
1. Übersicht
Wir alle kennen das Problem mit „Dark Data“. Es handelt sich um die PDFs, Bilder und Textdateien, die sich in Cloud Storage-Buckets befinden und für Ihre SQL-Abfragen und BI-Dashboards völlig unsichtbar sind. Bisher waren für den Zugriff auf diese Daten komplexe OCR-Pipelines, manuelle Dateneingabe oder anfällige benutzerdefinierte Scripts erforderlich.
Das ist kein Problem mehr.
In diesem Lab zeige ich Ihnen, wie Sie 400 unstrukturierte PDF-Dateien mit Text, Tabellen und Bildern in übersichtlich strukturierte BigQuery-Tabellen konvertieren, wobei Beziehungen zwischen den Tabellen automatisch abgeleitet werden. Mit BigQuery Knowledge Catalog und Dataplex dauert das nur wenige Minuten.
Aufgaben
Sehen wir uns dazu ein fiktives Unternehmen an: ein schnell wachsendes Frozen Yogurt-Franchise.
Stellen Sie sich vor, Sie verwalten die Daten für dieses Froyo-Unternehmen. Sie haben Hunderte von Rezepten und Spezifikationen von Lieferanten, die alle als PDFs gespeichert sind. Die Führungskräfte möchten einen KI-Agenten einführen, mit dem Filialleiter und Kunden Produktdetails abfragen können.
Hier ist das Worst-Case-Szenario: Ein Kunde fragt: „Ich interessiere mich sehr für Ihr Midnight Swirl-Frozen Yogurt. Sind Allergene enthalten?“
Um diese Frage zu beantworten, müsste Ihr System normalerweise Folgendes tun:
- Suchen Sie nach dem PDF-Rezept für „Midnight Swirl“.
- Lesen Sie die Zutatenliste (z.B. „Kakaopulver“, „Milchbasis“, „Emulgator X“).
- Dutzende von Lieferanten-PDFs durchsuchen, um die Datenblätter für diese spezifischen Inhaltsstoffe zu finden.
- Prüfen Sie die Lieferantendatenblätter auf versteckte Allergene, die mit diesen Zutaten zusammenhängen.
Einen KI-Agenten zu erstellen, der dies spontan durch Lesen von 400 rohen PDFs zur Laufzeit erledigt, ist langsam, teuer und anfällig für Halluzinationen. Stattdessen verwenden wir die semantische Inferenz, um all diese Informationen zuerst in eine relationale Datenbank zu extrahieren. Dadurch wird unser zukünftiger KI-Agent blitzschnell und basiert zu 100% auf faktischen SQL-Daten.
Legen wir los!
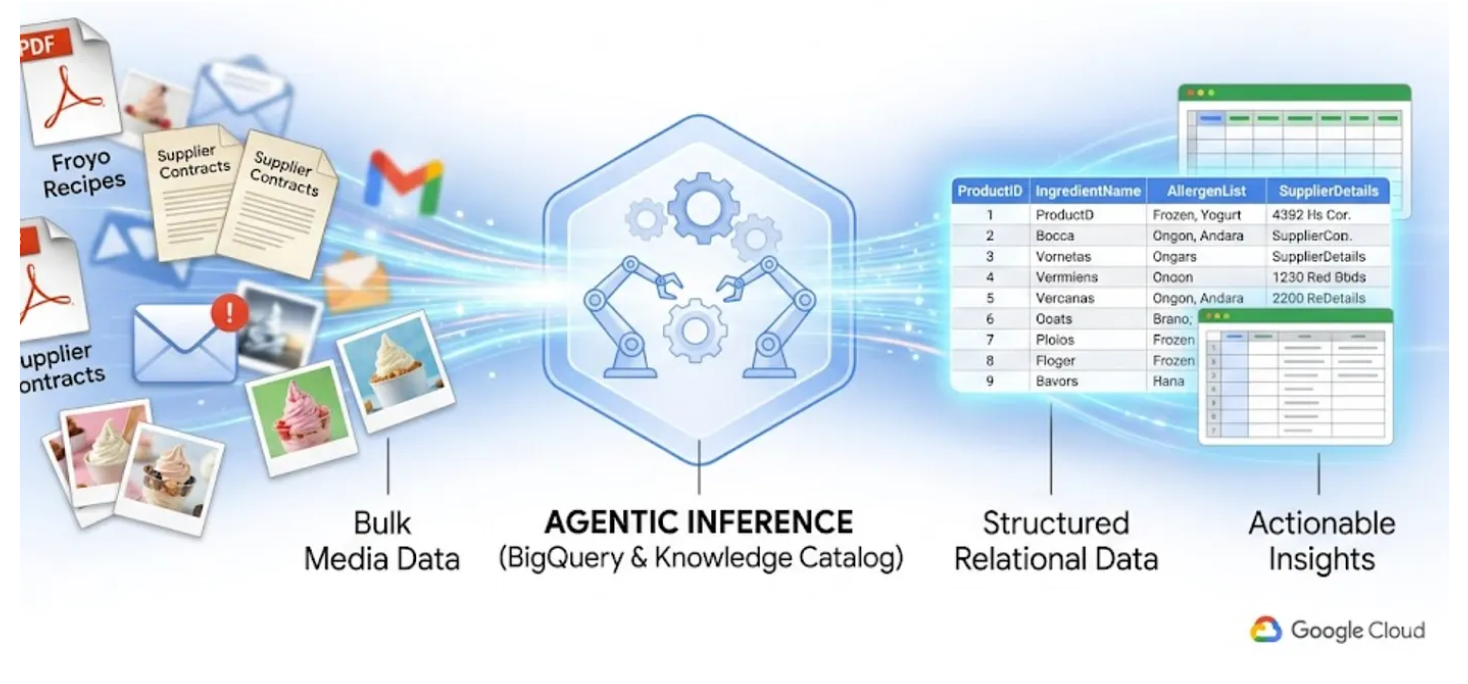
Lerninhalte
- Cloud Storage-Bucket für die Quelldateien (PDFs) einrichten
- Datascan-Job und semantische Inferenz in Knowledge Catalog einrichten und ausführen, um Daten aus Quell-PDFs zu extrahieren, Verbindungen und Kontext semantisch abzuleiten und in BigQuery zu speichern
- BigQuery-Agents verwenden, um mit dem neu erstellten Dataset zu chatten
Voraussetzungen
2. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.

- Sobald die Verbindung mit der Cloud Shell hergestellt ist, können Sie mit dem folgenden Befehl prüfen, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu prüfen, ob der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Sie sich authentifizieren möchten,
gcloud auth login
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Aktivieren Sie die erforderlichen APIs: Führen Sie diesen Befehl aus, um alle erforderlichen APIs zu aktivieren:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
Fallstricke und Fehlerbehebung
Das „Geisterprojekt“-Syndrom | Sie haben |
Die Abrechnungsbarrikade | Sie haben das Projekt aktiviert, aber das Rechnungskonto vergessen. AlloyDB ist eine leistungsstarke Engine, die nicht startet, wenn der „Benzintank“ (Abrechnung) leer ist. |
Verzögerung bei der API-Weitergabe | Sie haben auf „APIs aktivieren“ geklickt, aber in der Befehlszeile wird weiterhin |
Kontingent -Quags | Wenn Sie ein brandneues Testkonto verwenden, erreichen Sie möglicherweise ein regionales Kontingent für AlloyDB-Instanzen. Wenn |
Verborgener Kundenservicemitarbeiter | Manchmal wird dem AlloyDB-Dienst-Agenten die Rolle |
3. Google Cloud Storage-Bucket einrichten
In diesem Abschnitt erstellen Sie eine Organisationsstruktur in BigQuery, um Froyo-Rezept- und ‑Lieferantendaten speziell für Froyo-Produktdetails zu speichern. Außerdem wird eine Cloud-Ressourcenverbindung eingerichtet, die als sichere „Brücke“ fungiert, über die BigQuery Dateien aus externen Quellen wie Cloud Storage lesen kann.
Hinweise:
Dieses Repository enthält Rezepte und PDF-Dateien von Lieferanten, die wir in diesem Projekt verwenden. Laden Sie diese Dateien herunter. So laden Sie die Dateien herunter:
Führen Sie in Cloud Shell den folgenden Befehl aus:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
Wechseln Sie in den neu erstellten Ordner:
cd next-26-keynotes
Rufen Sie den Ordner data-cloud-demo ab.
git sparse-checkout set genkey/data-cloud-demo
Wechseln Sie nach Abschluss des Check-outs zum Ordner data-cloud-demo und entpacken Sie die ZIP-Dateien, um auf die Codelab-Assets zuzugreifen.
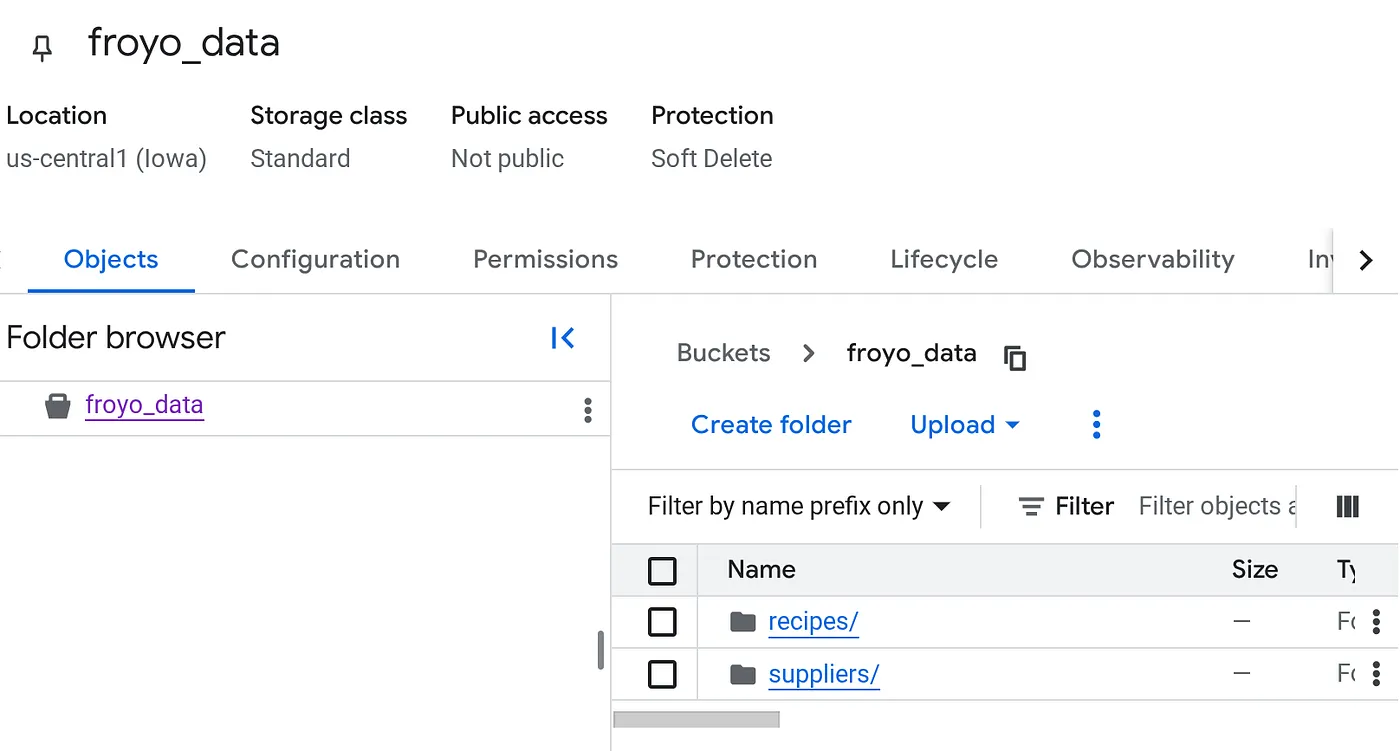
Bucket erstellen und Froyo-PDF-Dateien (Rezepte und Lieferanten) hochladen
- Wechseln Sie in der Google Cloud Console zur Seite Cloud Storage-Buckets.
- Klicken Sie auf „Erstellen“.
- Geben Sie auf der Seite Bucket erstellen die Bucket-Informationen ein. Klicken Sie nach jedem der folgenden Schritte auf „Weiter“, um mit dem nächsten Schritt fortzufahren:
- Geben Sie im Bereich Erste Schritte den Namen des Buckets ein. Beispiel: froyo_data
- Wählen Sie im Abschnitt Speicherort für Daten auswählen die Option „Region“ aus und geben Sie dann Ihre Region ein. us-central1
- Entfernen Sie im Abschnitt Legen Sie fest, wie der Zugriff auf Objekte gesteuert wird das Häkchen bei „Verhinderung des öffentlichen Zugriffs für diesen Bucket erzwingen“.
- Klicken Sie auf „Erstellen“.
- Klicken Sie in der Liste der Buckets auf den Bucket, den Sie erstellt haben.
- Klicken Sie auf dem Tab Objekte für den Bucket auf „Hochladen“ und dann auf „Ordner hochladen“.
- Wählen Sie den Ordner recipes aus, den Sie im Abschnitt „Vorbereitung“ dieses Codelabs extrahiert haben.
- Klicken Sie auf Hochladen.
- Wiederholen Sie den Uploadvorgang für den Ordner suppliers.
Nach dem Hochladen sollte Ihre Bucket-Struktur so aussehen (unabhängig vom Bucket-Namen):
4. BigQuery-Verbindung einrichten
Cloud-Ressourcenverbindung erstellen Dadurch wird ein eindeutiges Dienstkonto generiert, das als „Ausweis“ von BigQuery für den Zugriff auf externe Dateien dient.
- Rufen Sie die Seite BigQuery auf.
- Klicken Sie im linken Bereich auf „Explorer“. Wenn Sie den linken Bereich nicht sehen, klicken Sie auf „Linken Bereich maximieren“, um ihn zu öffnen.
- Maximieren Sie im Bereich „Explorer“ den Namen Ihres Projekts und klicken Sie dann auf „Verbindungen“.
- Klicken Sie auf der Seite „Verbindungen“ auf „Verbindung erstellen“.
- Wählen Sie als Verbindungstyp „Vertex AI-Remote-Modelle, Remote-Funktionen, BigLake und Cloud Spanner (Cloud-Ressource)“ aus.
- Geben Sie im Feld „Verbindungs-ID“ den Namen der Verbindungs-ID ein:
- bq-connection. Notieren Sie sich diese ID, da Sie sie später in diesem Codelab benötigen, wenn Sie den Datenscan einrichten.
- Legen Sie den Standorttyp auf „Region“ fest und wählen Sie dann eine Region aus. Beispiel: us-central1. Die Verbindung sollte sich in derselben Region wie Ihre anderen Ressourcen, z. B. Datasets, befinden.
- Klicken Sie auf „Verbindung erstellen“.
- Klicken Sie auf „Zur Verbindung“.
- Kopieren Sie im Bereich „Verbindungsinformationen“ die Dienstkonto-ID zur Verwendung in einem späteren Schritt. Das Dienstkonto sieht in etwa so aus: bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
5. Berechtigungen einrichten
- Der BigQuery-Verbindung die erforderlichen Berechtigungen für den Zugriff auf Cloud Storage-Objekte und den Knowledge Catalog erteilen
Rufen Sie die Seite „IAM & Verwaltung“ auf und klicken Sie im Bereich „Nach Hauptkonten ansehen“ auf die Schaltfläche „Zugriff gewähren“. Fügen Sie ein Hauptkonto hinzu, indem Sie das im letzten Schritt kopierte Dienstkonto einfügen. Fügen Sie im Abschnitt „Rollen“ die Namen der folgenden Rollen einzeln hinzu und speichern Sie:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- Dataplex-Dienstkonto Berechtigungen für den Zugriff auf den Cloud Storage-Bucket erteilen
Rufen Sie die Seite IAM und Verwaltung auf und klicken Sie im Bereich Nach Hauptkonten ansehen auf die Schaltfläche Zugriff gewähren. Fügen Sie ein Hauptkonto hinzu, indem Sie das Wort dataplex in die Textleiste „Neues Hauptkonto“ eingeben. Wählen Sie aus der Liste, die automatisch vervollständigt wird, den Dataplex-Dienstkonto-Principal aus, der so aussieht: (Verwenden Sie die Projektnummer und nicht die Projekt-ID in der E-Mail-ID des Dienstkontos unten.)
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Wenn das oben genannte Dienstkonto für Ihre Projektnummer aus irgendeinem Grund nicht erkannt wird, wurde der Dataplex-Dienst möglicherweise noch nicht für das Projekt initialisiert. Rufen Sie das Cloud Shell-Terminal auf und versuchen Sie, die API zu aktivieren (falls dies nicht bereits in der Phase Vorbereitung geschehen ist), indem Sie den folgenden Befehl ausführen: gcloud services enable dataplex.googleapis.com
Wenn das Dienstkonto für Dataplex auch danach nicht erkannt wird, erzwingen Sie das Erstellen eines Test-Dataplex-Scanjobs auf der Seite Metadaten-Curation und geben Sie die Details auf der Seite zum Erstellen von Discover-Jobs ein:
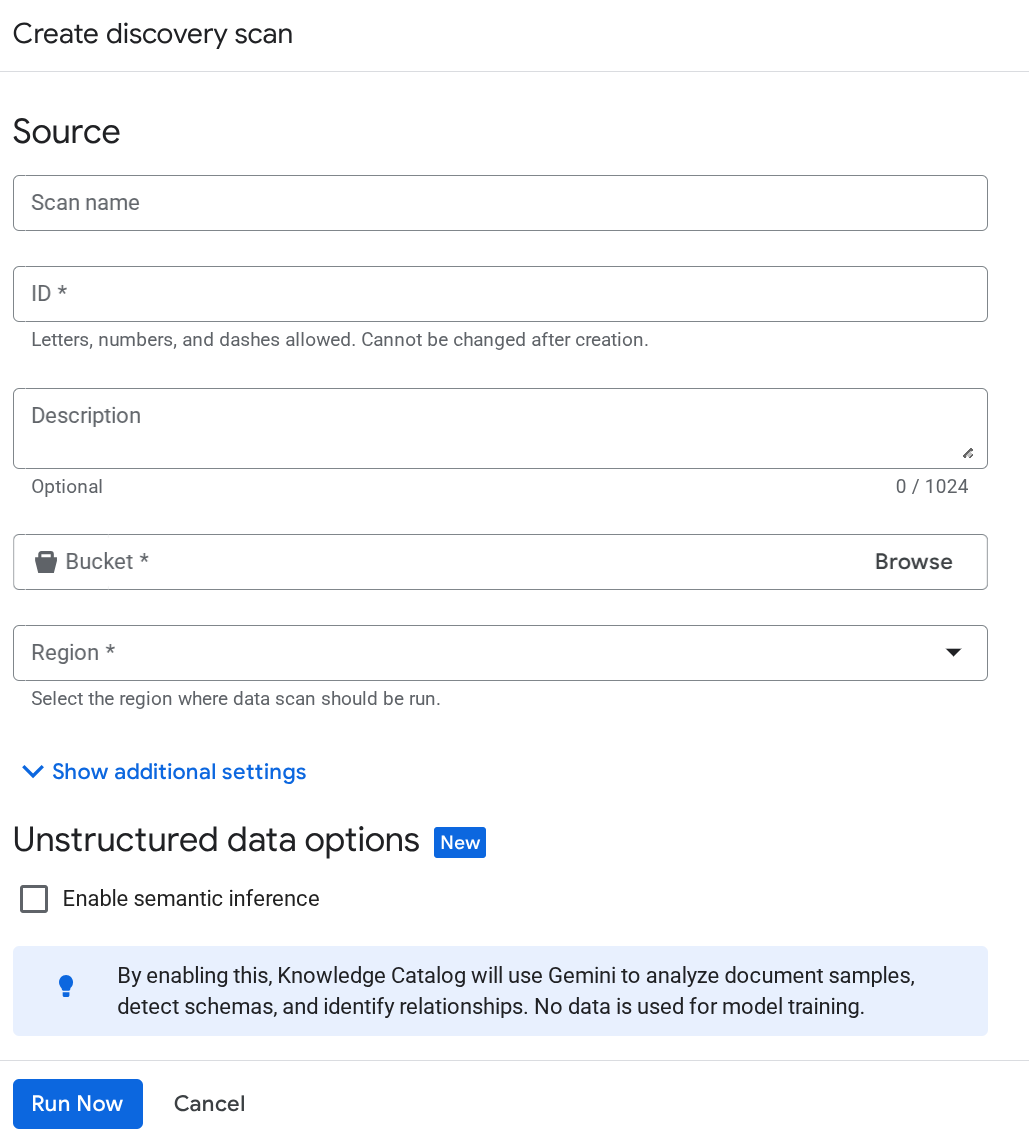
Klicken Sie auf Jetzt ausführen. Der Job schlägt fehl, aber die Dienstkonto-ID wird jetzt für Ihren Dataplex-Dienst initialisiert.
Kehren Sie zur Seite IAM & Verwaltung zurück und klicken Sie im Bereich Nach Hauptkonten ansehen auf die Schaltfläche Zugriff gewähren und dann auf „Hauptkonto hinzufügen“. Fügen Sie das Dienstkonto ein:
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Weisen Sie diesem Dienstkonto dann die folgenden Rollen zu:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. Knowledge Catalog einrichten
Erstellen Sie einen Knowledge Catalog, um die unstrukturierten Daten zu vereinheitlichen und die Erkennung unstrukturierter Dateien (z. B. PDF-Rezepte und PDF-Lieferanten) zu automatisieren.
DataScan-Job über die Konsole erstellen:
- Rufen Sie die Seite Metadaten-Kurierung auf.
- Klicken Sie auf „Erstellen“ und geben Sie die Details für Ihre Einrichtung ein:
Wichtiger Hinweis: Vergessen Sie nicht, „Semantische Inferenz aktivieren“ anzukreuzen.
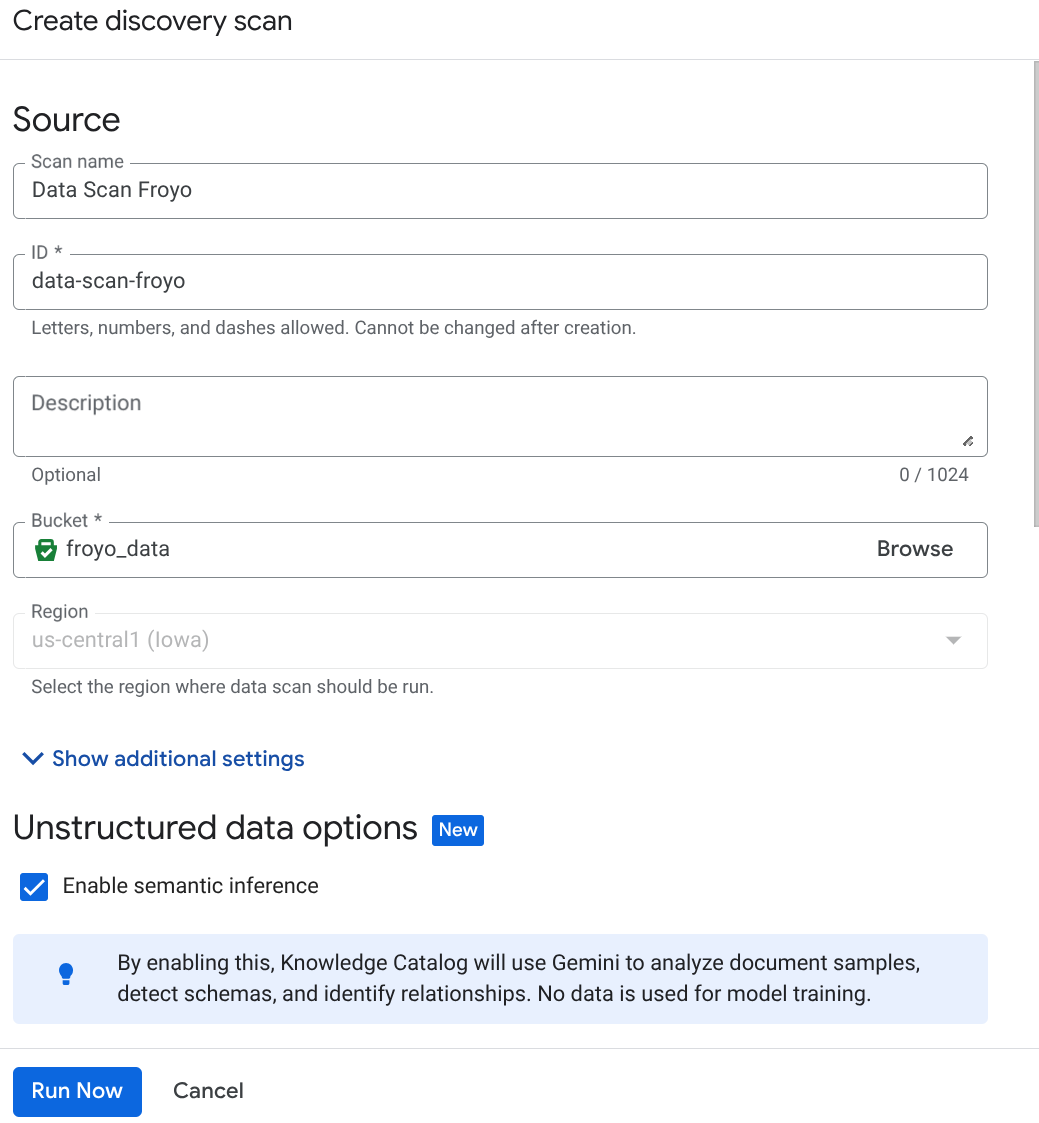
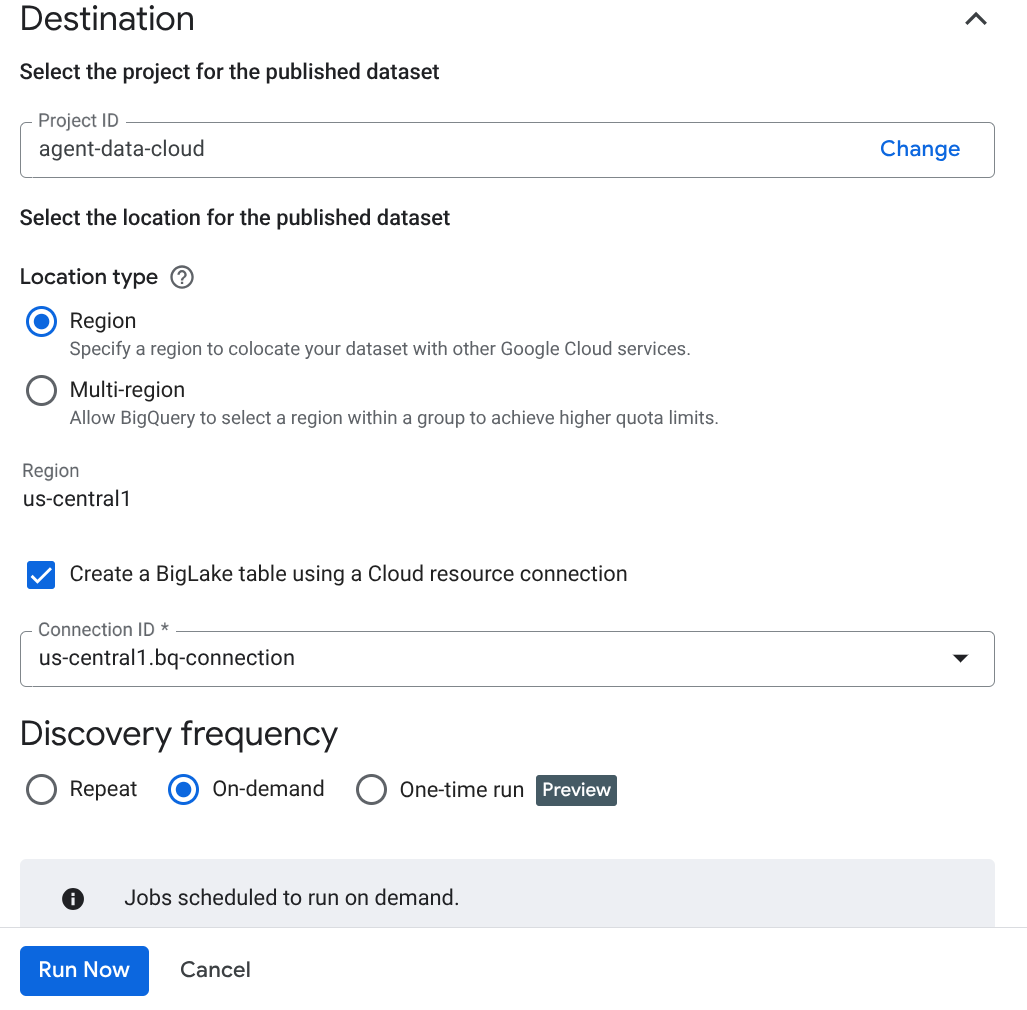
- Klicken Sie auf „Jetzt ausführen“.
- Es dauert einige Zeit, bis der Scanvorgang abgeschlossen ist. Prüfen Sie nach Abschluss des Jobs, ob das veröffentlichte Dataset vorhanden ist. Um den Jobstatus zu prüfen, können Sie auf der Seite Metadata curation (Metadaten-Curation) auf dem Tab „Cloud Storage discovery“ (Cloud Storage-Erkennung) auf den Namen der Erkennungsscans des letzten Laufs klicken. Das veröffentlichte Dataset sollte wie unten dargestellt angezeigt werden:
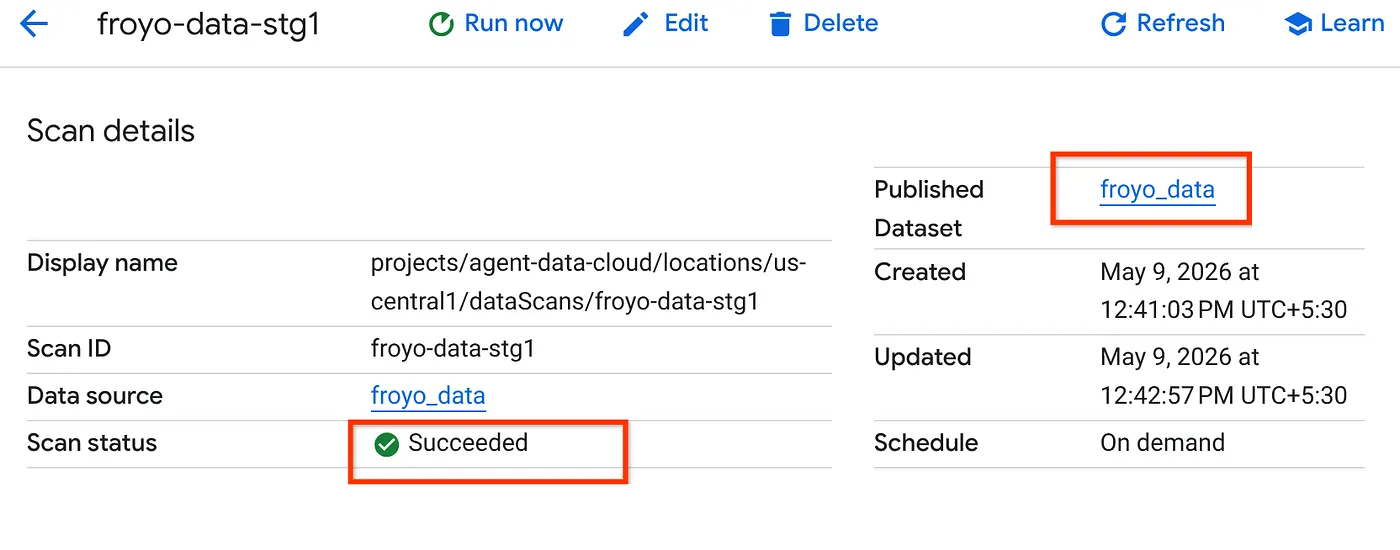
Hinweis: Wenn beim Scannen Fehler auftreten, warten Sie einige Zeit und versuchen Sie es dann noch einmal. Es dauert einige Minuten, bis der Job erstellt und die Ausführung abgeschlossen ist.
- Sie können die Tabelle in BigQuery aufrufen, indem Sie auf das Dataset froyo_data klicken. Klicken Sie in BigQuery auf die Tabellen-ID und führen Sie die folgende Abfrage auf dem Tab „Abfrageeditor“ aus:
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
Das Ergebnis ist 400. Wenn nicht, können Sie zurückgehen und den Datascan-Job noch einmal ausführen.
7. Semantische Datenextraktion
Super! Nun extrahieren wir die Inferenz für diese unstrukturierten Objekte mit Knowledge Catalog.
Wir verwenden die Funktion „Insights“, um SQL-Anweisungen zu generieren, mit denen strukturierte Daten aus der unstrukturierten Tabelle extrahiert werden.
- Rufen Sie in der Google Cloud Console die Seite Knowledge Catalog Search auf.
- Suchen Sie nach der Dataset-Tabelle, für die Sie Statistiken aufrufen möchten. Geben Sie in der Suchleiste den Dataset-/Tabellennamen aus dem vorherigen Schritt ein: „froyo_data“ und drücken Sie die Eingabetaste.
- Klicken Sie in der Ergebnisliste auf den Eintrag TABLE (nicht auf den Datensatz).
- Der Tab INSIGHTS sollte angezeigt werden. Klicken Sie darauf. Wenn Sie aufgefordert werden, eine API zu aktivieren, folgen Sie der Anleitung und aktivieren Sie die API.
Wenn Sie an dieser Stelle APIs aktiviert haben, müssen Sie den Scanjob noch einmal ausführen.
- Auf dem Tab „INSIGHTS“ sehen Sie das Drop-down-Menü für die Schaltfläche „EXTRACT“. Klicken Sie darauf und wählen Sie die Option „Mit SQL extrahieren“ aus.
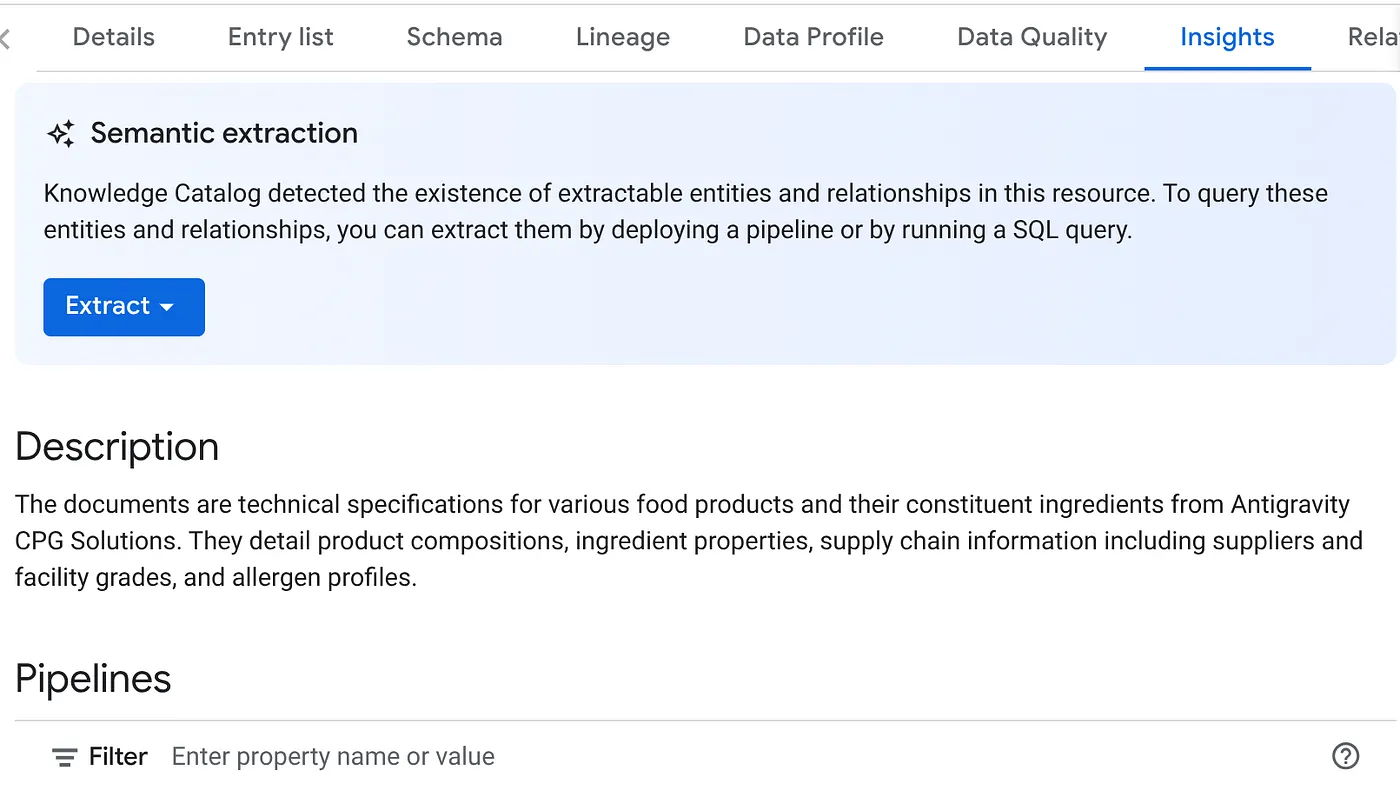
Legen Sie im Pop-up-Dialogfeld Mit SQL extrahieren das ZIEL-Dataset als das Dataset fest, das Sie im Ergebnis des Datascan-Jobs gesehen haben. Beginnen Sie mit der Eingabe des Namens. Er sollte in der automatischen Vervollständigung angezeigt werden. Klicken Sie auf den Button Extrahieren. Alternativ können Sie an dieser Stelle ein neues Dataset erstellen und Daten extrahieren.
Dadurch sollte der BigQuery-Abfrageeditor mit einem Tab geöffnet werden, der mit der extrahierten SQL aus der Datenanalyse-Inferenz gefüllt ist.
8. SQL-Validierung und Schemaerstellung
Wenn die generierte Abfrage gut aussieht und semantisch relevant für Ihre unstrukturierten Daten ist, können Sie sie ausführen, indem Sie im Abfrageeditor auf die Schaltfläche „Ausführen“ klicken. Es dauert einige Minuten, bis das Schema erstellt ist, das für die strukturierte Speicherung Ihrer unstrukturierten Media erforderlich ist.
Anschließend können Sie das Schema überprüfen, indem Sie das Dataset im Explorer-Bereich von BigQuery Studio maximieren (siehe unten):
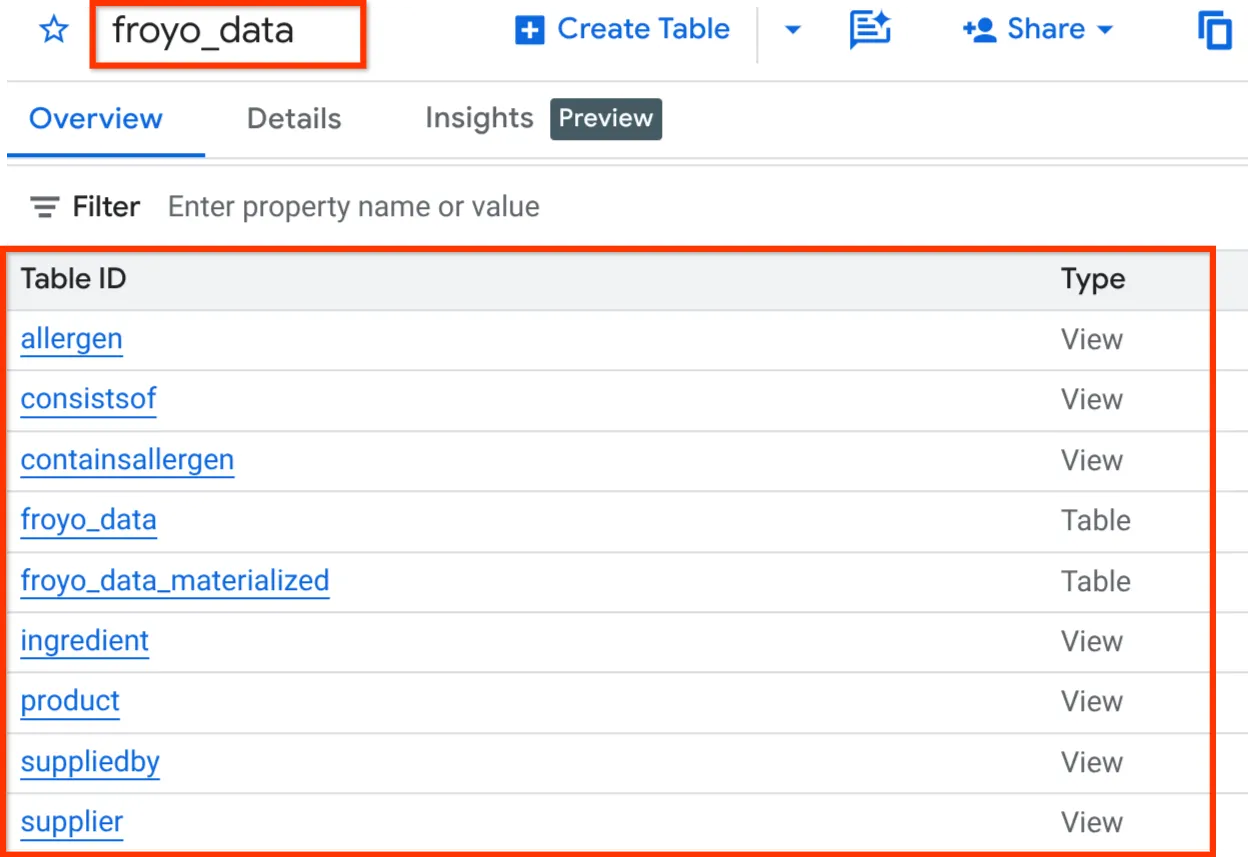
Alles klar! Es war so schön, dass wir all diese Datenbankvorgänge sehr schnell erledigt haben. Jetzt ist es Zeit für den ultimativen Test.
So können Sie weiterhin auf die Daten zugreifen, ohne ein Abrechnungskonto zu haben:
- Sie können die CSV-Dateien (BigQuery-Daten) über den oben genannten GitHub-Link abrufen.
- Erstellen Sie zuerst das BigQuery-Dataset, indem Sie den folgenden Befehl im Cloud Shell-Terminal ausführen:
bq mk --location us-central1 --dataset froyo_data
- Laden Sie als Nächstes die acht Datendateien (CSV-Dateien) aus dem GitHub-Repository in Ihr Arbeitsverzeichnis herunter, indem Sie die folgenden Befehle einzeln ausführen:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Führen Sie die folgenden Befehle nacheinander aus, um diese Tabellen mit den Daten in Ihrem neu erstellten Dataset zu erstellen.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Nachdem das Dataset, die Tabellen und die Daten erstellt wurden, können Sie die Daten, die wir gerade besprochen haben, testen und sich damit vertraut machen.
9. Der ultimative Test!!!
Angenommen, ich möchte, dass mein Agent auf die Fragen des Nutzers mit echten, vollständigen und gut strukturierten Informationen antwortet, die auf Fakten basieren. Ich werde eine Frage stellen, die der Agent nur beantworten kann, wenn er sich auf mehrere Mediendateien und Referenzen aus meiner Quelle bezieht.
Das ist meine Nutzerfrage:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
Bei einer allgemeinen Suche oder einer LLM-Suche wird jetzt „Keine Zutaten“ angezeigt. Wir haben jedoch eine vollständige semantische Inferenz entwickelt, mit der alle unsere unstrukturierten Medien in strukturierte Daten umgewandelt werden. Hier ist eine einfache SQL-Anweisung, mit der Sie diese Informationen abrufen können:
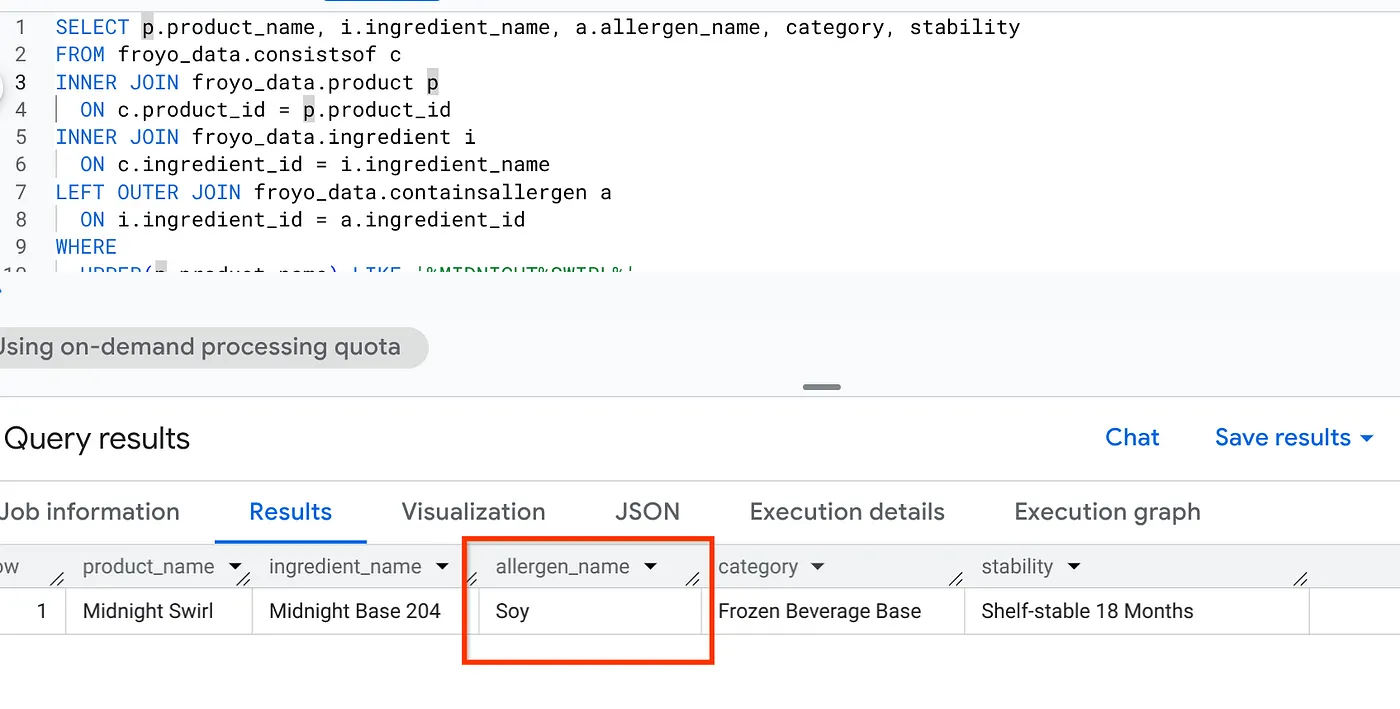
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
Endlich! Sehen Sie sich das Ergebnis an:
10. Bereinigen
Vergessen Sie nicht, den Scanjob und die BigQuery-Tabellen zu löschen, die durch den Job erstellt wurden.
Rufen Sie https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery auf. Wählen Sie den Job aus, den Sie löschen möchten, indem Sie daneben auf das Dreipunkt-Menü klicken, und klicken Sie auf „LÖSCHEN“.
Dadurch sollte der Job bereinigt werden.
11. Glückwunsch
Bei unserer Implementierung konnte das verborgene Allergen erfolgreich identifiziert werden. Schluss mit Dark Data! Im zweiten Teil werden wir diese BigQuery-Daten in einem transaktionalen System mit AlloyDB zusammenführen, um die Datenanforderungen für unsere Agent-Anwendung zu vereinheitlichen.