
1. סקירה כללית
כולנו מכירים את הבעיה של 'נתונים לא גלויים'. אלה קובצי PDF, תמונות וקובצי טקסט שמאוחסנים בדלי אחסון בענן, והם לא גלויים בכלל לשאילתות SQL וללוחות בקרה של BI. בעבר, כדי לגשת לנתונים האלה היה צריך להשתמש בצינורות OCR מורכבים, להזין את הנתונים באופן ידני או להשתמש בסקריפטים מותאמים אישית שנוטים להיכשל.
לא יותר.
בשיעור Lab הזה נראה לכם איך להמיר 400 קובצי PDF לא מובְנים – שמכילים טקסט, טבלאות ותמונות – לטבלאות מובְנות ב-BigQuery, עם קשרים שנוצרו אוטומטית ביניהן. אנחנו נעשה את זה תוך דקות באמצעות BigQuery Knowledge Catalog ו-Dataplex.
מה תפַתחו
כדי להמחיש את הרעיון, נתבונן בעסק פיקטיבי: רשת פרוזן יוגורט שצומחת במהירות.
נניח שאתם מנהלים את הנתונים של עסק הפרוזן יוגורט הזה. יש לכם מאות מתכונים וגיליונות מפרט של ספקים, שכולם נשמרו כקובצי PDF. מנהלי העסק רוצים להשיק סוכן AI שיעזור למנהלי החנויות וללקוחות לשאול שאלות לגבי פרטי המוצרים.
הנה תרחיש סיוט: לקוח שואל, "אני מאוד מתעניין ביוגורט הקפוא שלך בטעם Midnight Swirl. יש בזה אלרגנים?"
כדי לענות על השאלה הזו, המערכת צריכה בדרך כלל:
- מחפשים את קובץ ה-PDF של המתכון 'Midnight Swirl'.
- קוראים את רשימת הרכיבים (למשל, "אבקת קקאו", "בסיס חלב", "מתחלב X").
- לחפש בעשרות קובצי PDF של ספקים כדי למצוא את דפי המפרט של הרכיבים הספציפיים האלה.
- צריך לבדוק בגיליונות של הספק אם יש אלרגנים מוסתרים שקשורים לרכיבים האלה.
ניסיון לבנות סוכן AI שעושה את זה תוך כדי תנועה על ידי קריאת 400 קובצי PDF גולמיים בזמן ריצה הוא איטי, יקר ונוטה להזיות. במקום זאת, אנחנו נשתמש בהסקת מסקנות סמנטית כדי לחלץ את כל הנתונים האלה למסד נתונים רלציוני, וכך סוכן ה-AI העתידי שלנו יהיה מהיר מאוד ויסתמך באופן מלא על נתוני SQL עובדתיים.
בואו נתחיל לבנות!
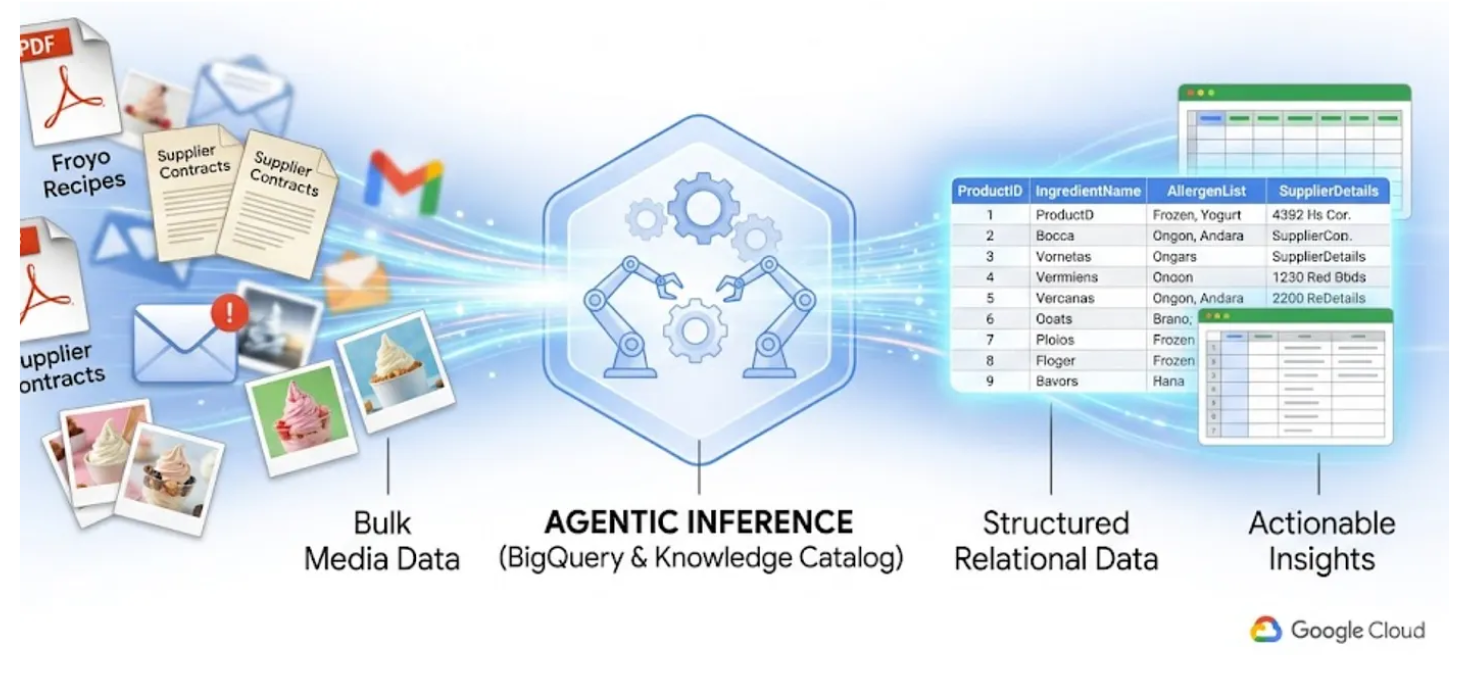
מה תלמדו
- איך מגדירים קטגוריה של Cloud Storage לקובצי המקור (קובצי PDF)
- איך מגדירים ומריצים משימת סריקת נתונים והסקת מסקנות סמנטיות ב-Knowledge Catalog כדי לחלץ נתונים מקובצי PDF של מקורות, להסיק באופן סמנטי את הקשרים וההקשר ולאחסן אותם ב-BigQuery
- איך משתמשים בסוכני BigQuery כדי לשוחח עם מערך הנתונים החדש שנוצר
דרישות
2. לפני שמתחילים
יצירת פרויקט
- ב-Google Cloud Console, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- מוודאים שהחיוב מופעל בפרויקט ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט.
- תשתמשו ב-Cloud Shell, סביבת שורת פקודה שפועלת ב-Google Cloud. לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud.

- אחרי שמתחברים ל-Cloud Shell, בודקים שכבר בוצע אימות ושהפרויקט מוגדר למזהה הפרויקט באמצעות הפקודה הבאה:
gcloud auth list
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט.
gcloud config list project
- אם רוצים לבצע אימות
gcloud auth login
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- מפעילים את ממשקי ה-API הנדרשים: מריצים את הפקודה הבאה כדי להפעיל את כל ממשקי ה-API הנדרשים:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
נקודות חשובות ופתרון בעיות
תסמונת הפרויקט הרפאים | הפעלתם את הפקודה |
מחסום החיוב | הפעלתם את הפרויקט, אבל שכחתם להוסיף חשבון לחיוב. AlloyDB הוא מנוע עם ביצועים גבוהים, והוא לא יופעל אם 'מיכל הדלק' (החיוב) ריק. |
השהיה בפרסום ה-API | לחצתם על 'הפעלת ממשקי API', אבל בשורת הפקודה עדיין מופיע |
מכסה Quags | אם אתם משתמשים בחשבון ניסיון חדש לגמרי, יכול להיות שתגיעו למכסה אזורית של מופעי AlloyDB. אם הפעולה |
סוכן שירות 'מוסתר' | לפעמים סוכן השירות של AlloyDB לא מקבל אוטומטית את התפקיד |
3. הגדרה של קטגוריה ב-Google Cloud Storage
בקטע הזה, תיצרו מבנה ארגוני ב-BigQuery כדי לאחסן את המתכון של הפרוזן יוגורט ואת נתוני הספקים, במיוחד את פרטי המוצר של הפרוזן יוגורט. החיבור גם יוצר קישור למשאבים ב-Cloud, שמשמש כ'גשר' מאובטח שמאפשר ל-BigQuery לקרוא קבצים ממקורות חיצוניים כמו Cloud Storage.
לפני שמתחילים:
המאגר הזה מכיל מתכונים וקובצי PDF של ספקים שנשתמש בהם בפרויקט הזה. חשוב להוריד את הקבצים האלה. כדי להוריד את הקבצים, מבצעים את הפעולות הבאות.
ב-Cloud Shell, מריצים את הפקודה הבאה:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
עוברים לתיקייה החדשה שנוצרה:
cd next-26-keynotes
משיכת התיקייה data-cloud-demo
git sparse-checkout set genkey/data-cloud-demo
אחרי שהתשלום יסתיים, עוברים לתיקייה data-cloud-demo ומחלצים את קובצי ה-ZIP כדי לגשת לנכסי ה-codelab.
יצירת קטגוריה והעלאה של קובצי ה-PDF של Froyo (מתכונים וספקים)
- במסוף Google Cloud, נכנסים לדף Cloud Storage Buckets.
- לוחצים על 'יצירה'.
- בדף Create a bucket מזינים את פרטי הקטגוריה. אחרי כל אחד מהשלבים הבאים, לוחצים על 'המשך' כדי לעבור לשלב הבא:
- בקטע Get started (תחילת העבודה), מזינים את שם הקטגוריה. לדוגמה: froyo_data
- בקטע 'בחירת מיקום לאחסון הנתונים', בוחרים באפשרות 'אזור' ומזינים את האזור הרצוי. us-central1
- בקטע Choose how to control access to objects, מבטלים את הסימון בתיבה Enforce public access prevention on this bucket.
- לוחצים על 'יצירה'.
- ברשימת הקטגוריות, לוחצים על הקטגוריה שיצרתם.
- בכרטיסייה Objects של הקטגוריה, לוחצים על Upload ואז על Upload folders.
- בוחרים את התיקייה recipes שחולצה בקטע 'לפני שמתחילים' של ה-codelab הזה.
- לחץ על 'העלה'.
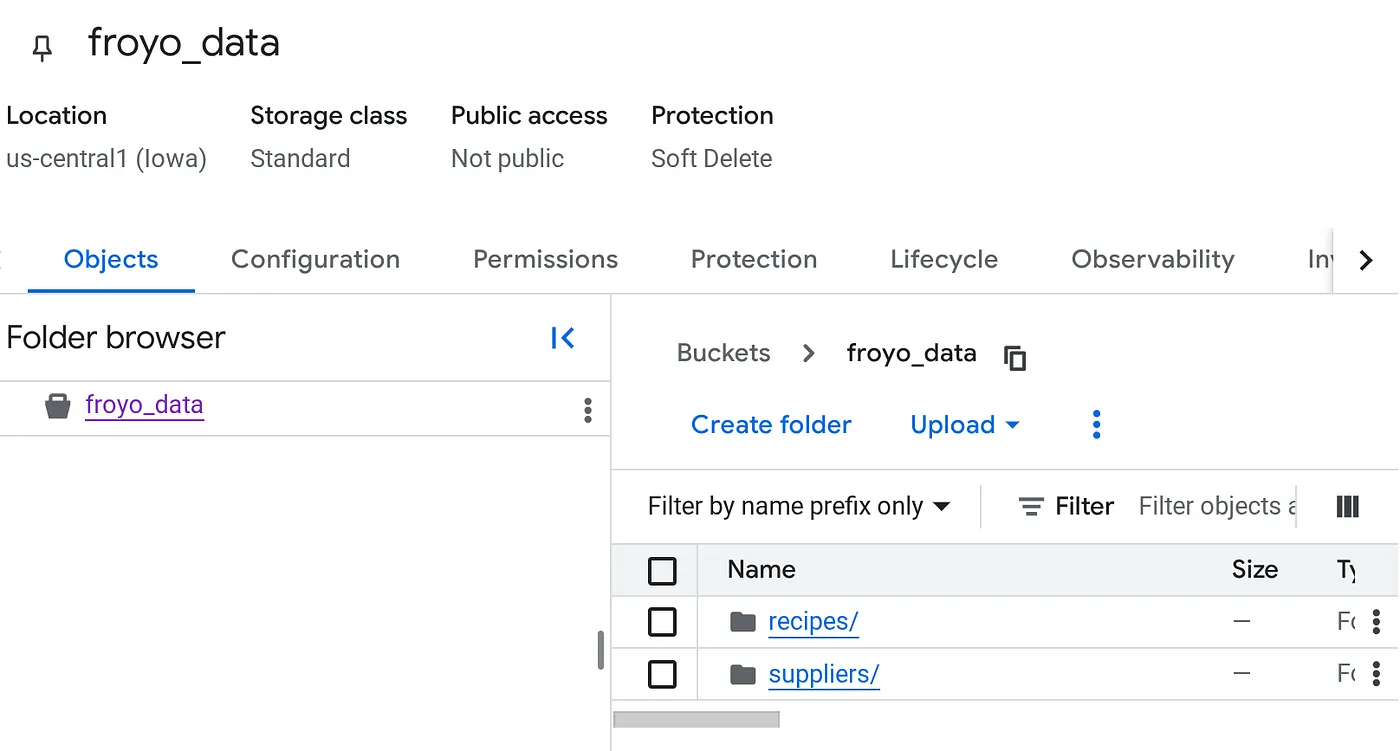
- חוזרים על תהליך ההעלאה עבור התיקייה suppliers.
אחרי ההעלאה, מבנה הקטגוריה אמור להיראות כך (שם הקטגוריה):
4. הגדרת חיבור ל-BigQuery
יוצרים קישור למשאבים ב-Cloud. הפעולה הזו יוצרת חשבון שירות ייחודי שמשמש כ"תעודת הזהות" של BigQuery לצורך גישה לקבצים חיצוניים.
- עוברים לדף BigQuery.
- בחלונית הימנית, לוחצים על סמל הניתוח. אם החלונית הימנית לא מוצגת, לוחצים על 'הרחבת החלונית הימנית' כדי לפתוח אותה.
- בחלונית Explorer, מרחיבים את שם הפרויקט ואז לוחצים על Connections (חיבורים).
- בדף 'חיבורים', לוחצים על 'יצירת חיבור'.
- בקטע Connection type (סוג החיבור), בוחרים באפשרות Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource) (מודלים מרוחקים, פונקציות מרוחקות, BigLake ו-Spanner של Vertex AI (משאב בענן)).
- בשדה Connection ID (מזהה החיבור), מזינים את שם מזהה החיבור:
- bq-connection. חשוב לרשום את המזהה הזה, כי תצטרכו אותו בהמשך כשתיצרו את סריקת הנתונים ב-codelab הזה.
- מגדירים את סוג המיקום ל'אזור' ואז בוחרים אזור. לדוגמה, us-central1. החיבור צריך להיות באותו אזור שבו נמצאים משאבים אחרים, כמו מערכי נתונים.
- לוחצים על 'יצירת קישור'.
- לוחצים על 'מעבר לחיבור'.
- בחלונית Connection info (פרטי התחברות), מעתיקים את מזהה חשבון השירות לשימוש בשלב מאוחר יותר. חשבון השירות נראה בערך כך: bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
5. הגדרת הרשאות
- הענקת ההרשאות הנדרשות לחיבור BigQuery כדי לגשת לאובייקטים ב-Cloud Storage ול-Knowledge Catalog
עוברים לדף IAM & Admin (ניהול זהויות והרשאות גישה) ובקטע View by Principals (תצוגה לפי חשבונות משתמש), לוחצים על הלחצן Grant access (הענקת גישה), מוסיפים חשבון משתמש על ידי הדבקת חשבון השירות שהעתקתם בשלב הקודם. בקטע התפקידים, מוסיפים את השמות של התפקידים הבאים אחד אחרי השני ושומרים:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- מתן הרשאות לחשבון השירות של Dataplex לגשת לקטגוריה של Cloud Storage
עוברים לדף IAM & Admin (ניהול הרשאות וניהול חשבון) ובקטע View by Principals (תצוגה לפי חשבונות משתמש), לוחצים על הלחצן Grant access (מתן גישה) ומוסיפים חשבון משתמש על ידי הקלדת המילה dataplex בסרגל הטקסט New principal (חשבון משתמש חדש). מהרשימה שמופיעה בהשלמה האוטומטית, בוחרים את ישות מורשית של חשבון השירות של Dataplex, שדומה לזה: (צריך להשתמש במספר הפרויקט ולא במזהה הפרויקט בכתובת האימייל בחשבון של חשבון השירות שמופיע בהמשך)
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
אם מסיבה כלשהי חשבון השירות שלמעלה עם מספר הפרויקט לא מזוהה, יכול להיות ששירות Dataplex עדיין לא אותחל בפרויקט. עוברים אל Cloud Shell Terminal ומנסים להפעיל את ה-API (אם לא עשיתם זאת כבר בשלב לפני שמתחילים) על ידי הרצת הפקודה הבאה: gcloud services enable dataplex.googleapis.com
גם אחרי זה, אם חשבון השירות של Dataplex לא מזוהה, צריך ליצור בכוח משימת סריקה של Dataplex לניסיון בדף Metadata Curation ולהזין את הפרטים בדף Discover Job creation:
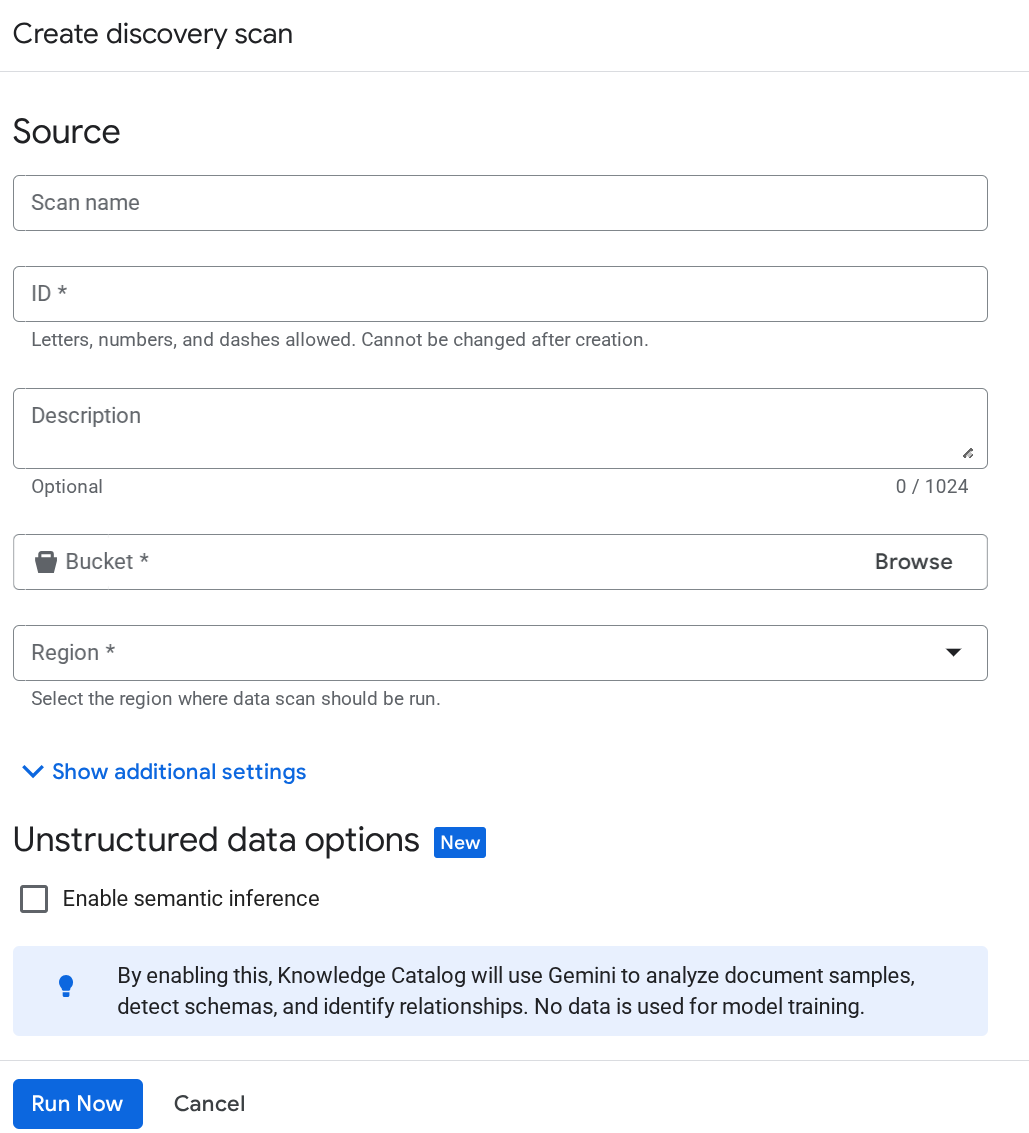
לוחצים על הפעלה מיידית. העבודה תיכשל, אבל כך תובטח האתחול של מזהה חשבון השירות בשירות Dataplex שלכם.
חוזרים לדף IAM & Admin ובקטע View by Principals לוחצים על הלחצן Grant access ואז על add a principal. מדביקים את חשבון השירות:
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
לאחר מכן מקצים לחשבון השירות הזה את התפקידים הבאים:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. הגדרה של Knowledge Catalog
ליצור Knowledge Catalog כדי לאחד את הנתונים הלא מובנים ולבצע אוטומציה של גילוי קבצים לא מובנים (כמו מתכונים ב-PDF וספקים ב-PDF).
יוצרים את עבודת DataScan מהמסוף:
- עוברים לדף Metadata curation (אוצרות מטא-נתונים).
- לוחצים על 'יצירה' ומזינים את הפרטים שמתאימים להגדרה:
הערה חשובה: אל תשכחו לסמן את התיבה לצד 'הפעלת הסקה סמנטית'.
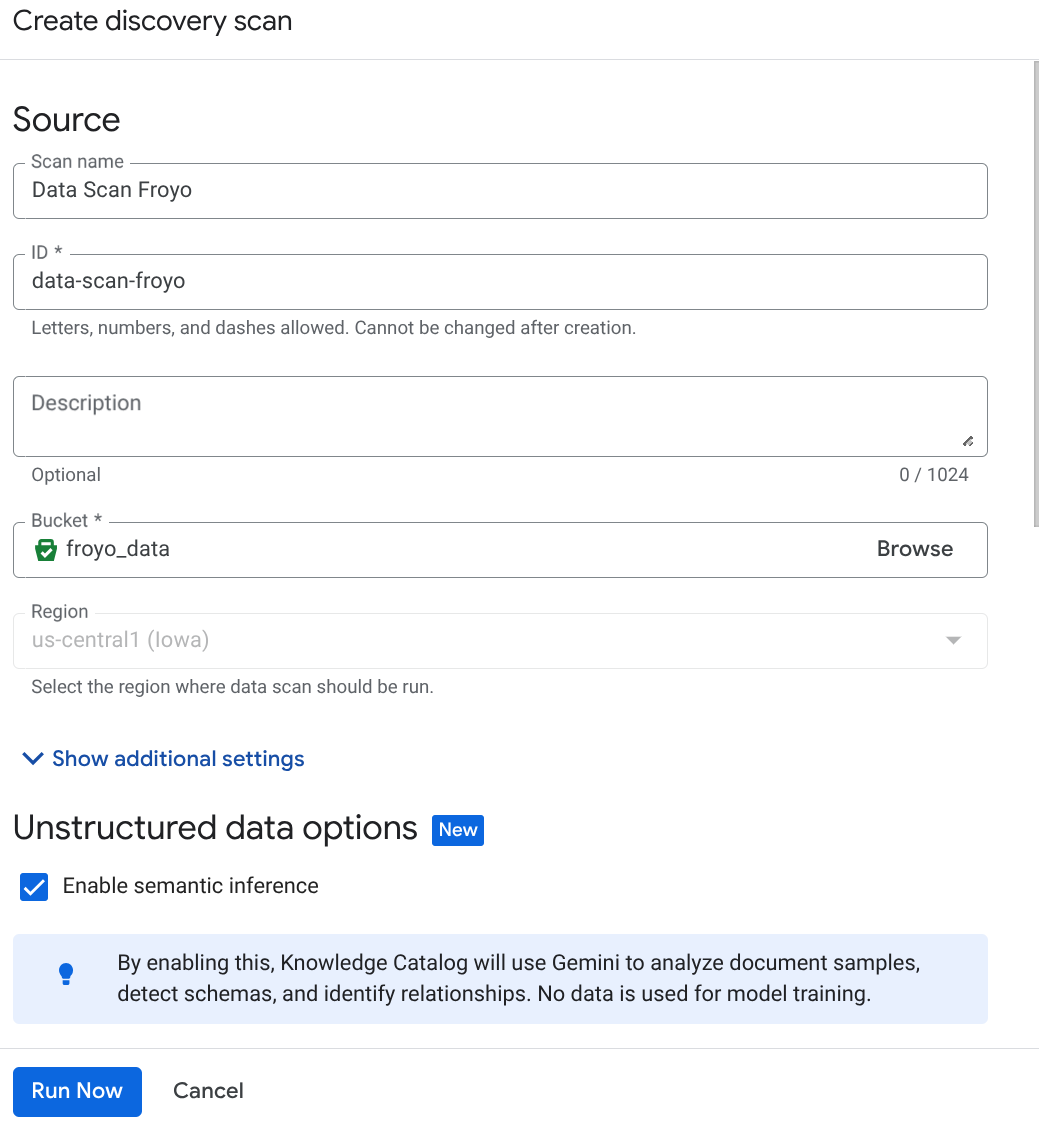
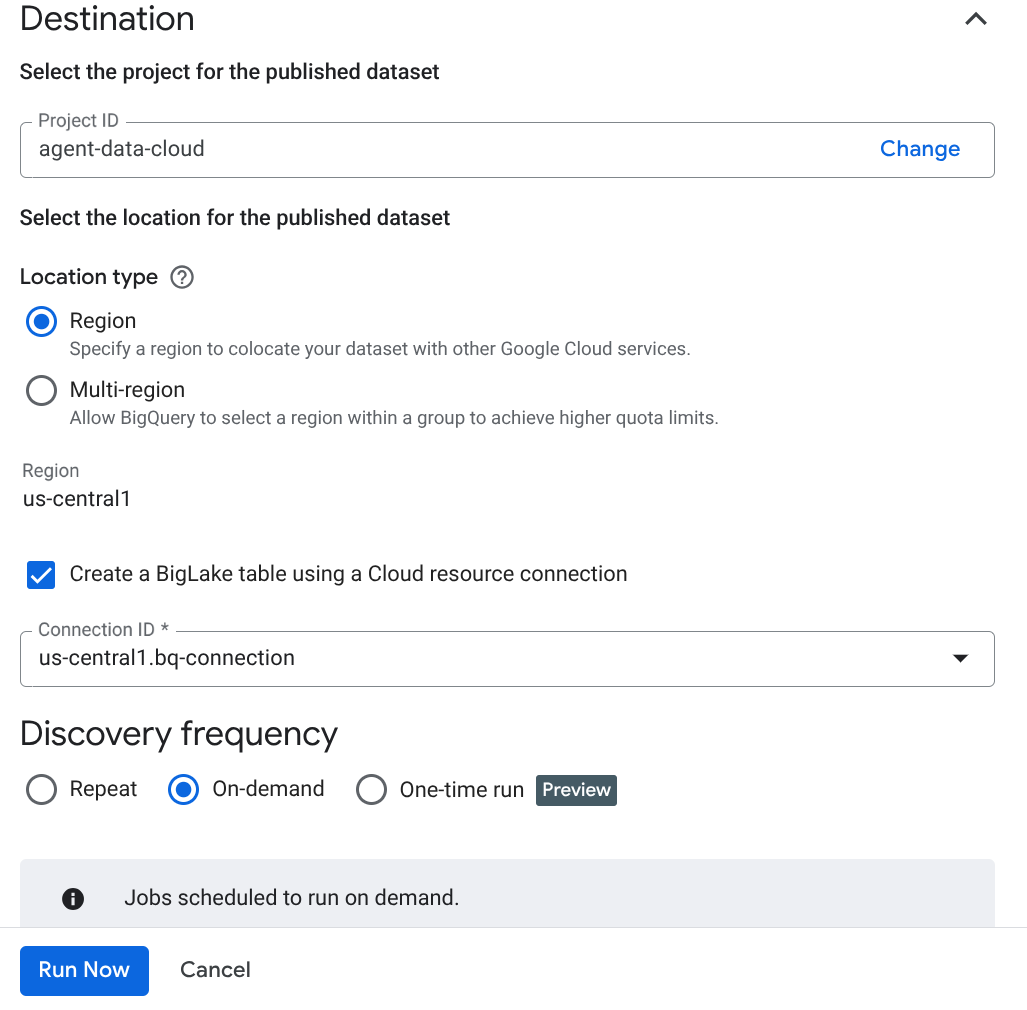
- לוחצים על Run Now (הפעלה).
- השלמת עבודת הסריקה תימשך זמן מה. אחרי שהעבודה מסתיימת, בודקים אם מערך הנתונים שפורסם קיים. כדי לבדוק את סטטוס העבודה, אפשר לעבור לדף Metadata curation, ובכרטיסייה Cloud Storage discovery ללחוץ על השם של סריקות הגילוי של ההרצה האחרונה. אמור להופיע מערך הנתונים שפורסם, כמו בדוגמה הבאה:
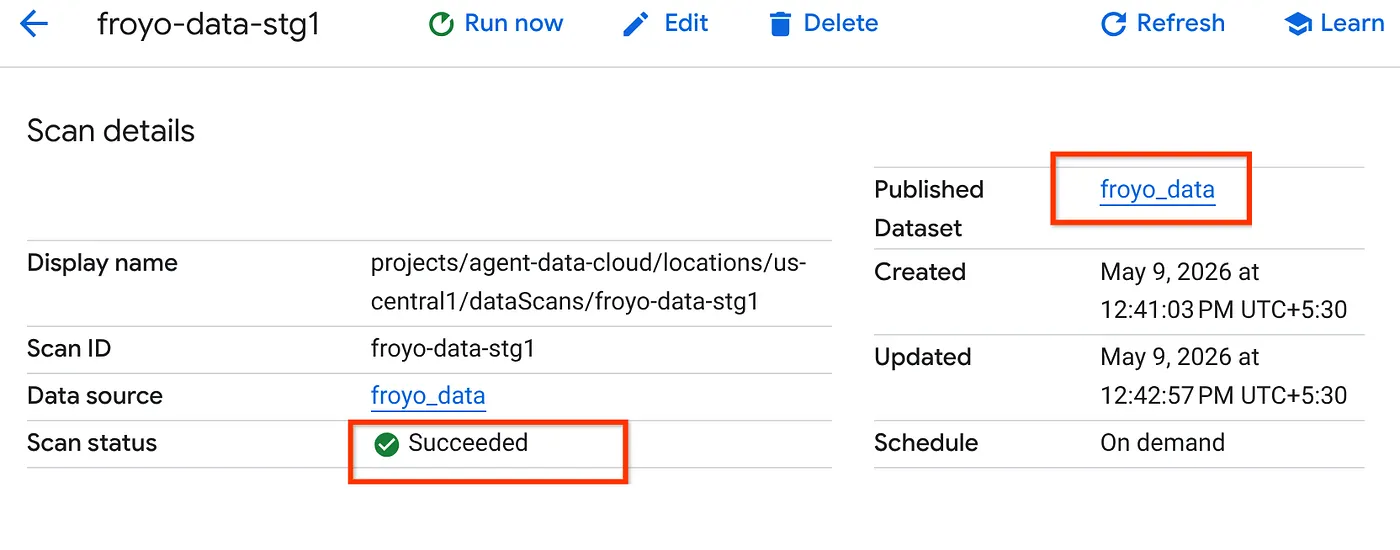
הערה: אם נתקלתם בשגיאות בשלב הסריקה, פשוט המתינו כמה דקות ונסו שוב (יצירת המשימה והשלמת ההרצה אורכות כמה דקות).
- אפשר לראות את הטבלה ב-BigQuery על ידי לחיצה על מערך הנתונים froyo_data ומעבר אליו. לוחצים על מזהה הטבלה ב-BigQuery ומריצים את השאילתה שלמטה בכרטיסייה 'עורך השאילתות':
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
התוצאה היא 400 (אם לא, אפשר לחזור ולהריץ שוב את עבודת סריקת הנתונים).
7. חילוץ נתונים סמנטי
נהדר! עכשיו נחלץ את ההסקה עבור האובייקטים הלא מובנים האלה באמצעות Knowledge Catalog.
נשתמש בתכונת התובנות כדי ליצור הצהרות SQL לחילוץ נתונים מובְנים מהטבלה הלא מובְנית
- במסוף Google Cloud, עוברים לדף Knowledge Catalog Search.
- מחפשים את טבלת מערך הנתונים שרוצים לראות את התובנות לגביה. בסרגל החיפוש, מזינים את שם מערך הנתונים או הטבלה מהשלב הקודם: froyo_data ומקישים על Enter.
- ברשימת התוצאות, לוחצים על הערך TABLE (לא על מערך הנתונים).
- אמורה להופיע הכרטיסייה תובנות. לוחצים על האפשרות הזו (אם צריך להפעיל API כלשהו, פשוט מפעילים אותו).
אם הפעלתם ממש עכשיו את ה-API, תצטרכו להריץ מחדש את עבודת הסריקה.
- בכרטיסייה 'תובנות' יופיע התפריט הנפתח של הלחצן 'חילוץ'. לוחצים על האפשרות הזו ובוחרים באפשרות 'חילוץ באמצעות SQL'.
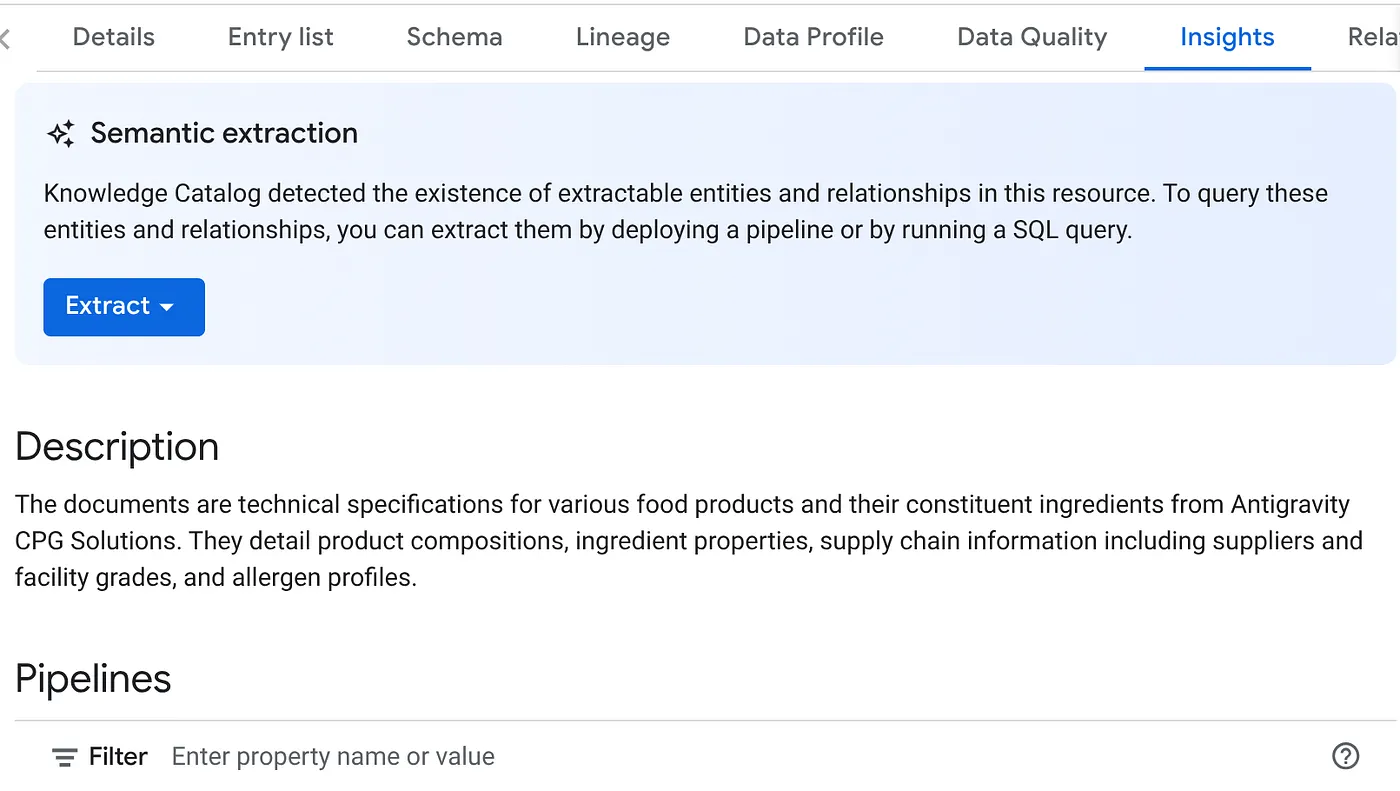
בתיבת הדו-שיח Extract with SQL (חילוץ באמצעות SQL) שמופיעה, מגדירים את מערך הנתונים DESTINATION (יעד) כמערך שמופיע בתוצאה של משימת סריקת הנתונים. מתחילים להקליד את השם שלו והוא אמור להופיע בהשלמה האוטומטית. לוחצים על הלחצן חילוץ. אפשר גם ליצור בשלב הזה מערך נתונים חדש ולבצע חילוץ.
עורך השאילתות של BigQuery אמור להיפתח עם כרטיסייה מאוכלסת ב-SQL שחולץ מהסקת המסקנות של סריקת הנתונים.
8. אימות SQL ויצירת סכימה
אם השאילתה שנוצרה נראית תקינה ורלוונטית מבחינה סמנטית לנתונים הלא מובְנים, אפשר להריץ אותה בלחיצה על הלחצן 'הפעלה' בעורך השאילתות. ייקח כמה דקות ליצור את הסכימה שנדרשת לאחסון המובנה של המדיה הלא מובנית.
אחרי שתסיימו, תוכלו לוודא שהסכימה נכונה על ידי הרחבת מערך הנתונים בחלונית הסייר של BigQuery Studio, כמו שמוצג בהמשך:
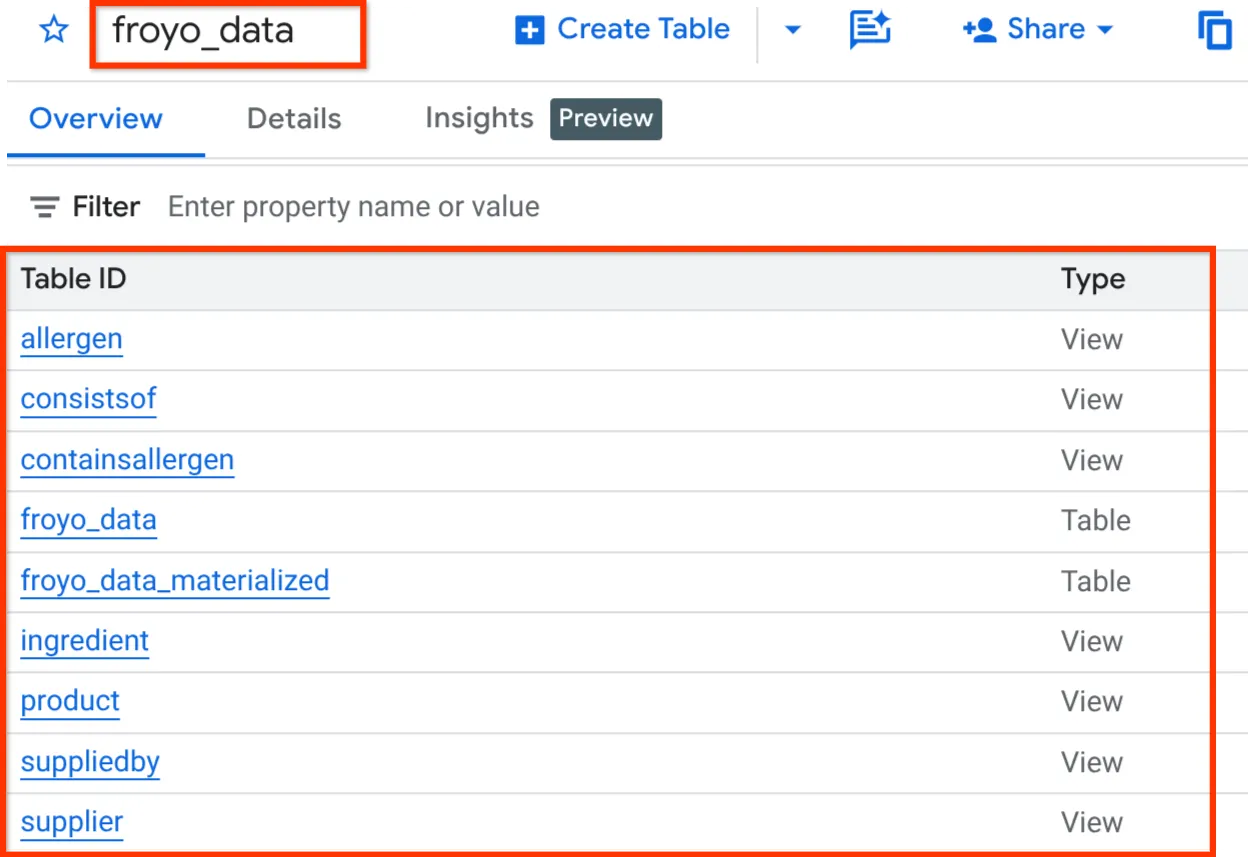
מעולה!!! היה כל כך נחמד שביצענו את כל הפעולות האלה במסד הנתונים ממש מהר. עכשיו הגיע הזמן למבחן האולטימטיבי!
כדי להמשיך ליהנות מהנתונים בלי חשבון לחיוב:
- אפשר להוריד את קובצי ה-csv (נתוני BigQuery) מקישור המאגר ב-GitHub שמופיע למעלה.
- קודם יוצרים את מערך הנתונים ב-BigQuery על ידי הפעלת הפקודה הבאה ממסוף Cloud Shell:
bq mk --location us-central1 --dataset froyo_data
- בשלב הבא, מורידים את 8 קובצי הנתונים (קובצי CSV) ממאגר GitHub לספריית העבודה על ידי הפעלת הפקודות הבאות אחת אחרי השנייה:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- מריצים את הפקודות הבאות אחת אחרי השנייה כדי ליצור את הטבלאות האלה עם הנתונים במערך הנתונים החדש שיצרתם
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
אחרי שיוצרים את מערך הנתונים, הטבלאות והנתונים, אפשר לבדוק את הנתונים שדיברנו עליהם.
9. המבחן האולטימטיבי!!!
נניח שאני רוצה שהסוכן שלי יענה על שאלות של משתמשים עם מידע אמיתי, מלא ומאורגן היטב שמבוסס על עובדות. אני עומד לשאול שאלה שהסוכן יוכל לענות עליה רק על סמך הפניות לכמה קובצי מדיה והפניות מהמקור שלי.
השאלה של המשתמש שלי:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
עכשיו, בחיפוש כללי או בחיפוש באמצעות LLM, יופיע הכיתוב 'אפס רכיבים'. אבל בנינו הסקה סמנטית מלאה שממירה את כל המדיה הלא מובנית שלנו לנתונים מובנים. אז הנה, עם SQL פשוט שיאחזר את המידע הזה:
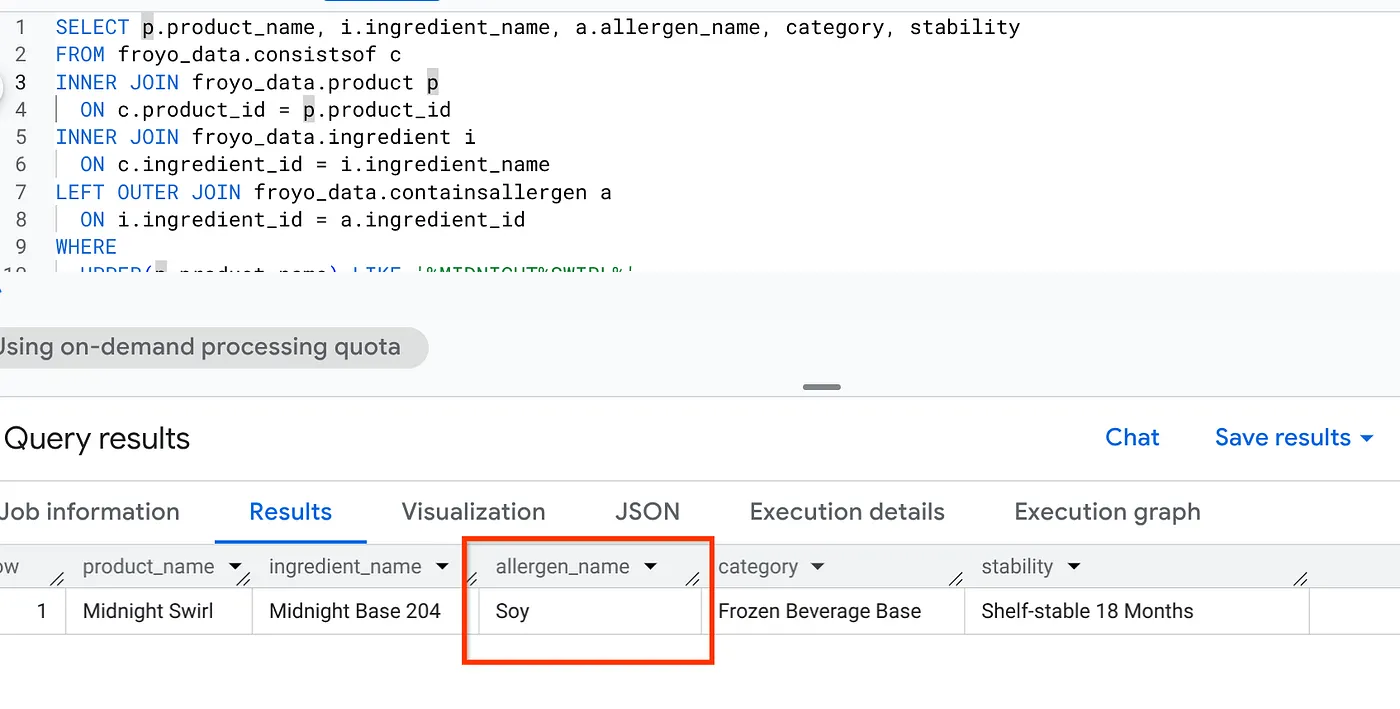
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
יש! בודקים את התוצאה:
10. הסרת המשאבים
בסיום ה-Lab, אל תשכחו למחוק את משימת הסריקה ואת טבלאות BigQuery שהמשימה יצרה.
עוברים אל https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery. לוחצים על סמל האפשרויות הנוספות (שלוש נקודות אנכיות) לצד המשרה שרוצים למחוק ואז על סמל המחיקה.
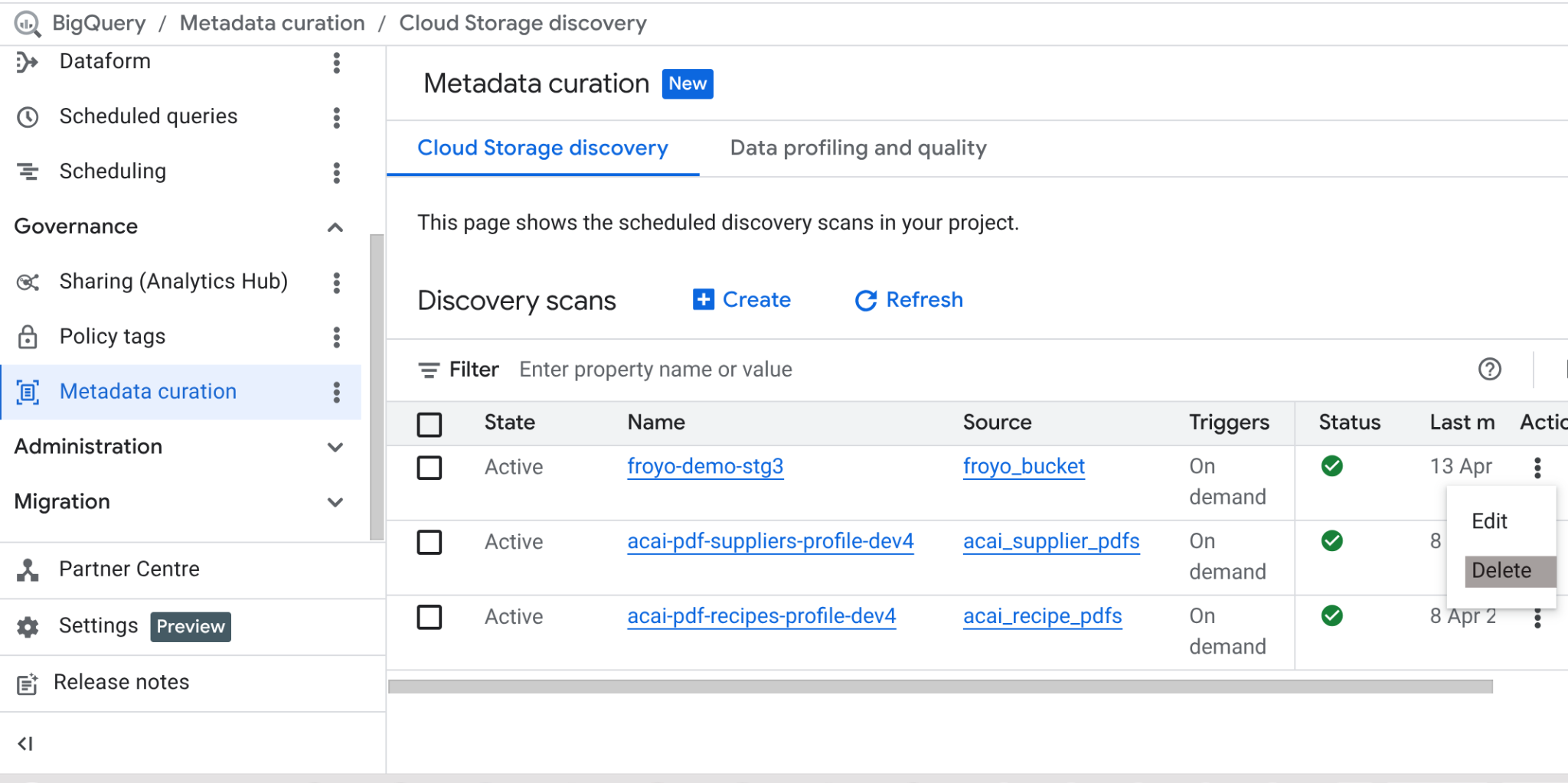
הפעולה הזו אמורה לנקות את המשימה.
11. מזל טוב
ההטמעה שלנו הצליחה לזהות את האלרגן המוסתר. אין יותר נתונים לא ברורים, חברים!!! בחלק 2, נבצע איחוד של נתוני BigQuery האלה במערכת טרנזקציונלית עם AlloyDB כדי לאחד את צורכי הנתונים של האפליקציה מבוססת-הסוכן שלנו.