
1. Descripción general
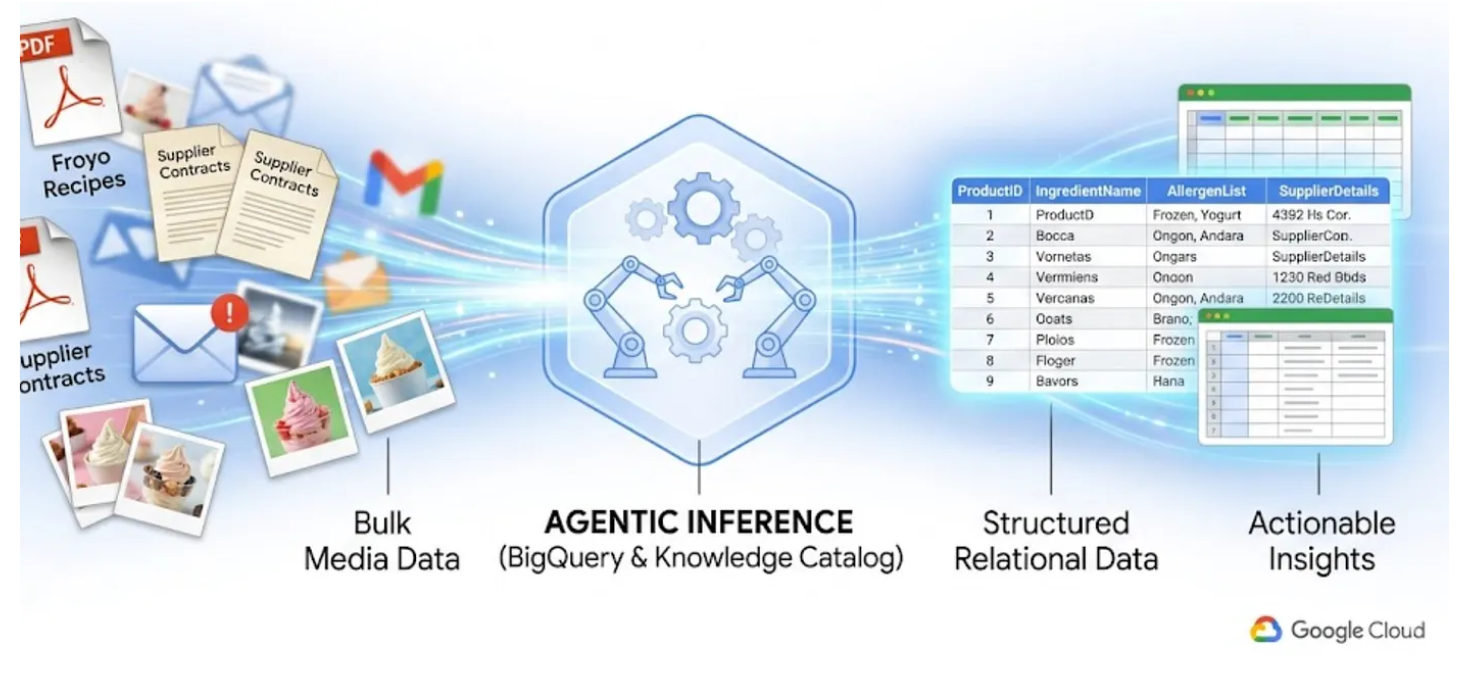
Todos conocemos el problema de los "datos oscuros". Son los archivos PDF, las imágenes y los archivos de texto que se encuentran en los buckets de almacenamiento en la nube, completamente invisibles para tus consultas en SQL y tus paneles de BI. Tradicionalmente, para acceder a estos datos, se necesitaban canalizaciones de OCR complejas, ingreso manual de datos o secuencias de comandos personalizadas frágiles.
Ya no.
En este lab, te mostraré cómo convertir 400 archivos PDF no estructurados (que abarcan texto, tablas e imágenes) en tablas de BigQuery claramente estructuradas con relaciones inferidas automáticamente entre ellas. Y lo haremos en minutos con BigQuery Knowledge Catalog y Dataplex.
Qué compilarás
Para que esto sea más concreto, veamos un negocio ficticio: una franquicia de yogur helado en rápido crecimiento.
Imagina que administras los datos de este negocio de Froyo. Tienes cientos de recetas y hojas de especificaciones de proveedores, todas guardadas como PDFs. Los líderes empresariales quieren lanzar un agente de IA para ayudar a los administradores de la tienda y a los clientes a consultar los detalles de los productos.
Esta es la peor situación posible: Un cliente pregunta: "Me interesa mucho su yogur helado Midnight Swirl. ¿Tiene alérgenos?".
Para responder esto, tu sistema normalmente debería hacer lo siguiente:
- Busca el PDF de la receta "Midnight Swirl".
- Lee los ingredientes (p.ej., " de cacao", "Base láctea", "Emulsionante X").
- Buscar en decenas de PDFs de proveedores para encontrar las hojas de especificaciones de esos ingredientes específicos
- Revisa las hojas de los proveedores para ver si hay alérgenos ocultos relacionados con esos ingredientes.
Intentar crear un agente de IA que haga esto sobre la marcha leyendo 400 PDFs sin procesar en el tiempo de ejecución es lento, costoso y propenso a alucinaciones. En cambio, usaremos la inferencia semántica para extraer todo esto en una base de datos relacional primero, lo que hará que nuestro futuro agente de IA sea increíblemente rápido y esté 100% basado en datos SQL fácticos.
¡Comencemos a crear!
Qué aprenderás
- Cómo configurar el bucket de Cloud Storage para los archivos fuente (PDFs)
- Cómo configurar y ejecutar el trabajo de DataScan y la inferencia semántica en Knowledge Catalog para extraer datos de PDFs de origen y, luego, inferir semánticamente las conexiones y el contexto, y almacenarlos en BigQuery
- Cómo usar los agentes de BigQuery para chatear con el conjunto de datos recién creado
Requisitos
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si quieres autenticarte
gcloud auth login
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las APIs requeridas: Ejecuta este comando para habilitar todas las APIs requeridas:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
Problemas potenciales y solución de problemas
El síndrome del "Proyecto fantasma" | Ejecutaste |
La barricada de facturación | Habilitaste el proyecto, pero olvidaste la cuenta de facturación. AlloyDB es un motor de alto rendimiento que no se iniciará si el "tanque de combustible" (facturación) está vacío. |
Retraso en la propagación de la API | Hiciste clic en "Habilitar APIs", pero la línea de comandos aún dice |
Cuota de Quags | Si usas una cuenta de prueba nueva, es posible que alcances una cuota regional para las instancias de AlloyDB. Si falla |
Agente de servicio"oculto" | A veces, al agente de servicio de AlloyDB no se le otorga automáticamente el rol de |
3. Configuración del bucket de Google Cloud Storage
En esta sección, crearás una estructura organizativa dentro de BigQuery para almacenar datos de recetas y proveedores de Froyo, específicamente para los detalles del producto Froyo. También establece una conexión a recursos de Cloud, que actúa como un "puente" seguro que permite a BigQuery leer archivos de fuentes externas, como Cloud Storage.
Antes de comenzar:
Este repositorio contiene recetas y archivos PDF de proveedores que usaremos en este proyecto. Asegúrate de descargar estos archivos. Para descargar los archivos, sigue estos pasos.
En Cloud Shell, ejecuta el siguiente comando:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
Navega a la carpeta recién creada:
cd next-26-keynotes
Extrae la carpeta data-cloud-demo.
git sparse-checkout set genkey/data-cloud-demo
Una vez que se complete la confirmación de compra, navega a la carpeta data-cloud-demo y extrae los archivos ZIP para acceder a los recursos del codelab.
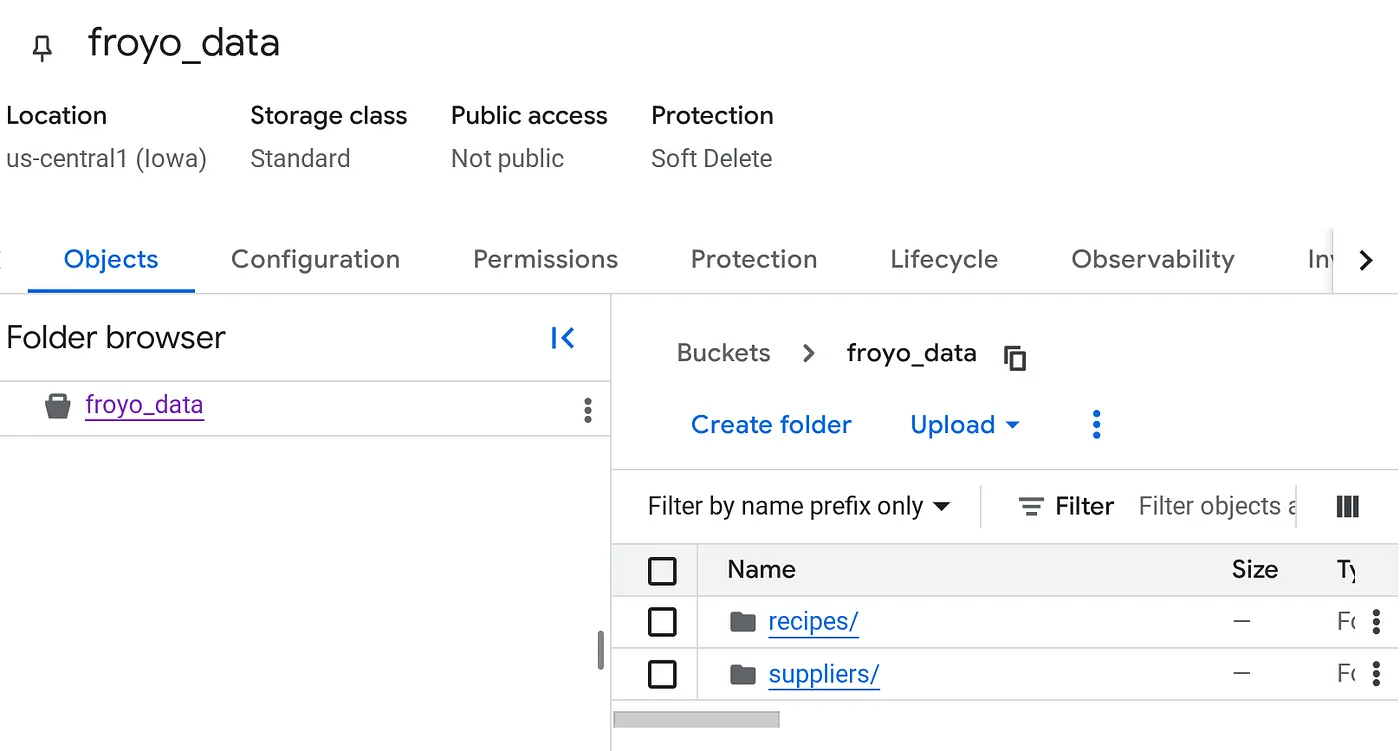
Crea un bucket y sube los archivos PDF de Froyo (recetas y proveedores)
- En la consola de Google Cloud, ve a la página Buckets de Cloud Storage.
- Haz clic en Crear.
- En la página Crear un bucket, ingresa la información de tu bucket. Después de cada uno de los siguientes pasos, haz clic en Continuar para avanzar al siguiente paso:
- En la sección Primeros pasos, ingresa el nombre del bucket. P. ej., froyo_data
- En la sección Elige dónde almacenar tus datos, selecciona Región y, luego, ingresa tu región. us-central1
- En la sección Elige cómo controlar el acceso a los objetos, desmarca la casilla de verificación Aplicar la prevención de acceso público a este bucket.
- Haz clic en Crear.
- En la lista de buckets, haz clic en el que creaste.
- En la pestaña Objetos del bucket, haz clic en Subir y, luego, en Subir carpetas.
- Selecciona la carpeta recipes que extrajiste en la sección Antes de comenzar de este codelab.
- Haz clic en Subir.
- Repite el proceso de carga para la carpeta suppliers.
Una vez que se suba, la estructura del bucket debería verse de la siguiente manera (cualquiera sea el nombre del bucket):
4. Configuración de la conexión de BigQuery
Crea una conexión a recursos de Cloud. Esto genera una cuenta de servicio única que actúa como la "tarjeta de identificación" de BigQuery para acceder a archivos externos.
- Ve a la página de BigQuery.
- En el panel de la izquierda, haz clic en Explorer. Si no ves el panel izquierdo, haz clic en Expandir panel izquierdo para abrirlo.
- En el panel Explorador, expande el nombre de tu proyecto y, luego, haz clic en Conexiones.
- En la página Connections, haz clic en Create connection.
- En Tipo de conexión, elige Modelos remotos de Vertex AI, funciones remotas, BigLake y Spanner (Cloud Resource).
- En el campo ID de conexión, ingresa el nombre del ID de conexión:
- bq-connection. Asegúrate de anotar este ID, ya que lo necesitarás cuando configures el análisis de datos más adelante en este codelab.
- Configura el tipo de ubicación como Región y, luego, selecciona una región. Por ejemplo, us-central1. La conexión debe estar ubicada en la misma región que tus otros recursos, como los conjuntos de datos.
- Haz clic en Crear conexión.
- Haz clic en Ir a la conexión.
- En el panel Información de conexión, copia el ID de la cuenta de servicio para usarlo en un paso posterior. La cuenta de servicio se verá de la siguiente manera: bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
5. Configuración de permisos
- Otorga los permisos necesarios a la conexión de BigQuery para acceder a los objetos de Cloud Storage y a Knowledge Catalog
Ve a la página IAM y administración y, en la sección Ver por principales, haz clic en el botón Otorgar acceso y agrega un principal pegando la cuenta de servicio que copiaste en el último paso. En la sección de roles, agrega los nombres de los siguientes roles uno por uno y guarda los cambios:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- Otorga permisos a la cuenta de servicio de Dataplex para acceder al bucket de Cloud Storage
Ve a la página IAM y administración y, en la sección Ver por principales, haz clic en el botón Otorgar acceso y agrega una principal escribiendo la palabra dataplex en la barra de texto Principal nueva. En la lista que se autocompleta, selecciona la principal de la cuenta de servicio de Dataplex que se parece a esta: (usa el número del proyecto y no el ID del proyecto en el ID de correo electrónico de la cuenta de servicio que se muestra a continuación).
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Si, por algún motivo, no se reconoce la cuenta de servicio anterior para el número de tu proyecto, es posible que el proyecto aún no haya inicializado el servicio de Dataplex. Ve a la terminal de Cloud Shell y ejecuta el siguiente comando para intentar habilitar la API (si aún no lo hiciste en la etapa de antes de comenzar): gcloud services enable dataplex.googleapis.com
Incluso después de eso, si no se reconoce la cuenta de servicio de Dataplex, fuerza la creación de un trabajo de análisis de Dataplex de prueba en la página Metadata Curation y, luego, ingresa los detalles en la página de creación de Discover Job:
Haz clic en Ejecutar ahora. El trabajo fallará, pero esto garantizará que el ID de la cuenta de servicio se inicialice para tu servicio de Dataplex.
Vuelve a la página IAM y administración y, en la sección Ver por principales, haz clic en el botón Otorgar acceso y, luego, en Agregar una principal. Pega la cuenta de servicio:
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Luego, otorga los siguientes roles a esta cuenta de servicio:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. Configuración de Knowledge Catalog
Crea un Knowledge Catalog para unificar los datos no estructurados y automatizar el descubrimiento de archivos no estructurados (como recetas en PDF y proveedores en PDF).
Crea el trabajo de DataScan desde la consola:
- Ve a la página Curación de metadatos.
- Haz clic en Crear y, luego, ingresa los detalles correspondientes a tu configuración:
Nota importante: No olvides marcar la opción Habilitar la inferencia semántica.
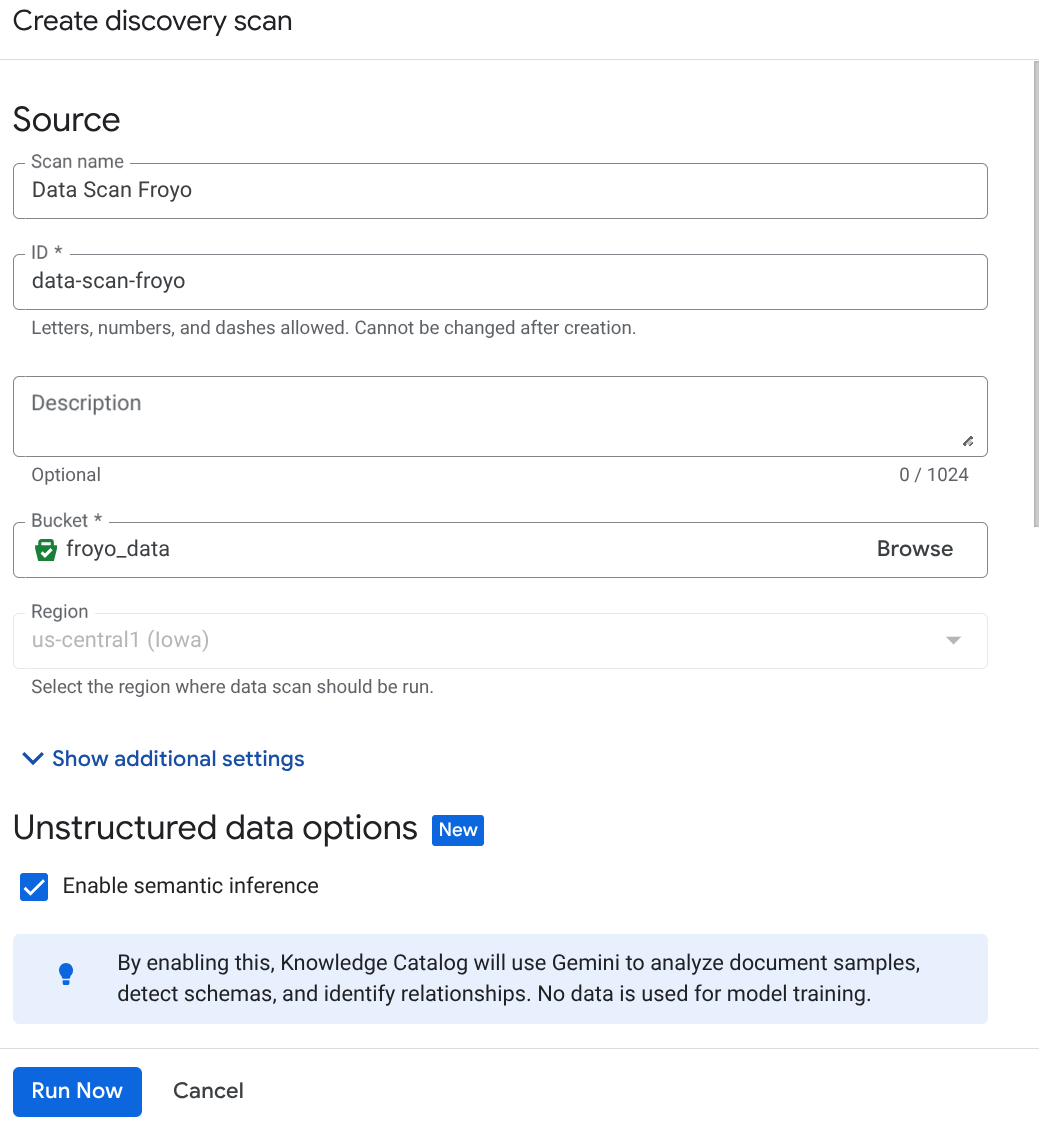
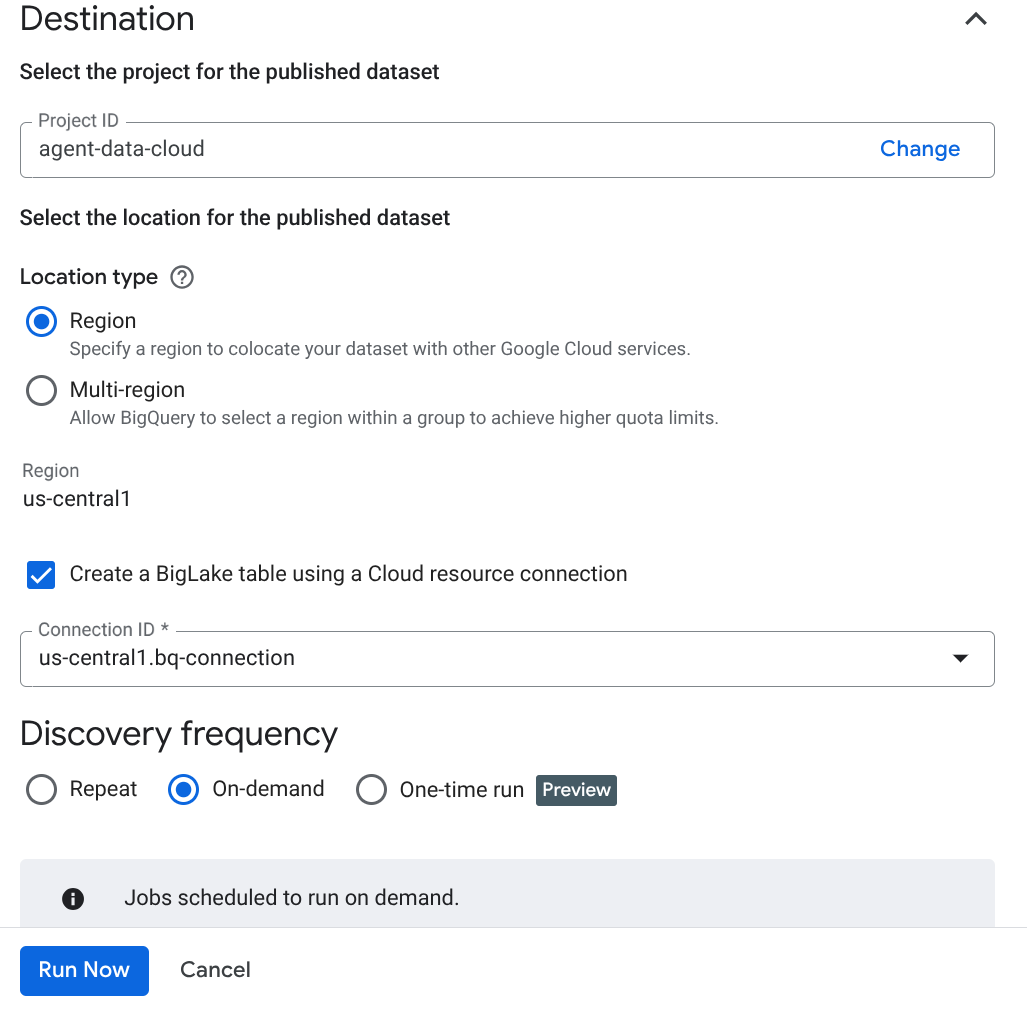
- Haz clic en "Ejecutar ahora".
- El trabajo de análisis tardará un tiempo en completarse. Una vez que finalice el trabajo, verifica si está presente el conjunto de datos publicado. Para verificar el estado del trabajo, puedes consultar la página Metadata curation. En la pestaña de detección de Cloud Storage, haz clic en el nombre de los análisis de detección de la ejecución reciente. Deberías ver el conjunto de datos publicado, como se muestra a continuación:
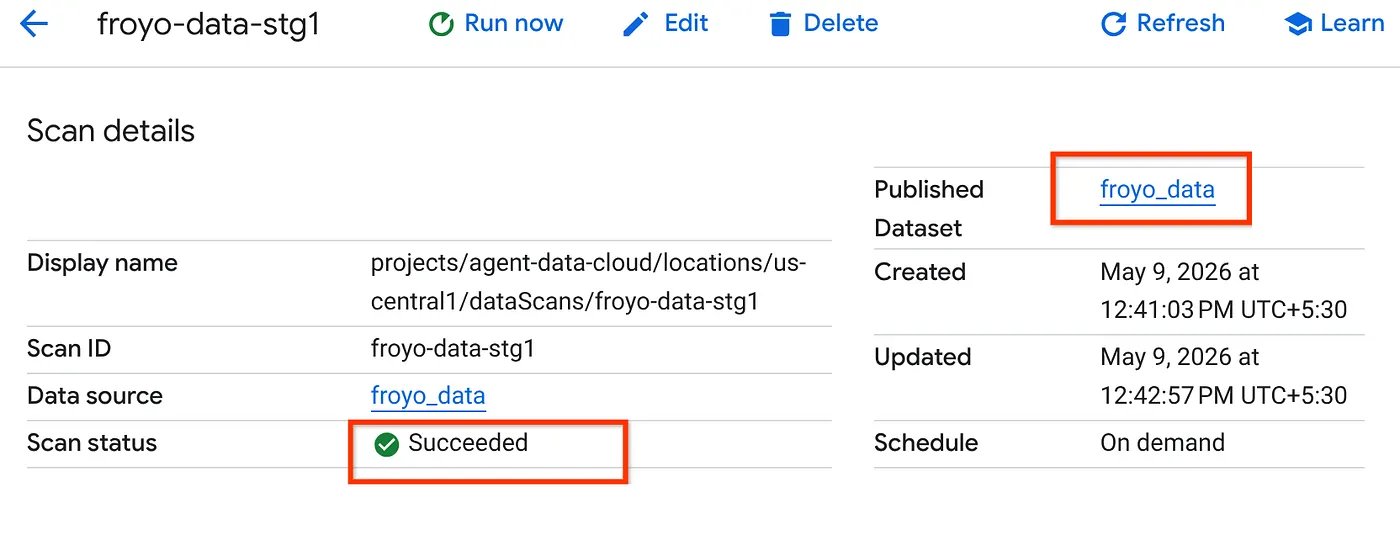
Nota: Si se producen errores en el paso de análisis, espera un momento y vuelve a intentarlo (se tarda unos minutos en crear el trabajo y completar la ejecución).
- Para ver la tabla en BigQuery, haz clic en el conjunto de datos froyo_data y navega a él. Haz clic en el ID de la tabla en BigQuery y ejecuta la siguiente consulta en la pestaña Editor de consultas:
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
Esto genera un error 400 (si no es así, puedes volver y ejecutar el trabajo de DataScan de nuevo).
7. Extracción de datos semánticos
¡Excelente! Ahora, extraigamos la inferencia para estos objetos no estructurados con Knowledge Catalog.
Usaremos la función Estadísticas para generar sentencias SQL que permitan extraer datos estructurados de la tabla no estructurada.
- En la consola de Google Cloud, ve a la página Búsqueda en Knowledge Catalog.
- Busca la tabla del conjunto de datos para la que deseas ver estadísticas. En la barra de búsqueda, ingresa el nombre del conjunto de datos o la tabla del paso anterior: “froyo_data” y presiona Intro.
- En la lista de resultados, haz clic en la entrada TABLE (no en la del conjunto de datos).
- Deberías ver la pestaña ESTADÍSTICAS. Haz clic en él (si te solicita que habilites alguna API, sigue las instrucciones y habilita las APIs).
Si habilitaste APIs en este punto, debes volver a ejecutar el trabajo de análisis.
- En la pestaña INSIGHTS, verás el menú desplegable del botón EXTRACT. Haz clic en esa opción y selecciona "Extract with SQL".
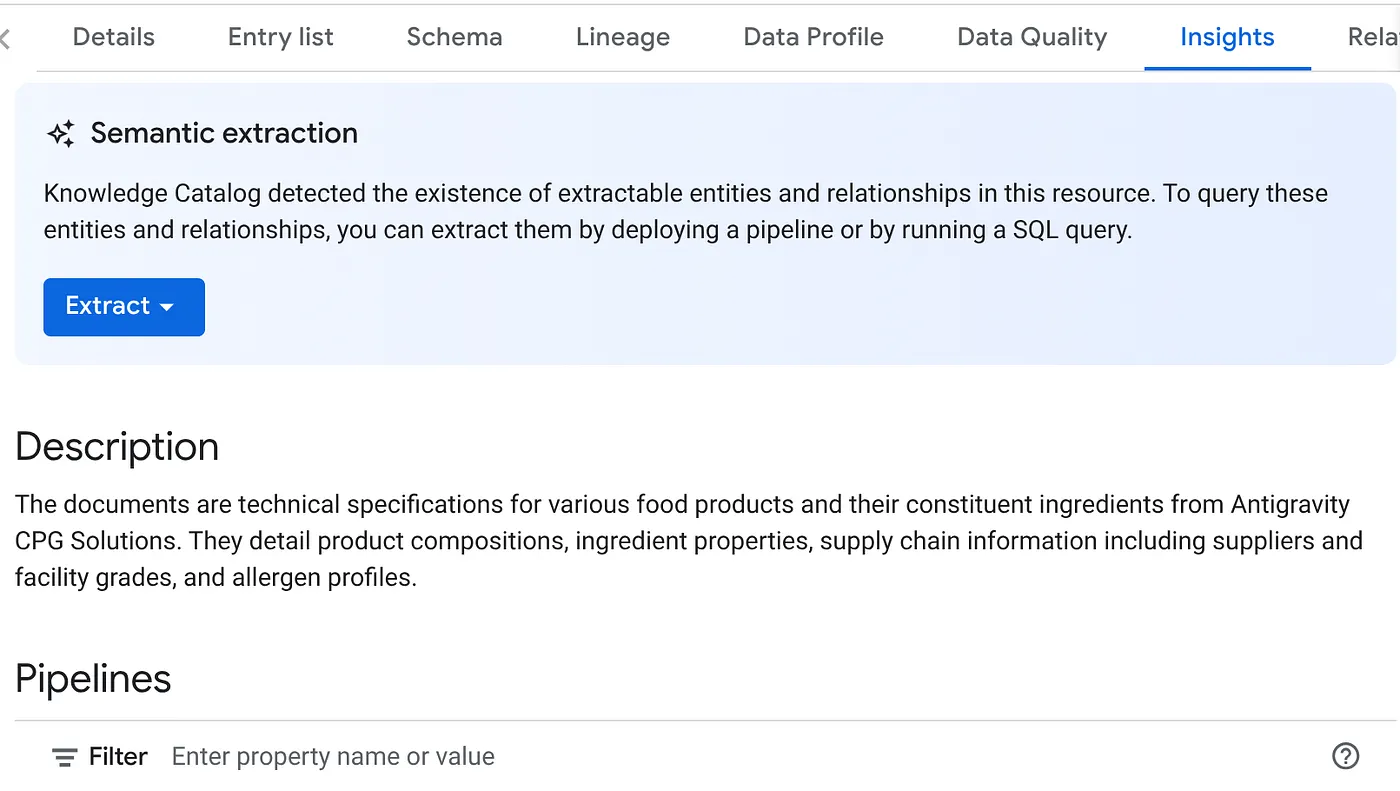
En el cuadro de diálogo emergente "Extract with SQL", establece el conjunto de datos de DESTINO como el que viste en el resultado del trabajo de DataScan. Comienza a escribir su nombre y debería aparecer en el autocompletado. Haz clic en el botón "Extraer". Como alternativa, puedes crear un nuevo conjunto de datos en este punto y realizar la extracción.
Esto debería abrir el editor de consultas de BigQuery con una pestaña abierta que contenga el código SQL extraído de la inferencia del análisis de datos.
8. Validación de SQL y creación de esquemas
Si la consulta generada parece correcta y pertinente semánticamente para tus datos no estructurados, haz clic en el botón Ejecutar del editor de consultas para ejecutarla. La creación del esquema necesario para el almacenamiento estructurado de tu contenido multimedia no estructurado tardará unos minutos.
Una vez que termines, podrás verificar el esquema expandiendo el conjunto de datos en el panel del explorador de BigQuery Studio, como se muestra a continuación:
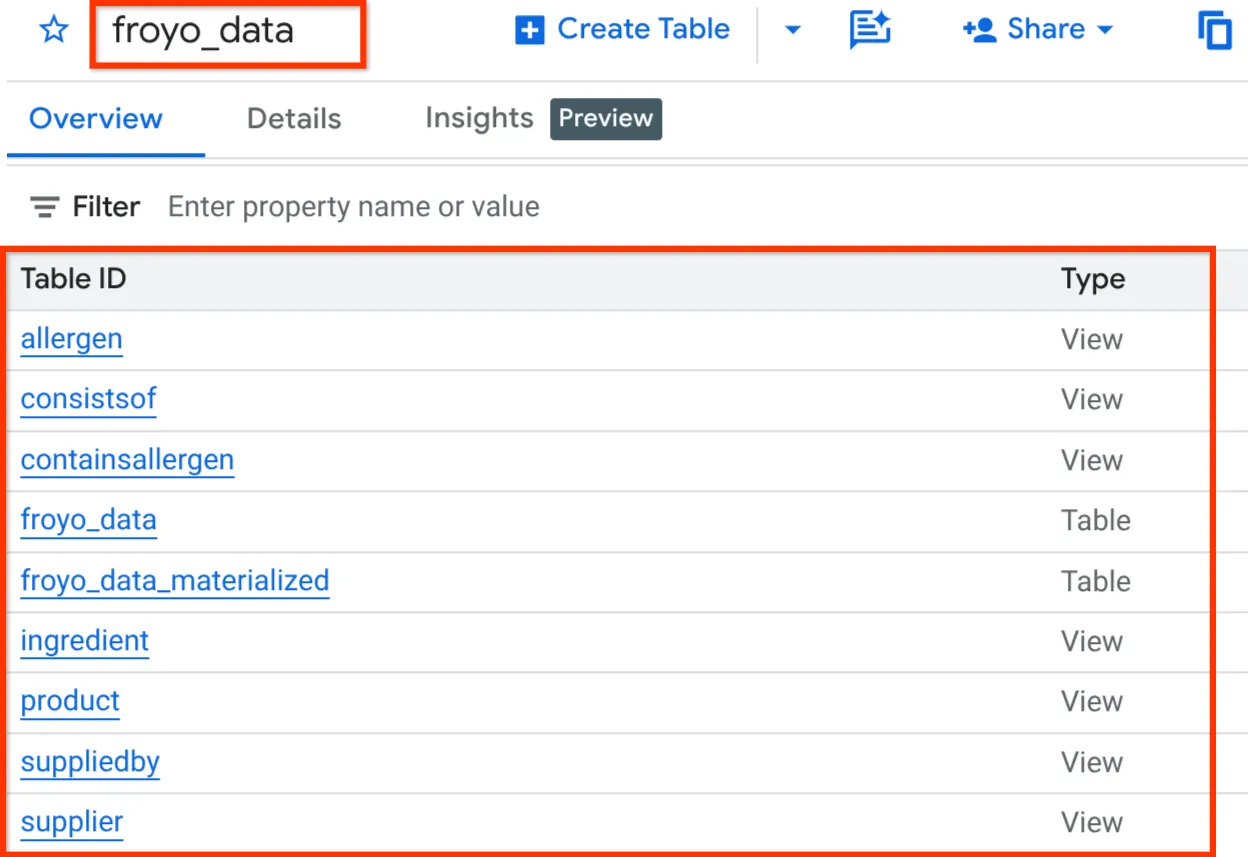
¡Muy bien! Fue tan dulce que hicimos todas esas cosas de la base de datos muy rápido. Ahora es el momento de la prueba final.
Sigue estos pasos para seguir disfrutando de los datos sin la cuenta de facturación:
- Puedes obtener los archivos csv de datos (datos de BigQuery) desde el vínculo del repositorio de GitHub que se encuentra más arriba.
- Primero, crea el conjunto de datos de BigQuery ejecutando el siguiente comando desde la terminal de Cloud Shell:
bq mk --location us-central1 --dataset froyo_data
- A continuación, descarga los 8 archivos de datos (archivos CSV) del repositorio de GitHub en tu directorio de trabajo ejecutando los siguientes comandos uno por uno:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Ejecuta los siguientes comandos uno por uno para crear estas tablas con los datos de tu conjunto de datos recién creado.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Una vez que se creen el conjunto de datos, las tablas y los datos, podrás probar y experimentar con los datos que acabamos de analizar.
9. ¡¡¡La prueba definitiva!!!
Supongamos que quiero que mi agente responda las preguntas del usuario con información real, completa y bien organizada basada en hechos. Voy a hacer una pregunta que el agente solo podrá responder consultando varios archivos multimedia y referencias de mi fuente.
Esta es mi pregunta del usuario:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
Ahora, una búsqueda genérica o una búsqueda con LLM dirá "Cero ingredientes". Sin embargo, creamos una inferencia semántica completa que convierte todos nuestros medios no estructurados en datos estructurados. Aquí tienes un SQL simple que recuperará esta información:
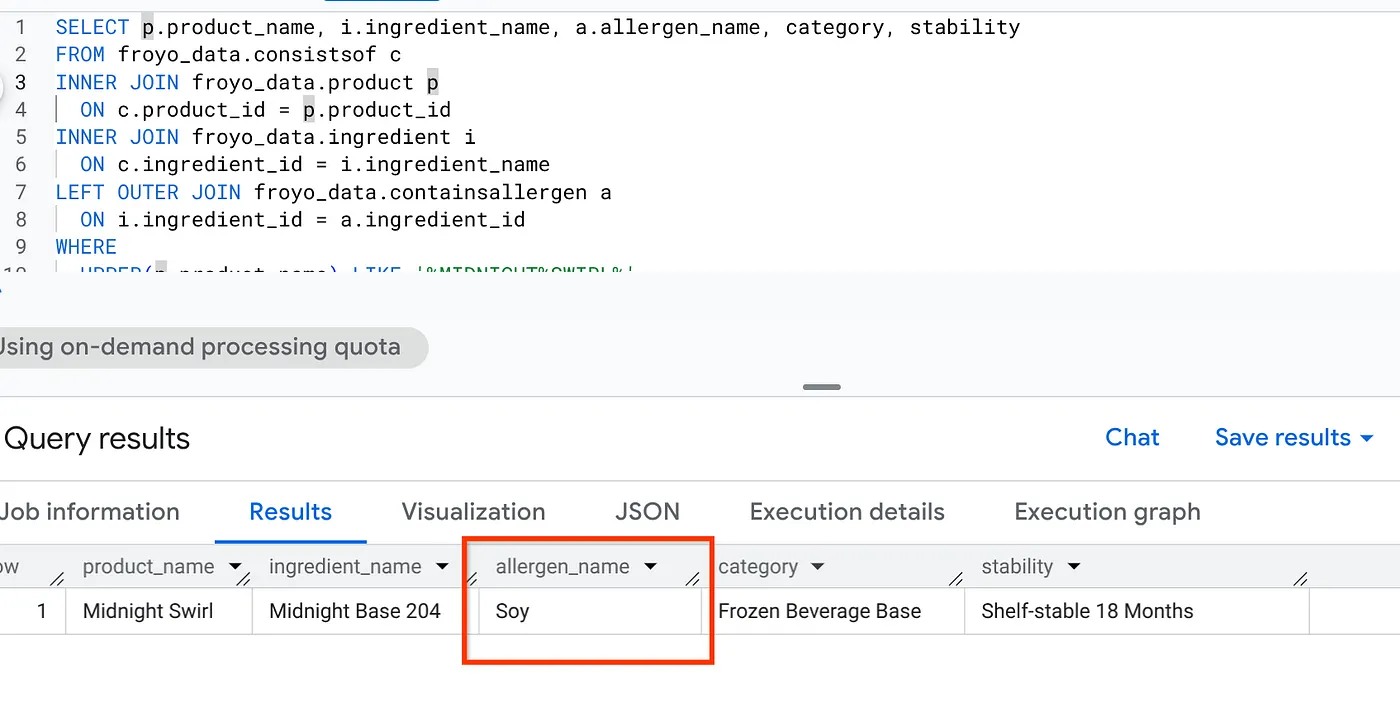
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
¡Muy bien! Observa el resultado:
10. Limpia
Cuando termines este lab, no olvides borrar el trabajo de análisis y las tablas de BigQuery que creó el trabajo.
Ve a https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery. Para seleccionar el trabajo que quieres borrar, haz clic en los puntos suspensivos verticales que se encuentran junto a él y, luego, en BORRAR.
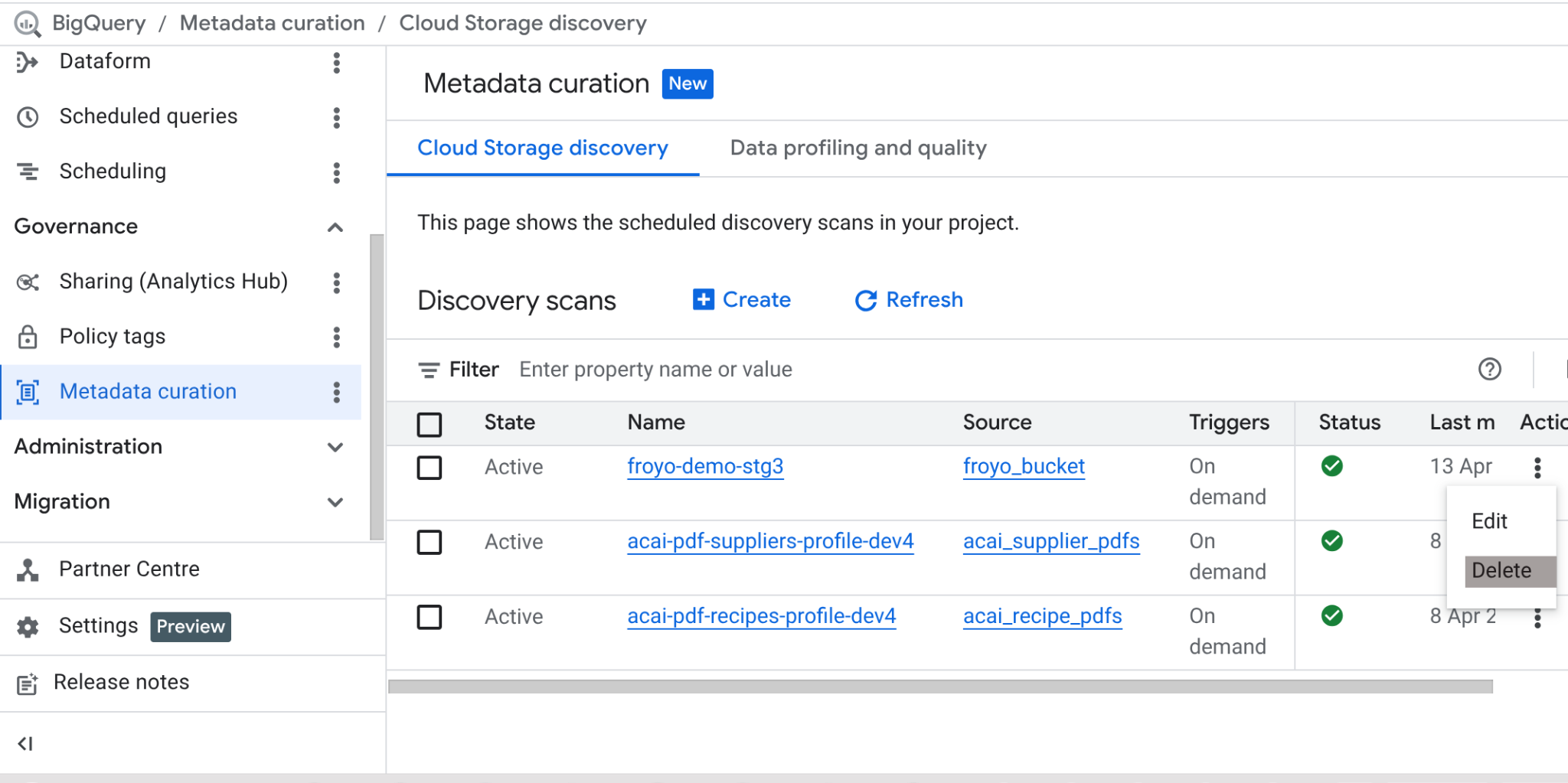
Debería liberar espacio.
11. Felicitaciones
Nuestra implementación pudo identificar correctamente el alérgeno oculto. ¡¡¡Ya no más datos oscuros, gente!!! En la parte 2, federaremos estos datos de BigQuery en un sistema transaccional con AlloyDB para unificar las necesidades de datos de nuestra aplicación basada en agentes.