
۱. مرور کلی
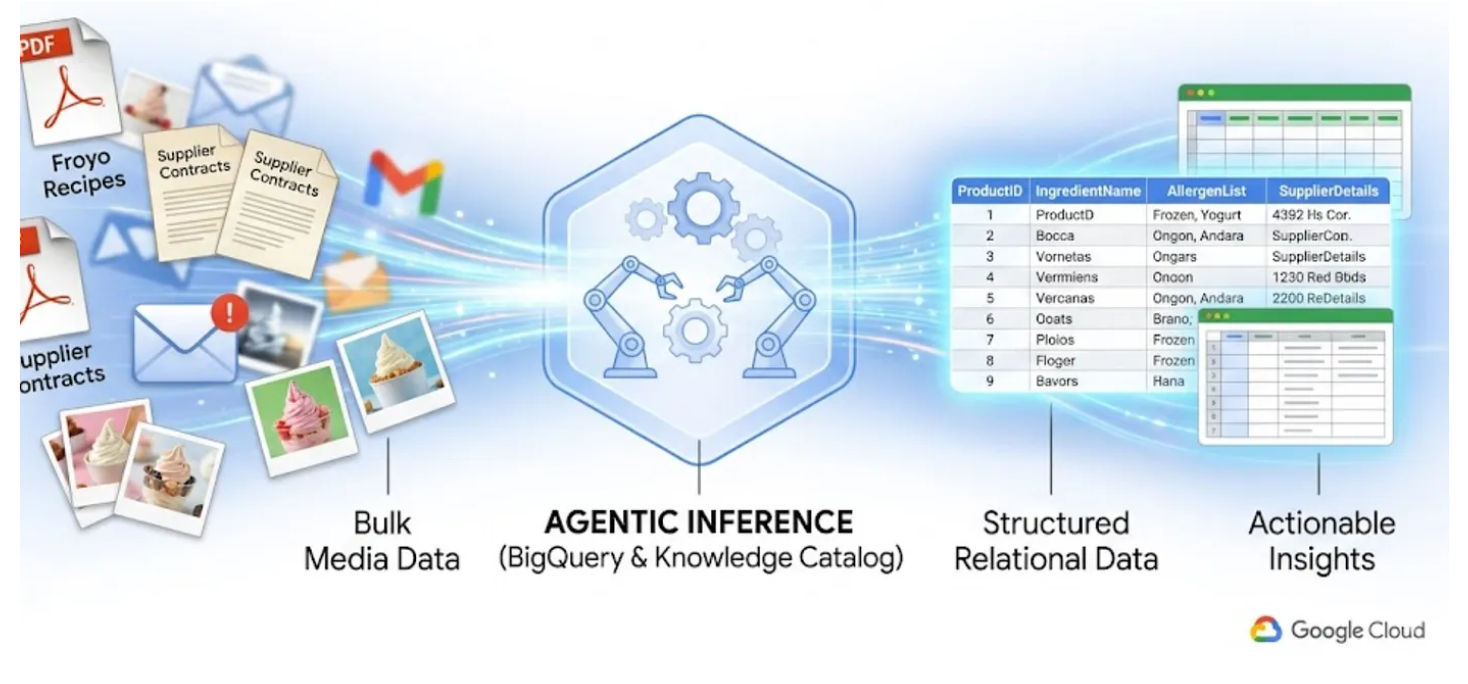
همه ما با دردسر «دادههای تاریک» آشنا هستیم. این دادهها شامل فایلهای PDF، تصاویر و متنهایی هستند که در فضای ذخیرهسازی ابری قرار دارند و کاملاً از دید کوئریهای SQL و داشبوردهای هوش تجاری شما پنهان هستند. بهطور سنتی، رمزگشایی این دادهها نیاز به خطوط لوله OCR پیچیده، ورود دستی دادهها یا اسکریپتهای سفارشی شکننده داشت.
دیگر نه.
در این آزمایش، به شما نشان خواهم داد که چگونه ۴۰۰ فایل PDF بدون ساختار - شامل متن، جداول و تصاویر - را به جداول BigQuery با ساختار تمیز تبدیل کنید که روابط بین آنها به طور خودکار استنباط میشود. و ما این کار را در عرض چند دقیقه با استفاده از BigQuery Knowledge Catalog و Dataplex انجام خواهیم داد.
آنچه خواهید ساخت
برای اینکه این موضوع را به واقعیت تبدیل کنیم، بیایید به یک کسب و کار خیالی نگاهی بیندازیم: یک فروشگاه زنجیرهای ماست یخزده که به سرعت در حال رشد است.
تصور کنید که شما دادههای مربوط به این کسبوکار Froyo را مدیریت میکنید. شما صدها دستور غذا و برگه مشخصات تأمینکنندگان دارید که همگی به صورت PDF ذخیره شدهاند. رهبران کسبوکار میخواهند یک عامل هوش مصنوعی راهاندازی کنند تا به مدیران فروشگاه و مشتریان در جستجوی جزئیات محصول کمک کند.
این سناریوی کابوسوار است: مشتری میپرسد: «من واقعاً به بستنی یخی Midnight Swirl شما علاقهمند هستم. آیا مواد حساسیتزا در آن وجود دارد؟»
برای پاسخ به این سوال، سیستم شما معمولاً باید:
- دستور پخت «چرخش نیمهشب» را به صورت PDF پیدا کنید.
- مواد تشکیل دهنده را بخوانید (مثلاً "پودر کاکائو"، "پایه لبنی"، "امولسیفایر X").
- برای یافتن برگه مشخصات مربوط به آن مواد خاص، دهها فایل PDF از تأمینکنندگان را جستجو کنید.
- برای اطلاع از آلرژنهای پنهان مرتبط با آن مواد، برگههای اطلاعات تأمینکننده را بررسی کنید.
تلاش برای ساخت یک عامل هوش مصنوعی که این کار را با خواندن ۴۰۰ فایل PDF خام در زمان اجرا، به صورت آنی انجام دهد، کند، پرهزینه و مستعد توهم است. در عوض، ما قصد داریم ابتدا از استنتاج معنایی برای استخراج همه این موارد به یک پایگاه داده رابطهای استفاده کنیم و عامل هوش مصنوعی آینده خود را به سرعت برق و ۱۰۰٪ مبتنی بر دادههای واقعی SQL بسازیم.
بیایید شروع به ساختن کنیم!
آنچه یاد خواهید گرفت
- نحوه تنظیم فضای ذخیرهسازی ابری برای فایلهای منبع (PDF)
- نحوه تنظیم و اجرای کار Datascan و استنتاج معنایی در Knowledge Catalog برای استخراج دادهها از فایلهای PDF منبع و استنتاج معنایی ارتباطات و زمینه و ذخیره آن در BigQuery
- نحوه استفاده از BigQuery Agents برای چت با مجموعه داده تازه ایجاد شده
الزامات
۲. قبل از شروع
ایجاد یک پروژه
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
- شما از Cloud Shell ، یک محیط خط فرمان که در Google Cloud اجرا میشود، استفاده خواهید کرد. روی Activate Cloud Shell در بالای کنسول Google Cloud کلیک کنید.

- پس از اتصال به Cloud Shell، با استفاده از دستور زیر بررسی میکنید که آیا از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است یا خیر:
gcloud auth list
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید شود که دستور gcloud از پروژه شما اطلاع دارد.
gcloud config list project
- اگر میخواهید احراز هویت کنید
gcloud auth login
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- فعال کردن API های مورد نیاز: برای فعال کردن تمام API های مورد نیاز، این دستور را اجرا کنید:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
اشکالات و عیبیابی
سندرم «پروژه ارواح» | شما |
سنگر بیلینگ | شما پروژه را فعال کردید، اما حساب صورتحساب را فراموش کردید. AlloyDB یک موتور با کارایی بالا است؛ اگر "مخزن بنزین" (صورتحساب) خالی باشد، روشن نمیشود. |
تأخیر انتشار API | شما روی «فعال کردن APIها» کلیک کردهاید، اما خط فرمان هنوز میگوید |
کواگهای سهمیهای | اگر از یک حساب آزمایشی کاملاً جدید استفاده میکنید، ممکن است به سهمیه منطقهای برای نمونههای AlloyDB برسید. اگر |
نماینده خدمات "پنهان" | گاهی اوقات به طور خودکار نقش |
۳. راهاندازی سطل ذخیرهسازی ابری گوگل
در این بخش، شما یک ساختار سازمانی در BigQuery ایجاد میکنید تا دادههای دستور پخت و تأمینکننده Froyo، به ویژه برای جزئیات محصول Froyo، را ذخیره کند. همچنین یک اتصال منابع ابری ایجاد میکند که به عنوان یک "پل" امن عمل میکند و به BigQuery اجازه میدهد فایلها را از منابع خارجی مانند Cloud Storage بخواند.
قبل از شروع:
این مخزن شامل دستور پختها، فایلهای PDF تامینکنندگان و فایلهایی است که در این پروژه از آنها استفاده خواهیم کرد. حتماً این فایلها را دانلود کنید. برای دانلود فایلها، مراحل زیر را انجام دهید.
در Cloud Shell، دستور زیر را اجرا کنید:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
به پوشه تازه ایجاد شده بروید:
cd next-26-keynotes
پوشه data-cloud-demo را استخراج کنید
git sparse-checkout set genkey/data-cloud-demo
پس از اتمام پرداخت، به پوشه data-cloud-demo بروید و فایلهای ZIP را استخراج کنید تا به فایلهای codelab دسترسی پیدا کنید.
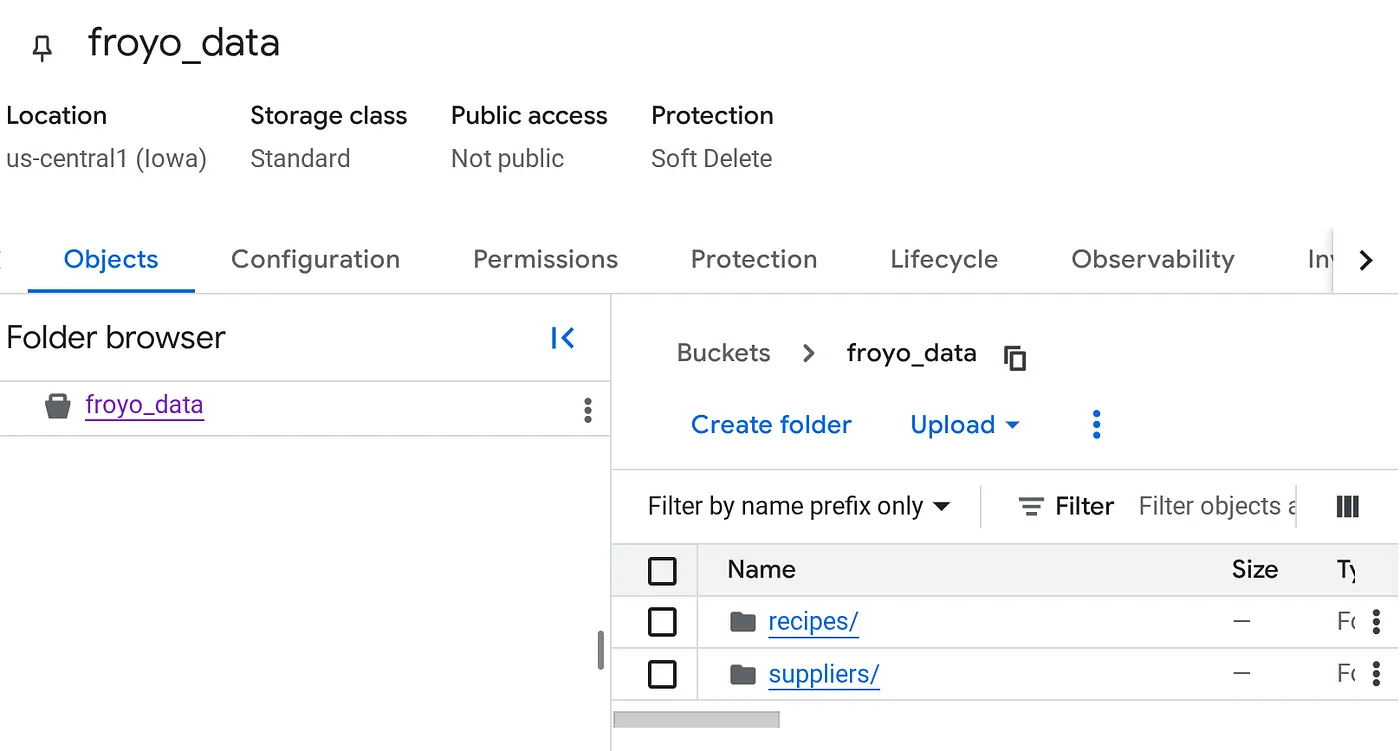
یک باکت ایجاد کنید و فایلهای پیدیاف Froyo (دستور پختها و تامینکنندگان) را آپلود کنید.
- در کنسول گوگل کلود، به صفحه Cloud Storage Buckets بروید.
- روی ایجاد کلیک کنید.
- در صفحه ایجاد یک سطل ، اطلاعات سطل خود را وارد کنید. پس از هر یک از مراحل زیر، برای رفتن به مرحله بعدی، روی ادامه کلیک کنید:
- در بخش شروع به کار ، نام سطل را وارد کنید. به عنوان مثال: froyo_data
- در بخش «انتخاب محل ذخیره دادههایتان» ، منطقه را انتخاب کرده و سپس منطقه خود را وارد کنید. us-central1
- در بخش «انتخاب نحوه کنترل دسترسی به اشیاء» ، کادر انتخاب «اجرای پیشگیری از دسترسی عمومی در این بخش» را علامت بزنید.
- روی ایجاد کلیک کنید.
- در لیست سطلها، روی سطلی که ایجاد کردهاید کلیک کنید.
- در تب اشیاء مربوط به سطل، روی بارگذاری و سپس بارگذاری پوشهها کلیک کنید.
- پوشه دستور پختهایی که در بخش «قبل از شروع» این آزمایشگاه کد، استخراج کردهاید را انتخاب کنید.
- روی آپلود کلیک کنید.
- فرآیند آپلود را برای پوشه تامینکنندگان تکرار کنید.
پس از آپلود، ساختار سطل شما باید (صرف نظر از نام سطل) به شکل زیر باشد:
۴. تنظیمات اتصال BigQuery
یک اتصال به منابع ابری ایجاد کنید. این یک حساب کاربری سرویس منحصر به فرد ایجاد میکند که به عنوان "کارت شناسایی" BigQuery برای دسترسی به فایلهای خارجی عمل میکند.
- به صفحه BigQuery بروید.
- در پنل سمت چپ، روی Explorer کلیک کنید. اگر پنل سمت چپ را نمیبینید، روی Expand left pane کلیک کنید تا پنل باز شود.
- در پنل Explorer، نام پروژه خود را باز کنید و سپس روی Connections کلیک کنید.
- در صفحه اتصالات، روی ایجاد اتصال کلیک کنید.
- برای نوع اتصال، مدلهای از راه دور Vertex AI، توابع از راه دور، BigLake و Spanner (Cloud Resource) را انتخاب کنید.
- در قسمت شناسه اتصال، نام شناسه اتصال را وارد کنید:
- اتصال bq. حتماً این شناسه را یادداشت کنید زیرا هنگام تنظیم اسکن دادهها در ادامهی این آزمایشگاه کد به آن نیاز خواهید داشت.
- نوع مکان (Location type) را روی منطقه (Region) تنظیم کنید و سپس یک منطقه (Region) را انتخاب کنید. برای مثال، us-central1. اتصال باید در همان منطقهای باشد که سایر منابع شما مانند مجموعه دادهها قرار دارند.
- روی ایجاد اتصال کلیک کنید.
- روی رفتن به اتصال کلیک کنید.
- در پنجره اطلاعات اتصال، شناسه حساب سرویس را برای استفاده در مرحله بعد کپی کنید. حساب سرویس شبیه به bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com است.
۵. تنظیمات مجوزها
- مجوزهای لازم را به اتصال BigQuery برای دسترسی به اشیاء ذخیرهسازی ابری و کاتالوگ دانش اعطا کنید.
به صفحه IAM & Admin بروید و در بخش View by Principals، روی دکمه Grant access کلیک کنید، با چسباندن حساب کاربری سرویسی که در مرحله قبل کپی کردهاید، یک مدیر اصلی اضافه کنید. در بخش roles، نام نقشهای زیر را یکی یکی اضافه کرده و ذخیره کنید:
- نقشها/ذخیرهسازی.شیءکاربر
- نقشها/ذخیرهسازی.مشاهدهگر شیء
- نقشها/bigquery.user
- roles/bigquery.dataEditor
- نقشها/aiplatform.viewer
- نقشها/پلتفرم عامل.کاربر
- نقشها/ذخیرهسازی.مدیر
- role/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- role/dataplex.serviceAgent
- نقشها/dataplex.securityAdmin
- مجوزهای دسترسی به Cloud Storage Bucket را به حساب کاربری سرویس Dataplex اعطا کنید.
به صفحه IAM & Admin بروید و در بخش View by Principals ، روی دکمه Grant access کلیک کنید و با تایپ کلمه dataplex در نوار متن New principal، یک principal اضافه کنید. از لیستی که به صورت خودکار تکمیل میشود، principal حساب سرویس Dataplex را که شبیه به این است انتخاب کنید: (در شناسه ایمیل حساب سرویس در زیر از شماره پروژه استفاده کنید و نه شناسه پروژه )
سرویس-<< شماره پروژه شما >>@ gcp-sa-dataplex.iam.gserviceaccount.com
اگر به هر دلیلی حساب سرویس فوق برای شماره پروژه شما شناسایی نمیشود، ممکن است به این دلیل باشد که پروژه هنوز سرویس دیتاپلکس را مقداردهی اولیه نکرده است. به ترمینال Cloud Shell بروید و با اجرای دستور زیر، API را فعال کنید (اگر قبلاً در مرحله قبل از شروع این کار را انجام ندادهاید): gcloud services enable dataplex.googleapis.com
حتی پس از آن، اگر حساب سرویس مربوط به Dataplex شناسایی نشد، یک فرآیند آزمایشی ایجاد شغل اسکن Dataplex را در صفحه Metadata Curation اعمال کنید و جزئیات را در صفحه Discover Job creation وارد کنید:
روی «اکنون اجرا کن» کلیک کنید. کار با شکست مواجه خواهد شد، اما این کار تضمین میکند که شناسه حساب سرویس اکنون برای سرویس Dataplex شما مقداردهی اولیه خواهد شد.
به صفحه IAM & Admin برگردید و در بخش View by Principals ، روی دکمه Grant access کلیک کنید و سپس روی add a principal کلیک کنید. حساب کاربری سرویس را جایگذاری کنید:
سرویس-<< شماره پروژه شما >>@ gcp-sa-dataplex.iam.gserviceaccount.com
سپس نقشهای زیر را به این حساب سرویس اعطا کنید:
- نقشها/ذخیرهسازی.شیءکاربر
- نقشها/ذخیرهسازی.مشاهدهگر شیء
- نقشها/ذخیرهسازی.بیننده
- role/dataplex.discoveryBigLakePublishingServiceAgent
۶. راهاندازی کاتالوگ دانش
یک کاتالوگ دانش بسازید تا دادههای بدون ساختار را یکپارچه کنید و کشف فایلهای بدون ساختار (مانند دستور العملهای PDF و تامینکنندگان PDF) را خودکار کنید.
کار DataScan را از کنسول ایجاد کنید:
- به صفحه گردآوری فراداده بروید.
- روی ایجاد کلیک کنید و جزئیات مربوط به تنظیمات خود را وارد کنید:
نکته مهم: فراموش نکنید که گزینه Enable Semantic Inference را تیک بزنید.
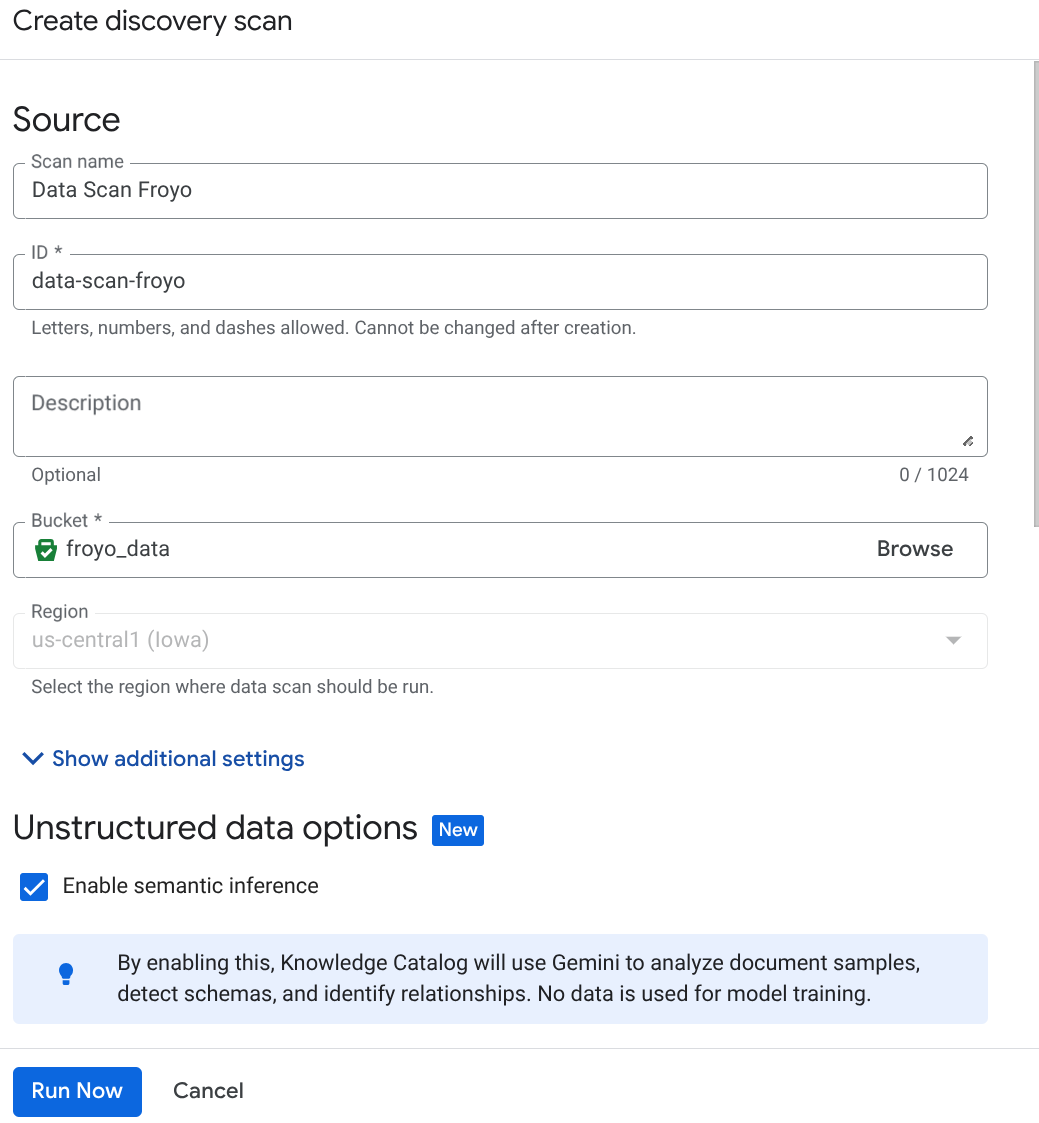
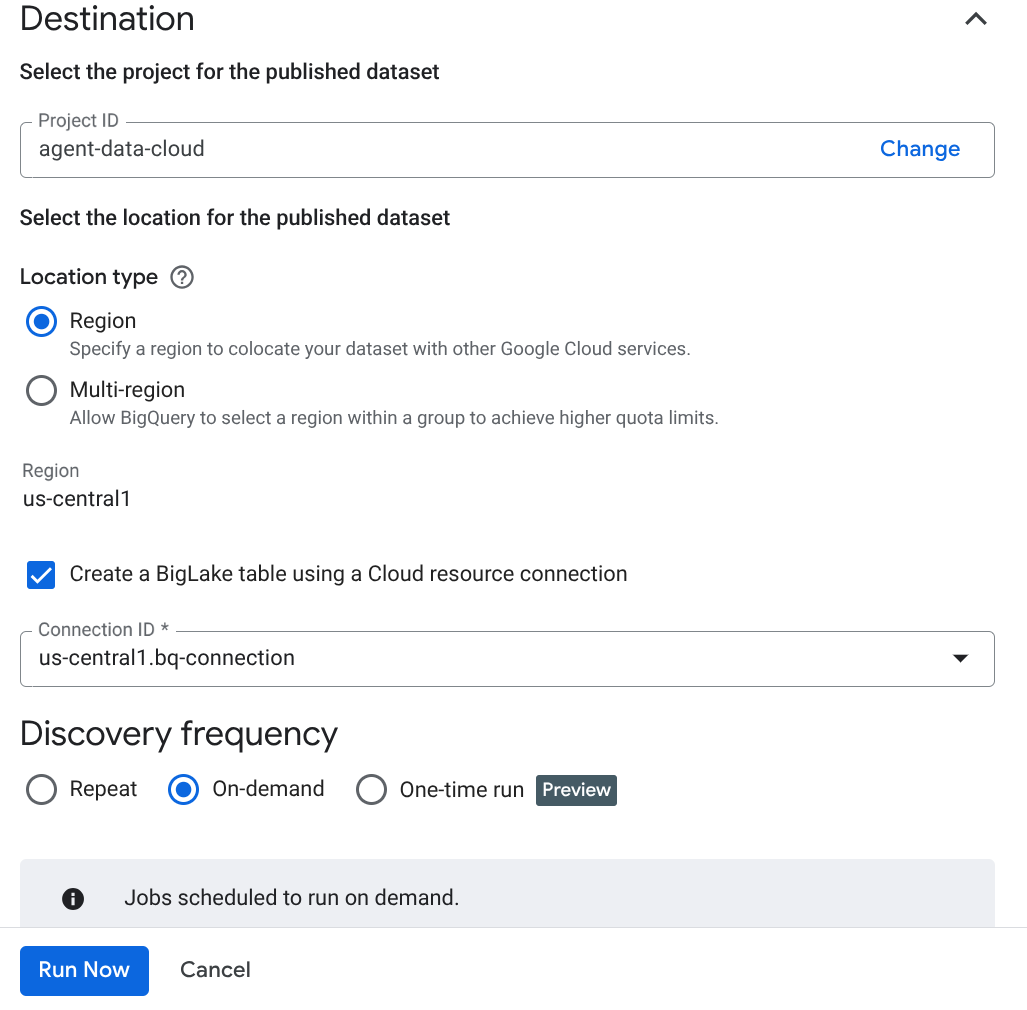
- روی «اجرای اکنون» کلیک کنید.
- تکمیل کار اسکن مدتی طول میکشد. پس از اتمام کار، بررسی کنید که آیا مجموعه داده منتشر شده وجود دارد یا خیر. برای بررسی وضعیت کار، میتوانید در صفحه Metadata curation ، در تب Cloud Storage discovery، روی نام اسکنهای کشفشده در اجرای اخیر کلیک کنید. باید مجموعه داده منتشر شده را مانند تصویر زیر مشاهده کنید:
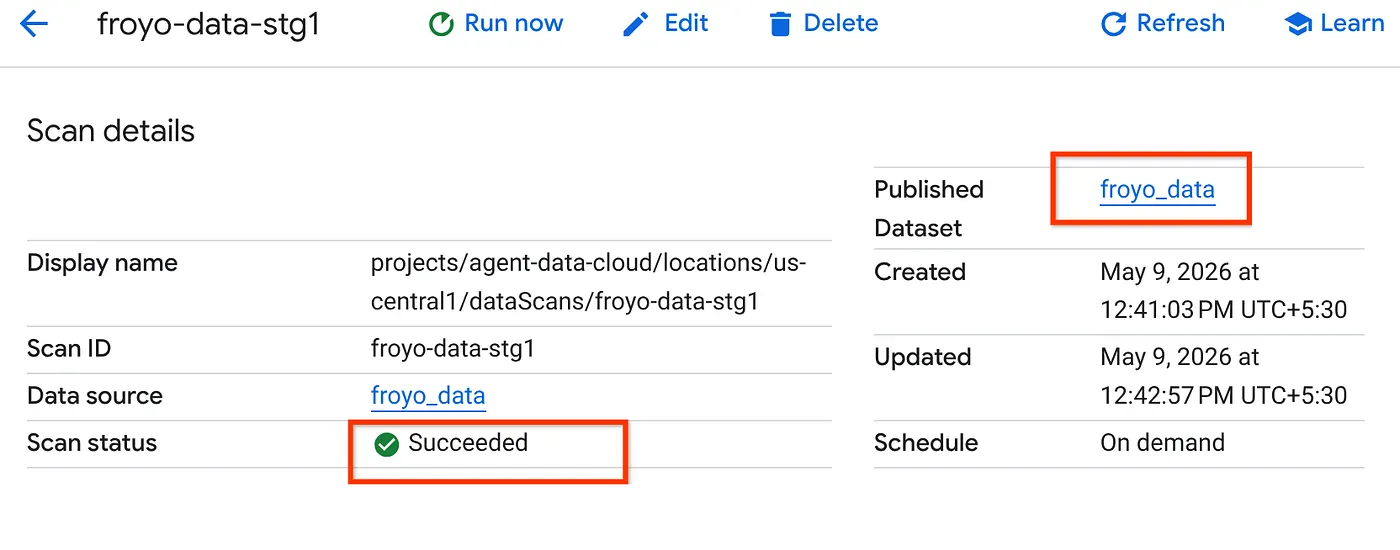
توجه: اگر در مرحله اسکن با خطایی مواجه شدید، کمی به آن زمان بدهید و سپس دوباره امتحان کنید (ایجاد و اجرای کامل کار چند دقیقه طول میکشد).
- شما میتوانید جدول را در BigQuery با کلیک کردن و رفتن به مجموعه داده froyo_data مشاهده کنید. روی شناسه جدول در BigQuery کلیک کنید و کوئری زیر را در تب Query Editor اجرا کنید:
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
این نتیجه ۴۰۰ میشود (اگر نه، میتوانید برگردید و کار Datascan را دوباره اجرا کنید).
۷. استخراج دادههای معنایی
عالی!! حالا بیایید با استفاده از کاتالوگ دانش، استنتاج را برای این اشیاء بدون ساختار استخراج کنیم.
ما از ویژگی Insights برای تولید دستورات SQL جهت استخراج دادههای ساختاریافته از جدول بدون ساختار استفاده خواهیم کرد.
- در کنسول گوگل کلود، به صفحه جستجوی کاتالوگ دانش بروید.
- جدول مجموعه دادهای را که میخواهید اطلاعات آن را مشاهده کنید، جستجو کنید. در نوار جستجو، نام مجموعه داده/جدول را از مرحله قبل وارد کنید: "froyo_data" و کلید اینتر را بزنید.
- از لیست نتایج، روی ورودی TABLE (نه روی ورودی مجموعه داده) کلیک کنید.
- شما باید تب INSIGHTS را ببینید. روی آن کلیک کنید (اگر لازم است API خاصی را فعال کنید، مراحل را دنبال کنید و فقط APIها را فعال کنید).
اگر در این مرحله APIها را فعال کردهاید، باید کار اسکن را دوباره اجرا کنید.
- در تب INSIGHTS، دکمه کشویی EXTRACT را مشاهده خواهید کرد. روی آن کلیک کنید و گزینه "Extract with SQL" را انتخاب کنید.
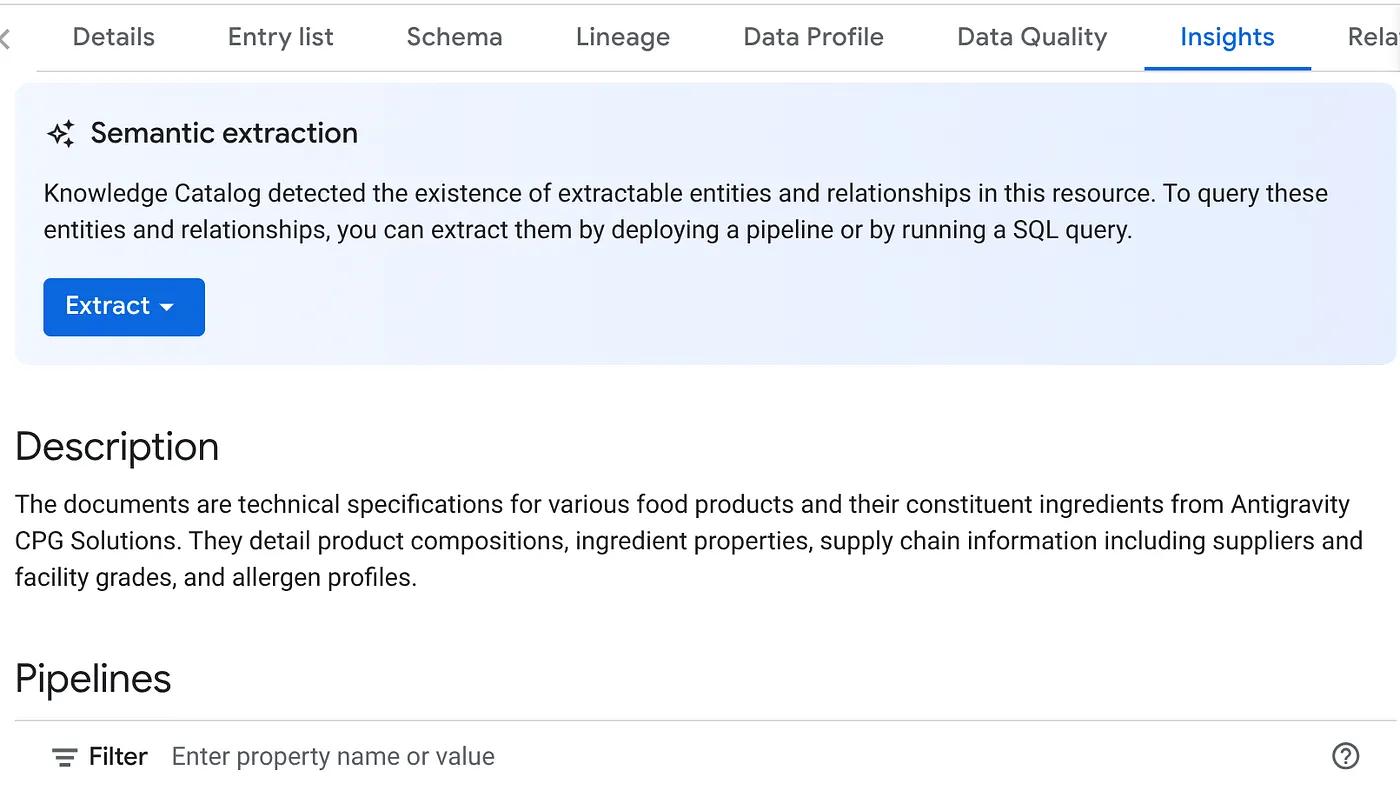
در پنجرهی « استخراج با SQL » که ظاهر میشود، مجموعه دادهی DESTINATION را به عنوان مجموعه دادهای که در نتیجهی کار Datascan مشاهده کردید، تنظیم کنید. نام آن را تایپ کنید تا به صورت خودکار نمایش داده شود. روی دکمهی « استخراج » کلیک کنید. همچنین میتوانید در این مرحله یک مجموعه دادهی جدید ایجاد کرده و آن را استخراج کنید.
این باید ویرایشگر پرس و جوی BigQuery را با یک برگه باز شده که حاوی SQL استخراج شده از استنتاج اسکن دادهها است، باز کند.
۸. اعتبارسنجی SQL و ایجاد طرحواره
اگر کوئری تولید شده خوب به نظر میرسد و از نظر معنایی با دادههای بدون ساختار شما مرتبط است، با کلیک بر روی دکمه Run در ویرایشگر کوئری، آن را اجرا کنید. ایجاد طرحواره مورد نیاز برای ذخیرهسازی ساختاریافته رسانههای بدون ساختار شما چند دقیقه طول خواهد کشید.
پس از انجام این کار، باید بتوانید با گسترش مجموعه دادهها در پنل اکسپلورر BigQuery Studio، همانطور که در زیر مشاهده میکنید، طرحواره را تأیید کنید:
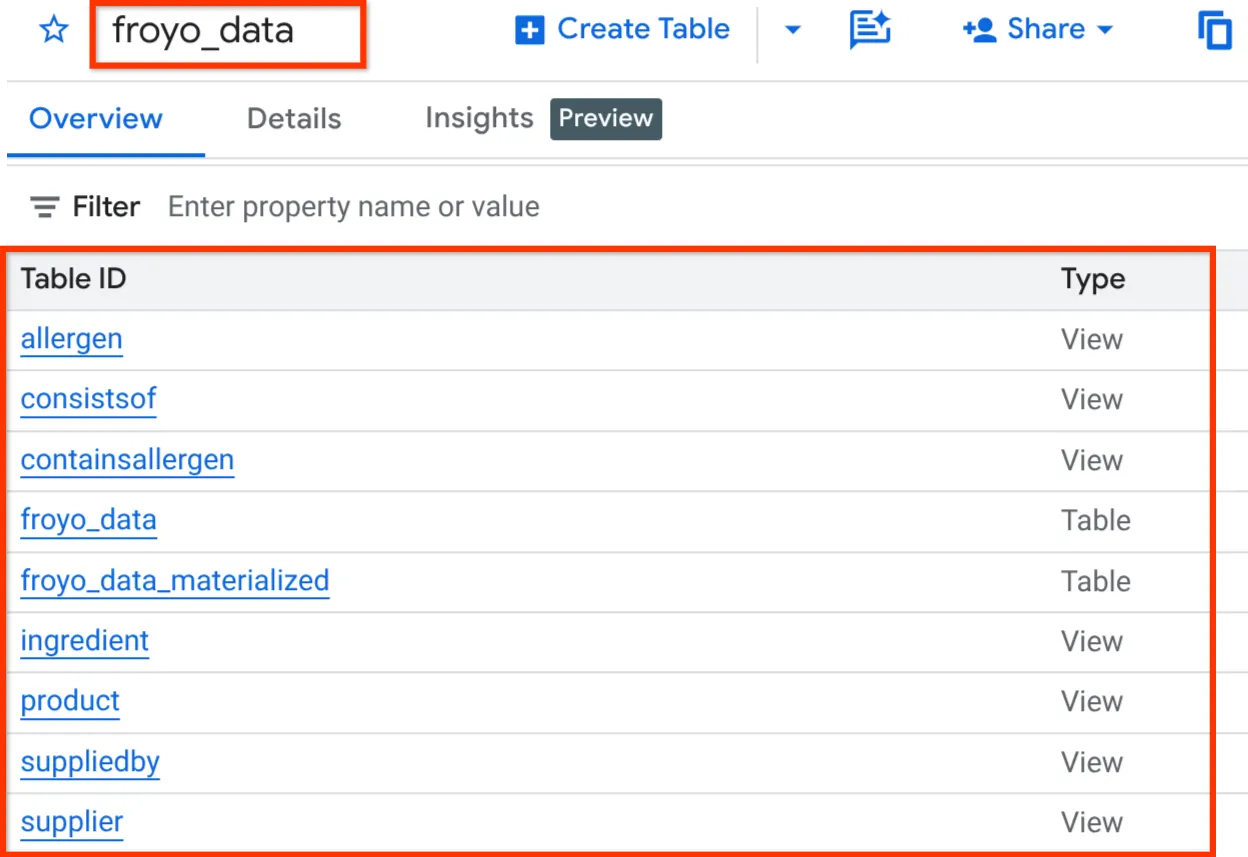
خیلی خب!!! خیلی خوب بود که همه کارهای مربوط به پایگاه داده رو خیلی سریع انجام دادیم. حالا وقت امتحان نهاییه!
مراحل ادامه استفاده از دادهها بدون نیاز به حساب صورتحساب:
- میتوانید فایلهای csv دادهها (BigQuery Data) را از لینک مخزن گیتهاب بالا دریافت کنید.
- ابتدا، با اجرای دستور زیر از ترمینال Cloud Shell، مجموعه داده BigQuery را ایجاد کنید:
bq mk --location us-central1 --dataset froyo_data
- در مرحله بعد، با اجرای دستورات زیر به صورت یک به یک، 8 فایل داده (فایلهای csv) را از مخزن گیتهاب در دایرکتوری کاری خود دانلود کنید:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- دستورات زیر را یکی یکی اجرا کنید تا این جداول با دادههای موجود در مجموعه داده جدید ایجاد شوند.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
پس از ایجاد مجموعه دادهها، جداول و دادهها، میتوانید به آزمایش و تجربه دادههایی که در مورد آنها صحبت کردیم، بپردازید.
۹. آزمون نهایی!!!
فرض کنید میخواهم عامل من با اطلاعات واقعی، کامل و بهخوبی هماهنگشده و مبتنی بر واقعیتها به سوالات کاربر پاسخ دهد. قرار است سوالی بپرسم که عامل فقط با مراجعه به چندین فایل رسانهای و ارجاعات از منبع من بتواند به آن پاسخ دهد.
سوال کاربری من اینه:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
حالا یک جستجوی عمومی یا جستجوی LLM میگوید "بدون مواد تشکیلدهنده". اما ما یک استنتاج معنایی کامل ایجاد کردیم که تمام رسانههای بدون ساختار ما را به دادههای ساختاریافته تبدیل میکند. بنابراین، با یک SQL ساده که این اطلاعات را دریافت میکند، این کار را انجام میدهیم:
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
وای! به نتیجه نگاه کنید:
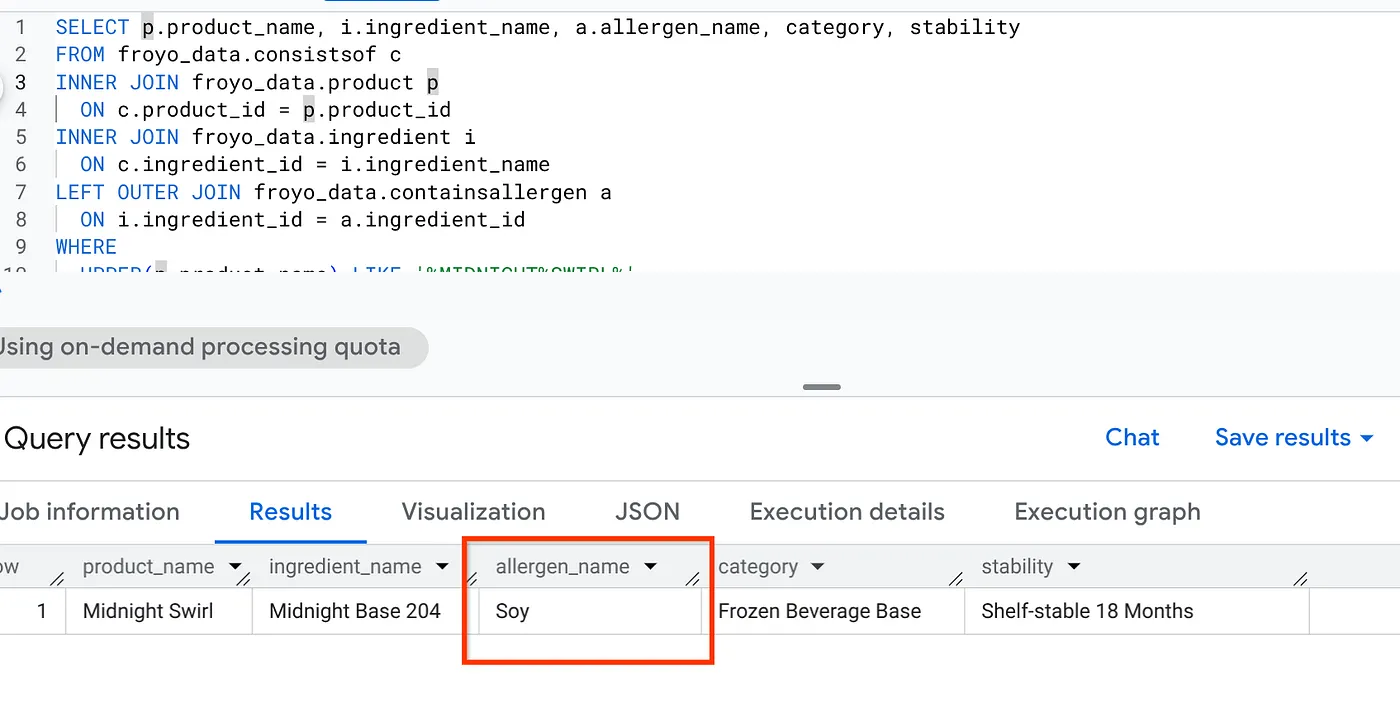
۱۰. تمیز کردن
پس از اتمام این آزمایش، فراموش نکنید که اسکن جاب و جداول BigQuery که در نهایت توسط این جاب ایجاد شدهاند را حذف کنید.
به آدرس https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery بروید. با کلیک روی سه نقطه عمودی کنار وظیفهای که میخواهید حذف کنید، آن را انتخاب کرده و روی دکمه DELETE کلیک کنید.
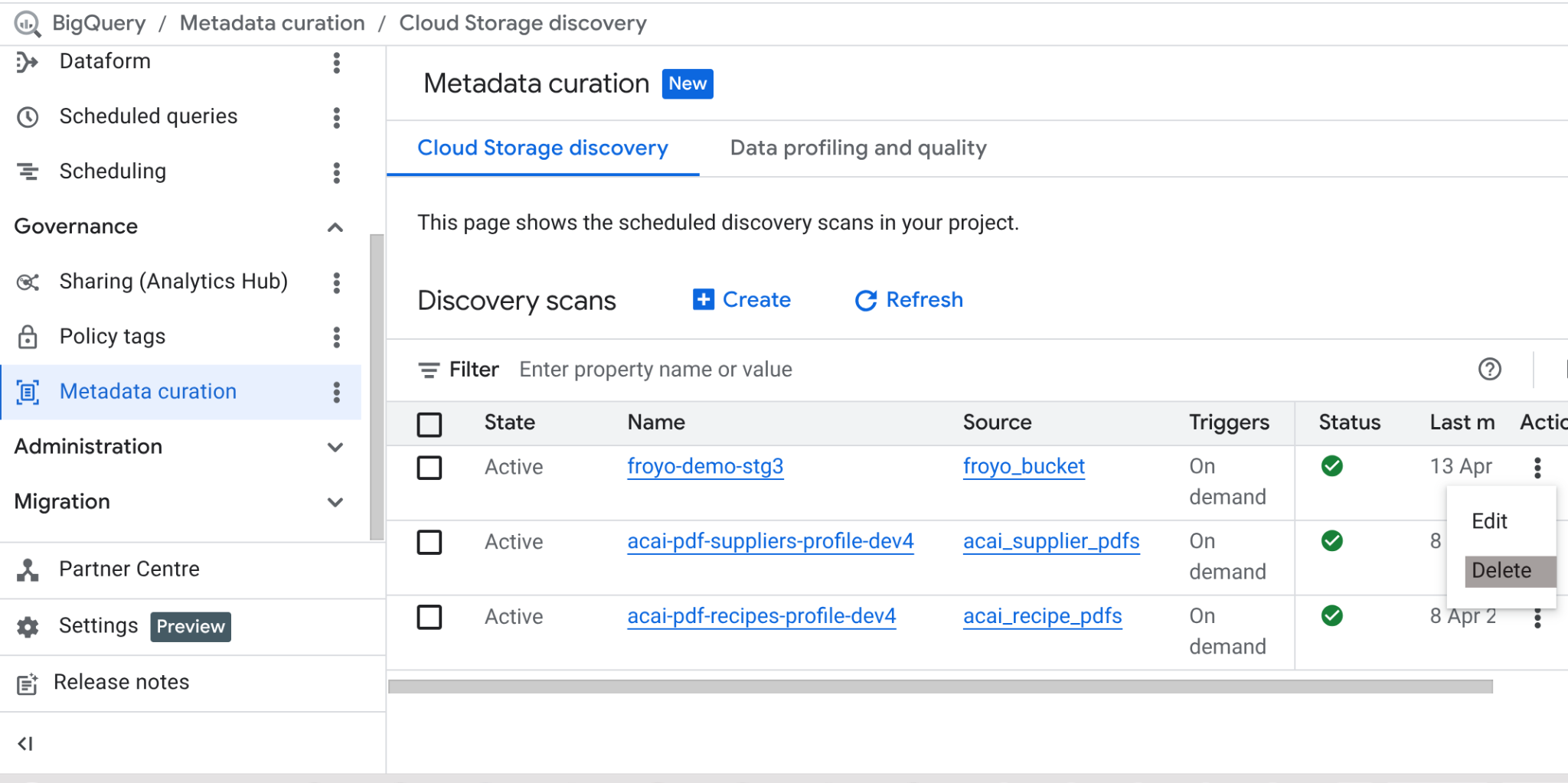
باید کار را تمیز کند.
۱۱. تبریک
پیادهسازی ما با موفقیت توانست آلرژن پنهان را شناسایی کند. دیگر نیازی به دادههای تاریک نیست، رفقا!!! در بخش ۲ ، این دادههای BigQuery را در یک سیستم تراکنشی با AlloyDB ادغام خواهیم کرد تا نیازهای دادهای برنامه عاملمحور خود را یکپارچه کنیم.