
1. खास जानकारी
हम सभी "डार्क डेटा" की समस्या से वाक़िफ़ हैं. ये क्लाउड स्टोरेज बकेट में मौजूद PDF, इमेज, और टेक्स्ट फ़ाइलें होती हैं. ये आपकी एसक्यूएल क्वेरी और बीआई डैशबोर्ड में नहीं दिखती हैं. पहले, इस डेटा को अनलॉक करने के लिए, जटिल ओसीआर पाइपलाइन, मैन्युअल डेटा एंट्री या कस्टम स्क्रिप्ट की ज़रूरत होती थी.
अब नहीं.
इस लैब में, हम आपको 400 अनस्ट्रक्चर्ड PDF फ़ाइलों को साफ़ तौर पर स्ट्रक्चर्ड BigQuery टेबल में बदलने का तरीका बताएंगे. इन फ़ाइलों में टेक्स्ट, टेबल, और इमेज शामिल हैं. साथ ही, हम आपको यह भी बताएंगे कि इन टेबल के बीच संबंध अपने-आप कैसे तय होते हैं. हम BigQuery Knowledge Catalog और Dataplex का इस्तेमाल करके, इसे कुछ ही मिनटों में पूरा करेंगे.
आपको क्या बनाना है
इसे समझने के लिए, आइए एक काल्पनिक कारोबार के बारे में जानते हैं: यह तेज़ी से बढ़ती हुई फ़्रोज़न योगर्ट फ़्रैंचाइज़ी है.
मान लें कि आपको इस फ़्रोयो कारोबार का डेटा मैनेज करना है. आपके पास सैकड़ों रेसिपी और सप्लायर की स्पेसिफ़िकेशन शीट हैं. ये सभी PDF के तौर पर सेव हैं. कारोबार के लीडर, एआई एजेंट लॉन्च करना चाहते हैं. इससे स्टोर मैनेजर और खरीदारों को प्रॉडक्ट की जानकारी के बारे में सवाल पूछने में मदद मिलेगी.
यहां एक मुश्किल स्थिति दी गई है: एक ग्राहक पूछता है, "मुझे आपके मिडनाइट स्वर्ल फ़्रोज़न योगर्ट में बहुत दिलचस्पी है. क्या इसमें कोई एलर्जन मौजूद है?"
इस सवाल का जवाब देने के लिए, आपके सिस्टम को आम तौर पर ये काम करने होंगे:
- "मिडनाइट स्वर्ल" रेसिपी का PDF ढूंढें.
- सामग्री पढ़ें. जैसे, "कोको पाउडर", "डेयरी बेस", "इमल्सिफ़ायर X".
- सप्लायर के दर्जनों PDF में खोज करके, उन खास सामग्रियों की स्पेसिफ़िकेशन शीट ढूंढें.
- सप्लायर की शीट में, उन सामग्रियों से जुड़े छिपे हुए ऐलर्जन देखें.
अगर आपको ऐसा एआई एजेंट बनाना है जो रनटाइम के दौरान 400 रॉ PDF पढ़कर, तुरंत जवाब दे सके, तो इसमें समय लगेगा और यह महंगा भी होगा. साथ ही, इसमें गलत जानकारी देने की संभावना भी ज़्यादा होगी. इसके बजाय, हम सिमैंटिक अनुमान का इस्तेमाल करके, इस सभी डेटा को पहले रिलेशनल डेटाबेस में एक्सट्रैक्ट करेंगे. इससे, आने वाले समय में हमारा एआई एजेंट बहुत तेज़ी से काम कर पाएगा और एसक्यूएल के तथ्यों पर आधारित डेटा पर 100% आधारित होगा.
चलिए, अब ऐप्लिकेशन बनाना शुरू करते हैं!
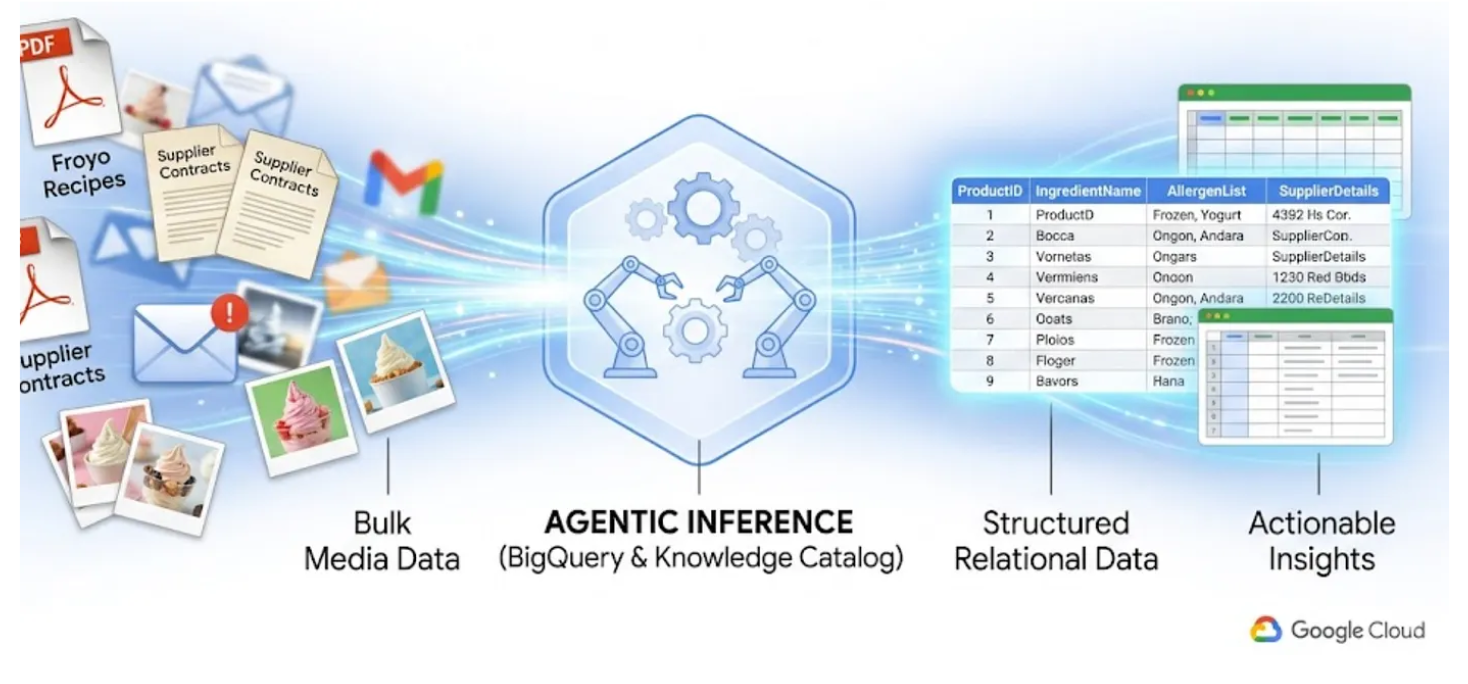
आपको क्या सीखने को मिलेगा
- सोर्स फ़ाइलों (PDF) के लिए Cloud Storage बकेट को सेट अप करने का तरीका
- सोर्स पीडीएफ़ से डेटा निकालने के लिए, Knowledge Catalog में डेटास्कैन जॉब और सिमैंटिक इन्फ़रेंस को सेट अप और चलाने का तरीका. साथ ही, कनेक्शन और कॉन्टेक्स्ट के बारे में सिमैंटिक इन्फ़रेंस का पता लगाने और उसे BigQuery में सेव करने का तरीका
- नए डेटासेट के साथ चैट करने के लिए, BigQuery एजेंटों का इस्तेमाल कैसे करें
ज़रूरी शर्तें
2. शुरू करने से पहले
प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर जाकर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग की सुविधा चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें.
- आपको Cloud Shell का इस्तेमाल करना होगा. यह Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.

- Cloud Shell से कनेक्ट होने के बाद, यह देखने के लिए कि आपकी पुष्टि हो चुकी है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर सेट किया गया है, इस कमांड का इस्तेमाल करें:
gcloud auth list
- यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं.
gcloud config list project
- अगर आपको पुष्टि करनी है
gcloud auth login
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- ज़रूरी एपीआई चालू करें: सभी ज़रूरी एपीआई चालू करने के लिए, यह निर्देश चलाएं:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
समस्याएं और उन्हें हल करने का तरीका
"घोस्ट प्रोजेक्ट" सिंड्रोम | आपने |
बिलिंग बैरिकेड | आपने प्रोजेक्ट चालू किया है, लेकिन बिलिंग खाते की जानकारी नहीं दी है. AlloyDB एक हाई-परफ़ॉर्मेंस इंजन है. अगर "गैस टैंक" (बिलिंग) खाली है, तो यह शुरू नहीं होगा. |
एपीआई के डेटा को अपडेट होने में लगने वाला समय | आपने "एपीआई चालू करें" पर क्लिक किया है, लेकिन कमांड लाइन में अब भी |
कोटा Quags | अगर आपने नया ट्रायल खाता इस्तेमाल करना शुरू किया है, तो हो सकता है कि आप AlloyDB इंस्टेंस के लिए क्षेत्र के हिसाब से तय किए गए कोटे तक पहुंच जाएं. अगर |
"छिपा हुआ" सर्विस एजेंट | कभी-कभी, AlloyDB सेवा एजेंट को |
3. Google Cloud Storage बकेट का सेटअप
इस सेक्शन में, BigQuery में एक संगठन का स्ट्रक्चर बनाया जाता है. इसमें Froyo की रेसिपी और सप्लायर का डेटा सेव किया जाता है. यह डेटा, खास तौर पर Froyo प्रॉडक्ट की जानकारी के लिए होता है. यह Cloud Resource Connection भी बनाता है. यह एक सुरक्षित "ब्रिज" के तौर पर काम करता है. इससे BigQuery, Cloud Storage जैसे बाहरी सोर्स से फ़ाइलें पढ़ पाता है.
शुरू करने से पहले:
इस डेटाबेस में रेसिपी और सप्लायर की PDF फ़ाइलें शामिल हैं. इनका इस्तेमाल हम इस प्रोजेक्ट में करेंगे. पक्का करें कि आपने इन फ़ाइलों को डाउनलोड कर लिया हो. फ़ाइलें डाउनलोड करने के लिए, यह तरीका अपनाएं.
Cloud Shell में, यह कमांड चलाएं:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
नए बनाए गए फ़ोल्डर में जाएं:
cd next-26-keynotes
data-cloud-demo फ़ोल्डर को पुल करें
git sparse-checkout set genkey/data-cloud-demo
चेकआउट पूरा होने के बाद, data-cloud-demo फ़ोल्डर पर जाएं और कोडलैब ऐसेट को ऐक्सेस करने के लिए, ZIP फ़ाइलों को एक्सट्रैक्ट करें.
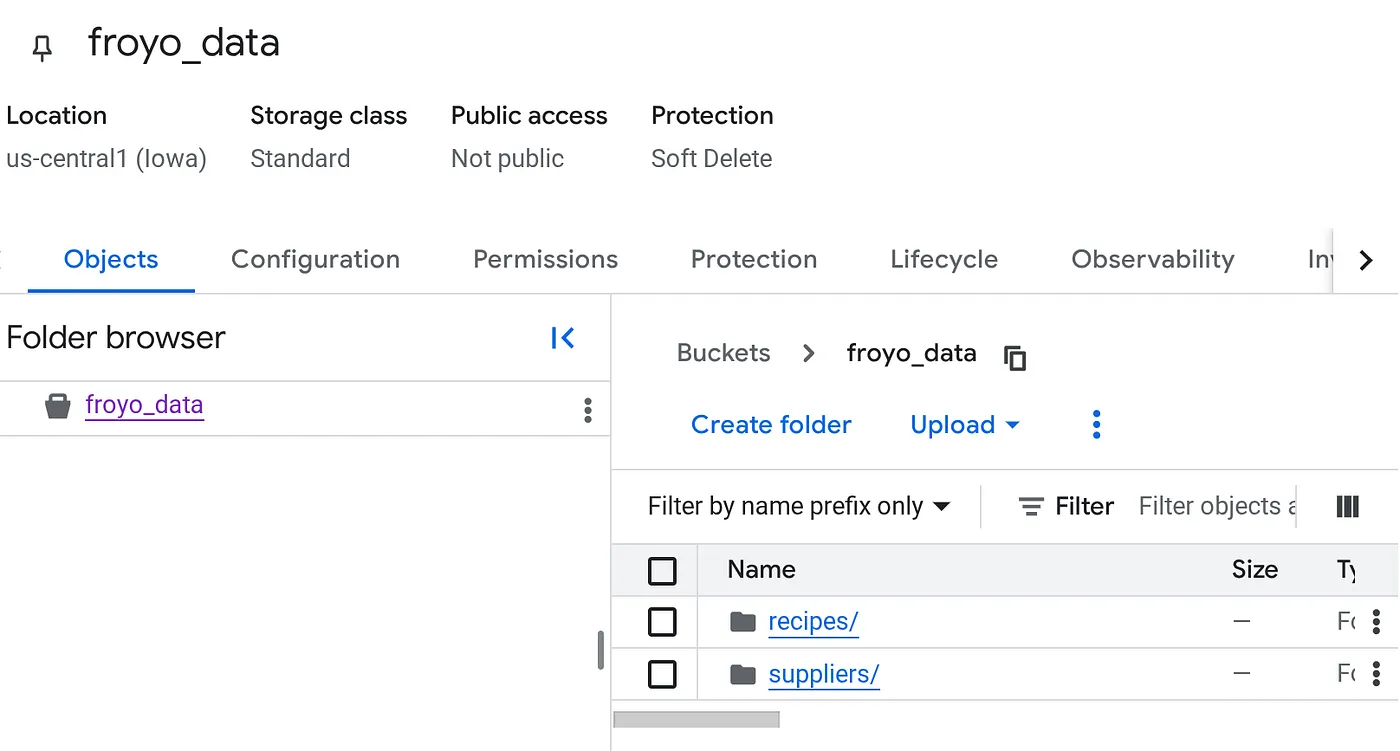
बकेट बनाएं और Froyo (रेसिपी और सप्लायर) की PDF फ़ाइलें अपलोड करें
- Google Cloud Console में, Cloud Storage बकेट पेज पर जाएं.
- 'बनाएं' पर क्लिक करें.
- बकेट बनाएं पेज पर, बकेट की जानकारी डालें. यहां दिए गए हर चरण को पूरा करने के बाद, अगले चरण पर जाने के लिए, जारी रखें पर क्लिक करें:
- शुरू करें सेक्शन में, बकेट का नाम डालें. उदाहरण के लिए: froyo_data
- आपको अपना डेटा कहां सेव करना है सेक्शन में, क्षेत्र चुनें. इसके बाद, अपना क्षेत्र डालें. us-central1
- ऑब्जेक्ट के ऐक्सेस को कंट्रोल करने का तरीका चुनें सेक्शन में जाकर, 'इस बकेट पर सार्वजनिक ऐक्सेस को रोकने की सुविधा लागू करें' चेकबॉक्स से सही का निशान हटाएं.
- 'बनाएं' पर क्लिक करें.
- बकेट की सूची में, बनाई गई बकेट पर क्लिक करें.
- बकेट के ऑब्जेक्ट टैब में, अपलोड करें और फिर फ़ोल्डर अपलोड करें पर क्लिक करें.
- recipes फ़ोल्डर चुनें. इसे आपने इस कोडलैब के 'शुरू करने से पहले' सेक्शन में एक्सट्रैक्ट किया था.
- अपलोड करें क्लिक करें.
- suppliers फ़ोल्डर के लिए, अपलोड करने की प्रोसेस दोहराएं.
अपलोड करने के बाद, आपके बकेट का स्ट्रक्चर ऐसा दिखना चाहिए (बकेट का नाम कुछ भी हो सकता है):
4. BigQuery कनेक्शन सेटअप करना
Cloud Resource Connection बनाएं. इससे एक यूनीक सेवा खाता जनरेट होता है. यह बाहरी फ़ाइलों को ऐक्सेस करने के लिए, BigQuery के "आईडी कार्ड" के तौर पर काम करता है.
- BigQuery पेज पर जाएं.
- बाईं ओर मौजूद पैनल में, एक्सप्लोरर पर क्लिक करें. अगर आपको बायां पैनल नहीं दिखता है, तो पैनल खोलने के लिए, बाएं पैनल को बड़ा करें पर क्लिक करें.
- एक्सप्लोरर पैनल में, अपने प्रोजेक्ट के नाम को बड़ा करें. इसके बाद, कनेक्शन पर क्लिक करें.
- कनेक्शन पेज पर, कनेक्शन बनाएं पर क्लिक करें.
- कनेक्शन टाइप के लिए, Vertex AI रिमोट मॉडल, रिमोट फ़ंक्शन, BigLake, और Spanner (क्लाउड रिसॉर्स) चुनें.
- कनेक्शन आईडी फ़ील्ड में, कनेक्शन आईडी का नाम डालें:
- bq-connection. इस आईडी को नोट करना न भूलें. आपको इसकी ज़रूरत तब पड़ेगी, जब इस कोडलैब में बाद में डेटा स्कैन करने की सुविधा सेट अप की जाएगी.
- जगह के टाइप को 'देश/इलाका' पर सेट करें. इसके बाद, कोई देश/इलाका चुनें. उदाहरण के लिए, us-central1. कनेक्शन, उसी इलाके में होना चाहिए जहां आपके अन्य संसाधन मौजूद हैं. जैसे, डेटासेट.
- कनेक्शन बनाएं पर क्लिक करें.
- कनेक्शन पर जाएं पर क्लिक करें.
- कनेक्शन की जानकारी वाले पैनल में, सेवा खाता आईडी कॉपी करें, ताकि इसका इस्तेमाल बाद में किया जा सके. सेवा खाता, bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com जैसा दिखता है.
5. अनुमतियां सेट अप करना
- Cloud Storage ऑब्जेक्ट और Knowledge Catalog को ऐक्सेस करने के लिए, BigQuery कनेक्शन को ज़रूरी अनुमतियां दें
आईएएम और एडमिन पेज पर जाएं. इसके बाद, 'प्रिंसिपल के हिसाब से देखें' सेक्शन में जाकर, 'ऐक्सेस दें' बटन पर क्लिक करें. इसके बाद, पिछले चरण में कॉपी किए गए सेवा खाते को चिपकाकर, प्रिंसिपल जोड़ें. भूमिकाएं सेक्शन में जाकर, एक-एक करके इन भूमिकाओं के नाम जोड़ें और सेव करें:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- Dataplex सेवा खाते को Cloud Storage बकेट ऐक्सेस करने की अनुमतियां देना
IAM और एडमिन पेज पर जाएं. इसके बाद, प्रिंसिपल के हिसाब से देखें सेक्शन में, ऐक्सेस दें बटन पर क्लिक करें. इसके बाद, dataplex शब्द को नए प्रिंसिपल के टेक्स्ट बार में टाइप करके, प्रिंसिपल जोड़ें. अपने-आप पूरी होने वाली सूची में से, Dataplex सेवा खाते का वह प्रिंसिपल चुनें जो इस तरह दिखता हो: (नीचे दिए गए सेवा खाते के ईमेल पते में प्रोजेक्ट आईडी के बजाय प्रोजेक्ट नंबर का इस्तेमाल करें)
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
अगर किसी वजह से, आपके प्रोजेक्ट नंबर के लिए ऊपर दिया गया सेवा खाता नहीं पहचाना जा रहा है, तो हो सकता है कि प्रोजेक्ट ने अब तक Dataplex सेवा शुरू न की हो. Cloud Shell टर्मिनल पर जाएं. अगर आपने शुरू करने से पहले वाले चरण में एपीआई चालू नहीं किया है, तो इसे चालू करने के लिए यह कमांड चलाएं: gcloud services enable dataplex.googleapis.com
इसके बाद भी, अगर Dataplex के लिए सर्विस खाते की पहचान नहीं हो रही है, तो मेटाडेटा क्यूरेशन पेज में जाकर, Dataplex स्कैन जॉब को ज़बरदस्ती टेस्ट करें. साथ ही, 'डिस्कवर' जॉब बनाने वाले पेज पर यह जानकारी डालें:
अभी चलाएं पर क्लिक करें. जॉब पूरा नहीं होगा. हालांकि, इससे यह पक्का हो जाएगा कि अब आपकी Dataplex सेवा के लिए, सेवा खाते का आईडी शुरू हो गया है.
IAM और एडमिन पेज पर वापस जाएं. इसके बाद, प्रिंसिपल के हिसाब से देखें सेक्शन में जाकर, ऐक्सेस दें बटन पर क्लिक करें. इसके बाद, प्रिंसिपल जोड़ें पर क्लिक करें. सेवा खाता चिपकाएं:
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
इसके बाद, इस सेवा खाते को ये भूमिकाएं असाइन करें:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. नॉलेज कैटलॉग का सेटअप
अनस्ट्रक्चर्ड डेटा को एक जगह इकट्ठा करने के लिए, नॉलेज कैटलॉग बनाएं. साथ ही, अनस्ट्रक्चर्ड फ़ाइलों (जैसे कि पीडीएफ़ फ़ॉर्मैट में रेसिपी और पीडीएफ़ फ़ॉर्मैट में सप्लायर) को अपने-आप ढूंढने की सुविधा चालू करें.
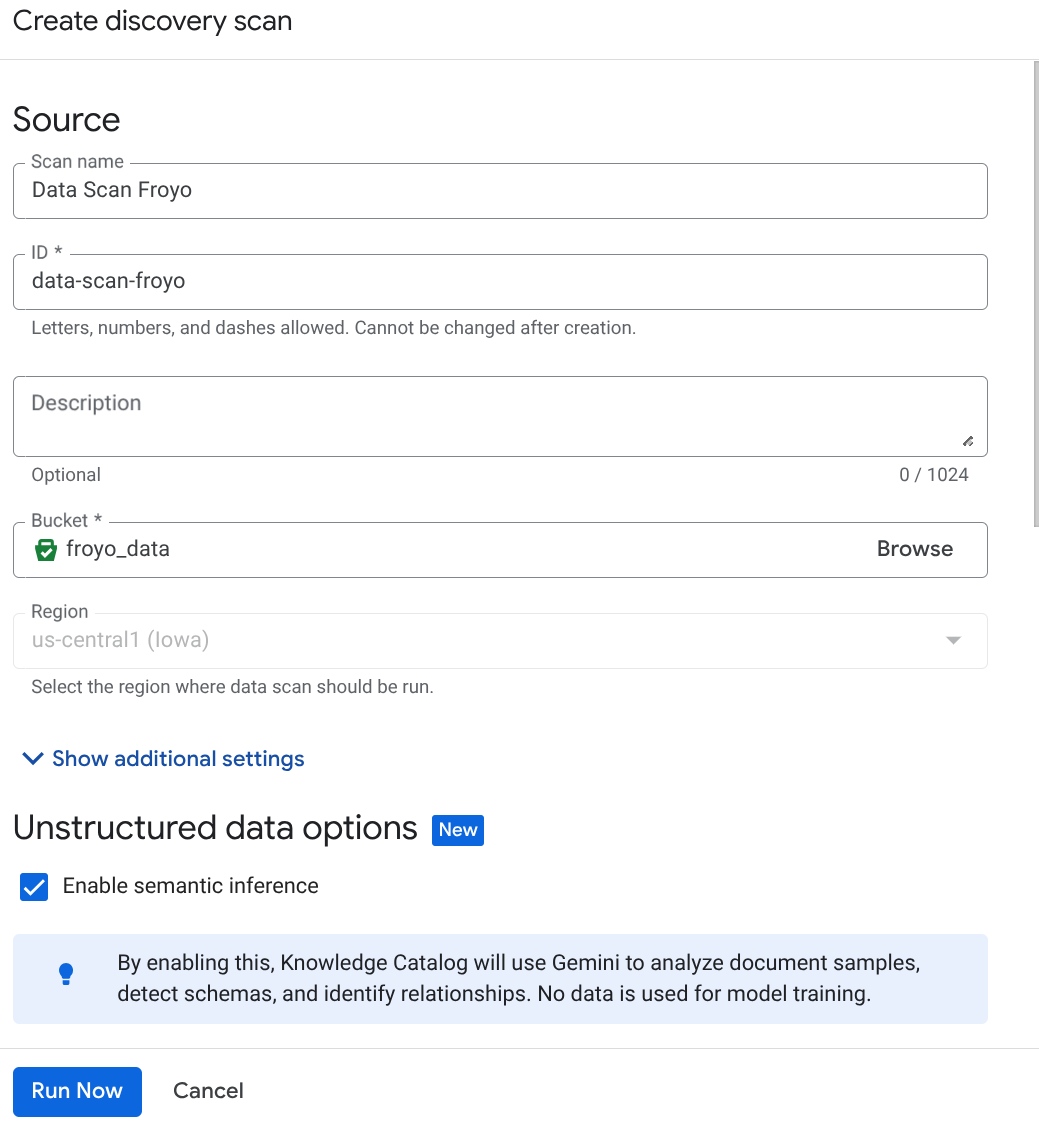
कंसोल से DataScan जॉब बनाएं:
- मेटाडेटा क्यूरेशन पेज पर जाएं.
- 'बनाएं' पर क्लिक करें और अपने सेटअप से जुड़ी जानकारी डालें:
अहम जानकारी: सिमेंटिक इन्फ़रेंस की सुविधा चालू करना न भूलें.
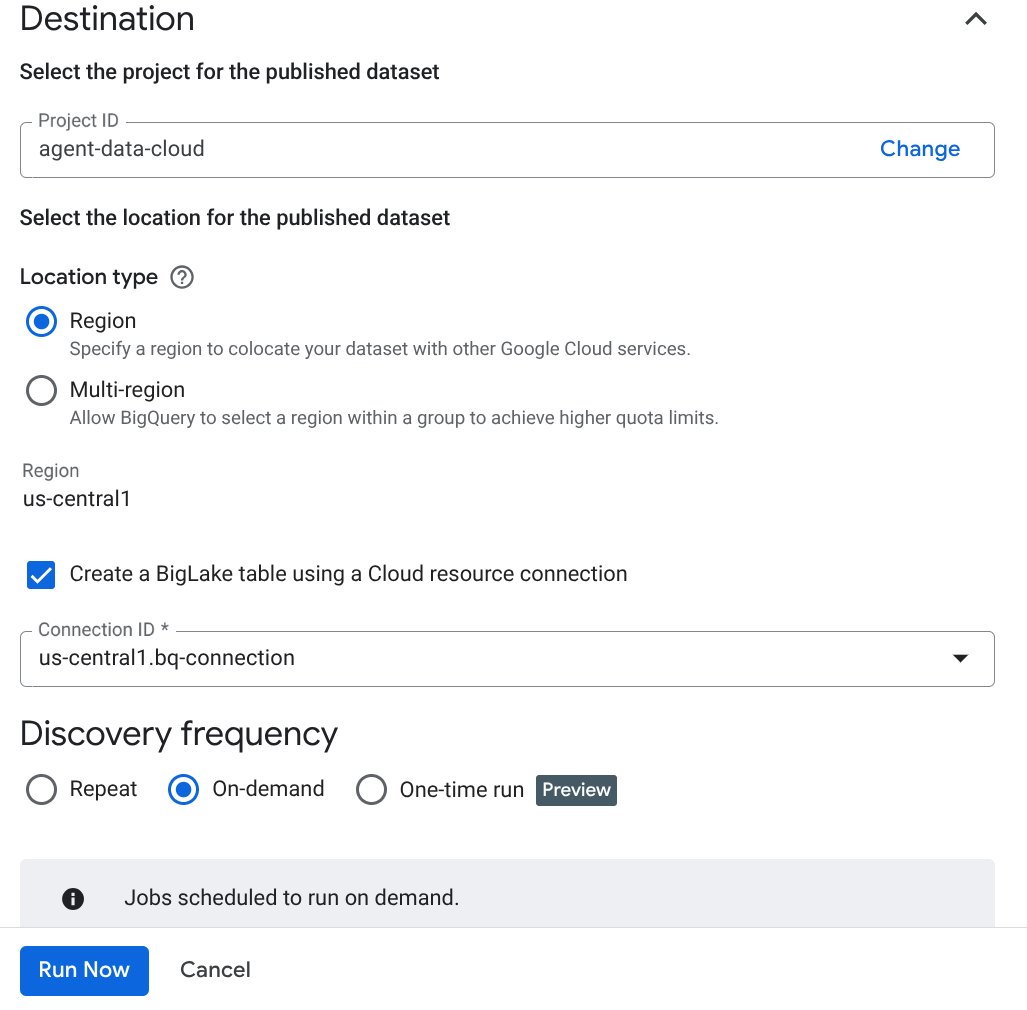
- "अभी चलाएं" पर क्लिक करें.
- स्कैन करने की प्रोसेस पूरी होने में कुछ समय लगेगा. जॉब पूरा होने के बाद, देखें कि पब्लिश किया गया डेटासेट मौजूद है या नहीं. जॉब का स्टेटस देखने के लिए, मेटाडेटा क्यूरेशन पेज पर जाएं. इसके बाद, Cloud Storage डिस्कवरी टैब में जाकर, हाल ही में किए गए डिस्कवरी स्कैन के नाम पर क्लिक करें. आपको पब्लिश किया गया डेटासेट इस तरह दिखेगा:
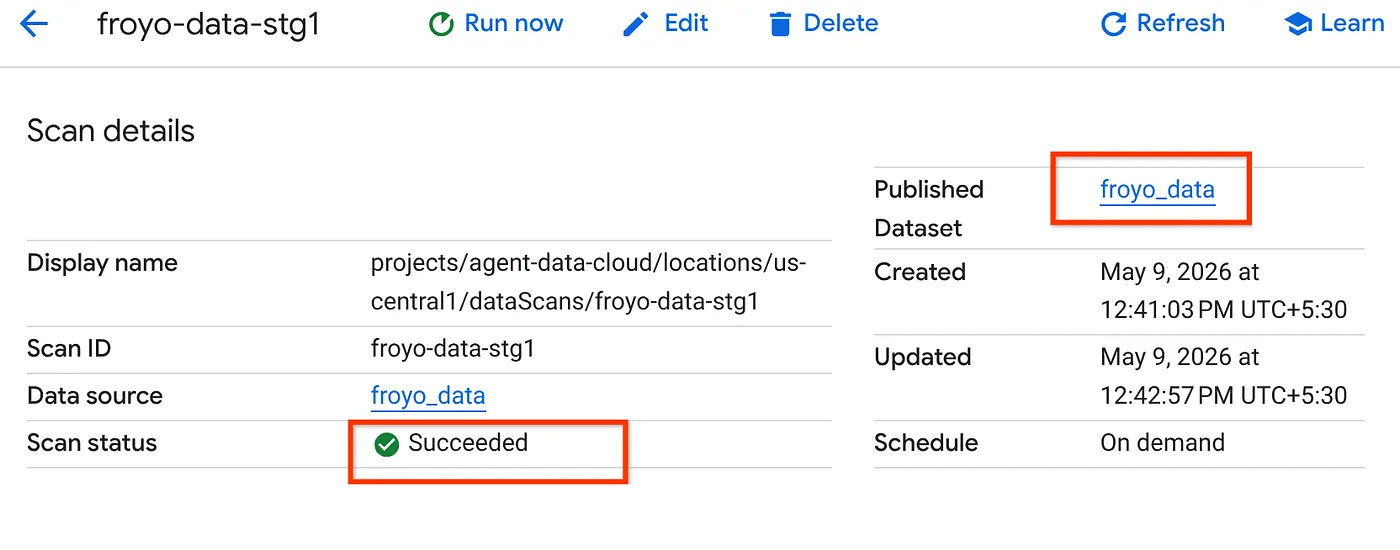
ध्यान दें: अगर स्कैन करने के चरण में आपको गड़बड़ियां मिलती हैं, तो कुछ समय इंतज़ार करें. इसके बाद, फिर से कोशिश करें. जॉब बनाने और उसे पूरा करने में कुछ मिनट लगते हैं.
- BigQuery में टेबल देखने के लिए, froyo_data डेटासेट पर क्लिक करें और उस पर जाएं. BigQuery में टेबल आईडी पर क्लिक करें और क्वेरी एडिटर टैब में नीचे दी गई क्वेरी चलाएं:
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
इससे 400 मिलता है. अगर ऐसा नहीं होता है, तो वापस जाकर डेटास्कैन जॉब को फिर से चलाएं.
7. सिमैंटिक डेटा एक्सट्रैक्शन
बहुत बढ़िया!! अब नॉलेज कैटलॉग का इस्तेमाल करके, इन अनस्ट्रक्चर्ड ऑब्जेक्ट के लिए अनुमान निकालते हैं.
हम इनसाइट जनरेट करने की सुविधा का इस्तेमाल करके, एसक्यूएल स्टेटमेंट जनरेट करेंगे. इससे अनस्ट्रक्चर्ड टेबल से स्ट्रक्चर्ड डेटा निकाला जा सकेगा
- Google Cloud Console में, नॉलेज कैटलॉग खोजें पेज पर जाएं.
- उस डेटासेट टेबल को खोजें जिसके लिए आपको अहम जानकारी देखनी है. खोज बार में, पिछले चरण में इस्तेमाल किया गया डेटासेट / टेबल का नाम डालें: "froyo_data" और Enter दबाएं
- नतीजों की सूची में, टेबल एंट्री पर क्लिक करें (डेटासेट वाली एंट्री पर नहीं)
- आपको अहम जानकारी टैब दिखेगा. उस पर क्लिक करें. अगर आपको कोई एपीआई चालू करना है, तो निर्देशों का पालन करें और सिर्फ़ एपीआई चालू करें.
अगर आपने इस चरण में एपीआई चालू कर दिए हैं, तो आपको स्कैन करने की प्रोसेस फिर से शुरू करनी होगी.
- आपको 'खास जानकारी' टैब में, 'डेटा एक्सट्रैक्ट करें' बटन का ड्रॉप-डाउन दिखेगा. उस पर क्लिक करें और "SQL की मदद से डेटा निकालना" विकल्प चुनें.
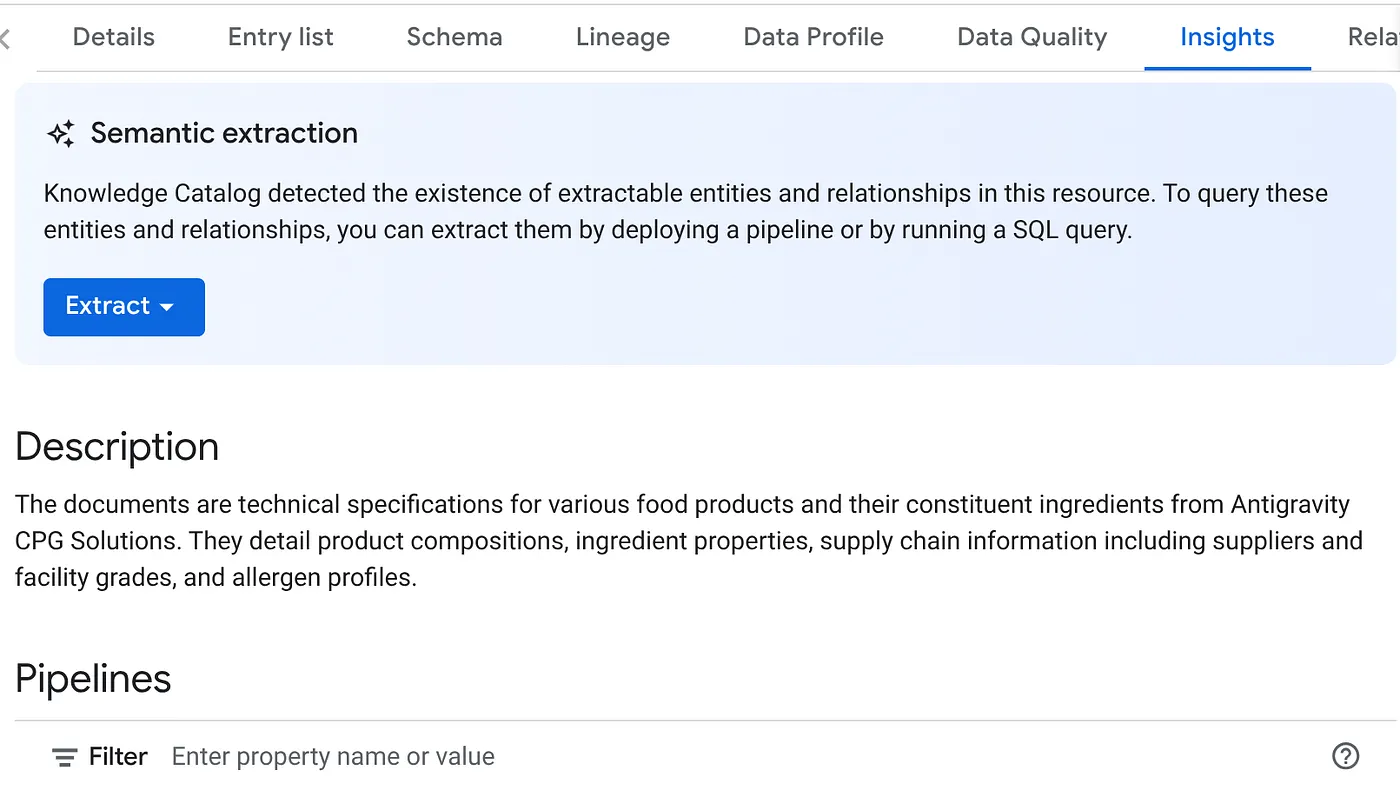
"Extract with SQL" डायलॉग पॉप-अप में, DESTINATION डेटासेट को उस डेटासेट के तौर पर सेट करें जो आपको डेटास्कैन जॉब के नतीजे में दिखा था. उसका नाम टाइप करना शुरू करें. इसके बाद, वह नाम अपने-आप पूरा होने लगेगा. "निकालें" बटन पर क्लिक करें. इसके अलावा, इस समय एक नया डेटासेट बनाया जा सकता है और उसे एक्सट्रैक्ट किया जा सकता है.
इससे BigQuery क्वेरी एडिटर खुलना चाहिए. इसमें एक टैब खुला होगा. इसमें डेटा स्कैन करने के बाद निकाली गई एसक्यूएल क्वेरी मौजूद होगी.
8. एसक्यूएल की पुष्टि करना और स्कीमा बनाना
अगर जनरेट की गई क्वेरी सही लगती है और आपके अनस्ट्रक्चर्ड डेटा के हिसाब से सिमैंटिक तौर पर सही है, तो क्वेरी एडिटर में मौजूद 'चलाएं' बटन पर क्लिक करके इसे रन करें. आपके अव्यवस्थित मीडिया को व्यवस्थित तरीके से सेव करने के लिए ज़रूरी स्कीमा बनाने में कुछ मिनट लगेंगे.
इसके बाद, आपको स्कीमा की पुष्टि करने का विकल्प मिलेगा. इसके लिए, BigQuery Studio के एक्सप्लोरर पैनल में डेटासेट को बड़ा करें. इसे यहां दिखाया गया है:
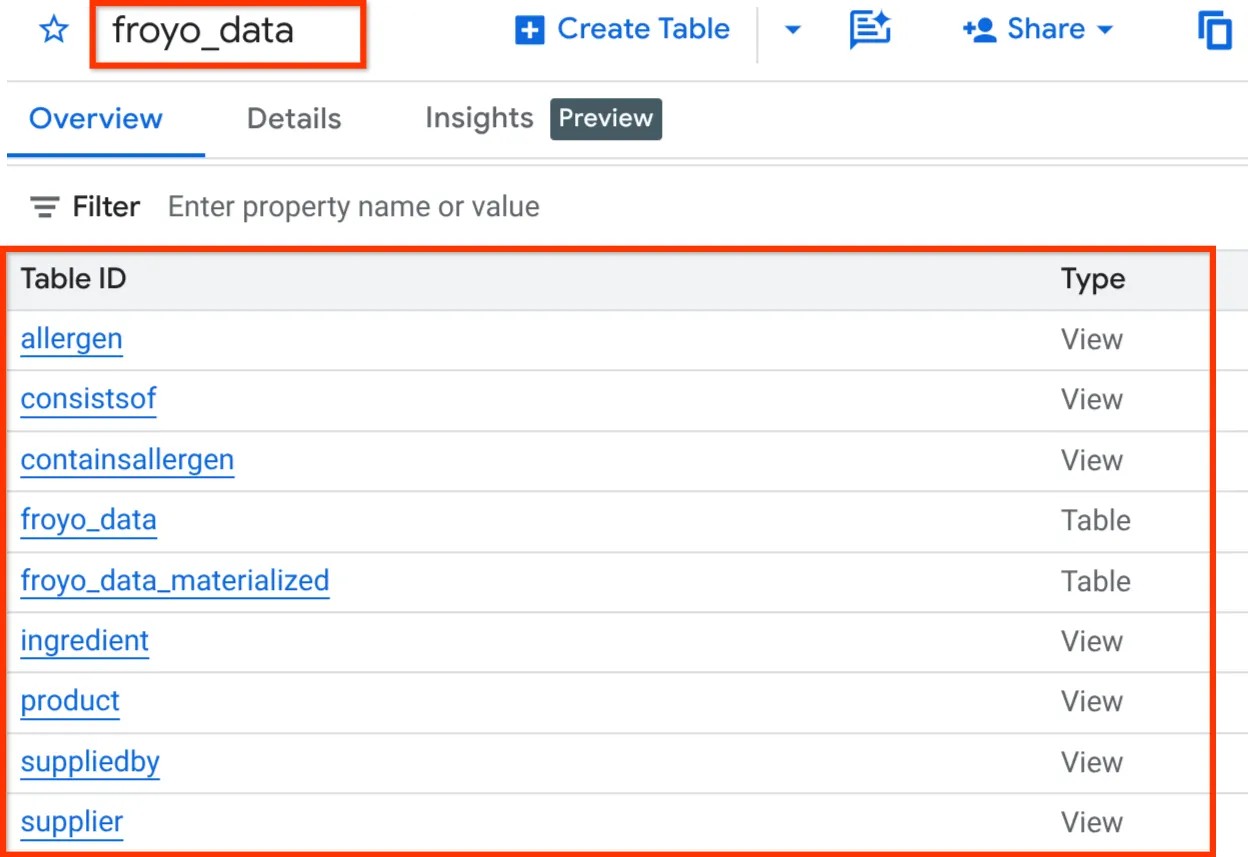
ठीक है!!! यह बहुत अच्छा था कि हमने डेटाबेस से जुड़ी सभी कार्रवाइयां बहुत तेज़ी से कीं. अब समय है आखिरी परीक्षा का!
बिलिंग खाते के बिना डेटा का इस्तेमाल जारी रखने का तरीका:
- ऊपर दिए गए github repo लिंक से, csv फ़ाइलों (BigQuery डेटा) का डेटा पाया जा सकता है.
- सबसे पहले, Cloud Shell टर्मिनल से नीचे दिए गए निर्देश को चलाकर BigQuery डेटासेट बनाएं:
bq mk --location us-central1 --dataset froyo_data
- इसके बाद, github repo से आठ डेटा फ़ाइलें (csv फ़ाइलें) अपनी वर्किंग डायरेक्ट्री में डाउनलोड करें. इसके लिए, एक-एक करके ये कमांड चलाएं:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- नई टेबल बनाने के लिए, एक-एक करके ये कमांड चलाएं. इन टेबल में, आपके नए डेटासेट का डेटा होगा
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
डेटासेट, टेबल, और डेटा बनाने के बाद, उस डेटा की जांच की जा सकती है जिसके बारे में हमने अभी बात की है.
9. सबसे मुश्किल परीक्षा!!!
मान लें कि मुझे अपने एजेंट से, लोगों के सवालों के जवाब में तथ्यों पर आधारित, सही, पूरी, और व्यवस्थित जानकारी देनी है. मैं एक ऐसा सवाल पूछने जा रहा/रही हूं जिसका जवाब एजेंट सिर्फ़ मेरी मीडिया फ़ाइलों और सोर्स के रेफ़रंस से दे पाएगा.
उपयोगकर्ता का सवाल यहां दिया गया है:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
अब सामान्य खोज या एलएलएम खोज में, "कोई सामग्री नहीं" दिखेगा. हालांकि, हमने पूरी तरह से सिमैंटिक इन्फ़रेंस बनाया है. इससे हमारे सभी अनस्ट्रक्चर्ड मीडिया को स्ट्रक्चर्ड डेटा में बदला जा सकता है. इसलिए, यहां एक आसान एसक्यूएल दिया गया है, जो यह जानकारी फ़ेच करेगा:
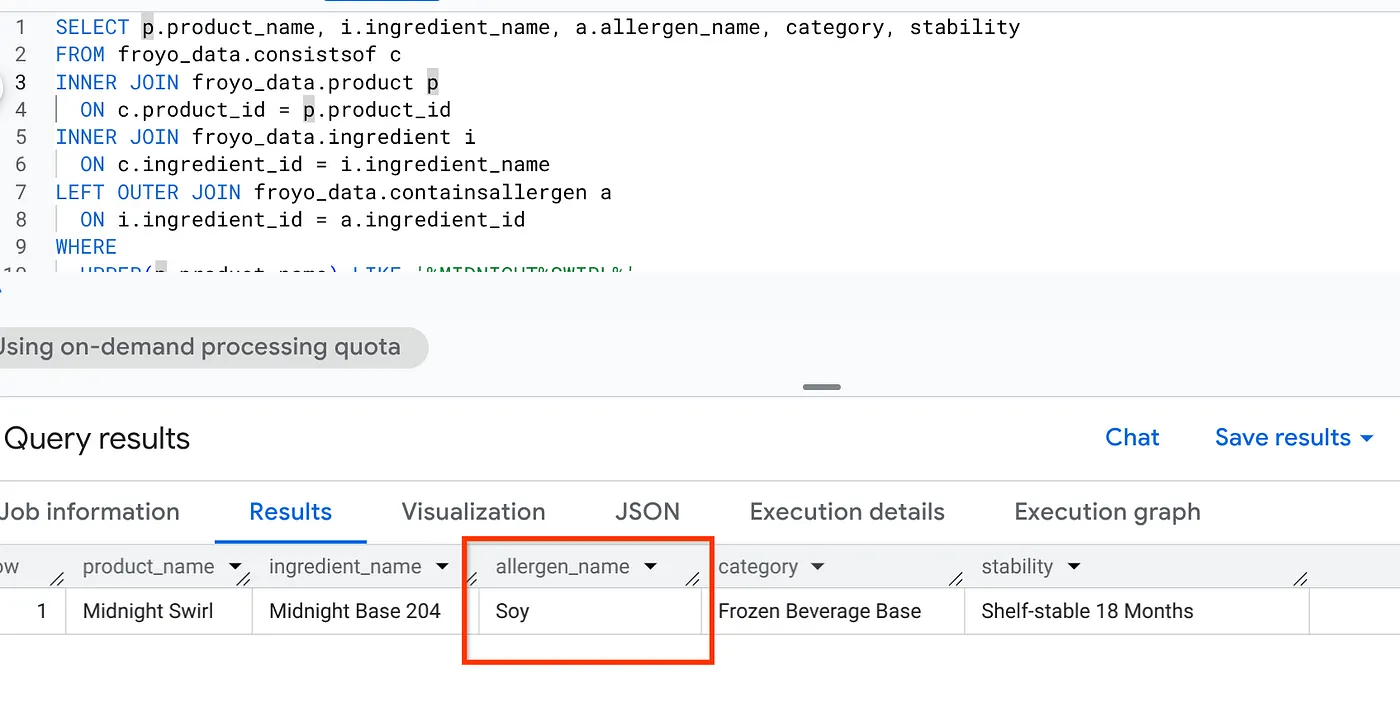
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
बहुत बढ़िया! नतीजा देखें:
10. व्यवस्थित करें
यह लैब पूरा होने के बाद, स्कैन जॉब और उस जॉब से बनी BigQuery टेबल को मिटाना न भूलें.
https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery पर जाएं. आपको जिस नौकरी को मिटाना है उसे चुनें. इसके लिए, उसके बगल में मौजूद तीन बिंदु वाले आइकॉन पर क्लिक करें. इसके बाद, मिटाएं पर क्लिक करें.
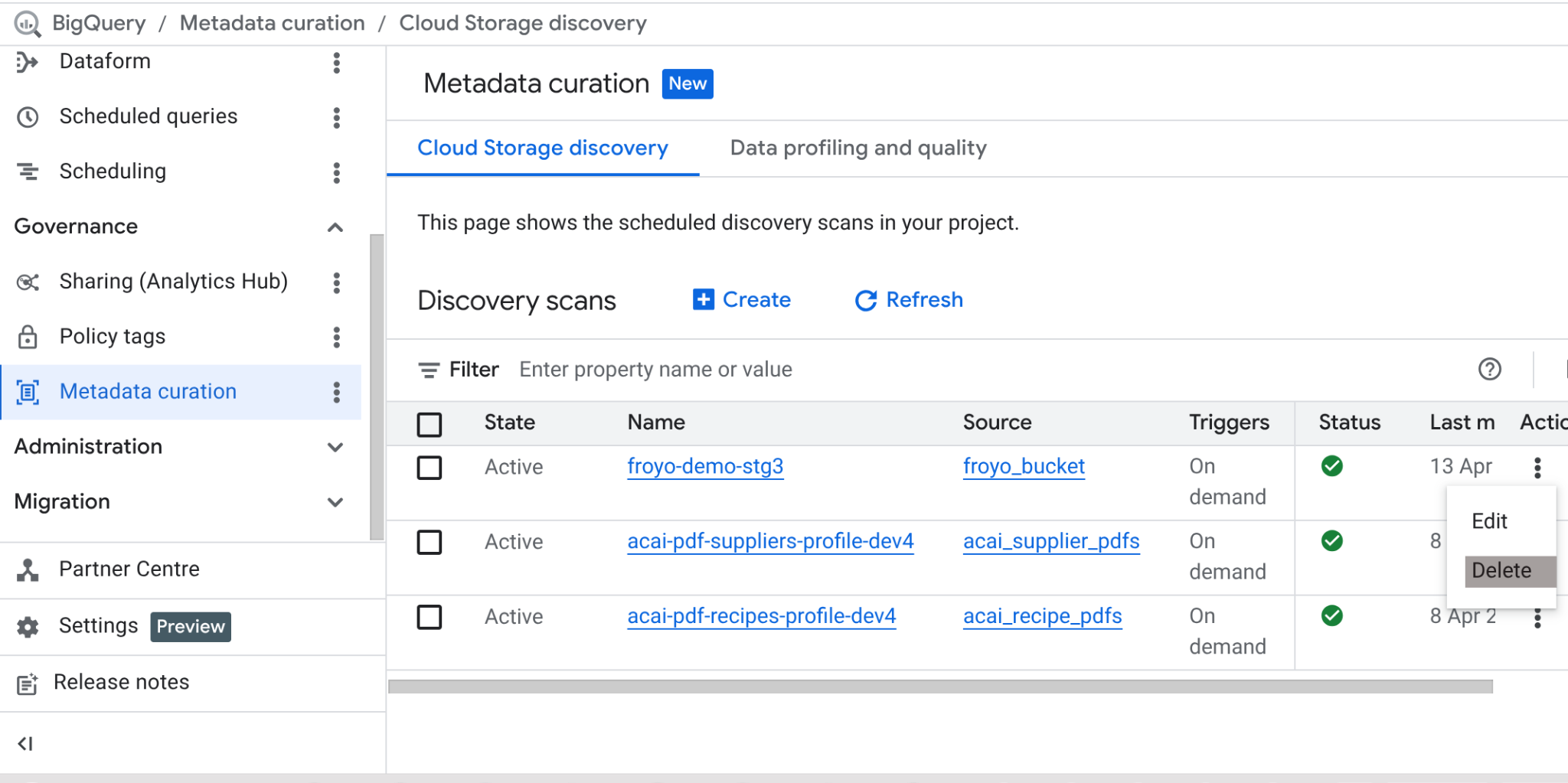
इससे नौकरी से जुड़ी जानकारी मिट जाएगी.
11. बधाई हो
हमारे सिस्टम ने, छिपे हुए ऐलर्जन की पहचान कर ली है. अब कम रोशनी में लिए गए डेटा की ज़रूरत नहीं है!!! दूसरे हिस्से में, हम इस BigQuery डेटा को AlloyDB के साथ लेन-देन वाले सिस्टम में फ़ेडरेट करेंगे, ताकि हमारे एजेंटिक ऐप्लिकेशन के लिए डेटा की ज़रूरतों को पूरा किया जा सके.