
1. 概要
「ダークデータ」の苦痛は誰もが知っています。クラウド ストレージ バケットに保存されている PDF、画像、テキスト ファイルは、SQL クエリや BI ダッシュボードから完全に認識できません。従来、このデータのロックを解除するには、複雑な OCR パイプライン、手動によるデータ入力、脆弱なカスタム スクリプトが必要でした。
ないですよね
このラボでは、テキスト、テーブル、画像を含む 400 個の非構造化 PDF ファイルを、関係が自動的に推論される構造化された BigQuery テーブルに変換する方法を説明します。BigQuery Knowledge Catalog と Dataplex を使用して、数分で実現します。
作成するアプリの概要
具体例として、急成長中のフローズン ヨーグルトのフランチャイズという架空のビジネスを見てみましょう。
このフローズン ヨーグルト店のデータを管理しているとします。レシピやサプライヤーの仕様書が数百件あり、すべて PDF 形式で保存されています。ビジネス リーダーは、店舗のマネージャーと顧客が商品の詳細を問い合わせるのに役立つ AI エージェントをリリースしたいと考えています。
次のような最悪のシナリオを考えてみましょう。お客様から「Midnight Swirl のフローズン ヨーグルトに興味があります。アレルゲンは含まれていますか?」
この質問に答えるには、通常、システムで次の処理を行う必要があります。
- 「Midnight Swirl」のレシピ PDF を探します。
- 原材料(「ココアパウダー」、「乳製品ベース」、「乳化剤 X」など)を読みます。
- 数十件のサプライヤーの PDF を検索して、特定の成分の仕様書を見つけます。
- サプライヤー シートで、それらの材料に関連する隠れたアレルゲンを確認します。
実行時に 400 個の未加工の PDF を読み取って、これをその場で実行する AI エージェントを構築しようとすると、処理が遅く、費用がかかり、ハルシネーションが発生しやすくなります。代わりに、セマンティック推論を使用して、これらすべてをまずリレーショナル データベースに抽出します。これにより、将来の AI エージェントは高速になり、事実に基づく SQL データに 100% 基づくようになります。
構築を始めましょう。
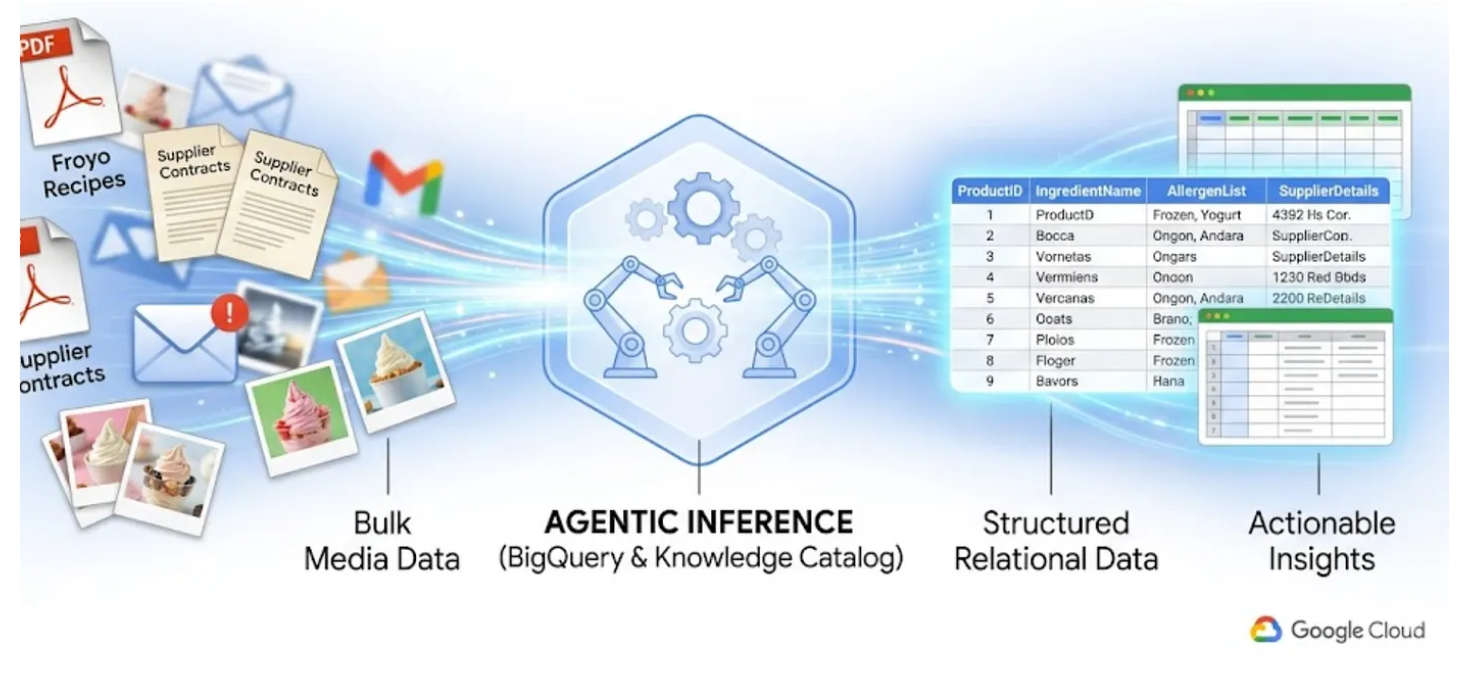
学習内容
- ソースファイル(PDF)用の Cloud Storage バケットを設定する方法
- Knowledge Catalog で Datascan ジョブとセマンティック推論を設定して実行し、ソース PDF からデータを抽出し、接続とコンテキストをセマンティックに推論して BigQuery に保存する方法
- BigQuery エージェントを使用して新しく作成したデータセットとチャットする方法
要件
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- Google Cloud 上で動作するコマンドライン環境の Cloud Shell を使用します。Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
![[Cloud Shell をアクティブにする] ボタンの画像](https://codelabs.developers.google.com/static/dark-data-agent-chat/img/91567e2f55467574.png?hl=ja)
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- 認証を行う場合
gcloud auth login
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- 必要な API を有効にする: 次のコマンドを実行して、必要な API をすべて有効にします。
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
注意点とトラブルシューティング
「ゴースト プロジェクト」症候群 |
|
請求のバリケード | プロジェクトを有効にしたが、請求先アカウントを忘れた。AlloyDB は高性能エンジンです。ガソリン タンク(課金)が空の場合、起動しません。 |
API 伝播の遅延 | [API を有効にする] をクリックしたのに、コマンドラインに |
割り当て Quags | 新しいトライアル アカウントを使用している場合は、AlloyDB インスタンスのリージョン割り当てに達する可能性があります。 |
「非表示」のサービス エージェント | AlloyDB サービス エージェントに |
3. Google Cloud Storage バケットの設定
このセクションでは、BigQuery 内に組織構造を作成して、Froyo のレシピとサプライヤーのデータ(特に Froyo 製品の詳細)を保存します。また、Cloud リソース接続も確立します。これは、BigQuery が Cloud Storage などの外部ソースからファイルを読み取ることができる安全な「ブリッジ」として機能します。
始める前に:
このリポジトリには、このプロジェクトで使用するレシピとサプライヤーの PDF ファイルが含まれています。これらのファイルをダウンロードしてください。ファイルをダウンロードする手順は次のとおりです。
Cloud Shell で、次のコマンドを実行します。
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
新しく作成したフォルダに移動します。
cd next-26-keynotes
data-cloud-demo フォルダを pull する
git sparse-checkout set genkey/data-cloud-demo
チェックアウトが完了したら、data-cloud-demo フォルダに移動し、ZIP ファイルを抽出して Codelab アセットにアクセスします。
バケットを作成して Froyo(レシピとサプライヤー)の PDF ファイルをアップロードする
- Google Cloud コンソールで、Cloud Storage の [バケット] ページに移動します。
- [作成] をクリックします。
- [バケットの作成] ページで、バケット情報を入力します。以下のステップでは、操作を完了した後に [続行] をクリックして、次のステップに進みます。
- [始める] セクションで、バケット名を入力します。例: froyo_data
- [データの保存場所の選択] セクションで、[リージョン] を選択し、リージョンを入力します。us-central1
- [オブジェクトへのアクセスを制御する方法を選択する] セクションで、[このバケットに対する公開アクセス禁止を適用する] チェックボックスをオフにします。
- [作成] をクリックします。
- バケットのリストで、作成したバケットをクリックします。
- バケットの [オブジェクト] タブで、[アップロード]、[フォルダをアップロード] の順にクリックします。
- この Codelab の「始める前に」セクションで抽出した recipes フォルダを選択します。
- [アップロード] をクリックします。
- suppliers フォルダでもアップロードの手順を繰り返します。
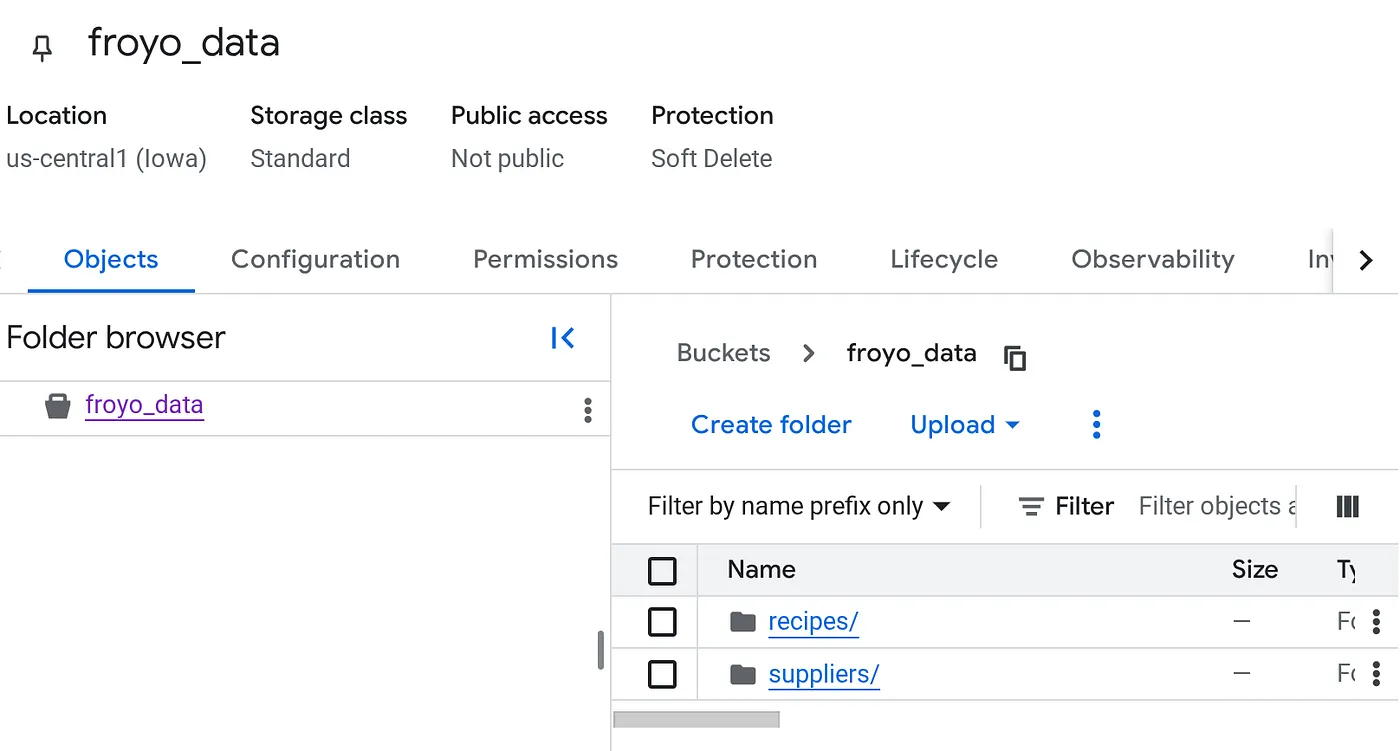
アップロードが完了すると、バケット構造は次のようになります(バケット名は任意)。
4. BigQuery 接続の設定
Cloud リソース接続を作成します。これにより、外部ファイルにアクセスするための BigQuery の「ID カード」として機能する一意のサービス アカウントが生成されます。
- [BigQuery] ページに移動します。
- 左側のペインで、[エクスプローラ] をクリックします。左側のペインが表示されていない場合は、[左ペインを開く] をクリックしてペインを開きます。
- [エクスプローラ] ペインで、プロジェクト名を開き、[接続] をクリックします。
- [接続] ページで、[接続を作成] をクリックします。
- [接続タイプ] で、[Vertex AI リモートモデル、リモート関数、BigLake、Spanner(Cloud リソース)] を選択します。
- [接続 ID] フィールドに、接続 ID 名を入力します。
- bq-connection。この ID は、この Codelab の後半でデータスキャンを設定する際に必要になるため、メモしておいてください。
- [ロケーション タイプ] を [リージョン] に設定し、リージョンを選択します。たとえば、us-central1 などです。この接続は、データセットなどの他のリソースと同じリージョンに配置する必要があります。
- [接続を作成] をクリックします。
- [接続に移動] をクリックします。
- [接続情報] ペインで、以降の手順で使用するサービス アカウント ID をコピーします。サービス アカウントは bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com のようになります。
5. 権限の設定
- Cloud Storage オブジェクトと Knowledge Catalog にアクセスするために必要な権限を BigQuery 接続に付与する
[IAM と管理] ページに移動し、[プリンシパル別に表示] セクションで [アクセス権を付与] ボタンをクリックし、前の手順でコピーしたサービス アカウントを貼り付けてプリンシパルを追加します。[ロール] セクションで、次のロールの名前を 1 つずつ追加して保存します。
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- Cloud Storage バケットにアクセスする権限を Dataplex サービス アカウントに付与する
[IAM と管理] ページに移動し、[プリンシパル別に表示] セクションで [アクセスを許可] ボタンをクリックし、[新しいプリンシパル] テキストバーに「dataplex」と入力してプリンシパルを追加します。自動補完されたリストから、次のような Dataplex サービス アカウント プリンシパルを選択します(下のサービス アカウントのメール ID にはプロジェクト ID ではなくプロジェクト番号を使用します)。
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
プロジェクト番号の上記のサービス アカウントが認識されない場合は、プロジェクトで dataplex サービスがまだ初期化されていない可能性があります。Cloud Shell ターミナルに移動し、次のコマンドを実行して API を有効にします(始める前にの手順でまだ有効にしていない場合)。gcloud services enable dataplex.googleapis.com
それでも Dataplex のサービス アカウントが認識されない場合は、[メタデータ キュレーション] ページでテスト Dataplex スキャン ジョブの作成を強制し、[検出ジョブの作成] ページに詳細を入力します。
[今すぐ実行] をクリックします。ジョブは失敗しますが、これにより、Dataplex サービスのサービス アカウント ID が初期化されます。
[IAM と管理] ページに戻り、[プリンシパル別に表示] セクションで、[アクセス権を付与] ボタンをクリックし、[プリンシパルを追加] をクリックします。サービス アカウントを貼り付けます。
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
次に、このサービス アカウントに次のロールを付与します。
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. Knowledge Catalog の設定
Knowledge Catalog を構築して非構造化データを統合し、非構造化ファイル(PDF レシピや PDF サプライヤーなど)の検出を自動化します。
コンソールから DataScan ジョブを作成します。
- [メタデータのキュレーション] ページに移動します。
- [作成] をクリックし、設定に対応する詳細を入力します。
重要な注意事項: [Enable Semantic Inference](セマンティック推論を有効にする)を忘れずにオンにしてください。
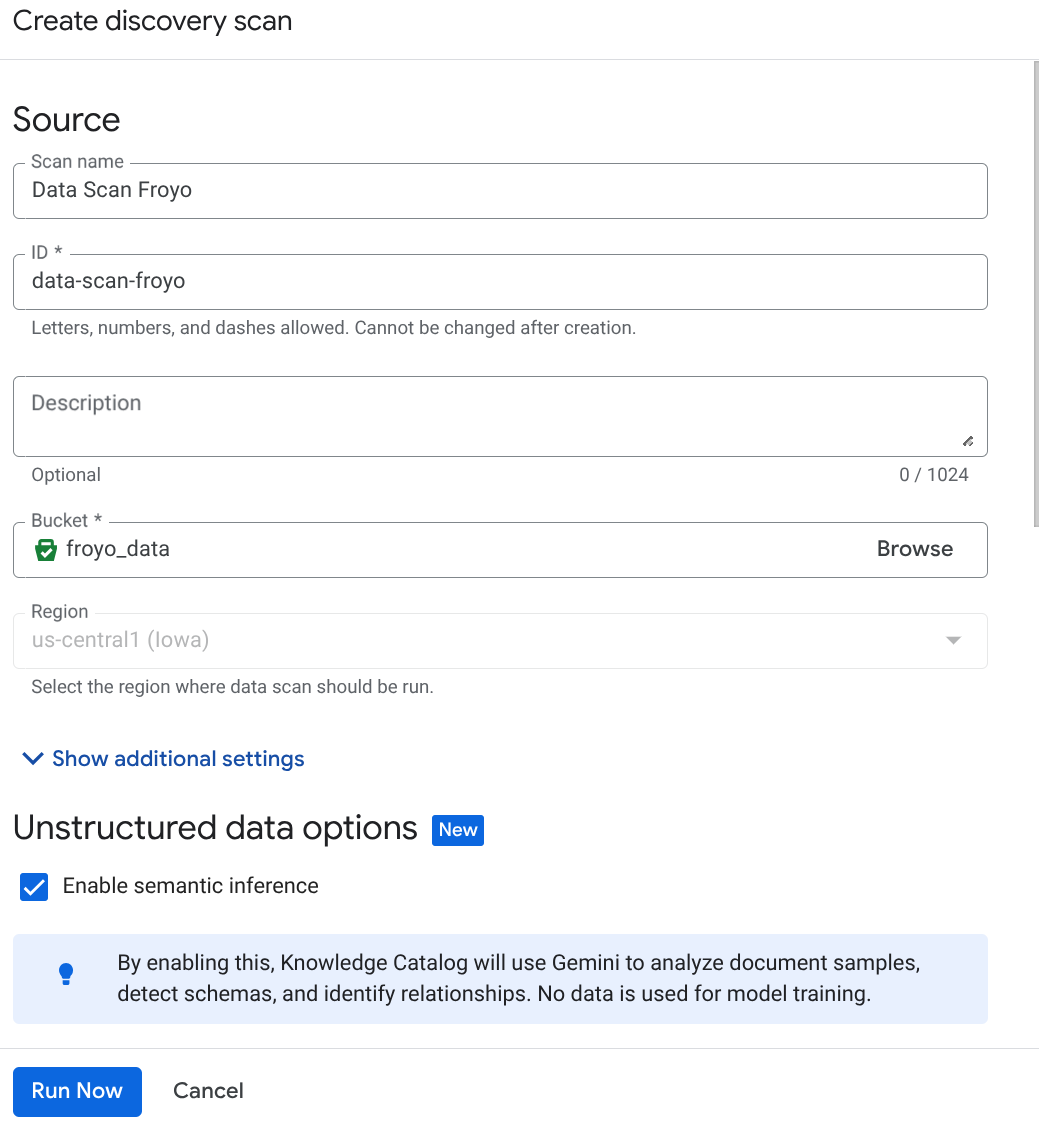
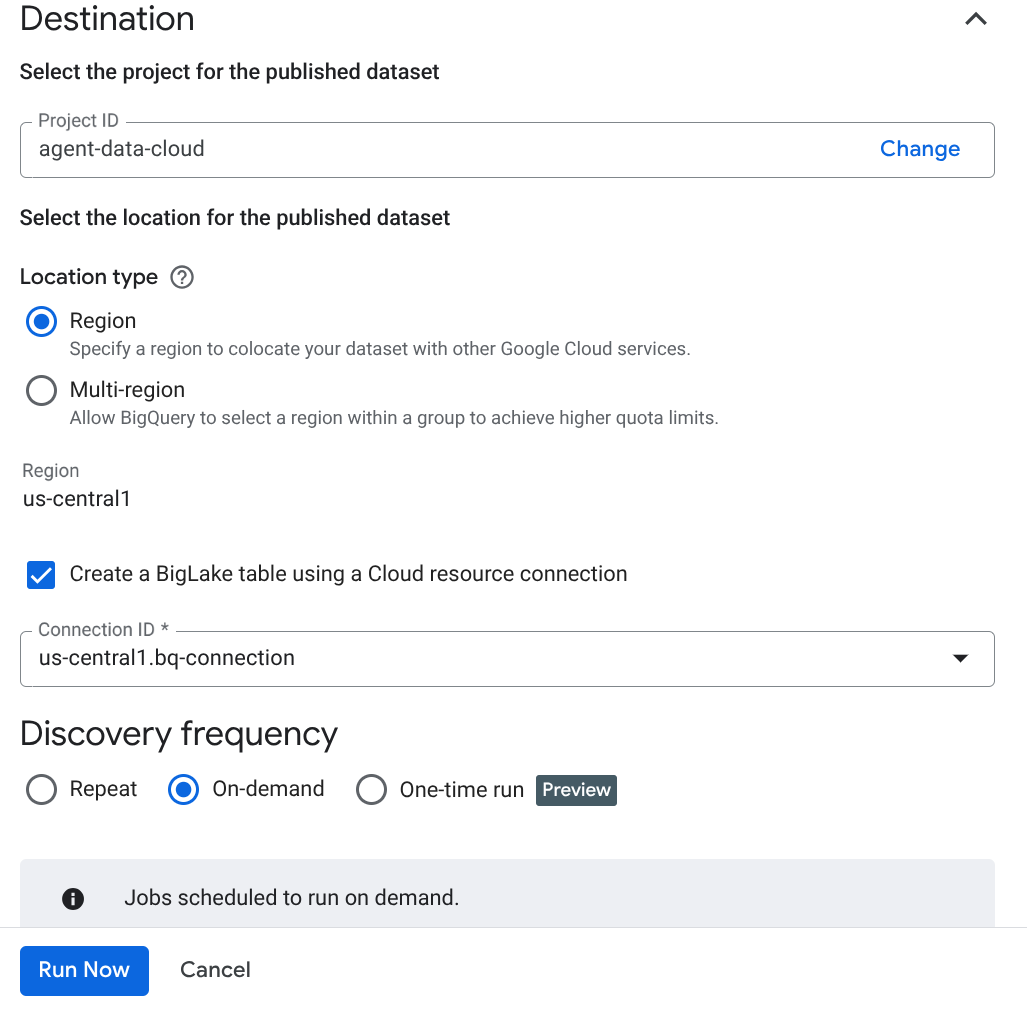
- [今すぐ実行] をクリックします。
- スキャン ジョブが完了するまでしばらく時間がかかります。ジョブが完了したら、公開されたデータセットが存在するかどうかを確認します。ジョブのステータスを確認するには、[メタデータのキュレーション] ページの [Cloud Storage の検出] タブで、最近実行された検出スキャンの名前をクリックします。次のように、公開されたデータセットが表示されます。
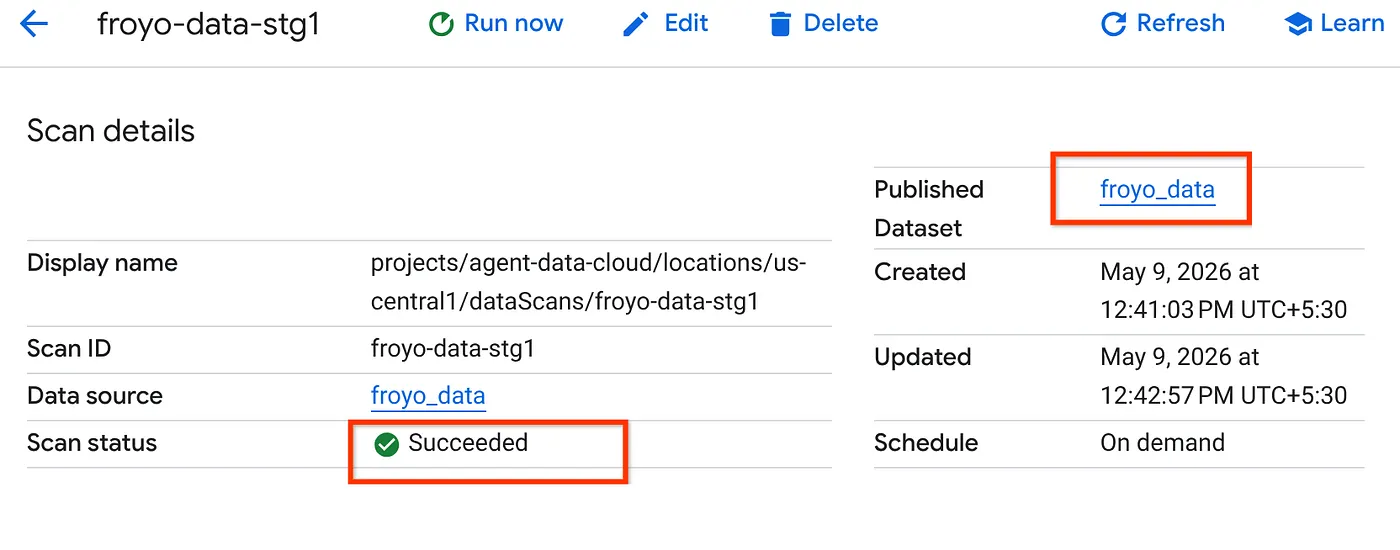
注: スキャン ステップでエラーが発生した場合は、しばらく待ってから再試行してください(ジョブの作成と実行の完了には数分かかります)。
- BigQuery でテーブルを表示するには、froyo_data データセットをクリックして移動します。BigQuery でテーブル ID をクリックし、[クエリエディタ] タブで次のクエリを実行します。
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
これにより、400 が返されます(返されない場合は、戻って Datascan ジョブを再度実行します)。
7. セマンティック データ抽出
素晴らしい!!次に、Knowledge Catalog を使用して、これらの非構造化オブジェクトの推論を抽出します。
分析情報機能を使用して、構造化されていないテーブルから構造化データを抽出する SQL ステートメントを生成します。
- Google Cloud コンソールで、[Knowledge Catalog 検索] ページに移動します。
- 分析情報を表示するデータセット テーブルを検索します。検索バーに、前の手順のデータセット / テーブル名「froyo_data」を入力して、Enter キーを押します。
- 結果リストで、TABLE エントリ(データセット エントリではない)をクリックします。
- [分析情報] タブが表示されます。それをクリックします(API の有効化が必要な場合は、手順に沿って API を有効にします)。
この時点で API を有効にした場合は、スキャンジョブを再度実行する必要があります。
- [INSIGHTS] タブに、[EXTRACT] ボタンのプルダウンが表示されます。それをクリックして、[SQL で抽出] オプションを選択します。
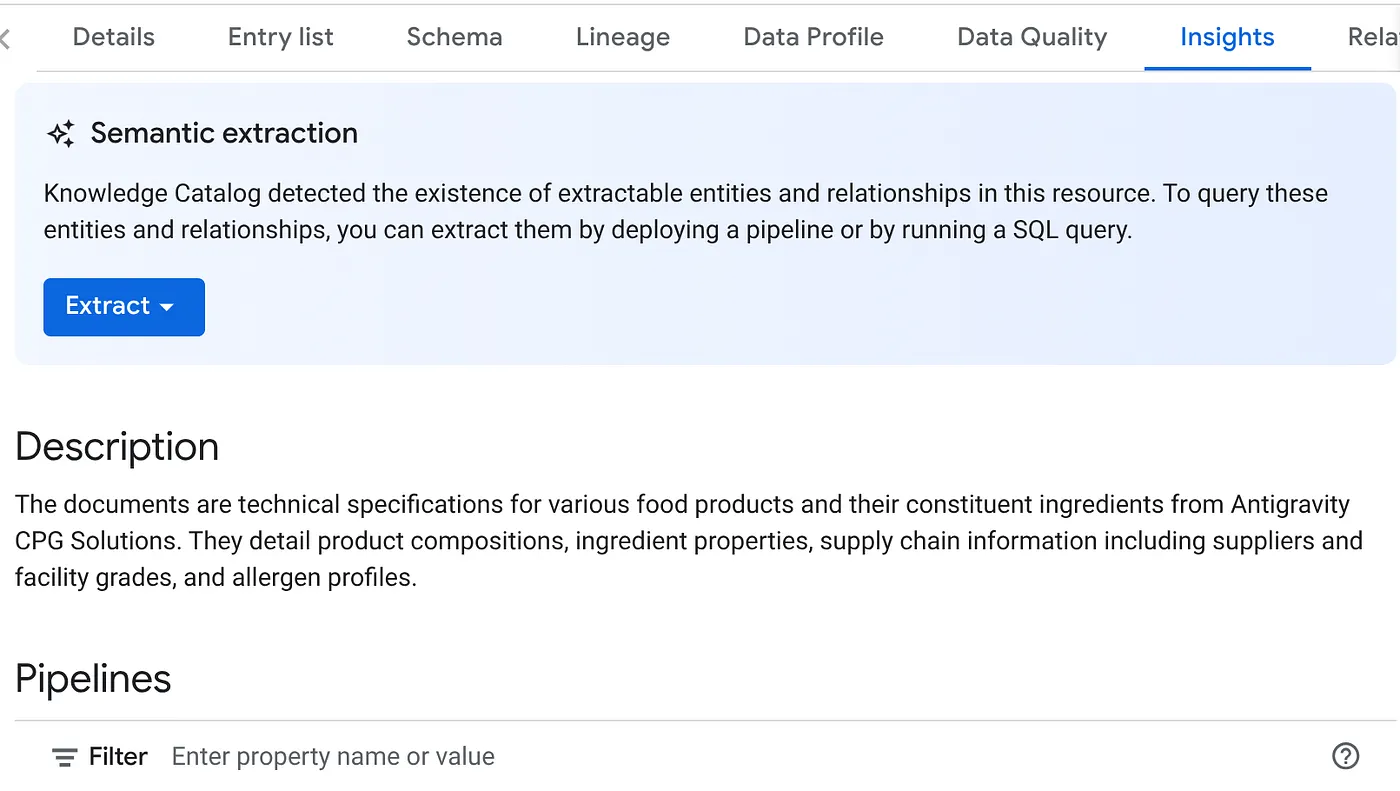
[SQL で抽出] ダイアログ ポップアップで、宛先データセットをデータスキャン ジョブの結果に表示されたデータセットとして設定します。名前の入力を開始すると、自動補完で表示されます。[解凍] ボタンをクリックします。この時点で新しいデータセットを作成して抽出することもできます。
これにより、データスキャン推論から抽出された SQL が入力されたタブが開いた状態で、BigQuery クエリエディタが開きます。
8. SQL の検証とスキーマの作成
生成されたクエリが適切で、非構造化データと意味的に関連していると思われる場合は、クエリエディタの [実行] ボタンをクリックして実行します。非構造化メディアの構造化ストレージに必要なスキーマの作成には数分かかります。
完了すると、次のように BigQuery Studio のエクスプローラ ペインでデータセットを開いてスキーマを確認できます。
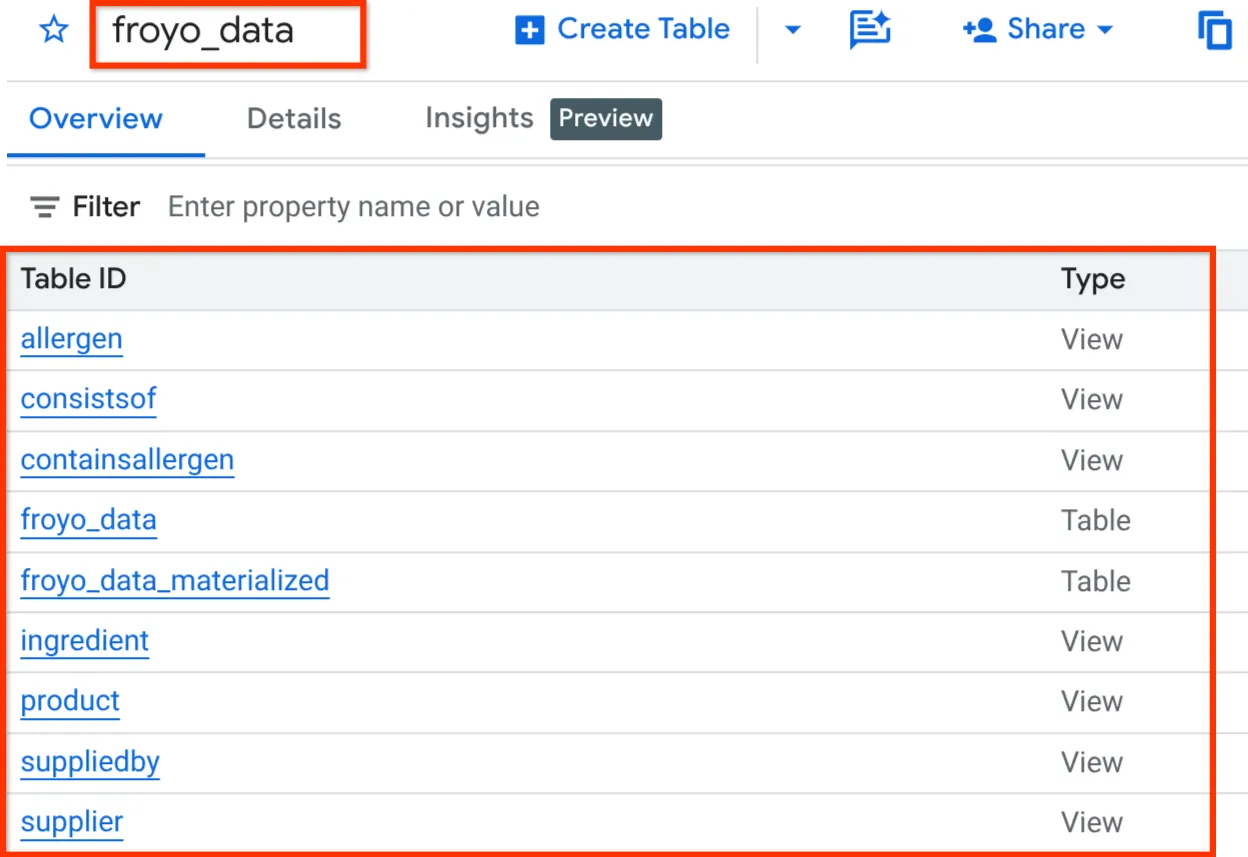
承知いたしました。データベース関連の作業をすべて迅速に完了できたのは、本当に素晴らしいことでした。いよいよ最終テストです。
請求先アカウントなしでデータを引き続き利用する手順:
- 上記の github repo リンクから、データ csv ファイル(BigQuery データ)を取得できます。
- まず、Cloud Shell ターミナルから次のコマンドを実行して、BigQuery データセットを作成します。
bq mk --location us-central1 --dataset froyo_data
- 次に、次のコマンドを 1 つずつ実行して、GitHub リポジトリから 8 個のデータファイル(CSV ファイル)をワーキング ディレクトリにダウンロードします。
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- 次のコマンドを 1 つずつ実行して、新しく作成したデータセットのデータを使用してこれらのテーブルを作成します。
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
データセット、テーブル、データが作成されたら、テストに進み、先ほど説明したデータを体験できます。
9. 究極のテスト!!!
エージェントが事実に基づいた、完全で適切に調整された情報でユーザーの質問に回答するようにしたいとします。エージェントが複数のメディア ファイルとソースの参照元を参照しないと回答できない質問をします。
お客様からの質問は次のとおりです。
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
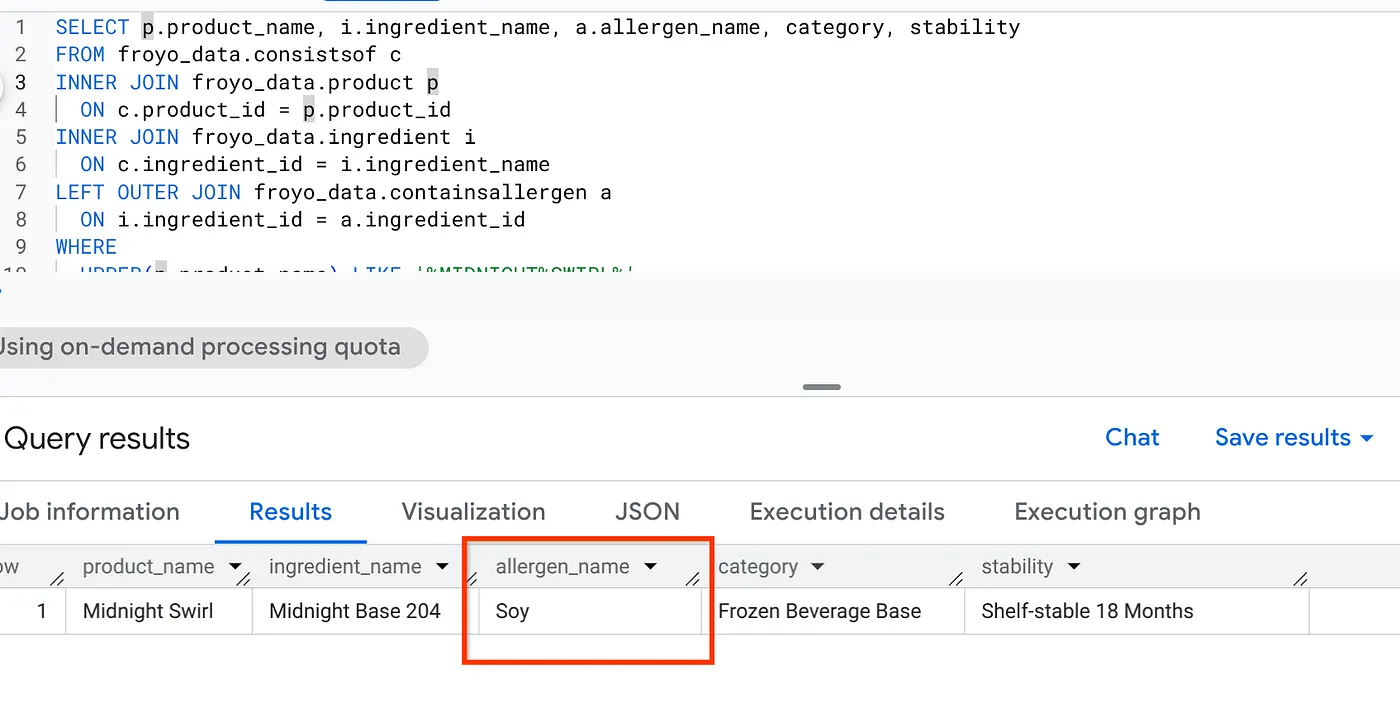
これで、一般的な検索や LLM 検索で「材料なし」と表示されるようになります。しかし、すべての非構造化メディアを構造化データに変換する完全なセマンティック推論を構築しました。この情報を取得する簡単な SQL は次のとおりです。
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
おめでとうございます!結果を確認します。
10. クリーンアップ
このラボが完了したら、スキャンジョブと、ジョブによって作成された BigQuery テーブルを削除してください。
https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery に移動します。削除するジョブを選択するには、ジョブの横にある縦の省略記号をクリックし、[削除] をクリックします。
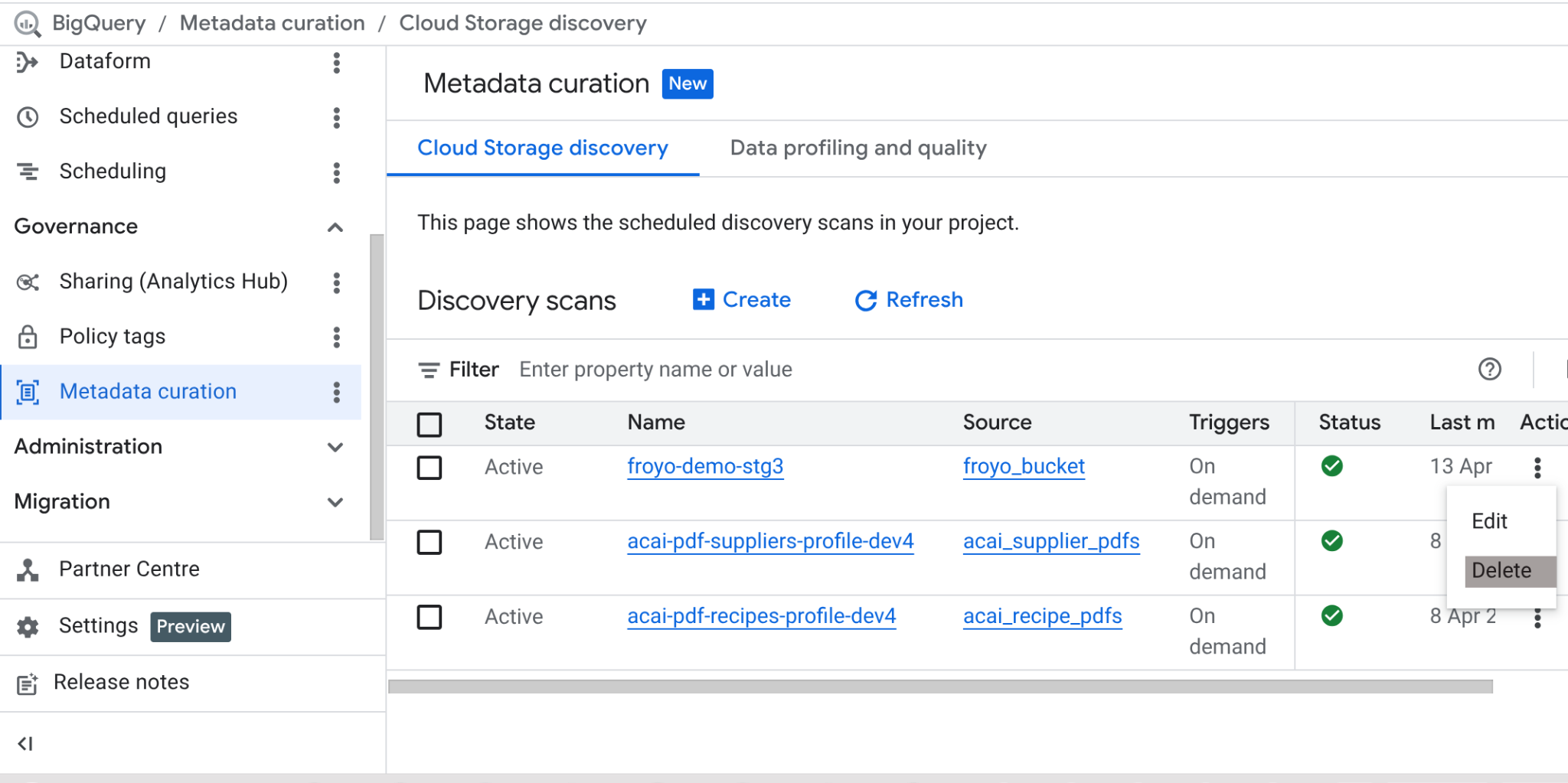
ジョブがクリーンアップされます。
11. 完了
この実装により、隠れたアレルゲンを特定できました。ダークデータはもう不要です。パート 2 では、この BigQuery データを AlloyDB を使用してトランザクション システムに統合し、エージェント アプリケーションのデータニーズを統合します。