
1. סקירה כללית
בחלק 1, הצלחנו להפוך קובצי PDF לא מובְנים ומבולגנים לטבלאות נקיות, חכמות ומובְנות ב-BigQuery באמצעות Knowledge Catalog ו-DataScan. עכשיו יש לנו מחסן נתונים חזק.
אם אתם צריכים תזכורת מהירה, במעבדה של חלק 1 השתמשנו בתרחיש לדוגמה של רשת פיקטיבית של חנויות יוגורט קפוא והמרנו 400 קובצי PDF לא מובְנים שלה – שכללו טקסט, טבלאות ותמונות – לטבלאות מובְנות ב-BigQuery עם קשרים שנוצרו ביניהן באופן אוטומטי באמצעות BigQuery Knowledge Catalog ו-Dataplex.
מה תפַתחו
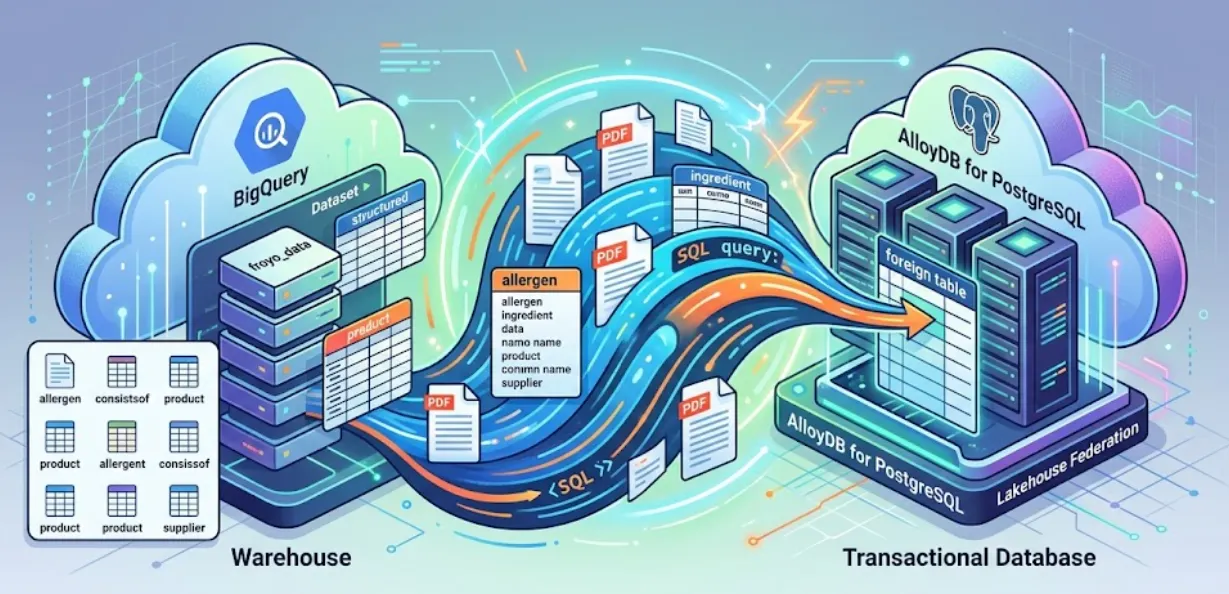
בסשן הזה נגדיר את AlloyDB ל-PostgreSQL ונעשה משהו קסום: נאחד את נתוני BigQuery ישירות ב-AlloyDB. המשמעות היא שהאפליקציה העסקית שלנו יכולה לשלוח שאילתות לנתונים במחסן בזמן אמת, בלי להעתיק או לשכפל אותם.
אתם כמפתחים צריכים לשאול את השאלה הזו בשלב הזה:
"אם הנתונים כבר נמצאים ב-BigQuery, למה צריך להשתמש גם ב-AlloyDB? למה האפליקציה לא מריצה פשוט הצהרת SELECT ישירות מול BigQuery?"
הסיבות לכך:
בעזרת Lakehouse Federation, אפשר להשתמש במנוע השאילתות של AlloyDB כדי להפעיל את עומסי העבודה הטרנזקציוניים והאנליטיים של האפליקציה, מתוך אותו ממשק. אתם יכולים גם להפוך את הנתונים האלה למוחשיים או לייבא אותם אל AlloyDB כדי לקבל גישה מהירה יותר לשימוש באפליקציות שלכם, וכך תוכלו להשתמש ב-AlloyDB AI ובמנוע מבוסס-העמודות.
אתם יכולים להשתמש ב-AlloyDB כבסיס נתונים טרנזקציוני, וגם לאחסן כמויות גדולות של נתונים ב-BigQuery או ב-BigLake. בדרך כלל, האפליקציות שלכם משולבות באופן עצמאי עם שתי המערכות האלה כדי לגשת לנתונים בשירותים השונים של Google Cloud. Lakehouse Federation for AlloyDB מאפשרת לכם להשתמש בתמיכה של AlloyDB בשאילתה לכמה מסדי נתונים, שמוטמעת כעטיפת נתונים חיצוניים, כדי לגשת לנתונים של BigQuery ו-AlloyDB באמצעות ממשק SQL ב-AlloyDB.
במקום ליצור צינור ETL שביר כדי לשלוח שאילתות לנתוני BigQuery מ-AlloyDB, נשתמש בשאילתות מאוחדות. AlloyDB ישמש כנקודת קצה מאוחדת, ויגיע ל-BigQuery בצורה חלקה כשצריך.
בואו נתחיל לבנות!
מה תלמדו
- איך מגדירים אשכול, מכונה ורשת של AlloyDB בלחיצת כפתור
- איך מגדירים את התוסף כדי להתכונן לאיחוד
- איך מגדירים פדרציה מ-BigQuery ל-AlloyDB
- אני רוצה לנסות
דרישות
2. לפני שמתחילים
יצירת פרויקט
- ב-מסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- מוודאים שהחיוב מופעל בפרויקט ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט.
- תשתמשו ב-Cloud Shell, סביבת שורת פקודה שפועלת ב-Google Cloud. לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud.

- אחרי שמתחברים ל-Cloud Shell, בודקים שכבר בוצע אימות ושהפרויקט מוגדר למזהה הפרויקט באמצעות הפקודה הבאה:
gcloud auth list
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט.
gcloud config list project
- אם רוצים לבצע אימות
gcloud auth login
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- מפעילים את ממשקי ה-API הנדרשים: מריצים את הפקודה הבאה כדי להפעיל את כל ממשקי ה-API הנדרשים:
gcloud services enable alloydb.googleapis.com
נקודות חשובות ופתרון בעיות
תסמונת 'פרויקט הרפאים' | הפעלת את הפקודה |
מחסום בחיוב | הפעלתם את הפרויקט, אבל שכחתם להוסיף חשבון לחיוב. AlloyDB הוא מנוע עם ביצועים גבוהים, והוא לא יופעל אם 'מיכל הדלק' (החיוב) ריק. |
השהיה בהפצת API | לחצתם על 'הפעלת ממשקי API', אבל בשורת הפקודה עדיין מופיעה ההודעה |
מכסות Quags | אם אתם משתמשים בחשבון ניסיון חדש לגמרי, יכול להיות שתגיעו למכסה אזורית של מופעי AlloyDB. אם הפעולה |
3. סיכום מהיר של הנתונים מחלק 1
בקטע הזה, צריך לוודא שהנתונים המובְנים שחולצו מקובצי PDF לא מובְנים זמינים ב-BigQuery. אם פספסתם את חלק 1 או שאין לכם חשבון לחיוב, לא נורא, אתם יכולים לבצע את השלבים הבאים ולהתחיל:
נכנסים אל מסוף Google Cloud דרך חשבון Gmail האישי ולוחצים על הלחצן Activate Cloud Shell (הפעלת Cloud Shell) בפינה השמאלית העליונה של המסוף:
ואז מבצעים את השלבים שבקטע 'אין חשבון לחיוב' שבהמשך:
כדי להמשיך ליהנות מהנתונים בלי חשבון לחיוב:
- אפשר להוריד את קובצי ה-csv (נתוני BigQuery) מקישור המאגר ב-GitHub שמופיע למעלה.
- קודם יוצרים את מערך הנתונים ב-BigQuery על ידי הפעלת הפקודה הבאה ממסוף Cloud Shell:
bq mk --location us-central1 --dataset froyo_data
- בשלב הבא, מורידים את 8 קובצי הנתונים (קובצי CSV) ממאגר github לספריית העבודה על ידי הפעלת הפקודות הבאות אחת אחרי השנייה:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- מריצים את הפקודות הבאות אחת אחרי השנייה כדי ליצור את הטבלאות האלה עם הנתונים במערך הנתונים החדש שיצרתם
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
עכשיו כשהנתונים נמצאים ב-BigQuery, אפשר להמשיך לשלבים הבאים.
4. הגדרת אשכול, מכונה ורשת של AlloyDB
יש אפליקציה להפעלה מהירה מבוססת-אינטרנט שתעזור לכם להגדיר אשכול, מכונה ותלות אחרת של AlloyDB. אפשר לבצע את שלבים 2 עד 4 במעבדה הזו כדי להגדיר אותו בלחיצת כפתור:
https://codelabs.developers.google.com/quick-alloydb-setup
אחרי שיוצרים את האשכול, עוברים לדף הסקירה הכללית של האשכול ומעתיקים משם את פרטי חשבון השירות.
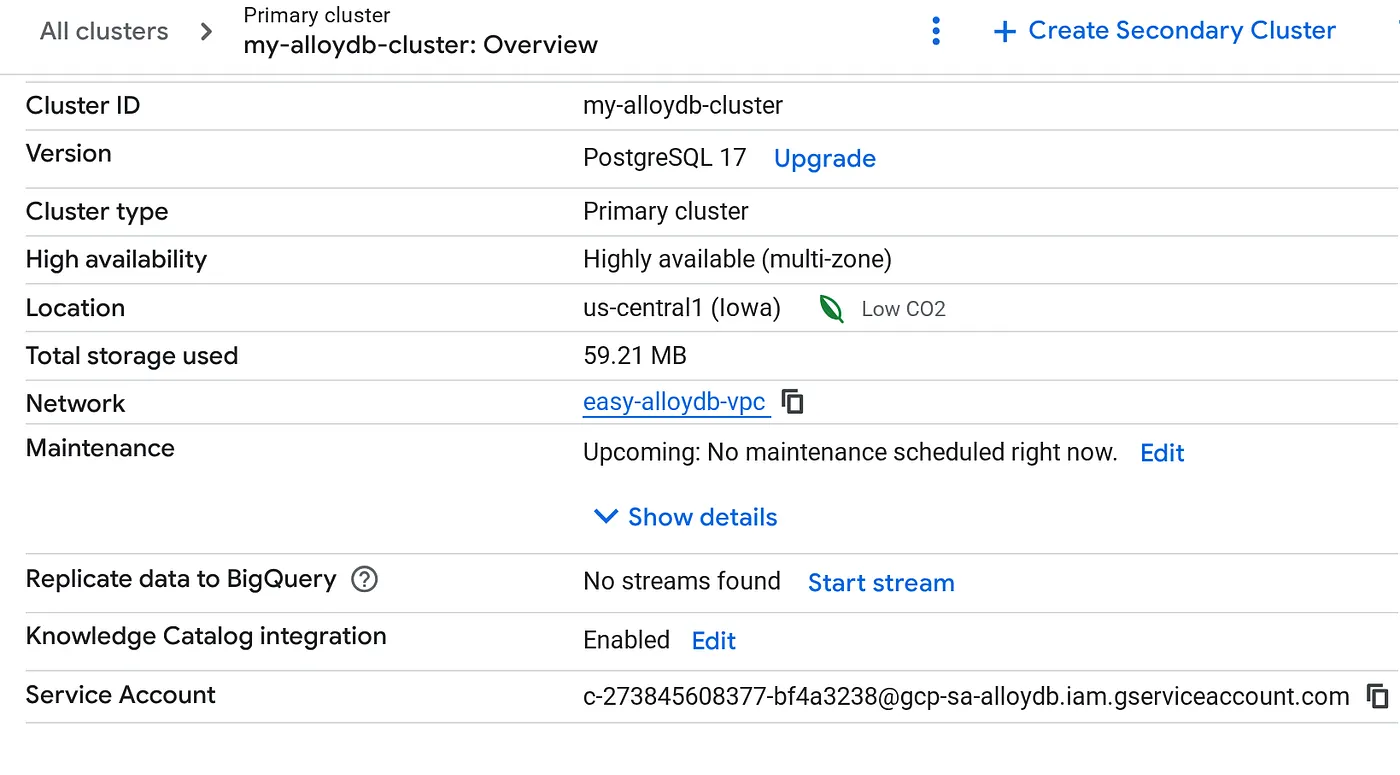
5. הגדרת הרשאות
הענקת הרשאות BigQuery לחשבון השירות הזה
- עוברים אל IAM & Admin > IAM.
- לוחצים על Grant Access (הענקת גישה).
- מדביקים את הכתובת של חשבון השירות של AlloyDB בשדה New principals (חשבונות משתמשים חדשים).
- מקצים את התפקידים הבאים:
- BigQuery Data Viewer (roles/bigquery.dataViewer): מאפשר קריאת הנתונים.
- BigQuery User (משתמש ב-BigQuery) (roles/bigquery.user): מאפשר להריץ את השאילתות.
- (אופציונלי, אבל מומלץ) משתמש בסשן קריאה של BigQuery (roles/bigquery.readSessionUser): מאפשר קריאה אופטימלית של מערכי נתונים גדולים באמצעות Storage Read API.
6. התחברות ל-AlloyDB והפעלת התוסף BigQuery
עכשיו מתחברים למופע AlloyDB החדש כדי להגדיר את תוסף הפדרציה. לצורך זה נשתמש ב-AlloyDB Studio.
- בדף 'סקירה כללית של האשכול' (מסוף AlloyDB), לוחצים על עריכת הראשי במופע הראשי וגוללים לתחתית אל אפשרויות מתקדמות להגדרה.
- עוברים לקטע Flags (דגלים) ומפעילים את 2 הדגלים למצב On (מופעל), כמו שמוצג בהמשך:
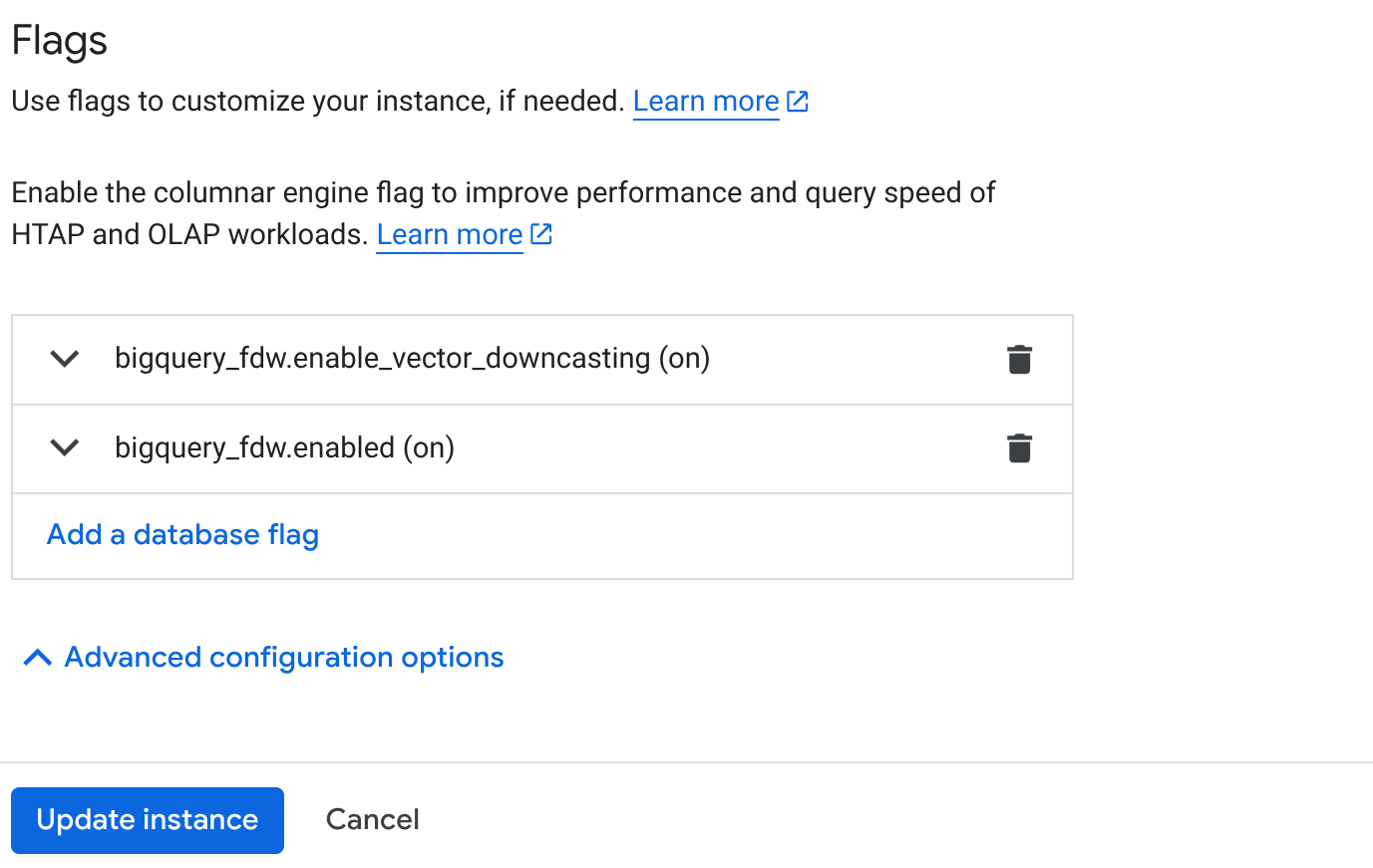 3. לוחצים על הלחצן Update instance (עדכון המכונה) והעדכון יימשך כמה דקות. 4. בדף Cluster Overview (סקירה כללית של האשכול) במסוף AlloyDB, לוחצים על AlloyDB Studio.
3. לוחצים על הלחצן Update instance (עדכון המכונה) והעדכון יימשך כמה דקות. 4. בדף Cluster Overview (סקירה כללית של האשכול) במסוף AlloyDB, לוחצים על AlloyDB Studio.
- מתחברים למסד הנתונים באמצעות שם המשתמש והסיסמה שהגדרתם בשלב ההגדרה המהירה של AlloyDB.
- אחרי שמתחברים, בכרטיסייה Query Editor (עורך השאילתות) בצד שמאל, מזינים את ההצהרות הבאות ומריצים אותן אחת אחרי השנייה:
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- אחרי שמסיימים בהצלחה, עוברים לחלונית הניווט בצד ימין וגוללים למטה אל BigQuery tables (טבלאות BigQuery):
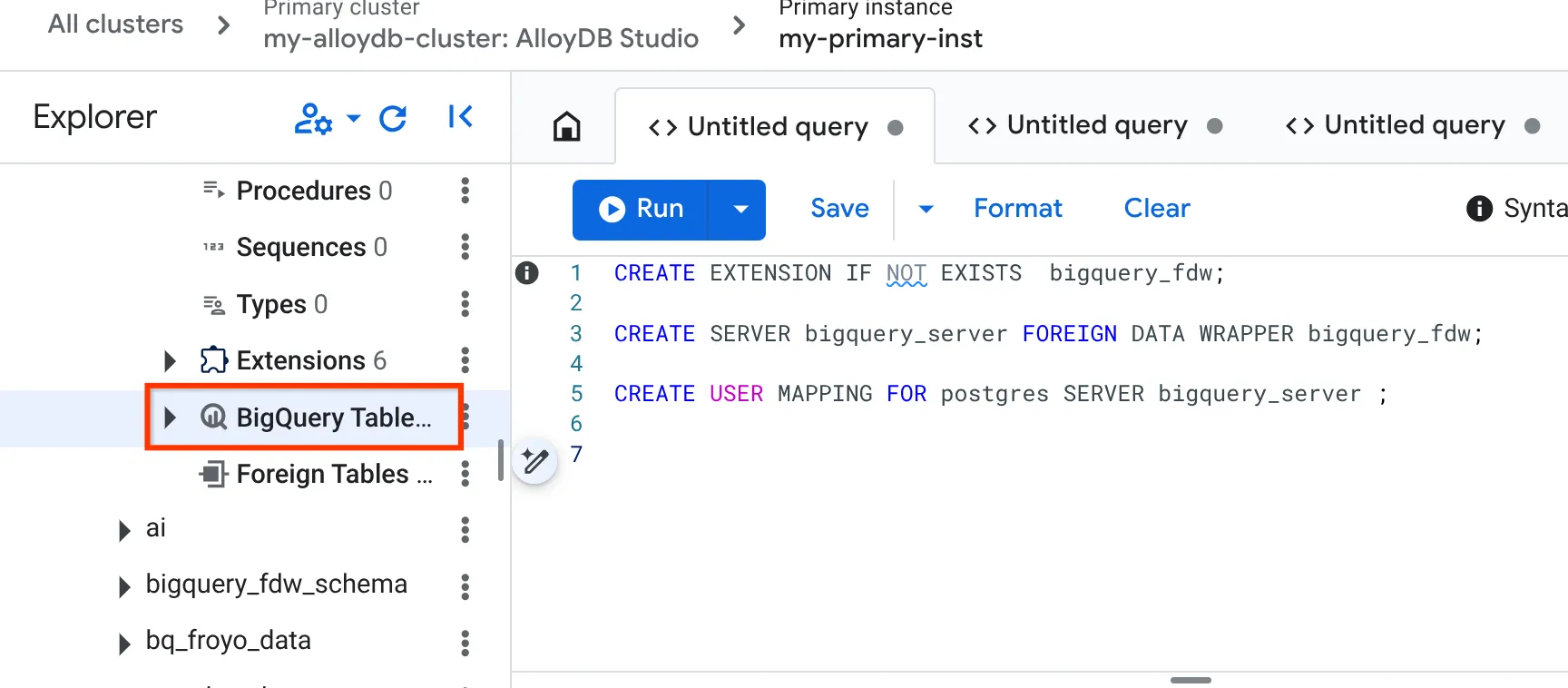
- לוחצים על סמל 3 הנקודות ואז על קישור טבלת BigQuery.
- בחלון הקופץ Connect BigQuery Table שנפתח, בוחרים את project_id ואת שם מערך הנתונים ב-BigQuery (שנוצר בחלק 1) שממנו רוצים לשלוח שאילתה לנתונים במסד הנתונים של AlloyDB.
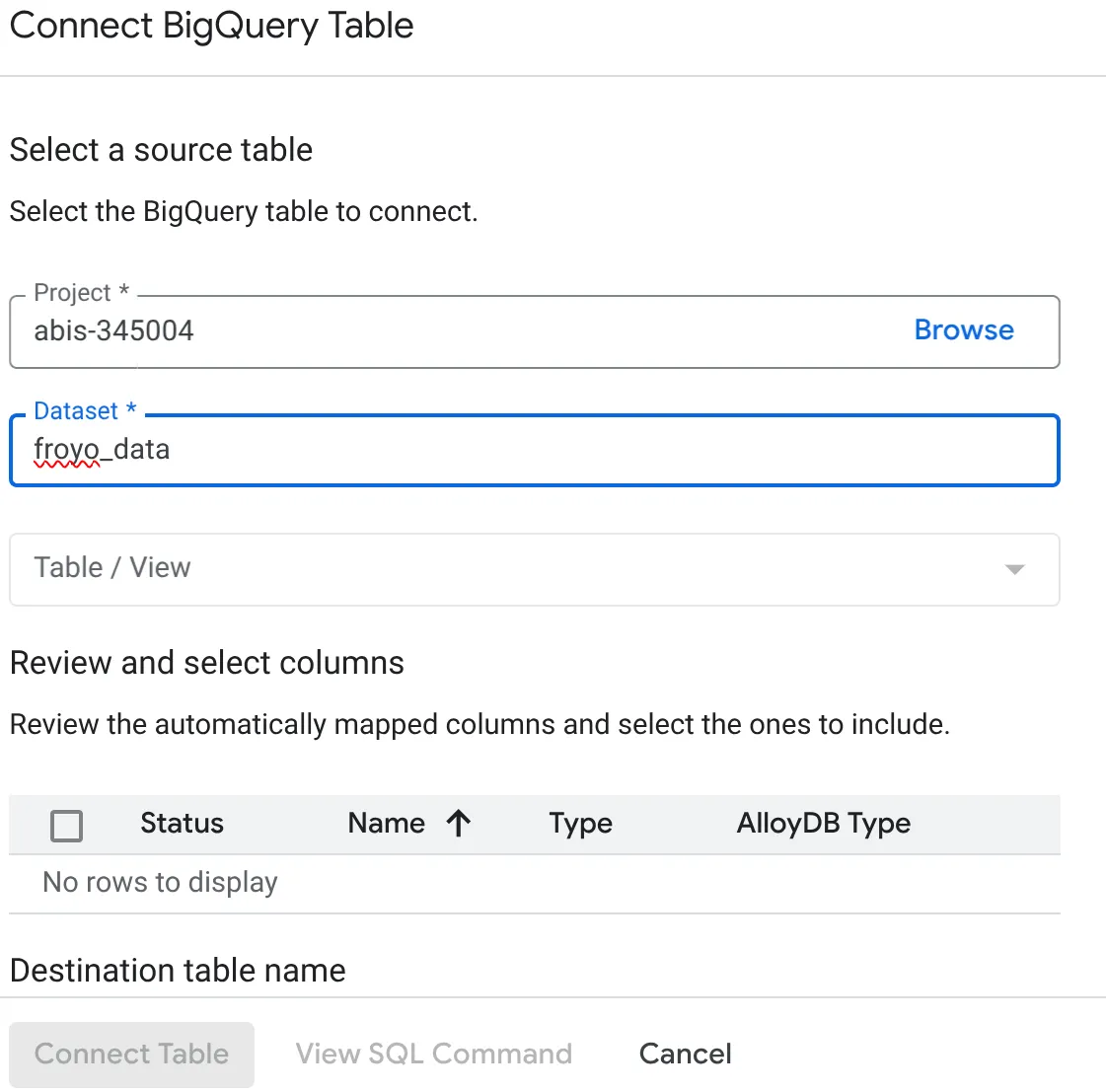
- בוחרים באפשרות כל טבלה בנפרד כדי לחבר את כל הנתונים ל-AlloyDB. אנחנו עושים את זה כדי לאמת את סוגי העמודות ולוודא שהם נתמכים ב-AlloyDB.
אם רוצים לעשות את אותו הדבר באמצעות SQL במקום באמצעות גישת הצבעה ולחיצה:
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
הקסם!!!
הרגע יצרנו 'טבלאות חיצוניות' ב-AlloyDB. הן נראות ומתנהגות כמו טבלאות רגילות של PostgreSQL, אבל הן לא מאחסנות נתונים. כשמריצים עליהם שאילתה, AlloyDB מעביר את השאילתה באופן מיידי ל-BigQuery, מאחזר את התוצאות ומחזיר אותן.
7. בדיקת הפדרציה ב-AlloyDB
נבדוק שאפשר להריץ שאילתות על מערך הנתונים הענק והאנליטי של BigQuery ישירות ממסד הנתונים הטרנזקציונלי של PostgreSQL.
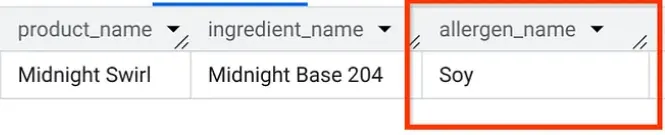
עדיין ב-AlloyDB Studio, נריץ שאילתה כדי לגלות אילו אלרגנים יש ב-Midnight Swirl (אותה שאלה ששאלנו בחלק 1, אבל הפעם נשאלת מ-AlloyDB):
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
Boom. אתם אמורים לראות את אותן תוצאות בדיוק כמו ב-BigQuery.
8. הסרת המשאבים
אחרי שמסיימים את ה-Lab הזה, חשוב למחוק את אשכול AlloyDB ואת המכונה.
הוא אמור לנקות את האשכול יחד עם המופעים שלו.
9. מזל טוב על שכבת הנתונים המאוחדת
בואו נחשוב על מה שהשגנו עכשיו:
- האפליקציה העסקית שלנו (שפועלת ב-AlloyDB) יכולה לטפל בסשנים מהירים של משתמשים בו-זמנית.
- כשהוא צריך נתונים אנליטיים מפורטים או הקשר היסטורי (כמו פרטי ספקים או מיפויים מורכבים של רכיבים), הוא שולח שאילתה ל-froyo_dataschema ב-BigQuery.
- Zero ETL. אין פייפליינים שמופעלים. אין מסדי נתונים לא מסונכרנים. אנחנו מאחסנים את הנתונים פעם אחת (ב-BQ) ומבצעים את החישובים במקום שבו אנחנו צריכים אותם.
עכשיו, אחרי שבנינו בסיס נתונים מוצק ומקושר – גם אנליטי וגם טרנזקציונלי – אנחנו מוכנים לחלק הכיפי.
בחלק 3, נבנה את אפליקציית ה-Multi-Agent שפועלת על גבי הארכיטקטורה הזו כדי להפעיל את הפעולות העסקיות של Froyo.