
1. Présentation
Dans la partie 1, nous avons transformé des PDF chaotiques et non structurés en tables propres, intelligentes et structurées dans BigQuery à l'aide de Knowledge Catalog et de DataScan. Nous disposons désormais d'un entrepôt de données robuste.
Pour rappel, dans l'atelier de la partie 1, nous avons pris l'exemple d'une franchise fictive de yaourts glacés et converti 400 de ses fichiers PDF non structurés (comprenant du texte, des tableaux et des images) en tables BigQuery clairement structurées, avec des relations automatiquement déduites entre elles à l'aide de BigQuery Knowledge Catalog et de Dataplex.
Objectifs de l'atelier
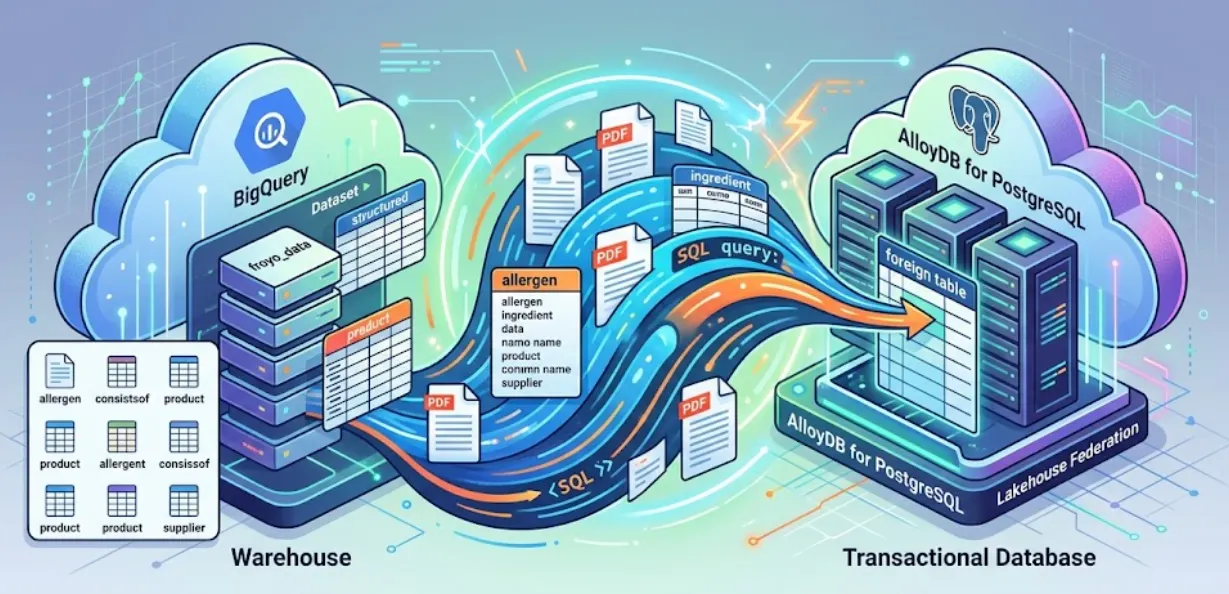
Dans cette session, nous allons configurer AlloyDB pour PostgreSQL et faire quelque chose de magique : fédérer nos données BigQuery directement dans AlloyDB. Cela signifie que notre application transactionnelle peut interroger les données de notre entrepôt en temps réel, sans avoir à les copier ni à les dupliquer.
En tant que développeur, vous devez vous poser la question suivante à ce stade :
"Si les données sont déjà dans BigQuery, pourquoi utiliser AlloyDB ? Pourquoi l'application n'exécute-t-elle pas simplement une instruction SELECT directement sur BigQuery ?"
Voici pourquoi :
Avec Lakehouse Federation, vous pouvez utiliser le moteur de requêtes d'AlloyDB pour alimenter les charges de travail transactionnelles et analytiques de votre application à partir de la même interface. Vous pouvez également matérialiser ou importer ces données sur AlloyDB pour un accès plus rapide dans vos applications, ce qui vous permet d'utiliser AlloyDB AI et le moteur de données en colonnes.
Vous pouvez utiliser AlloyDB comme base de données transactionnelle et disposer de grandes quantités de données dans BigQuery ou BigLake. Vos applications s'intègrent généralement indépendamment à ces deux systèmes pour accéder aux données de ces différents services Google Cloud. Lakehouse Federation pour AlloyDB vous permet d'utiliser la prise en charge des requêtes fédérées d'AlloyDB implémentée en tant que wrapper de données externes pour accéder aux données BigQuery et AlloyDB à l'aide d'une interface SQL dans AlloyDB.
Au lieu de créer un pipeline ETL fragile pour interroger les données BigQuery à partir d'AlloyDB, nous allons utiliser des requêtes fédérées. AlloyDB agira comme un point de terminaison unifié, accédant de manière transparente à BigQuery en cas de besoin.
Commençons à créer !
Points abordés
- Configurer un cluster, une instance et un réseau AlloyDB en un clic
- Configurer une extension pour préparer la fédération
- Configurer la fédération de BigQuery à AlloyDB
- Effectuer un test
Conditions requises
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée pour un projet.
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud. Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud reconnaît votre projet
gcloud config list project
- Si vous souhaitez vous authentifier
gcloud auth login
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API requises : exécutez cette commande pour activer toutes les API requises :
gcloud services enable alloydb.googleapis.com
Pièges et dépannage
Syndrome du "projet fantôme" | Vous avez exécuté |
Barrière de la facturation | Vous avez activé le projet, mais vous avez oublié le compte de facturation. AlloyDB est un moteur hautes performances. Il ne démarrera pas si le "réservoir" (facturation) est vide. |
Délai de propagation de l'API | Vous avez cliqué sur "Activer les API", mais la ligne de commande indique toujours |
Quotas | Si vous utilisez un tout nouveau compte d'essai, vous pouvez atteindre un quota régional pour les instances AlloyDB. Si |
3. Récapitulatif rapide des données de la partie 1
Dans cette section, vous devez vous assurer que les données structurées que nous avons extraites des PDF non structurés sont disponibles dans BigQuery. Si vous avez manqué la partie 1 ou si vous ne disposez pas de compte de facturation, vous pouvez suivre les étapes ci-dessous et commencer :
Accédez à la console Google Cloud à partir de votre compte Gmail personnel, puis cliquez sur le bouton Activer Cloud Shell en haut à droite de la console :
Suivez ensuite les étapes de la section "Vous n'avez pas de compte de facturation ?" ci-dessous :
Étapes à suivre pour continuer à découvrir les données sans compte de facturation :
- Vous pouvez obtenir les fichiers de données CSV (données BigQuery) à partir du lien du dépôt GitHub ci-dessus.
- Commencez par créer l'ensemble de données BigQuery en exécutant la commande ci-dessous à partir du terminal Cloud Shell :
bq mk --location us-central1 --dataset froyo_data
- Ensuite, téléchargez les huit fichiers de données (fichiers CSV) du dépôt GitHub dans votre répertoire de travail en exécutant les commandes suivantes une par une :
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Exécutez les commandes suivantes une par une pour créer ces tables avec les données de l'ensemble de données que vous venez de créer
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Maintenant que les données sont dans BigQuery, passons aux étapes suivantes.
4. Configurer un cluster, une instance et un réseau AlloyDB
Une application Web de démarrage rapide vous aidera à configurer un cluster, une instance et d'autres dépendances AlloyDB. Vous pouvez suivre les étapes 2 à 4 de cet atelier pour le configurer en un clic :
https://codelabs.developers.google.com/quick-alloydb-setup
Une fois votre cluster créé, accédez à la page "Présentation du cluster" et copiez les détails du compte de service.
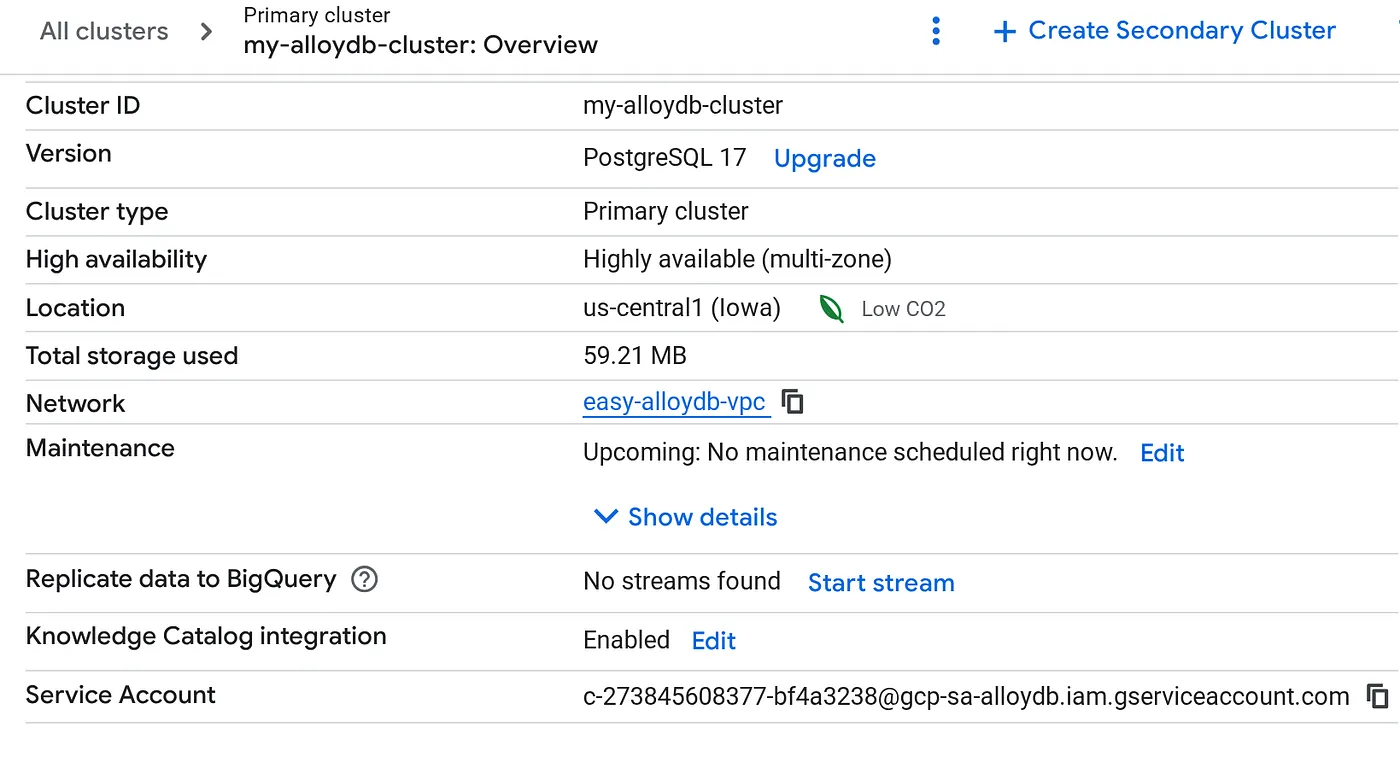
5. Configurer les autorisations
Accorder des autorisations BigQuery à ce compte de service
- Accédez à IAM et administration > IAM.
- Cliquez sur Accorder l'accès.
- Collez l'adresse du compte de service AlloyDB dans le champ Nouveaux comptes principaux.
- Attribuez les rôles suivants :
- Lecteur de données BigQuery (roles/bigquery.dataViewer) : permet de lire les données.
- Utilisateur BigQuery (roles/bigquery.user) : permet d'exécuter les requêtes.
- (Facultatif, mais recommandé) Utilisateur de session de lecture BigQuery (roles/bigquery.readSessionUser) : optimise la lecture de grands ensembles de données via l'API Storage Read.
6. Se connecter à AlloyDB et activer l'extension BigQuery
Nous allons maintenant nous connecter à notre nouvelle instance AlloyDB pour configurer l'extension de fédération. Pour cela, nous allons utiliser AlloyDB Studio.
- Sur la page "Présentation du cluster" (console AlloyDB), cliquez sur "Modifier l'instance principale" sur votre instance principale, puis faites défiler la page jusqu'en bas pour accéder aux "options de configuration avancées".
- Accédez à la section "Indicateurs" et activez les deux indicateurs sur "Activé", comme indiqué ci-dessous :
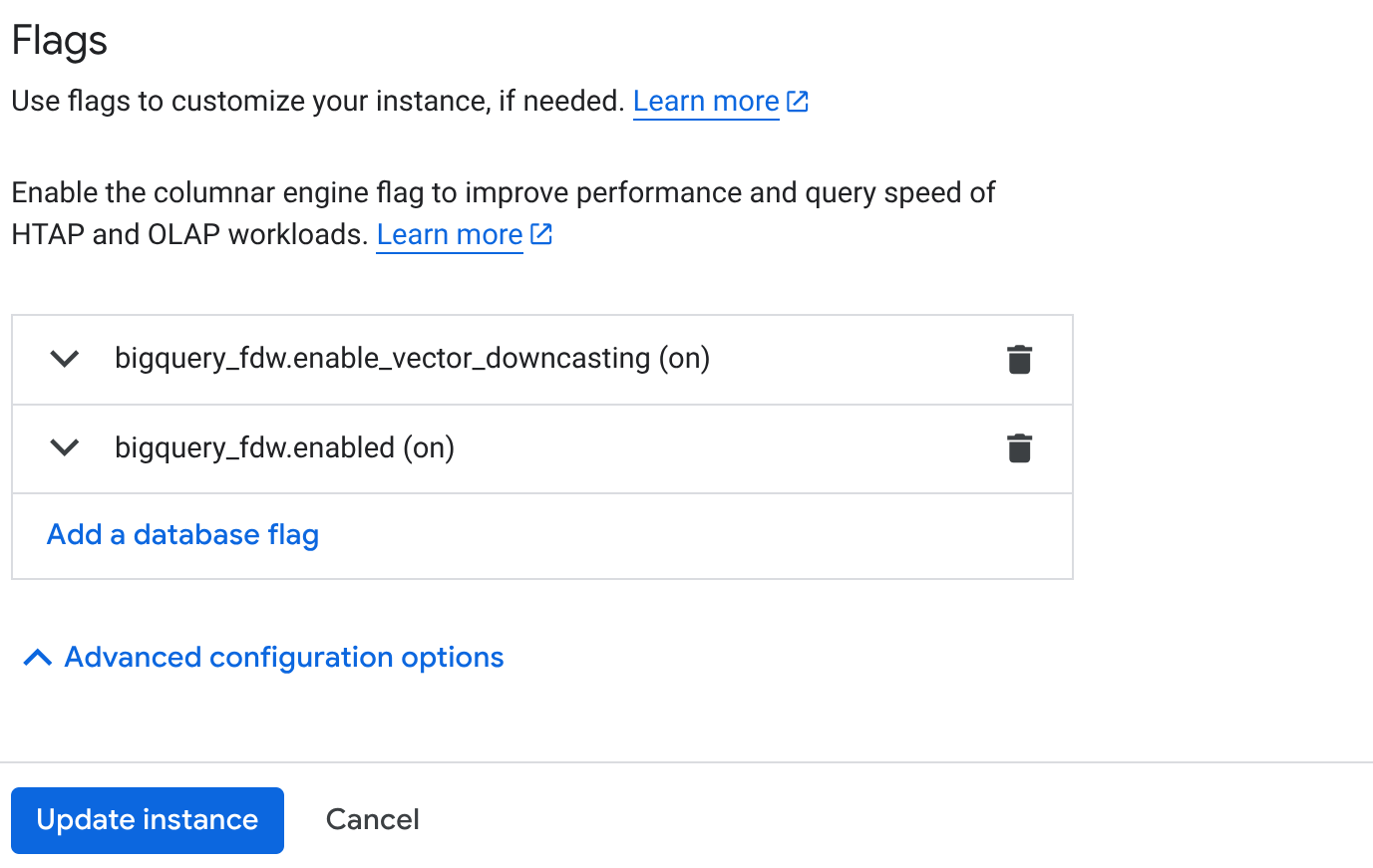 3. Cliquez sur le bouton Mettre à jour l'instance . La mise à jour prendra quelques minutes. 4. Sur la page "Présentation du cluster" (console AlloyDB), cliquez sur AlloyDB Studio.
3. Cliquez sur le bouton Mettre à jour l'instance . La mise à jour prendra quelques minutes. 4. Sur la page "Présentation du cluster" (console AlloyDB), cliquez sur AlloyDB Studio.
- Connectez-vous avec la base de données, le nom d'utilisateur et le mot de passe que vous avez configurés lors de l'étape de configuration rapide d'AlloyDB.
- Une fois connecté, dans l'onglet "Éditeur de requête" à droite, saisissez les instructions suivantes et EXÉCUTEZ-les une par une :
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- Une fois l'opération terminée, accédez au volet de l'explorateur à gauche et faites défiler la page jusqu'aux tables BigQuery :
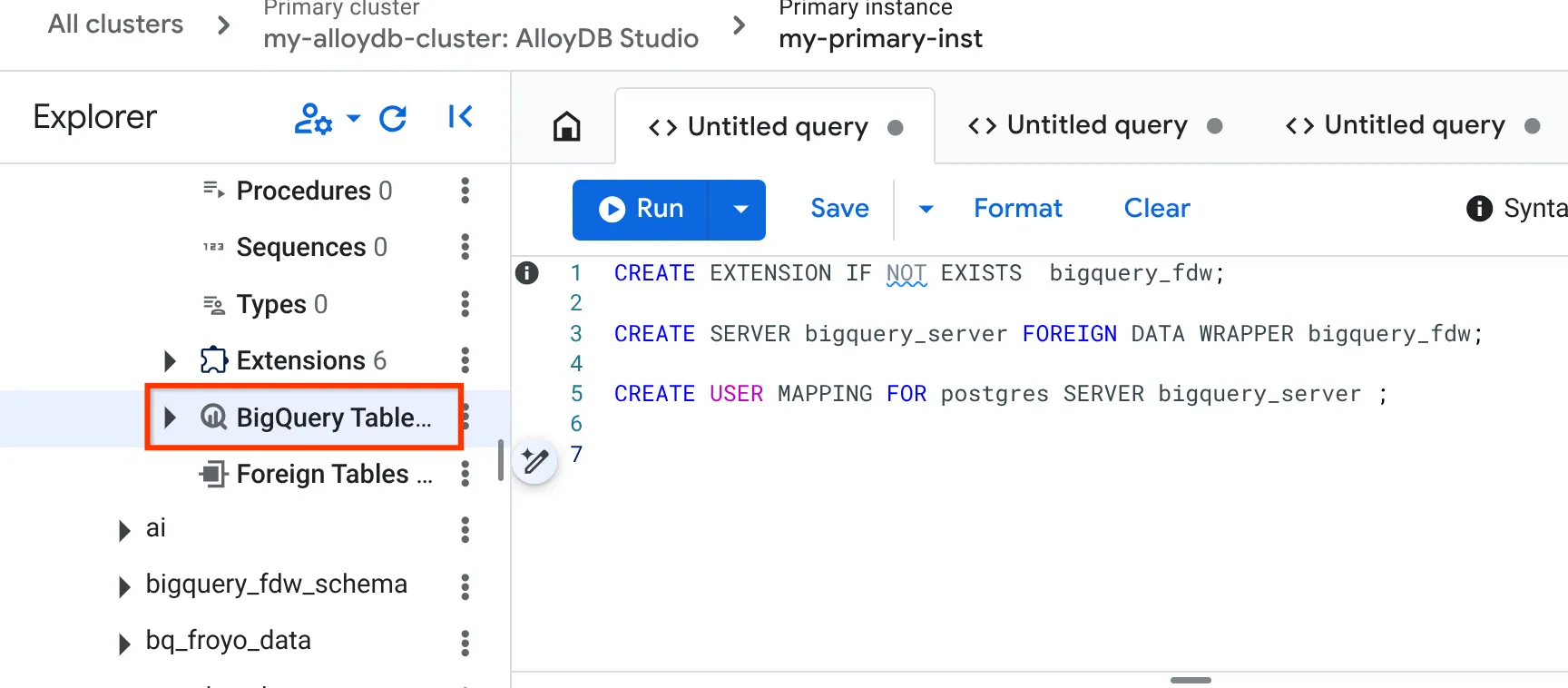
- Cliquez sur les trois points, puis sur "Connecter la table BigQuery".
- Dans la fenêtre pop-up "Connecter la table BigQuery" qui s'ouvre, sélectionnez votre project_id et le nom de l'ensemble de données BigQuery (créé dans la partie 1) à partir duquel vous souhaitez interroger les données de votre base de données AlloyDB.
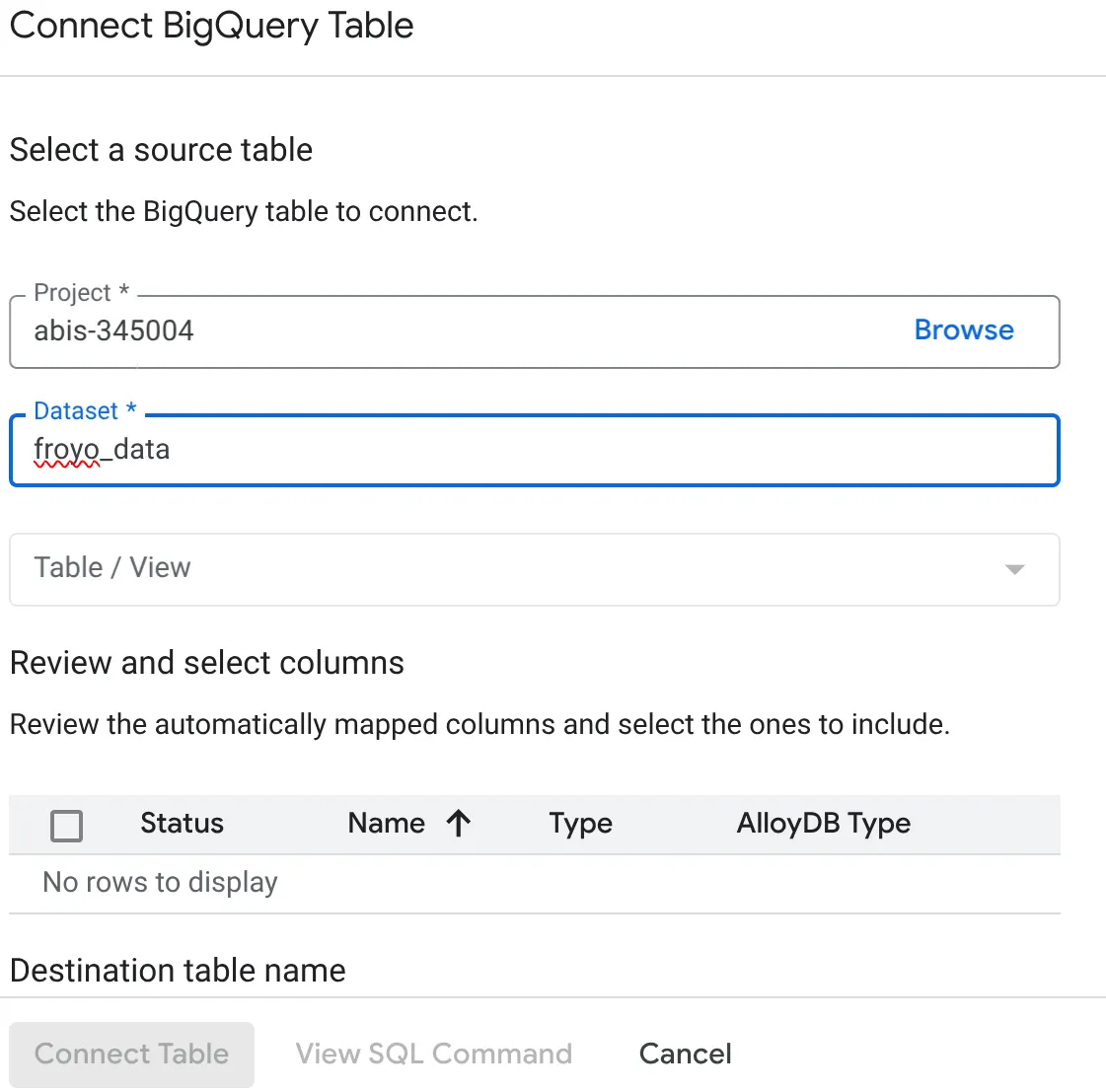
- Sélectionnez chaque table une par une pour connecter toutes vos données à AlloyDB. Nous allons ainsi valider les types de colonnes pour nous assurer qu'ils sont compatibles avec AlloyDB.
Si vous souhaitez effectuer la même opération avec une requête SQL au lieu de l'approche pointer-cliquer :
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
La magie !
Nous venons de créer des "tables externes" dans AlloyDB. Elles ressemblent à des tables PostgreSQL normales et agissent comme telles, mais elles ne stockent aucune donnée. Lorsque vous les interrogez, AlloyDB transmet instantanément la requête à BigQuery, récupère les résultats et vous les renvoie.
7. Tester la fédération dans AlloyDB
Vérifions que nous pouvons interroger notre ensemble de données BigQuery analytique massif directement à partir de notre base de données PostgreSQL transactionnelle.
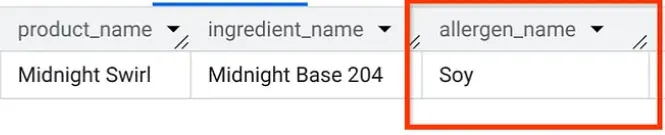
Toujours dans AlloyDB Studio, exécutons une requête pour savoir quels allergènes sont présents dans le "Midnight Swirl" (la même question que nous avons posée dans la partie 1, mais cette fois-ci à partir d'AlloyDB) :
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
Et voilà ! Vous devriez obtenir exactement les mêmes résultats que dans BigQuery.
8. Libérer de l'espace
Une fois cet atelier terminé, n'oubliez pas de supprimer le cluster et l'instance AlloyDB.
Le cluster et ses instances devraient être supprimés.
9. Félicitations pour votre couche de données unifiée
Réfléchissez à ce que nous venons d'accomplir :
- Notre application transactionnelle (exécutée sur AlloyDB) peut gérer des sessions utilisateur rapides et simultanées.
- Lorsqu'elle a besoin de données analytiques volumineuses ou d'un contexte historique (comme les détails du fournisseur ou des mappages d'ingrédients complexes), elle interroge le froyo_dataschema BigQuery.
- Aucun ETL. Aucun pipeline de données interrompu. Aucune base de données désynchronisée. Nous stockons les données une seule fois (dans BQ) et nous les calculons là où nous en avons besoin.
Maintenant que notre base de données (analytique et transactionnelle) est solide et interconnectée, nous sommes prêts à passer à la partie amusante.
Dans la partie 3, nous allons créer l'application multi-agent qui se trouve au-dessus de cette architecture pour exécuter les opérations commerciales de Froyo.