
1. Présentation
Nous connaissons tous les difficultés liées aux "données obscures". Il s'agit des fichiers PDF, des images et des fichiers texte qui se trouvent dans des buckets de stockage cloud, complètement invisibles pour vos requêtes SQL et vos tableaux de bord BI. Auparavant, pour accéder à ces données, il fallait des pipelines OCR complexes, une saisie manuelle des données ou des scripts personnalisés fragiles.
Plus maintenant.
Dans cet atelier, je vais vous montrer comment convertir 400 fichiers PDF non structurés (contenant du texte, des tableaux et des images) en tables BigQuery clairement structurées, avec des relations automatiquement déduites entre elles. Nous allons le faire en quelques minutes à l'aide de BigQuery Knowledge Catalog et Dataplex.
Ce que vous allez faire
Pour illustrer cela, prenons l'exemple d'une franchise de yaourts glacés en pleine croissance.
Imaginez que vous gérez les données de cette entreprise de yaourts glacés. Vous avez des centaines de recettes et de fiches techniques de fournisseurs, toutes enregistrées au format PDF. Les dirigeants souhaitent lancer un agent IA pour aider les responsables de magasin et les clients à obtenir des informations sur les produits.
Voici un scénario cauchemardesque : un client vous demande : "Je suis très intéressé par votre yaourt glacé Midnight Swirl. Contient-il des allergènes ?"
Pour répondre à cette question, votre système devrait normalement :
- Trouvez le PDF de la recette "Midnight Swirl".
- Lisez les ingrédients (par exemple, "Poudre de cacao", "Base laitière", "Émulsifiant X").
- Recherchez dans des dizaines de PDF de fournisseurs pour trouver les fiches techniques de ces ingrédients spécifiques.
- Consultez les fiches des fournisseurs pour identifier les allergènes cachés liés à ces ingrédients.
Essayer de créer un agent d'IA qui effectue cette tâche à la volée en lisant 400 PDF bruts au moment de l'exécution est lent, coûteux et sujet aux hallucinations. Au lieu de cela, nous allons utiliser l'inférence sémantique pour extraire toutes ces informations dans une base de données relationnelle. Notre futur agent d'IA sera ainsi extrêmement rapide et 100% ancré dans des données SQL factuelles.
Commençons à créer !
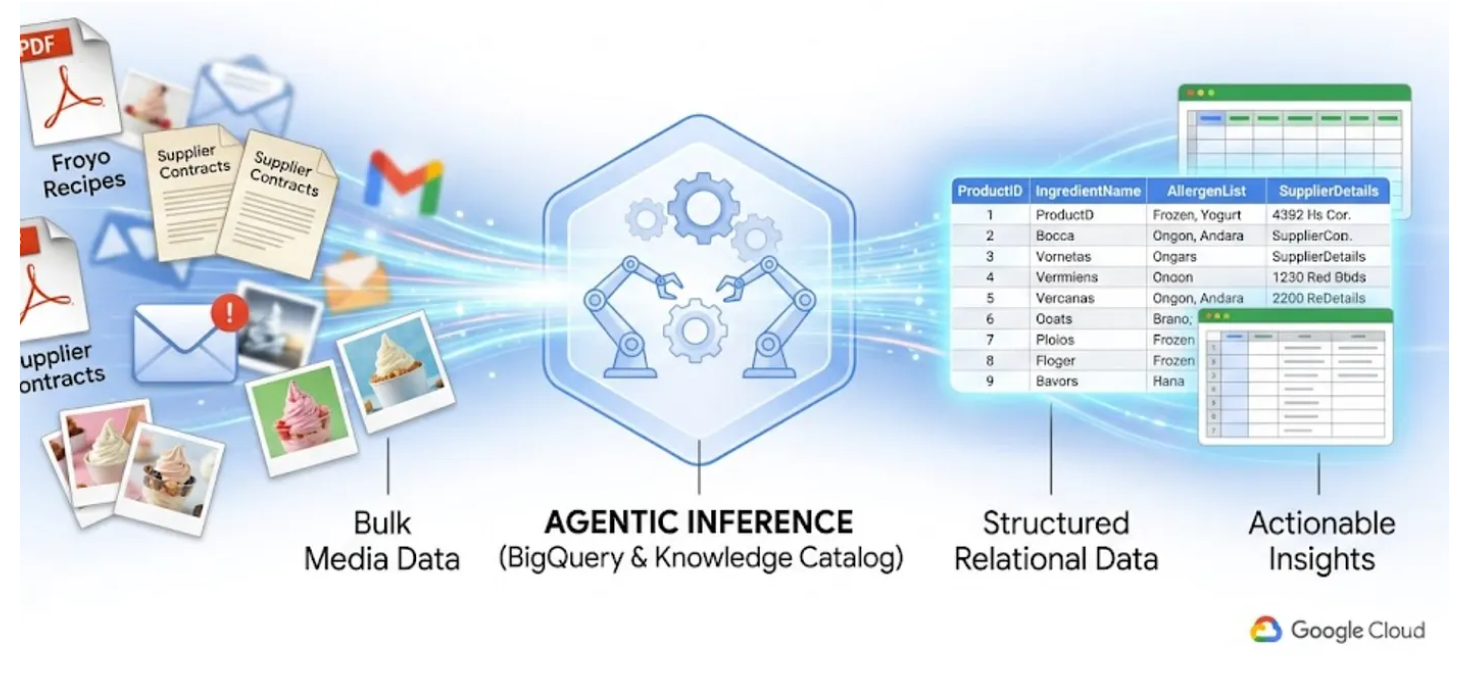
Points abordés
- Configurer un bucket Cloud Storage pour les fichiers sources (PDF)
- Configurer et exécuter un job Datascan et une inférence sémantique dans Knowledge Catalog pour extraire des données à partir de PDF sources, inférer sémantiquement les connexions et le contexte, et les stocker dans BigQuery
- Utiliser les agents BigQuery pour discuter avec l'ensemble de données nouvellement créé
Conditions requises
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si vous souhaitez vous authentifier
gcloud auth login
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API requises : exécutez cette commande pour activer toutes les API requises :
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
Problèmes et dépannage
Syndrome du projet fantôme | Vous avez exécuté |
Barricade de facturation | Vous avez activé le projet, mais vous avez oublié le compte de facturation. AlloyDB est un moteur hautes performances. Il ne démarrera pas si le "réservoir" (la facturation) est vide. |
Latence de propagation de l'API | Vous avez cliqué sur "Activer les API", mais la ligne de commande indique toujours |
Quags de quota | Si vous utilisez un tout nouveau compte d'essai, vous pouvez atteindre un quota régional pour les instances AlloyDB. Si |
Agent du service"Caché" | Il arrive que l'agent de service AlloyDB ne reçoive pas automatiquement le rôle |
3. Configurer un bucket Google Cloud Storage
Dans cette section, vous allez créer une structure organisationnelle dans BigQuery pour stocker les données sur les recettes et les fournisseurs de yaourts glacés, en particulier les informations sur les produits. Il établit également une connexion aux ressources cloud, qui sert de "pont" sécurisé permettant à BigQuery de lire les fichiers provenant de sources externes telles que Cloud Storage.
Avant de commencer :
Ce dépôt contient les recettes et les fichiers PDF des fournisseurs que nous utiliserons dans ce projet. Assurez-vous de télécharger ces fichiers. Pour télécharger les fichiers, procédez comme suit.
Dans Cloud Shell, exécutez la commande suivante :
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
Accédez au dossier que vous venez de créer :
cd next-26-keynotes
Extrayez le dossier data-cloud-demo.
git sparse-checkout set genkey/data-cloud-demo
Une fois le paiement effectué, accédez au dossier data-cloud-demo et extrayez les fichiers ZIP pour accéder aux ressources de l'atelier de programmation.
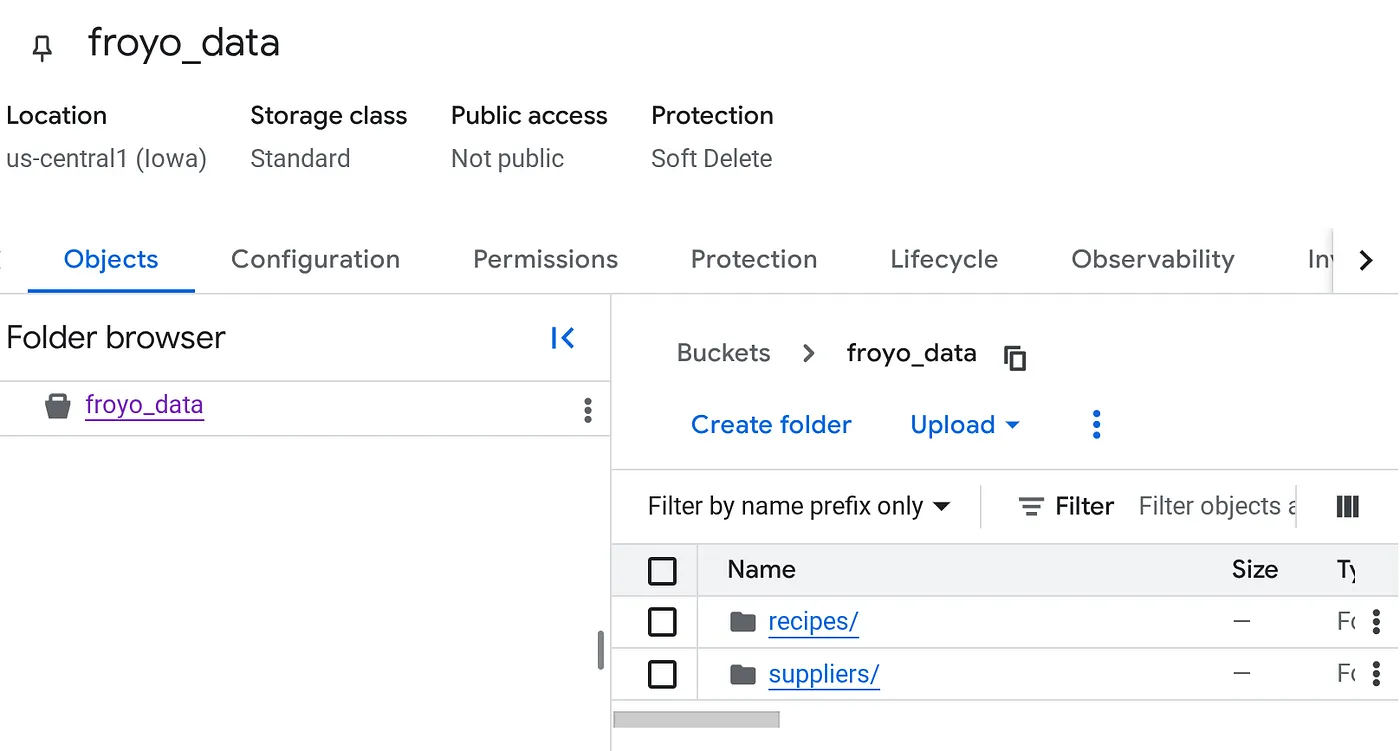
Créer un bucket et importer les fichiers PDF Froyo (recettes et fournisseurs)
- Dans la console Google Cloud, accédez à la page Buckets Cloud Storage.
- Cliquez sur Créer.
- Sur la page Créer un bucket, saisissez les informations concernant votre bucket. Après chacune des étapes suivantes, cliquez sur "Continuer" pour passer à la suivante :
- Dans la section Premiers pas, saisissez le nom du bucket. Exemple : froyo_data
- Dans la section Choisissez où stocker vos données, sélectionnez "Région", puis saisissez votre région. us-central1
- Dans la section Choisir comment contrôler l'accès aux objets, décochez la case "Appliquer la protection contre l'accès public sur ce bucket".
- Cliquez sur Créer.
- Dans la liste des buckets, cliquez sur celui que vous avez créé.
- Dans l'onglet Objets du bucket, cliquez sur "Importer", puis sur "Importer des dossiers".
- Sélectionnez le dossier recipes que vous avez extrait dans la section "Avant de commencer" de cet atelier de programmation.
- Cliquez sur Envoyer.
- Répétez la procédure d'importation pour le dossier suppliers.
Une fois le bucket importé, sa structure doit se présenter comme suit (quel que soit son nom) :
4. Configurer la connexion BigQuery
Créez une connexion aux ressources Cloud. Cela génère un compte de service unique qui sert de "carte d'identité" à BigQuery pour accéder aux fichiers externes.
- Accédez à la page BigQuery.
- Dans le volet de gauche, cliquez sur "Explorateur". Si le volet de gauche ne s'affiche pas, cliquez sur "Développer le volet de gauche" pour l'ouvrir.
- Dans le volet "Explorateur", développez le nom de votre projet, puis cliquez sur "Connexions".
- Sur la page "Connexions", cliquez sur "Créer une connexion".
- Pour le type de connexion, sélectionnez "Modèles distants Vertex AI, fonctions distantes, BigLake et Spanner (Ressource Cloud)".
- Dans le champ "ID de connexion", saisissez le nom de l'ID de connexion :
- bq-connection. Veillez à noter cet ID, car vous en aurez besoin lorsque vous configurerez l'analyse des données plus loin dans cet atelier de programmation.
- Définissez le type d'emplacement sur "Région", puis sélectionnez une région. Par exemple, us-central1. La connexion doit se trouver dans la même région que vos autres ressources, comme les ensembles de données.
- Cliquez sur "Créer une connexion".
- Cliquez sur "Accéder à la connexion".
- Dans le volet "Informations de connexion", copiez l'ID du compte de service à utiliser à l'étape suivante. Le compte de service ressemble à bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
5. Configurer les autorisations
- Accorder les autorisations nécessaires à la connexion BigQuery pour accéder aux objets Cloud Storage et au Knowledge Catalog
Accédez à la page "IAM et administration", puis, dans la section "Afficher par compte principal", cliquez sur le bouton "Accorder l'accès". Ajoutez un compte principal en collant le compte de service que vous avez copié à la dernière étape. Dans la section "Rôles", ajoutez les noms des rôles suivants un par un, puis enregistrez :
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- Accorder au compte de service Dataplex les autorisations d'accès au bucket Cloud Storage
Accédez à la page IAM et administration, puis, dans la section Afficher par compte principal, cliquez sur le bouton Accorder l'accès et ajoutez un compte principal en saisissant le mot dataplex dans la barre de texte "Nouveau compte principal". Dans la liste qui s'affiche automatiquement, sélectionnez le principal du compte de service Dataplex qui ressemble à ceci : (utilisez le numéro de projet et non l'ID de projet dans l'adresse e-mail du compte de service ci-dessous).
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Si, pour une raison quelconque, le compte de service ci-dessus pour votre numéro de projet n'est pas reconnu, il se peut que le service Dataplex n'ait pas encore été initialisé pour le projet. Accédez au terminal Cloud Shell et essayez d'activer l'API (si ce n'est pas déjà fait à l'étape Avant de commencer) en exécutant la commande suivante : gcloud services enable dataplex.googleapis.com.
Si le compte de service pour Dataplex n'est toujours pas reconnu, forcez la création d'un job d'analyse Dataplex de test sur la page Curation des métadonnées, puis saisissez les informations sur la page de création du job Discover :
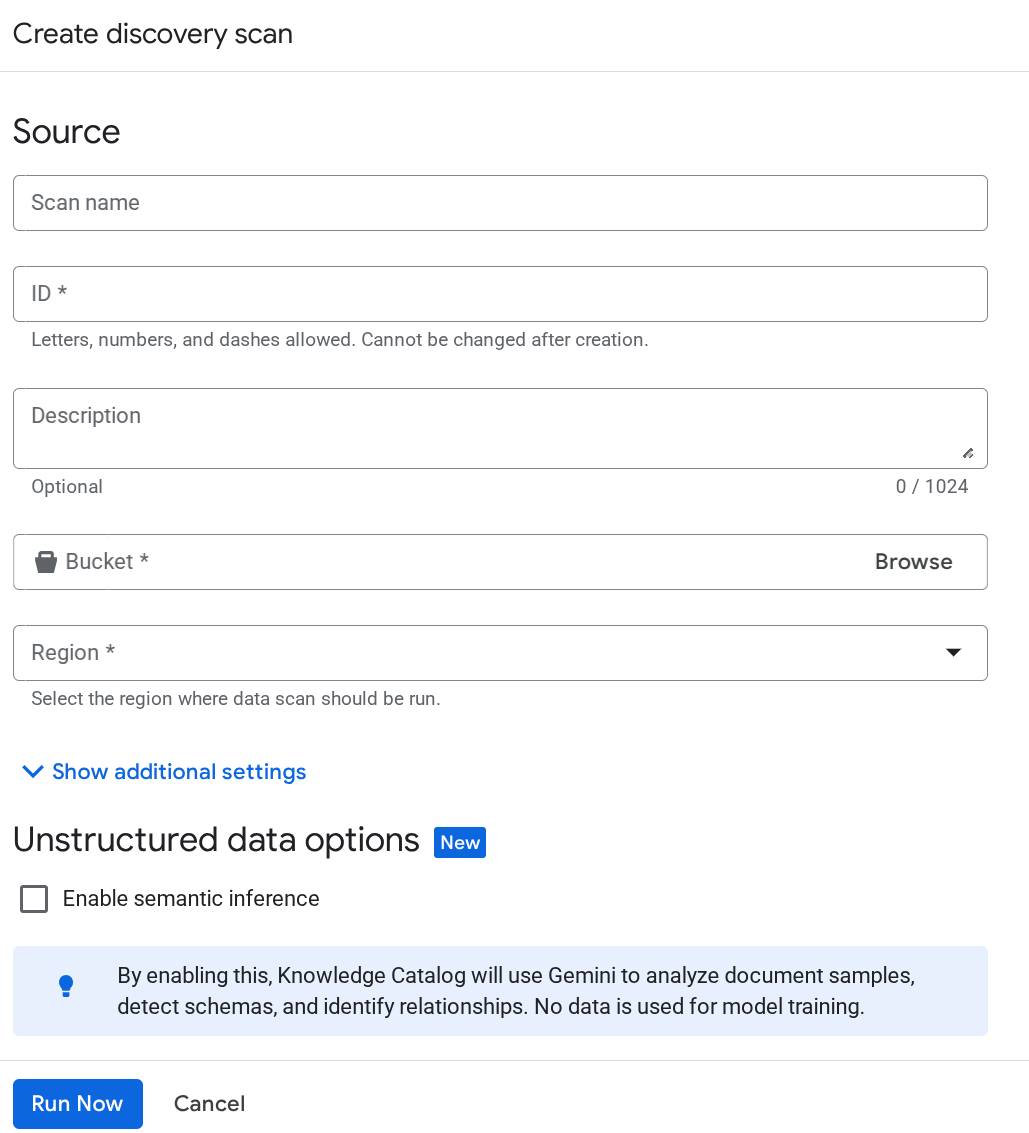
Cliquez sur Exécuter maintenant. La tâche échouera, mais cela garantira que l'ID du compte de service sera initialisé pour votre service Dataplex.
Revenez à la page IAM et administration, puis, dans la section Afficher par compte principal, cliquez sur le bouton Accorder l'accès, puis sur "Ajouter un compte principal". Collez le compte de service :
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Attribuez ensuite les rôles suivants à ce compte de service :
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. Configurer Knowledge Catalog
Créez un Knowledge Catalog pour unifier les données non structurées et automatiser la découverte des fichiers non structurés (comme les recettes et les fournisseurs au format PDF).
Créez le job DataScan à partir de la console :
- Accédez à la page Curation des métadonnées.
- Cliquez sur "Créer" et saisissez les informations correspondant à votre configuration :
Important : N'oubliez pas de cocher la case "Activer l'inférence sémantique".
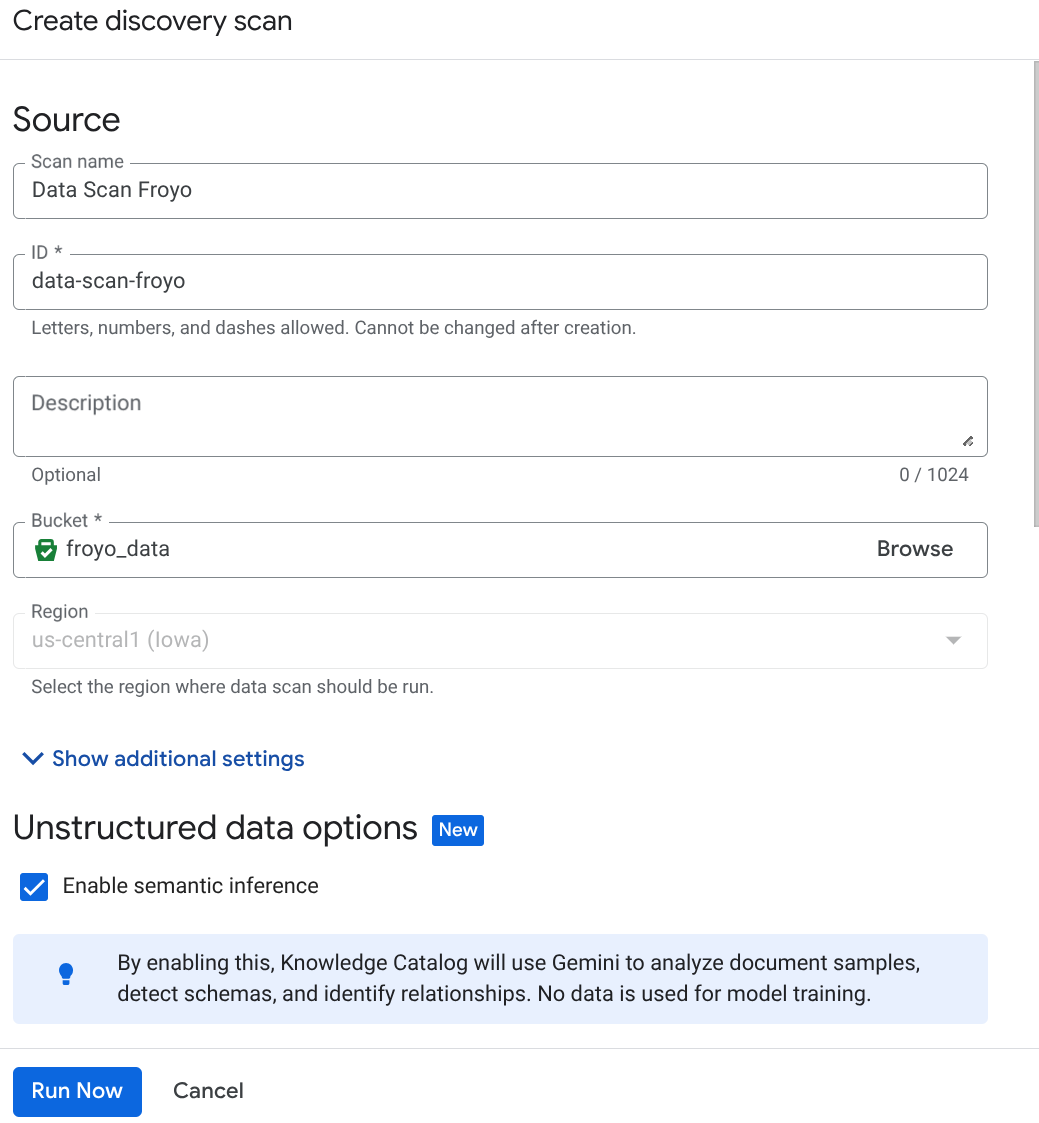
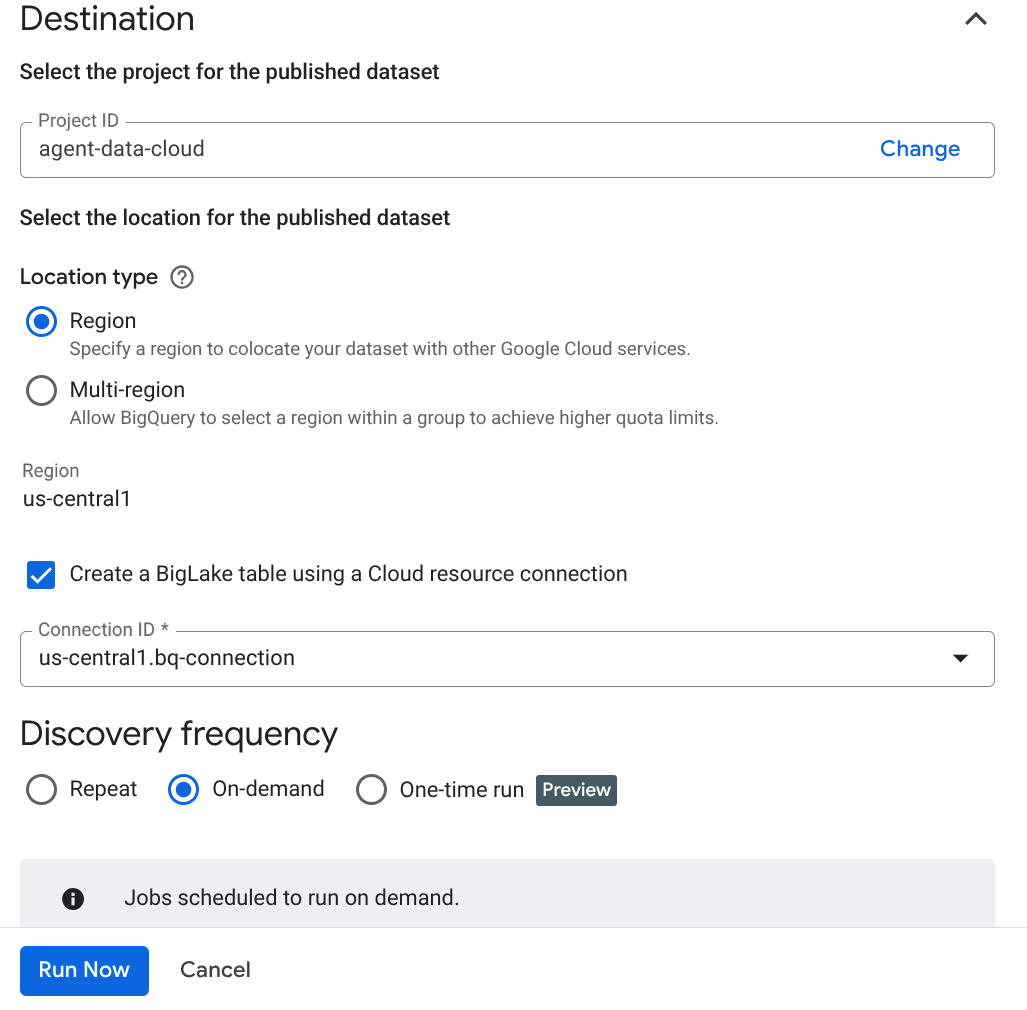
- Cliquez sur "Exécuter maintenant".
- L'analyse prendra un certain temps. Une fois le job terminé, vérifiez si l'ensemble de données publié est présent. Pour vérifier l'état du job, accédez à la page Curation des métadonnées, puis, dans l'onglet "Découverte Cloud Storage", cliquez sur le nom des analyses de découverte de la dernière exécution. L'ensemble de données publié devrait s'afficher comme suit :
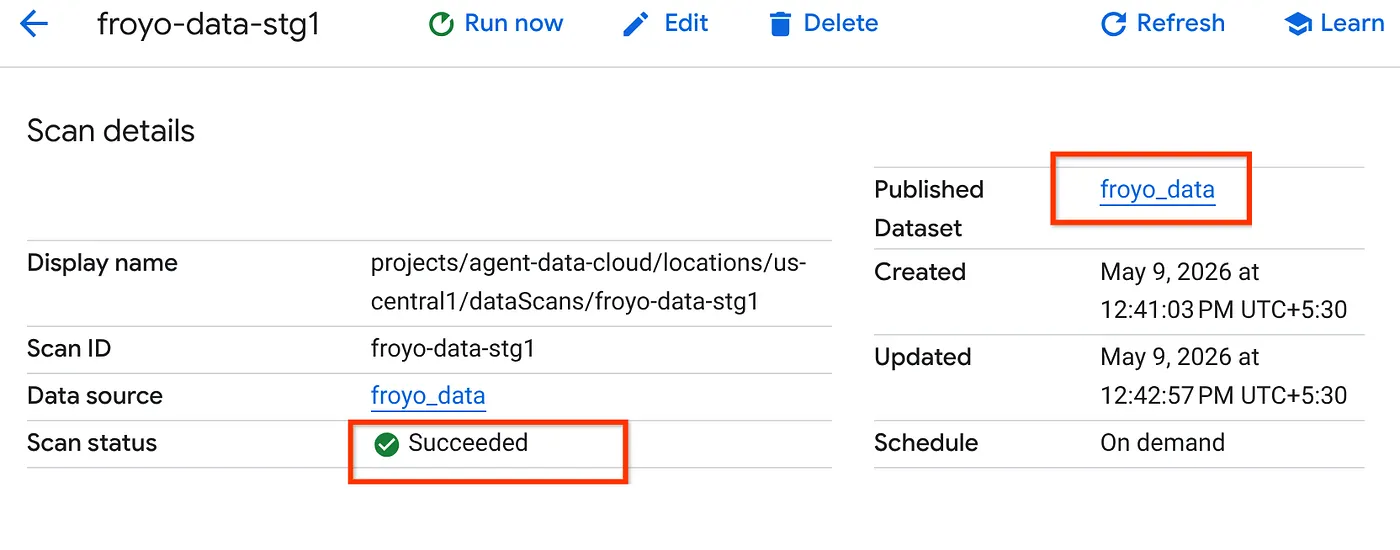
Remarque : Si vous rencontrez des erreurs lors de l'étape d'analyse, patientez un peu, puis réessayez (il faut quelques minutes pour créer le job et terminer l'exécution).
- Pour afficher la table dans BigQuery, cliquez sur l'ensemble de données froyo_data et accédez-y. Cliquez sur l'ID de la table dans BigQuery, puis exécutez la requête ci-dessous dans l'onglet "Éditeur de requête" :
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
Le résultat est 400 (si ce n'est pas le cas, vous pouvez revenir en arrière et exécuter à nouveau le job Datascan).
7. Extraction sémantique des données
Super ! Extrayons maintenant les inférences pour ces objets non structurés à l'aide de Knowledge Catalog.
Nous allons utiliser la fonctionnalité Insights pour générer des instructions SQL permettant d'extraire des données structurées de la table non structurée.
- Dans la console Google Cloud, accédez à la page Recherche Knowledge Catalog.
- Recherchez la table de l'ensemble de données pour laquelle vous souhaitez afficher des insights. Dans la barre de recherche, saisissez le nom de l'ensemble de données / de la table de l'étape précédente ("froyo_data"), puis appuyez sur Entrée.
- Dans la liste des résultats, cliquez sur l'entrée TABLE (et non sur celle de l'ensemble de données).
- L'onglet INSIGHTS doit s'afficher. Cliquez dessus (si vous devez activer une API, suivez les instructions et activez-la).
Si vous avez activé des API à ce stade, vous devez réexécuter le job d'analyse.
- Dans l'onglet "INSIGHTS" (Insights), vous verrez le menu déroulant du bouton "EXTRACT" (Extraire). Cliquez dessus, puis sélectionnez l'option "Extraire avec SQL".
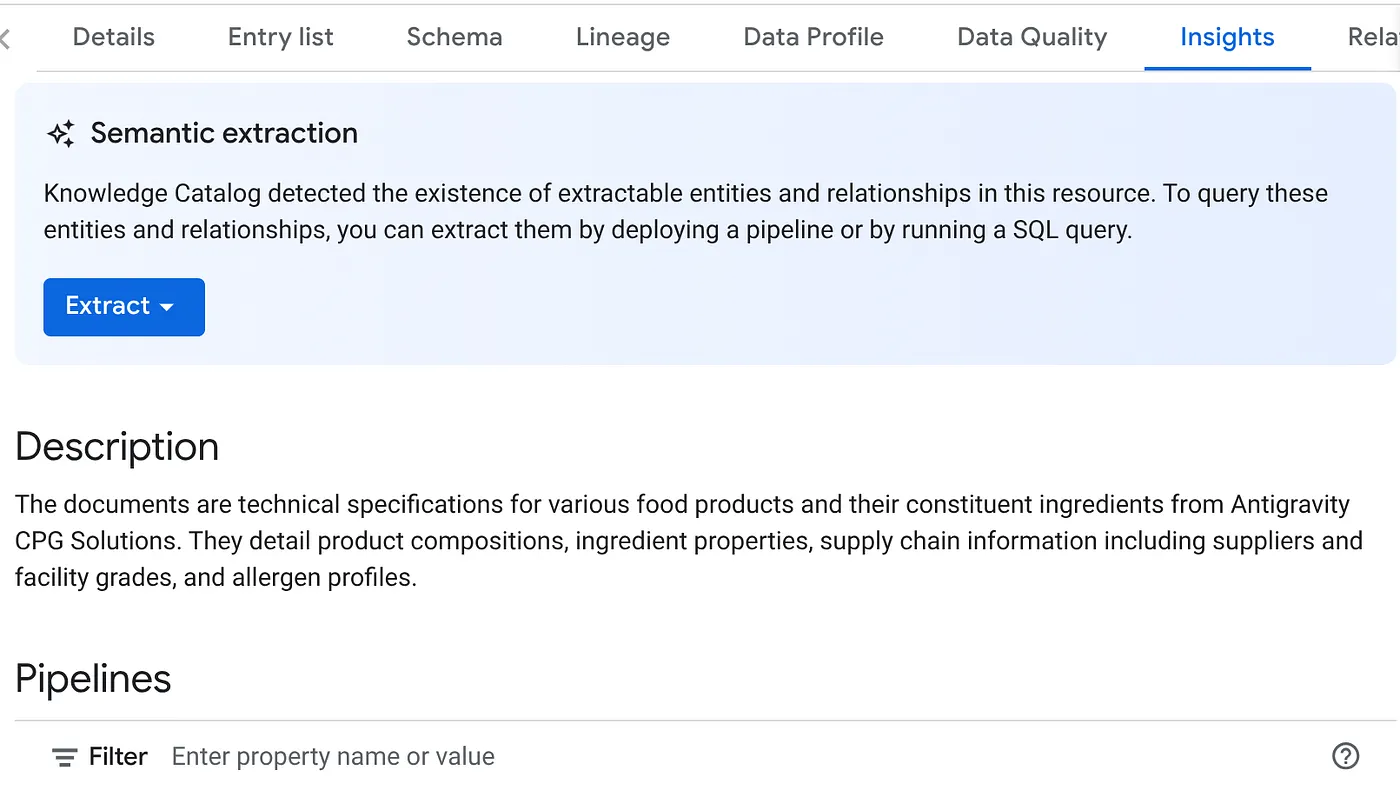
Dans la boîte de dialogue Extraire avec SQL, définissez l'ensemble de données de DESTINATION comme celui qui s'affiche dans le résultat du job Datascan. Commencez à saisir son nom. Il devrait apparaître dans la saisie semi-automatique. Cliquez sur le bouton Extraire. Vous pouvez également créer un ensemble de données à ce stade et l'extraire.
L'éditeur de requête BigQuery devrait s'ouvrir sur un onglet contenant le code SQL extrait de l'inférence de l'analyse des données.
8. Validation SQL et création de schéma
Si la requête générée semble correcte et pertinente sémantiquement par rapport à vos données non structurées, exécutez-la en cliquant sur le bouton "Exécuter" dans l'éditeur de requêtes. La création du schéma requis pour le stockage structuré de vos contenus multimédias non structurés prendra quelques minutes.
Une fois l'opération terminée, vous devriez pouvoir vérifier le schéma en développant l'ensemble de données dans le volet de l'explorateur de BigQuery Studio, comme indiqué ci-dessous :
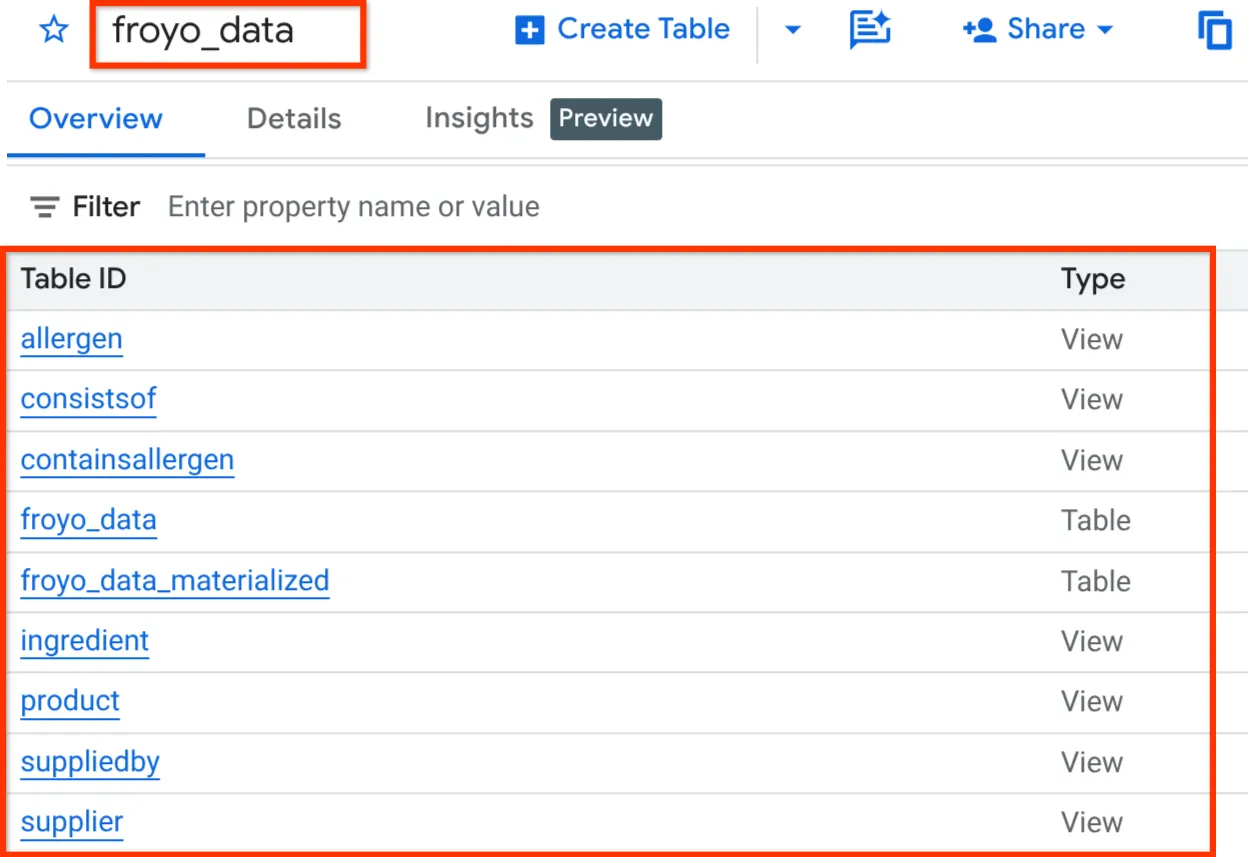
Très bien ! C'était tellement agréable de faire toutes ces choses liées à la base de données très rapidement. Il est maintenant temps de passer au test ultime !
Voici comment continuer à accéder aux données sans compte de facturation :
- Vous pouvez obtenir les fichiers CSV (données BigQuery) à partir du dépôt GitHub dont le lien est indiqué ci-dessus.
- Commencez par créer l'ensemble de données BigQuery en exécutant la commande ci-dessous à partir du terminal Cloud Shell :
bq mk --location us-central1 --dataset froyo_data
- Ensuite, téléchargez les huit fichiers de données (fichiers CSV) du dépôt GitHub dans votre répertoire de travail en exécutant les commandes suivantes une par une :
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Exécutez les commandes suivantes une par une pour créer ces tables avec les données de l'ensemble de données que vous venez de créer.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Une fois l'ensemble de données, les tables et les données créés, vous pouvez tester et découvrir les données dont nous venons de parler.
9. Le test ultime !!!
Imaginons que je souhaite que mon agent réponde aux questions des utilisateurs avec des informations réelles, complètes et bien orchestrées, ancrées dans des faits. Je vais poser une question à laquelle l'agent ne pourra répondre qu'en se référant à plusieurs fichiers multimédias et références de ma source.
Voici ma question :
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
Désormais, une recherche générique ou une recherche LLM indiquera "Aucun ingrédient". Nous avons toutefois créé une inférence sémantique complète qui convertit tous nos contenus multimédias non structurés en données structurées. Voici une requête SQL simple qui récupère ces informations :
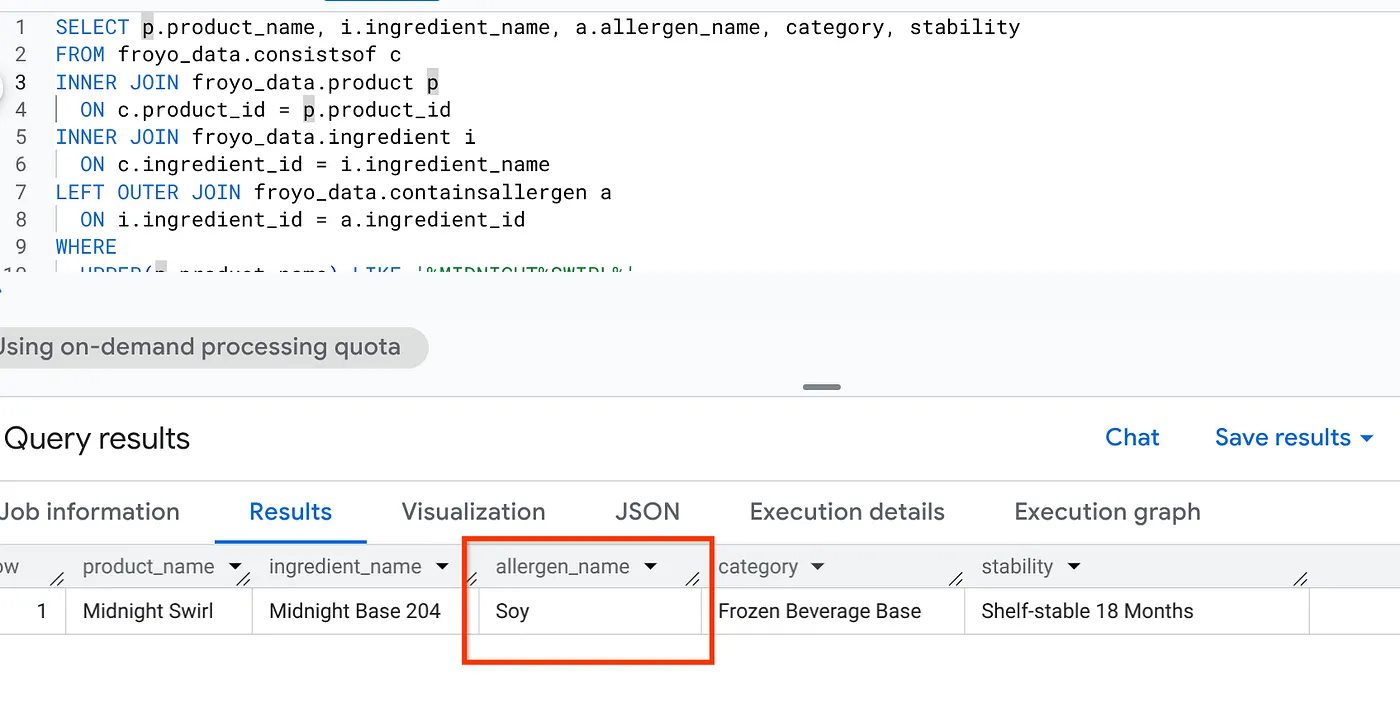
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
Excellent ! Examinez le résultat :
10. Effectuer un nettoyage
Une fois cet atelier terminé, n'oubliez pas de supprimer le job d'analyse et les tables BigQuery qu'il a créées.
Accédez à https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery. Sélectionnez le job que vous souhaitez supprimer en cliquant sur les trois points verticaux à côté, puis sur SUPPRIMER.
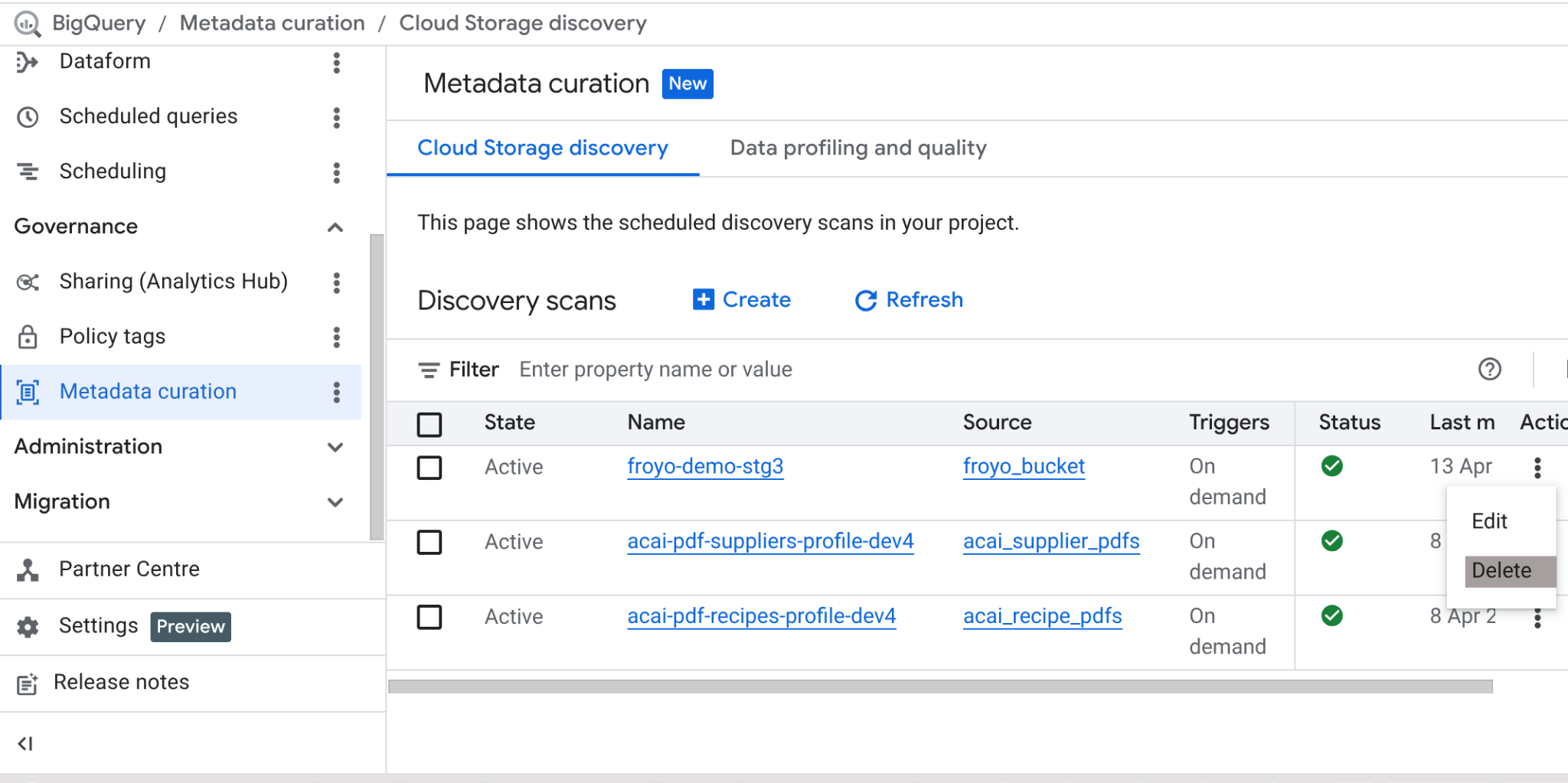
Cela devrait libérer de l'espace.
11. Félicitations
Notre implémentation a réussi à identifier l'allergène caché. Plus de dark data, les amis !!! Dans la partie 2, nous fédérerons ces données BigQuery dans un système transactionnel avec AlloyDB pour unifier les besoins en données de notre application agentique.