
১. সংক্ষিপ্ত বিবরণ
আমরা সবাই 'ডার্ক ডেটা'-র যন্ত্রণা সম্পর্কে জানি। এগুলো হলো ক্লাউড স্টোরেজে থাকা সেইসব পিডিএফ, ছবি এবং টেক্সট ফাইল, যা আপনার SQL কোয়েরি এবং BI ড্যাশবোর্ডের কাছে সম্পূর্ণ অদৃশ্য থাকে। প্রচলিতভাবে, এই ডেটা আনলক করার জন্য জটিল OCR পাইপলাইন, ম্যানুয়াল ডেটা এন্ট্রি অথবা ভঙ্গুর কাস্টম স্ক্রিপ্টের প্রয়োজন হতো।
আর না।
এই ল্যাবে, আমি আপনাদের দেখাবো কিভাবে টেক্সট, টেবিল এবং ছবি সম্বলিত ৪০০টি অসংগঠিত পিডিএফ ফাইলকে পরিচ্ছন্নভাবে গঠিত BigQuery টেবিলে রূপান্তর করা যায়, যেখানে ফাইলগুলোর মধ্যে সম্পর্ক স্বয়ংক্রিয়ভাবে অনুমান করা থাকবে। এবং আমরা BigQuery Knowledge Catalog ও Dataplex ব্যবহার করে কয়েক মিনিটের মধ্যেই এই কাজটি করব।
আপনি যা তৈরি করবেন
বিষয়টিকে বাস্তব রূপ দিতে, চলুন একটি কাল্পনিক ব্যবসার দিকে নজর দেওয়া যাক: একটি দ্রুত বর্ধনশীল ফ্রোজেন ইয়োগার্ট ফ্র্যাঞ্চাইজি।
ধরুন, আপনি এই ফ্রয়ো ব্যবসার ডেটা পরিচালনা করেন। আপনার কাছে শত শত রেসিপি এবং সরবরাহকারীর স্পেসিফিকেশন শিট রয়েছে, যা সবই পিডিএফ হিসেবে সংরক্ষিত। ব্যবসার নেতারা স্টোর ম্যানেজার এবং গ্রাহকদের পণ্যের বিবরণ জানতে সাহায্য করার জন্য একটি এআই এজেন্ট চালু করতে চান।
দুঃস্বপ্নের মতো পরিস্থিতিটা হলো: একজন গ্রাহক জিজ্ঞেস করেন, "আমি আপনাদের মিডনাইট সুইর্ল ফ্রোজেন ইয়োগার্টটা নিতে খুব আগ্রহী। এতে কি কোনো অ্যালার্জেন আছে?"
এর উত্তর দিতে, আপনার সিস্টেমকে সাধারণত যা করতে হবে তা হলো:
- ‘মিডনাইট সুইর্ল’ রেসিপির পিডিএফটি খুঁজুন।
- উপাদানগুলো পড়ুন (যেমন, ‘কোকো পাউডার’, ‘ডেয়ারি বেস’, ‘ইমালসিফায়ার X’)।
- ঐ নির্দিষ্ট উপাদানগুলোর স্পেসিফিকেশন শিট খুঁজে বের করার জন্য সরবরাহকারীদের কয়েক ডজন পিডিএফ ফাইল অনুসন্ধান করুন।
- ঐ উপাদানগুলোর সাথে সম্পর্কিত কোনো লুকানো অ্যালার্জেন আছে কিনা তা জানতে সরবরাহকারীর তথ্যপত্রগুলো যাচাই করুন।
রানটাইমে ৪০০টি কাঁচা পিডিএফ পড়ে তাৎক্ষণিকভাবে এই কাজটি করতে পারে এমন একটি এআই এজেন্ট তৈরি করার চেষ্টা ধীর, ব্যয়বহুল এবং এতে ভুল হওয়ার সম্ভাবনা থাকে। এর পরিবর্তে, আমরা প্রথমে সিমান্টিক ইনফারেন্স ব্যবহার করে এই সবকিছু একটি রিলেশনাল ডেটাবেসে নিয়ে আসব, যা আমাদের ভবিষ্যৎ এআই এজেন্টকে অত্যন্ত দ্রুত এবং ১০০% বাস্তব SQL ডেটার উপর ভিত্তি করে তৈরি করবে।
চলুন নির্মাণ শুরু করা যাক!
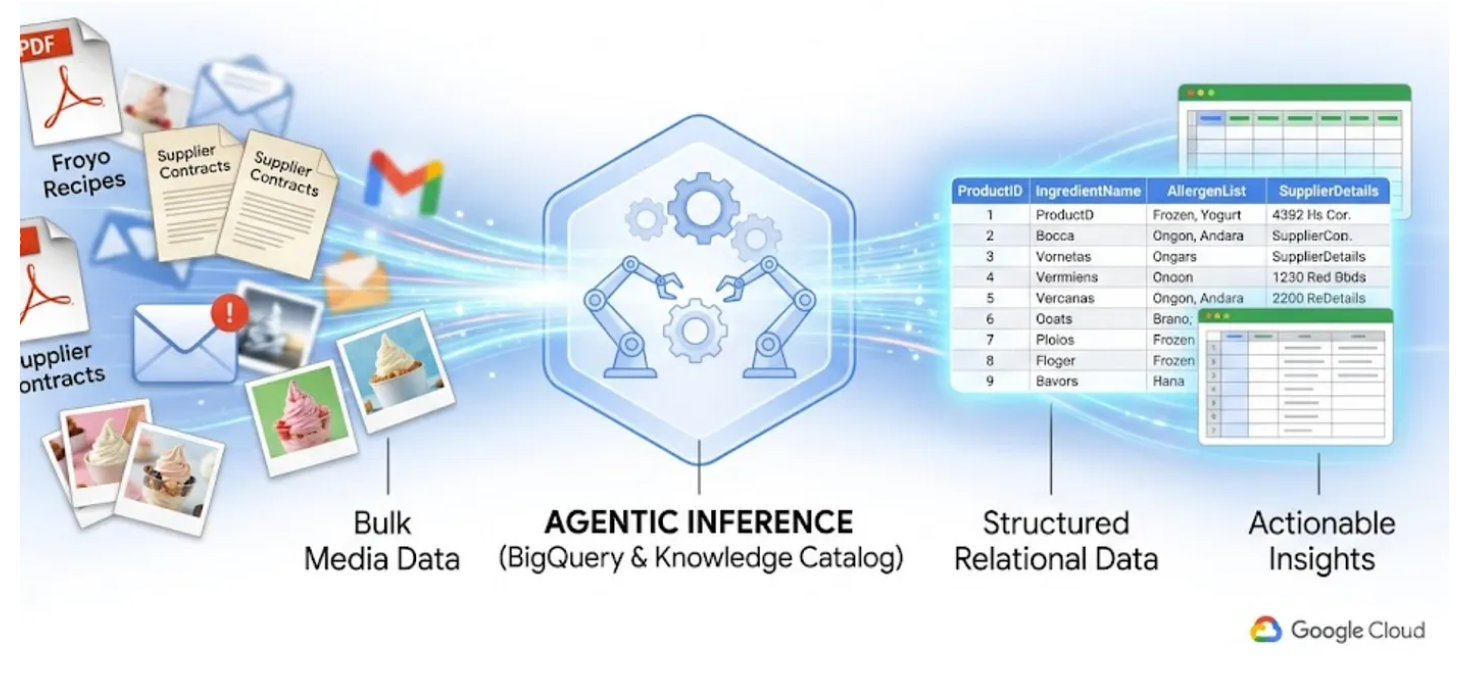
আপনি যা শিখবেন
- উৎস ফাইলগুলির (পিডিএফ) জন্য কীভাবে ক্লাউড স্টোরেজ বাকেট সেট আপ করবেন
- সোর্স পিডিএফ থেকে ডেটা এক্সট্র্যাক্ট করতে, কানেকশন ও কনটেক্সট-এর অর্থগত অনুমান করতে এবং সেই ডেটা BigQuery-তে স্টোর করার জন্য নলেজ ক্যাটালগে কীভাবে ডেটাস্ক্যান জব ও সিমান্টিক ইনফারেন্স সেট আপ এবং রান করতে হয়।
- নতুন তৈরি ডেটাসেটের সাথে চ্যাট করার জন্য কীভাবে BigQuery Agent ব্যবহার করবেন
প্রয়োজনীয়তা
- একটি ব্রাউজার, যেমন ক্রোম বা ফায়ারফক্স ।
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
- SQL এবং Java সম্পর্কে প্রাথমিক ধারণা।
২. শুরু করার আগে
একটি প্রকল্প তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন ।
- আপনি ক্লাউড শেল ব্যবহার করবেন, যা গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ। গুগল ক্লাউড কনসোলের শীর্ষে থাকা ‘Activate Cloud Shell’-এ ক্লিক করুন।

- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি নিম্নলিখিত কমান্ডটি ব্যবহার করে যাচাই করে নিন যে আপনি ইতিমধ্যেই প্রমাণীকৃত এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে:
gcloud auth list
- gcloud কমান্ডটি আপনার প্রজেক্ট সম্পর্কে অবগত আছে কিনা, তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান।
gcloud config list project
- আপনি যদি প্রমাণীকরণ করতে চান
gcloud auth login
- আপনার প্রজেক্টটি সেট করা না থাকলে, এটি সেট করতে নিম্নলিখিত কমান্ডটি ব্যবহার করুন:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- প্রয়োজনীয় API-গুলো সক্রিয় করুন: সমস্ত প্রয়োজনীয় API সক্রিয় করতে এই কমান্ডটি চালান:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
অপ্রত্যাশিত সমস্যা ও সমাধান
"ঘোস্ট প্রজেক্ট" সিন্ড্রোম | আপনি |
বিলিং ব্যারিকেড | আপনি প্রজেক্টটি চালু করেছেন, কিন্তু বিলিং অ্যাকাউন্টটি দিতে ভুলে গেছেন। AlloyDB একটি উচ্চ-ক্ষমতাসম্পন্ন ইঞ্জিন; এর 'গ্যাস ট্যাঙ্ক' (বিলিং) খালি থাকলে এটি চালু হবে না। |
এপিআই প্রচার বিলম্ব | আপনি "এপিআই সক্ষম করুন" এ ক্লিক করেছেন, কিন্তু কমান্ড লাইনে এখনও |
কোটা কোয়াগস | আপনি যদি একটি একেবারে নতুন ট্রায়াল অ্যাকাউন্ট ব্যবহার করেন, তাহলে AlloyDB ইনস্ট্যান্সের জন্য আপনার আঞ্চলিক কোটা শেষ হয়ে যেতে পারে। যদি |
"লুকানো" পরিষেবা এজেন্ট | কখনও কখনও AlloyDB সার্ভিস এজেন্টকে স্বয়ংক্রিয়ভাবে |
৩. গুগল ক্লাউড স্টোরেজ বাকেট সেটআপ
এই অংশে, আপনি BigQuery-এর মধ্যে Froyo রেসিপি এবং সরবরাহকারীর ডেটা, বিশেষ করে Froyo পণ্যের বিবরণ সংরক্ষণের জন্য একটি সাংগঠনিক কাঠামো তৈরি করেন। এটি একটি ক্লাউড রিসোর্স কানেকশনও স্থাপন করে, যা একটি সুরক্ষিত 'সেতু' হিসেবে কাজ করে এবং BigQuery-কে ক্লাউড স্টোরেজের মতো বাহ্যিক উৎস থেকে ফাইল পড়তে সাহায্য করে।
শুরু করার আগে:
এই রিপোজিটরিতে রেসিপি এবং সরবরাহকারীদের পিডিএফ ফাইল রয়েছে যা আমরা এই প্রকল্পে ব্যবহার করব। এই ফাইলগুলো ডাউনলোড করে নিন। ফাইলগুলো ডাউনলোড করতে, নিম্নলিখিত পদক্ষেপগুলো অনুসরণ করুন।
ক্লাউড শেলে, নিম্নলিখিত কমান্ডটি চালান:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
নতুন তৈরি করা ফোল্ডারটিতে প্রবেশ করুন:
cd next-26-keynotes
data-cloud-demo ফোল্ডারটি পুল করুন
git sparse-checkout set genkey/data-cloud-demo
চেকআউট সম্পন্ন হওয়ার পর, data-cloud-demo ফোল্ডারে যান এবং কোডল্যাব অ্যাসেটগুলো অ্যাক্সেস করার জন্য ZIP ফাইলগুলো এক্সট্র্যাক্ট করুন।
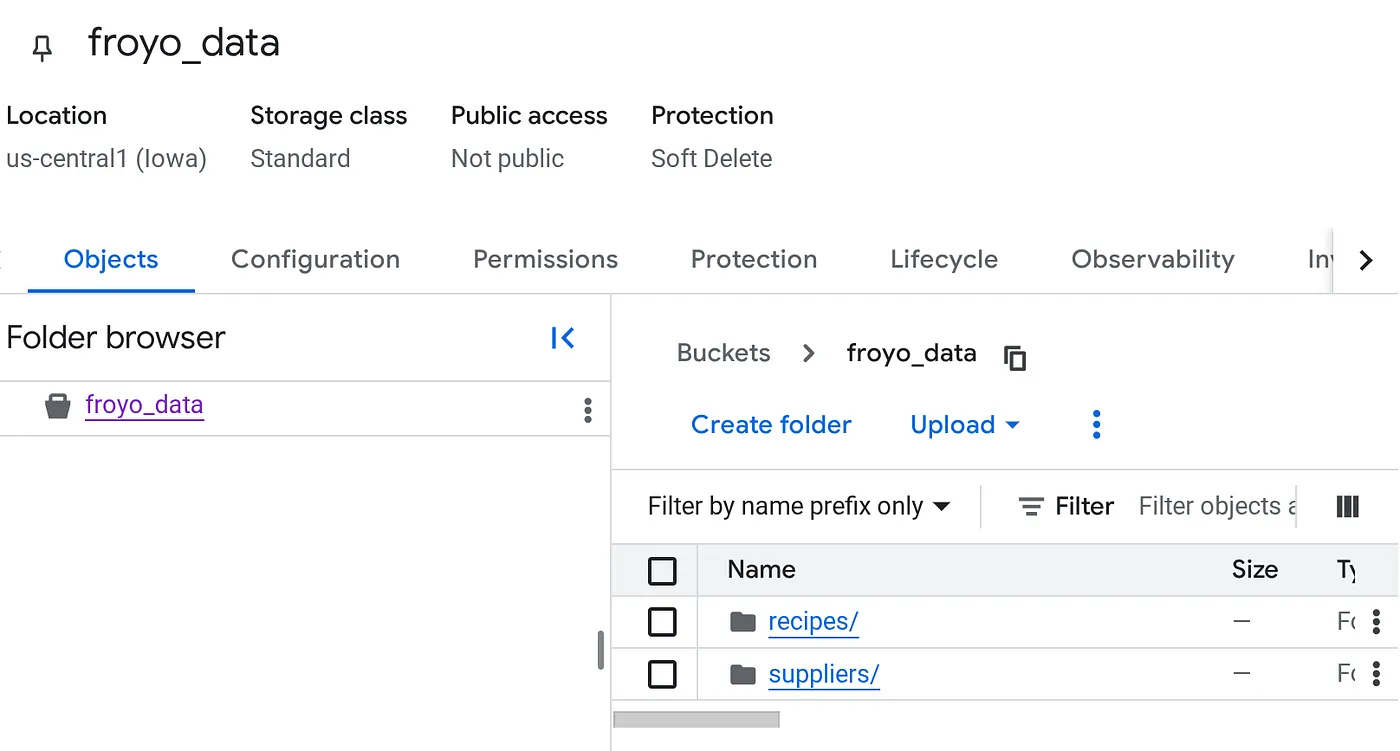
একটি বাকেট তৈরি করুন এবং Froyo (রেসিপি ও সরবরাহকারী) পিডিএফ ফাইলগুলো আপলোড করুন।
- গুগল ক্লাউড কনসোলে, ক্লাউড স্টোরেজ বাকেটস পৃষ্ঠায় যান।
- তৈরি করুন-এ ক্লিক করুন।
- 'Create a bucket ' পেজে আপনার বাকেটের তথ্য লিখুন। নিচের প্রতিটি ধাপের পর, পরবর্তী ধাপে যাওয়ার জন্য 'Continue'-তে ক্লিক করুন:
- 'Get started' বিভাগে বাকেটের নামটি লিখুন। যেমন: froyo_data
- "আপনার ডেটা কোথায় সংরক্ষণ করবেন তা বেছে নিন" বিভাগে, অঞ্চল নির্বাচন করুন এবং তারপরে আপনার অঞ্চল লিখুন। us-central1
- "Choose how to control access to objects" বিভাগে, "Enforce public access prevention on this bucket" চেকবক্সটি থেকে টিক চিহ্ন তুলে দিন।
- তৈরি করুন-এ ক্লিক করুন।
- বাকেটগুলোর তালিকা থেকে আপনার তৈরি করা বাকেটটিতে ক্লিক করুন।
- বাকেটের অবজেক্টস ট্যাবে, আপলোড-এ ক্লিক করুন এবং তারপরে আপলোড ফোল্ডারস-এ ক্লিক করুন।
- এই কোডল্যাবের 'শুরু করার আগে' অংশে আপনি যে রেসিপি ফোল্ডারটি এক্সট্র্যাক্ট করেছিলেন, সেটি নির্বাচন করুন।
- আপলোড-এ ক্লিক করুন।
- সাপ্লায়ার ফোল্ডারটির জন্য আপলোড প্রক্রিয়াটি পুনরাবৃত্তি করুন।
আপলোড হয়ে গেলে, আপনার বাকেট কাঠামোটি (বাকেটের নাম যা-ই হোক না কেন) দেখতে এইরকম হবে:
৪. BigQuery সংযোগ স্থাপন
একটি ক্লাউড রিসোর্স কানেকশন তৈরি করুন। এটি একটি অনন্য সার্ভিস অ্যাকাউন্ট তৈরি করে যা বাইরের ফাইল অ্যাক্সেস করার জন্য BigQuery-এর "আইডি কার্ড" হিসেবে কাজ করে।
- BigQuery পৃষ্ঠায় যান।
- বাম প্যানে, এক্সপ্লোরার-এ ক্লিক করুন। যদি আপনি বাম প্যানেটি দেখতে না পান, তবে প্যানেটি খোলার জন্য এক্সপ্যান্ড লেফট প্যানে-তে ক্লিক করুন।
- এক্সপ্লোরার প্যানে আপনার প্রজেক্টের নামটি এক্সপ্যান্ড করুন এবং তারপরে কানেকশনস-এ ক্লিক করুন।
- কানেকশন পেজে, ক্রিয়েট কানেকশন-এ ক্লিক করুন।
- কানেকশন টাইপের জন্য, ভার্টেক্স এআই রিমোট মডেল, রিমোট ফাংশন, বিগলেক এবং স্প্যানার (ক্লাউড রিসোর্স) বেছে নিন।
- কানেকশন আইডি ফিল্ডে কানেকশন আইডি নামটি লিখুন:
- bq-connection। এই আইডিটি অবশ্যই লিখে রাখুন, কারণ এই কোডল্যাবের পরবর্তী অংশে ডেটা স্ক্যান সেট আপ করার সময় এটি আপনার প্রয়োজন হবে।
- লোকেশন টাইপ ‘রিজিওন’-এ সেট করুন এবং তারপর একটি অঞ্চল নির্বাচন করুন। উদাহরণস্বরূপ, us-central1। কানেকশনটি আপনার অন্যান্য রিসোর্স, যেমন ডেটাসেট, যে অঞ্চলে অবস্থিত, সেই একই অঞ্চলে থাকা উচিত।
- সংযোগ তৈরি করুন-এ ক্লিক করুন।
- সংযোগে যেতে ক্লিক করুন।
- কানেকশন ইনফো প্যানে, পরবর্তী ধাপে ব্যবহারের জন্য সার্ভিস অ্যাকাউন্ট আইডিটি কপি করুন। সার্ভিস অ্যাকাউন্টটি দেখতে bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com-এর মতো।
৫. অনুমতি সেটআপ
- ক্লাউড স্টোরেজ অবজেক্ট এবং নলেজ ক্যাটালগ অ্যাক্সেস করার জন্য BigQuery কানেকশনকে প্রয়োজনীয় অনুমতি প্রদান করুন।
IAM ও অ্যাডমিন পেজে যান এবং 'View by Principals' সেকশনে, 'Grant access' বাটনে ক্লিক করুন, এরপর গত ধাপে কপি করা সার্ভিস অ্যাকাউন্টটি পেস্ট করে একটি প্রিন্সিপাল যোগ করুন। 'roles' সেকশনে, নিচের রোলগুলোর নাম এক এক করে যোগ করুন এবং সেভ করুন:
- ভূমিকা/স্টোরেজ.অবজেক্টইউজার
- ভূমিকা/স্টোরেজ.অবজেক্টভিউয়ার
- ভূমিকা/বিগকোয়েরি.ব্যবহারকারী
- ভূমিকা/বড় কোয়েরি.ডেটা সম্পাদক
- ভূমিকা/এআইপ্ল্যাটফর্ম.ভিউয়ার
- ভূমিকা/এজেন্টপ্ল্যাটফর্ম.ব্যবহারকারী
- ভূমিকা/স্টোরেজ.অ্যাডমিন
- ভূমিকা/ডেটাপ্রক.পরিষেবাএজেন্ট
- ভূমিকা/ডেটাপ্লেক্স.ডিসকভারি পাবলিশিং সার্ভিস এজেন্ট
- ভূমিকা/ডেটাপ্লেক্স.সার্ভিসএজেন্ট
- ভূমিকা/ডেটাপ্লেক্স.সিকিউরিটিঅ্যাডমিন
- ক্লাউড স্টোরেজ বাকেট অ্যাক্সেস করার জন্য ডেটাপ্লেক্স সার্ভিস অ্যাকাউন্টকে অনুমতি দিন।
IAM ও অ্যাডমিন পেজে যান এবং 'View by Principals' সেকশনে, 'Grant access' বাটনে ক্লিক করুন ও 'New principal' টেক্সট বারে 'dataplex ' শব্দটি টাইপ করে একটি প্রিন্সিপাল যোগ করুন। যে তালিকাটি স্বয়ংক্রিয়ভাবে পূরণ হবে, সেখান থেকে 'Dataplex Service Account' প্রিন্সিপালটি নির্বাচন করুন, যা দেখতে এইরকম: (নীচের সার্ভিস অ্যাকাউন্ট ইমেল আইডিতে প্রজেক্ট আইডির পরিবর্তে প্রজেক্ট নম্বর ব্যবহার করুন )।
service-<< আপনার_প্রজেক্ট_নম্বর >>@ gcp-sa-dataplex.iam.gserviceaccount.com
যদি কোনো কারণে আপনার প্রজেক্ট নম্বরের জন্য উপরের সার্ভিস অ্যাকাউন্টটি শনাক্ত না হয়, তাহলে হতে পারে যে প্রজেক্টটি এখনও ডেটাপ্লেক্স সার্ভিসটি চালু করেনি। ক্লাউড শেল টার্মিনালে যান এবং নিম্নলিখিত কমান্ডটি চালিয়ে API-টি সক্রিয় করার চেষ্টা করুন (যদি 'শুরু করার আগের' পর্যায়ে এটি করা না হয়ে থাকে): gcloud services enable dataplex.googleapis.com
এর পরেও যদি Dataplex-এর সার্ভিস অ্যাকাউন্টটি শনাক্ত না হয়, তাহলে Metadata Curation পেজে জোরপূর্বক একটি টেস্ট Dataplex স্ক্যান জব তৈরি করুন এবং Discover Job তৈরির পেজে বিস্তারিত তথ্য প্রবেশ করান:
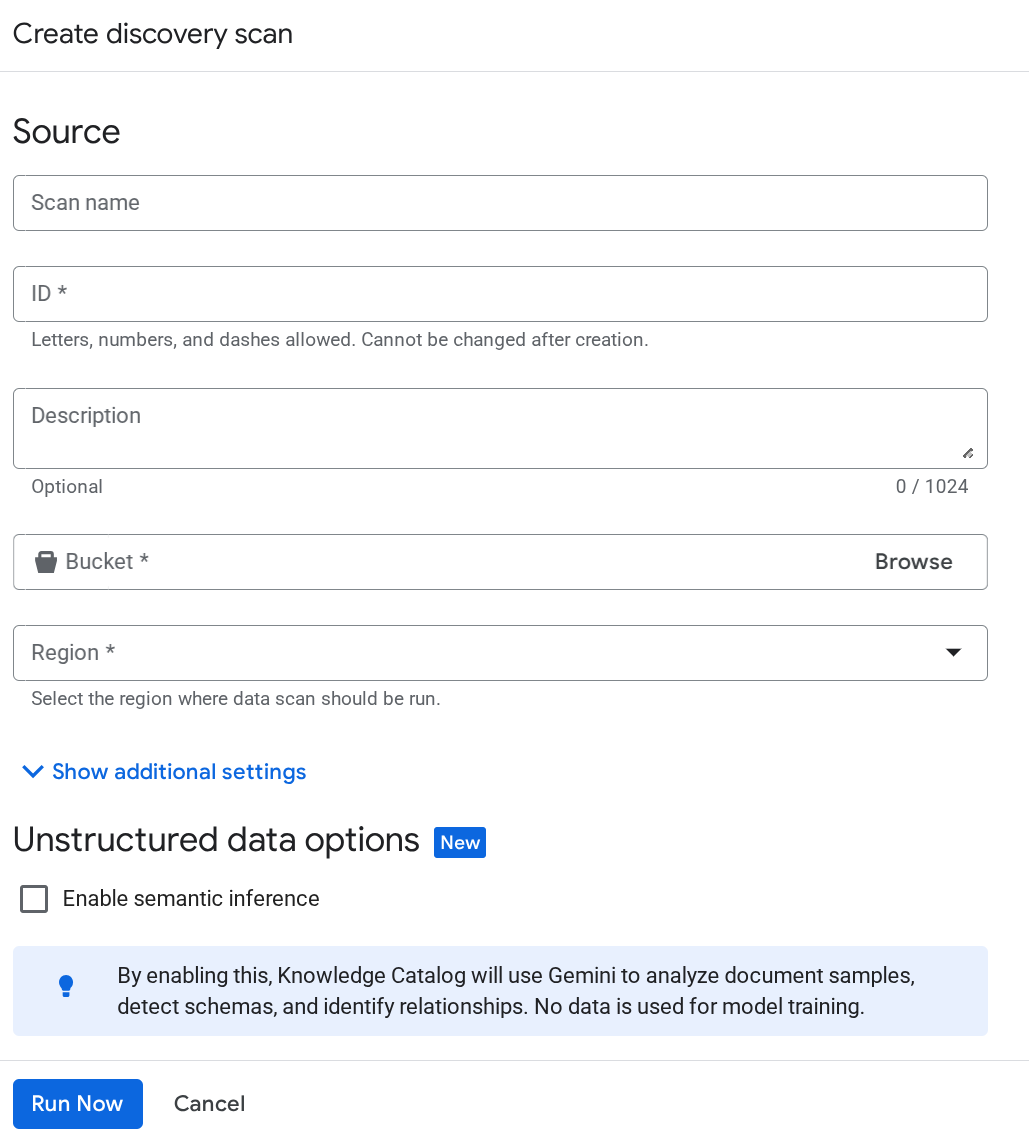
'Run Now'-এ ক্লিক করুন। কাজটি ব্যর্থ হবে, কিন্তু এর মাধ্যমে আপনার Dataplex সার্ভিসের জন্য সার্ভিস অ্যাকাউন্ট আইডিটি এখন চালু হয়ে যাবে।
IAM ও অ্যাডমিন পেজে ফিরে যান এবং 'View by Principals' সেকশনে, 'Grant access' বাটনে ক্লিক করে 'add a principal'-এ ক্লিক করুন। সার্ভিস অ্যাকাউন্টটি পেস্ট করুন:
service-<< আপনার_প্রজেক্ট_নম্বর >>@ gcp-sa-dataplex.iam.gserviceaccount.com
তারপর এই সার্ভিস অ্যাকাউন্টটিকে নিম্নলিখিত ভূমিকাগুলি প্রদান করুন:
- ভূমিকা/স্টোরেজ.অবজেক্টইউজার
- ভূমিকা/স্টোরেজ.অবজেক্টভিউয়ার
- ভূমিকা/স্টোরেজ.ভিউয়ার
- ভূমিকা/ডেটাপ্লেক্স.ডিসকভারিবিগলেকপাবলিশিংসার্ভিসএজেন্ট
৬. নলেজ ক্যাটালগ সেটআপ
অসংগঠিত ডেটা একত্রিত করতে এবং অসংগঠিত ফাইল (যেমন পিডিএফ রেসিপি ও পিডিএফ সরবরাহকারী) স্বয়ংক্রিয়ভাবে খুঁজে বের করার জন্য একটি নলেজ ক্যাটালগ তৈরি করুন।
কনসোল থেকে ডেটাস্ক্যান জবটি তৈরি করুন:
- মেটাডেটা কিউরেশন পৃষ্ঠায় যান।
- তৈরি করুন-এ ক্লিক করুন এবং আপনার সেটআপ অনুযায়ী বিবরণ লিখুন:
গুরুত্বপূর্ণ দ্রষ্টব্য: ‘Enable Semantic Inference’ চেক করতে ভুলবেন না।
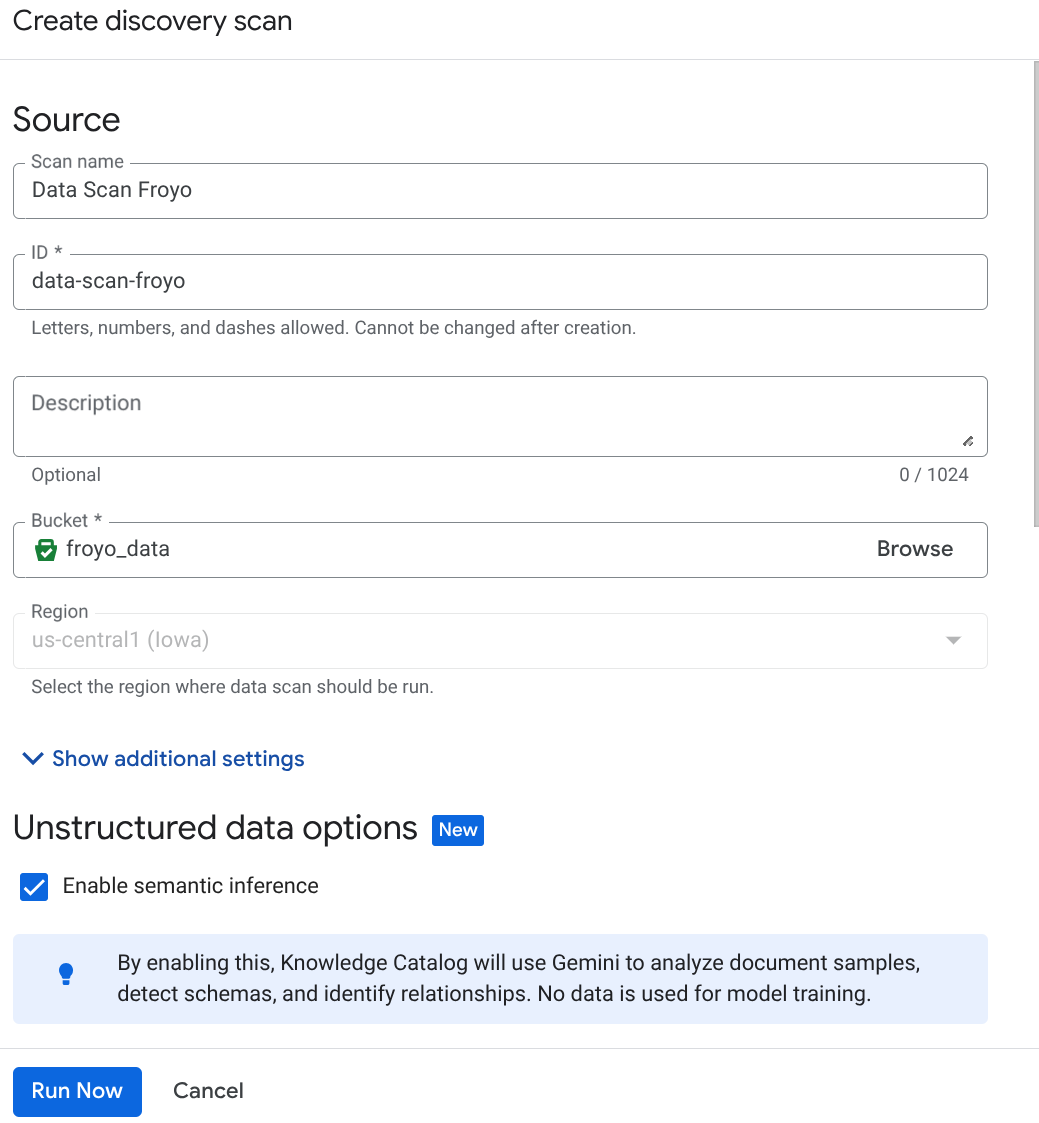
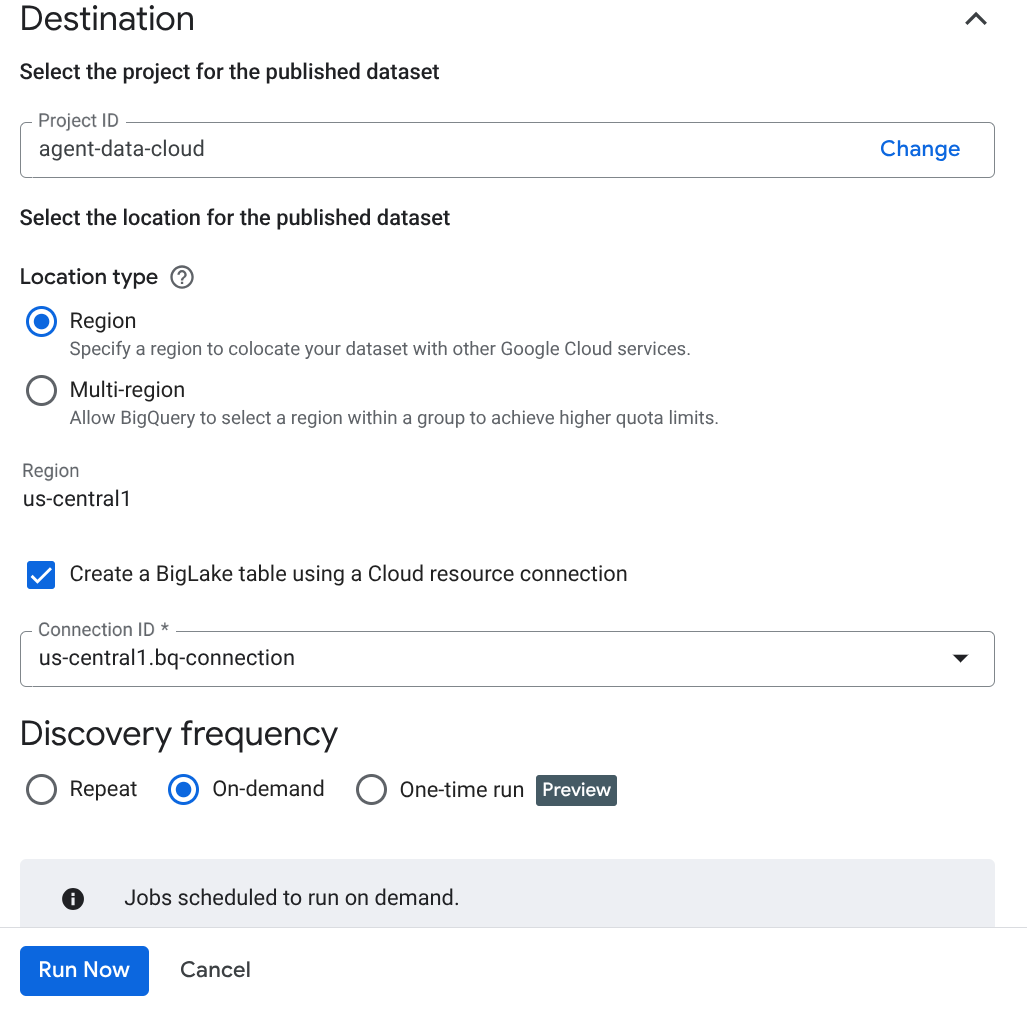
- 'এখন চালান'-এ ক্লিক করুন।
- স্ক্যান কাজটি সম্পন্ন হতে কিছুটা সময় লাগবে। কাজটি শেষ হয়ে গেলে, প্রকাশিত ডেটাসেটটি উপস্থিত আছে কিনা তা পরীক্ষা করুন। কাজের অবস্থা পরীক্ষা করার জন্য, আপনি মেটাডেটা কিউরেশন পৃষ্ঠার ক্লাউড স্টোরেজ ডিসকভারি ট্যাবে গিয়ে সাম্প্রতিক রানের ডিসকভারি স্ক্যানগুলোর নামে ক্লিক করতে পারেন। আপনি নীচের ছবির মতো প্রকাশিত ডেটাসেটটি দেখতে পাবেন:
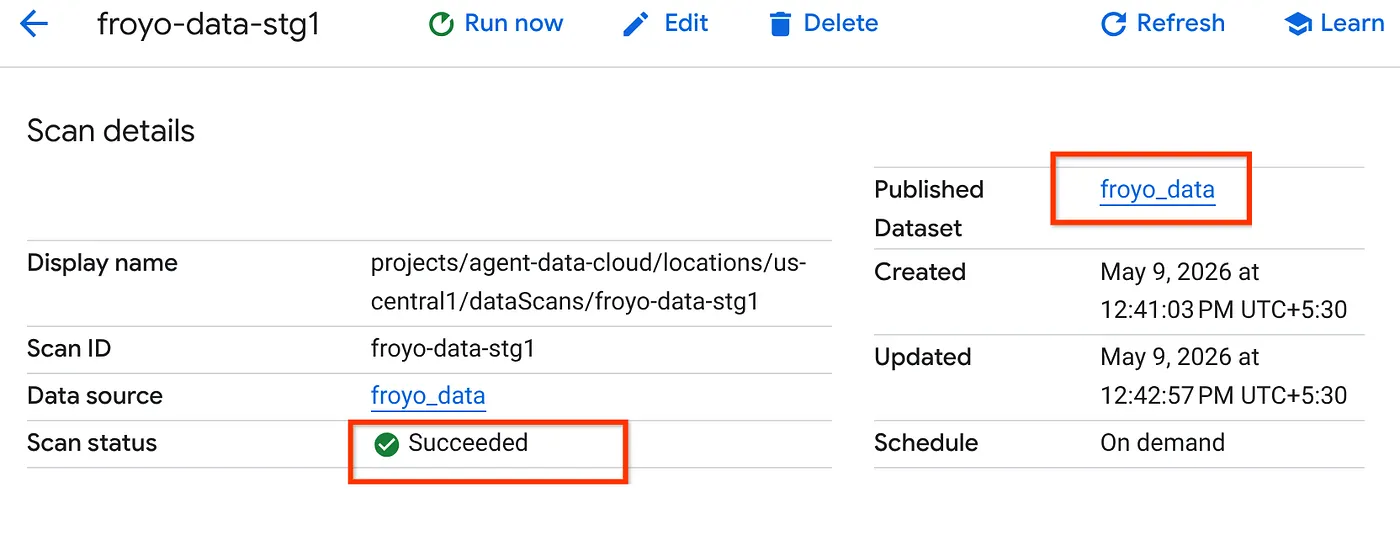
দ্রষ্টব্য: স্ক্যান ধাপে কোনো ত্রুটি দেখা দিলে, কিছুক্ষণ অপেক্ষা করুন এবং তারপর আবার চেষ্টা করুন (জবটি তৈরি হতে এবং এর নির্বাহ সম্পন্ন হতে কয়েক মিনিট সময় লাগে)।
- আপনি BigQuery-তে froyo_data ডেটাসেটে ক্লিক করে এবং নেভিগেট করে টেবিলটি দেখতে পারেন। BigQuery-তে টেবিল আইডিতে ক্লিক করুন এবং কোয়েরি এডিটর ট্যাবে নিচের কোয়েরিটি চালান:
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
এর ফলে ৪০০ আসবে (যদি তা না হয়, আপনি ফিরে গিয়ে ডেটাস্ক্যান জবটি আবার চালাতে পারেন)।
৭. শব্দার্থিক তথ্য নিষ্কাশন
চমৎকার!! এবার নলেজ ক্যাটালগ ব্যবহার করে এই অসংগঠিত অবজেক্টগুলোর জন্য ইনফারেন্স বের করা যাক।
আমরা ইনসাইটস ফিচারটি ব্যবহার করে আনস্ট্রাকচার্ড টেবিল থেকে স্ট্রাকচার্ড ডেটা বের করার জন্য SQL স্টেটমেন্ট তৈরি করব।
- গুগল ক্লাউড কনসোলে, নলেজ ক্যাটালগ সার্চ পেজে যান।
- যে ডেটাসেট টেবিলের ইনসাইট দেখতে চান, সেটি খুঁজুন। সার্চ বারে, আগের ধাপ থেকে ডেটাসেট / টেবিলের নাম: "froyo_data" লিখুন এবং এন্টার চাপুন।
- ফলাফলের তালিকা থেকে, TABLE এন্ট্রিতে ক্লিক করুন (ডেটাসেট এন্ট্রিতে নয়)।
- আপনি INSIGHTS ট্যাবটি দেখতে পাবেন। সেটিতে ক্লিক করুন (যদি কোনো API সক্রিয় করার প্রয়োজন হয়, তবে নির্দেশাবলী অনুসরণ করে শুধু API-গুলো সক্রিয় করুন)।
আপনি যদি এই পর্যায়ে এপিআই (API) সক্রিয় করে থাকেন, তাহলে আপনাকে স্ক্যান জবটি আবার চালাতে হবে।
- INSIGHTS ট্যাবে আপনি EXTRACT বাটনের ড্রপ-ডাউন দেখতে পাবেন। সেটিতে ক্লিক করে "Extract with SQL" অপশনটি নির্বাচন করুন।
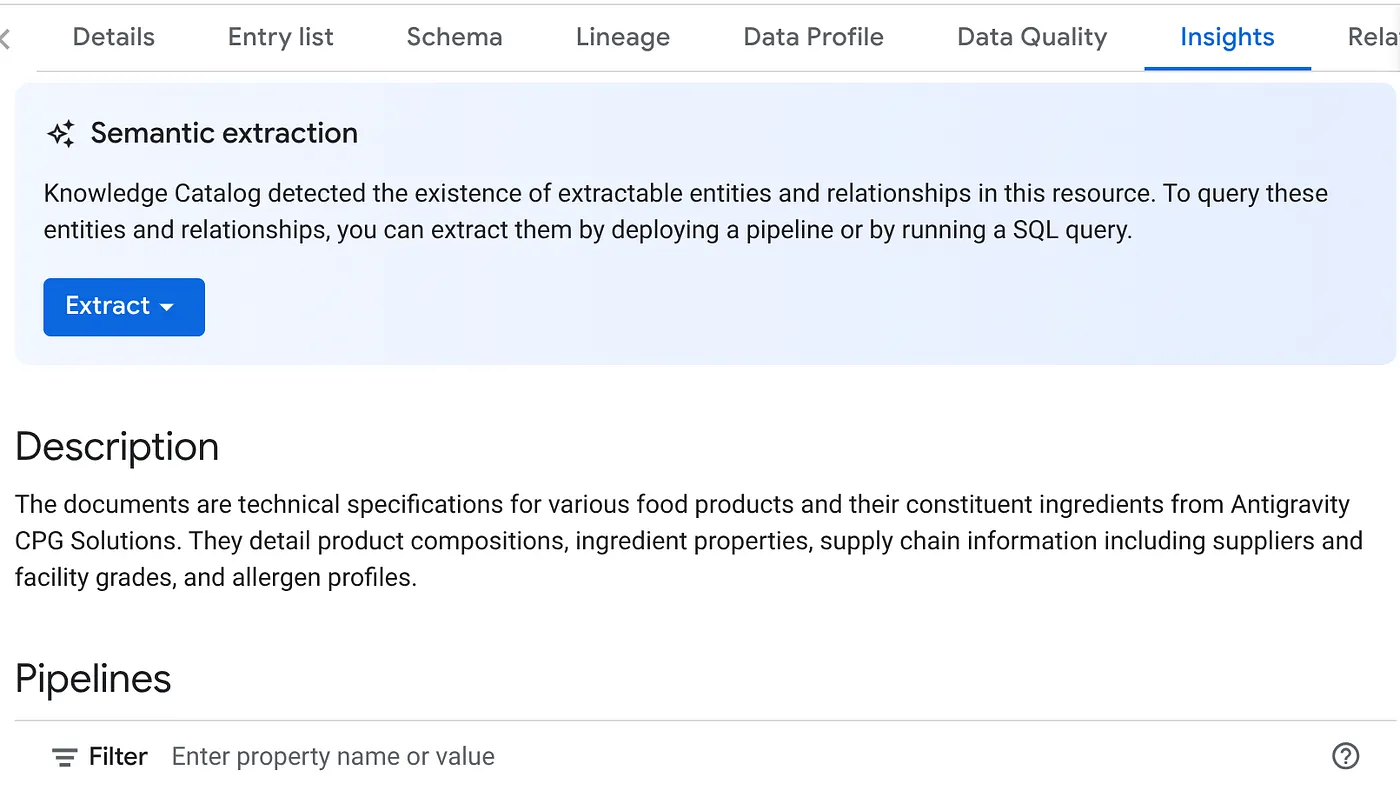
" Extract with SQL " ডায়ালগ পপ-আপে, Datascan জবের ফলাফলে দেখা ডেটাসেটটিকে গন্তব্য (DESTINATION) হিসেবে সেট করুন। এর নামটি টাইপ করা শুরু করুন এবং এটি অটোকমপ্লিটে দেখানো উচিত। " Extract " বোতামে ক্লিক করুন। বিকল্পভাবে, আপনি এই পর্যায়ে একটি নতুন ডেটাসেট তৈরি করে এক্সট্র্যাক্ট করতে পারেন।
এটি BigQuery Query Editor খুলবে, যেখানে ডেটা স্ক্যান ইনফারেন্স থেকে সংগৃহীত SQL দিয়ে একটি ট্যাব পূর্ণ থাকবে।
৮. SQL যাচাইকরণ ও স্কিমা তৈরি
তৈরি করা কোয়েরিটি যদি ঠিকঠাক এবং আপনার অসংগঠিত ডেটার জন্য অর্থগতভাবে প্রাসঙ্গিক বলে মনে হয়, তবে কোয়েরি এডিটরে থাকা 'রান' বোতামে ক্লিক করে এটি চালিয়ে দিন। আপনার অসংগঠিত মিডিয়ার সংগঠিত সংরক্ষণের জন্য প্রয়োজনীয় স্কিমা তৈরি করতে কয়েক মিনিট সময় লাগবে।
একবার সম্পন্ন হলে, নিচে দেখানো অনুযায়ী BigQuery Studio-এর এক্সপ্লোরার প্যানে ডেটাসেটটি এক্সপ্যান্ড করে আপনি স্কিমাটি যাচাই করতে পারবেন:
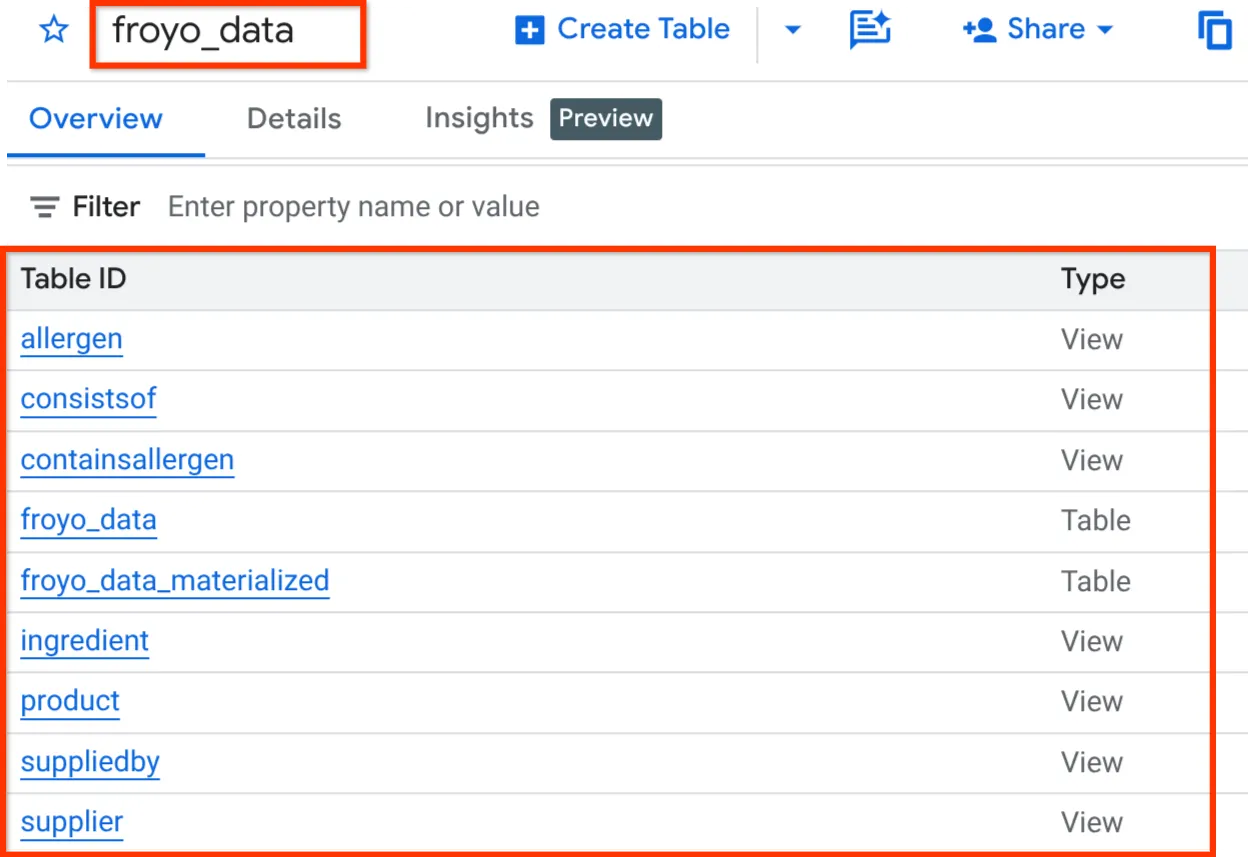
দারুণ!!! আমরা যে ডেটাবেসের সব কাজ খুব দ্রুত করে ফেলেছি, সেটা খুবই ভালো হয়েছে। এখন চূড়ান্ত পরীক্ষার পালা!
বিলিং অ্যাকাউন্ট ছাড়াই ডেটা উপভোগ করা চালিয়ে যাওয়ার পদক্ষেপ:
- আপনি উপরের গিটহাব রিপো লিঙ্ক থেকে ডেটা সিএসভি ফাইলগুলো (বিগকোয়েরি ডেটা) পেতে পারেন।
- প্রথমে, ক্লাউড শেল টার্মিনাল থেকে নিচের কমান্ডটি চালিয়ে BigQuery ডেটাসেটটি তৈরি করুন:
bq mk --location us-central1 --dataset froyo_data
- এরপর, নিচের কমান্ডগুলো এক এক করে চালিয়ে গিটহাব রিপো থেকে ৮টি ডেটা ফাইল (csv ফাইল) আপনার ওয়ার্কিং ডিরেক্টরিতে ডাউনলোড করুন:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- আপনার নতুন তৈরি করা ডেটাসেটের ডেটা দিয়ে এই টেবিলগুলো তৈরি করতে নিচের কমান্ডগুলো এক এক করে চালান।
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
একবার ডেটাসেট, টেবিল এবং ডেটা তৈরি হয়ে গেলে, আপনি আমাদের আলোচিত ডেটাগুলো পরীক্ষা ও অভিজ্ঞতা অর্জনের জন্য অগ্রসর হতে পারেন।
৯. চূড়ান্ত পরীক্ষা!!!
ধরা যাক, আমি চাই আমার এজেন্ট ব্যবহারকারীর প্রশ্নের উত্তর বাস্তব, সম্পূর্ণ এবং তথ্য-প্রমাণের উপর ভিত্তি করে সুসংগঠিত তথ্য দিয়ে দিক। আমি এমন একটি প্রশ্ন করব যার উত্তর এজেন্টটি কেবল আমার উৎস থেকে একাধিক মিডিয়া ফাইল এবং তথ্যসূত্র দেখেই দিতে পারবে।
এখানে আমার ব্যবহারকারী প্রশ্নটি রয়েছে:
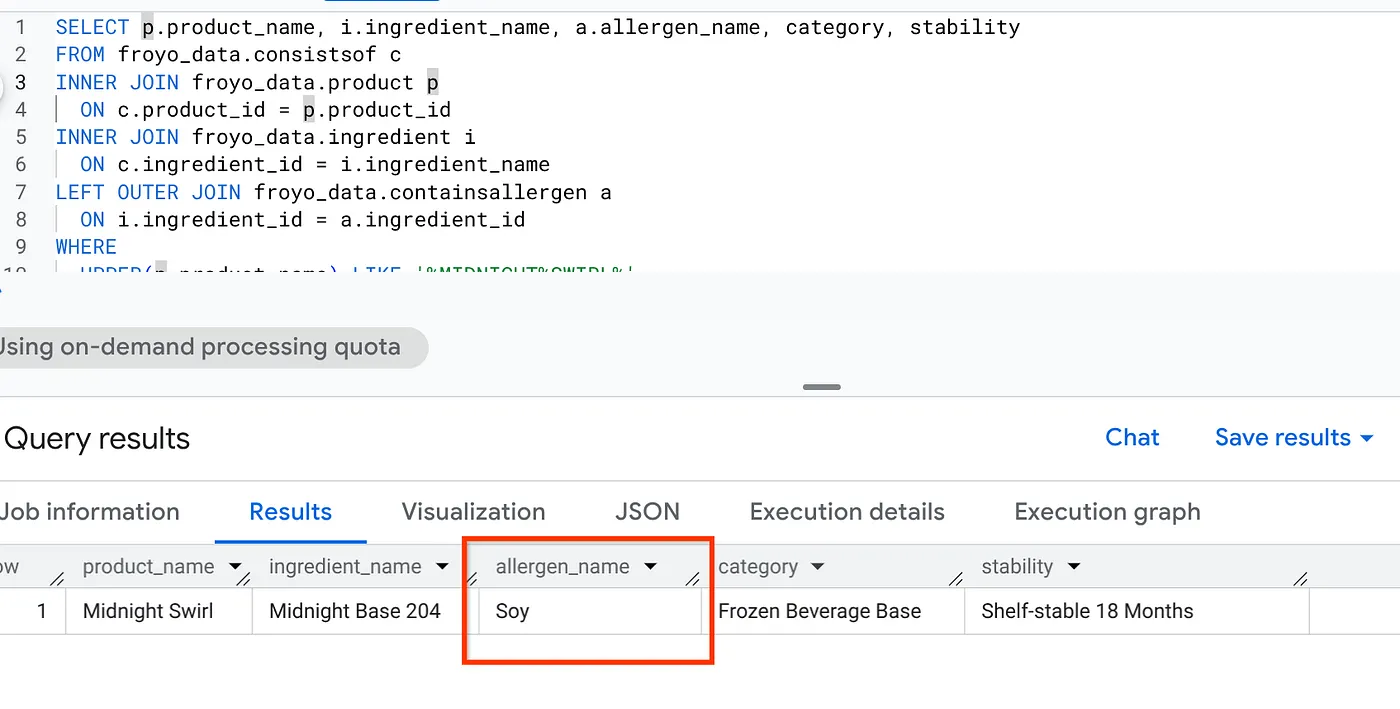
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
এখন একটি জেনেরিক সার্চ বা এলএলএম সার্চে দেখাবে "শূন্য উপাদান"। কিন্তু আমরা আমাদের সমস্ত অসংগঠিত মিডিয়াকে সংগঠিত ডেটাতে রূপান্তর করে একটি সম্পূর্ণ সিমান্টিক ইনফারেন্স তৈরি করেছি। তাহলে চলুন, একটি সাধারণ SQL দিয়ে এই তথ্যটি সংগ্রহ করা যাক:
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
বাহ! ফলাফলটা দেখুন:
১০. পরিষ্কার করুন
এই ল্যাবটি সম্পন্ন হয়ে গেলে, স্ক্যান জবটি এবং এর ফলে তৈরি হওয়া BigQuery টেবিলগুলো ডিলিট করতে ভুলবেন না।
https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery -এ যান। যে জবটি মুছতে চান, সেটির পাশে থাকা উল্লম্ব এলিপসিস-এ ক্লিক করে সেটি নির্বাচন করুন এবং DELETE-এ ক্লিক করুন।
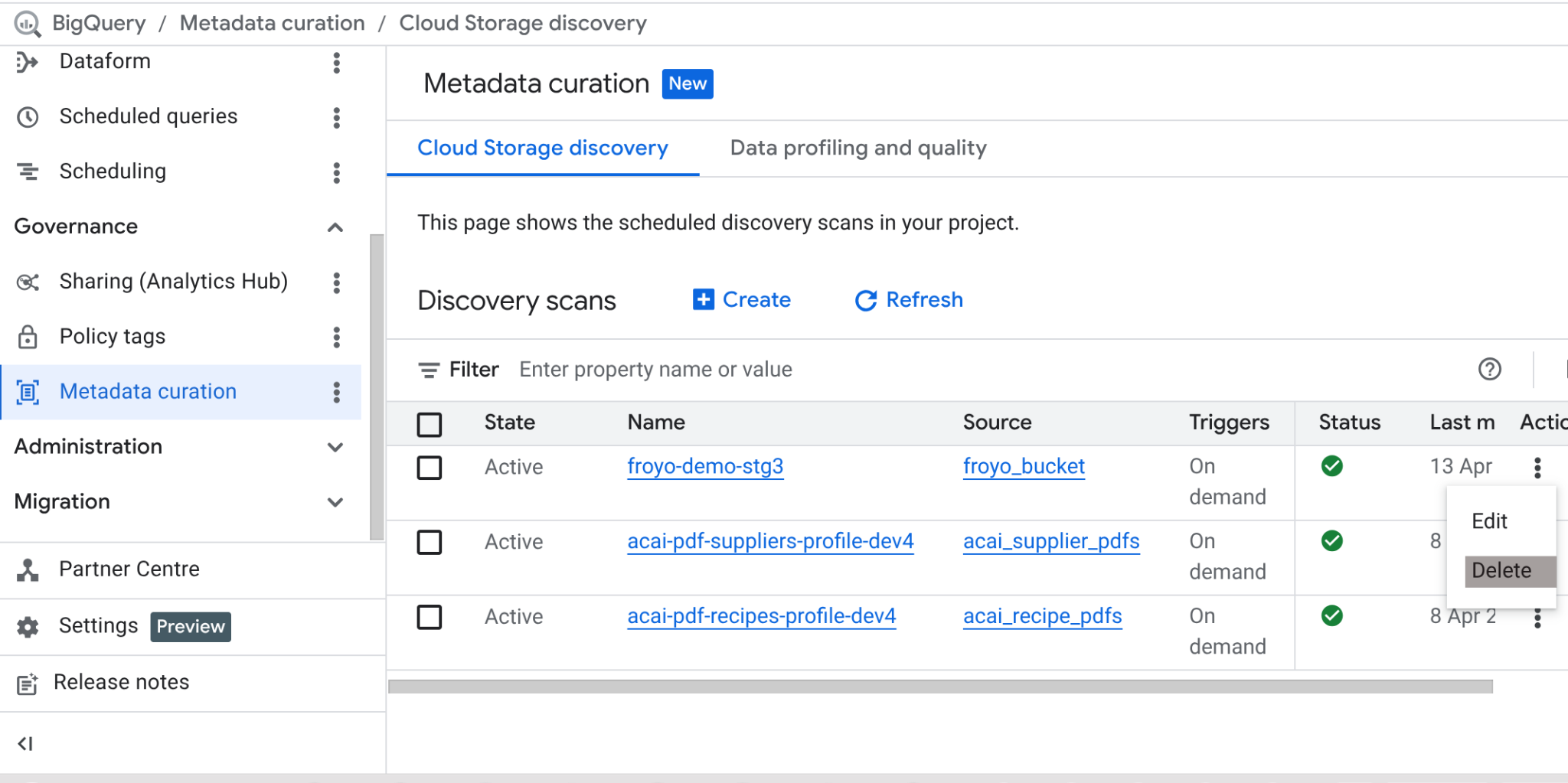
এটা কাজটা পরিষ্কার করে দেবে।
১১. অভিনন্দন
আমাদের বাস্তবায়ন সফলভাবে লুকানো অ্যালার্জেনটি শনাক্ত করতে পেরেছে। আর কোনো ডার্ক ডেটা নয়!!! দ্বিতীয় পর্বে , আমরা আমাদের এজেন্টিক অ্যাপ্লিকেশনের ডেটার চাহিদা একীভূত করার জন্য AlloyDB-সহ একটি ট্রানজ্যাকশনাল সিস্টেমে এই BigQuery ডেটা ফেডারেট করব।