
1. نظرة عامة
في الجزء 1، نجحنا في تحويل ملفات PDF غير منظَّمة وغير مرتبة إلى جداول منظَّمة وذكية ومرتبة في BigQuery باستخدام Knowledge Catalog وDataScan. والآن، أصبح لدينا مستودع بيانات قوي.
إذا كنت بحاجة إلى تذكير سريع، في الجزء الأول من المختبر، تناولنا حالة استخدام لسلسلة امتيازات وهمية لبيع الزبادي المثلّج، وحوّلنا 400 ملف PDF غير منظَّم يتضمّن نصوصًا وجداول وصورًا إلى جداول BigQuery منظَّمة بشكلٍ واضح مع استنتاج العلاقات بينها تلقائيًا باستخدام BigQuery Knowledge Catalog وDataplex.
ما ستنشئه
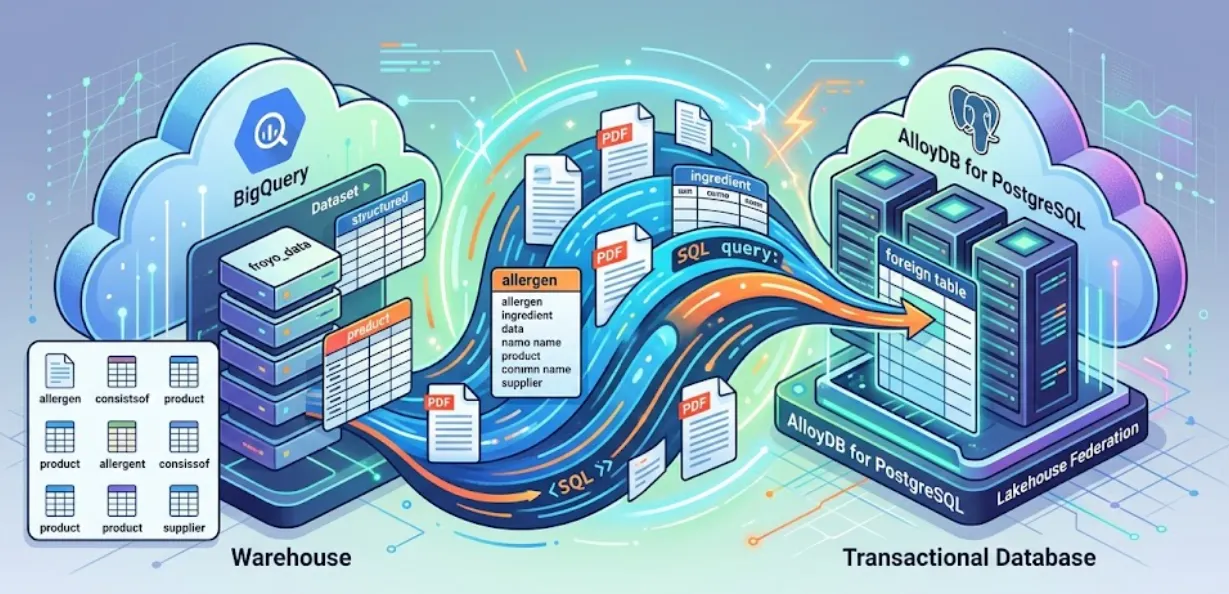
في هذه الجلسة، سنعمل على إعداد AlloyDB for PostgreSQL وتنفيذ عملية سحرية، وهي دمج بيانات BigQuery مباشرةً في AlloyDB. وهذا يعني أنّ تطبيقنا الخاص بالمعاملات يمكنه طلب بيانات المستودع في الوقت الفعلي، بدون نسخ أيّ منها أو تكرارها.
يجب أن يطرح المطوِّر السؤال التالي في هذه المرحلة:
"إذا كانت البيانات متوفّرة في BigQuery، لماذا يتم استخدام AlloyDB؟ لماذا لا ينفّذ التطبيق عبارة SELECT مباشرةً في BigQuery؟"
إليك السبب:
باستخدام Lakehouse Federation، يمكنك استخدام محرّك طلبات البحث في AlloyDB لتشغيل أحمال العمل المعاملاتية والتحليلية لتطبيقك من داخل الواجهة نفسها. يمكنك أيضًا إنشاء نسخة مادية من هذه البيانات أو استيرادها إلى AlloyDB للوصول إليها بشكل أسرع واستخدامها في تطبيقاتك، ما يتيح لك استخدام AlloyDB AI ومحرك الأعمدة.
يمكنك استخدام AlloyDB كقاعدة بيانات معاملات، ويمكنك أيضًا تخزين كميات كبيرة من البيانات في BigQuery أو BigLake. تتكامل تطبيقاتك عادةً بشكل مستقل مع كلا النظامين للوصول إلى البيانات على مستوى خدمات Google Cloud المختلفة هذه. تتيح لك ميزة Lakehouse Federation for AlloyDB استخدام ميزة طلب البحث الموحّد في AlloyDB التي تم تنفيذها كبرنامج تضمين لبيانات خارجية للوصول إلى بيانات BigQuery وAlloyDB باستخدام واجهة SQL في AlloyDB.
بدلاً من إنشاء مسار ETL هشّ للاستعلام عن بيانات BigQuery من AlloyDB، سنستخدم الاستعلامات الموحّدة. ستعمل AlloyDB كنقطة نهاية موحّدة، ما يتيح الوصول بسلاسة إلى BigQuery عند الحاجة.
لنبدأ في إنشاء التطبيق.
أهداف الدورة التعليمية
- كيفية إعداد مجموعة AlloyDB ومثيل AlloyDB والشبكات بنقرة زر واحدة
- كيفية إعداد إضافة للاستعداد لعملية الاتحاد
- كيفية إعداد الاتحاد من BigQuery إلى AlloyDB
- تجربة الميزة
المتطلبات
2. قبل البدء
إنشاء مشروع
- في Google Cloud Console، ضمن صفحة اختيار المشروع، اختَر أو أنشِئ مشروعًا على Google Cloud.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. كيفية التحقّق من تفعيل الفوترة في مشروع
- ستستخدم Cloud Shell، وهي بيئة سطر أوامر تعمل في Google Cloud. انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud".

- بعد الاتصال بـ Cloud Shell، يمكنك التأكّد من إكمال عملية المصادقة وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك.
gcloud config list project
- إذا أردت إثبات ملكية حسابك
gcloud auth login
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- فعِّل واجهات برمجة التطبيقات المطلوبة: نفِّذ الأمر التالي لتفعيل جميع واجهات برمجة التطبيقات المطلوبة:
gcloud services enable alloydb.googleapis.com
المشاكل المحتملة وتحديد المشاكل وحلّها
متلازمة "المشروع الوهمي" | نفّذت الأمر |
حاجز الفوترة | لقد فعّلت المشروع، ولكن نسيت حساب الفوترة. AlloyDB هو محرّك عالي الأداء، ولن يبدأ إذا كان "خزان الوقود" (الفوترة) فارغًا. |
تأخّر انتشار واجهة برمجة التطبيقات | نقرت على "تفعيل واجهات برمجة التطبيقات"، ولكن سطر الأوامر لا يزال يعرض |
Quota Quags | إذا كنت تستخدم حسابًا تجريبيًا جديدًا تمامًا، قد تبلغ حصة إقليمية لمثيلات AlloyDB. إذا تعذّر تنفيذ |
3- ملخّص سريع للبيانات من الجزء 1
في هذا القسم، عليك التأكّد من أنّ البيانات المنظَّمة التي استخرجناها من ملفات PDF غير المنظَّمة متوفّرة في BigQuery. إذا فاتك الجزء الأول أو لم يكن لديك حساب فوترة، لا بأس، يمكنك إكمال الخطوات التالية والبدء:
انتقِل إلى Google Cloud Console من حسابك الشخصي على Gmail وانقر على الزر "تفعيل Cloud Shell" في أعلى يسار وحدة التحكّم:
بعد ذلك، اتّبِع الخطوات الواردة في قسم "لا يوجد حساب فوترة" أدناه:
خطوات مواصلة تجربة البيانات بدون حساب الفوترة:
- يمكنك الحصول على ملفات csv (بيانات BigQuery) من رابط المستودع على GitHub أعلاه.
- أولاً، أنشئ مجموعة بيانات BigQuery من خلال تنفيذ الأمر التالي من Cloud Shell Terminal:
bq mk --location us-central1 --dataset froyo_data
- بعد ذلك، نزِّل ملفات البيانات الثمانية (ملفات csv) من مستودع github إلى دليل العمل عن طريق تنفيذ الأوامر التالية واحدًا تلو الآخر:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- نفِّذ الأوامر التالية واحدًا تلو الآخر لإنشاء هذه الجداول باستخدام البيانات في مجموعة البيانات التي أنشأتها حديثًا
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
بعد أن أصبحت البيانات متوفّرة في BigQuery، لننتقل إلى الخطوات التالية.
4. إعداد مجموعة ومثيل وشبكة AlloyDB
يتوفّر تطبيق سريع التشغيل مستند إلى الويب يساعدك في إعداد مجموعة AlloyDB ومثيل AlloyDB والتبعيات الأخرى. يمكنك اتّباع الخطوات من 2 إلى 4 في هذا المختبر لإعدادها بنقرة زر:
https://codelabs.developers.google.com/quick-alloydb-setup
بعد إنشاء مجموعتك، انتقِل إلى صفحة "نظرة عامة على المجموعة" وانسخ تفاصيل حساب الخدمة من هناك.
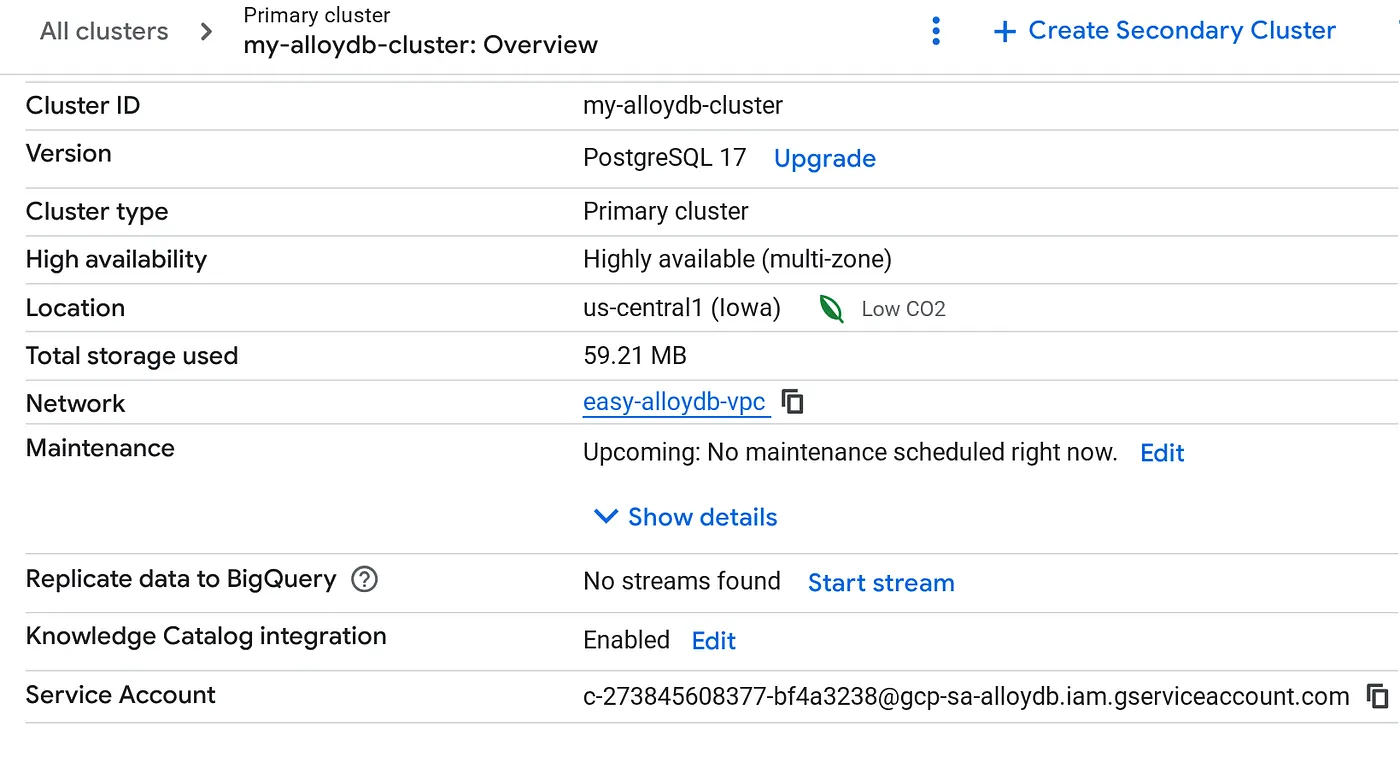
5- إعداد الأذونات
منح أذونات BigQuery لحساب الخدمة هذا
- انتقِل إلى "إدارة الهوية وإمكانية الوصول والمشرف" > "إدارة الهوية وإمكانية الوصول".
- انقر على "منح إذن الوصول".
- ألصِق عنوان حساب خدمة AlloyDB في حقل "الجهات الرئيسية الجديدة".
- عيِّن الأدوار التالية:
- عارِض بيانات في BigQuery (roles/bigquery.dataViewer): يتيح قراءة البيانات.
- مستخدِم BigQuery (roles/bigquery.user): يتيح تنفيذ طلبات البحث.
- (اختياري ولكن يُنصح به) مستخدم جلسة القراءة في BigQuery (roles/bigquery.readSessionUser): يحسّن قراءة مجموعات البيانات الكبيرة من خلال Storage Read API.
6. الربط بـ AlloyDB وتفعيل إضافة BigQuery
الآن، نتصل بنسخة AlloyDB الجديدة لضبط إضافة الاتحاد. سنستخدم AlloyDB Studio لهذا الغرض.
- من صفحة "نظرة عامة على المجموعة" (وحدة تحكّم AlloyDB)، انقر على تعديل الأساسي في مثيلك الأساسي وانتقِل إلى أسفل الصفحة إلى خيارات الإعداد المتقدّمة.
- انتقِل إلى قسم "العلامات" وفعِّل العلامتَين على "مفعّلة" كما هو موضّح أدناه:
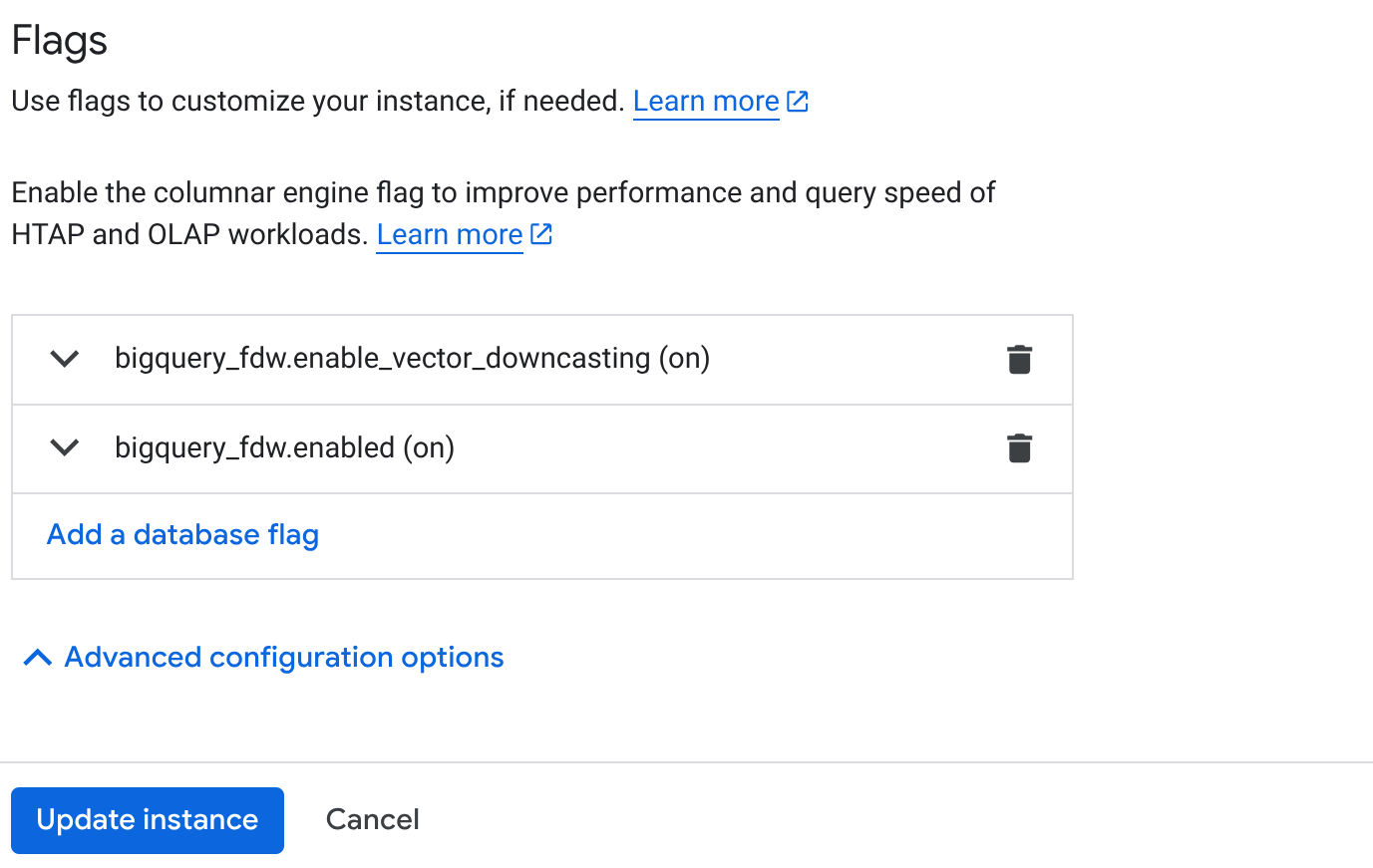 3. انقر على الزر تعديل الجهاز الظاهري، وسيستغرق إكمال التعديل بضع دقائق. 4. من صفحة "نظرة عامة على المجموعة" (Cluster Overview) (وحدة تحكّم AlloyDB)، انقر على AlloyDB Studio.
3. انقر على الزر تعديل الجهاز الظاهري، وسيستغرق إكمال التعديل بضع دقائق. 4. من صفحة "نظرة عامة على المجموعة" (Cluster Overview) (وحدة تحكّم AlloyDB)، انقر على AlloyDB Studio.
- اتّصِل بقاعدة البيانات واسم المستخدم وكلمة المرور اللذين ضبطتهما في خطوة "الإعداد السريع" في AlloyDB.
- بعد الربط، في علامة التبويب "محرّر طلب البحث" على يسار الصفحة، أدخِل العبارات التالية وشغِّلها واحدةً تلو الأخرى:
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- بعد الانتهاء بنجاح، انتقِل إلى جزء المستكشف على يمين الصفحة وانتقِل للأسفل إلى جداول BigQuery:
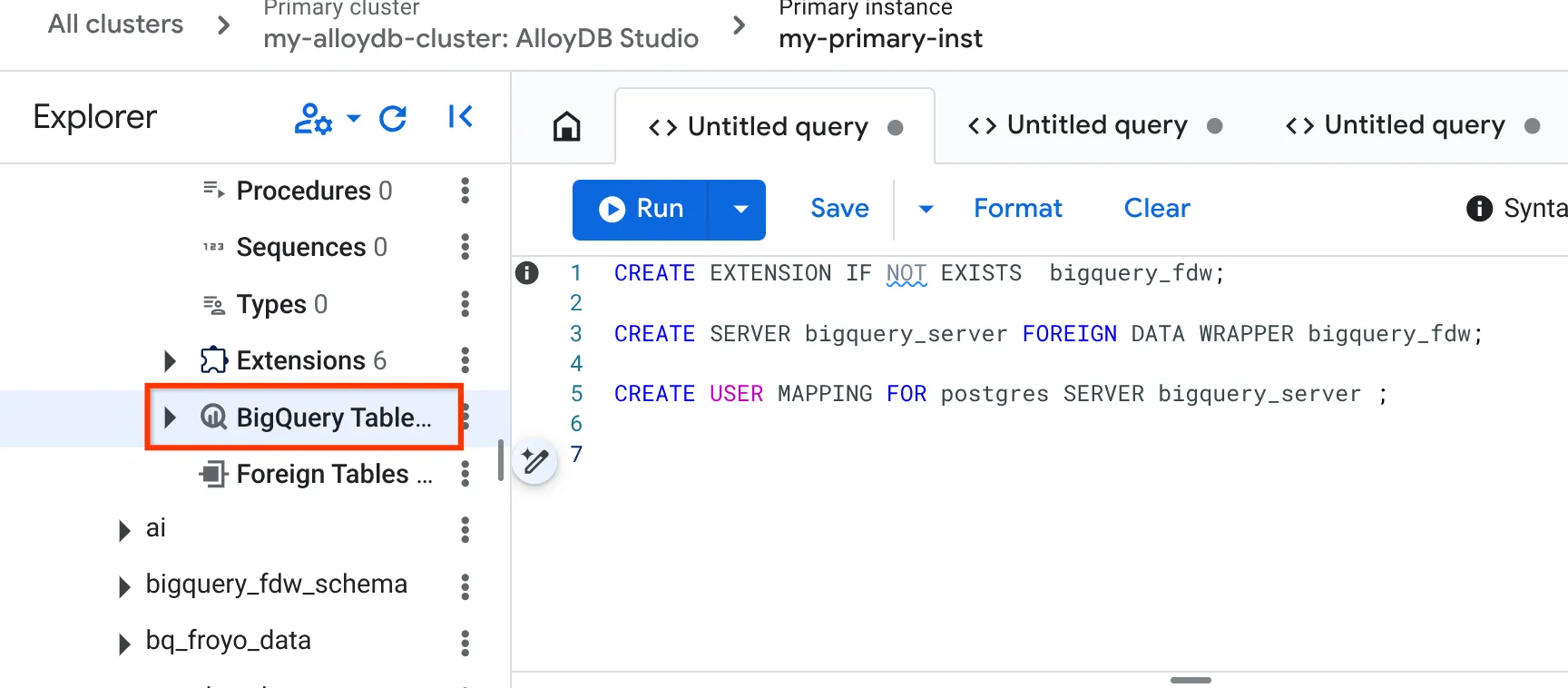
- انقر على النقاط الثلاث ثم على ربط جدول BigQuery.
- في النافذة المنبثقة "ربط جدول BigQuery" (Connect BigQuery Table) التي تفتح، اختَر project_id واسم مجموعة بيانات BigQuery (التي تم إنشاؤها في الجزء 1) التي تريد طلب البيانات منها في قاعدة بيانات AlloyDB.
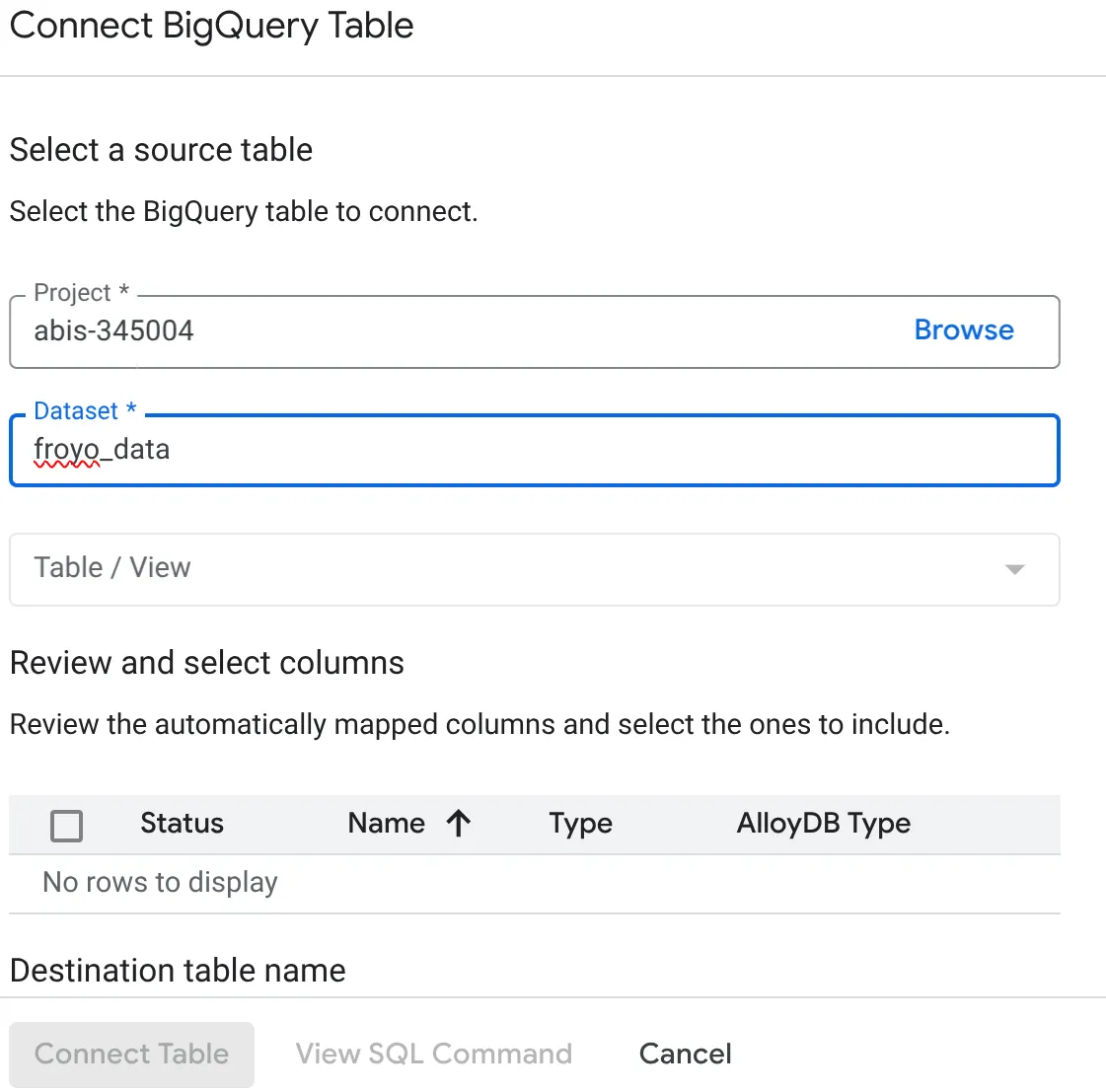
- اختَر كل جدول على حدة لربط جميع بياناتك بـ AlloyDB. يتم ذلك للتحقّق من أنواع الأعمدة والتأكّد من أنّها متوافقة مع AlloyDB.
إذا كنت تريد إجراء الأمر نفسه باستخدام SQL بدلاً من طريقة الإشارة والنقر:
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
النتيجة السحرية!!!
لقد أنشأنا للتو "جداول خارجية" في AlloyDB. تبدو هذه الجداول وتعمل مثل جداول PostgreSQL العادية، ولكنّها لا تخزّن أي بيانات. عند الاستعلام عنها، تحوّل AlloyDB طلب البحث على الفور إلى BigQuery، وتستردّ النتائج، وتعرضها لك.
7. اختبار الاتحاد في AlloyDB
لنتأكّد من إمكانية طلب البحث في مجموعة بيانات BigQuery التحليلية الضخمة مباشرةً من قاعدة بيانات PostgreSQL المعاملاتية.
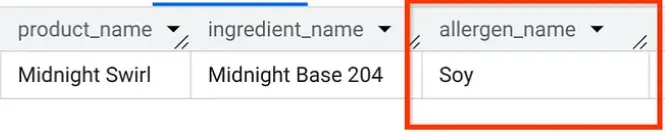
في AlloyDB Studio، لننفّذ طلب بحث لمعرفة المواد المسبّبة للحساسية في "Midnight Swirl" (السؤال نفسه الذي طرحناه في الجزء 1، ولكن هذه المرة من AlloyDB):
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
Boom. من المفترض أن تظهر لك النتائج نفسها التي ظهرت لك في BigQuery.
8. تَنظيم
بعد الانتهاء من هذا المختبر، لا تنسَ حذف مجموعة AlloyDB ونسختها.
يجب أن يؤدي ذلك إلى تنظيف المجموعة مع مثيلاتها.
9- تهانينا على طبقة البيانات الموحّدة
لنفكّر في ما أنجزناه للتو:
- يمكن لتطبيقنا المعامَلاتي (الذي يعمل على AlloyDB) التعامل مع جلسات المستخدمين السريعة والمتزامنة.
- عندما تحتاج إلى بيانات تحليلية كبيرة أو سياق سابق (مثل تفاصيل المورّد أو عمليات ربط المكوّنات المعقّدة)، فإنّها تستعلم عن froyo_dataschema في BigQuery.
- Zero ETL. لا توجد مسارات بيانات معطّلة. ما مِن قواعد بيانات غير متزامنة. نخزّن البيانات مرة واحدة (في BigQuery) ونعالجها حيثما نحتاج إليها.
بعد أن أصبح أساس بياناتنا، سواء التحليلية أو المتعلقة بالمعاملات، متينًا ومترابطًا، أصبحنا مستعدين للجزء الممتع.
في الجزء 3، سننشئ تطبيقًا متعدد الوكلاء يستند إلى هذه البنية لتنفيذ عمليات نشاط Froyo التجاري.