
1. Wprowadzenie
W tym ćwiczeniu dowiesz się, jak korzystać z integracji Cloud SQL for MySQL z Vertex AI, łącząc wyszukiwanie wektorowe z wektorami dystrybucyjnymi Vertex AI.

Wymagania wstępne
- Podstawowa wiedza o Google Cloud i konsoli
- Podstawowe umiejętności w zakresie interfejsu wiersza poleceń i Cloud Shell
Czego się nauczysz
- Jak wdrożyć instancję Cloud SQL dla PostgreSQL
- Jak utworzyć bazę danych i włączyć integrację Cloud SQL z AI
- Wczytywanie danych do bazy danych
- Jak korzystać z Cloud SQL Studio
- Jak używać modelu wektorów dystrybucyjnych Vertex AI w Cloud SQL
- Jak korzystać z Vertex AI Studio
- Jak wzbogacić wynik za pomocą modelu generatywnego Vertex AI
- Jak poprawić wydajność za pomocą indeksu wektorów
Czego potrzebujesz
- Konto Google Cloud i projekt Google Cloud
- Przeglądarka internetowa, np. Chrome, obsługująca konsolę Google Cloud i Cloud Shell
2. Konfiguracja i wymagania
Konfiguracja projektu
- Zaloguj się w konsoli Google Cloud. Jeśli nie masz jeszcze konta Gmail lub Google Workspace, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
- Utwórz nowy projekt lub użyj istniejącego. Aby utworzyć nowy projekt w konsoli Google Cloud, w nagłówku kliknij przycisk Wybierz projekt. Otworzy się okno wyskakujące.

W oknie Wybierz projekt kliknij przycisk Nowy projekt, który otworzy okno dialogowe nowego projektu.
W oknie dialogowym wpisz preferowaną nazwę projektu i wybierz lokalizację.
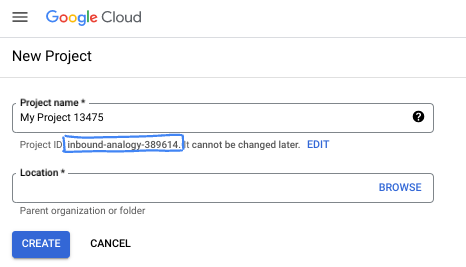
- Nazwa projektu to wyświetlana nazwa dla uczestników tego projektu. Nazwa projektu nie jest używana przez interfejsy API Google i można ją w każdej chwili zmienić.
- Identyfikator projektu jest unikalny we wszystkich projektach Google Cloud i nie można go zmienić po ustawieniu. Konsola Google Cloud automatycznie generuje unikalny identyfikator, ale możesz go dostosować. Jeśli wygenerowany identyfikator Ci się nie podoba, możesz wygenerować kolejny losowy identyfikator lub podać własny, aby sprawdzić jego dostępność. W większości ćwiczeń z programowania musisz odwoływać się do identyfikatora projektu, który jest zwykle oznaczony zmienną PROJECT_ID.
- Warto wiedzieć, że istnieje jeszcze trzecia wartość, numer projektu, której używają niektóre interfejsy API. Więcej informacji o tych 3 wartościach znajdziesz w dokumentacji.
Włącz płatności
Aby włączyć płatności, masz 2 możliwości. Możesz użyć osobistego konta rozliczeniowego lub wykorzystać środki, wykonując te czynności.
Odbieranie środków w Google Cloud (opcjonalnie)
Aby przeprowadzić te warsztaty, musisz mieć konto rozliczeniowe z określonymi środkami. Aby rozpocząć, użyj środków z banera u góry tego modułu. Jeśli masz już połączenie z kontem rozliczeniowym, możesz pominąć ten krok.
Konfigurowanie osobistego konta rozliczeniowego
Jeśli skonfigurujesz płatności za pomocą środków w Google Cloud, możesz pominąć ten krok.
Aby skonfigurować osobiste konto rozliczeniowe, włącz płatności w Cloud Console.
Uwagi:
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 3 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Uruchamianie Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym ćwiczeniu użyjesz Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Możesz też nacisnąć G, a potem S. Ta sekwencja aktywuje Cloud Shell, jeśli korzystasz z konsoli Google Cloud. Możesz też użyć tego linku.
Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym laboratorium możesz wykonać w przeglądarce. Nie musisz niczego instalować.
3. Zanim zaczniesz
Włącz API
Aby korzystać z Cloud SQL, Compute Engine, usług sieciowych i Vertex AI, musisz włączyć odpowiednie interfejsy API w projekcie Google Cloud.
W terminalu Cloud Shell sprawdź, czy identyfikator projektu jest skonfigurowany:
gcloud config set project [YOUR-PROJECT-ID]
Ustaw zmienną środowiskową PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Włącz wszystkie niezbędne usługi:
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Oczekiwane dane wyjściowe
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Przedstawiamy interfejsy API
- Cloud SQL Admin API (
sqladmin.googleapis.com) umożliwia programowe tworzenie, konfigurowanie i zarządzanie instancjami Cloud SQL. Zapewnia platformę sterującą dla w pełni zarządzanej usługi relacyjnej bazy danych Google (obsługującej MySQL, PostgreSQL i SQL Server), która obsługuje zadania takie jak udostępnianie, tworzenie kopii zapasowych, wysoka dostępność i skalowanie. - Compute Engine API (
compute.googleapis.com) umożliwia tworzenie maszyn wirtualnych, dysków trwałych i ustawień sieciowych oraz zarządzanie nimi. Zapewnia podstawową infrastrukturę jako usługę (IaaS) potrzebną do uruchamiania zbiorów zadań i hostowania infrastruktury bazowej dla wielu usług zarządzanych. - Cloud Resource Manager API (
cloudresourcemanager.googleapis.com) umożliwia zautomatyzowane zarządzanie metadanymi i konfiguracją projektu Google Cloud. Umożliwia organizowanie zasobów, obsługę zasad Identity and Access Management (IAM) oraz weryfikowanie uprawnień w hierarchii projektu. - Service Networking API (
servicenetworking.googleapis.com) umożliwia automatyzację konfiguracji prywatnej łączności między siecią Virtual Private Cloud (VPC) a usługami zarządzanymi Google. Jest to szczególnie ważne w przypadku zapewnienia dostępu do usług takich jak AlloyDB za pomocą prywatnego adresu IP, aby mogły one bezpiecznie komunikować się z innymi zasobami. - Interfejs Vertex AI API (
aiplatform.googleapis.com) umożliwia aplikacjom tworzenie, wdrażanie i skalowanie modeli uczenia maszynowego. Zapewnia on ujednolicony interfejs dla wszystkich usług AI w Google Cloud, w tym dostęp do modeli generatywnej AI (takich jak Gemini) i trenowania modeli niestandardowych.
4. Tworzenie instancji Cloud SQL
Utwórz instancję Cloud SQL z integracją bazy danych z Vertex AI.
Utwórz hasło do bazy danych
Określ hasło domyślnego użytkownika bazy danych. Możesz zdefiniować własne hasło lub użyć funkcji losowej, aby je wygenerować:
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
Zanotuj wygenerowaną wartość hasła:
echo $CLOUDSQL_PASSWORD
Tworzenie instancji Cloud SQL for MySQL
Flagę cloudsql_vector można włączyć podczas tworzenia instancji. Obsługa wektorów jest obecnie dostępna w przypadku MySQL w wersji 8.0 R20241208.01_00 lub nowszej.
W sesji Cloud Shell wykonaj to polecenie:
gcloud sql instances create my-cloudsql-instance \
--database-version=MYSQL_8_4 \
--tier=db-custom-2-8192 \
--region=us-central1 \
--enable-google-ml-integration \
--edition=ENTERPRISE \
--root-password=$CLOUDSQL_PASSWORD
Możemy zweryfikować połączenie, wykonując je z Cloud Shell.
gcloud sql connect my-cloudsql-instance --user=root
Uruchom polecenie i wpisz hasło w odpowiednim miejscu, gdy będzie gotowe do połączenia.
Oczekiwane dane wyjściowe:
$gcloud sql connect my-cloudsql-instance --user=root Allowlisting your IP for incoming connection for 5 minutes...done. Connecting to database with SQL user [root].Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 71 Server version: 8.4.4-google (Google) Copyright (c) 2000, 2025, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
Na razie wyjdź z sesji mysql, używając skrótu klawiszowego Ctrl+D lub wykonując polecenie exit.
exit
Włącz integrację z Vertex AI
Przyznaj wewnętrznemu kontu usługi Cloud SQL niezbędne uprawnienia, aby można było korzystać z integracji z Vertex AI.
Znajdź adres e-mail wewnętrznego konta usługi Cloud SQL i wyeksportuj go jako zmienną.
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
Przyznaj dostęp do Vertex AI kontu usługi Cloud SQL:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Więcej informacji o tworzeniu i konfigurowaniu instancji znajdziesz w dokumentacji Cloud SQL tutaj.
5. Przygotowywanie bazy danych
Teraz musimy utworzyć bazę danych i włączyć obsługę wektorów.
Utwórz bazę danych
Utwórz bazę danych o nazwie quickstart_db. Możesz to zrobić na różne sposoby, np. za pomocą klientów bazy danych w wierszu poleceń, takich jak mysql w przypadku MySQL, pakietu SDK lub Cloud SQL Studio. Do utworzenia bazy danych użyjemy pakietu SDK (gcloud).
W Cloud Shell uruchom polecenie utworzenia bazy danych.
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
6. Wczytaj dane
Teraz musimy utworzyć obiekty w bazie danych i załadować dane. Będziemy używać fikcyjnych danych sklepu Cymbal Store. Dane są dostępne w formacie SQL (dla schematu) i CSV (dla danych).
Cloud Shell będzie naszym głównym środowiskiem do łączenia się z bazą danych, tworzenia wszystkich obiektów i wczytywania danych.
Najpierw musimy dodać publiczny adres IP Cloud Shell do listy autoryzowanych sieci w przypadku naszej instancji Cloud SQL. W Cloud Shell wykonaj to polecenie:
gcloud sql instances patch my-cloudsql-instance --authorized-networks=$(curl ifconfig.me)
Jeśli sesja została utracona, zresetowana lub pracujesz w innym narzędziu, ponownie wyeksportuj zmienną CLOUDSQL_PASSWORD:
export CLOUDSQL_PASSWORD=...your password defined for the instance...
Teraz możemy utworzyć w bazie danych wszystkie wymagane obiekty. W tym celu użyjemy narzędzia MySQL mysql w połączeniu z narzędziem curl, które pobiera dane z publicznego źródła.
W Cloud Shell wykonaj to polecenie:
export INSTANCE_IP=$(gcloud sql instances describe my-cloudsql-instance --format="value(ipAddresses.ipAddress)")
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_mysql_schema.sql | mysql --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db
Co dokładnie zrobiliśmy w poprzednim poleceniu? Połączyliśmy się z bazą danych i wykonaliśmy pobrany kod SQL, który utworzył tabele, indeksy i sekwencje.
Następnym krokiem jest wczytanie danych cymbal_products. Używamy tych samych narzędzi curl i mysql.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_products.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_products FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
Następnie przechodzimy do cymbal_stores.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_stores.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_stores FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
Uzupełnij go o kolumnę cymbal_inventory, która zawiera liczbę każdego produktu w każdym sklepie.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_inventory.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_inventory FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
Jeśli masz własne dane przykładowe i pliki CSV zgodne z narzędziem do importowania Cloud SQL dostępnym w konsoli Cloud, możesz ich użyć zamiast przedstawionego podejścia.
7. Tworzenie wektorów dystrybucyjnych
Następnym krokiem jest utworzenie wektorów osadzania dla opisów produktów za pomocą modelu textembedding-005 z Google Vertex AI i zapisanie ich w nowej kolumnie w tabeli cymbal_products.
Aby przechowywać dane wektorowe, musimy włączyć funkcje wektorowe w instancji Cloud SQL. Uruchom w Cloud Shell:
gcloud sql instances patch my-cloudsql-instance \
--database-flags=cloudsql_vector=on
Połącz się z bazą danych:
mysql --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db
Następnie utwórz w tabeli cymbal_products nową kolumnę embedding za pomocą funkcji embedding. Ta nowa kolumna będzie zawierać osadzenia wektorowe na podstawie tekstu w kolumnie product_description.
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) using varbinary;
UPDATE cymbal_products SET embedding = mysql.ml_embedding('text-embedding-005', product_description);
Wygenerowanie osadzeń wektorowych dla 2000 wierszy zajmuje zwykle mniej niż 5 minut, ale czasami może potrwać nieco dłużej, a często kończy się znacznie szybciej.
8. Uruchom wyszukiwanie podobieństw
Możemy teraz przeprowadzić wyszukiwanie podobieństwa na podstawie wartości wektorowych obliczonych dla opisów oraz wartości wektorowej wygenerowanej dla naszego żądania przy użyciu tego samego modelu osadzania.
Zapytanie SQL można wykonać z tego samego interfejsu wiersza poleceń lub z Cloud SQL Studio. Wszystkie zapytania wielowierszowe i złożone lepiej jest zarządzać w Cloud SQL Studio.
Tworzenie użytkownika
Potrzebujemy nowego użytkownika, który może korzystać z Cloud SQL Studio. Utworzymy użytkownika typu wbudowanego student z tym samym hasłem, którego użyliśmy w przypadku użytkownika root.
W Cloud Shell uruchom:
gcloud sql users create student --instance=my-cloudsql-instance --password=$CLOUDSQL_PASSWORD --host=%
Uruchamianie Cloud SQL Studio
W konsoli kliknij utworzoną wcześniej instancję Cloud SQL.
Po otwarciu panelu po prawej stronie widzimy Cloud SQL Studio. Kliknij ją.
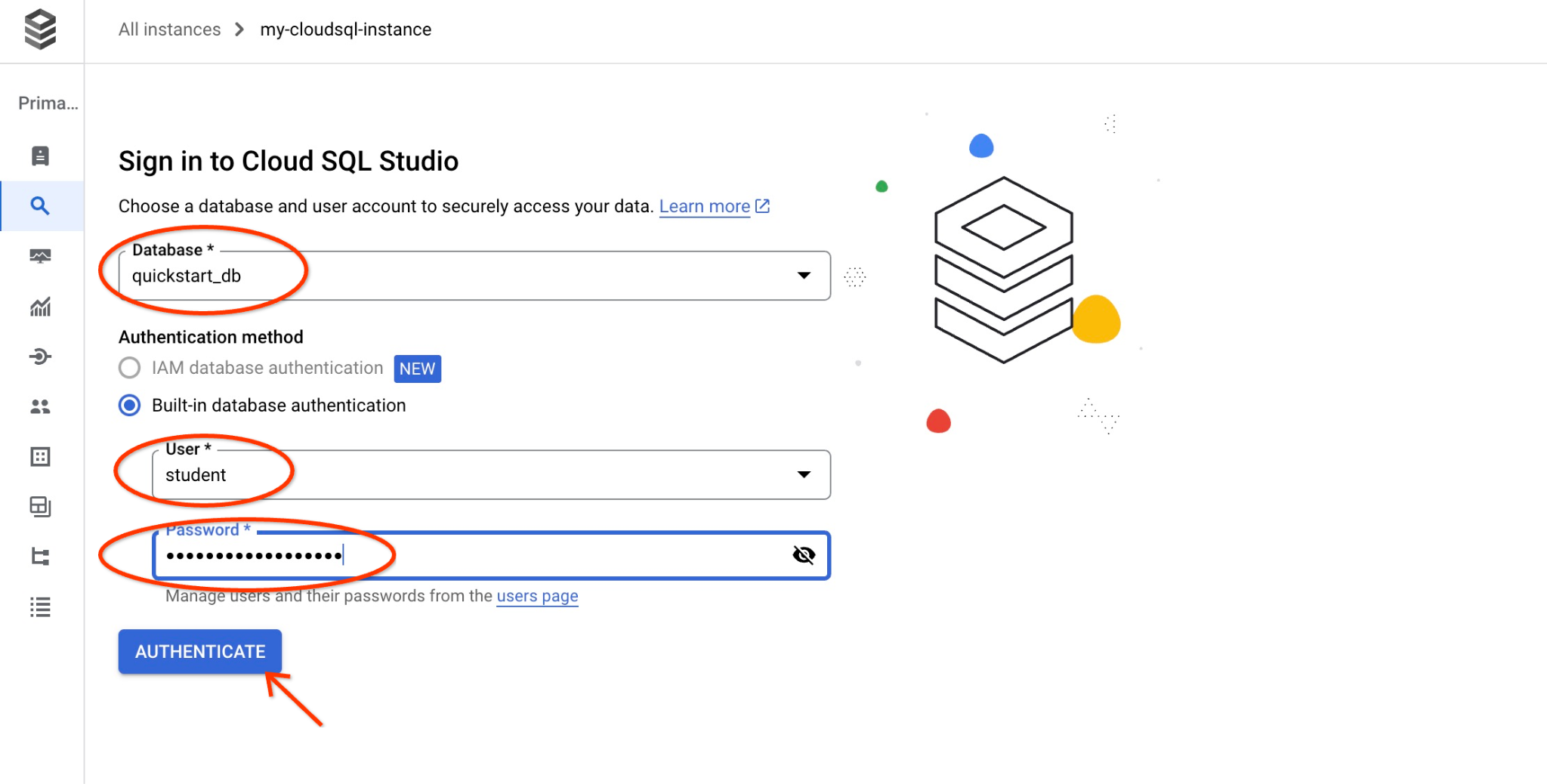
Otworzy się okno dialogowe, w którym możesz podać nazwę bazy danych i swoje dane logowania:
- Baza danych: quickstart_db
- Użytkownik: student
- Hasło: zapisane hasło użytkownika.
Następnie kliknij przycisk „AUTHENTICATE” (UWIERZYTELNIJ).
Otworzy się kolejne okno, w którym po prawej stronie kliknij kartę „Edytor”, aby otworzyć edytor SQL.
Teraz możemy uruchomić zapytania.
Uruchom zapytanie
Uruchom zapytanie, aby uzyskać listę dostępnych produktów najbardziej związanych z prośbą klienta. Żądanie, które przekażemy do Vertex AI, aby uzyskać wartość wektora, będzie brzmieć: „Jakie drzewa owocowe dobrze tu rosną?”.
Uruchamianie zapytania z funkcją cosine_distance na potrzeby wyszukiwania wektorowego KNN (dokładnego)
Oto zapytanie, które możesz uruchomić, aby wybrać 5 pierwszych elementów najbardziej odpowiednich dla Twojej prośby, korzystając z funkcji cosine_distance:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cosine_distance(cp.embedding ,@query_vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Skopiuj i wklej zapytanie do edytora Cloud SQL Studio, a następnie kliknij przycisk „URUCHOM” lub wklej je w sesji wiersza poleceń połączonej z bazą danych quickstart_db.
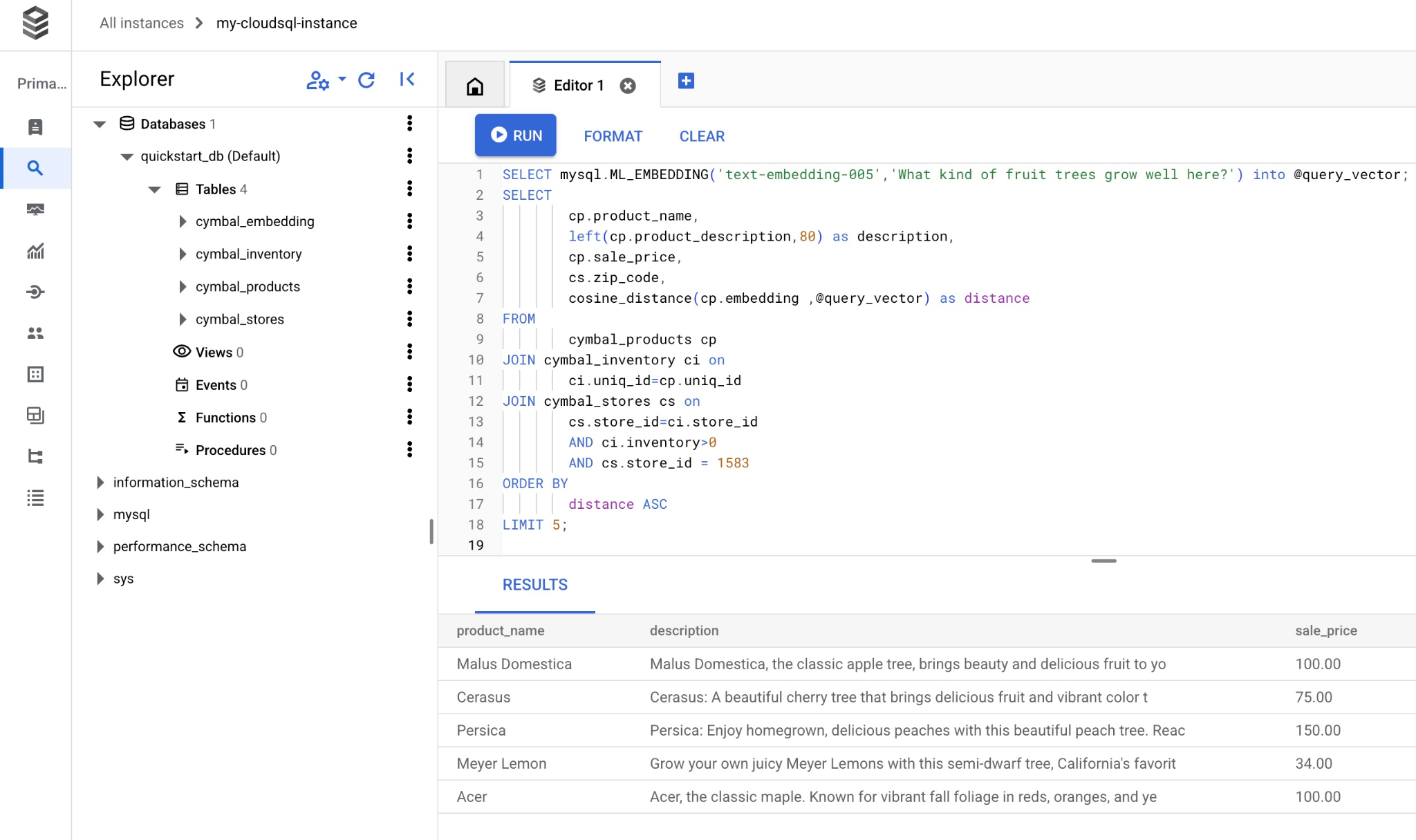
A oto lista wybranych produktów pasujących do zapytania.
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| product_name | description | sale_price | zip_code | distance |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 |
| Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 |
| Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 |
| Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 |
| Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
5 rows in set (0.13 sec)
Wykonanie zapytania z funkcją cosine_distance zajęło 0,13 sekundy.
Uruchamianie zapytania z funkcją approx_distance na potrzeby wyszukiwania wektorowego KNN (dokładnego)
Teraz uruchomimy to samo zapytanie, ale użyjemy wyszukiwania KNN za pomocą funkcji approx_distance. Jeśli nie mamy indeksu ANN dla naszych wektorów, automatycznie wracamy do dokładnego wyszukiwania w tle:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
A oto lista produktów zwróconych przez zapytanie.
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| product_name | description | sale_price | zip_code | distance |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 |
| Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 |
| Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 |
| Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 |
| Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
5 rows in set, 1 warning (0.12 sec)
Wykonanie zapytania zajęło tylko 0,12 sekundy. Uzyskaliśmy te same wyniki co w przypadku funkcji cosine_distance.
9. Ulepszanie odpowiedzi LLM za pomocą pobranych danych
Możemy ulepszyć odpowiedź modelu LLM generatywnej AI na aplikację klienta, korzystając z wyniku wykonanego zapytania, i przygotować przydatne dane wyjściowe, używając dostarczonych wyników zapytania jako części promptu do generatywnego modelu podstawowego Vertex AI.
Aby to osiągnąć, musimy wygenerować plik JSON z wynikami wyszukiwania wektorowego, a następnie użyć go jako dodatku do promptu dla modelu LLM w Vertex AI, aby uzyskać wartościowe dane wyjściowe. W pierwszym kroku generujemy kod JSON, następnie testujemy go w Vertex AI Studio, a w ostatnim kroku włączamy go do instrukcji SQL, której można używać w aplikacji.
Generowanie danych wyjściowych w formacie JSON
Zmodyfikuj zapytanie, aby wygenerować dane wyjściowe w formacie JSON i zwrócić tylko jeden wiersz do przekazania do Vertex AI.
Oto przykład zapytania z użyciem wyszukiwania ANN:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine')) ASC
LIMIT 1)
SELECT json_arrayagg(json_object('product_name',product_name,'description',description,'sale_price',sale_price,'zip_code',zip_code,'product_id',product_id)) FROM trees;
Oto oczekiwany format JSON w danych wyjściowych:
[{"zip_code": 93230, "product_id": "23e41a71d63d8bbc9bdfa1d118cfddc5", "sale_price": 100.00, "description": "Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo", "product_name": "Malus Domestica"}]
Uruchom prompt w Vertex AI Studio
Wygenerowany kod JSON możemy wykorzystać jako część prompta dla modelu generatywnej AI w Vertex AI Studio.
Otwórz prompt w Vertex AI Studio w konsoli Google Cloud.
Może poprosić Cię o włączenie dodatkowych interfejsów API, ale możesz zignorować tę prośbę. Do ukończenia tego laboratorium nie potrzebujemy żadnych dodatkowych interfejsów API.
Wpisz prompt w Studio.
Oto prompt, którego użyjemy:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
A tak wygląda to po zastąpieniu obiektu zastępczego JSON odpowiedzią na zapytanie:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
{"zip_code": 93230, "product_id": "23e41a71d63d8bbc9bdfa1d118cfddc5", "sale_price": 100.00, "description": "Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo", "product_name": "Malus Domestica"}
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
A oto wynik po uruchomieniu promptu z wartościami JSON i modelem gemini-2.5-flash:
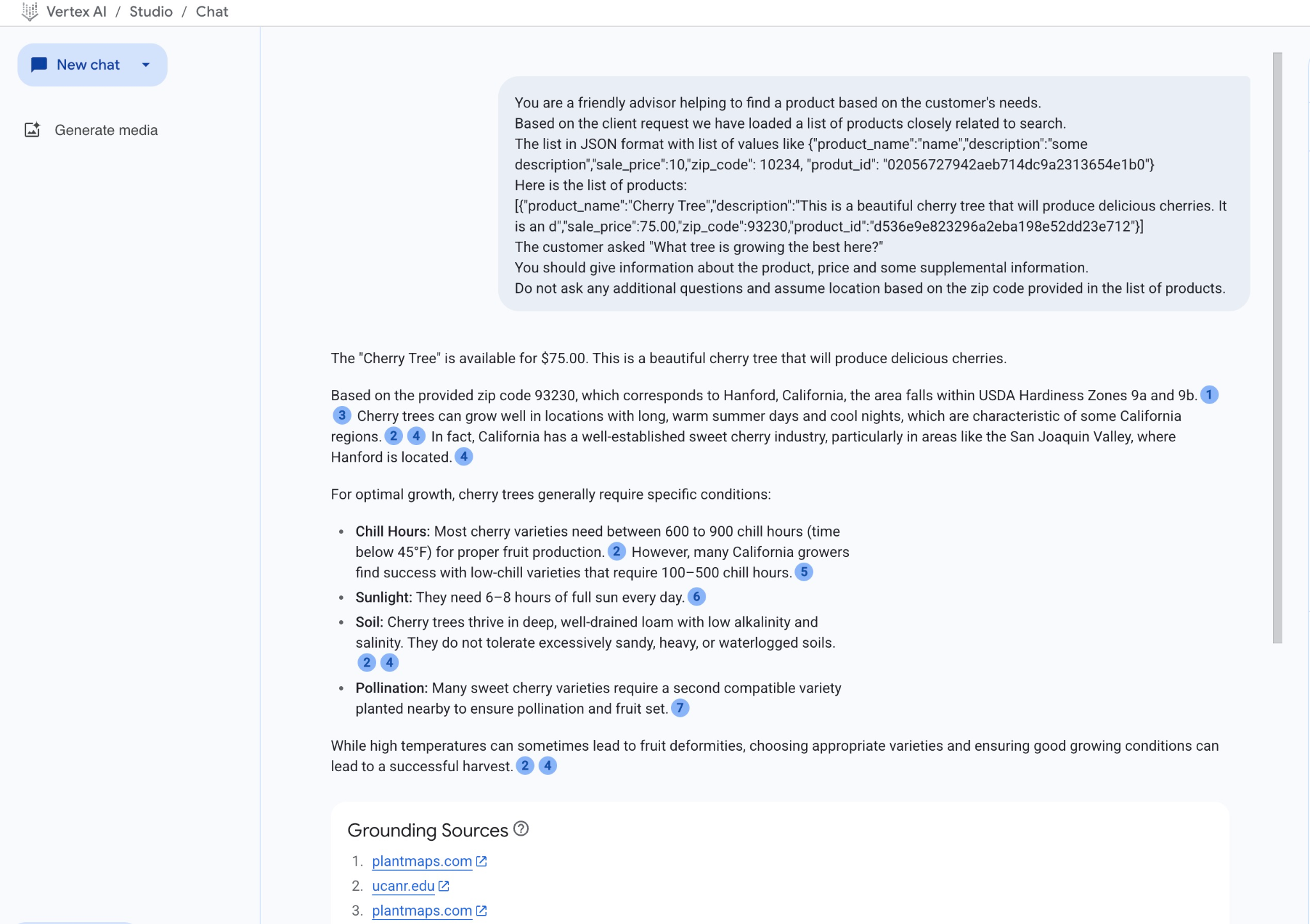
Odpowiedź, którą uzyskaliśmy od modelu w tym przykładzie, została wygenerowana na podstawie wyników wyszukiwania semantycznego i najlepiej dopasowanego produktu dostępnego w podanym kodzie pocztowym.
Uruchamianie prompta w SQL
Możemy też użyć integracji Cloud SQL AI z Vertex AI, aby uzyskać podobną odpowiedź z modelu generatywnego za pomocą SQL bezpośrednio w bazie danych.
Teraz możemy użyć wygenerowanego zapytania w podzapytaniu z wynikami JSON, aby przekazać je jako część promptu do modelu tekstowego generatywnej AI za pomocą SQL.
W sesji mysql lub Cloud SQL Studio w bazie danych uruchom zapytanie
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine')) ASC
LIMIT 1),
prompt AS (
SELECT
CONCAT( 'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:', json_arrayagg(json_object('product_name',trees.product_name,'description',trees.description,'sale_price',trees.sale_price,'zip_code',trees.zip_code,'product_id',trees.product_id)) , 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information') AS prompt_text
FROM
trees),
response AS (
SELECT
mysql.ML_PREDICT_ROW('publishers/google/models/gemini-2.0-flash-001:generateContent',
json_object('contents',
json_object('role',
'user',
'parts',
json_array(
json_object('text',
prompt_text))))) AS resp
FROM
prompt)
SELECT
JSON_EXTRACT(resp, '$.candidates[0].content.parts[0].text')
FROM
response;
Oto przykładowe dane wyjściowe. Wynik może się różnić w zależności od wersji modelu i parametrów:
"Okay, I see you're looking for fruit trees that grow well in your area. Based on the available product, the **Malus Domestica** (Apple Tree) is a great option to consider!\n\n* **Product:** Malus Domestica (Apple Tree)\n* **Description:** This classic apple tree grows to about 30 feet tall and provides beautiful seasonal color with green leaves in summer and fiery colors in the fall. It's known for its strength and provides good shade. Most importantly, it produces delicious apples!\n* **Price:** \\$100.00\n* **Growing Zones:** This particular apple tree is well-suited for USDA zones 4-8. Since your zip code is 93230, you are likely in USDA zone 9a or 9b. While this specific tree is rated for zones 4-8, with proper care and variety selection, apple trees can still thrive in slightly warmer climates. You may need to provide extra care during heat waves.\n\n**Recommendation:** I would recommend investigating varieties of Malus Domestica suited to slightly warmer climates or contacting a local nursery/arborist to verify if it is a good fit for your local climate conditions.\n"
Dane wyjściowe są podawane w formacie Markdown.
10. Tworzenie indeksu najbliższych sąsiadów
Nasz zbiór danych jest stosunkowo mały, a czas odpowiedzi zależy głównie od interakcji z modelami AI. Jednak w przypadku milionów wektorów wyszukiwanie wektorowe może zajmować znaczną część czasu odpowiedzi i mocno obciążać system. Aby to poprawić, możemy utworzyć indeks na podstawie naszych wektorów.
Utwórz indeks ScaNN
Do testu użyjemy typu indeksu ScANN.
Aby utworzyć indeks dla kolumny wektorów dystrybucyjnych, musimy zdefiniować pomiar odległości dla tej kolumny. Szczegółowe informacje o parametrach znajdziesz w dokumentacji.
CREATE VECTOR INDEX cymbal_products_embedding_idx ON cymbal_products(embedding) USING SCANN DISTANCE_MEASURE=COSINE;
Porównaj odpowiedź
Teraz możemy ponownie uruchomić zapytanie w ramach wyszukiwania wektorowego i zobaczyć wyniki.
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Oczekiwane dane wyjściowe:
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ | product_name | description | sale_price | zip_code | distance | +-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ | Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 | | Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 | | Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 | | Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 | | Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 | +-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ 5 rows in set (0.08 sec)
Widzimy, że czas wykonania był tylko nieznacznie inny, ale w przypadku tak małego zbioru danych jest to oczekiwane. Powinno to być znacznie bardziej zauważalne w przypadku dużych zbiorów danych zawierających miliony wektorów.
Plan wykonania możemy sprawdzić za pomocą polecenia EXPLAIN:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
EXPLAIN ANALYZE SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Plan wykonania (fragment):
...
-> Nested loop inner join (cost=443 rows=5) (actual time=1.14..1.18 rows=5 loops=1)
-> Vector index scan on cp (cost=441 rows=5) (actual time=1.1..1.1 rows=5 loops=1)
-> Single-row index lookup on cp using PRIMARY (uniq_id=cp.uniq_id) (cost=0.25 rows=1) (actual time=0.0152..0.0152 rows=1 loops=5)
...
Widzimy, że użyto skanowania indeksu wektorów w tabeli cp (alias tabeli cymbal_products).
Możesz eksperymentować z własnymi danymi lub testować różne zapytania, aby sprawdzić, jak działa wyszukiwanie semantyczne w MySQL.
11. Zwalnianie miejsca w środowisku
Usuwanie instancji Cloud SQL
Po zakończeniu ćwiczenia zniszcz instancję Cloud SQL.
W Cloud Shell zdefiniuj projekt i zmienne środowiskowe, jeśli połączenie zostało przerwane i wszystkie poprzednie ustawienia zostały utracone:
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
Usuń instancję:
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
12. Gratulacje
Gratulujemy ukończenia ćwiczenia.
Ścieżka szkoleniowa Google Cloud
Ten moduł jest częścią ścieżki szkoleniowej dotyczącej AI w Google Cloud gotowej do wdrożenia w środowisku produkcyjnym.
- Poznaj pełny program nauczania, aby przejść od prototypu do produkcji.
- Udostępnij swoje postępy z hashtagiem
#ProductionReadyAI.
Omówione zagadnienia
- Jak wdrożyć instancję Cloud SQL dla PostgreSQL
- Jak utworzyć bazę danych i włączyć integrację Cloud SQL z AI
- Wczytywanie danych do bazy danych
- Jak korzystać z Cloud SQL Studio
- Jak używać modelu wektorów dystrybucyjnych Vertex AI w Cloud SQL
- Jak korzystać z Vertex AI Studio
- Jak wzbogacić wynik za pomocą modelu generatywnego Vertex AI
- Jak poprawić wydajność za pomocą indeksu wektorów
Wypróbuj podobne laboratorium programowania dotyczące AlloyDB lub laboratorium programowania dotyczące Cloud SQL for Postgres
13. Ankieta
Dane wyjściowe: