
1. Descripción general
En la Parte 1, transformamos correctamente los PDFs caóticos y no estructurados en tablas limpias, inteligentes y estructuradas en BigQuery con Knowledge Catalog y DataScan. Ahora tenemos un almacén de datos sólido.
Si necesitas un repaso rápido, en el lab 1, tomamos el caso de uso de una franquicia ficticia de yogur helado y convertimos 400 de sus archivos PDF no estructurados (que abarcan texto, tablas e imágenes) en tablas de BigQuery claramente estructuradas con relaciones inferidas automáticamente entre ellas usando BigQuery Knowledge Catalog y Dataplex.
Qué compilarás
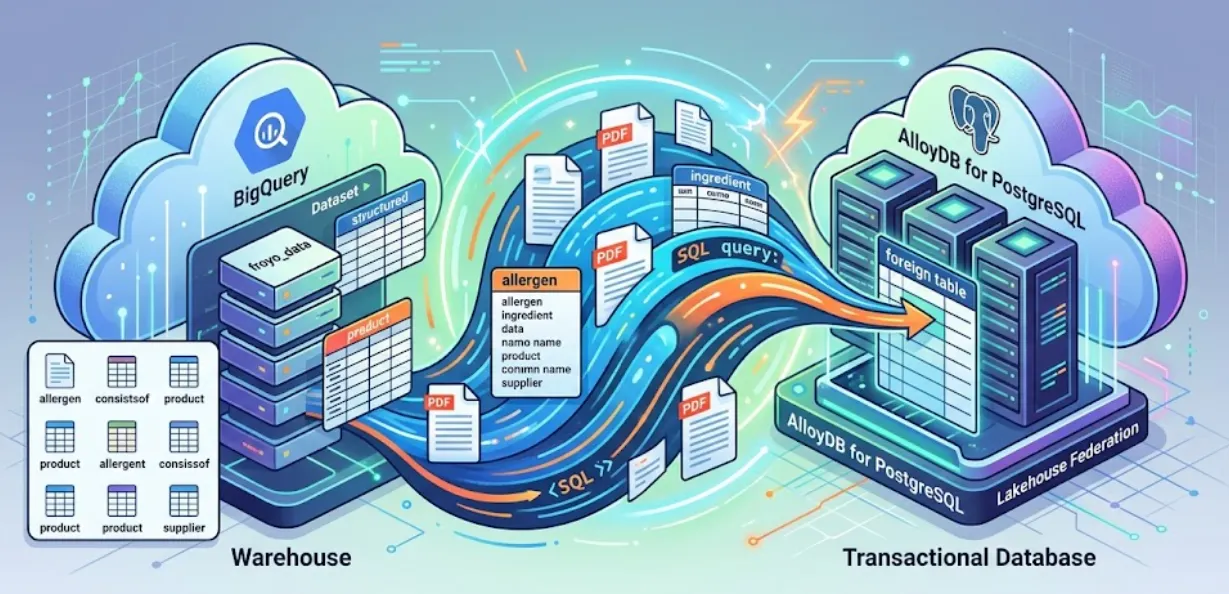
En esta sesión, configuraremos AlloyDB para PostgreSQL y haremos algo mágico: federar nuestros datos de BigQuery directamente en AlloyDB. Esto significa que nuestra app transaccional puede consultar los datos de nuestro almacén en tiempo real, sin copiar ni duplicar ninguno de ellos.
Como desarrollador, debes hacerte esta pregunta en esta etapa:
"Si los datos ya están en BigQuery, ¿por qué incluir AlloyDB? ¿Por qué la aplicación no ejecuta una instrucción SELECT directamente en BigQuery?"
Estos son los motivos:
Con la federación de lakehouse, puedes usar el motor de consultas de AlloyDB para potenciar las cargas de trabajo transaccionales y analíticas de tu aplicación desde la misma interfaz. También puedes materializar o importar estos datos en AlloyDB para acceder a ellos más rápido y usarlos en tus aplicaciones, lo que te permite usar AlloyDB AI y el motor de columnas.
Puedes usar AlloyDB como una base de datos transaccional y también tener grandes cantidades de datos en BigQuery o BigLake. Por lo general, tus aplicaciones se integran de forma independiente con ambos sistemas para acceder a los datos en estos diferentes servicios de Google Cloud. La federación de Lakehouse para AlloyDB te permite usar la compatibilidad con consultas federadas de AlloyDB implementada como un wrapper de datos externos para acceder a los datos de BigQuery y AlloyDB con una interfaz de SQL en AlloyDB.
En lugar de compilar una canalización de ETL frágil para consultar los datos de BigQuery desde AlloyDB, usaremos consultas federadas. AlloyDB actuará como un extremo unificado y accederá a BigQuery sin problemas cuando sea necesario.
¡Comencemos a crear!
Qué aprenderás
- Cómo configurar un clúster, una instancia y una red de AlloyDB con un solo clic
- Cómo configurar la extensión para prepararse para la federación
- Cómo configurar la federación de BigQuery a AlloyDB
- Pruébalo
Requisitos
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si quieres autenticarte
gcloud auth login
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las APIs requeridas: Ejecuta este comando para habilitar todas las APIs requeridas:
gcloud services enable alloydb.googleapis.com
Problemas potenciales y solución de problemas
El síndrome del "Proyecto fantasma" | Ejecutaste |
La barricada de facturación | Habilitaste el proyecto, pero olvidaste la cuenta de facturación. AlloyDB es un motor de alto rendimiento que no se iniciará si el "tanque de combustible" (facturación) está vacío. |
Retraso en la propagación de la API | Hiciste clic en "Habilitar APIs", pero la línea de comandos aún dice |
Cuota de Quags | Si usas una cuenta de prueba nueva, es posible que alcances una cuota regional para las instancias de AlloyDB. Si falla |
3. Resumen rápido de los datos de la parte 1
En esta sección, debes asegurarte de que los datos estructurados que extrajimos de los PDFs no estructurados estén disponibles en BigQuery. Si te perdiste la parte 1 o no tienes una cuenta de facturación, no hay problema. Puedes completar los siguientes pasos y comenzar:
Ve a la consola de Google Cloud desde tu cuenta personal de Gmail y haz clic en el botón Activar Cloud Shell en la esquina superior derecha de la consola:
Luego, sigue los pasos que se indican en la sección sin cuenta de facturación a continuación:
Sigue estos pasos para seguir disfrutando de los datos sin la cuenta de facturación:
- Puedes obtener los archivos csv de datos (datos de BigQuery) desde el vínculo del repositorio de GitHub que se encuentra más arriba.
- Primero, crea el conjunto de datos de BigQuery ejecutando el siguiente comando desde la terminal de Cloud Shell:
bq mk --location us-central1 --dataset froyo_data
- A continuación, descarga los 8 archivos de datos (archivos CSV) del repositorio de GitHub en tu directorio de trabajo ejecutando los siguientes comandos uno por uno:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Ejecuta los siguientes comandos uno por uno para crear estas tablas con los datos de tu conjunto de datos recién creado.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Ahora que tenemos los datos en BigQuery, pasemos a los próximos pasos.
4. Configura el clúster, la instancia y la red de AlloyDB
Hay una aplicación de inicio rápido basada en la Web que te ayudará a configurar el clúster, la instancia y otras dependencias de AlloyDB. Puedes seguir los pasos del 2 al 4 de este lab para configurarlo con un solo clic:
https://codelabs.developers.google.com/quick-alloydb-setup
Una vez que se cree el clúster, ve a la página de descripción general del clúster y copia los detalles de la cuenta de servicio desde allí.
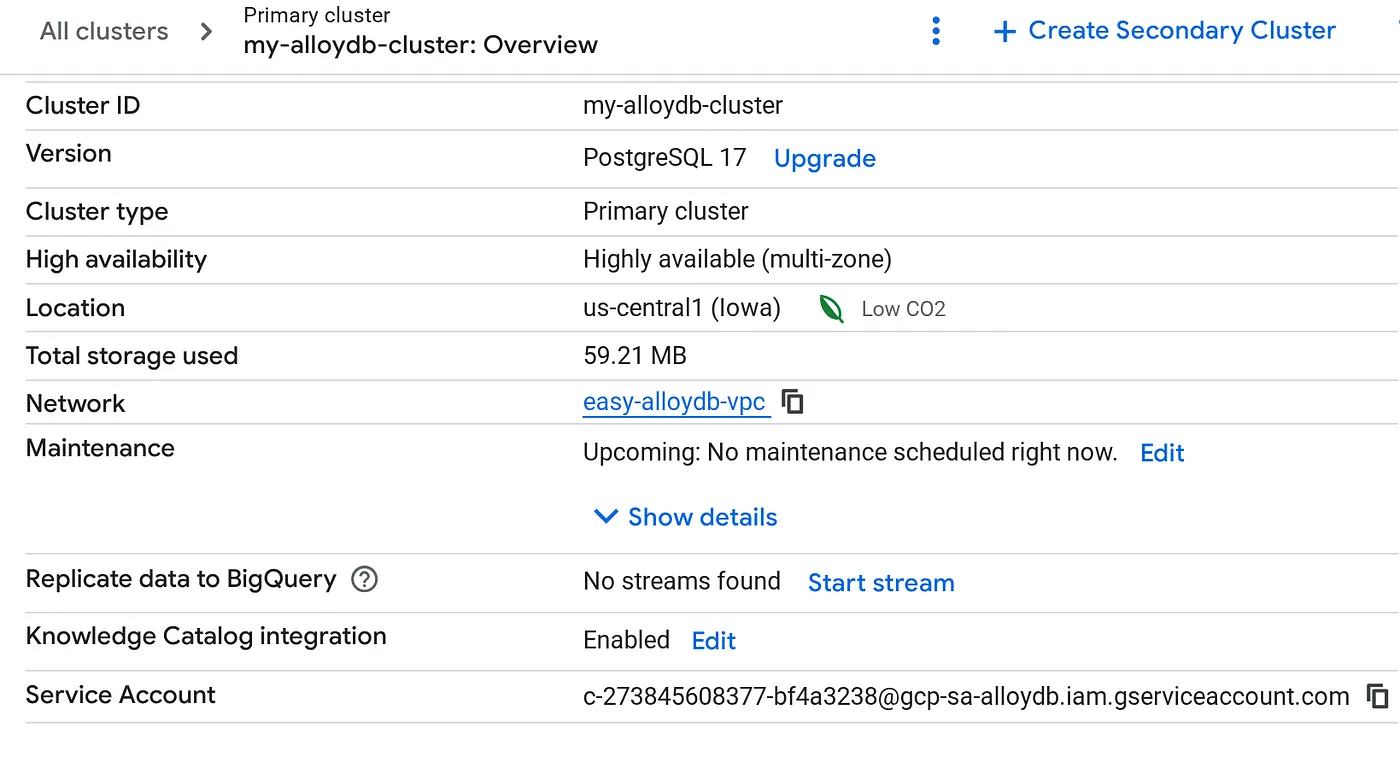
5. Configuración de permisos
Otorga permisos de BigQuery a esta cuenta de servicio
- Navega a IAM y administración > IAM.
- Haz clic en Grant Access.
- Pega la dirección de la cuenta de servicio de AlloyDB en el campo Entidades nuevas.
- Asigna los siguientes roles:
- Visualizador de datos de BigQuery (roles/bigquery.dataViewer): Permite leer los datos.
- Usuario de BigQuery (roles/bigquery.user): Permite ejecutar las consultas.
- (Opcional, pero recomendado) Usuario de sesión de lectura de BigQuery (roles/bigquery.readSessionUser): Optimiza la lectura de conjuntos de datos grandes a través de la API de Storage Read.
6. Conéctate a AlloyDB y habilita la extensión de BigQuery
Ahora nos conectaremos a nuestra instancia nueva de AlloyDB para configurar la extensión de federación. Para ello, usaremos AlloyDB Studio.
- En la página Descripción general del clúster (consola de AlloyDB), haz clic en "Editar instancia principal" en tu instancia principal y desplázate hasta la parte inferior para ver las "Opciones de configuración avanzadas".
- Ve a la sección "Flags" y habilita las 2 marcas en "On", como se muestra a continuación:
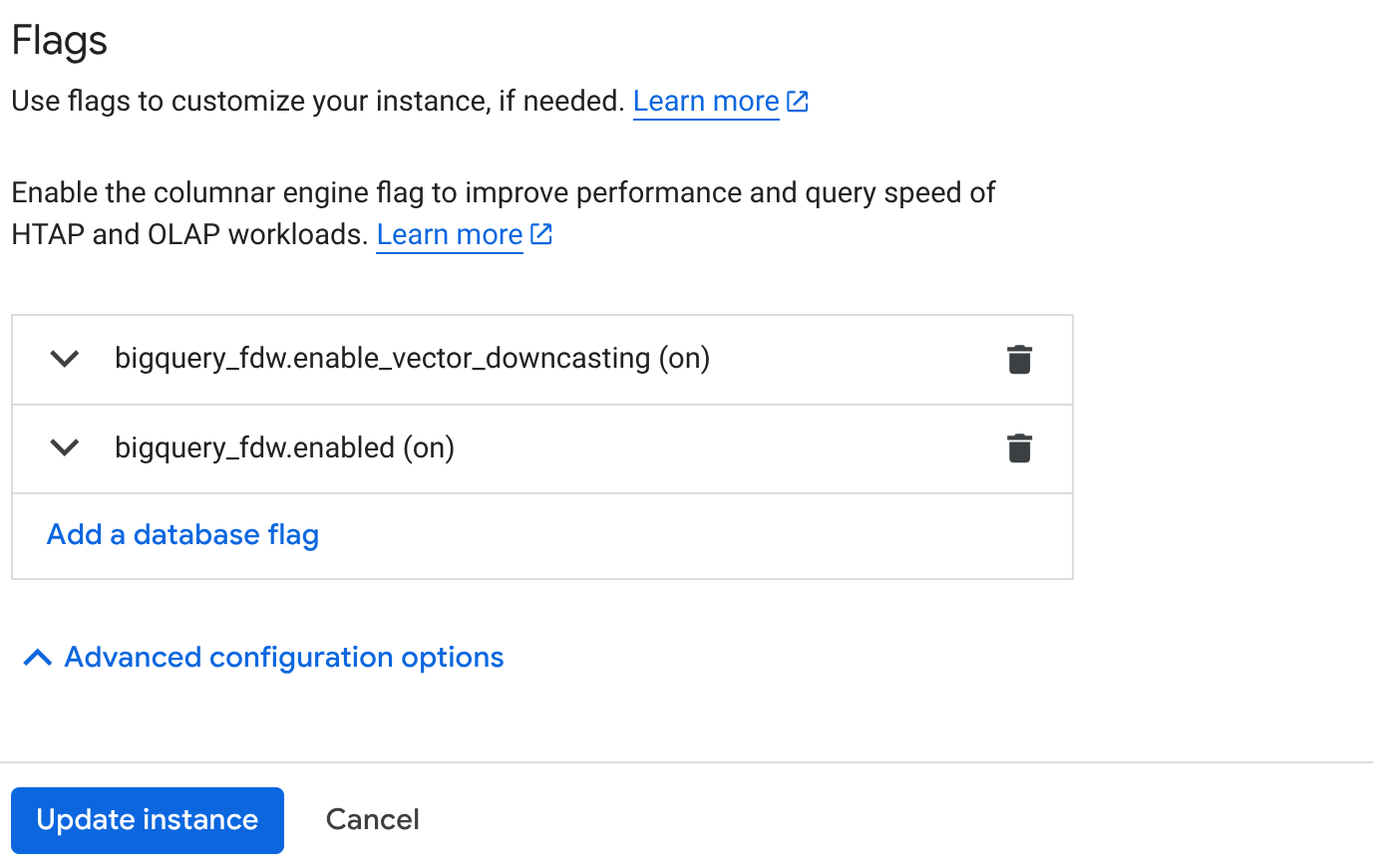 3. Haz clic en el botón Actualizar instancia y la actualización tardará unos minutos en completarse. 4. En la página de descripción general del clúster (consola de AlloyDB), haz clic en AlloyDB Studio.
3. Haz clic en el botón Actualizar instancia y la actualización tardará unos minutos en completarse. 4. En la página de descripción general del clúster (consola de AlloyDB), haz clic en AlloyDB Studio.
- Conéctate con la base de datos, el nombre de usuario y la contraseña que configuraste en el paso de configuración rápida de AlloyDB.
- Una vez que se haya establecido la conexión, en la pestaña Editor de consultas del lado derecho, ingresa las siguientes instrucciones y EJECÚTALAS una por una:
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- Una vez que lo hayas hecho correctamente, navega al panel del explorador que se encuentra a la izquierda y desplázate hacia abajo hasta las tablas de BigQuery:
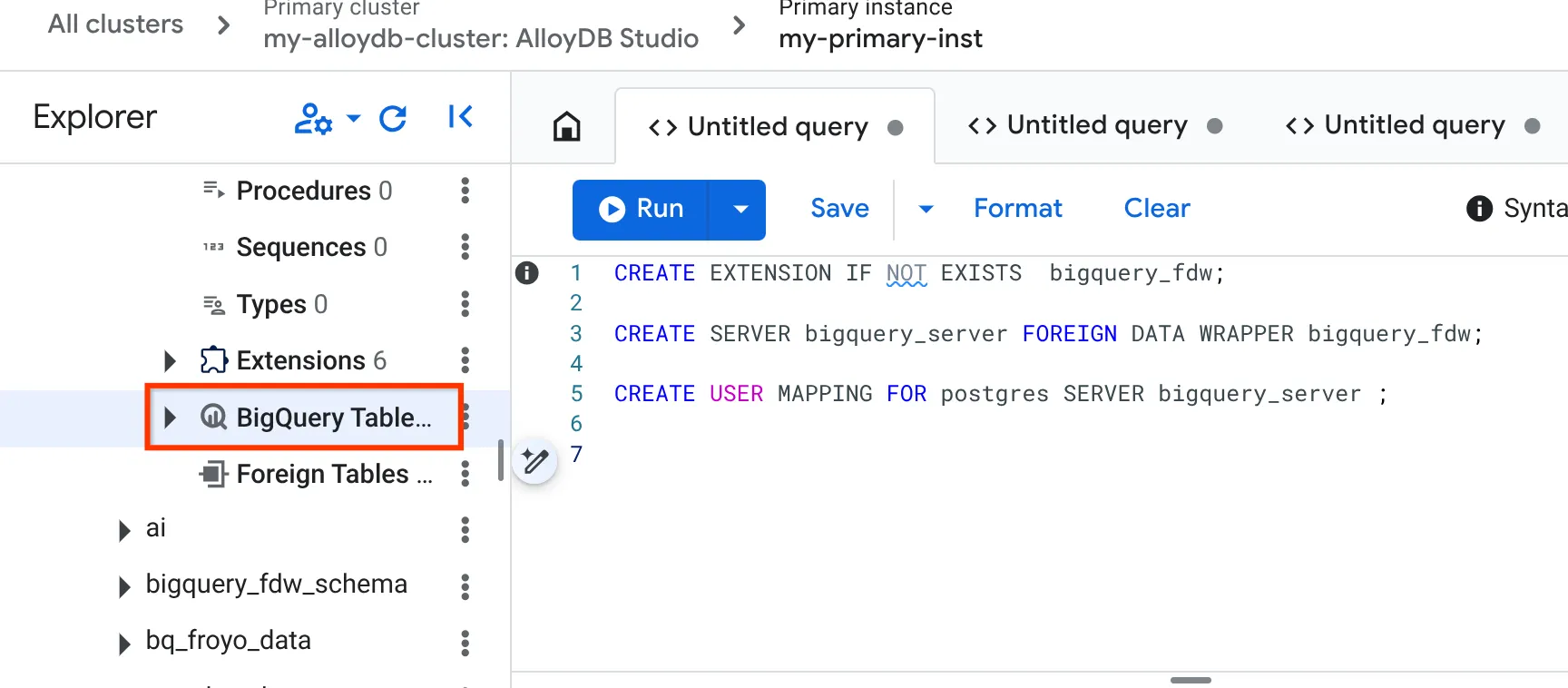
- Haz clic en los 3 puntos y, luego, en "Conectar tabla de BigQuery".
- En la ventana emergente Connect BigQuery Table que se abre, selecciona tu project_id y el nombre del conjunto de datos de BigQuery (creado en la parte 1) desde el que deseas consultar los datos en tu base de datos de AlloyDB.
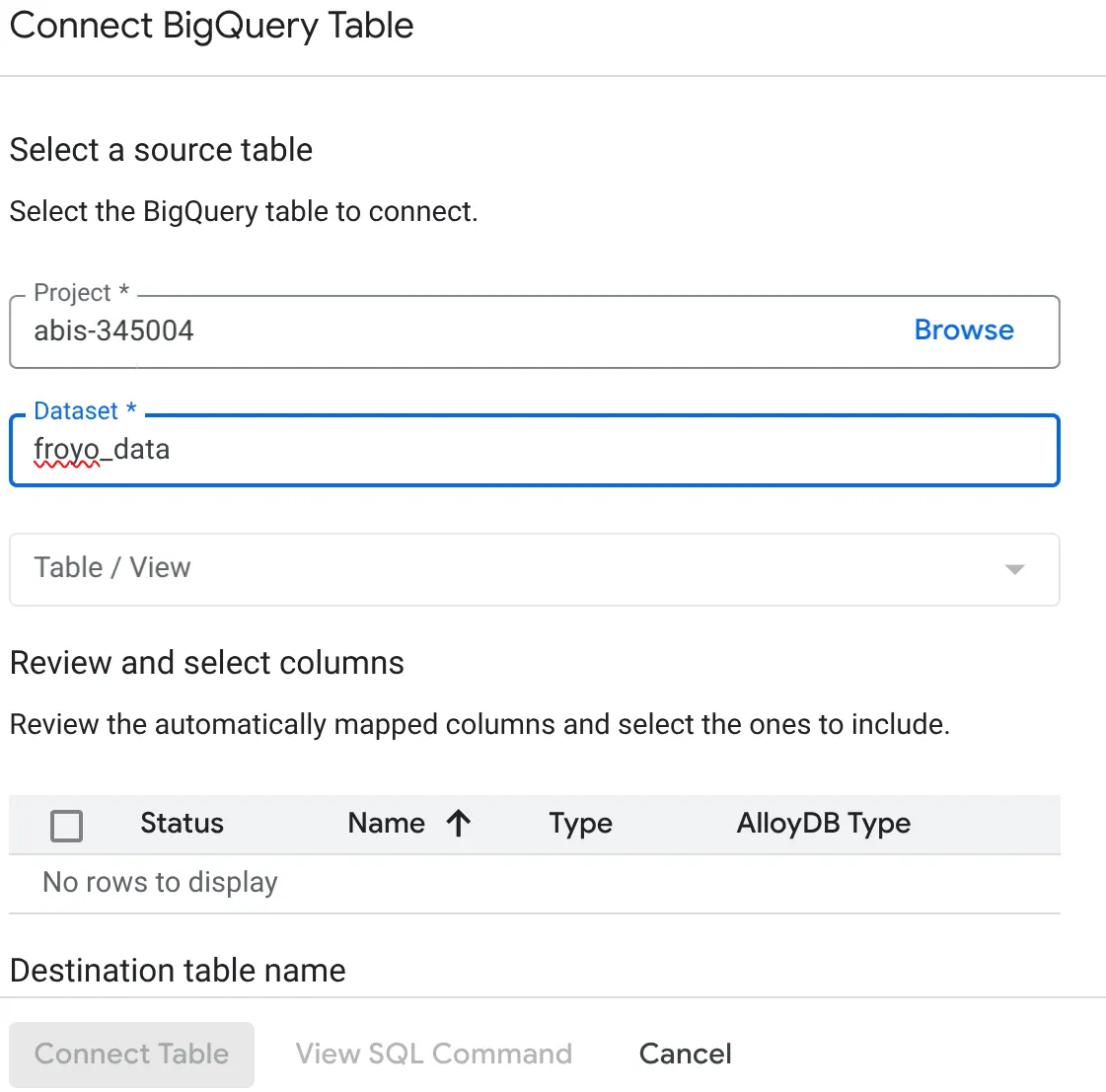
- Selecciona cada tabla una por una para conectar todos tus datos a AlloyDB. Esto nos permite validar los tipos de columnas para asegurarnos de que sean compatibles con AlloyDB.
Si deseas hacer lo mismo con SQL en lugar de usar el enfoque de apuntar y hacer clic, sigue estos pasos:
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
¡¡¡La magia!!!
Acabamos de crear "tablas externas" en AlloyDB. Se ven y actúan como tablas normales de PostgreSQL, pero no almacenan ningún dato. Cuando las consultas, AlloyDB las pasa instantáneamente a BigQuery, recupera los resultados y te los devuelve.
7. Prueba la federación en AlloyDB
Verifiquemos que podemos consultar nuestro enorme conjunto de datos analíticos de BigQuery directamente desde nuestra base de datos transaccional de PostgreSQL.
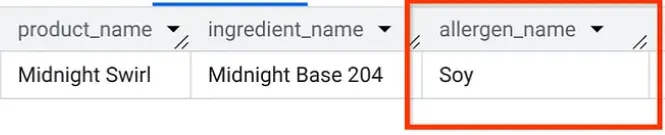
Aún en AlloyDB Studio, ejecutemos una consulta para averiguar qué alérgenos contiene el "Midnight Swirl" (la misma pregunta que hicimos en la Parte 1, pero esta vez desde AlloyDB):
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
Boom. Deberías ver exactamente los mismos resultados que en BigQuery.
8. Limpia
Cuando termines este lab, no olvides borrar el clúster y la instancia de AlloyDB.
Debería limpiar el clúster junto con sus instancias.
9. Felicitaciones por tu capa de datos unificada
Piensa en lo que acabamos de lograr:
- Nuestra app transaccional (que se ejecuta en AlloyDB) puede controlar sesiones de usuarios rápidas y simultáneas.
- Cuando necesita datos analíticos detallados o contexto histórico (como detalles del proveedor o asignaciones complejas de ingredientes), consulta froyo_dataschema de BigQuery.
- Zero ETL No se interrumpen las canalizaciones de datos. No hay bases de datos desincronizadas. Almacenamos los datos una vez (en BQ) y los calculamos donde los necesitamos.
Ahora que nuestra base de datos, tanto analíticos como transaccionales, es sólida y está interconectada, estamos listos para la parte divertida.
En la parte 3, compilaremos la aplicación multiagente que se encuentra en la parte superior de esta arquitectura para ejecutar las operaciones comerciales de Froyo.