
۱. مرور کلی
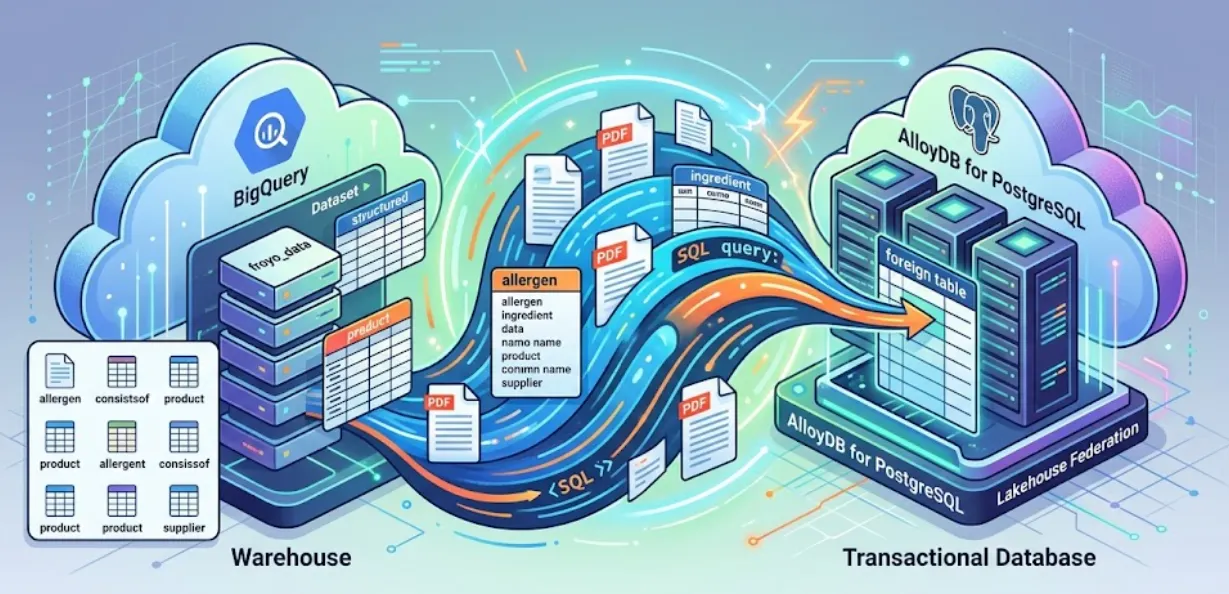
در بخش اول ، ما با موفقیت فایلهای PDF بینظم و بدون ساختار را با استفاده از Knowledge Catalog و DataScan به جداول تمیز، هوشمند و ساختاریافته در BigQuery تبدیل کردیم. اکنون، ما یک انبار داده قوی داریم.
اگر به یادآوری سریع نیاز دارید، در آزمایش بخش اول، ما مورد استفاده یک فرنچایز خیالی Frozen Yogurt را در نظر گرفتیم و ۴۰۰ فایل PDF بدون ساختار آن - شامل متن، جداول و تصاویر - را به جداول BigQuery با ساختار تمیز تبدیل کردیم که روابط بین آنها به طور خودکار با استفاده از BigQuery Knowledge Catalog و Dataplex استنباط میشد.
آنچه خواهید ساخت
در این جلسه، ما AlloyDB را برای PostgreSQL راهاندازی میکنیم و کاری جادویی انجام میدهیم: دادههای BigQuery خود را مستقیماً در AlloyDB ادغام میکنیم. این بدان معناست که برنامه تراکنشی ما میتواند دادههای انبار داده ما را به صورت بلادرنگ و بدون کپی کردن یا تکثیر هیچ یک از آنها، جستجو کند.
شما به عنوان یک توسعهدهنده باید در این مرحله این سوال را بپرسید:
«اگر دادهها از قبل در BigQuery وجود دارند، چرا AlloyDB را هم به این مجموعه اضافه کنیم؟ چرا برنامه مستقیماً یک دستور SELECT را در BigQuery اجرا نمیکند؟»
دلیلش این است:
با Lakehouse Federation، میتوانید از موتور جستجوی AlloyDB برای تقویت بارهای کاری تراکنشی و تحلیلی برنامه خود از طریق همان رابط کاربری استفاده کنید. همچنین میتوانید این دادهها را برای دسترسی سریعتر جهت استفاده در برنامههای خود، در AlloyDB پیادهسازی یا وارد کنید که به شما امکان میدهد از هوش مصنوعی AlloyDB و موتور ستونی استفاده کنید.
شما میتوانید از AlloyDB به عنوان یک پایگاه داده تراکنشی استفاده کنید و همچنین حجم زیادی از دادهها را در BigQuery یا BigLake ذخیره کنید. برنامههای شما معمولاً به طور مستقل با هر دوی این سیستمها ادغام میشوند تا به دادهها در این سرویسهای مختلف Google Cloud دسترسی داشته باشند. Lakehouse Federation برای AlloyDB به شما امکان میدهد از پشتیبانی پرسوجوی فدرال AlloyDB که به عنوان یک پوشش داده خارجی پیادهسازی شده است، برای دسترسی به دادههای BigQuery و AlloyDB با استفاده از یک رابط SQL در AlloyDB استفاده کنید.
به جای ساخت یک خط لوله ETL شکننده برای پرسوجوی دادههای BigQuery از AlloyDB، از پرسوجوهای یکپارچه استفاده خواهیم کرد. AlloyDB به عنوان یک نقطه پایانی یکپارچه عمل میکند و در صورت نیاز به طور یکپارچه به BigQuery دسترسی پیدا میکند.
بیایید شروع به ساختن کنیم!
آنچه یاد خواهید گرفت
- نحوه راهاندازی کلاستر، نمونه و شبکهسازی AlloyDB تنها با یک کلیک
- نحوه تنظیم برنامه الحاقی برای آماده شدن برای فدراسیون
- نحوه راه اندازی فدراسیون از BigQuery به AlloyDB
- آن را آزمایش کنید
الزامات
۲. قبل از شروع
ایجاد یک پروژه
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
- شما از Cloud Shell ، یک محیط خط فرمان که در Google Cloud اجرا میشود، استفاده خواهید کرد. روی Activate Cloud Shell در بالای کنسول Google Cloud کلیک کنید.

- پس از اتصال به Cloud Shell، با استفاده از دستور زیر بررسی میکنید که آیا از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است یا خیر:
gcloud auth list
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید شود که دستور gcloud از پروژه شما اطلاع دارد.
gcloud config list project
- اگر میخواهید احراز هویت کنید
gcloud auth login
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- فعال کردن API های مورد نیاز: برای فعال کردن تمام API های مورد نیاز، این دستور را اجرا کنید:
gcloud services enable alloydb.googleapis.com
اشکالات و عیبیابی
سندرم «پروژه ارواح» | شما |
سنگر بیلینگ | شما پروژه را فعال کردید، اما حساب صورتحساب را فراموش کردید. AlloyDB یک موتور با کارایی بالا است؛ اگر "مخزن بنزین" (صورتحساب) خالی باشد، روشن نمیشود. |
تأخیر انتشار API | شما روی «فعال کردن APIها» کلیک کردهاید، اما خط فرمان هنوز میگوید |
کواگهای سهمیهای | اگر از یک حساب آزمایشی کاملاً جدید استفاده میکنید، ممکن است به سهمیه منطقهای برای نمونههای AlloyDB برسید. اگر |
۳. خلاصهای سریع از دادههای بخش ۱
در این بخش، باید مطمئن شوید که دادههای ساختاریافتهای که از فایلهای PDF بدون ساختار استخراج کردهایم، در BigQuery موجود هستند. حال اگر بخش ۱ را از دست دادهاید یا حساب صورتحساب ندارید، اشکالی ندارد، میتوانید مراحل زیر را انجام دهید و شروع کنید:
از حساب جیمیل شخصی خود به کنسول ابری گوگل بروید و روی دکمه فعالسازی پوسته ابری در گوشه سمت راست بالای کنسول کلیک کنید:
سپس مراحل زیر را در بخش حساب بدون صورتحساب دنبال کنید:
مراحل ادامه استفاده از دادهها بدون نیاز به حساب صورتحساب:
- میتوانید فایلهای csv دادهها (BigQuery Data) را از لینک مخزن گیتهاب بالا دریافت کنید.
- ابتدا، با اجرای دستور زیر از ترمینال Cloud Shell، مجموعه داده BigQuery را ایجاد کنید:
bq mk --location us-central1 --dataset froyo_data
- در مرحله بعد، با اجرای دستورات زیر به صورت یک به یک، 8 فایل داده (فایلهای csv) را از مخزن گیتهاب در دایرکتوری کاری خود دانلود کنید:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- دستورات زیر را یکی یکی اجرا کنید تا این جداول با دادههای موجود در مجموعه داده جدید ایجاد شوند.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
حالا که دادهها را در BigQuery داریم، به مراحل بعدی میرویم.
۴. راهاندازی کلاستر، نمونه و شبکه AlloyDB
یک برنامهی تحت وب برای شروع سریع وجود دارد که به شما در راهاندازی AlloyDB Cluster، Instance و سایر وابستگیها کمک میکند. میتوانید مراحل ۲ تا ۴ این آزمایش را دنبال کنید تا آن را تنها با یک کلیک راهاندازی کنید:
https://codelabs.developers.google.com/quick-alloydb-setup
پس از ایجاد کلاستر، به صفحه نمای کلی کلاستر بروید و جزئیات حساب سرویس را از آنجا کپی کنید.
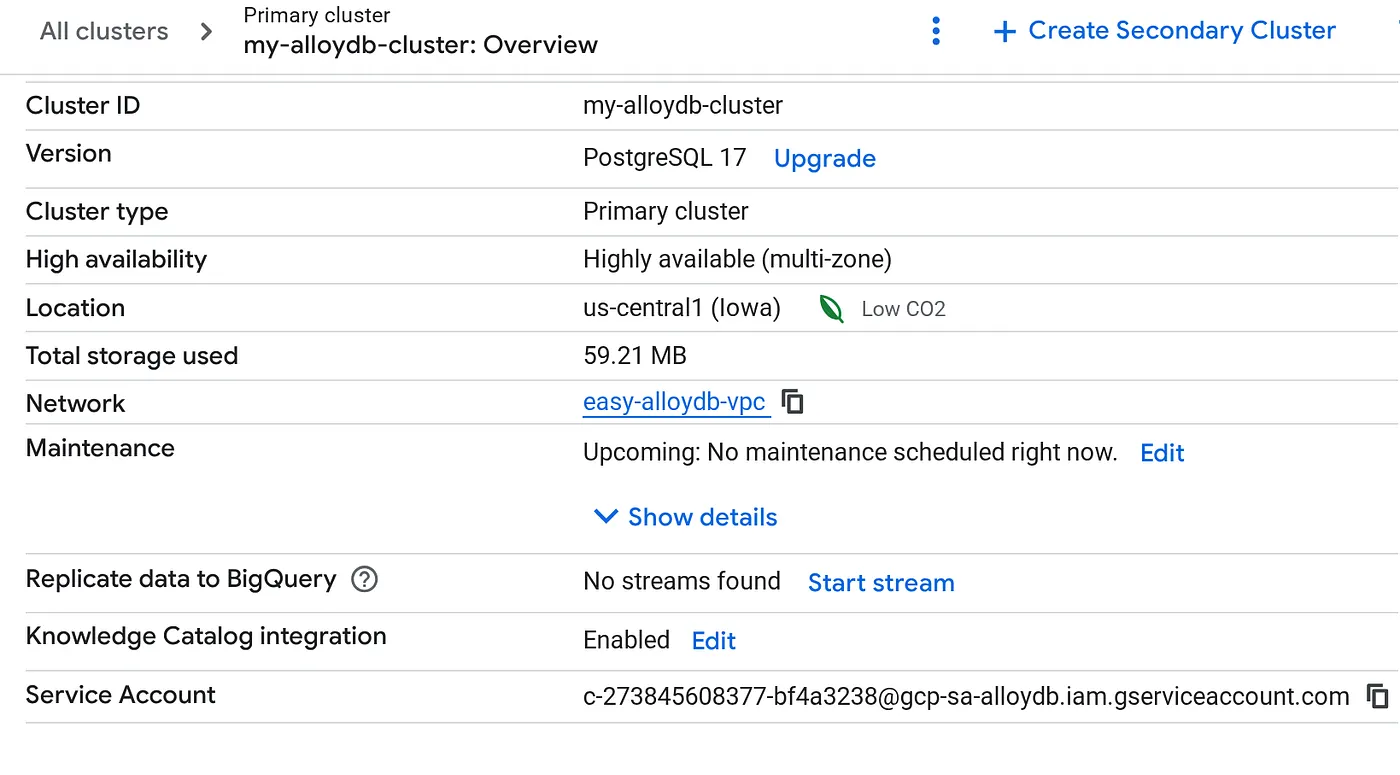
۵. تنظیمات مجوزها
مجوزهای BigQuery را به این حساب سرویس اعطا کنید
- به IAM & Admin > IAM بروید.
- روی اعطای دسترسی کلیک کنید.
- آدرس حساب سرویس AlloyDB را در فیلد New principals جایگذاری کنید.
- نقشهای زیر را اختصاص دهید:
- نمایشگر دادههای BigQuery (roles/bigquery.dataViewer): امکان خواندن دادهها را فراهم میکند.
- کاربر BigQuery (roles/bigquery.user): اجازه اجرای کوئریها را میدهد.
- (اختیاری اما توصیه میشود) کاربر جلسه خواندن BigQuery (roles/bigquery.readSessionUser): خواندن مجموعه دادههای بزرگ را از طریق API خواندن ذخیرهسازی بهینه میکند.
۶. به AlloyDB متصل شوید و افزونه BigQuery را فعال کنید
اکنون به نمونه جدید AlloyDB خود متصل میشویم تا افزونه Federation را پیکربندی کنیم. برای این کار از AlloyDB Studio استفاده خواهیم کرد.
- از صفحه نمای کلی کلاستر (کنسول AlloyDB)، روی نمونه اصلی خود روی « ویرایش اولیه » کلیک کنید و به پایین صفحه بروید تا به « گزینههای پیکربندی پیشرفته » برسید.
- به بخش « پرچمها » بروید و دو پرچم را مطابق شکل زیر روی « روشن » فعال کنید:
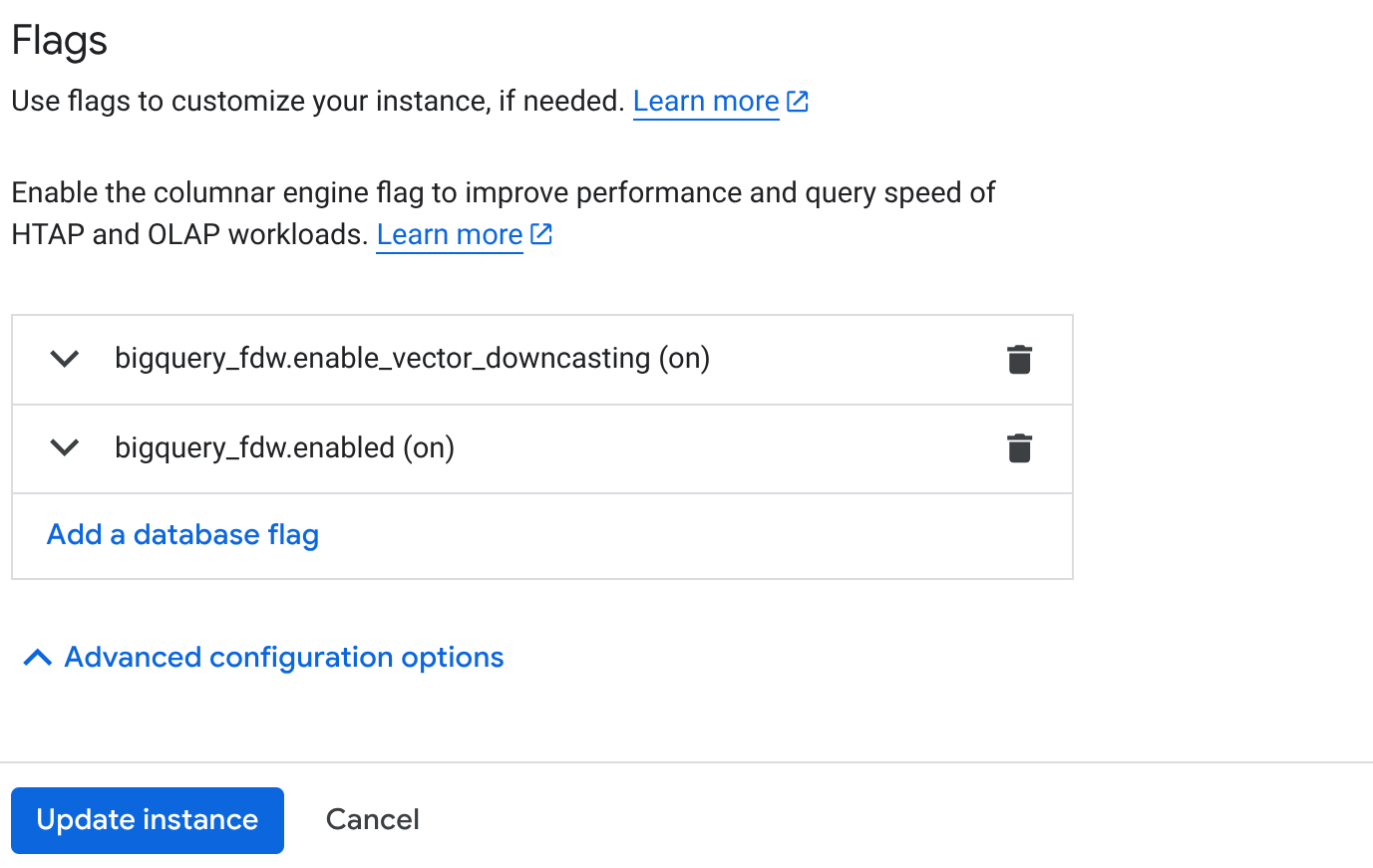 ۳. روی دکمهی **بهروزرسانی نمونه** کلیک کنید. تکمیل بهروزرسانی چند دقیقه طول میکشد. ۴. از صفحهی نمای کلی کلاستر (کنسول AlloyDB)، روی AlloyDB Studio کلیک کنید.
۳. روی دکمهی **بهروزرسانی نمونه** کلیک کنید. تکمیل بهروزرسانی چند دقیقه طول میکشد. ۴. از صفحهی نمای کلی کلاستر (کنسول AlloyDB)، روی AlloyDB Studio کلیک کنید. 
- با پایگاه داده، نام کاربری و رمز عبوری که در مرحله راهاندازی سریع AlloyDB پیکربندی کردهاید، ارتباط برقرار کنید.
- پس از اتصال، در تب Query Editor در سمت راست، دستورات زیر را وارد کرده و یکی یکی اجرا کنید:
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- پس از انجام موفقیتآمیز، به پنل اکسپلورر در سمت چپ بروید و به پایین اسکرول کنید تا به جداول BigQuery برسید:
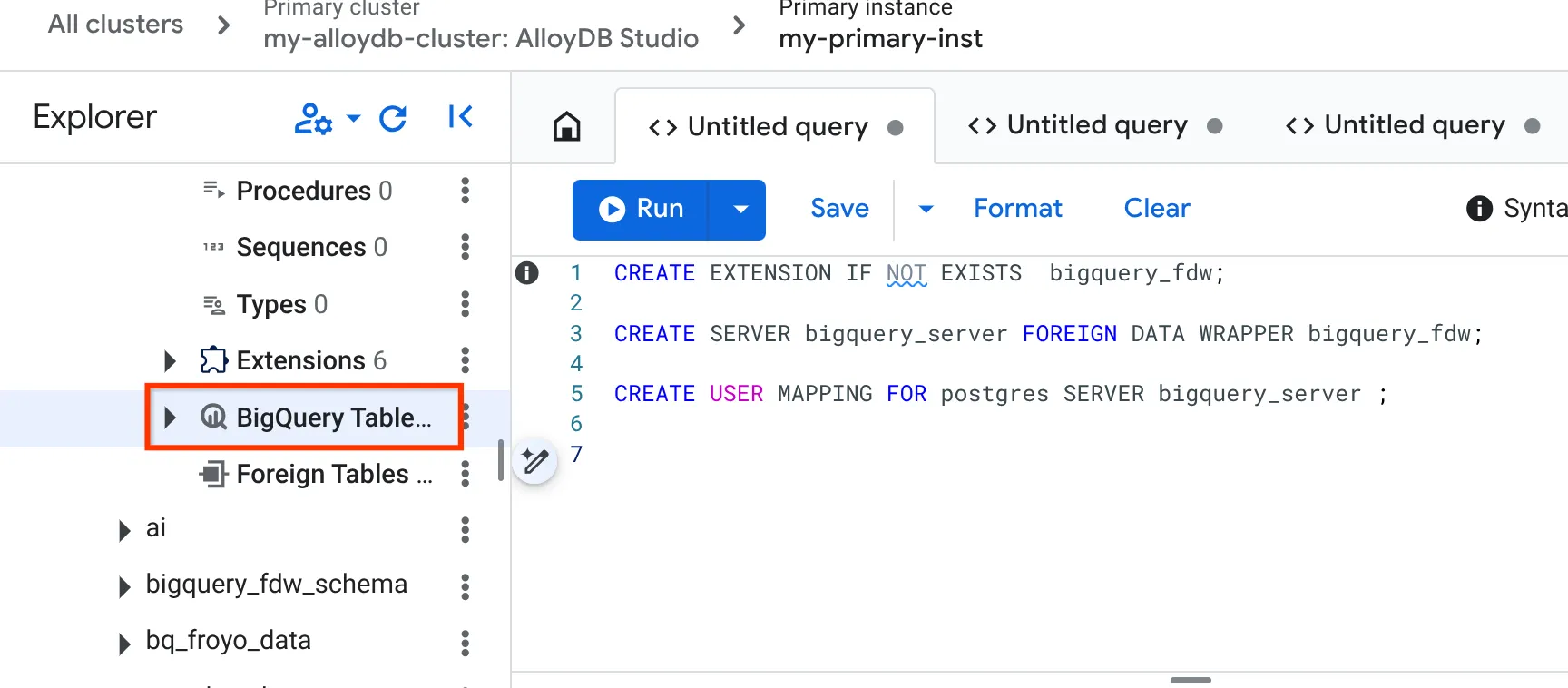
- روی سه نقطه کلیک کنید و روی « اتصال جدول BigQuery » کلیک کنید.
- در پنجره باز شده Connect BigQuery Table، شناسه پروژه (project_id) و نام مجموعه داده BigQuery (که در بخش 1 ایجاد شد) را که میخواهید دادههای موجود در پایگاه داده AlloyDB خود را از آن پرسوجو کنید، انتخاب کنید.
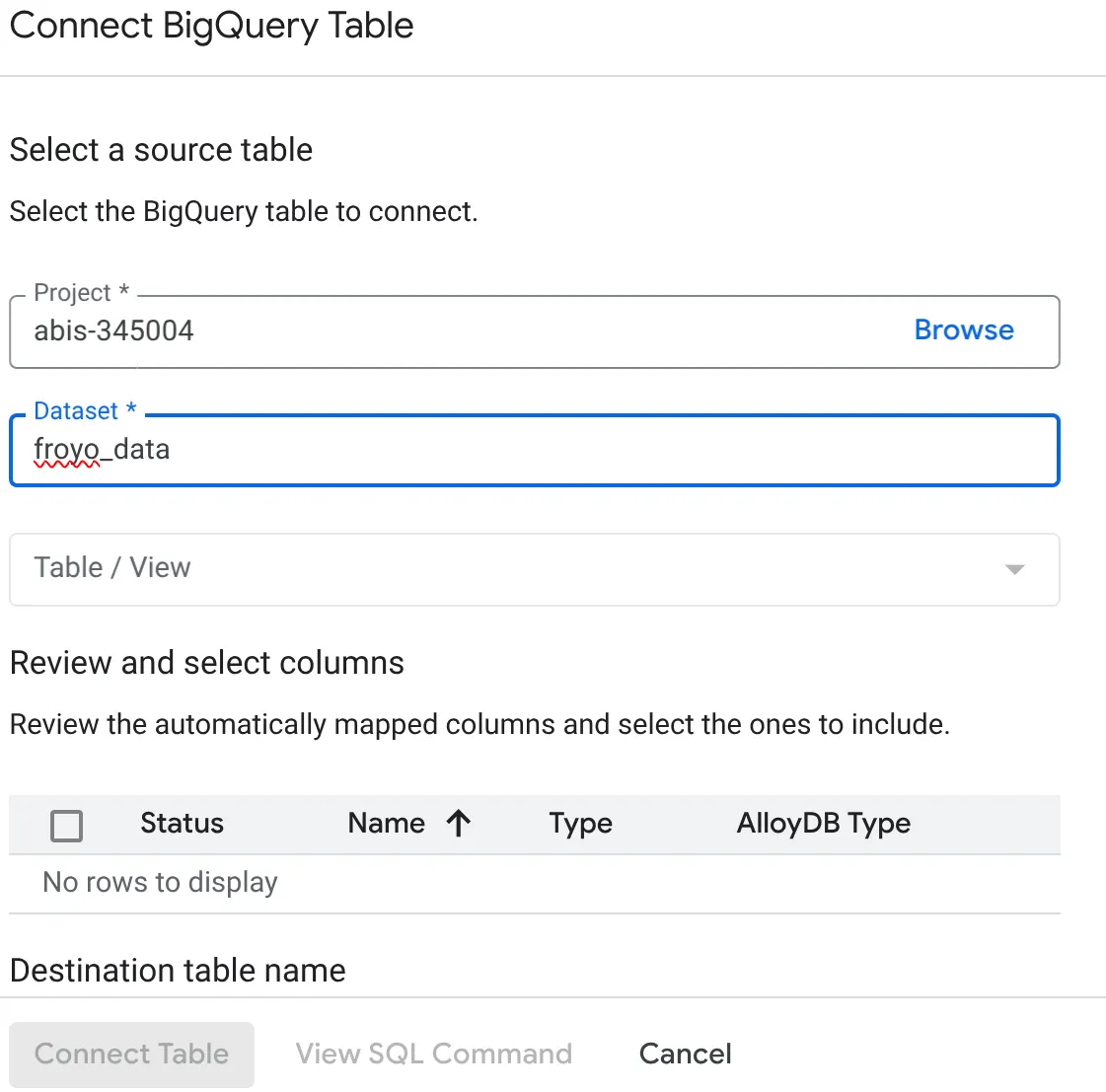
- هر جدول را یکی یکی انتخاب کنید تا تمام دادههای شما به AlloyDB متصل شوند. به این ترتیب انواع ستونها را اعتبارسنجی میکنیم تا مطمئن شویم که در AlloyDB پشتیبانی میشوند.
اگر میخواهید همین کار را با SQL به جای روش اشاره و کلیک انجام دهید:
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
جادو!!!
ما به تازگی «جداول خارجی» را در AlloyDB ایجاد کردهایم. این جداول مانند جداول معمولی PostgreSQL به نظر میرسند و عمل میکنند، اما هیچ دادهای را ذخیره نمیکنند. وقتی از آنها پرسوجو میکنید، AlloyDB فوراً پرسوجو را به BigQuery ارسال میکند، نتایج را دریافت میکند و آنها را به شما برمیگرداند.
۷. تست کردن فدراسیون در AlloyDB
بیایید بررسی کنیم که آیا میتوانیم مستقیماً از پایگاه داده تراکنشی PostgreSQL خود، به مجموعه دادههای عظیم و تحلیلی BigQuery خود کوئری ارسال کنیم یا خیر.
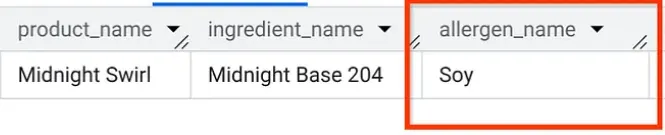
هنوز در استودیوی AlloyDB خود هستید، بیایید یک کوئری اجرا کنیم تا بفهمیم چه آلرژنهایی در "Midnight Swirl" وجود دارند (همان سوالی که در بخش 1 پرسیدیم، اما این بار از AlloyDB پرسیده شده است!):
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
بوم. شما باید دقیقاً همان نتایجی را که در BigQuery مشاهده کردید، ببینید.
۸. تمیز کردن
پس از انجام این آزمایش، فراموش نکنید که کلاستر و نمونه AlloyDB را حذف کنید.
باید کلاستر را به همراه نمونه(های) آن پاکسازی کند.
۹. تبریک بابت لایه داده یکپارچه (Unified Data Layer)
به کاری که تازه انجام دادیم فکر کنید:
- برنامه تراکنشی ما (که روی AlloyDB اجرا میشود) میتواند جلسات کاربری سریع و همزمان را مدیریت کند.
- وقتی به دادههای تحلیلی سنگین یا پیشینهی تاریخی (مانند جزئیات تأمینکنندگان یا نگاشتهای پیچیدهی مواد تشکیلدهنده) نیاز دارد، از BigQuery froyo_dataschema پرسوجو میکند.
- بدون ETL. بدون خرابی خطوط لوله داده. بدون پایگاههای داده ناهمگام. ما یک بار (در BQ) ذخیره میکنیم و هر جا که نیاز داشته باشیم، محاسبه میکنیم.
حالا که پایه دادههای ما - چه تحلیلی و چه تراکنشی - محکم و به هم پیوسته است، برای بخش سرگرمکننده آمادهایم.
در بخش سوم ، ما یک برنامه چندعاملی خواهیم ساخت که بر روی این معماری قرار میگیرد تا عملیات تجاری Froyo را اجرا کند!