
1. Übersicht
In Teil 1 haben wir chaotische, unstrukturierte PDFs mit Knowledge Catalog und DataScan in saubere, intelligente und strukturierte Tabellen in BigQuery umgewandelt. Jetzt haben wir ein robustes Data Warehouse.
Zur Erinnerung: Im Lab zu Teil 1 haben wir den Anwendungsfall eines fiktiven Frozen-Yogurt-Franchise-Unternehmens verwendet und 400 unstrukturierte PDF-Dateien mit Text, Tabellen und Bildern in sauber strukturierte BigQuery-Tabellen umgewandelt. Dabei wurden die Beziehungen zwischen den Tabellen automatisch mit BigQuery Knowledge Catalog und Dataplex abgeleitet.
Aufgaben
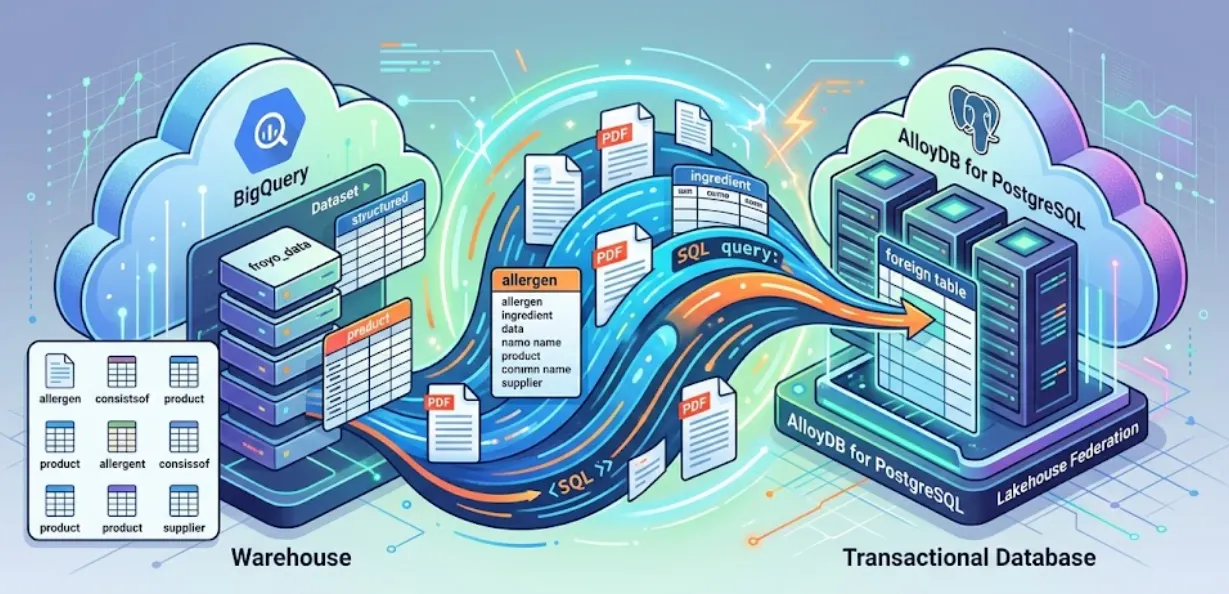
In dieser Sitzung richten wir AlloyDB for PostgreSQL ein und führen etwas Magisches aus: Wir föderieren unsere BigQuery-Daten direkt in AlloyDB. Das bedeutet, dass unsere Transaktionsanwendung unsere Data-Warehouse-Daten in Echtzeit abfragen kann, ohne sie kopieren oder duplizieren zu müssen.
Als Entwickler müssen Sie sich an dieser Stelle Folgendes fragen:
„Wenn die Daten bereits in BigQuery sind, warum dann AlloyDB? Warum führt die Anwendung nicht einfach eine SELECT-Anweisung direkt für BigQuery aus?“
Hier sind die Gründe:
Mit Lakehouse Federation können Sie die Abfrage-Engine von AlloyDB verwenden, um die transaktionalen und analytischen Arbeitslasten Ihrer Anwendung über dieselbe Oberfläche zu verarbeiten. Sie können diese Daten auch in AlloyDB materialisieren oder importieren, um schneller darauf zugreifen zu können. So können Sie AlloyDB AI und die spaltenbasierte Engine verwenden.
Sie können AlloyDB als Transaktionsdatenbank verwenden und große Datenmengen in BigQuery oder BigLake speichern. Ihre Anwendungen werden in der Regel unabhängig in beide Systeme eingebunden, um auf Daten in diesen verschiedenen Google Cloud-Diensten zuzugreifen. Lakehouse Federation for AlloyDB ermöglicht Ihnen die Nutzung der Unterstützung für föderierte Abfragen von AlloyDB, die als Foreign Data Wrapper implementiert ist, um über eine SQL-Schnittstelle in AlloyDB auf BigQuery- und AlloyDB-Daten zuzugreifen.
Anstatt eine fragile ETL-Pipeline zu erstellen, um die BigQuery-Daten aus AlloyDB abzufragen, verwenden wir föderierte Abfragen. AlloyDB fungiert als einheitlicher Endpunkt und greift bei Bedarf nahtlos auf BigQuery zu.
Los geht's!
Lerninhalte
- AlloyDB-Cluster, ‑Instanz und ‑Netzwerk mit einem Klick einrichten
- Erweiterung für die Vorbereitung auf die Föderation einrichten
- Föderation von BigQuery zu AlloyDB einrichten
- Testen
Voraussetzungen
2. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. Informationen zum Prüfen, ob die Abrechnung für ein Projekt aktiviert ist .
- Sie verwenden die Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.

- Sobald die Verbindung mit der Cloud Shell hergestellt ist, prüfen Sie mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie in der Cloud Shell den folgenden Befehl aus, um zu prüfen, ob der gcloud-Befehl Ihr Projekt kennt:
gcloud config list project
- Wenn Sie sich authentifizieren möchten
gcloud auth login
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Aktivieren Sie die erforderlichen APIs: Führen Sie diesen Befehl aus, um alle erforderlichen APIs zu aktivieren:
gcloud services enable alloydb.googleapis.com
Fallstricke und Fehlerbehebung
Das „Ghost Project“-Syndrom | Sie haben |
Die Abrechnungsbarriere | Sie haben das Projekt aktiviert, aber das Rechnungskonto vergessen. AlloyDB ist eine leistungsstarke Engine. Sie wird nicht gestartet, wenn der „Tank“ (Abrechnung) leer ist. |
Verzögerung bei der API-Weitergabe | Sie haben auf „APIs aktivieren“ geklickt, aber in der Befehlszeile wird immer noch |
Kontingentprobleme | Wenn Sie ein brandneues Testkonto verwenden, erreichen Sie möglicherweise ein regionales Kontingent für AlloyDB-Instanzen. Wenn |
3. Kurze Zusammenfassung der Daten aus Teil 1
In diesem Abschnitt müssen Sie dafür sorgen, dass die strukturierten Daten, die wir aus unstrukturierten PDFs extrahiert haben, in BigQuery verfügbar sind. Wenn Sie Teil 1 verpasst haben oder kein Rechnungskonto haben, können Sie die folgenden Schritte ausführen:
Rufen Sie die Google Cloud Console über Ihr privates Gmail-Konto auf und klicken Sie rechts oben in der Console auf die Schaltfläche „Cloud Shell aktivieren“:
Folgen Sie dann der Anleitung im Abschnitt „Kein Rechnungskonto?“ unten:
Schritte, um die Daten ohne Rechnungskonto weiter zu nutzen:
- Sie können die CSV -Dateien mit den BigQuery-Daten über den Link zum GitHub- Repository oben abrufen.
- Erstellen Sie zuerst das BigQuery-Dataset, indem Sie den folgenden Befehl im Cloud Shell-Terminal ausführen:
bq mk --location us-central1 --dataset froyo_data
- Laden Sie als Nächstes die 8 Datendateien (CSV-Dateien) aus dem GitHub-Repository in Ihr Arbeitsverzeichnis herunter, indem Sie die folgenden Befehle einzeln ausführen:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Führen Sie die folgenden Befehle einzeln aus, um diese Tabellen mit den Daten in Ihrem neu erstellten Dataset zu erstellen:
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Nachdem die Daten in BigQuery verfügbar sind, können wir mit den nächsten Schritten fortfahren.
4. AlloyDB-Cluster, ‑Instanz und ‑Netzwerk einrichten
Es gibt eine webbasierte Kurzanleitung, mit der Sie AlloyDB-Cluster, ‑Instanz und andere Abhängigkeiten einrichten können. Folgen Sie dazu den Schritten 2 bis 4 in diesem Lab:
https://codelabs.developers.google.com/quick-alloydb-setup
Nachdem Ihr Cluster erstellt wurde, rufen Sie die Seite „Clusterübersicht“ auf und kopieren Sie die Details des Dienstkontos.
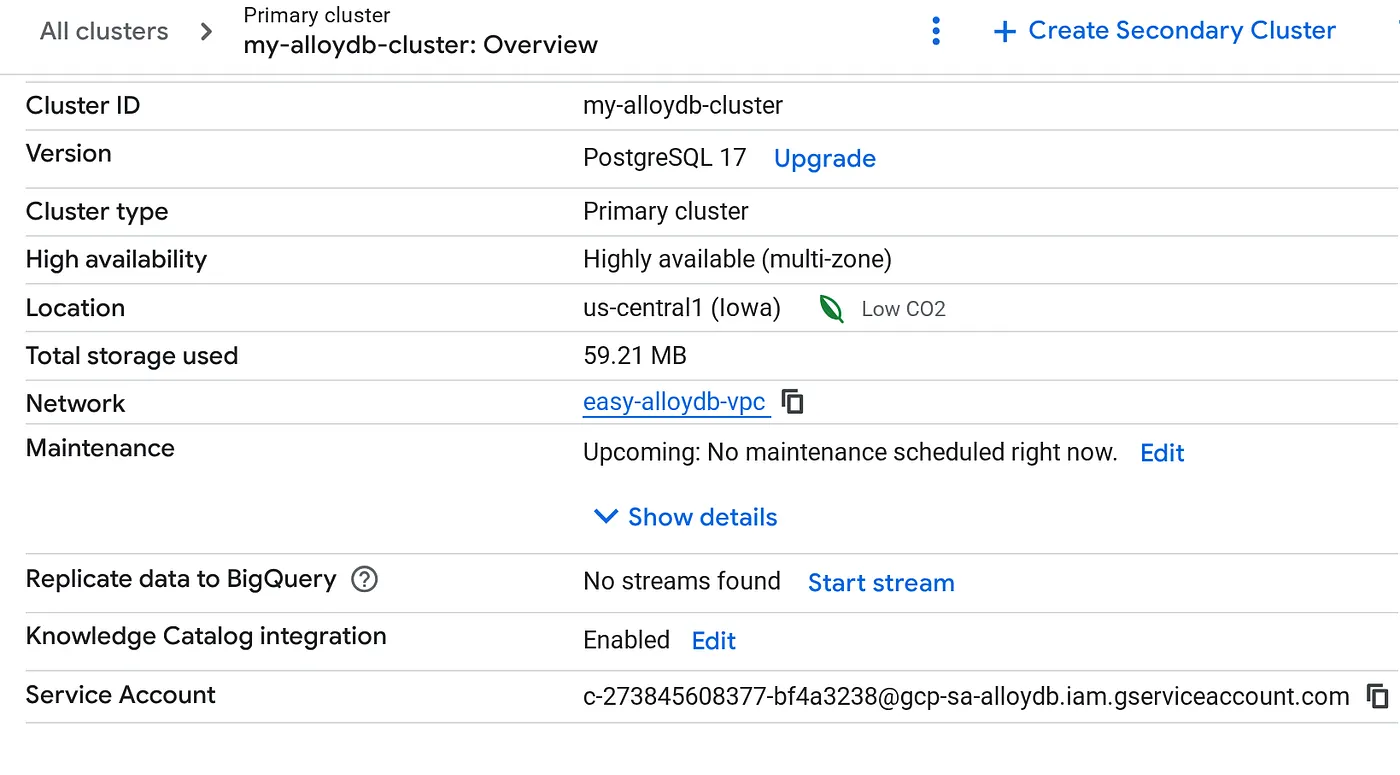
5. Berechtigungen einrichten
BigQuery-Berechtigungen für dieses Dienstkonto gewähren
- Rufen Sie „IAM & Verwaltung“ > „IAM“ auf.
- Klicken Sie auf „Zugriff gewähren“.
- Fügen Sie die Adresse des AlloyDB-Dienstkontos in das Feld „Neue Hauptkonten“ ein.
- Weisen Sie die folgenden Rollen zu:
- BigQuery-Datenbetrachter (roles/bigquery.dataViewer): Ermöglicht das Lesen der Daten.
- BigQuery-Nutzer (roles/bigquery.user): Ermöglicht das Ausführen der Abfragen.
- Optional, aber empfohlen: BigQuery-Lesesitzungsnutzer (roles/bigquery.readSessionUser): Optimiert das Lesen großer Datasets über die Storage Read API.
6. Mit AlloyDB verbinden und die BigQuery-Erweiterung aktivieren
Jetzt stellen wir eine Verbindung zu unserer neuen AlloyDB-Instanz her, um die Föderationserweiterung zu konfigurieren. Dazu verwenden wir AlloyDB Studio.
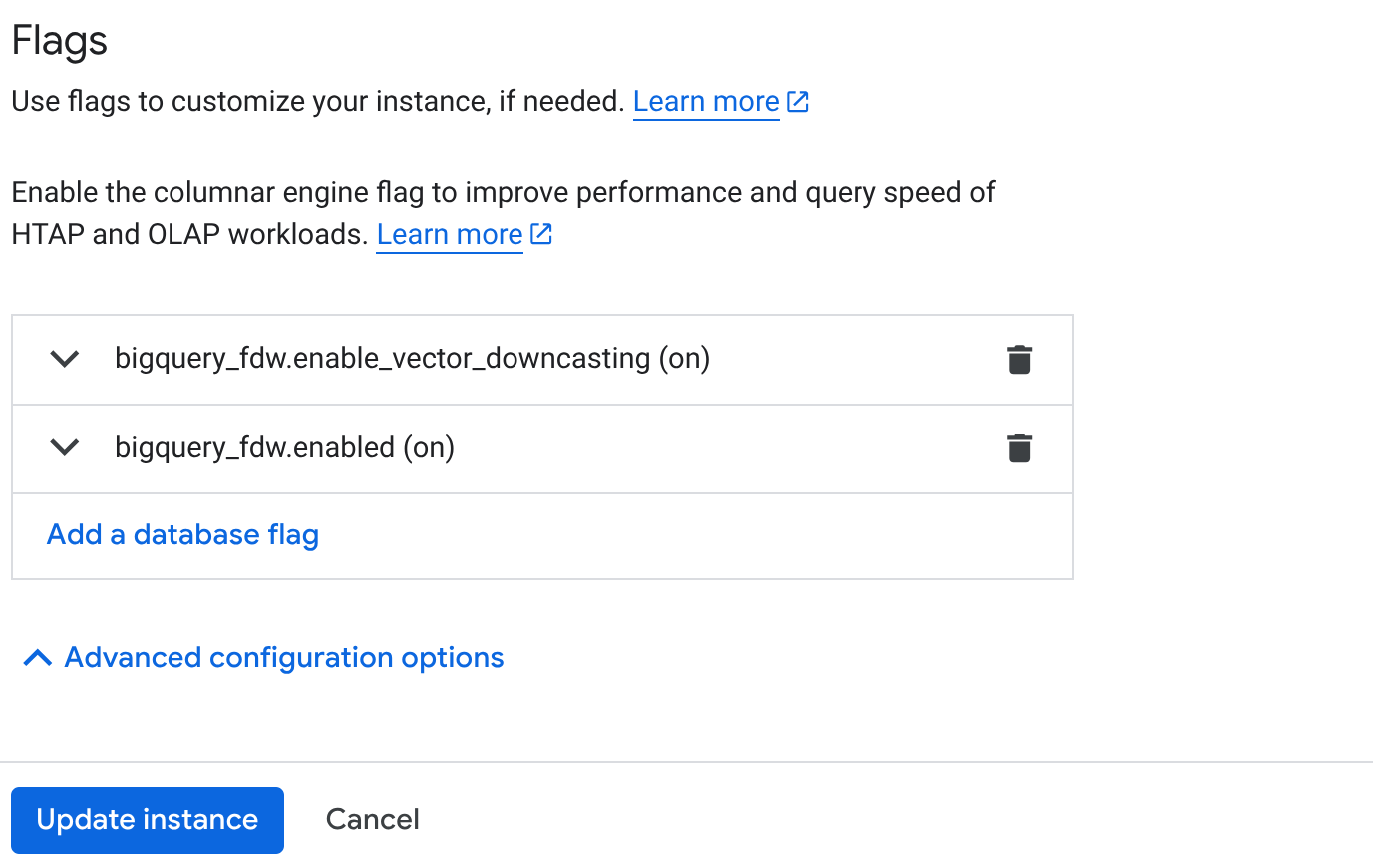
- Klicken Sie auf der Seite „Clusterübersicht“ (AlloyDB Console) für Ihre primäre Instanz auf Primäre bearbeiten und scrollen Sie nach unten zu Erweiterte Konfigurationsoptionen.
- Gehen Sie zum "Flags" Abschnitt, und aktivieren Sie die 2 Flags auf "On" wie unten gezeigt:
 3. Klicken Sie auf die Schaltfläche Instanz aktualisieren. Die Aktualisierung dauert einige Minuten. 4. Klicken Sie auf der Seite „Clusterübersicht“ (AlloyDB Console) auf „AlloyDB Studio“.
3. Klicken Sie auf die Schaltfläche Instanz aktualisieren. Die Aktualisierung dauert einige Minuten. 4. Klicken Sie auf der Seite „Clusterübersicht“ (AlloyDB Console) auf „AlloyDB Studio“.
- Stellen Sie eine Verbindung mit der Datenbank, dem Nutzernamen und dem Passwort her, die Sie bei der AlloyDB-Schnelleinrichtung konfiguriert haben.
- Geben Sie nach der Verbindung auf dem Tab „Abfrageeditor“ auf der rechten Seite die folgenden Anweisungen ein und führen Sie sie einzeln aus:
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- Navigieren Sie nach Abschluss der Einrichtung im Explorer-Bereich auf der linken Seite nach unten zu den BigQuery-Tabellen:
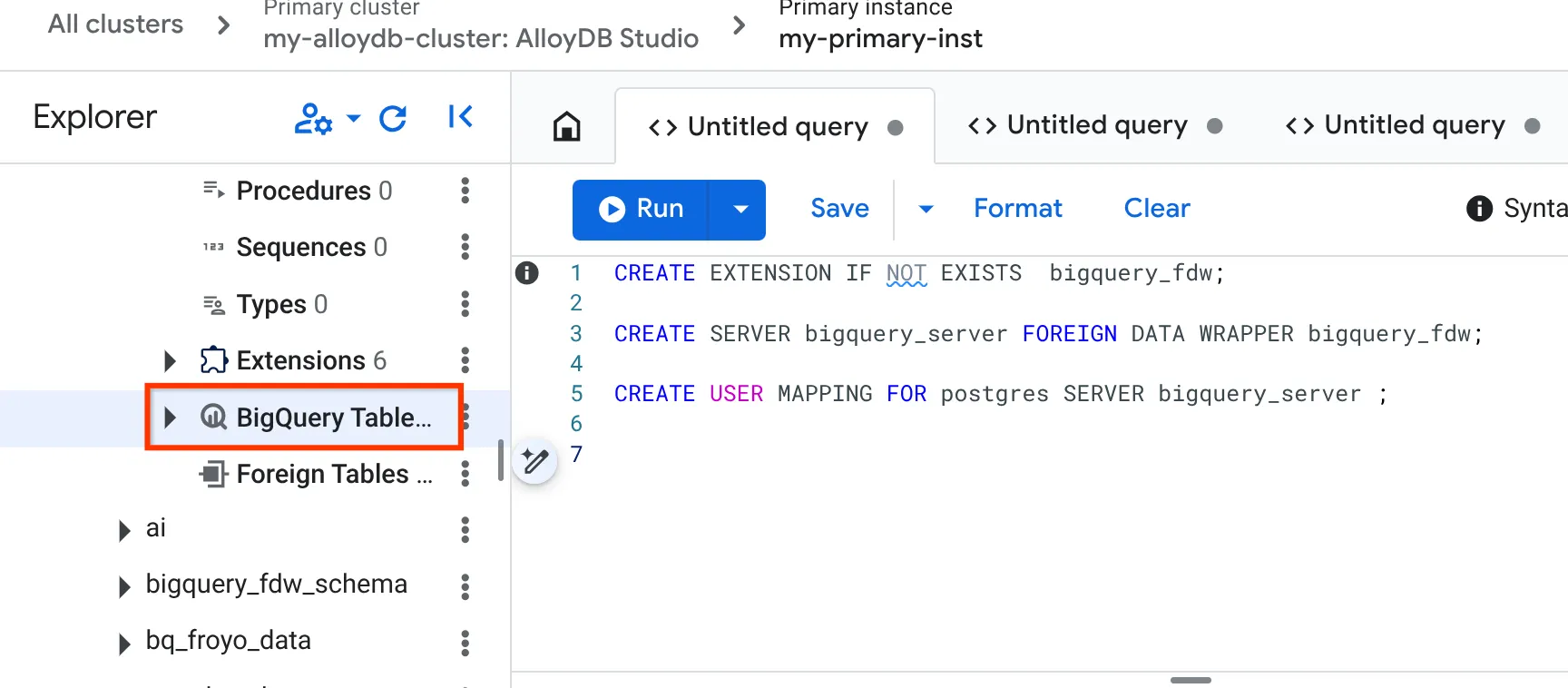
- Klicken Sie auf die drei Punkte und dann auf "BigQuery-Tabelle verbinden".
- Wählen Sie im Pop-up-Fenster „BigQuery-Tabelle verbinden“ Ihre Projekt-ID und den Namen des BigQuery-Datasets (in Teil 1 erstellt) aus, aus dem Sie die Daten in Ihrer AlloyDB-Datenbank abfragen möchten.
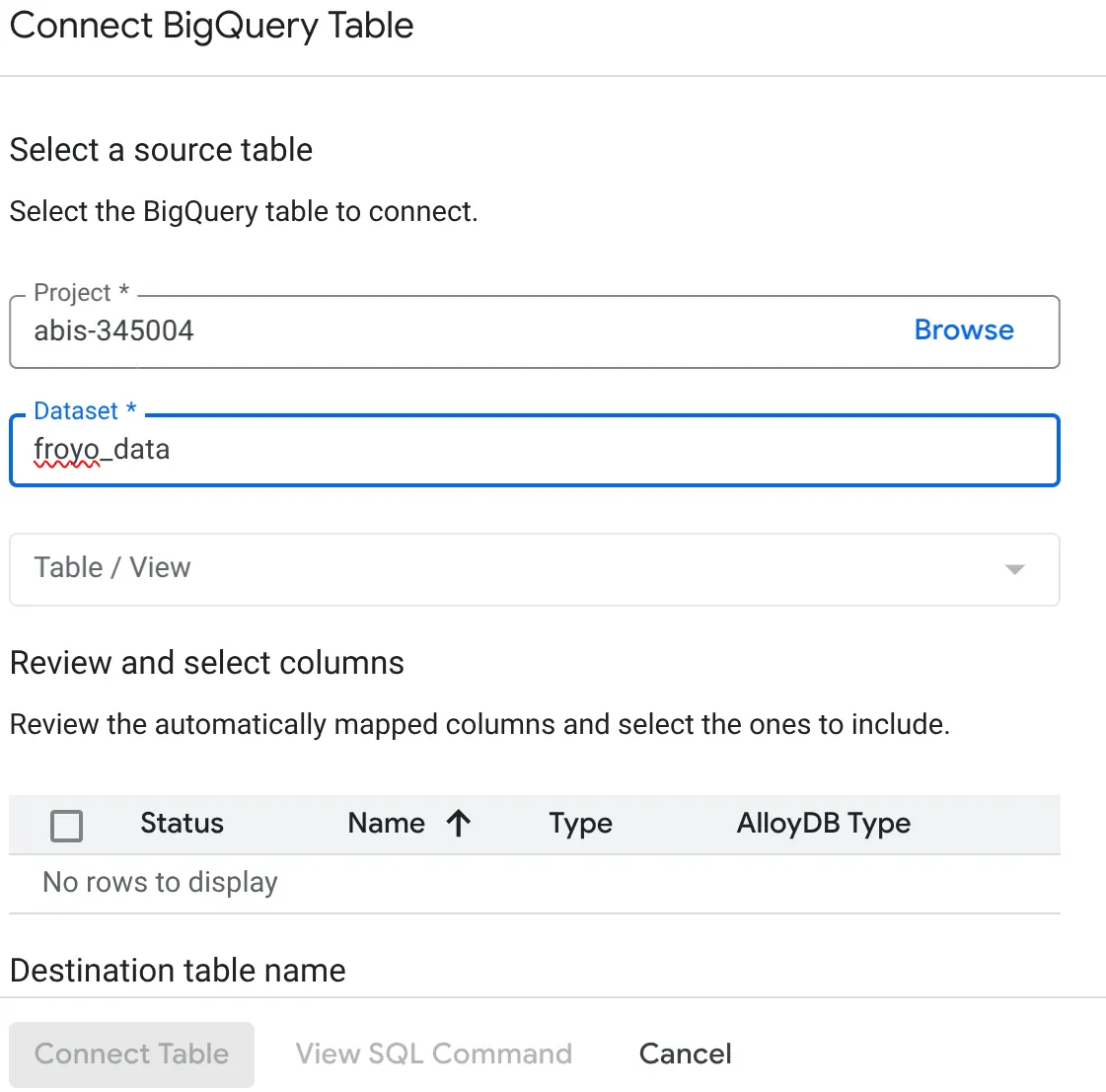
- Wählen Sie jede Tabelle einzeln aus, um alle Ihre Daten mit AlloyDB zu verbinden. So können wir die Spaltentypen validieren, um sicherzustellen, dass sie in AlloyDB unterstützt werden.
Wenn Sie dasselbe mit SQL anstelle des Point-and-Click -Ansatzes tun möchten:
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
Die Magie!!!
Wir haben gerade „externe Tabellen“ in AlloyDB erstellt. Diese sehen aus wie normale PostgreSQL-Tabellen und verhalten sich auch so, speichern aber keine Daten. Wenn Sie sie abfragen, übergibt AlloyDB die Abfrage sofort an BigQuery, ruft die Ergebnisse ab und gibt sie an Sie zurück.
7. Föderation in AlloyDB testen
Wir prüfen, ob wir unser großes analytisches BigQuery-Dataset direkt aus unserer transaktionalen PostgreSQL-Datenbank abfragen können.
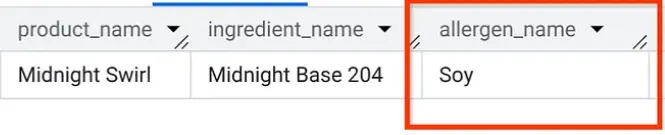
Führen Sie in AlloyDB Studio eine Abfrage aus, um herauszufinden, welche Allergene im „Midnight Swirl“ enthalten sind. Das ist dieselbe Frage, die wir in Teil 1 gestellt haben, aber dieses Mal aus AlloyDB:
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
Zack! Sie sollten genau dieselben Ergebnisse sehen wie in BigQuery.
8. Bereinigen
Vergessen Sie nicht, den AlloyDB-Cluster und die AlloyDB-Instanz zu löschen, wenn Sie dieses Lab abgeschlossen haben.
Dadurch werden der Cluster und seine Instanzen bereinigt.
9. Herzlichen Glückwunsch zu Ihrer einheitlichen Datenschicht
Denken Sie darüber nach, was wir gerade erreicht haben:
- Unsere Transaktionsanwendung (die in AlloyDB ausgeführt wird) kann schnelle, gleichzeitige Nutzersitzungen verarbeiten.
- Wenn sie umfangreiche analytische Daten oder einen historischen Kontext benötigt (z. B. Lieferantendetails oder komplexe Zuordnungen von Zutaten), fragt sie das BigQuery-Schema „froyo_dataschema“ ab.
- Keine ETL. Keine fehlerhaften Datenpipelines. Keine nicht synchronisierten Datenbanken. Wir speichern einmal (in BigQuery) und führen die Berechnungen dort aus, wo wir sie benötigen.
Nachdem unsere Datenbasis – sowohl analytisch als auch transaktional – solide und miteinander verbunden ist, können wir uns dem interessanten Teil zuwenden.
In Teil 3 erstellen wir die Multi-Agenten-Anwendung, die auf dieser Architektur basiert, um die Froyo-Geschäftsabläufe auszuführen.