
1. نظرة عامة
نعرف جميعًا المشاكل التي تسبّبها "البيانات غير المرئية". وهي ملفات PDF وصور وملفات نصية مخزَّنة في حِزم تخزين على السحابة الإلكترونية، ولا يمكن أن تراها استعلامات SQL ولوحات بيانات "إحصاءات النشاط التجاري" على الإطلاق. في السابق، كان الوصول إلى هذه البيانات يتطلّب مسارات تعلُّم معقّدة للتعرّف البصري على الحروف، أو إدخال البيانات يدويًا، أو نصوص برمجية مخصّصة غير مستقرة.
لم يعُد الأمر كذلك.
في هذا التمرين العملي، سأوضّح لك كيفية تحويل 400 ملف PDF غير منظَّم، تتضمّن نصوصًا وجداول وصورًا، إلى جداول BigQuery منظَّمة بشكلٍ واضح مع استنتاج العلاقات بينها تلقائيًا. وسننفّذ ذلك في غضون دقائق باستخدام "كتالوج المعرفة" في BigQuery وDataplex.
ما ستنشئه
لإثبات ذلك، لنلقِ نظرة على نشاط تجاري وهمي: امتياز زبادي مجمّد سريع النمو.
لنفترض أنّك تدير بيانات نشاط Froyo التجاري هذا. لديك المئات من وصفات الطعام وأوراق مواصفات المورّدين، وكلها محفوظة بتنسيق PDF. يريد قادة المؤسسة إطلاق وكيل الذكاء الاصطناعي لمساعدة مدراء المتاجر والعملاء في طلب تفاصيل المنتجات.
إليك السيناريو الأسوأ: يسأل أحد العملاء: "أنا مهتم حقًا بتجربة الزبادي المثلّج بنكهة "Midnight Swirl". هل يحتوي على أي مسبّبات للحساسية؟"
للإجابة عن هذا السؤال، يجب أن يقوم نظامك عادةً بما يلي:
- ابحث عن ملف PDF الخاص بوصفة "دوامة منتصف الليل".
- اقرأ المكوّنات (مثل "مسحوق الكاكاو" و"قاعدة الألبان" و"المستحلب X").
- البحث في عشرات ملفات PDF الخاصة بالمورّدين للعثور على أوراق المواصفات الخاصة بهذه المكوّنات
- راجِع أوراق بيانات المورِّدين بحثًا عن مواد مسبّبة للحساسية مخفية مرتبطة بهذه المكوّنات.
إنّ محاولة إنشاء وكيل مستند إلى الذكاء الاصطناعي ينفّذ هذه العملية بسرعة من خلال قراءة 400 ملف PDF أولي أثناء وقت التشغيل هي عملية بطيئة ومكلفة وعرضة للهلوسة. بدلاً من ذلك، سنستخدم الاستدلال الدلالي لاستخراج كل ذلك في قاعدة بيانات ارتباطية أولاً، ما سيجعل وكيل الذكاء الاصطناعي المستقبلي سريعًا جدًا ومستندًا بنسبة% 100 إلى بيانات SQL الفعلية.
لنبدأ في الإنشاء.
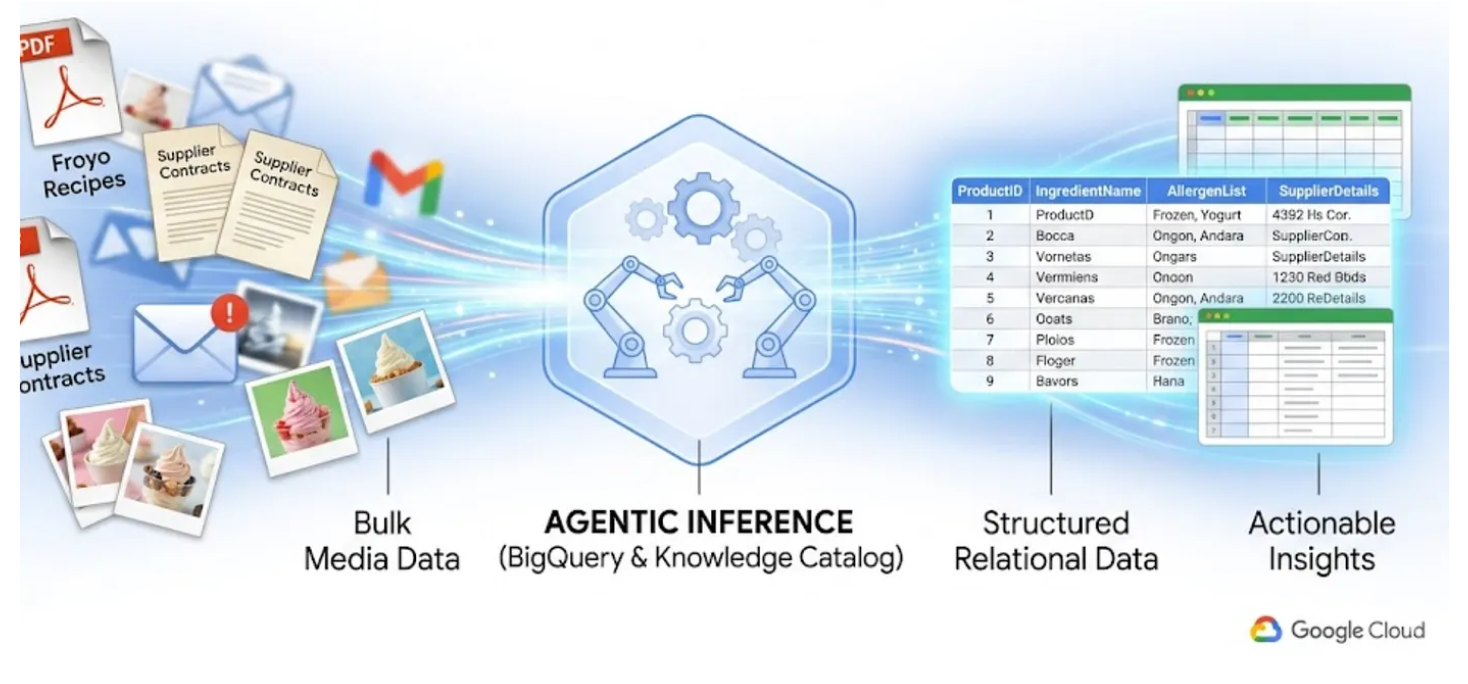
أهداف الدورة التعليمية
- كيفية إعداد حزمة Cloud Storage لملفات المصدر (ملفات PDF)
- كيفية إعداد مهمة Datascan وتشغيلها والاستدلال الدلالي في Knowledge Catalog لاستخراج البيانات من ملفات PDF المصدر والاستدلال دلاليًا على الروابط والسياق وتخزينها في BigQuery
- كيفية استخدام "وكلاء BigQuery" لإجراء محادثة مع مجموعة البيانات التي تم إنشاؤها حديثًا
المتطلبات
2. قبل البدء
إنشاء مشروع
- في Google Cloud Console، ضمن صفحة اختيار المشروع، اختَر أو أنشِئ مشروعًا على Google Cloud.
- تأكَّد من تفعيل الفوترة لمشروعك على Cloud. كيفية التحقّق من تفعيل الفوترة في مشروع
- ستستخدم Cloud Shell، وهي بيئة سطر أوامر تعمل في Google Cloud. انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud".

- بعد الاتصال بـ Cloud Shell، يمكنك التأكّد من إكمال عملية المصادقة وأنّ المشروع مضبوط على معرّف مشروعك باستخدام الأمر التالي:
gcloud auth list
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك.
gcloud config list project
- إذا أردت إثبات ملكية حسابك
gcloud auth login
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- فعِّل واجهات برمجة التطبيقات المطلوبة: نفِّذ الأمر التالي لتفعيل جميع واجهات برمجة التطبيقات المطلوبة:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
المشاكل المحتملة وتحديد المشاكل وحلّها
متلازمة "المشروع الوهمي" | نفّذت الأمر |
حاجز الفوترة | لقد فعّلت المشروع، ولكن نسيت حساب الفوترة. AlloyDB هو محرّك عالي الأداء، ولن يبدأ إذا كان "خزان الوقود" (الفوترة) فارغًا. |
تأخّر في نشر واجهة برمجة التطبيقات | نقرت على "تفعيل واجهات برمجة التطبيقات"، ولكن سطر الأوامر لا يزال يعرض |
Quota Quags | إذا كنت تستخدم حسابًا تجريبيًا جديدًا تمامًا، قد تبلغ حصة إقليمية لمثيلات AlloyDB. إذا تعذّر تنفيذ |
وكيل الخدمة"مخفي" | في بعض الأحيان، لا يتم منح دور |
3- إعداد حزمة Google Cloud Storage
في هذا القسم، ستنشئ بنية تنظيمية ضمن BigQuery لتخزين بيانات وصفة Froyo وبيانات المورّدين، وتحديدًا لتفاصيل منتج Froyo. ويُنشئ أيضًا "عملية ربط بمورد على السحابة الإلكترونية" تعمل كـ "جسر" آمن يتيح لـ BigQuery قراءة الملفات من مصادر خارجية، مثل Cloud Storage.
قبل البدء:
يحتوي هذا المستودع على وصفات وملفات PDF خاصة بالمورّدين سنستخدمها في هذا المشروع. احرص على تنزيل هذه الملفات. لتنزيل الملفات، اتّبِع الخطوات التالية:
في Cloud Shell، نفِّذ الأمر التالي:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
انتقِل إلى المجلد الذي تم إنشاؤه حديثًا:
cd next-26-keynotes
اسحب مجلد data-cloud-demo
git sparse-checkout set genkey/data-cloud-demo
بعد اكتمال عملية الدفع، انتقِل إلى المجلد data-cloud-demo واستخرِج ملفات ZIP للوصول إلى مواد العرض الخاصة بدرس تطبيقي حول الترميز.
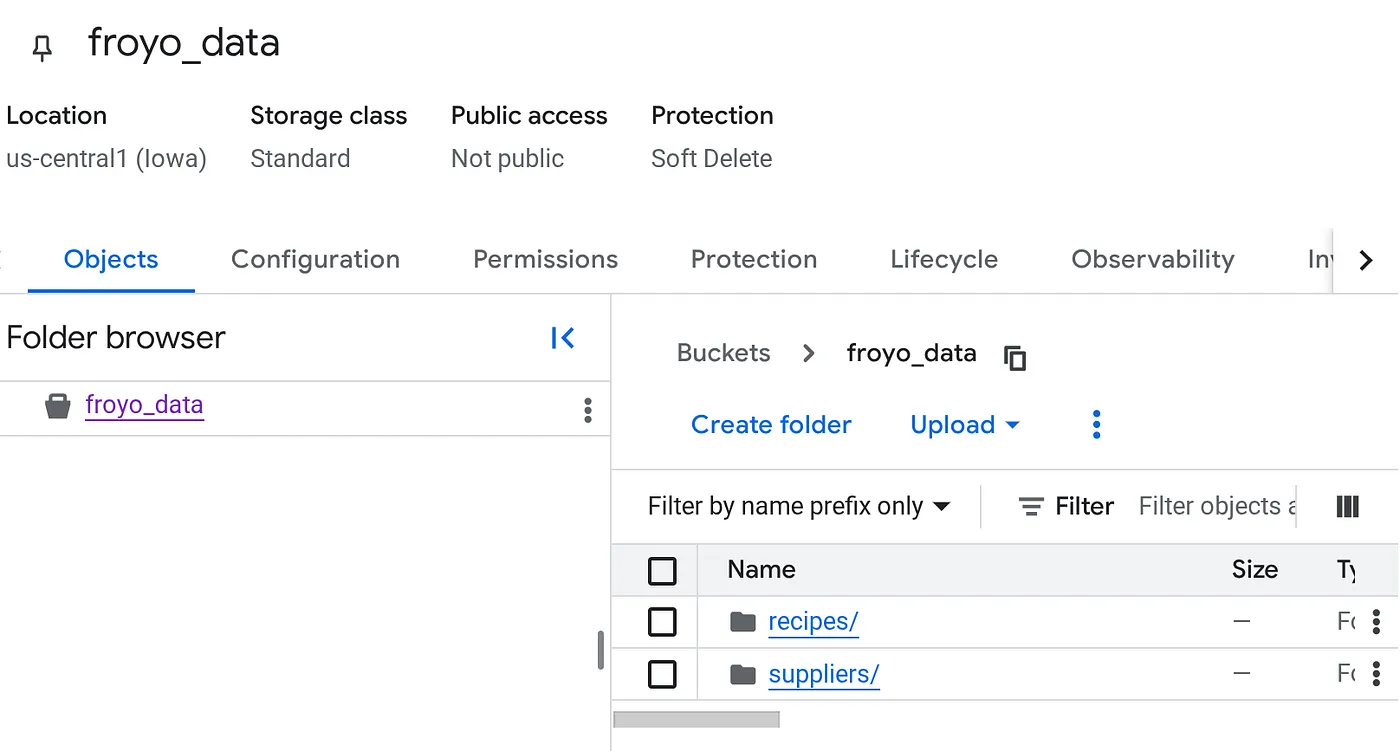
إنشاء حِزمة وتحميل ملفات PDF الخاصة بـ Froyo (الوصفات والمورّدين)
- في Google Cloud Console، انتقِل إلى صفحة حِزم Cloud Storage.
- انقر على "إنشاء".
- في صفحة إنشاء حزمة، أدخِل معلومات الحزمة. بعد كل خطوة من الخطوات التالية، انقر على "متابعة" للانتقال إلى الخطوة التالية:
- في قسم البدء، أدخِل اسم الحزمة. مثال: froyo_data
- في قسم "اختيار مكان تخزين بياناتك"، اختَر "المنطقة" ثم أدخِل منطقتك. us-central1
- في القسم اختيار طريقة التحكّم في الوصول إلى العناصر، أزِل العلامة من مربّع الاختيار "فرض منع الوصول العلني إلى هذه الحزمة" (Enforce public access prevention on this bucket).
- انقر على "إنشاء".
- في قائمة الحِزم، انقر على الحزمة التي أنشأتها.
- في علامة التبويب العناصر الخاصة بالحزمة، انقر على "تحميل" ثم على "تحميل المجلدات".
- اختَر مجلد الوصفات الذي استخرجته في قسم "قبل البدء" من هذا الدرس العملي.
- انقر على "تحميل".
- كرِّر عملية التحميل للمجلد المورّدون.
بعد التحميل، يجب أن تبدو بنية الحزمة على النحو التالي (أو أيًا كان اسم الحزمة):
4. إعداد BigQuery Connection
أنشئ Cloud Resource Connection. يؤدي ذلك إلى إنشاء حساب خدمة فريد يعمل كـ "بطاقة تعريف" لـ BigQuery للوصول إلى الملفات الخارجية.
- انتقِل إلى صفحة BigQuery.
- في اللوحة اليمنى، انقر على "المستكشف". إذا لم يظهر الجزء الأيمن، انقر على "توسيع الجزء الأيمن" لفتحه.
- في جزء "المستكشف"، وسِّع اسم مشروعك، ثم انقر على "عمليات الربط".
- في صفحة "عمليات الربط"، انقر على "إنشاء عملية ربط".
- بالنسبة إلى "نوع الاتصال"، اختَر "نماذج Vertex AI البعيدة" و"الدوال البعيدة" وBigLake وSpanner (مورد السحابة الإلكترونية).
- في حقل "رقم تعريف الاتصال"، أدخِل اسم رقم تعريف الاتصال:
- bq-connection. احرص على تدوين رقم التعريف هذا لأنّك ستحتاج إليه عند إعداد عملية فحص البيانات لاحقًا في هذا الدرس التطبيقي حول الترميز.
- اضبط "نوع الموقع الجغرافي" على "منطقة"، ثم اختَر منطقة. على سبيل المثال، us-central1. يجب أن يكون الاتصال في المنطقة نفسها التي تتوفّر فيها مواردك الأخرى، مثل مجموعات البيانات.
- انقر على "إنشاء عملية ربط".
- انقر على "الانتقال إلى عملية الربط".
- في لوحة "معلومات الاتصال"، انسخ رقم تعريف حساب الخدمة لاستخدامه في خطوة لاحقة. يبدو حساب الخدمة مشابهًا لما يلي: bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
5- إعداد الأذونات
- منح الأذونات اللازمة لعملية ربط BigQuery من أجل الوصول إلى عناصر Cloud Storage وKnowledge Catalog
انتقِل إلى صفحة "إدارة الهوية وإمكانية الوصول" (IAM) وفي قسم "العرض حسب الجهات الرئيسية"، انقر على الزر "منح إذن الوصول"، ثم أضِف جهة رئيسية عن طريق لصق حساب الخدمة الذي نسخته في الخطوة الأخيرة. في قسم الأدوار، أضِف أسماء الأدوار التالية واحدًا تلو الآخر واحفظها:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- منح حساب خدمة Dataplex أذونات الوصول إلى حزمة Cloud Storage
انتقِل إلى صفحة إدارة الهوية وإمكانية الوصول (IAM)، وفي قسم العرض حسب الجهات الرئيسية، انقر على زر منح إذن الوصول وأضِف جهة رئيسية عن طريق كتابة الكلمة dataplex في شريط النص "جهة رئيسية جديدة". من القائمة التي يتم إكمالها تلقائيًا، اختَر مدير حساب خدمة Dataplex الذي يبدو مشابهًا لما يلي: (استخدِم رقم المشروع وليس رقم تعريف المشروع في رقم تعريف البريد الإلكتروني لحساب الخدمة أدناه)
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
إذا لم يتم التعرّف على حساب الخدمة أعلاه لرقم مشروعك لأي سبب من الأسباب، قد يكون ذلك ببساطة لأنّ المشروع لم يبدأ بعد في تهيئة خدمة Dataplex. انتقِل إلى "وحدة Cloud Shell الطرفية" وحاوِل تفعيل واجهة برمجة التطبيقات (إذا لم يتم ذلك في مرحلة قبل البدء) من خلال تنفيذ الأمر التالي: gcloud services enable dataplex.googleapis.com
حتى بعد ذلك، إذا لم يتم التعرّف على حساب الخدمة في Dataplex، عليك فرض إنشاء مهمة فحص Dataplex تجريبية في صفحة "تنظيم البيانات الوصفية" وإدخال التفاصيل في صفحة إنشاء مهمة Discover:
انقر على تشغيل الآن. ستتعذّر المهمة، ولكن سيضمن ذلك تهيئة معرّف حساب الخدمة لخدمة Dataplex الآن.
ارجع إلى صفحة إدارة الهوية وإمكانية الوصول (IAM)، وفي قسم العرض حسب الجهات الرئيسية، انقر على زر منح إذن الوصول، ثم انقر على "إضافة جهة رئيسية". الصِق حساب الخدمة:
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
بعد ذلك، امنح حساب الخدمة هذا الأدوار التالية:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. إعداد "كتالوج المعارف"
إنشاء "كتالوج معلومات" لتوحيد البيانات غير المنظَّمة وأتمتة عملية العثور على الملفات غير المنظَّمة (مثل وصفات PDF والمورّدين الذين يستخدمون PDF)
إنشاء مهمة DataScan من وحدة التحكّم:
- انتقِل إلى صفحة إدارة البيانات الوصفية.
- انقر على "إنشاء" وأدخِل التفاصيل المتعلّقة بإعدادك:
ملاحظة مهمة: لا تنسَ وضع علامة في المربّع بجانب "تفعيل الاستدلال الدلالي".
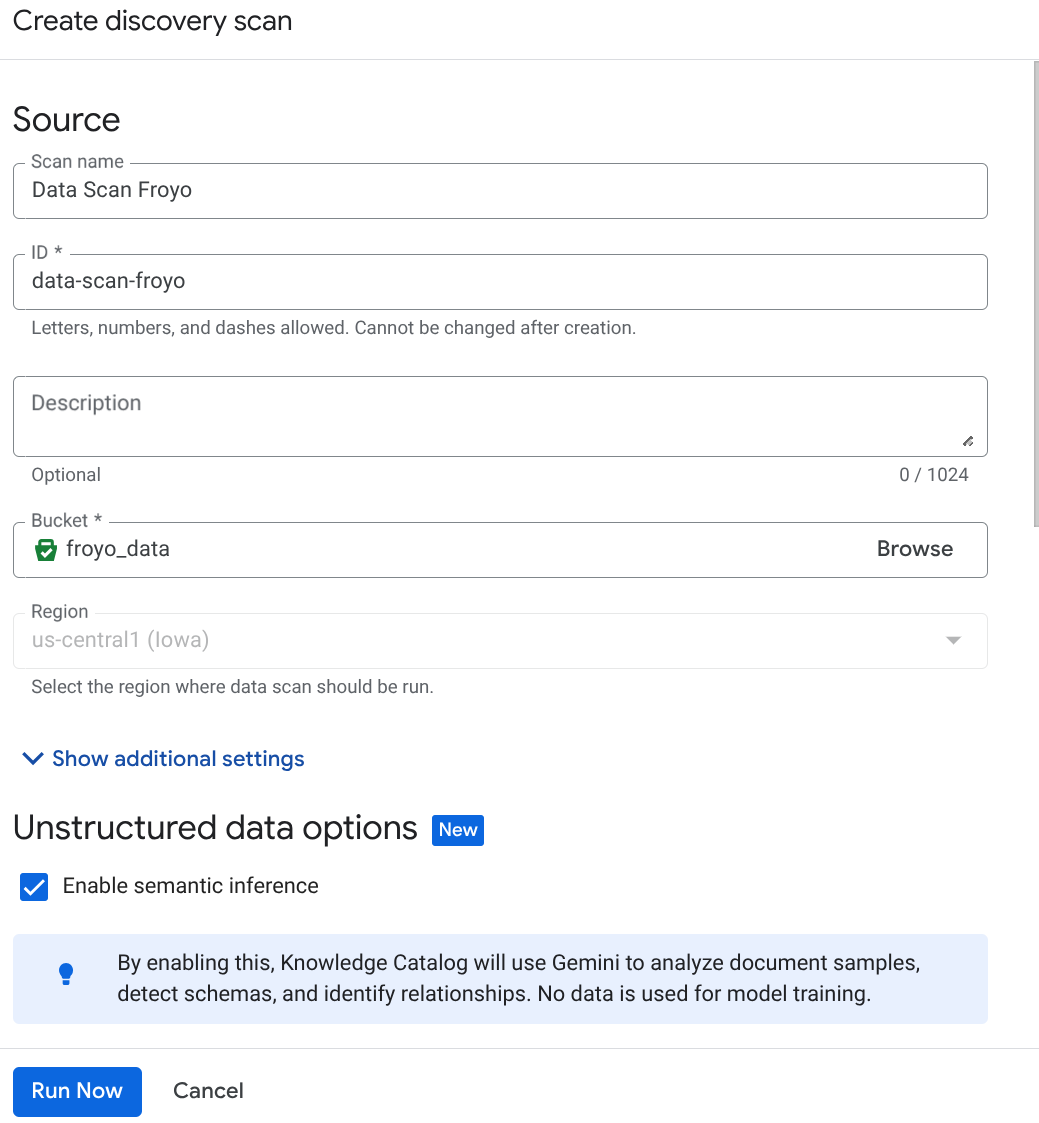
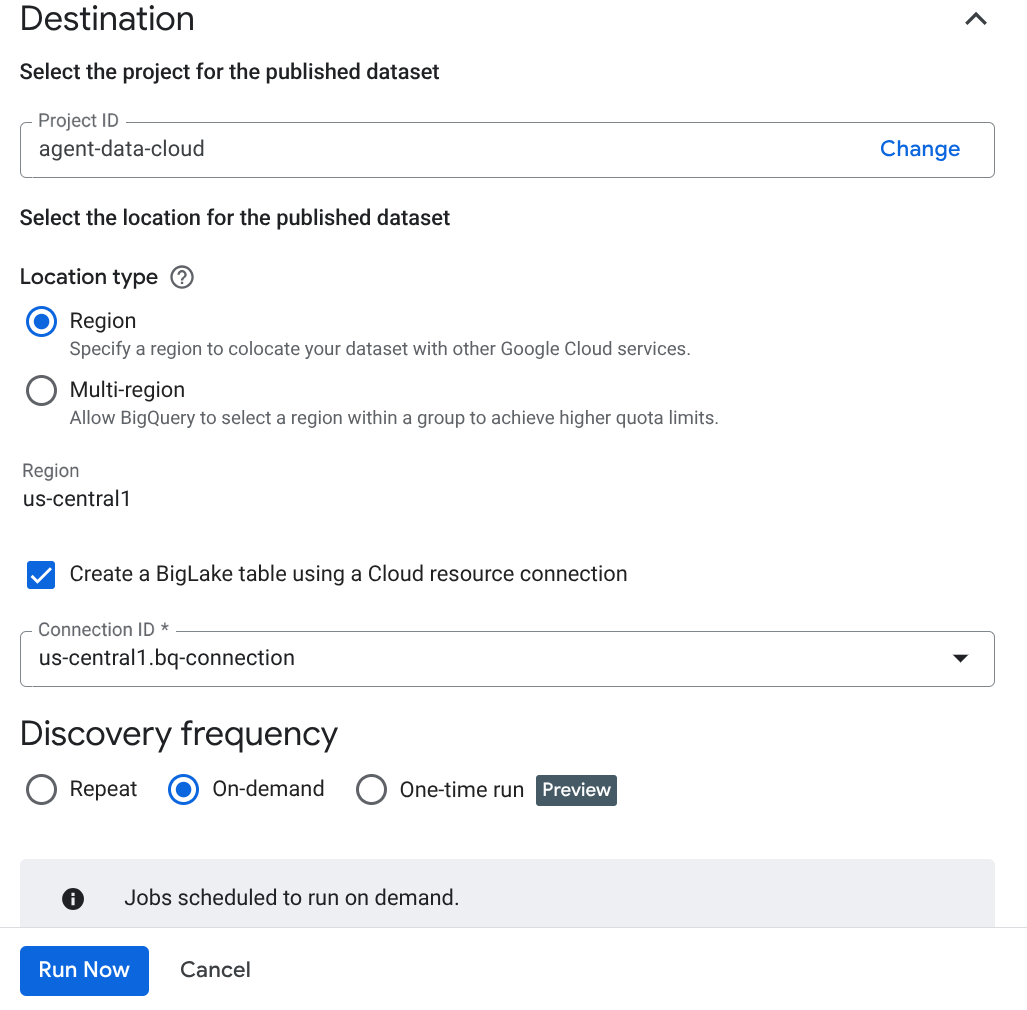
- انقر على "التشغيل الآن".
- سيستغرق إكمال مهمة البحث بعض الوقت. بعد انتهاء المهمة، تحقَّق ممّا إذا كانت مجموعة البيانات المنشورة متوفّرة. للاطّلاع على حالة المهمة، يمكنك الانتقال إلى صفحة تنظيم البيانات الوصفية، ثم النقر على اسم عمليات البحث الأخيرة في علامة التبويب "استكشاف Cloud Storage". من المفترض أن تظهر لك مجموعة البيانات المنشورة كما هو موضّح أدناه:
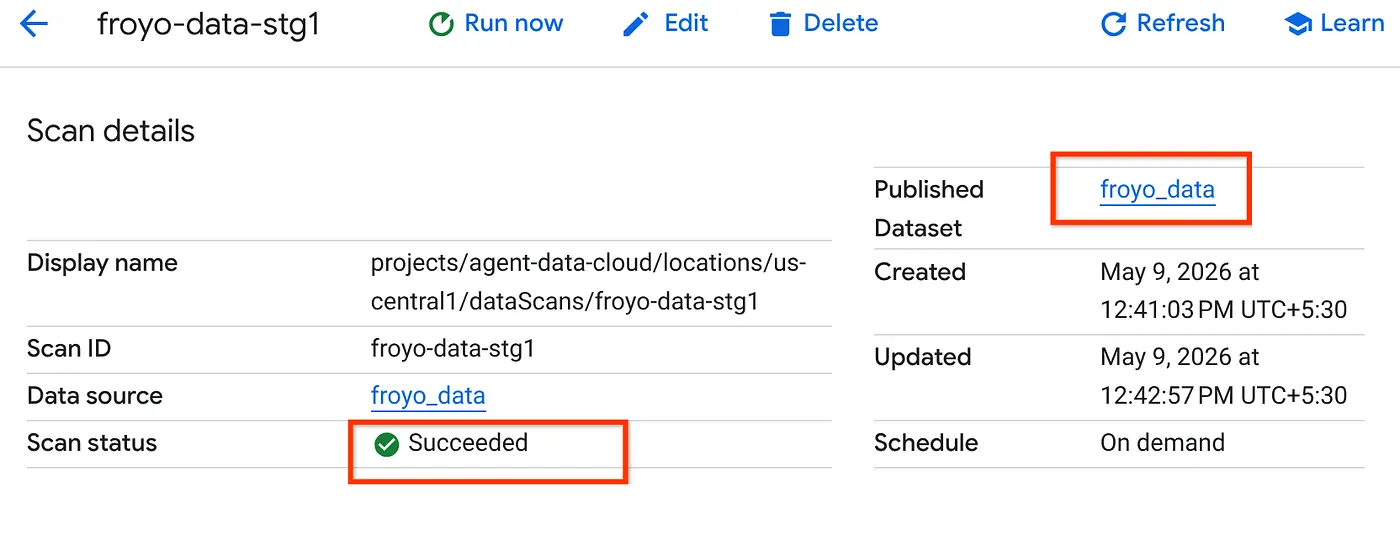
ملاحظة: إذا واجهت أخطاء في خطوة الفحص، ما عليك سوى الانتظار بعض الوقت ثم إعادة المحاولة (يستغرق إنشاء المهمة وإكمال تنفيذها بضع دقائق).
- يمكنك عرض الجدول في BigQuery من خلال النقر على مجموعة بيانات froyo_data والانتقال إليها. انقر على معرّف الجدول في BigQuery ونفِّذ الاستعلام أدناه في علامة التبويب "محرّر الطلبات":
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
سيؤدي ذلك إلى ظهور الرمز 400 (إذا لم يظهر، يمكنك الرجوع وتشغيل مهمة Datascan مرة أخرى).
7. استخراج البيانات الدلالية
رائع!! لنستخرِج الآن الاستنتاج الخاص بهذه العناصر غير المنظَّمة باستخدام "كتالوج المعارف".
سنستخدم ميزة "الإحصاءات" لإنشاء عبارات SQL لاستخراج البيانات المنظَّمة من الجدول غير المنظَّم.
- في Google Cloud Console، انتقِل إلى صفحة بحث في "كتالوج المعرفة".
- ابحث عن جدول مجموعة البيانات الذي تريد الاطّلاع على الإحصاءات الخاصة به. في شريط البحث، أدخِل اسم مجموعة البيانات أو الجدول من الخطوة السابقة: "froyo_data" واضغط على مفتاح Enter.
- من قائمة النتائج، انقر على إدخال الجدول (وليس مجموعة البيانات).
- من المفترض أن تظهر لك علامة التبويب الإحصاءات. انقر على ذلك (إذا كان يتطلّب منك تفعيل أي واجهة برمجة تطبيقات، اتّبِع التعليمات وفعِّل واجهات برمجة التطبيقات).
إذا انتهى بك الأمر بتفعيل واجهات برمجة التطبيقات في هذه المرحلة، عليك إعادة تشغيل مهمة الفحص مرة أخرى.
- في علامة التبويب "الإحصاءات"، سترى القائمة المنسدلة للزر "استخراج". انقر على ذلك الخيار وحدِّد الخيار "استخراج باستخدام SQL".
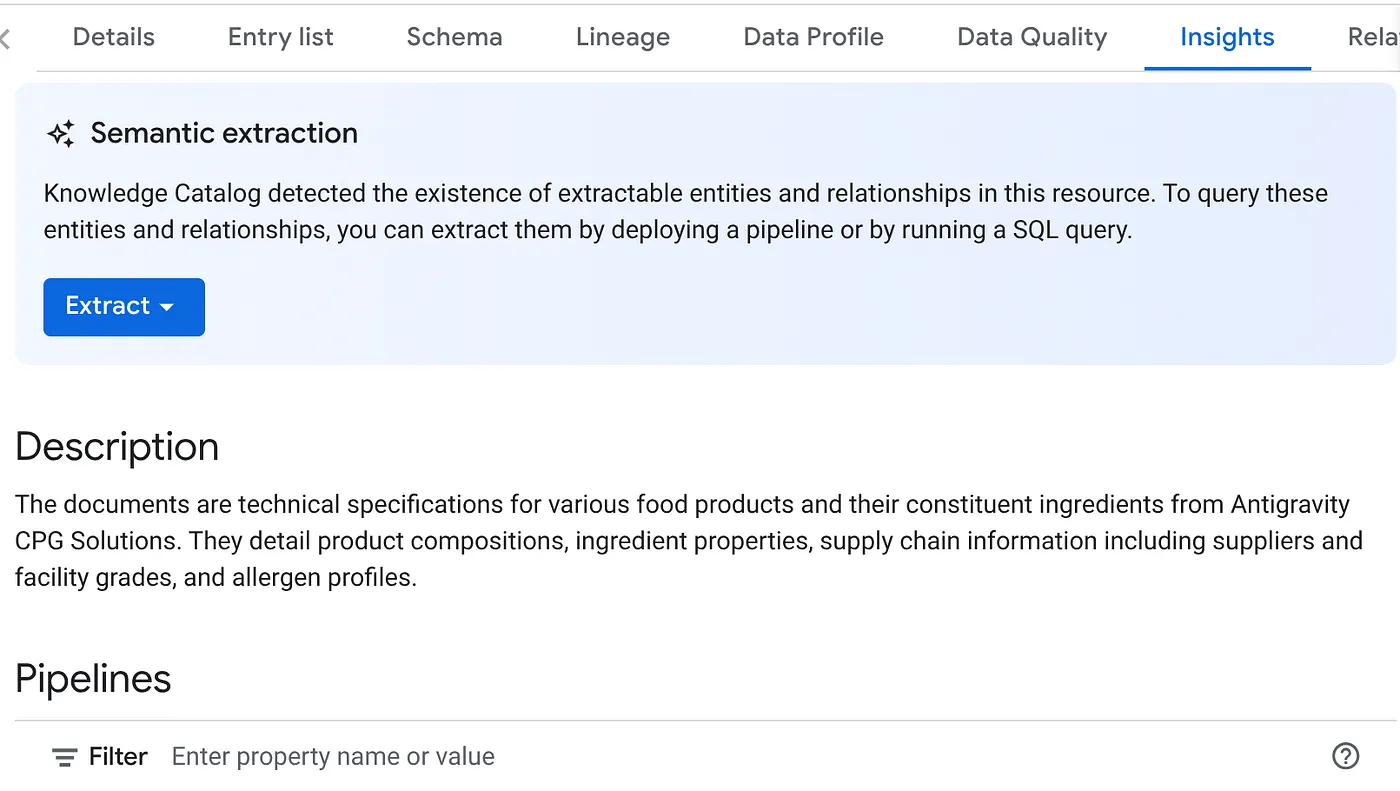
في مربّع الحوار المنبثق استخراج باستخدام SQL، اضبط مجموعة بيانات DESTINATION على المجموعة التي رأيتها في نتيجة مهمة Datascan. ابدأ بكتابة اسمه وسيظهر في ميزة الإكمال التلقائي. انقر على الزر استخراج. يمكنك بدلاً من ذلك إنشاء مجموعة بيانات جديدة في هذه المرحلة واستخراجها.
من المفترض أن يؤدي ذلك إلى فتح "أداة تحرير الطلبات" في BigQuery مع فتح علامة تبويب تتضمّن لغة SQL المستخرَجة من استنتاج فحص البيانات.
8. التحقّق من صحة SQL وإنشاء المخطط
إذا بدا طلب البحث الذي تم إنشاؤه جيدًا ومناسبًا من الناحية الدلالية لبياناتك غير المنظَّمة، يمكنك المتابعة وتشغيله من خلال النقر على الزر "تشغيل" في محرّر طلب البحث. سيستغرق إنشاء المخطط المطلوب للتخزين المنظَّم للوسائط غير المنظَّمة بضع دقائق.
بعد الانتهاء، يجب أن تتمكّن من التحقّق من المخطط عن طريق توسيع مجموعة البيانات في جزء المستكشف في BigQuery Studio كما هو موضّح أدناه:
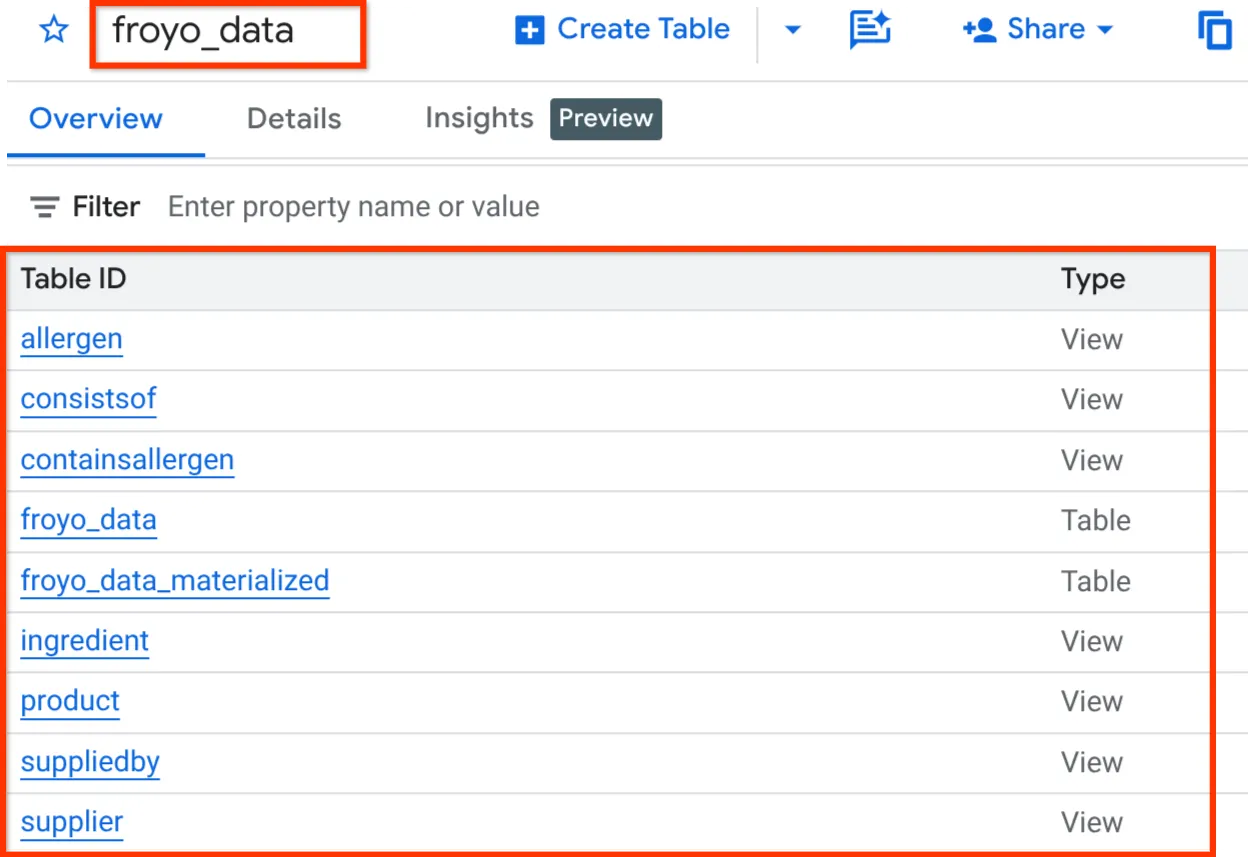
حسنًا!!! كان من الرائع أن نتمكّن من تنفيذ كل عمليات قاعدة البيانات هذه بسرعة كبيرة. حان الوقت الآن للاختبار النهائي.
خطوات مواصلة تجربة البيانات بدون حساب الفوترة:
- يمكنك الحصول على ملفات csv (بيانات BigQuery) من رابط المستودع على GitHub أعلاه.
- أولاً، أنشئ مجموعة بيانات BigQuery من خلال تنفيذ الأمر التالي من Cloud Shell Terminal:
bq mk --location us-central1 --dataset froyo_data
- بعد ذلك، نزِّل ملفات البيانات الثمانية (ملفات csv) من مستودع github إلى دليل العمل عن طريق تنفيذ الأوامر التالية واحدًا تلو الآخر:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- نفِّذ الأوامر التالية واحدًا تلو الآخر لإنشاء هذه الجداول باستخدام البيانات في مجموعة البيانات التي أنشأتها حديثًا
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
بعد إنشاء مجموعة البيانات والجداول والبيانات، يمكنك المتابعة لاختبار البيانات التي ناقشناها وتجربتها.
9. الاختبار النهائي!!!
لنفترض أنّني أريد أن يردّ الوكيل على أسئلة المستخدم بمعلومات حقيقية وكاملة ومنظَّمة بشكل جيد تستند إلى الحقائق. سأطرح سؤالاً لا يمكن للوكيل الإجابة عنه إلا بالرجوع إلى ملفات وسائط ومراجع متعددة من المصدر.
إليك سؤال المستخدم:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
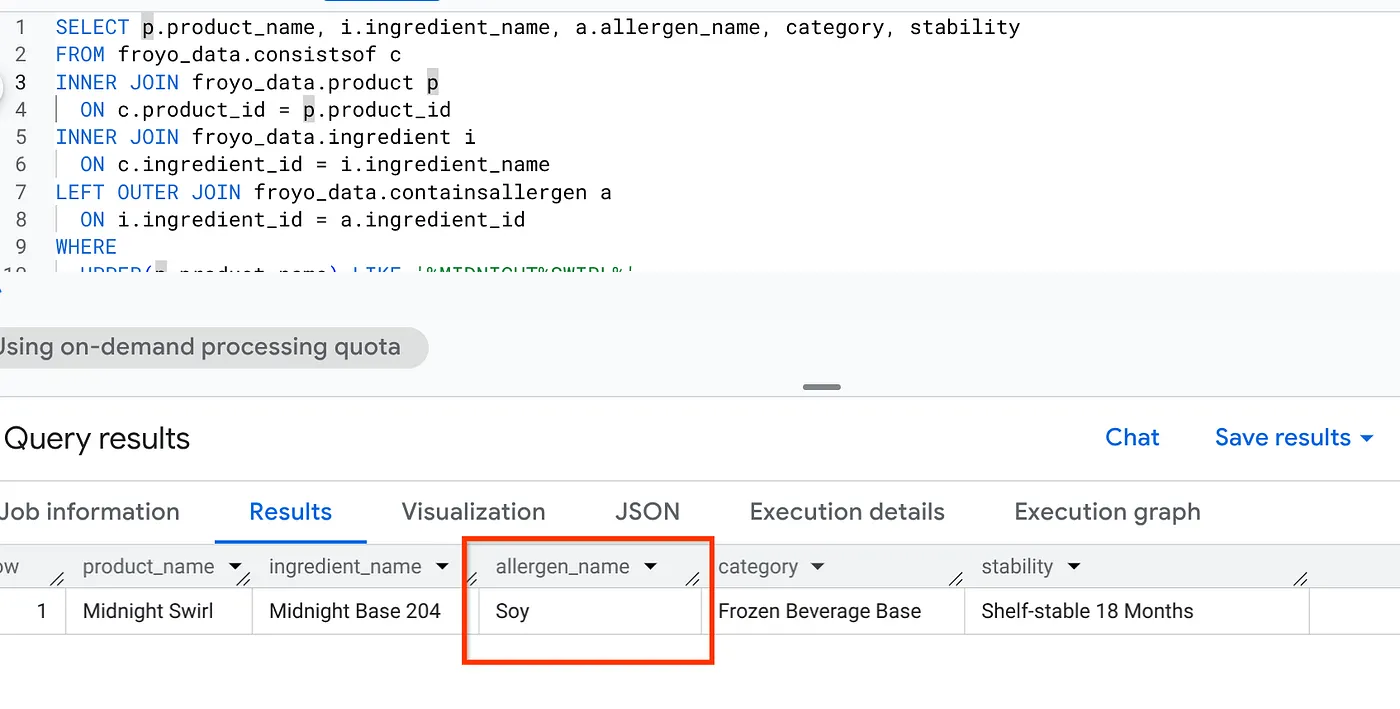
سيظهر الآن الردّ "لا تتضمّن أي مكوّنات" عند إجراء عملية بحث عامة أو بحث باستخدام نموذج لغوي كبير. ولكننا أنشأنا استنتاجًا دلاليًا كاملاً يحوّل جميع الوسائط غير المنظَّمة إلى بيانات منظَّمة. إليك مثال على ذلك باستخدام طلب بحث بسيط بلغة SQL سيجلب هذه المعلومات:
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
رائع! اطّلِع على النتيجة:
10. تَنظيم
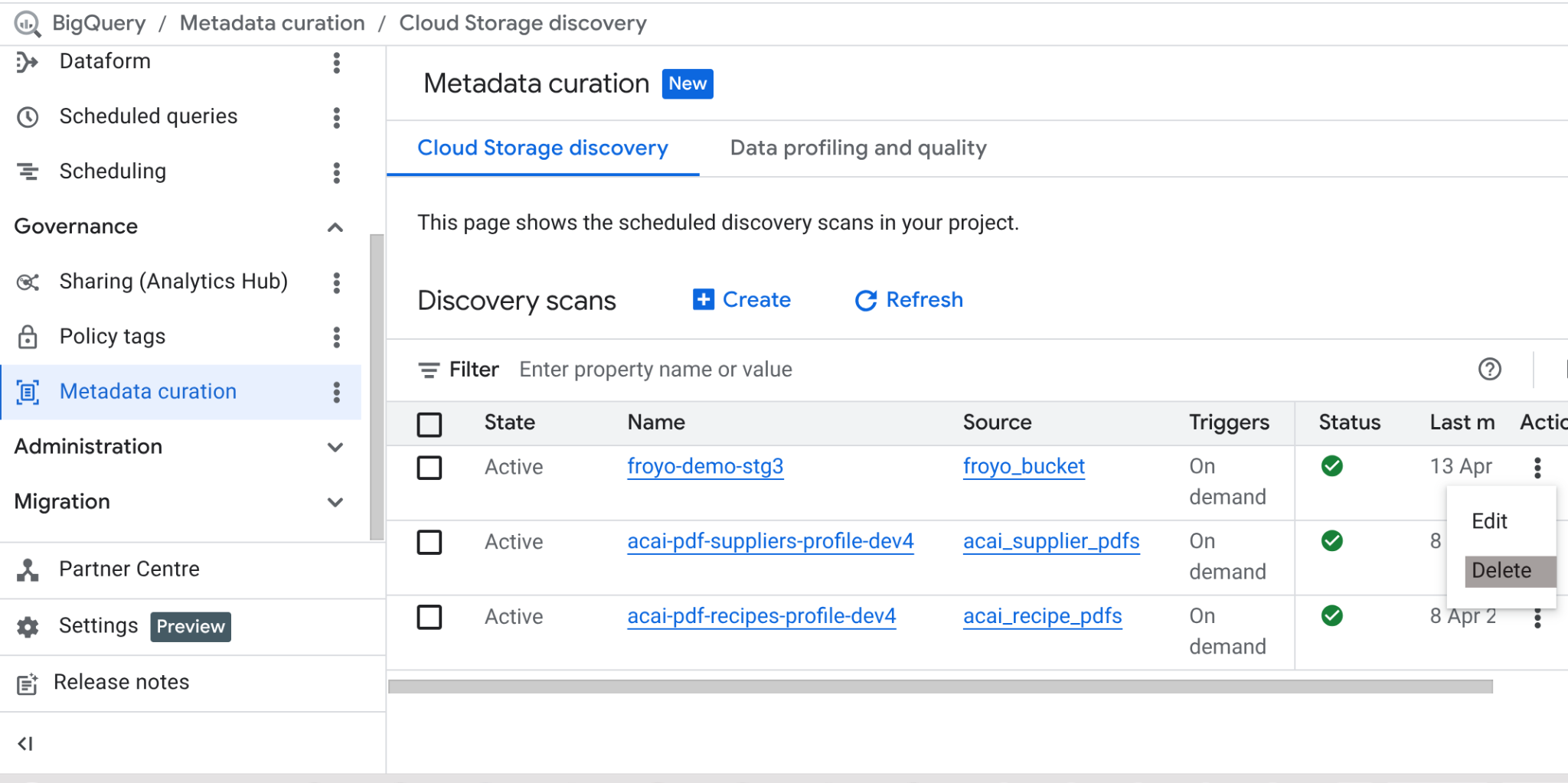
بعد الانتهاء من هذا الدرس العملي، لا تنسَ حذف مهمة الفحص وجداول BigQuery التي أنشأتها المهمة.
انتقِل إلى https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery. اختَر المهمة التي تريد حذفها من خلال النقر على علامة الحذف العمودية بجانبها، ثم انقر على "حذف".
من المفترض أن يؤدي ذلك إلى تنظيف الوظيفة.
11. تهانينا
تمكّن تطبيقنا بنجاح من تحديد مادة مسبّبة للحساسية مخفية. لا مزيد من البيانات غير الواضحة، أيها الناس!!! في الجزء 2، سنوحّد بيانات BigQuery هذه في نظام معاملات مع AlloyDB لتلبية احتياجات البيانات في تطبيقنا المستند إلى الوكلاء.