
1. खास जानकारी
पहले हिस्से में, हमने Knowledge Catalog और DataScan का इस्तेमाल करके, अनस्ट्रक्चर्ड और अव्यवस्थित PDF को BigQuery में साफ़-सुथरी, बेहतर, और स्ट्रक्चर्ड टेबल में बदला. अब हमारे पास एक मज़बूत डेटा वेयरहाउस है.
अगर आपको याद नहीं है, तो पहले पार्ट की लैब में हमने एक काल्पनिक फ़्रोज़न योगर्ट फ़्रैंचाइज़ी का इस्तेमाल किया था. हमने उसके 400 अनस्ट्रक्चर्ड PDF फ़ाइलों को साफ़ तौर पर स्ट्रक्चर्ड BigQuery टेबल में बदला था. इन फ़ाइलों में टेक्स्ट, टेबल, और इमेज शामिल थीं. साथ ही, BigQuery Knowledge Catalog और Dataplex का इस्तेमाल करके, उनके बीच के संबंध अपने-आप तय किए गए थे.
आपको क्या बनाना है
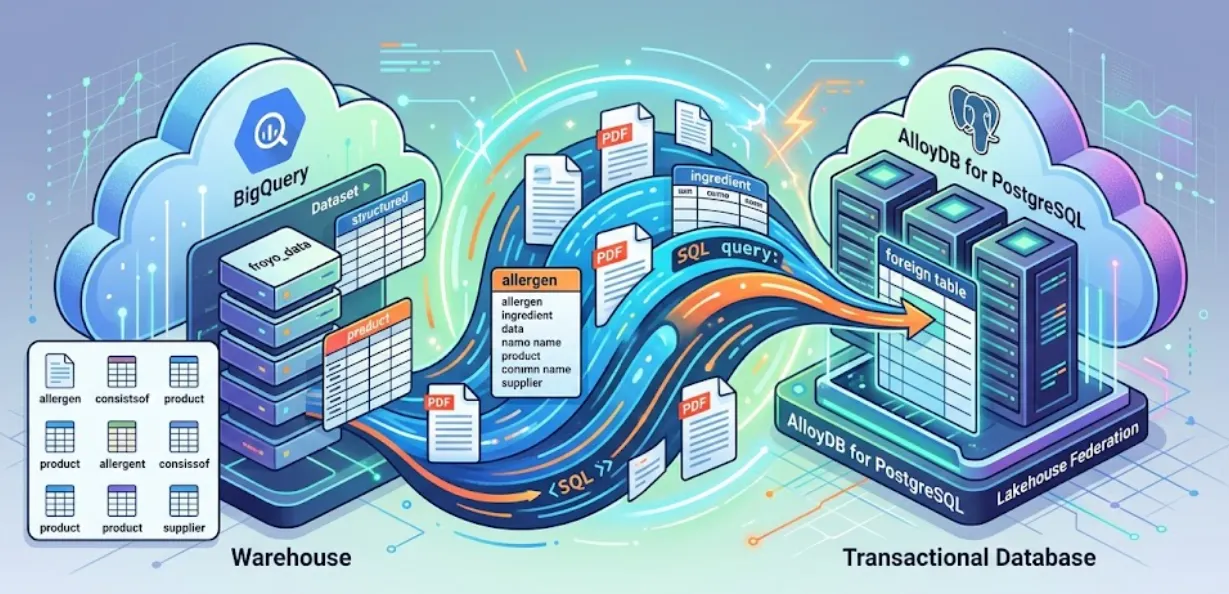
इस सेशन में, हम AlloyDB for PostgreSQL को सेट अप कर रहे हैं. साथ ही, हम कुछ ऐसा कर रहे हैं जो पहले कभी नहीं हुआ: हम अपने BigQuery डेटा को सीधे AlloyDB में फ़ेडरेट कर रहे हैं. इसका मतलब है कि हमारा लेन-देन वाला ऐप्लिकेशन, हमारे वेयरहाउस डेटा को रीयल-टाइम में क्वेरी कर सकता है. इसके लिए, उसे किसी भी डेटा को कॉपी या डुप्लीकेट करने की ज़रूरत नहीं होती.
डेवलपर के तौर पर, आपको इस चरण में यह सवाल पूछना होगा:
"अगर डेटा पहले से ही BigQuery में है, तो AlloyDB को क्यों इस्तेमाल करें? ऐप्लिकेशन, BigQuery के डेटा पर सीधे तौर पर SELECT स्टेटमेंट क्यों नहीं चलाता?"
यहां इसकी वजह बताई गई है:
लेकहाउस फ़ेडरेशन की मदद से, एक ही इंटरफ़ेस में AlloyDB के क्वेरी इंजन का इस्तेमाल करके, अपने ऐप्लिकेशन के लेन-देन और विश्लेषण से जुड़े वर्कलोड को मैनेज किया जा सकता है. इस डेटा को AlloyDB पर इंपोर्ट किया जा सकता है, ताकि इसे अपने ऐप्लिकेशन में तेज़ी से ऐक्सेस किया जा सके. इससे आपको AlloyDB AI और कॉलम इंजन का इस्तेमाल करने की सुविधा मिलती है.
AlloyDB का इस्तेमाल, लेन-देन वाले डेटाबेस के तौर पर किया जा सकता है. साथ ही, BigQuery या BigLake में बड़ी मात्रा में डेटा स्टोर किया जा सकता है. आपके ऐप्लिकेशन, आम तौर पर इन दोनों सिस्टम के साथ अलग-अलग तरीके से इंटिग्रेट होते हैं, ताकि Google Cloud की इन अलग-अलग सेवाओं का डेटा ऐक्सेस किया जा सके. AlloyDB के लिए Lakehouse Federation की मदद से, AlloyDB की फ़ेडरेटेड क्वेरी की सुविधा का इस्तेमाल किया जा सकता है. इसे फ़ॉरेन डेटा रैपर के तौर पर लागू किया जाता है. इससे AlloyDB में SQL इंटरफ़ेस का इस्तेमाल करके, BigQuery और AlloyDB के डेटा को ऐक्सेस किया जा सकता है.
AlloyDB से BigQuery डेटा की क्वेरी करने के लिए, हम कमज़ोर ईटीएल पाइपलाइन बनाने के बजाय फ़ेडरेटेड क्वेरी का इस्तेमाल करेंगे. AlloyDB, यूनिफ़ाइड एंडपॉइंट के तौर पर काम करेगा. ज़रूरत पड़ने पर, यह BigQuery को आसानी से ऐक्सेस कर सकेगा.
आइए, बनाना शुरू करें!
आपको क्या सीखने को मिलेगा
- एक बटन पर क्लिक करके, AlloyDB क्लस्टर, इंस्टेंस, और नेटवर्किंग को सेट अप करने का तरीका
- फ़ेडरेशन के लिए तैयारी करने के लिए एक्सटेंशन सेट अप करने का तरीका
- BigQuery से AlloyDB में फ़ेडरेशन सेट अप करने का तरीका
- इसे आज़माएं
ज़रूरी शर्तें
2. शुरू करने से पहले
प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. यह देखने का तरीका जानें कि किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं.
- आपको Cloud Shell का इस्तेमाल करना होगा. यह Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.

- Cloud Shell से कनेक्ट होने के बाद, यह देखने के लिए कि आपकी पुष्टि हो चुकी है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर सेट किया गया है, इस कमांड का इस्तेमाल करें:
gcloud auth list
- यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं.
gcloud config list project
- अगर आपको पुष्टि करनी है
gcloud auth login
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- ज़रूरी एपीआई चालू करें: सभी ज़रूरी एपीआई चालू करने के लिए, यह निर्देश चलाएं:
gcloud services enable alloydb.googleapis.com
समस्याएं और उन्हें हल करने का तरीका
"घोस्ट प्रोजेक्ट" सिंड्रोम | आपने |
बिलिंग बैरिकेड | आपने प्रोजेक्ट चालू कर दिया है, लेकिन बिलिंग खाते की जानकारी नहीं दी है. AlloyDB एक हाई-परफ़ॉर्मेंस इंजन है. अगर "गैस टैंक" (बिलिंग) खाली है, तो यह शुरू नहीं होगा. |
एपीआई के डेटा को अपडेट होने में लगने वाला समय | आपने "एपीआई चालू करें" पर क्लिक किया है, लेकिन कमांड लाइन में अब भी |
कोटा Quags | अगर आपने नया ट्रायल खाता इस्तेमाल करना शुरू किया है, तो हो सकता है कि आप AlloyDB इंस्टेंस के लिए क्षेत्र के हिसाब से तय किए गए कोटे तक पहुंच जाएं. अगर |
3. पहले हिस्से के डेटा की खास जानकारी
इस सेक्शन में, आपको यह पक्का करना होगा कि अनस्ट्रक्चर्ड PDF से निकाला गया स्ट्रक्चर्ड डेटा, BigQuery में उपलब्ध हो. अगर आपने पहला हिस्सा नहीं देखा है या आपके पास बिलिंग खाता नहीं है, तो कोई बात नहीं. यहां दिए गए चरणों को पूरा करके, आगे बढ़ा जा सकता है:
अपने निजी Gmail खाते से Google Cloud Console पर जाएं और कंसोल के सबसे ऊपर दाएं कोने में मौजूद, Cloud Shell चालू करें बटन पर क्लिक करें:
इसके बाद, 'बिलिंग खाता नहीं है' सेक्शन में दिया गया तरीका अपनाएं:
बिलिंग खाते के बिना डेटा का इस्तेमाल जारी रखने का तरीका:
- ऊपर दिए गए github repo लिंक से, csv फ़ाइलों (BigQuery डेटा) का डेटा पाया जा सकता है.
- सबसे पहले, Cloud Shell टर्मिनल से नीचे दिए गए निर्देश को चलाकर BigQuery डेटासेट बनाएं:
bq mk --location us-central1 --dataset froyo_data
- इसके बाद, github repo से आठ डेटा फ़ाइलें (csv फ़ाइलें) अपनी वर्किंग डायरेक्ट्री में डाउनलोड करें. इसके लिए, एक-एक करके ये कमांड चलाएं:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- अपने नए डेटासेट में मौजूद डेटा के साथ ये टेबल बनाने के लिए, एक-एक करके ये कमांड चलाएं
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
अब हमारे पास BigQuery में डेटा है. इसलिए, आइए अगले चरणों पर चलते हैं.
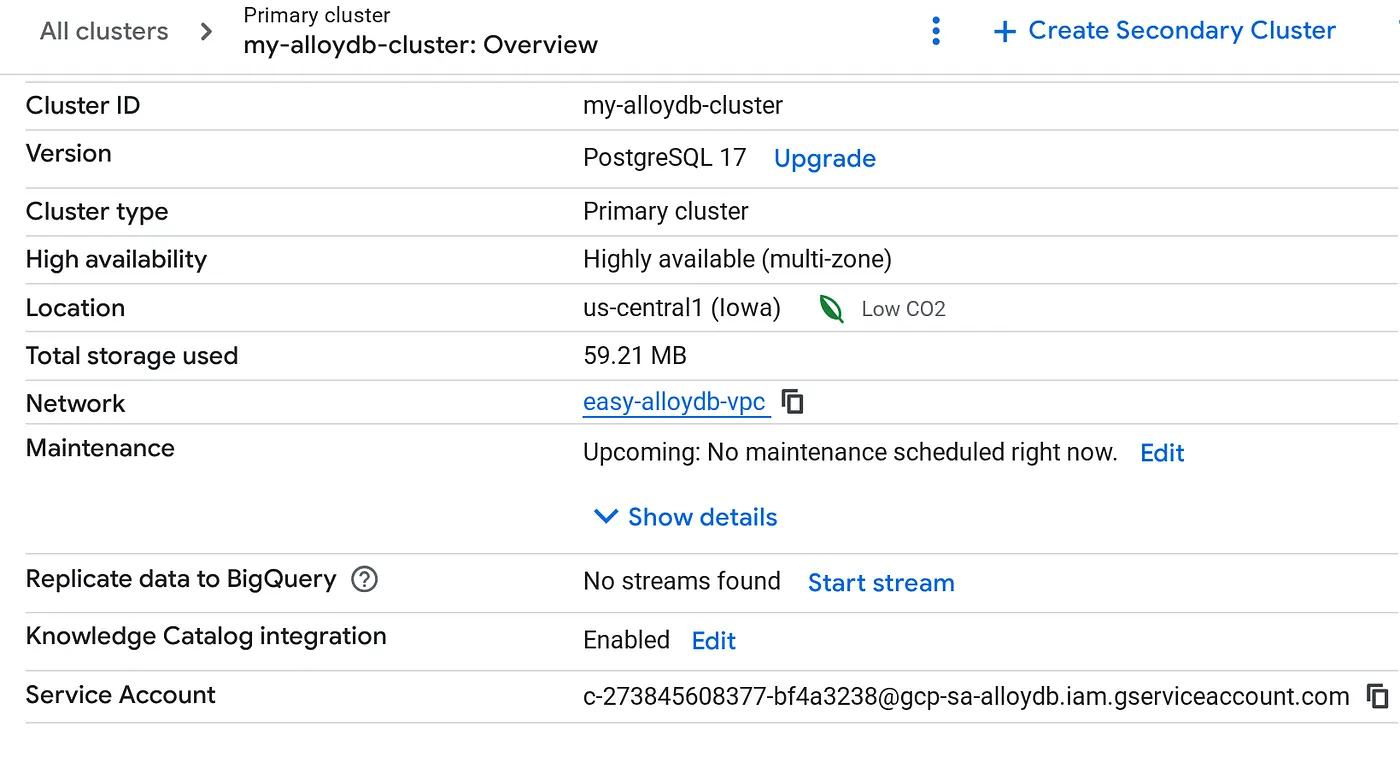
4. AlloyDB क्लस्टर, इंस्टेंस, और नेटवर्क सेटअप करना
वेब पर आधारित एक क्विक स्टार्ट ऐप्लिकेशन उपलब्ध है. इससे आपको AlloyDB क्लस्टर, इंस्टेंस, और अन्य डिपेंडेंसी सेट अप करने में मदद मिलेगी. इसे एक बटन पर क्लिक करके सेट अप करने के लिए, इस लैब में दिए गए चरण 2 से 4 तक का तरीका अपनाएं:
https://codelabs.developers.google.com/quick-alloydb-setup
क्लस्टर बन जाने के बाद, क्लस्टर की खास जानकारी वाले पेज पर जाएं और वहां से सेवा खाते की जानकारी कॉपी करें.
5. अनुमतियां सेट अप करना
इस सेवा खाते को BigQuery की अनुमतियां देना
- आईएएम और एडमिन > आईएएम पर जाएं.
- 'ऐक्सेस दें' पर क्लिक करें.
- AlloyDB सेवा खाते के पते को 'नए प्रिंसिपल' फ़ील्ड में चिपकाएं.
- ये भूमिकाएं असाइन करें:
- BigQuery डेटा व्यूअर (roles/bigquery.dataViewer): इससे डेटा को पढ़ने की अनुमति मिलती है.
- BigQuery उपयोगकर्ता (roles/bigquery.user): इससे क्वेरी चलाने की अनुमति मिलती है.
- (ज़रूरी नहीं, लेकिन सुझाव दिया जाता है) BigQuery Read Session User (roles/bigquery.readSessionUser): यह भूमिका, Storage Read API के ज़रिए बड़े डेटासेट को पढ़ने की प्रोसेस को ऑप्टिमाइज़ करती है.
6. AlloyDB से कनेक्ट करना और BigQuery एक्सटेंशन चालू करना
अब हम फ़ेडरेशन एक्सटेंशन को कॉन्फ़िगर करने के लिए, अपने नए AlloyDB इंस्टेंस से कनेक्ट करते हैं. इसके लिए, हम AlloyDB Studio का इस्तेमाल करेंगे.
- AlloyDB कंसोल में, क्लस्टर की खास जानकारी वाले पेज पर जाएं. इसके बाद, अपने प्राइमरी इंस्टेंस पर "प्राइमरी में बदलाव करें" पर क्लिक करें. इसके बाद, नीचे की ओर स्क्रोल करके "ऐडवांस कॉन्फ़िगरेशन के विकल्प" पर जाएं.
- "फ़्लैग" सेक्शन पर जाएं और नीचे दिए गए तरीके से, दोनों फ़्लैग को "चालू करें":
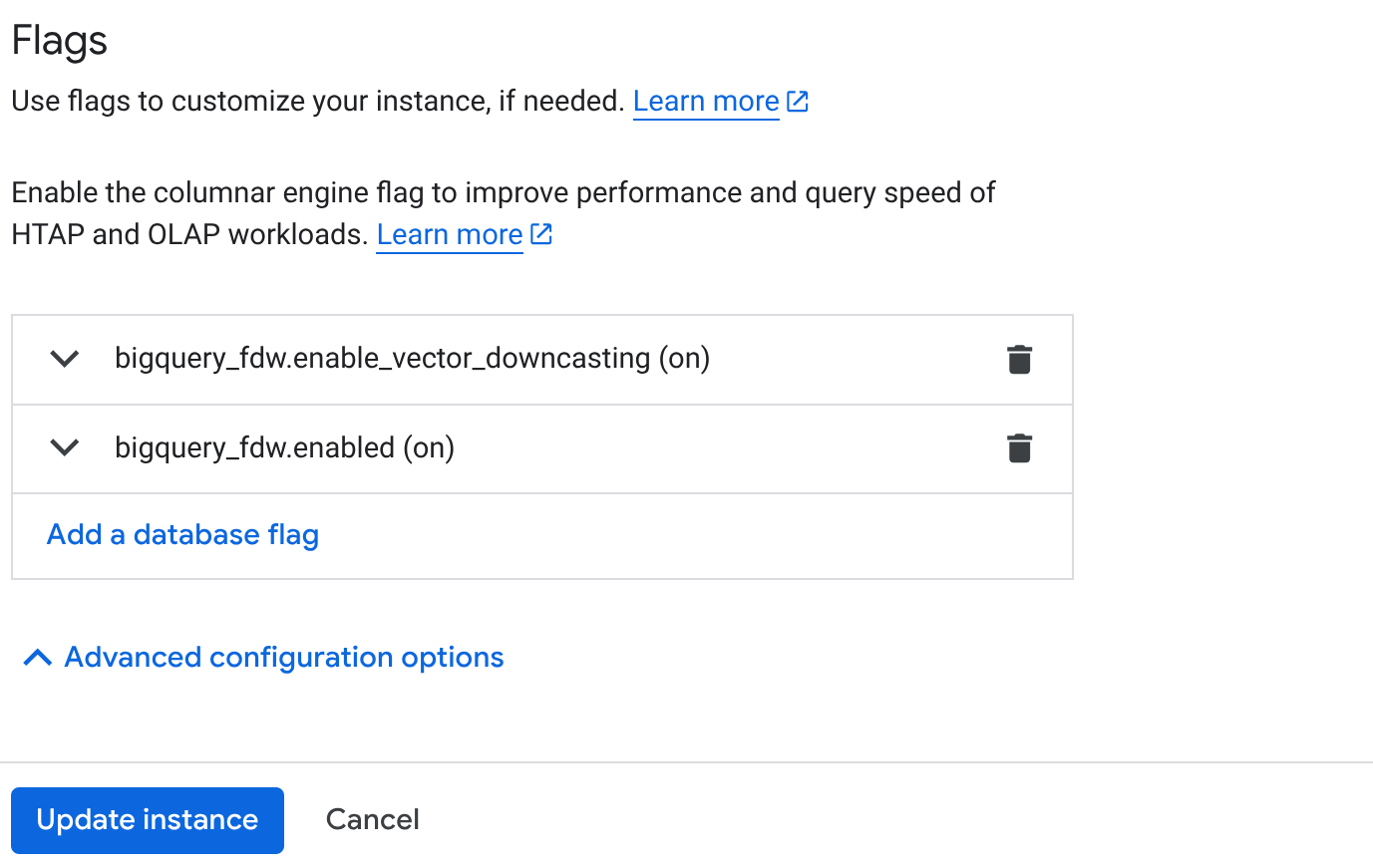 3. अपडेट इंस्टेंस बटन पर क्लिक करें. अपडेट होने में कुछ मिनट लगेंगे. 4. क्लस्टर की खास जानकारी देने वाले पेज (AlloyDB कंसोल) पर जाकर, AlloyDB Studio पर क्लिक करें.
3. अपडेट इंस्टेंस बटन पर क्लिक करें. अपडेट होने में कुछ मिनट लगेंगे. 4. क्लस्टर की खास जानकारी देने वाले पेज (AlloyDB कंसोल) पर जाकर, AlloyDB Studio पर क्लिक करें.
- अपने डेटाबेस, उपयोगकर्ता नाम, और पासवर्ड से कनेक्ट करें. इन्हें AlloyDB के क्विक सेटअप के दौरान कॉन्फ़िगर किया गया था.
- कनेक्ट होने के बाद, दाईं ओर मौजूद क्वेरी एडिटर टैब पर, ये स्टेटमेंट डालें और एक-एक करके चलाएं:
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- यह प्रोसेस पूरी होने के बाद, बाईं ओर मौजूद एक्सप्लोरर पैन पर जाएं और नीचे की ओर स्क्रोल करके BigQuery टेबल पर जाएं:
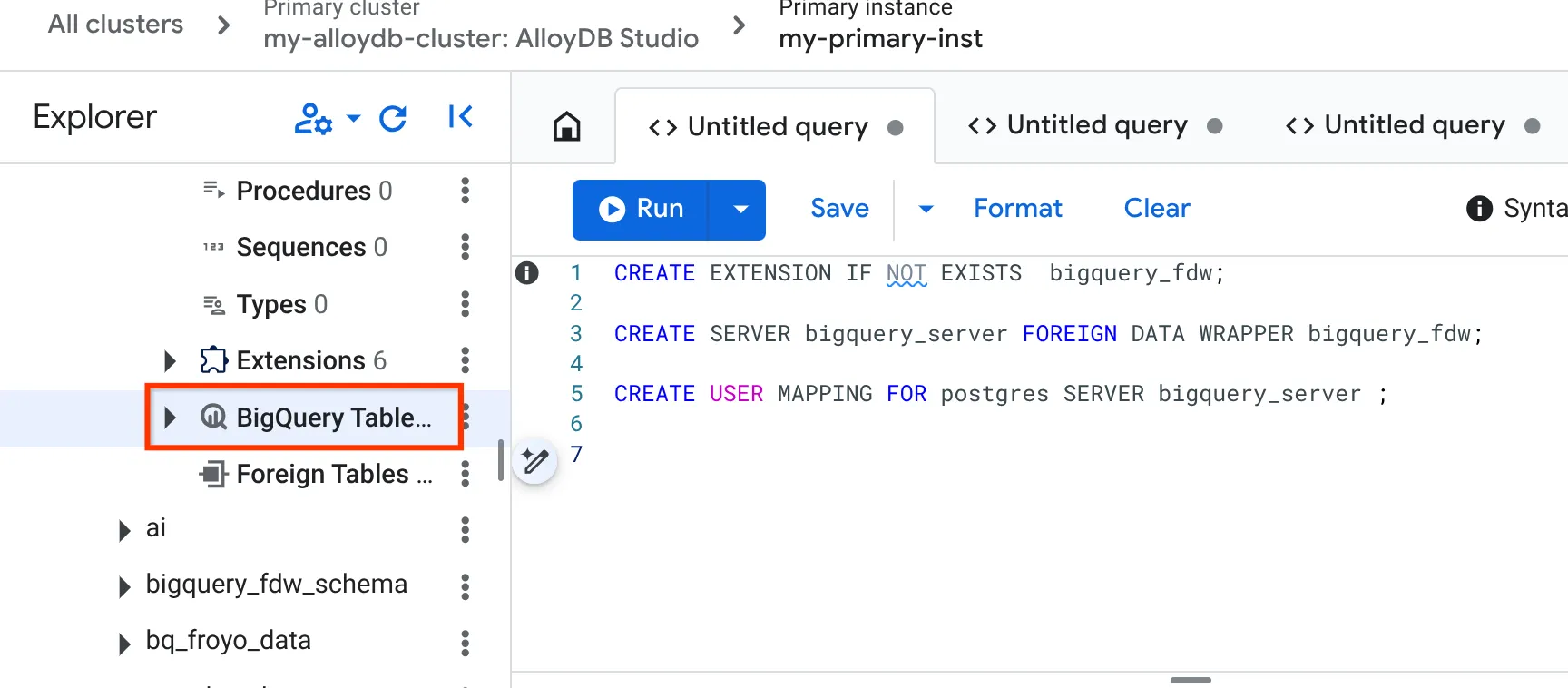
- तीन बिंदु वाले आइकॉन पर क्लिक करें. इसके बाद, "BigQuery टेबल कनेक्ट करें" पर क्लिक करें.
- 'BigQuery टेबल कनेक्ट करें' पॉप-अप में, अपना project_id और BigQuery डेटासेट का नाम (पहले हिस्से में बनाया गया) चुनें. इससे आपको अपने AlloyDB डेटाबेस में मौजूद डेटा को क्वेरी करने में मदद मिलेगी.
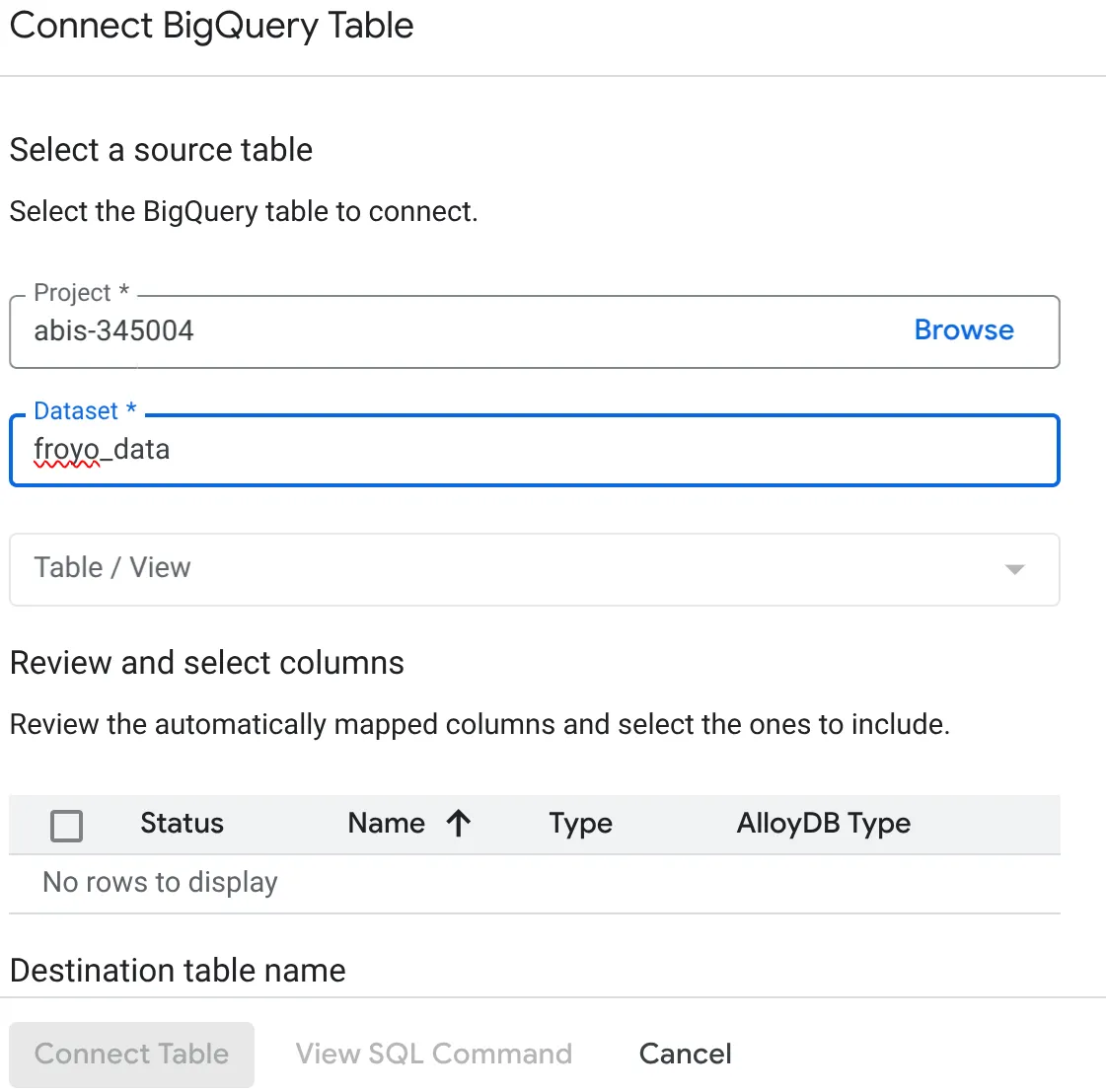
- AlloyDB से कनेक्ट किए गए अपने सभी डेटा को पाने के लिए, हर टेबल को एक-एक करके चुनें. ऐसा इसलिए किया जाता है, ताकि हम कॉलम टाइप की पुष्टि कर सकें और यह पक्का कर सकें कि वे AlloyDB में काम करते हैं.
अगर आपको पॉइंट-एंड-क्लिक अप्रोच के बदले SQL का इस्तेमाल करके ऐसा करना है, तो:
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
यह कमाल का है!!!
हमने AlloyDB में "फ़ॉरेन टेबल" बनाई हैं. ये सामान्य PostgreSQL टेबल की तरह दिखती हैं और काम करती हैं. हालांकि, इनमें कोई डेटा सेव नहीं होता. इन पर क्वेरी करने पर, AlloyDB तुरंत क्वेरी को BigQuery पर भेज देता है. इसके बाद, BigQuery से नतीजे मिलते हैं और AlloyDB उन्हें आपको दिखाता है.
7. AlloyDB में फ़ेडरेशन की जांच करना
आइए, पुष्टि करें कि हम अपने बड़े और विश्लेषणात्मक BigQuery डेटासेट को सीधे तौर पर अपने लेन-देन वाले PostgreSQL डेटाबेस से क्वेरी कर सकते हैं.
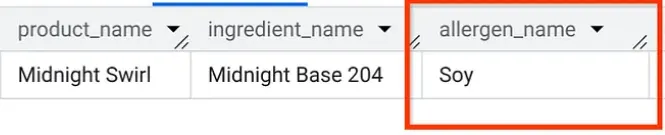
अब भी AlloyDB Studio में, "Midnight Swirl" में मौजूद ऐलर्जन के बारे में जानने के लिए क्वेरी चलाएं. यह वही सवाल है जो हमने पहले पार्ट में पूछा था. हालांकि, इस बार इसे AlloyDB से पूछा गया है!
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
बूम. आपको ठीक वही नतीजे दिखेंगे जो BigQuery में दिखे थे.
8. व्यवस्थित करें
इस लैब को पूरा करने के बाद, AlloyDB क्लस्टर और इंस्टेंस को मिटाना न भूलें.
इससे क्लस्टर और उसके इंस्टेंस मिट जाएंगे.
9. यूनिफ़ाइड डेटा लेयर के लिए बधाई
सोचें कि हमने अभी क्या-क्या किया:
- हमारा लेन-देन वाला ऐप्लिकेशन (AlloyDB पर चल रहा है), एक साथ कई उपयोगकर्ता सेशन को तेज़ी से हैंडल कर सकता है.
- जब इसे विश्लेषण के लिए ज़्यादा डेटा या पुराने कॉन्टेक्स्ट की ज़रूरत होती है, तब यह BigQuery froyo_dataschema से क्वेरी करता है. जैसे, सप्लायर की जानकारी या जटिल सामग्री की मैपिंग.
- ज़ीरो ईटीएल. डेटा पाइपलाइन में कोई रुकावट नहीं आती. कोई भी डेटाबेस सिंक नहीं किया गया है. हम डेटा को एक बार (BQ में) सेव करते हैं और जहां ज़रूरत होती है वहां इसका इस्तेमाल करते हैं.
अब हमारा डेटा फ़ाउंडेशन — दोनों तरह का डेटा, यानी कि विश्लेषण और लेन-देन से जुड़ा डेटा — मज़बूत और आपस में जुड़ा हुआ है. इसलिए, अब हम मज़ेदार काम करने के लिए तैयार हैं.
तीसरे हिस्से में, हम मल्टी-एजेंट ऐप्लिकेशन बनाएंगे. यह ऐप्लिकेशन, इस आर्किटेक्चर के ऊपर काम करेगा, ताकि Froyo के कारोबार को चलाया जा सके!