
1. Panoramica
Conosciamo tutti il problema dei "dati oscuri". Si tratta di file PDF, immagini e file di testo che si trovano nei bucket di spazio di archiviazione sul cloud, completamente invisibili alle query SQL e alle dashboard BI. Tradizionalmente, lo sblocco di questi dati richiedeva pipeline OCR complesse, inserimento manuale dei dati o script personalizzati fragili.
Non più.
In questo lab, ti mostrerò come convertire 400 file PDF non strutturati, contenenti testo, tabelle e immagini, in tabelle BigQuery strutturate in modo pulito con relazioni dedotte automaticamente tra loro. E lo faremo in pochi minuti utilizzando BigQuery Knowledge Catalog e Dataplex.
Cosa creerai
Per rendere tutto più concreto, esaminiamo un'attività fittizia: un franchising di frozen yogurt in rapida crescita.
Supponiamo che tu gestisca i dati di questa attività di vendita di yogurt ghiacciato. Hai centinaia di ricette e schede tecniche dei fornitori, tutte salvate come PDF. I leader aziendali vogliono lanciare un agente AI per aiutare i responsabili dei negozi e i clienti a interrogare i dettagli dei prodotti.
Ecco lo scenario peggiore: un cliente chiede: "Sono molto interessato al vostro froyo Midnight Swirl. Contiene allergeni?"
Per rispondere a questa domanda, il tuo sistema dovrebbe normalmente:
- Trova il PDF della ricetta "Midnight Swirl".
- Leggi gli ingredienti (ad es. "Cacao in polvere", "Base di latte", "Emulsionante X").
- Cerca tra decine di PDF dei fornitori per trovare le schede tecniche di questi ingredienti specifici.
- Controlla le schede dei fornitori per individuare gli allergeni nascosti legati a questi ingredienti.
Tentare di creare un agente AI che lo faccia al volo leggendo 400 PDF grezzi in fase di runtime è lento, costoso e soggetto ad allucinazioni. Invece, utilizzeremo l'inferenza semantica per estrarre tutte queste informazioni in un database relazionale, rendendo il nostro futuro agente AI velocissimo e basato al 100% su dati SQL reali.
Iniziamo a creare.
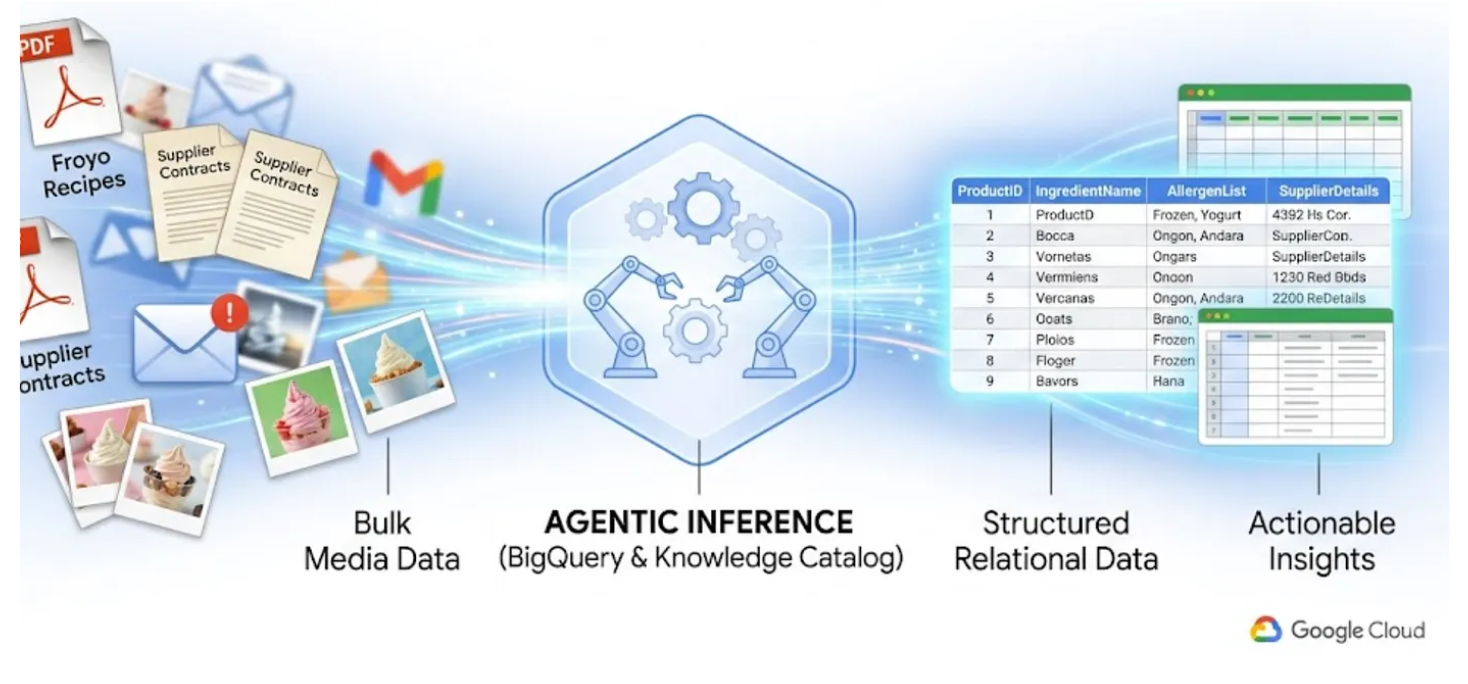
Obiettivi didattici
- Come configurare il bucket Cloud Storage per i file di origine (PDF)
- Come configurare ed eseguire il job Datascan e l'inferenza semantica in Knowledge Catalog per estrarre i dati dai PDF di origine, dedurre semanticamente le connessioni e il contesto e archiviarli in BigQuery
- Come utilizzare gli agenti BigQuery per chattare con il set di dati appena creato
Requisiti
2. Prima di iniziare
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se vuoi autenticarti
gcloud auth login
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Abilita le API richieste: esegui questo comando per abilitare tutte le API richieste:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
Aspetti da considerare e risoluzione dei problemi
La sindrome del "progetto fantasma" | Hai eseguito |
La barriera di fatturazione | Hai attivato il progetto, ma hai dimenticato l'account di fatturazione. AlloyDB è un motore ad alte prestazioni; non si avvia se il "serbatoio" (fatturazione) è vuoto. |
Ritardo di propagazione dell'API | Hai fatto clic su "Abilita API", ma la riga di comando indica ancora |
Quota Quags | Se utilizzi un account di prova nuovo di zecca, potresti raggiungere una quota regionale per le istanze AlloyDB. Se |
Service Agent"Nascosto" | A volte al service agent AlloyDB non viene concesso automaticamente il ruolo |
3. Configurazione del bucket Google Cloud Storage
In questa sezione, crei una struttura organizzativa in BigQuery per archiviare i dati di fornitori e ricette di Froyo, in particolare per i dettagli del prodotto Froyo. Stabilisce anche una connessione alle risorse cloud, che funge da "ponte" sicuro che consente a BigQuery di leggere i file da origini esterne come Cloud Storage.
Prima di iniziare:
Questo repository contiene ricette e file PDF dei fornitori che utilizzeremo in questo progetto. Assicurati di scaricare questi file. Per scaricare i file:
In Cloud Shell, esegui questo comando:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
Vai alla cartella appena creata:
cd next-26-keynotes
Estrai la cartella data-cloud-demo
git sparse-checkout set genkey/data-cloud-demo
Al termine del pagamento, vai alla cartella data-cloud-demo ed estrai i file ZIP per accedere agli asset del codelab.
Crea il bucket e carica i file PDF di Froyo (ricette e fornitori)
- Nella console Google Cloud, vai alla pagina Bucket Cloud Storage.
- Fai clic su Crea.
- Nella pagina Crea un bucket, inserisci le informazioni sul bucket. Dopo ogni passaggio che segue, fai clic su Continua per passare al passaggio successivo:
- Nella sezione Inizia, inserisci il nome del bucket. Ad es.: froyo_data
- Nella sezione Scegli dove archiviare i tuoi dati, seleziona Regione e poi inserisci la tua regione. us-central1
- Nella sezione Scegli come controllare l'accesso agli oggetti, deseleziona la casella di controllo Applica la prevenzione dell'accesso pubblico in questo bucket.
- Fai clic su Crea.
- Nell'elenco dei bucket, fai clic su quello che hai creato.
- Nella scheda Oggetti del bucket, fai clic su Carica e poi su Carica cartelle.
- Seleziona la cartella recipes che hai estratto nella sezione Prima di iniziare di questo codelab.
- Fai clic su "Carica".
- Ripeti la procedura di caricamento per la cartella fornitori.
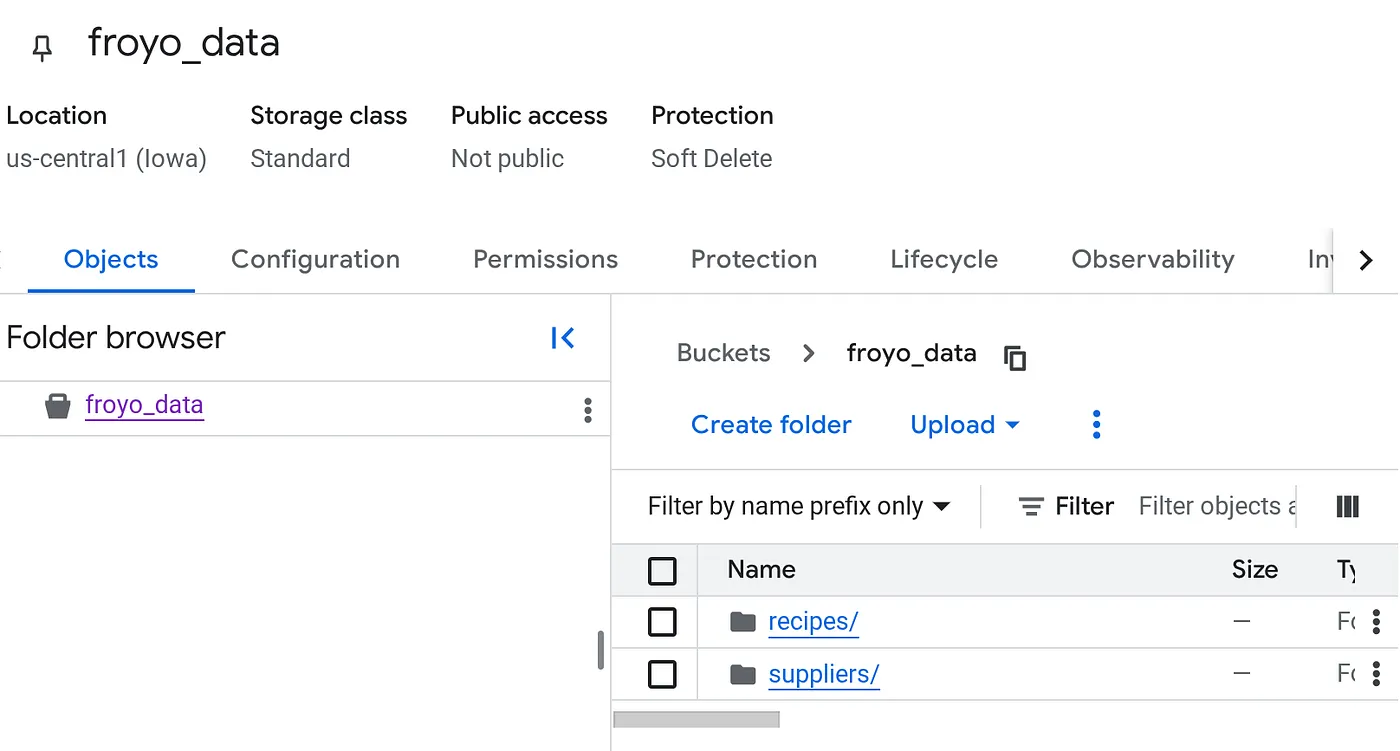
Una volta caricata, la struttura del bucket dovrebbe essere simile a (qualunque sia il nome del bucket):
4. Configurazione della connessione BigQuery
Crea una connessione alle risorse Cloud. In questo modo viene generato un service account univoco che funge da "documento di identità" di BigQuery per accedere ai file esterni.
- Vai alla pagina BigQuery.
- Nel riquadro a sinistra, fai clic su Explorer. Se non vedi il riquadro a sinistra, fai clic su Espandi riquadro a sinistra per aprirlo.
- Nel riquadro Explorer, espandi il nome del progetto e poi fai clic su Connessioni.
- Nella pagina Connessioni, fai clic su Crea connessione.
- In Tipo di connessione, scegli Modelli remoti di Vertex AI, funzioni remote, BigLake e Spanner (risorsa Cloud).
- Nel campo ID connessione, inserisci il nome dell'ID connessione:
- bq-connection. Assicurati di annotare questo ID, perché ti servirà quando configurerai la scansione dei dati più avanti in questo codelab.
- Imposta Tipo di località su Regione, quindi seleziona una regione. Ad esempio, us-central1. La connessione deve trovarsi nella stessa regione delle altre risorse, ad esempio i set di dati.
- Fai clic su Crea connessione.
- Fai clic su Vai alla connessione.
- Nel riquadro Informazioni sulla connessione, copia l'ID dell'account di servizio da utilizzare in un passaggio successivo. Il service account ha un aspetto simile a bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
5. Configurazione delle autorizzazioni
- Concedi le autorizzazioni necessarie alla connessione BigQuery per accedere agli oggetti Cloud Storage e a Knowledge Catalog
Vai alla pagina IAM e amministrazione e, nella sezione Visualizza per entità, fai clic sul pulsante Concedi accesso, aggiungi un'entità incollando il service account che hai copiato nell'ultimo passaggio. Nella sezione dei ruoli, aggiungi i nomi dei seguenti ruoli uno alla volta e salva:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- Concedi le autorizzazioni del service account Dataplex per accedere al bucket Cloud Storage
Vai alla pagina IAM e amministrazione e, nella sezione Visualizza per entità, fai clic sul pulsante Concedi accesso e aggiungi un'entità digitando la parola dataplex nella barra di testo Nuova entità. Dall'elenco di completamento automatico, seleziona l'entità service account Dataplex simile a questa: (utilizza il numero di progetto e non l'ID progetto nell'email dell'account di servizio riportato di seguito)
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Se per qualsiasi motivo il service account sopra indicato per il tuo numero di progetto non viene riconosciuto, è possibile che il servizio Dataplex non sia ancora stato inizializzato. Vai al terminale Cloud Shell e prova ad abilitare l'API (se non l'hai già fatto nella fase Prima di iniziare) eseguendo questo comando: gcloud services enable dataplex.googleapis.com
Anche dopo, se il service account per Dataplex non viene riconosciuto, forza la creazione di un job di analisi di test di Dataplex nella pagina Gestione dei metadati e inserisci i dettagli nella pagina di creazione del job di rilevamento:
Fai clic su Esegui ora. Il job non andrà a buon fine, ma in questo modo l'ID service account verrà inizializzato per il tuo servizio Dataplex.
Torna alla pagina IAM e amministrazione e, nella sezione Visualizza per entità, fai clic sul pulsante Concedi accesso e aggiungi un'entità. Incolla il service account:
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Poi concedi i seguenti ruoli a questo service account:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. Configurazione di Knowledge Catalog
Crea un Knowledge Catalog per unificare i dati non strutturati e automatizzare l'individuazione di file non strutturati (come ricette in PDF e fornitori in PDF).
Crea il job DataScan dalla console:
- Vai alla pagina Cura dei metadati.
- Fai clic su Crea e inserisci i dettagli corrispondenti alla tua configurazione:
Nota importante: non dimenticare di selezionare Attiva inferenza semantica.
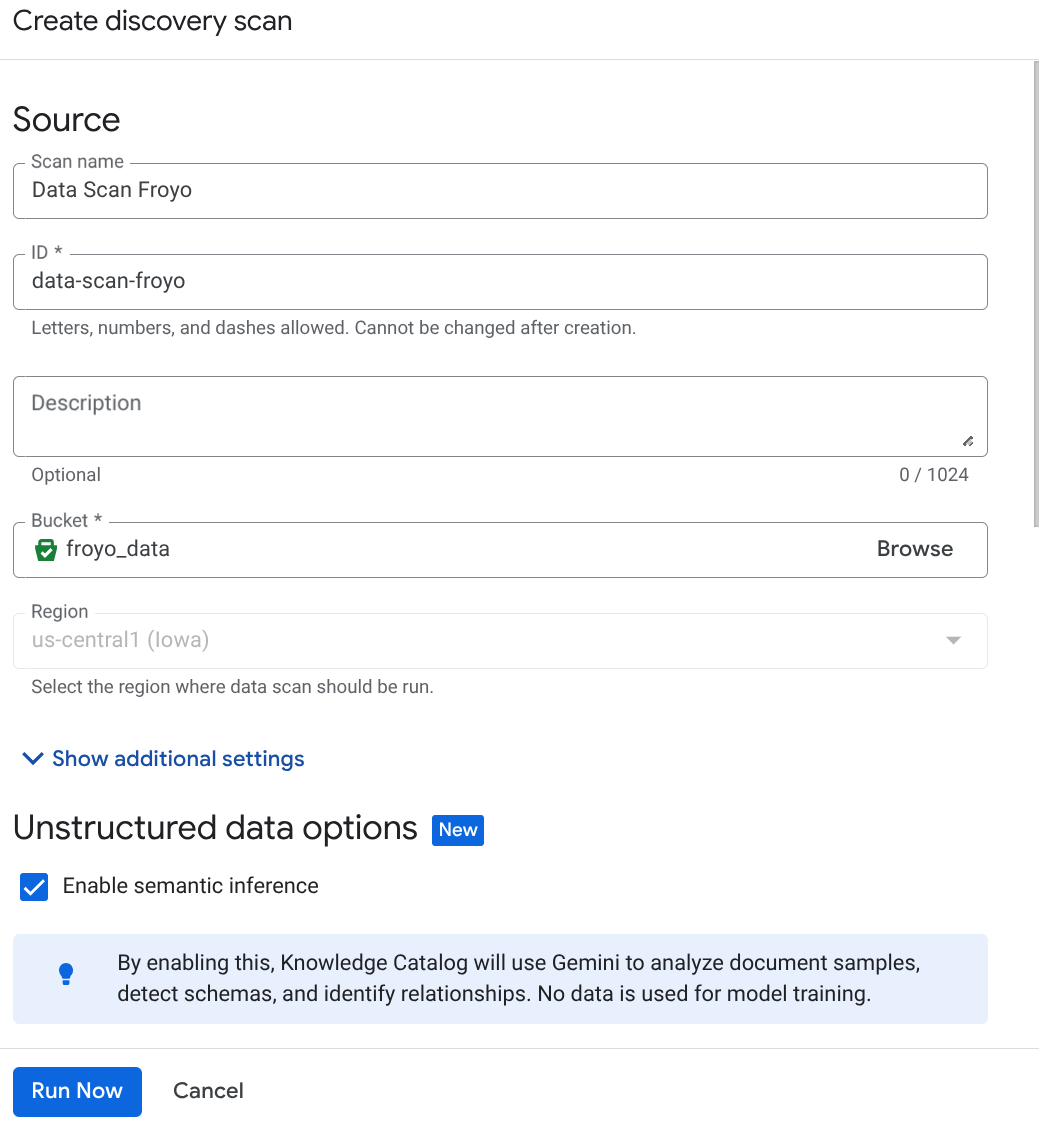
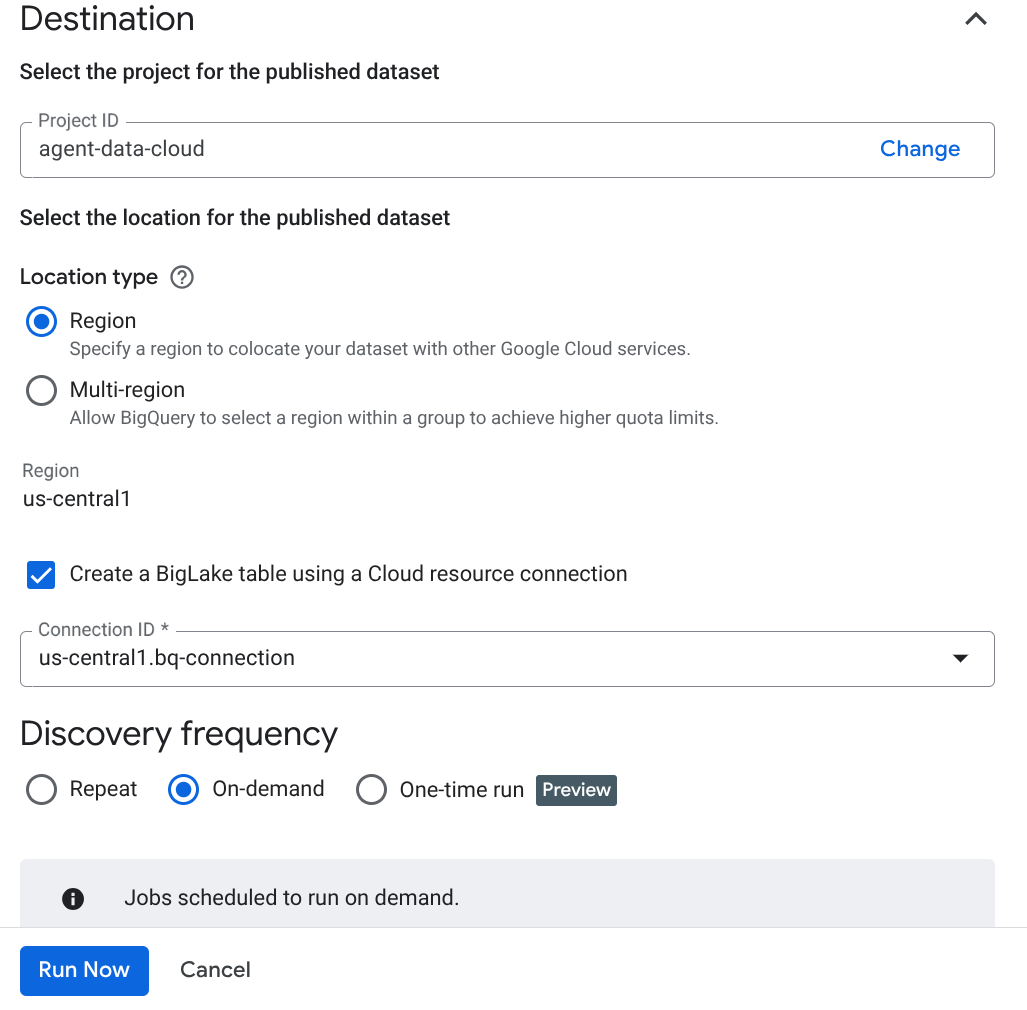
- Fai clic su "Esegui ora".
- Il completamento del job di scansione richiederà un po' di tempo. Al termine del job, controlla se è presente il set di dati pubblicato. Per controllare lo stato del job, puoi controllare nella pagina Cura dei metadati. Nella scheda Rilevamento di Cloud Storage, fai clic sul nome delle scansioni di rilevamento dell'esecuzione recente. Dovresti visualizzare il set di dati pubblicato come mostrato di seguito:
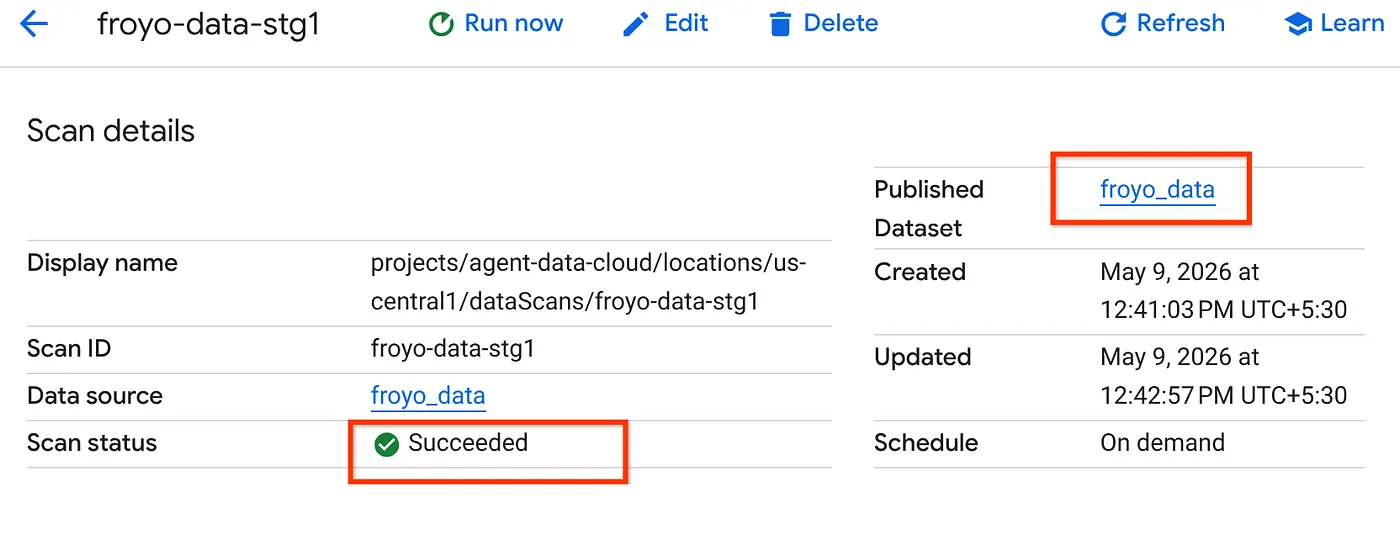
Nota: se si verificano errori nel passaggio di scansione, attendi un po' e riprova (la creazione del job e il completamento dell'esecuzione richiedono alcuni minuti).
- Puoi visualizzare la tabella in BigQuery facendo clic e andando al set di dati froyo_data. Fai clic sull'ID tabella in BigQuery ed esegui la query riportata di seguito nella scheda Editor query:
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
Il risultato è 400 (se non è così, puoi tornare indietro ed eseguire di nuovo il job Datascan).
7. Estrazione semantica dei dati
Ottimo! Ora estraiamo l'inferenza per questi oggetti non strutturati utilizzando Knowledge Catalog.
Utilizzeremo la funzionalità Insights per generare istruzioni SQL per estrarre dati strutturati dalla tabella non strutturata
- Nella console Google Cloud, vai alla pagina Ricerca nel catalogo delle conoscenze.
- Cerca la tabella del set di dati per cui vuoi visualizzare gli approfondimenti. Nella barra di ricerca, inserisci il nome del set di dati / della tabella del passaggio precedente: "froyo_data" e premi Invio.
- Nell'elenco dei risultati, fai clic sulla voce TABELLA (non sul set di dati)
- Dovresti visualizzare la scheda APPROFONDIMENTI. Fai clic (se ti viene richiesto di abilitare un'API, segui le istruzioni e abilita le API).
Se hai abilitato le API a questo punto, devi eseguire di nuovo il job di scansione.
- Nella scheda INSIGHTS, vedrai il menu a discesa del pulsante ESTRAI. Fai clic e seleziona l'opzione "Estrai con SQL".
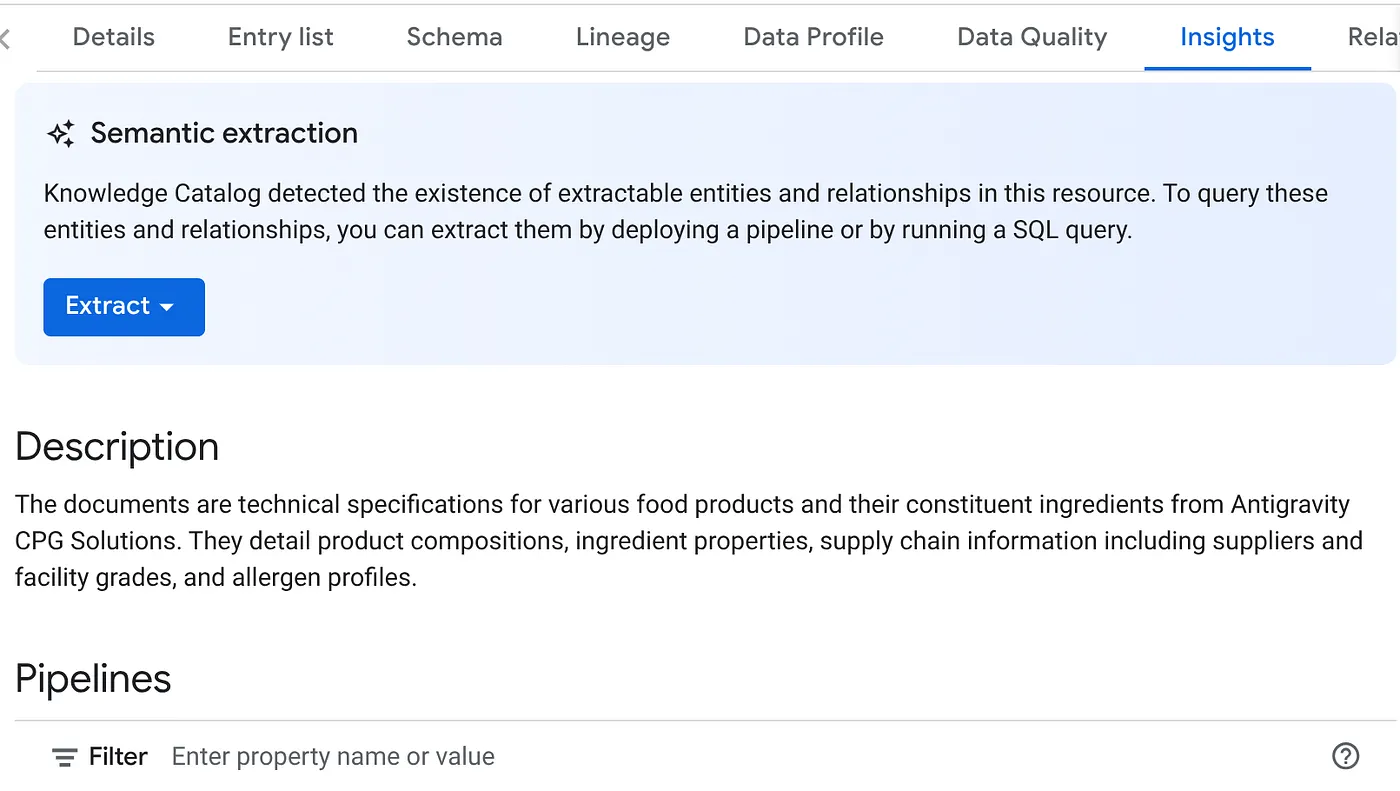
Nella finestra di dialogo "Estrai con SQL", imposta il set di dati DESTINAZIONE come quello visualizzato nel risultato del job Datascan. Inizia a digitare il nome e dovrebbe essere visualizzato nel completamento automatico. Fai clic sul pulsante "Estrai". In alternativa, puoi creare un nuovo set di dati a questo punto ed estrarlo.
Si aprirà l'editor di query BigQuery con una scheda aperta compilata con l'SQL estratto dall'inferenza della scansione dei dati.
8. Convalida SQL e creazione dello schema
Se la query generata sembra corretta e semanticamente pertinente ai tuoi dati non strutturati, esegui la query facendo clic sul pulsante Esegui nell'editor di query. La creazione dello schema richiesto per l'archiviazione strutturata dei contenuti multimediali non strutturati richiede alcuni minuti.
Una volta completata l'operazione, dovresti essere in grado di verificare lo schema espandendo il set di dati nel riquadro dell'esploratore di BigQuery Studio, come mostrato di seguito:
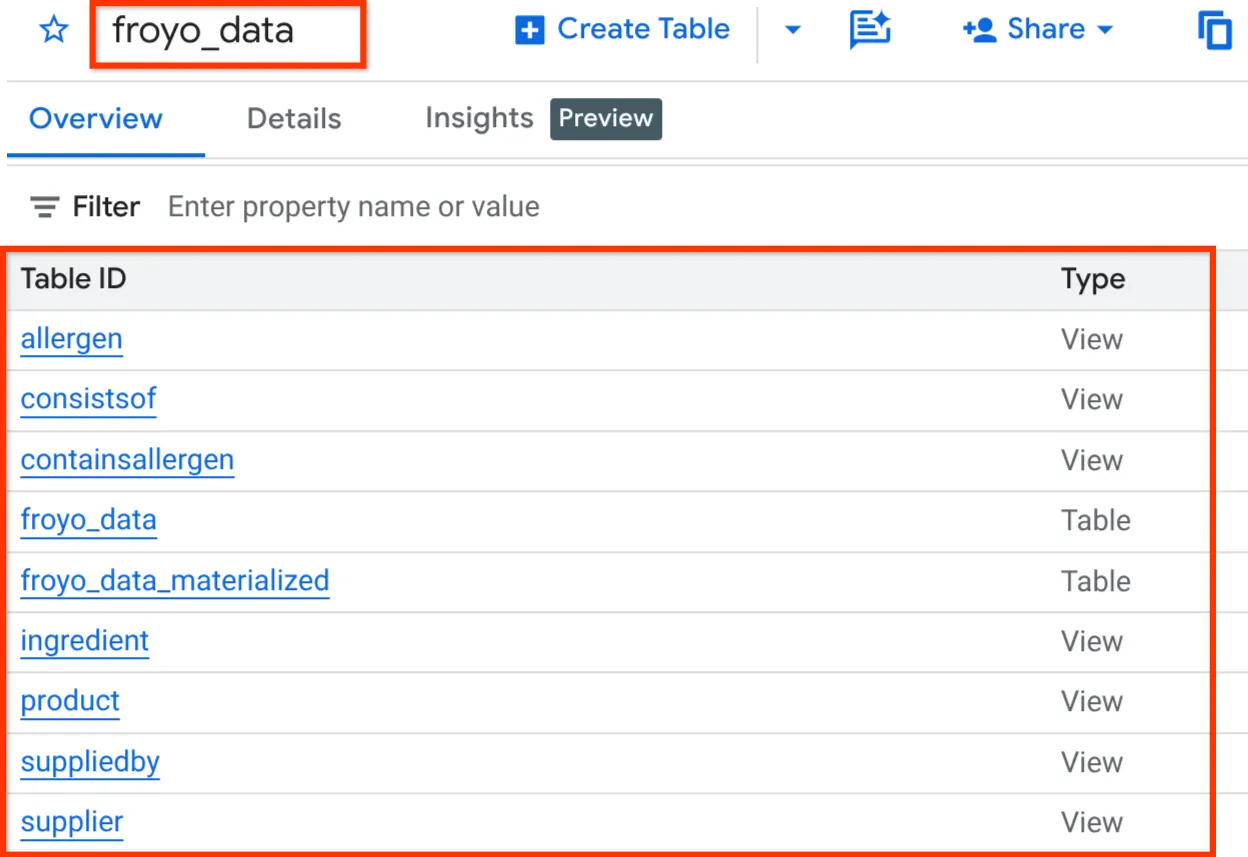
Ok!!! È stato così bello che abbiamo fatto tutte quelle cose del database molto velocemente. Ora è il momento della prova finale.
Passaggi per continuare a visualizzare i dati senza l'account di fatturazione:
- Puoi scaricare i file CSV (dati BigQuery) dal link del repository GitHub riportato sopra.
- Innanzitutto, crea il set di dati BigQuery eseguendo il comando riportato di seguito dal terminale Cloud Shell:
bq mk --location us-central1 --dataset froyo_data
- Successivamente, scarica gli otto file di dati (file CSV) dal repository GitHub nella tua directory di lavoro eseguendo i seguenti comandi uno alla volta:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Esegui i seguenti comandi uno alla volta per creare queste tabelle con i dati nel set di dati appena creato.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Una volta creati il set di dati, le tabelle e i dati, puoi procedere a testare e sperimentare i dati di cui abbiamo appena parlato.
9. La prova definitiva!!!
Supponiamo che io voglia che il mio agente risponda alle domande dell'utente con informazioni reali, complete e ben orchestrate basate su fatti. Farò una domanda a cui l'agente potrà rispondere solo facendo riferimento a più file multimediali e riferimenti della mia fonte.
Ecco la mia domanda utente:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
Ora una ricerca generica o una ricerca LLM indicherà "Zero ingredienti". Tuttavia, abbiamo creato un'inferenza semantica completa che converte tutti i nostri contenuti multimediali non strutturati in dati strutturati. Ecco una semplice query SQL che recupera queste informazioni:
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
Bene! Esamina il risultato:
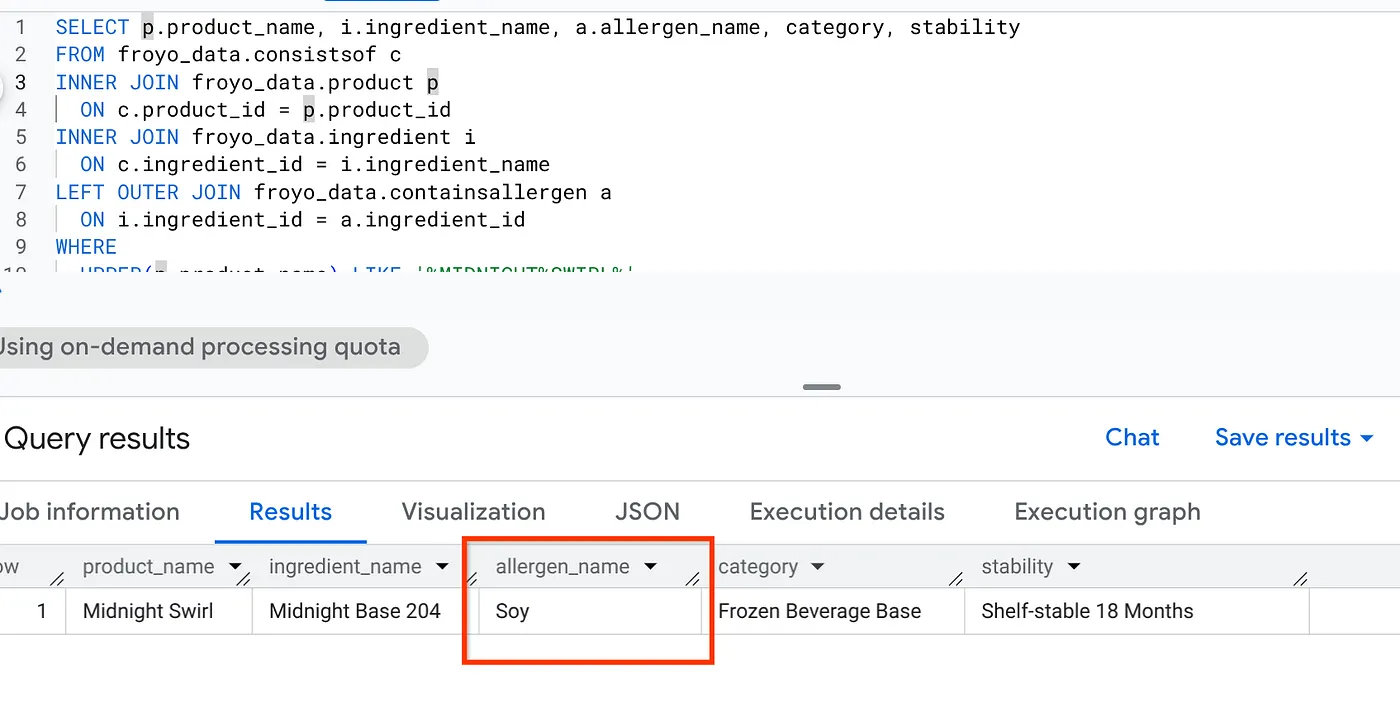
10. Esegui la pulizia
Al termine di questo lab, non dimenticare di eliminare il job di scansione e le tabelle BigQuery create dal job.
Vai alla pagina https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery. Seleziona il job da eliminare facendo clic sui tre puntini verticali accanto e poi su ELIMINA.
Dovrebbe liberare spazio.
11. Complimenti
La nostra implementazione è riuscita a identificare l'allergene nascosto. Basta con i dark data. Nella parte 2, federeremo questi dati BigQuery in un sistema transazionale con AlloyDB per unificare le esigenze di dati per la nostra applicazione agentica.