
1. Panoramica
Nella parte 1, abbiamo trasformato correttamente PDF caotici e non strutturati in tabelle pulite, intelligenti e strutturate in BigQuery utilizzando Knowledge Catalog e DataScan. Ora abbiamo un data warehouse solido.
Se hai bisogno di un rapido ripasso, nel lab della parte 1 abbiamo preso in esame il caso d'uso di un franchising fittizio di frozen yogurt e abbiamo convertito 400 dei suoi file PDF non strutturati, contenenti testo, tabelle e immagini, in tabelle BigQuery strutturate in modo pulito con relazioni dedotte automaticamente tra loro utilizzando BigQuery Knowledge Catalog e Dataplex.
Cosa creerai
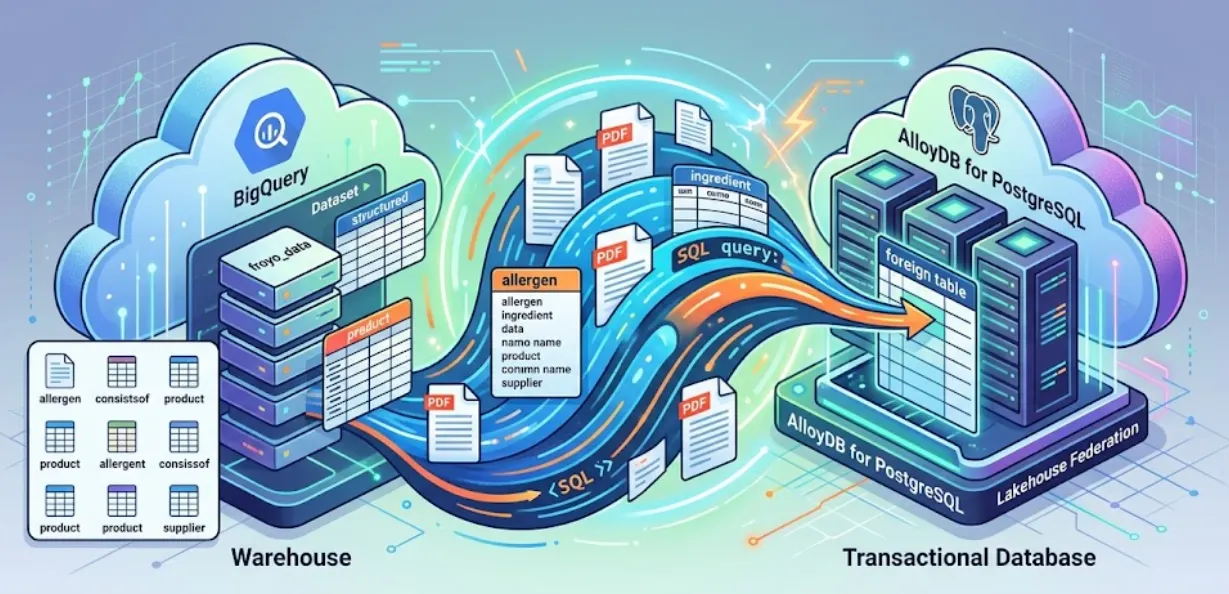
In questa sessione, configureremo AlloyDB per PostgreSQL e faremo qualcosa di magico: federeremo i nostri dati BigQuery direttamente in AlloyDB. Ciò significa che la nostra app transazionale può eseguire query sui dati del nostro data warehouse in tempo reale, senza copiarli o duplicarli.
In qualità di sviluppatore, devi porti questa domanda in questa fase:
"Se i dati sono già in BigQuery, perché introdurre AlloyDB? Perché l'applicazione non esegue un'istruzione SELECT direttamente su BigQuery?"
Ecco perché:
Con Lakehouse Federation, puoi utilizzare il motore di query di AlloyDB per gestire i carichi di lavoro transazionali e analitici della tua applicazione dalla stessa interfaccia. Puoi anche materializzare o importare questi dati su AlloyDB per un accesso più rapido da utilizzare nelle tue applicazioni, il che ti consente di utilizzare AlloyDB AI e il motore colonnare.
Puoi utilizzare AlloyDB come database transazionale e avere anche grandi quantità di dati in BigQuery o BigLake. In genere, le tue applicazioni si integrano in modo indipendente con entrambi i sistemi per accedere ai dati nei diversi servizi Google Cloud. Lakehouse Federation per AlloyDB ti consente di utilizzare il supporto delle query federate di AlloyDB implementato come wrapper di dati esterni per accedere ai dati di BigQuery e AlloyDB utilizzando un'interfaccia SQL in AlloyDB.
Anziché creare una fragile pipeline ETL per eseguire query sui dati BigQuery da AlloyDB, utilizzeremo query federate. AlloyDB fungerà da endpoint unificato, accedendo a BigQuery senza problemi quando necessario.
Iniziamo a creare.
Obiettivi didattici
- Come configurare il cluster, l'istanza e il networking AlloyDB con un clic
- Come configurare l'estensione per prepararsi alla federazione
- Come configurare la federazione da BigQuery ad AlloyDB
- Prova
Requisiti
2. Prima di iniziare
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se vuoi autenticarti
gcloud auth login
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Abilita le API richieste: esegui questo comando per abilitare tutte le API richieste:
gcloud services enable alloydb.googleapis.com
Aspetti da considerare e risoluzione dei problemi
La sindrome del "progetto fantasma" | Hai eseguito |
La barriera di fatturazione | Hai attivato il progetto, ma hai dimenticato l'account di fatturazione. AlloyDB è un motore ad alte prestazioni; non si avvia se il "serbatoio" (fatturazione) è vuoto. |
Ritardo di propagazione dell'API | Hai fatto clic su "Abilita API", ma la riga di comando indica ancora |
Quota Quags | Se utilizzi un account di prova nuovo di zecca, potresti raggiungere una quota regionale per le istanze AlloyDB. Se |
3. Riepilogo rapido dei dati della prima parte
In questa sezione, devi assicurarti che i dati strutturati che abbiamo estratto dai PDF non strutturati siano disponibili in BigQuery. Se non hai seguito la prima parte o non disponi di un account di fatturazione, non preoccuparti, puoi completare i seguenti passaggi e iniziare:
Vai alla console Google Cloud dal tuo account Gmail personale e fai clic sul pulsante Attiva Cloud Shell nell'angolo in alto a destra della console:
Poi segui i passaggi riportati nella sezione Nessun account di fatturazione di seguito:
Passaggi per continuare a visualizzare i dati senza l'account di fatturazione:
- Puoi scaricare i file CSV (dati BigQuery) dal link del repository GitHub riportato sopra.
- Innanzitutto, crea il set di dati BigQuery eseguendo il comando riportato di seguito dal terminale Cloud Shell:
bq mk --location us-central1 --dataset froyo_data
- Successivamente, scarica gli otto file di dati (file CSV) dal repository GitHub nella tua directory di lavoro eseguendo i seguenti comandi uno alla volta:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Esegui i seguenti comandi uno alla volta per creare queste tabelle con i dati nel set di dati appena creato.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Ora che abbiamo i dati in BigQuery, passiamo ai passaggi successivi.
4. Configura cluster, istanza e rete AlloyDB
Esiste un'applicazione di avvio rapido basata sul web che ti aiuterà a configurare il cluster AlloyDB, l'istanza e altre dipendenze. Puoi seguire i passaggi 2-4 di questo lab per configurarlo con un clic:
https://codelabs.developers.google.com/quick-alloydb-setup
Una volta creato il cluster, vai alla pagina Panoramica del cluster e copia i dettagli del service account.
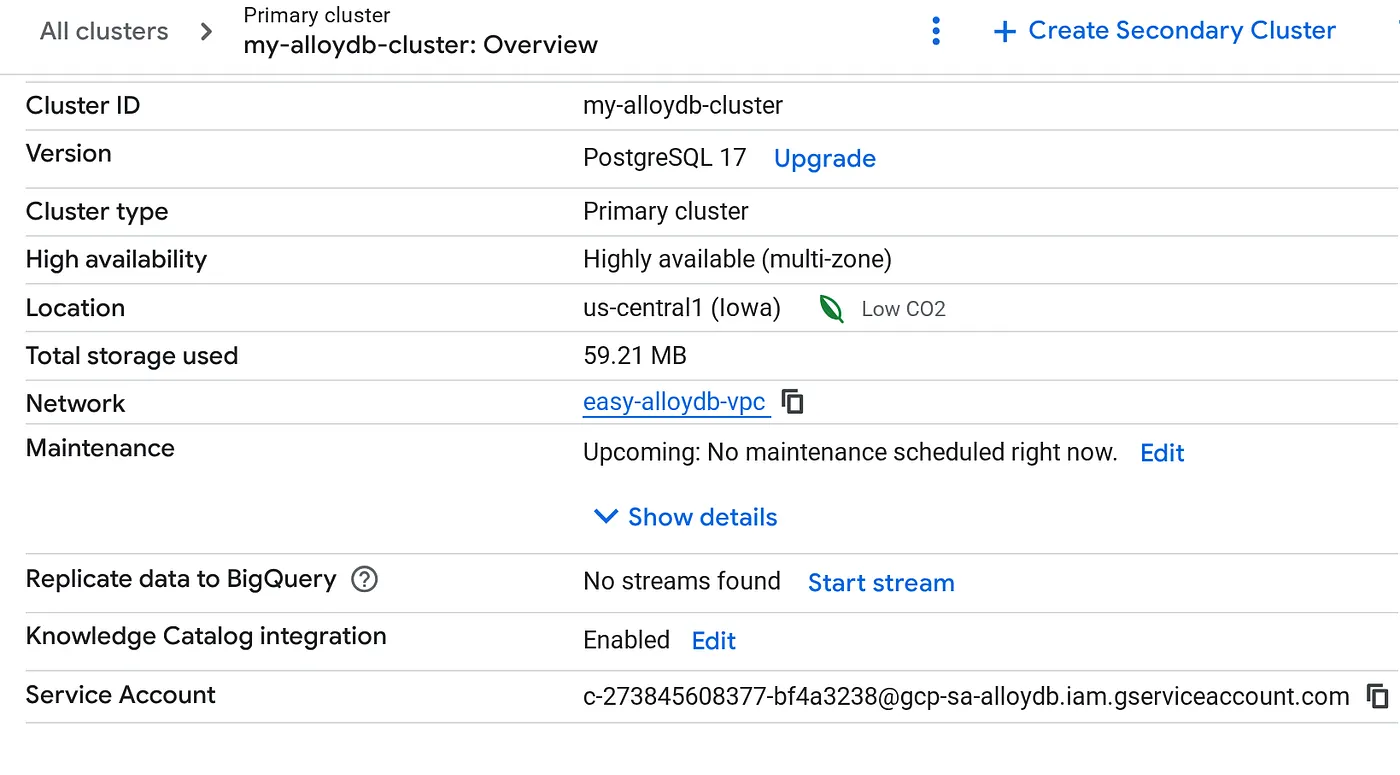
5. Configurazione delle autorizzazioni
Concedi le autorizzazioni BigQuery a questo service account
- Vai a IAM e amministrazione > IAM.
- Fai clic su Concedi accesso.
- Incolla l'indirizzo del service account AlloyDB nel campo Nuove entità.
- Assegna i seguenti ruoli:
- Visualizzatore dati BigQuery (roles/bigquery.dataViewer): consente di leggere i dati.
- Utente BigQuery (roles/bigquery.user): consente di eseguire le query.
- (Facoltativo, ma consigliato) Utente sessione di lettura BigQuery (roles/bigquery.readSessionUser): ottimizza la lettura di set di dati di grandi dimensioni tramite l'API Storage Read.
6. Connettersi ad AlloyDB e abilitare l'estensione BigQuery
Ora ci connettiamo alla nostra nuova istanza AlloyDB per configurare l'estensione di federazione. Per farlo, utilizzeremo AlloyDB Studio.
- Nella pagina Panoramica cluster (console AlloyDB), fai clic su "Modifica primaria" nell'istanza primaria e scorri verso il basso fino a "Opzioni di configurazione avanzate".
- Vai alla sezione "Flag" e attiva i due flag su "On" come mostrato di seguito:
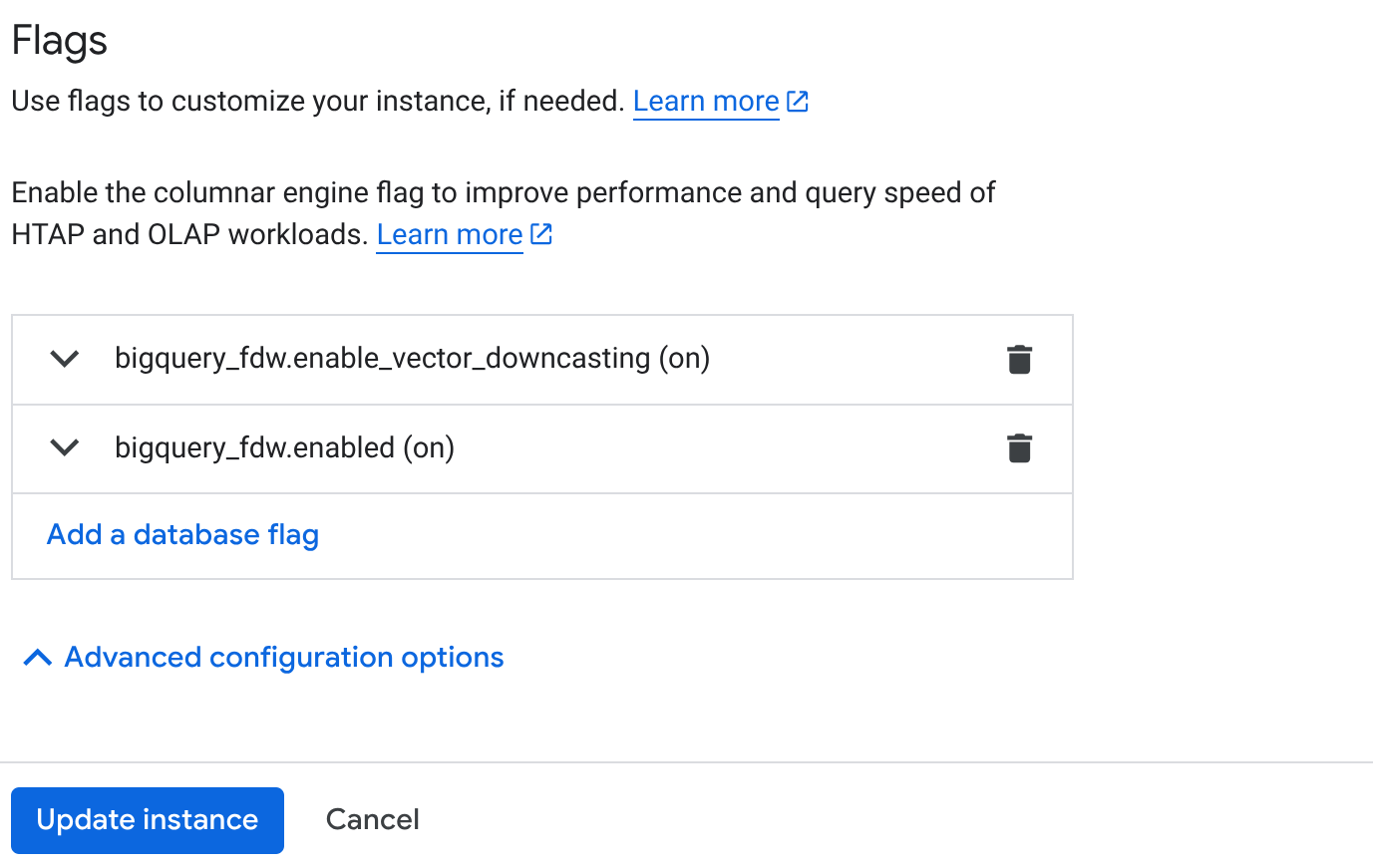 3. Fai clic sul pulsante Aggiorna istanza e attendi alcuni minuti per completare l'aggiornamento. 4. Nella pagina Panoramica cluster (console AlloyDB), fai clic su AlloyDB Studio.
3. Fai clic sul pulsante Aggiorna istanza e attendi alcuni minuti per completare l'aggiornamento. 4. Nella pagina Panoramica cluster (console AlloyDB), fai clic su AlloyDB Studio.
- Connettiti con il database, il nome utente e la password che hai configurato al momento del passaggio di configurazione rapida di AlloyDB.
- Una volta connesso, nella scheda Editor query a destra, inserisci le seguenti istruzioni ed ESEGUI una alla volta:
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- Una volta completata l'operazione, vai al riquadro dell'esploratore a sinistra e scorri verso il basso fino alle tabelle BigQuery:
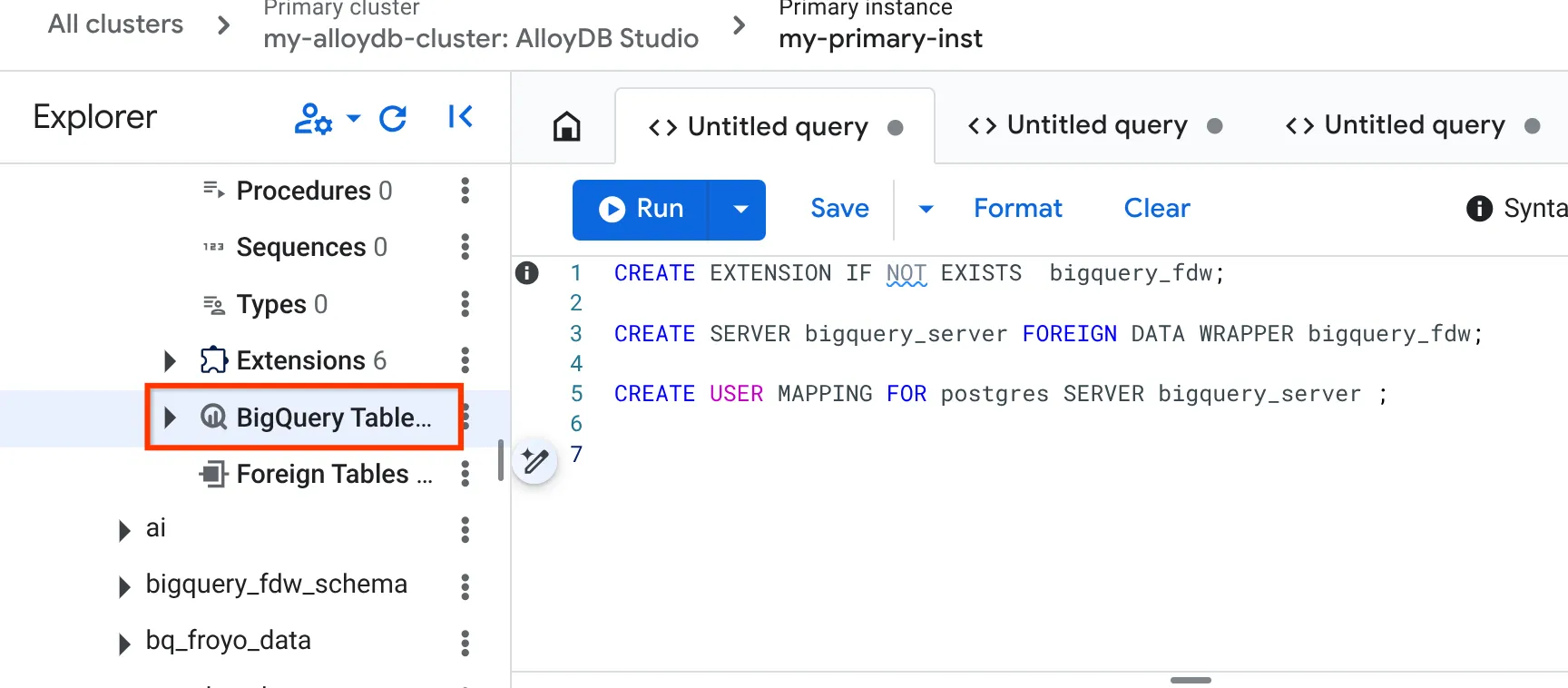
- Fai clic sui tre puntini e poi su "Connetti tabella BigQuery".
- Nel popup Connetti tabella BigQuery che si apre, seleziona il tuo project_id e il nome del set di dati BigQuery (creato nella parte 1) da cui vuoi eseguire query sui dati nel tuo database AlloyDB.
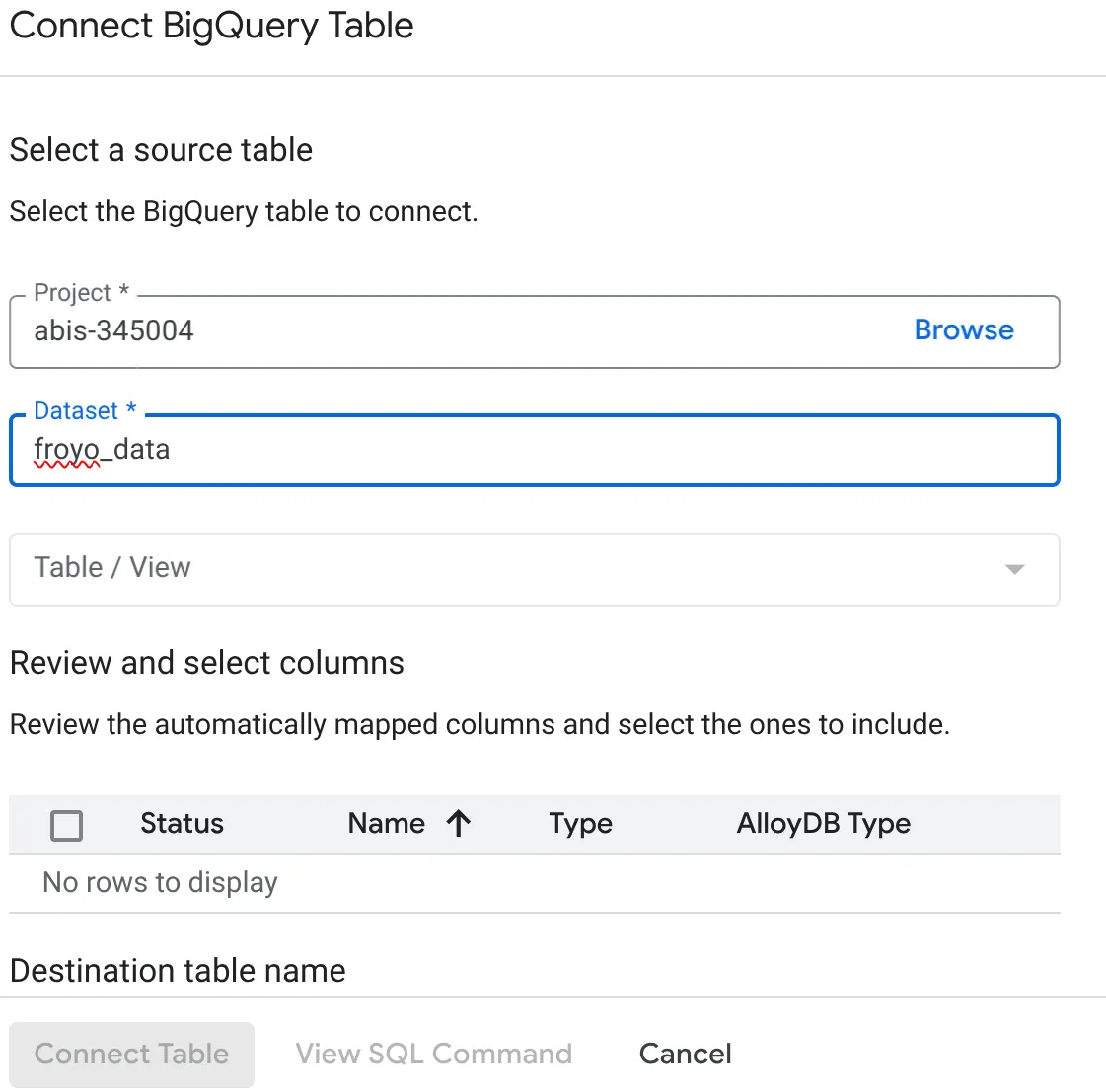
- Seleziona ogni tabella una alla volta per collegare tutti i tuoi dati ad AlloyDB. In questo modo convalidiamo i tipi di colonne per assicurarci che siano supportati in AlloyDB.
Se vuoi fare la stessa cosa con SQL invece che con l'approccio punta e clicca:
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
La magia!!!
Abbiamo appena creato le "tabelle esterne" in AlloyDB. Queste tabelle hanno l'aspetto e il comportamento delle normali tabelle PostgreSQL, ma non memorizzano dati. Quando esegui una query, AlloyDB la passa immediatamente a BigQuery, recupera i risultati e li restituisce.
7. Testa la federazione in AlloyDB
Verifichiamo di poter eseguire query sul nostro enorme set di dati analitici BigQuery direttamente dal nostro database PostgreSQL transazionale.
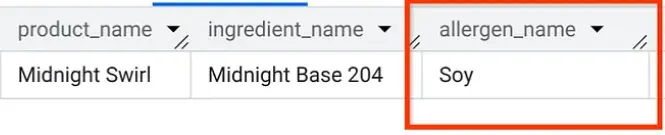
Sempre in AlloyDB Studio, eseguiamo una query per scoprire quali allergeni sono presenti nel gelato "Midnight Swirl" (la stessa domanda che abbiamo posto nella Parte 1, ma questa volta da AlloyDB):
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
Boom. Dovresti visualizzare esattamente gli stessi risultati ottenuti in BigQuery.
8. Esegui la pulizia
Una volta completato questo lab, non dimenticare di eliminare il cluster e l'istanza AlloyDB.
Dovrebbe liberare spazio nel cluster insieme alle relative istanze.
9. Congratulazioni per il tuo Unified Data Layer
Pensa a cosa abbiamo appena realizzato:
- La nostra app transazionale (in esecuzione su AlloyDB) può gestire sessioni utente rapide e simultanee.
- Quando ha bisogno di dati analitici o di un contesto storico (come i dettagli del fornitore o mappature complesse degli ingredienti), esegue query sullo schema froyo_dataschema di BigQuery.
- Zero ETL. Nessuna interruzione delle pipeline di dati. Nessun database non sincronizzato. Archiviamo una sola volta (in BQ) e calcoliamo dove ci serve.
Ora che la nostra base di dati, sia analitici che transazionali, è solida e interconnessa, siamo pronti per la parte divertente.
Nella Parte 3, creeremo l'applicazione multi-agente che si basa su questa architettura per eseguire le operazioni aziendali di Froyo.