
1. 概要
In パート 1 では、Knowledge Catalog と DataScan を使用して、カオスな非構造化 PDF をクリーンでインテリジェントな構造化テーブルに BigQuery で変換しました。これで、堅牢なデータ ウェアハウスができました。
パート 1 のラボでは、架空のフローズン ヨーグルト フランチャイズのユースケースを取り上げ、テキスト、テーブル、画像にまたがる 400 個の非構造化 PDF ファイルを、BigQuery Knowledge Catalog と Dataplex を使用して、関係が自動的に推測されるクリーンな構造化 BigQuery テーブルに変換しました。
作成するアプリの概要
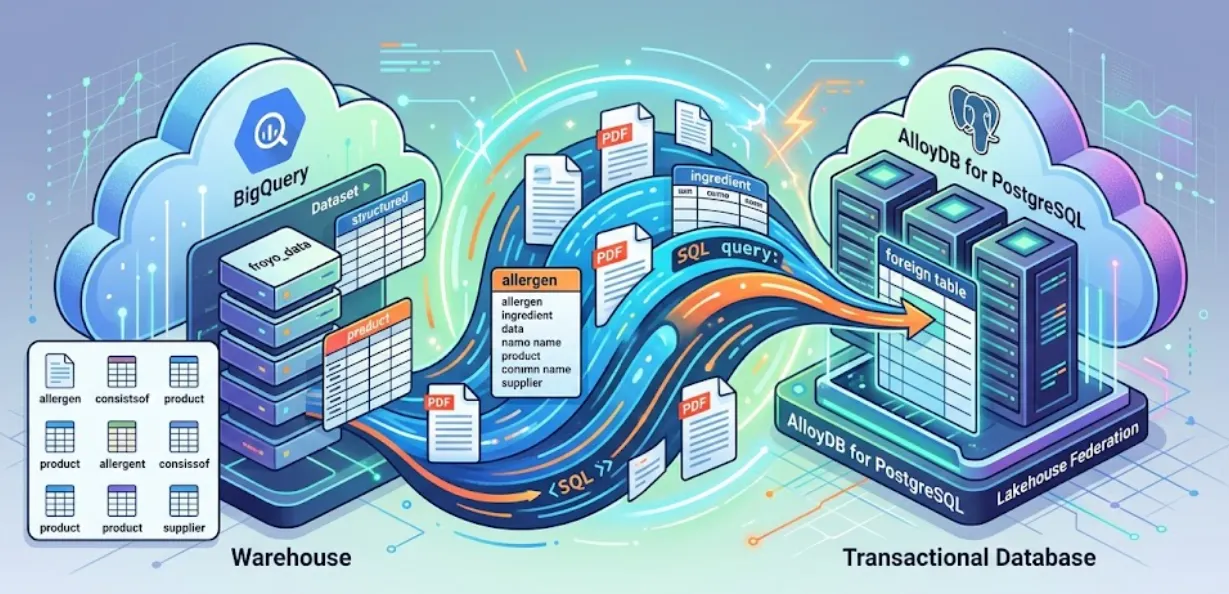
このセッションでは、AlloyDB for PostgreSQL を設定し、BigQuery データを AlloyDB に直接統合するという魔法のようなことを行います。つまり、トランザクション アプリは、データをコピーまたは複製することなく、ウェアハウス データにリアルタイムでクエリを実行できます。
デベロッパーは、この段階で次の質問をする必要があります。
「データがすでに BigQuery にあるのに、なぜ AlloyDB を使用するのですか?アプリケーションが BigQuery に対して SELECT ステートメントを直接実行しないのはなぜですか?」
理由は次のとおりです。
Lakehouse Federation を使用すると、AlloyDB のクエリエンジンを利用して、同じインターフェース内でアプリケーションのトランザクション ワークロードと分析ワークロードを強化できます。さらに、このデータを AlloyDB で具体化またはインポートして、アプリケーションで使用する際のアクセスを高速化し、AlloyDB AI および カラム型エンジン を使用できるようになります。
AlloyDB をトランザクション データベースとして使用しつつ、BigQuery または BigLake に大量のデータを保存できます。通常、アプリケーションは、こうした異なる Google Cloud サービスにまたがるデータにアクセスするために両システムとは個別に統合されます。 AlloyDB の Lakehouse Federation を使用すると、外部データラッパーとして実装された AlloyDB の連携クエリサポートを利用して、AlloyDB の SQL インターフェースを通じて BigQuery と AlloyDB のデータにアクセスできます。
AlloyDB から BigQuery データにクエリを実行するために脆弱な ETL パイプラインを構築する代わりに、連携クエリを使用します。AlloyDB は統合エンドポイントとして機能し、必要に応じて BigQuery にシームレスにアクセスします。
構築を開始しましょう。
学習内容
- ボタンをクリックして AlloyDB クラスタ、インスタンス、ネットワークを設定する方法
- 連携の準備として拡張機能を設定する方法
- BigQuery から AlloyDB への連携を設定する方法
- テストする
要件
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- Google Cloud 上で動作するコマンドライン環境の Cloud Shell を使用します。Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン をクリックします。
![[Cloud Shell をアクティブにする] ボタンの画像](https://codelabs.developers.google.com/static/federate-bq-to-alloydb/img/91567e2f55467574.png?hl=ja)
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- 認証する場合は
gcloud auth login
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- 必要な API を有効にします。次のコマンドを実行して、必要な API をすべて有効にします。
gcloud services enable alloydb.googleapis.com
注意点とトラブルシューティング
「ゴースト プロジェクト」 シンドローム |
|
**請求** のバリケード | プロジェクトを有効にしましたが、請求先アカウントを忘れていました。AlloyDB は高性能エンジンです。「ガソリン タンク」(請求)が空の場合、起動しません。 |
API の伝播 の遅延 | [API を有効にする] をクリックしましたが、コマンドラインに |
割り当て の問題 | 新しいトライアル アカウントを使用している場合は、AlloyDB インスタンスのリージョン割り当てに達している可能性があります。 |
3. パート 1 のデータの簡単なまとめ
このセクションでは、非構造化 PDF から抽出した構造化データが BigQuery で使用できることを確認する必要があります。 パート 1 を見逃した場合や、請求先アカウントがない場合は、次の手順を完了して開始できます。
個人の Gmail アカウントから Google Cloud コンソールに移動し、コンソールの右上にある [Cloud Shell をアクティブにする] ボタンをクリックします。
次に、以下の [請求先アカウントがない場合] セクションの手順に沿って操作します。
請求先アカウントなしでデータの操作を続行する手順:
- 上記の GitHub リポジトリ リンクからデータ csv ファイル(BigQuery データ)を取得できます。
- まず、Cloud Shell ターミナルから次のコマンドを実行して、BigQuery データセットを作成します。
bq mk --location us-central1 --dataset froyo_data
- 次に、次のコマンドを 1 つずつ実行して、GitHub リポジトリから 8 つのデータファイル(CSV ファイル)を作業ディレクトリにダウンロードします。
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- 次のコマンドを 1 つずつ実行して、新しく作成したデータセットにデータを含むテーブルを作成します。
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
BigQuery にデータが用意できたので、次のステップに進みましょう。
4. AlloyDB クラスタ、インスタンス、ネットワークを設定する
AlloyDB クラスタ、インスタンス、その他の依存関係の設定に役立つウェブベースのクイックスタート アプリケーションがあります。このラボの手順 2 ~ 4 に沿って、ボタンをクリックして設定できます。
https://codelabs.developers.google.com/quick-alloydb-setup
クラスタが作成されたら、[クラスタの概要] ページに移動し、サービス アカウントの詳細をコピーします。
5. 権限の設定
このサービス アカウントに BigQuery の権限を付与する
- [IAM と管理]、[IAM] の順に移動します。
- [アクセス権を付与] をクリックします。
- [新しいプリンシパル] フィールドに AlloyDB サービス アカウントのアドレスを貼り付けます。
- 次のロールを割り当てます。
- BigQuery データ閲覧者 (roles/bigquery.dataViewer): データの読み取りを許可します。
- BigQuery ユーザー (roles/bigquery.user): クエリの実行を許可します。
- (省略可ですが推奨)BigQuery 読み取りセッション ユーザー (roles/bigquery.readSessionUser): Storage Read API を介して大規模なデータセットの読み取りを最適化します。
6. AlloyDB に接続して BigQuery 拡張機能を有効にする
ここで、新しい AlloyDB インスタンスに接続して、統合拡張機能を構成します。これには AlloyDB Studio を使用します。
- [クラスタの概要] ページ(AlloyDB コンソール)で、プライマリ インスタンスの [プライマリを編集] をクリックし、一番下までスクロールして [詳細構成オプション] に移動します。
- [**フラグ**] セクションに移動し、次の図のように 2 つのフラグを [**オン**] にします。
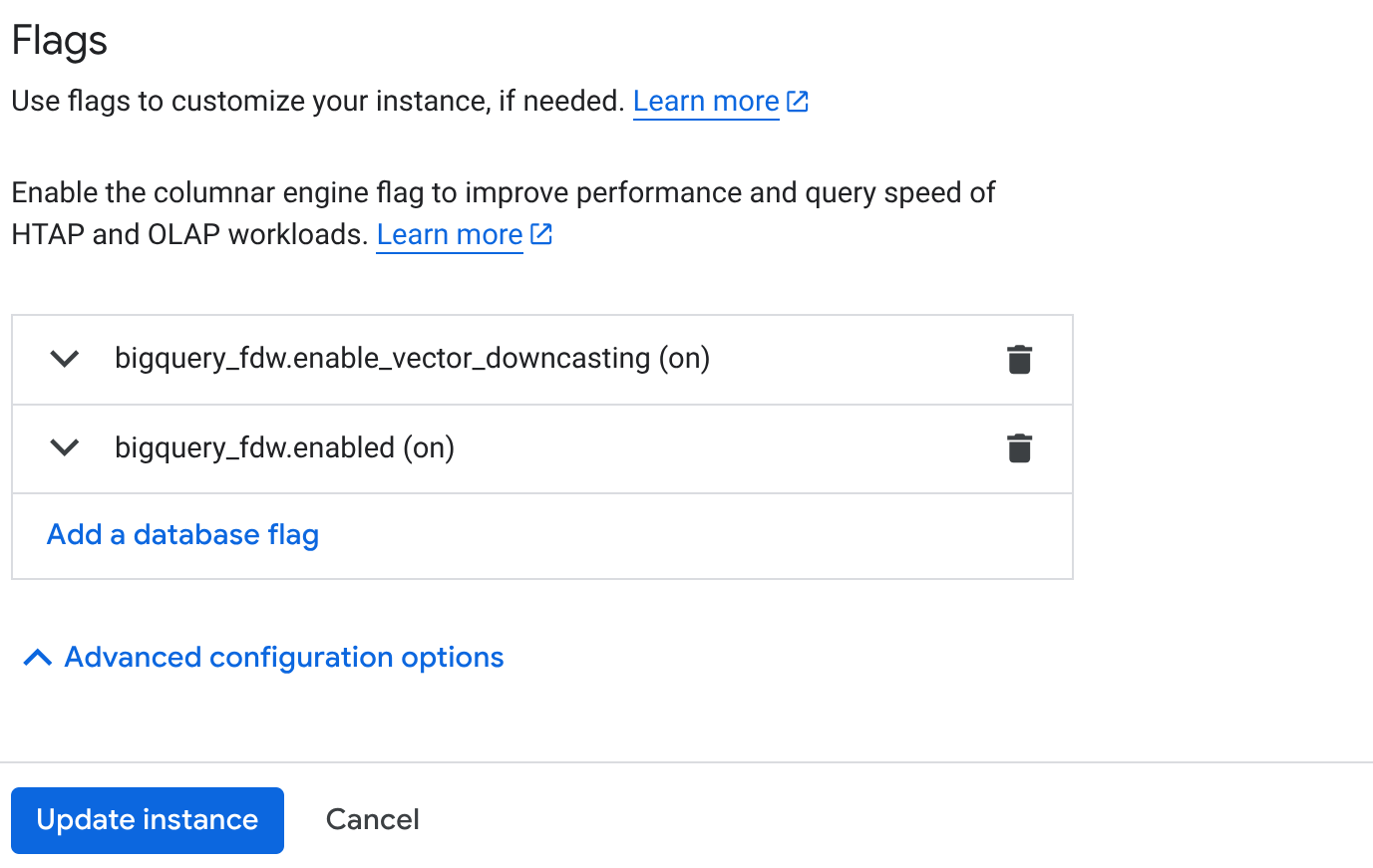 3. [インスタンスを更新] ボタンをクリックすると、更新が完了するまでに数分かかります。4. [クラスタの概要] ページ(AlloyDB コンソール)で、[AlloyDB Studio] をクリックします。
3. [インスタンスを更新] ボタンをクリックすると、更新が完了するまでに数分かかります。4. [クラスタの概要] ページ(AlloyDB コンソール)で、[AlloyDB Studio] をクリックします。
- AlloyDB のクイック設定ステップで構成したデータベース、ユーザー名、パスワードで接続します。
- 接続したら、右側の [クエリエディタ] タブで次のステートメントを入力し、1 つずつ実行します。
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- 完了したら、左側のエクスプローラ ペインに移動し、BigQuery テーブルまでスクロールします。
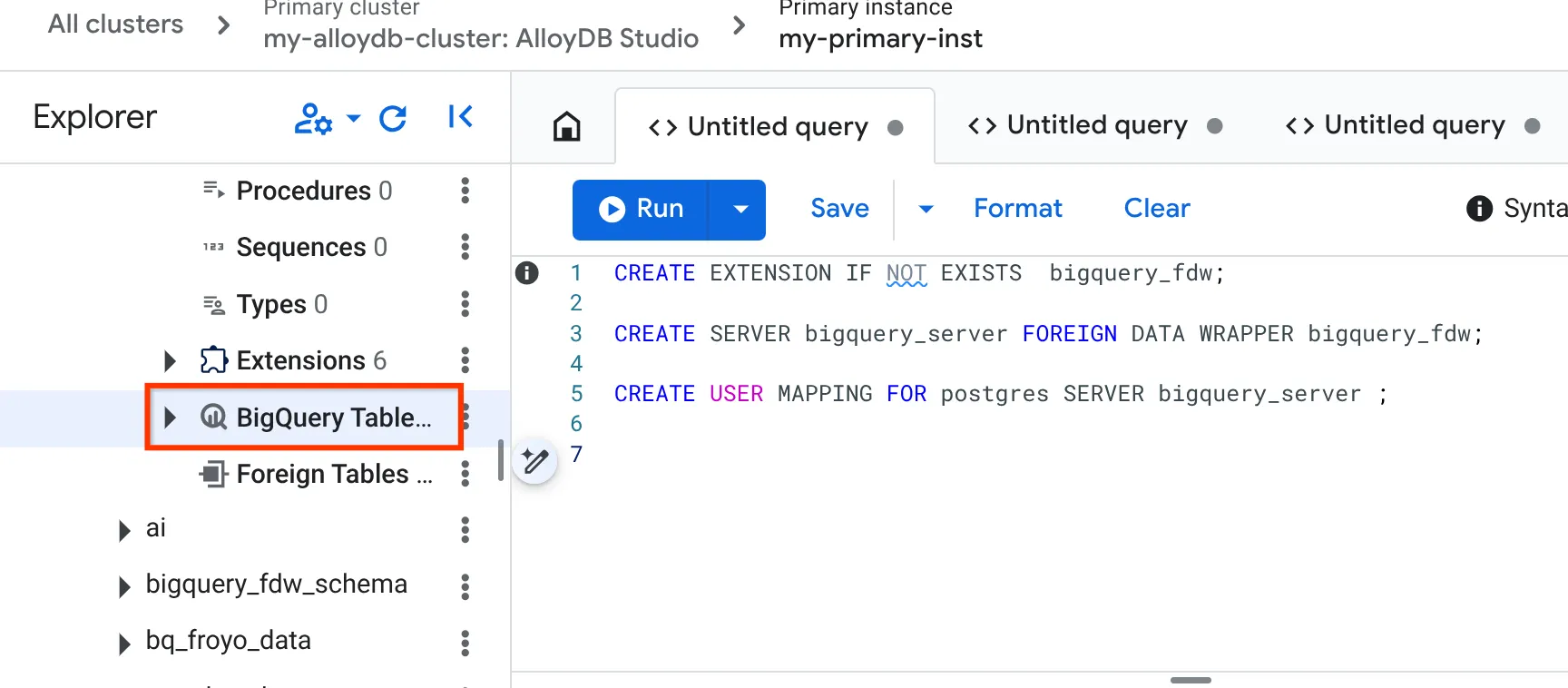
- 3 つのドットをクリックし、[BigQuery テーブルを接続] をクリックします。
- [BigQuery テーブルを接続] ポップアップが開いたら、project_id と、AlloyDB データベースでクエリを実行する BigQuery データセット名(パート 1 で作成)を選択します。
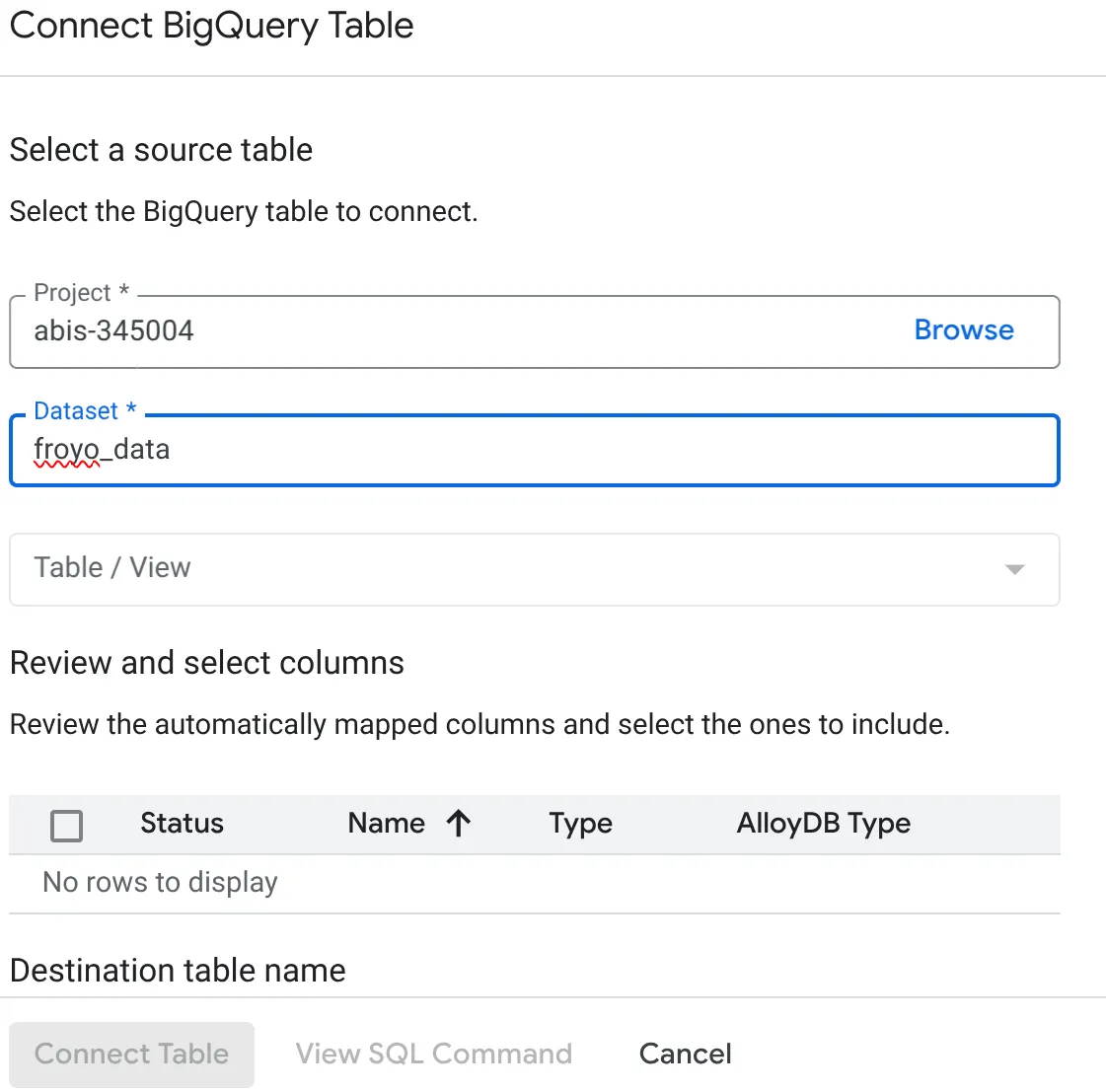
- 各テーブルを 1 つずつ選択 して、すべてのデータを AlloyDB に接続します。これは、列の型を検証して、AlloyDB でサポートされていることを確認するためです。
SQL でポイントアンドクリックではなくinsteadで同じことを行う場合は、次のようになります。
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
魔法!!!
AlloyDB に「外部テーブル」を作成しました。これらは通常の PostgreSQL テーブルのように見えますが、データを保存しません。クエリを実行すると、AlloyDB はクエリを BigQuery に即座に渡し、結果を取得して返します。
7. AlloyDB で連携をテストする
トランザクション PostgreSQL データベースから大規模な分析用 BigQuery データセットに直接クエリを実行できることを確認しましょう。
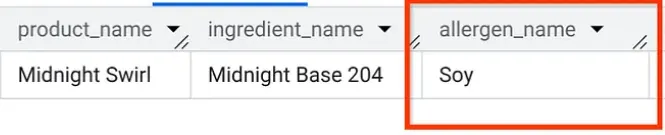
AlloyDB Studio で、クエリを実行して「Midnight Swirl」に含まれるアレルゲンを調べます(パート 1 と同じ質問ですが、今回は AlloyDB から質問します)。
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
簡単に見つかります。BigQuery とまったく同じ結果が表示されます。
8. クリーンアップ
このラボが完了したら、AlloyDB クラスタとインスタンスを削除してください。
クラスタとそのインスタンスがクリーンアップされます。
9. 統合データレイヤの完成
達成したことを考えてみましょう。
- トランザクション アプリ(AlloyDB で実行)は、同時実行のユーザー セッションを迅速に処理できます。
- 大量の分析データや履歴コンテキスト(サプライヤの詳細や複雑な成分マッピングなど)が必要な場合は、BigQuery froyo_dataschema にクエリを実行します。
- ETL は不要です。データ パイプラインが破損することはありません。データベースが同期しなくなることはありません。1 回保存(BQ)して、必要な場所で計算します。
分析とトランザクションの両方のデータ基盤が堅牢で相互接続されたので、楽しい部分に進みましょう。
パート 3 では、このアーキテクチャ上に Froyo のビジネス オペレーションを実行するマルチエージェント アプリケーションを構築します。