
১. সংক্ষিপ্ত বিবরণ
প্রথম পর্বে , আমরা নলেজ ক্যাটালগ এবং ডেটাস্ক্যান ব্যবহার করে বিগকোয়েরিতে বিশৃঙ্খল ও অসংগঠিত পিডিএফ ফাইলগুলোকে সফলভাবে পরিচ্ছন্ন, তথ্যসমৃদ্ধ এবং সুসংগঠিত টেবিলে রূপান্তরিত করেছি। এখন আমাদের একটি শক্তিশালী ডেটা ওয়্যারহাউস রয়েছে।
আপনার যদি দ্রুত মনে করার প্রয়োজন হয়, তাহলে বলি, পার্ট ১ ল্যাবে আমরা একটি কাল্পনিক ফ্রোজেন ইয়োগার্ট ফ্র্যাঞ্চাইজির ইউজ কেস নিয়েছিলাম এবং BigQuery Knowledge Catalog ও Dataplex ব্যবহার করে এর টেক্সট, টেবিল ও ছবি সম্বলিত ৪০০টি অসংগঠিত পিডিএফ ফাইলকে পরিচ্ছন্নভাবে গঠিত BigQuery টেবিলে রূপান্তর করেছিলাম, যেগুলোর মধ্যে সম্পর্ক স্বয়ংক্রিয়ভাবে অনুমান করা হয়েছিল।
আপনি যা তৈরি করবেন
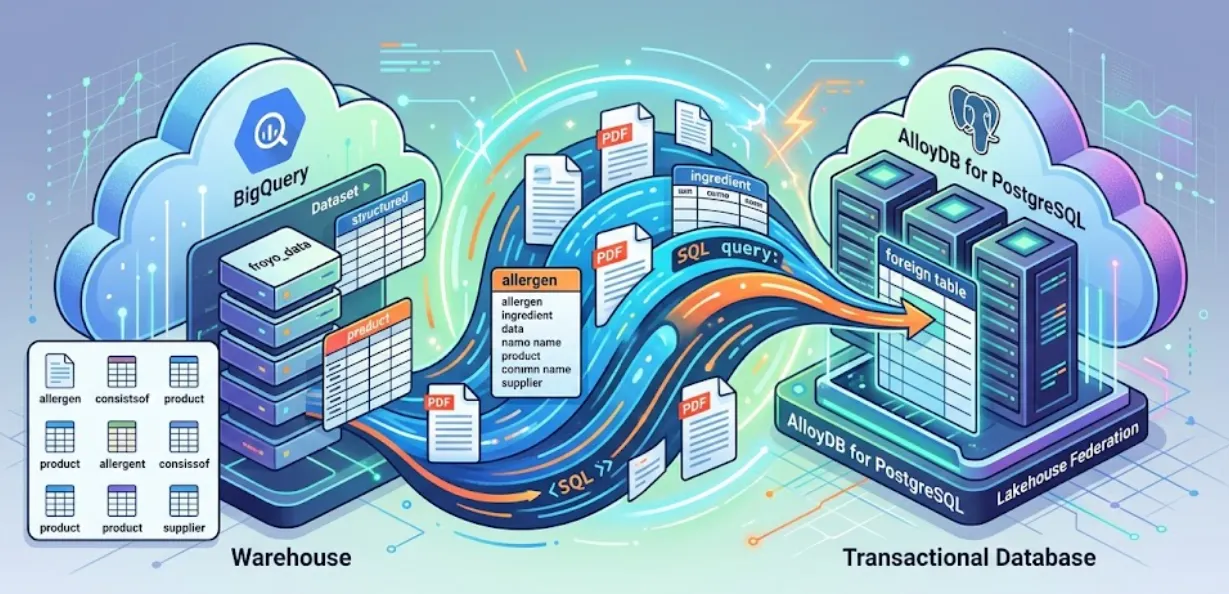
এই সেশনে, আমরা PostgreSQL-এর জন্য AlloyDB সেট আপ করছি এবং একটি জাদুকরী কাজ করছি: আমাদের BigQuery ডেটা সরাসরি AlloyDB-তে ফেডারেট করছি। এর মানে হলো, আমাদের ট্রানজ্যাকশনাল অ্যাপটি ডেটার কোনো অংশ কপি বা ডুপ্লিকেট না করেই রিয়েল-টাইমে আমাদের ডেটা ওয়্যারহাউস কোয়েরি করতে পারবে।
একজন ডেভেলপার হিসেবে এই পর্যায়ে আপনাকে অবশ্যই এই প্রশ্নটি করতে হবে:
ডেটা যদি ইতিমধ্যেই BigQuery-তে থাকে, তাহলে AlloyDB-কে এর মধ্যে আনার কী প্রয়োজন? অ্যাপ্লিকেশনটি সরাসরি BigQuery-এর বিরুদ্ধে একটি SELECT স্টেটমেন্ট চালায় না কেন?
এই হলো কারণ:
লেকহাউস ফেডারেশনের মাধ্যমে, আপনি একই ইন্টারফেস থেকে আপনার অ্যাপ্লিকেশনের ট্রানজ্যাকশনাল এবং অ্যানালিটিক্যাল ওয়ার্কলোডগুলো পরিচালনা করতে AlloyDB-এর কোয়েরি ইঞ্জিন ব্যবহার করতে পারেন। এছাড়াও, আপনার অ্যাপ্লিকেশনগুলোতে দ্রুত ব্যবহারের জন্য এই ডেটা AlloyDB-তে ম্যাটেরিয়ালাইজ বা ইম্পোর্ট করতে পারেন, যা আপনাকে AlloyDB AI এবং কলামনার ইঞ্জিন ব্যবহার করার সুযোগ দেয়।
আপনি AlloyDB-কে একটি ট্রানজ্যাকশনাল ডেটাবেস হিসেবে ব্যবহার করতে পারেন এবং একই সাথে BigQuery বা BigLake-এ বিপুল পরিমাণ ডেটা রাখতে পারেন। আপনার অ্যাপ্লিকেশনগুলো সাধারণত এই বিভিন্ন গুগল ক্লাউড পরিষেবাগুলো থেকে ডেটা অ্যাক্সেস করার জন্য এই দুটি সিস্টেমের সাথেই স্বাধীনভাবে ইন্টিগ্রেট করে। Lakehouse Federation for AlloyDB আপনাকে AlloyDB-এর ফেডারেটেড কোয়েরি সাপোর্ট ব্যবহার করার সুযোগ দেয়, যা একটি ফরেন ডেটা র্যাপার হিসেবে প্রয়োগ করা হয়েছে। এর মাধ্যমে আপনি AlloyDB-এর নিজস্ব SQL ইন্টারফেস ব্যবহার করে BigQuery এবং AlloyDB-এর ডেটা অ্যাক্সেস করতে পারেন।
AlloyDB থেকে BigQuery ডেটা কোয়েরি করার জন্য একটি ভঙ্গুর ETL পাইপলাইন তৈরি করার পরিবর্তে, আমরা ফেডারেটেড কোয়েরি ব্যবহার করব। AlloyDB একটি সমন্বিত এন্ডপয়েন্ট হিসেবে কাজ করবে, যা প্রয়োজনে নির্বিঘ্নে BigQuery-তে পৌঁছাতে পারবে।
চলুন নির্মাণ শুরু করা যাক!
আপনি যা শিখবেন
- এক ক্লিকেই কীভাবে AlloyDB ক্লাস্টার, ইনস্ট্যান্স এবং নেটওয়ার্কিং সেট আপ করবেন
- ফেডারেশনের জন্য প্রস্তুতি নিতে কীভাবে এক্সটেনশন সেট আপ করবেন
- BigQuery থেকে AlloyDB-তে ফেডারেশন কীভাবে সেট আপ করবেন
- পরীক্ষা করে দেখুন
প্রয়োজনীয়তা
- একটি ব্রাউজার, যেমন ক্রোম বা ফায়ারফক্স ।
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
- SQL সম্পর্কে প্রাথমিক ধারণা।
২. শুরু করার আগে
একটি প্রকল্প তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন ।
- আপনি ক্লাউড শেল ব্যবহার করবেন, যা গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ। গুগল ক্লাউড কনসোলের শীর্ষে থাকা ‘Activate Cloud Shell’-এ ক্লিক করুন।

- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি নিম্নলিখিত কমান্ডটি ব্যবহার করে যাচাই করে নিন যে আপনি ইতিমধ্যেই প্রমাণীকৃত এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে:
gcloud auth list
- gcloud কমান্ডটি আপনার প্রজেক্ট সম্পর্কে অবগত আছে কিনা, তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান।
gcloud config list project
- আপনি যদি প্রমাণীকরণ করতে চান
gcloud auth login
- আপনার প্রজেক্টটি সেট করা না থাকলে, এটি সেট করতে নিম্নলিখিত কমান্ডটি ব্যবহার করুন:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- প্রয়োজনীয় API-গুলো সক্রিয় করুন: সমস্ত প্রয়োজনীয় API সক্রিয় করতে এই কমান্ডটি চালান:
gcloud services enable alloydb.googleapis.com
অপ্রত্যাশিত সমস্যা ও সমাধান
"ঘোস্ট প্রজেক্ট" সিন্ড্রোম | আপনি |
বিলিং ব্যারিকেড | আপনি প্রজেক্টটি চালু করেছেন, কিন্তু বিলিং অ্যাকাউন্টটি দিতে ভুলে গেছেন। AlloyDB একটি উচ্চ-ক্ষমতাসম্পন্ন ইঞ্জিন; এর 'গ্যাস ট্যাঙ্ক' (বিলিং) খালি থাকলে এটি চালু হবে না। |
এপিআই প্রচার বিলম্ব | আপনি "এপিআই সক্ষম করুন" এ ক্লিক করেছেন, কিন্তু কমান্ড লাইনে এখনও |
কোটা কোয়াগস | আপনি যদি একটি একেবারে নতুন ট্রায়াল অ্যাকাউন্ট ব্যবহার করেন, তাহলে AlloyDB ইনস্ট্যান্সের জন্য আপনার আঞ্চলিক কোটা শেষ হয়ে যেতে পারে। যদি |
৩. প্রথম পর্বের তথ্যের সংক্ষিপ্ত পুনরালোচনা
এই অংশে, আপনাকে নিশ্চিত করতে হবে যে আমরা অসংগঠিত পিডিএফ থেকে যে সংগঠিত ডেটা বের করেছি তা BigQuery-তে আছে। এখন, যদি আপনি প্রথম অংশটি বাদ দিয়ে থাকেন অথবা আপনার কোনো বিলিং অ্যাকাউন্ট না থাকে, তাতেও কোনো সমস্যা নেই, আপনি নিচের ধাপগুলো সম্পন্ন করে কাজ শুরু করতে পারেন:
আপনার ব্যক্তিগত জিমেইল অ্যাকাউন্ট থেকে গুগল ক্লাউড কনসোলে যান এবং কনসোলের উপরের ডান কোণায় থাকা ‘Activate Cloud Shell’ বোতামটিতে ক্লিক করুন:
তারপর নিচের নো-বিলিং-অ্যাকাউন্ট বিভাগে দেওয়া ধাপগুলো অনুসরণ করুন:
বিলিং অ্যাকাউন্ট ছাড়াই ডেটা উপভোগ করা চালিয়ে যাওয়ার পদক্ষেপ:
- আপনি উপরের গিটহাব রিপো লিঙ্ক থেকে ডেটা সিএসভি ফাইলগুলো (বিগকোয়েরি ডেটা) পেতে পারেন।
- প্রথমে, ক্লাউড শেল টার্মিনাল থেকে নিচের কমান্ডটি চালিয়ে BigQuery ডেটাসেটটি তৈরি করুন:
bq mk --location us-central1 --dataset froyo_data
- এরপর, নিচের কমান্ডগুলো এক এক করে চালিয়ে গিটহাব রিপো থেকে ৮টি ডেটা ফাইল (csv ফাইল) আপনার ওয়ার্কিং ডিরেক্টরিতে ডাউনলোড করুন:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- আপনার নতুন তৈরি করা ডেটাসেটের ডেটা দিয়ে এই টেবিলগুলো তৈরি করতে নিচের কমান্ডগুলো এক এক করে চালান।
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
এখন যেহেতু আমাদের কাছে BigQuery-তে ডেটা আছে, চলুন পরবর্তী ধাপে এগিয়ে যাই।
৪. AlloyDB ক্লাস্টার, ইনস্ট্যান্স এবং নেটওয়ার্ক সেটআপ করুন
একটি ওয়েব-ভিত্তিক কুইক স্টার্ট অ্যাপ্লিকেশন রয়েছে যা আপনাকে AlloyDB ক্লাস্টার, ইনস্ট্যান্স এবং অন্যান্য ডিপেন্ডেন্সি সেট আপ করতে সাহায্য করবে। আপনি এই ল্যাবের ২-৪ ধাপ অনুসরণ করে একটি বোতামে ক্লিক করেই এটি সেট আপ করতে পারেন:
https://codelabs.developers.google.com/quick-alloydb-setup
আপনার ক্লাস্টার তৈরি হয়ে গেলে ক্লাস্টার ওভারভিউ পৃষ্ঠায় যান এবং সেখান থেকে সার্ভিস অ্যাকাউন্টের বিবরণ কপি করুন।
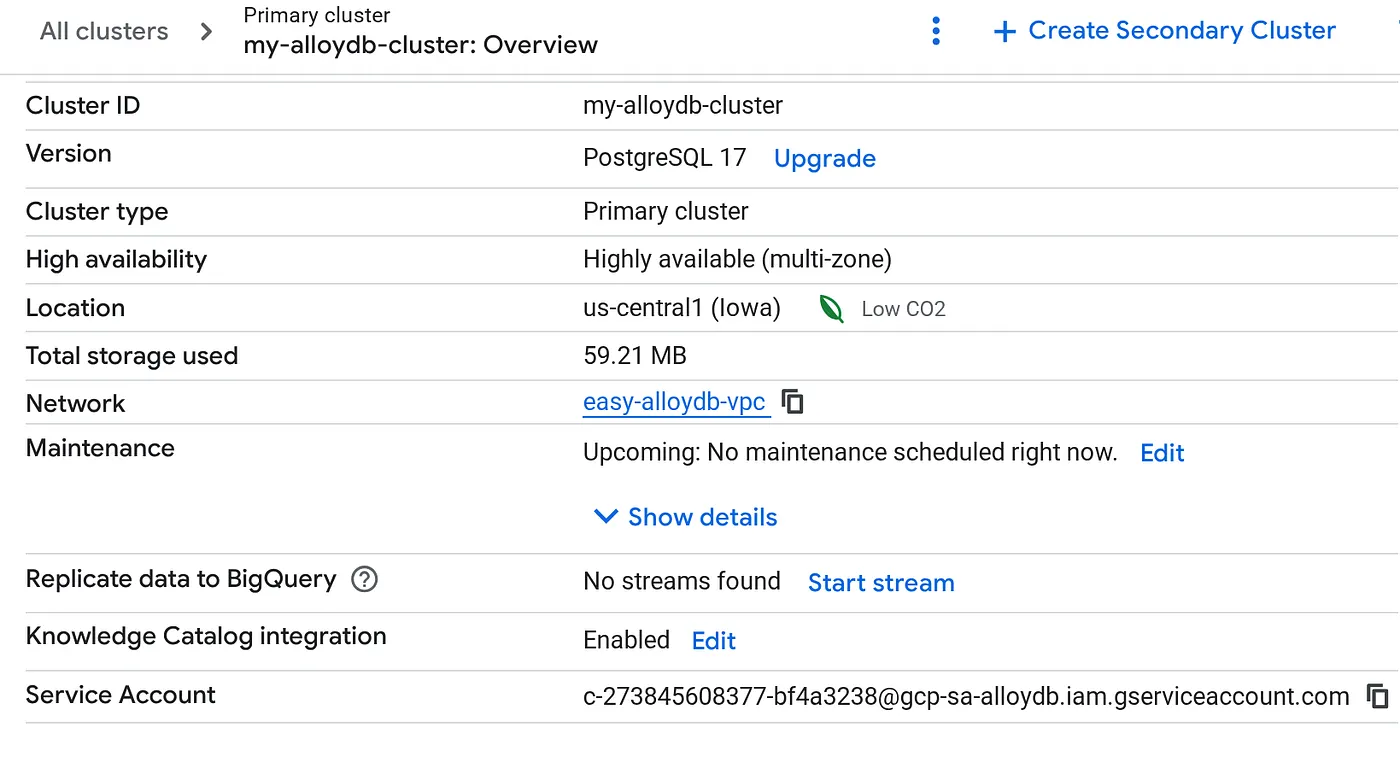
৫. অনুমতি সেটআপ
এই সার্ভিস অ্যাকাউন্টকে BigQuery অনুমতি প্রদান করুন
- IAM & Admin > IAM-এ নেভিগেট করুন।
- অ্যাক্সেস মঞ্জুর করুন-এ ক্লিক করুন।
- AlloyDB সার্ভিস অ্যাকাউন্টের ঠিকানাটি 'New principals' ফিল্ডে পেস্ট করুন।
- নিম্নলিখিত ভূমিকাগুলি অর্পণ করুন:
- BigQuery ডেটা ভিউয়ার (roles/bigquery.dataViewer): ডেটা পড়ার সুযোগ দেয়।
- BigQuery ব্যবহারকারী (roles/bigquery.user): কোয়েরি চালানোর অনুমতি দেয়।
- (ঐচ্ছিক কিন্তু প্রস্তাবিত) BigQuery Read Session User (roles/bigquery.readSessionUser): Storage Read API-এর মাধ্যমে বৃহৎ ডেটাসেট পড়ার প্রক্রিয়াকে অপ্টিমাইজ করে।
৬. AlloyDB-এর সাথে সংযোগ করুন এবং BigQuery এক্সটেনশনটি সক্রিয় করুন।
এখন আমরা ফেডারেশন এক্সটেনশনটি কনফিগার করার জন্য আমাদের নতুন AlloyDB ইনস্ট্যান্সের সাথে সংযোগ স্থাপন করব। এর জন্য আমরা AlloyDB Studio ব্যবহার করব।
- আপনার ক্লাস্টার ওভারভিউ পৃষ্ঠা (অ্যালয়ডিবি কনসোল) থেকে, আপনার প্রাইমারি ইনস্ট্যান্সের উপর " এডিট প্রাইমারি "-তে ক্লিক করুন এবং একদম নিচে " অ্যাডভান্সড কনফিগারেশন অপশনস " পর্যন্ত স্ক্রল করুন।
- " Flags " বিভাগে যান এবং নিচে দেখানো অনুযায়ী দুটি ফ্ল্যাগ " On " করুন:
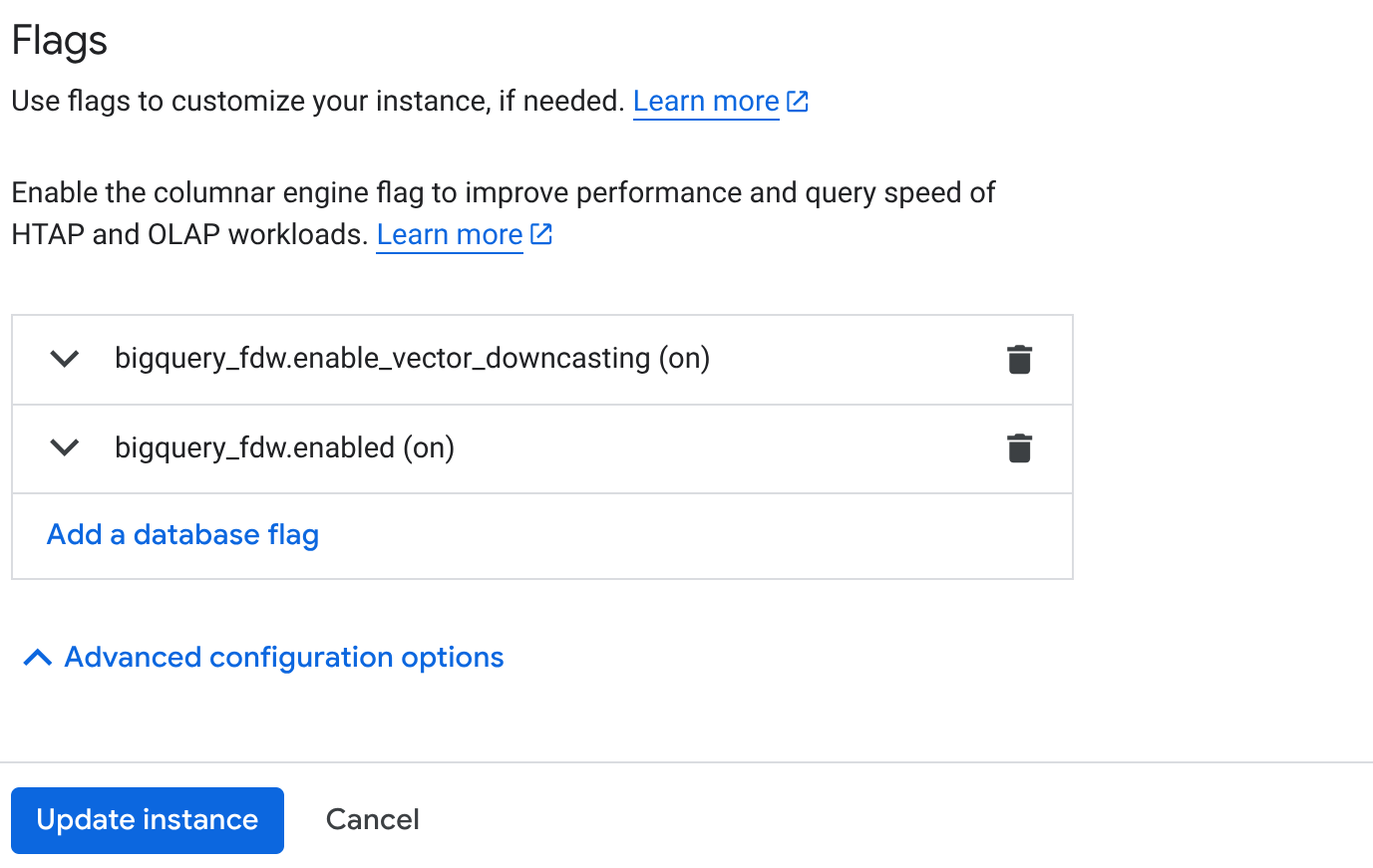 ৩. **আপডেট ইনস্ট্যান্স** বোতামে ক্লিক করুন এবং আপডেটটি সম্পন্ন হতে কয়েক মিনিট সময় লাগবে। ৪. আপনার ক্লাস্টার ওভারভিউ পৃষ্ঠা (অ্যালয়ডিবি কনসোল) থেকে, অ্যালয়ডিবি স্টুডিও-তে ক্লিক করুন।
৩. **আপডেট ইনস্ট্যান্স** বোতামে ক্লিক করুন এবং আপডেটটি সম্পন্ন হতে কয়েক মিনিট সময় লাগবে। ৪. আপনার ক্লাস্টার ওভারভিউ পৃষ্ঠা (অ্যালয়ডিবি কনসোল) থেকে, অ্যালয়ডিবি স্টুডিও-তে ক্লিক করুন। 
- AlloyDB কুইক সেটআপ ধাপে আপনার সেট করা ইউজারনেম এবং পাসওয়ার্ড দিয়ে ডাটাবেসে সংযোগ করুন।
- সংযোগ স্থাপন হয়ে গেলে, ডানদিকের কোয়েরি এডিটর ট্যাবে নিচের স্টেটমেন্টগুলো লিখে এক এক করে রান করুন:
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- একবার সফলভাবে সম্পন্ন হলে, বাম দিকের এক্সপ্লোরার প্যানে যান এবং BigQuery টেবিল পর্যন্ত স্ক্রোল করুন:
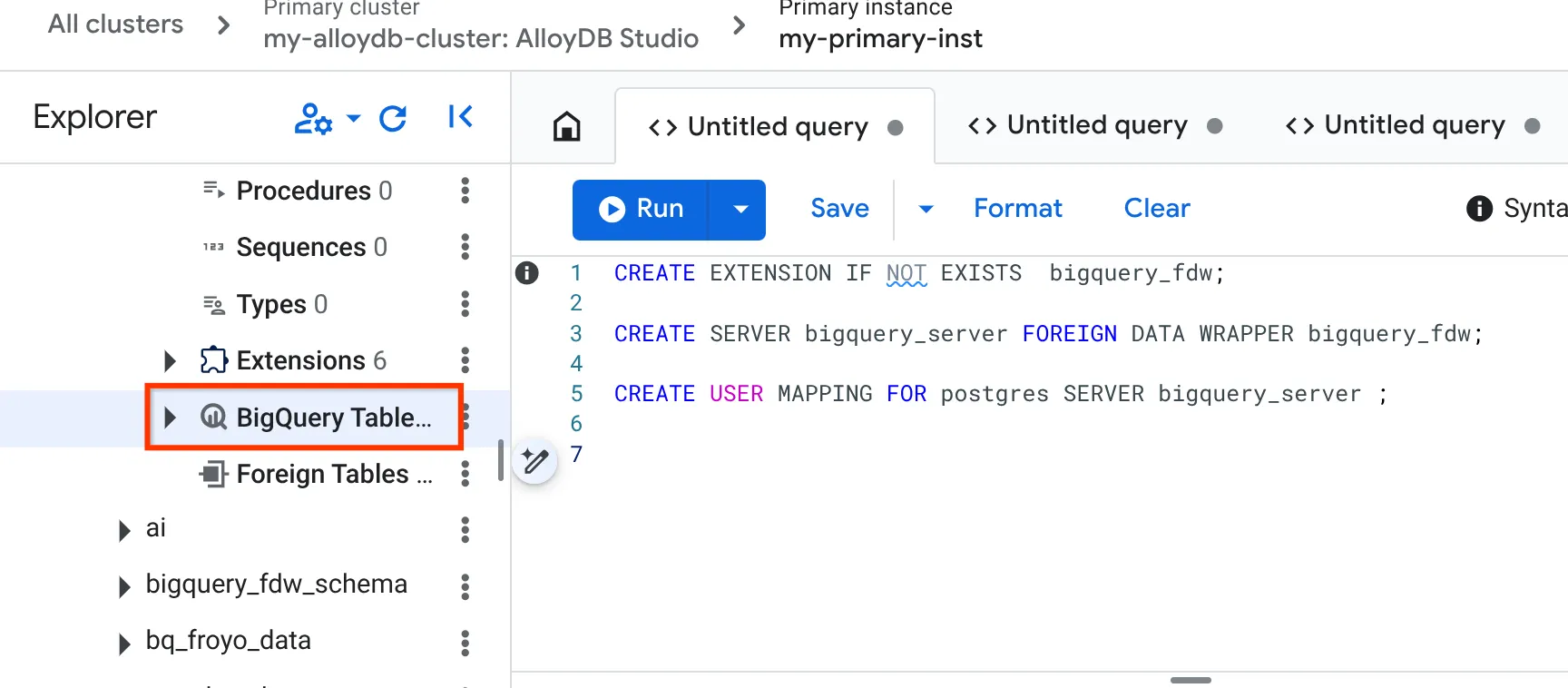
- ৩টি ডটে ক্লিক করুন এবং " Connect BigQuery Table "-এ ক্লিক করুন।
- যে Connect BigQuery Table পপআপটি খুলবে, সেখানে আপনার project_id এবং BigQuery ডেটাসেটের নামটি (যা পার্ট ১-এ তৈরি করা হয়েছে) নির্বাচন করুন, যেখান থেকে আপনি আপনার AlloyDB ডাটাবেসের ডেটা কোয়েরি করতে চান।
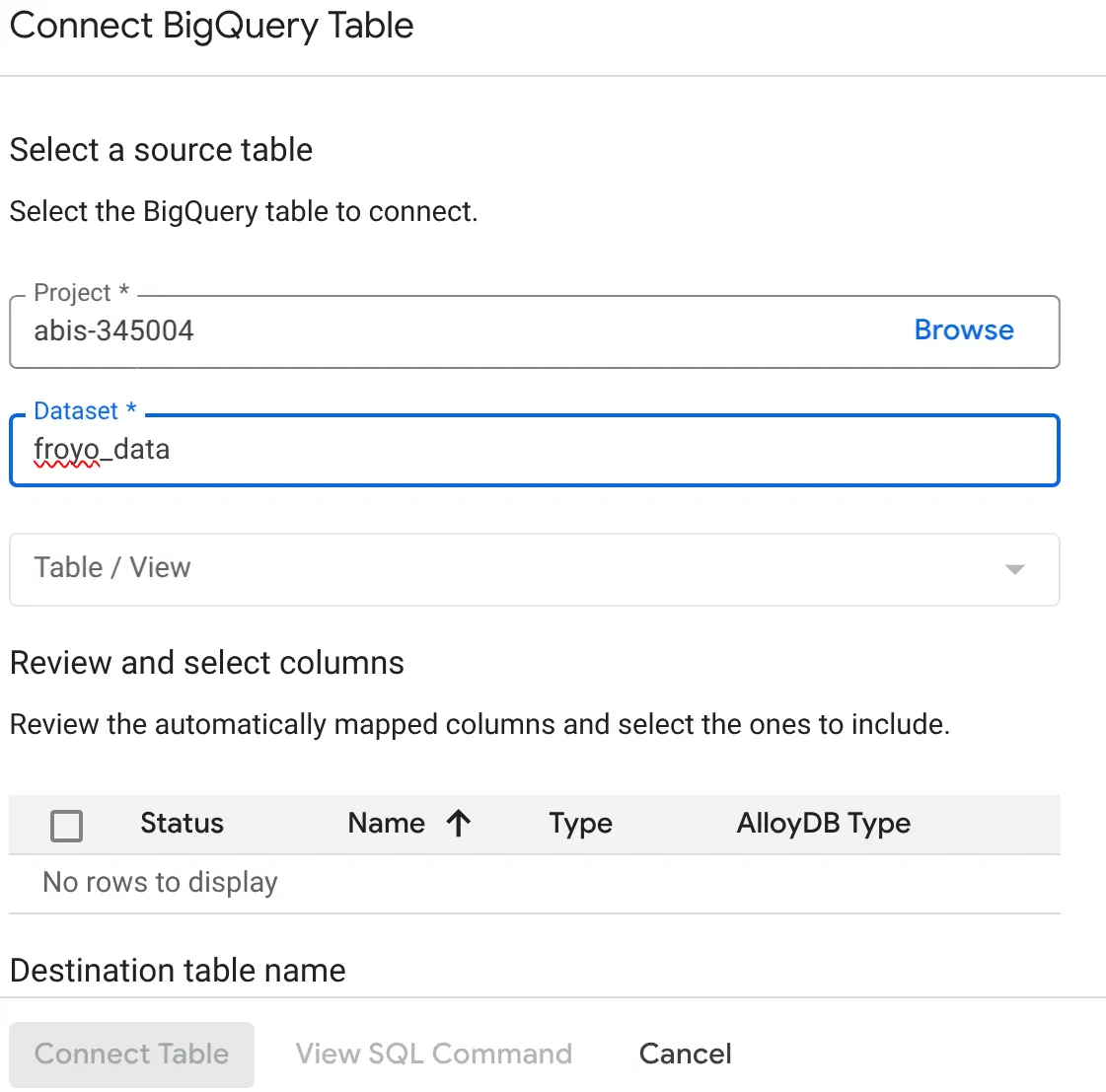
- আপনার সমস্ত ডেটা AlloyDB-এর সাথে সংযুক্ত করতে প্রতিটি টেবিল এক এক করে নির্বাচন করুন। এর মাধ্যমে আমরা কলামের ধরনগুলো যাচাই করে নিশ্চিত করি যে সেগুলো AlloyDB-তে সমর্থিত।
আপনি যদি পয়েন্ট-এন্ড-ক্লিক পদ্ধতির পরিবর্তে SQL ব্যবহার করে একই কাজটি করতে চান:
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
জাদু!!!
আমরা এইমাত্র AlloyDB-তে "ফরেন টেবিল" তৈরি করেছি। এগুলো দেখতে ও কাজ করতে সাধারণ PostgreSQL টেবিলের মতোই, কিন্তু এগুলোতে কোনো ডেটা জমা থাকে না। যখন আপনি এগুলোতে কোয়েরি করেন, AlloyDB সঙ্গে সঙ্গে কোয়েরিটি BigQuery-তে পাঠিয়ে দেয়, ফলাফল সংগ্রহ করে এবং আপনাকে তা ফেরত দেয়।
৭. AlloyDB-তে ফেডারেশনটি পরীক্ষা করুন।
চলুন যাচাই করে দেখি যে আমরা আমাদের ট্রানজ্যাকশনাল PostgreSQL ডাটাবেস থেকে সরাসরি আমাদের বিশাল, অ্যানালিটিক্যাল BigQuery ডাটাবেসে কোয়েরি করতে পারি কিনা।
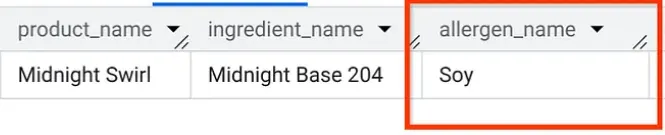
আপনার AlloyDB Studio-তেই, চলুন একটি কোয়েরি চালিয়ে খুঁজে বের করি "Midnight Swirl"-এ কী কী অ্যালার্জেন আছে (প্রথম পর্বে আমরা যে প্রশ্নটি করেছিলাম, এটিও ঠিক সেই একই প্রশ্ন, তবে এবার AlloyDB থেকে করা!):
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
ব্যাস। BigQuery-তে আপনি যেমনটা ফলাফল পেয়েছিলেন, ঠিক তেমনই দেখতে পাবেন।
৮. পরিষ্কার করুন
এই ল্যাবটি সম্পন্ন হয়ে গেলে, AlloyDB ক্লাস্টার এবং ইনস্ট্যান্সটি মুছে ফেলতে ভুলবেন না।
এটি ক্লাস্টারটিকে তার ইনস্ট্যান্স(গুলি) সহ পরিষ্কার করে দেবে।
৯. আপনার ইউনিফাইড ডেটা লেয়ারের জন্য অভিনন্দন।
আমরা এইমাত্র যা অর্জন করেছি তা নিয়ে ভাবুন:
- আমাদের ট্রানজ্যাকশনাল অ্যাপটি (AlloyDB-তে চালিত) দ্রুত গতিতে একই সাথে একাধিক ব্যবহারকারীর সেশন পরিচালনা করতে পারে।
- যখন ব্যাপক বিশ্লেষণমূলক ডেটা বা ঐতিহাসিক প্রেক্ষাপটের (যেমন সরবরাহকারীর বিবরণ বা জটিল উপাদানের ম্যাপিং) প্রয়োজন হয়, তখন এটি BigQuery froyo_dataschema-কে কোয়েরি করে।
- কোনো ETL নেই। ডেটা পাইপলাইন বিকল হওয়ার কোনো সম্ভাবনা নেই। ডেটাবেসগুলোর মধ্যে অসামঞ্জস্যতা নেই। আমরা ডেটা একবারই (BQ-তে) সংরক্ষণ করি এবং প্রয়োজন অনুযায়ী গণনা করি।
এখন যেহেতু আমাদের ডেটার ভিত্তি — বিশ্লেষণাত্মক এবং লেনদেনমূলক উভয়ই — অত্যন্ত মজবুত ও পরস্পর সংযুক্ত, আমরা মজার অংশের জন্য প্রস্তুত।
তৃতীয় পর্বে , আমরা এই আর্কিটেকচারের উপর ভিত্তি করে মাল্টি-এজেন্ট অ্যাপ্লিকেশনটি তৈরি করব, যা ফ্রোয়ো-র ব্যবসায়িক কার্যক্রমগুলো পরিচালনা করবে!