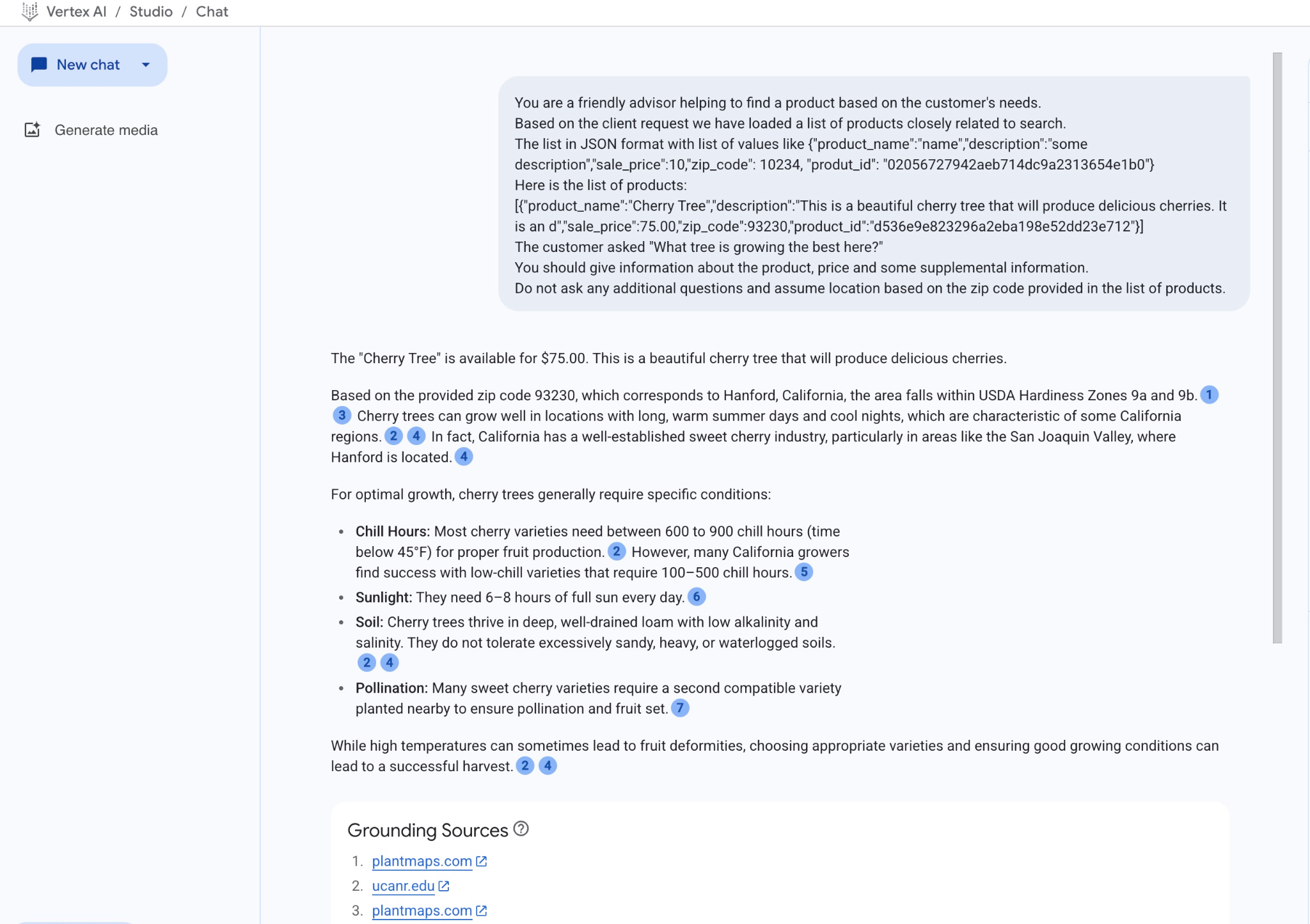
この例では、モデルから得られた回答は、セマンティック検索の結果と、言及された郵便番号で入手可能な最も一致する商品を使用して作成されています。
SQL でプロンプトを実行する
また、Cloud SQL AI と Vertex AI の統合を使用して、データベースで SQL を直接使用して生成モデルから同様のレスポンスを取得することもできます。
これで、生成された JSON 結果を含むサブクエリを SQL で使用して、生成 AI テキスト モデルのプロンプトの一部として指定できるようになりました。
データベースへの mysql セッションまたは Cloud SQL Studio セッションでクエリを実行します。
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine')) ASC
LIMIT 1),
prompt AS (
SELECT
CONCAT( 'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:', json_arrayagg(json_object('product_name',trees.product_name,'description',trees.description,'sale_price',trees.sale_price,'zip_code',trees.zip_code,'product_id',trees.product_id)) , 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information') AS prompt_text
FROM
trees),
response AS (
SELECT
mysql.ML_PREDICT_ROW('publishers/google/models/gemini-2.0-flash-001:generateContent',
json_object('contents',
json_object('role',
'user',
'parts',
json_array(
json_object('text',
prompt_text))))) AS resp
FROM
prompt)
SELECT
JSON_EXTRACT(resp, '$.candidates[0].content.parts[0].text')
FROM
response;
出力例を次に示します。出力は、モデルのバージョンとパラメータによって異なる場合があります。
"Okay, I see you're looking for fruit trees that grow well in your area. Based on the available product, the **Malus Domestica** (Apple Tree) is a great option to consider!\n\n* **Product:** Malus Domestica (Apple Tree)\n* **Description:** This classic apple tree grows to about 30 feet tall and provides beautiful seasonal color with green leaves in summer and fiery colors in the fall. It's known for its strength and provides good shade. Most importantly, it produces delicious apples!\n* **Price:** \\$100.00\n* **Growing Zones:** This particular apple tree is well-suited for USDA zones 4-8. Since your zip code is 93230, you are likely in USDA zone 9a or 9b. While this specific tree is rated for zones 4-8, with proper care and variety selection, apple trees can still thrive in slightly warmer climates. You may need to provide extra care during heat waves.\n\n**Recommendation:** I would recommend investigating varieties of Malus Domestica suited to slightly warmer climates or contacting a local nursery/arborist to verify if it is a good fit for your local climate conditions.\n"
出力はマークダウン形式で提供されます。
10. 最近傍インデックスを作成する
データセットは比較的小さく、レスポンス時間は主に AI モデルとのインタラクションに依存します。ただし、ベクトルが数百万個ある場合、ベクトル検索にかなりの時間がかかり、システムに大きな負荷がかかる可能性があります。これを改善するために、ベクトル上にインデックスを構築できます。
ScANN インデックスを作成する
テストには ScANN インデックス タイプを使用します。
埋め込み列のインデックスを構築するには、埋め込み列の距離測定を定義する必要があります。パラメータの詳細については、こちらのドキュメントをご覧ください。
CREATE VECTOR INDEX cymbal_products_embedding_idx ON cymbal_products(embedding) USING SCANN DISTANCE_MEASURE=COSINE;
レスポンスを比較する
これで、ベクトル検索クエリを再度実行して結果を確認できます。
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
予想される出力:
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ | product_name | description | sale_price | zip_code | distance | +-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ | Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 | | Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 | | Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 | | Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 | | Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 | +-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ 5 rows in set (0.08 sec)
実行時間はわずかに異なるだけですが、このような小さなデータセットでは想定内です。数百万のベクトルを含む大規模なデータセットでは、この違いがより顕著になります。
EXPLAIN コマンドを使用して実行プランを確認できます。
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
EXPLAIN ANALYZE SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
実行プラン(抜粋):
...
-> Nested loop inner join (cost=443 rows=5) (actual time=1.14..1.18 rows=5 loops=1)
-> Vector index scan on cp (cost=441 rows=5) (actual time=1.1..1.1 rows=5 loops=1)
-> Single-row index lookup on cp using PRIMARY (uniq_id=cp.uniq_id) (cost=0.25 rows=1) (actual time=0.0152..0.0152 rows=1 loops=5)
...
cp(cymbal_products テーブルのエイリアス)でベクトル インデックス スキャンが使用されていることがわかります。
独自のデータを試したり、さまざまな検索クエリをテストして、MySQL でセマンティック検索がどのように機能するかを確認できます。
11. 環境をクリーンアップする
Cloud SQL インスタンスを削除します。
ラボの終了時に Cloud SQL インスタンスを破棄します。
接続が切断され、以前の設定がすべて失われた場合は、Cloud Shell でプロジェクトと環境変数を定義します。
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
インスタンスを削除します。
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
想定されるコンソール出力:
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
12. 完了
以上で、この Codelab は完了です。
Google Cloud 学習プログラム
このラボは、「Google Cloud でのプロダクション レディな AI の開発」学習プログラムの一部です。
- カリキュラム全体で、プロトタイプから本番環境への移行についてご確認ください。
- ハッシュタグ
#ProductionReadyAIで進捗状況を共有しましょう。
学習した内容
- PostgreSQL 用 Cloud SQL インスタンスをデプロイする方法
- データベースを作成して Cloud SQL AI 統合を有効にする方法
- データベースにデータを読み込む方法
- Cloud SQL Studio の使用方法
- Cloud SQL で Vertex AI エンベディング モデルを使用する方法
- Vertex AI Studio の使用方法
- Vertex AI 生成モデルを使用して結果を拡充する方法
- ベクトル インデックスを使用してパフォーマンスを改善する方法
同様の AlloyDB の Codelab または Cloud SQL for Postgres の Codelab を試す
13. アンケート
出力: