
1. Przegląd
Wszyscy znamy problem „ciemnych danych”. Są to pliki PDF, obrazy i pliki tekstowe znajdujące się w zasobnikach pamięci w chmurze, całkowicie niewidoczne dla zapytań SQL i paneli BI. Tradycyjnie odblokowanie tych danych wymagało złożonych potoków OCR, ręcznego wprowadzania danych lub niestabilnych skryptów niestandardowych.
To już nie jest problem.
W tym module pokażę Ci, jak przekonwertować 400 nieuporządkowanych plików PDF zawierających tekst, tabele i obrazy na uporządkowane tabele BigQuery z automatycznie wywnioskowanymi relacjami między nimi. Zrobimy to w kilka minut za pomocą BigQuery, Knowledge Catalog i Dataplex.
Co utworzysz
Aby to zilustrować, przyjrzyjmy się fikcyjnej firmie: szybko rozwijającej się sieci franczyzowej z mrożonymi jogurtami.
Załóżmy, że zarządzasz danymi tej firmy Froyo. Masz setki przepisów i arkuszy specyfikacji dostawców, wszystkie zapisane w formacie PDF. Kierownictwo firmy chce wdrożyć agenta AI, który pomoże kierownikom sklepów i klientom w uzyskiwaniu szczegółowych informacji o produktach.
Oto koszmarny scenariusz: klient pyta: „Bardzo interesuje mnie Twój mrożony jogurt Midnight Swirl. Czy zawiera alergeny?
Aby odpowiedzieć na to pytanie, system musiałby zwykle:
- Znajdź plik PDF z przepisem na „Midnight Swirl”.
- Przeczytaj listę składników (np. „Kakao w proszku”, „Baza mleczna”, „Emulgator X”).
- Przeszukaj dziesiątki plików PDF od dostawców, aby znaleźć arkusze danych dla konkretnych składników.
- Sprawdź arkusze dostawców pod kątem ukrytych alergenów związanych z tymi składnikami.
Próba zbudowania agenta AI, który robi to na bieżąco, odczytując 400 surowych plików PDF w czasie działania, jest powolna, kosztowna i podatna na halucynacje. Zamiast tego użyjemy wnioskowania semantycznego, aby najpierw wyodrębnić wszystkie te informacje do relacyjnej bazy danych, dzięki czemu nasz przyszły agent AI będzie błyskawiczny i w 100% oparty na rzeczywistych danych SQL.
Zacznijmy tworzyć.
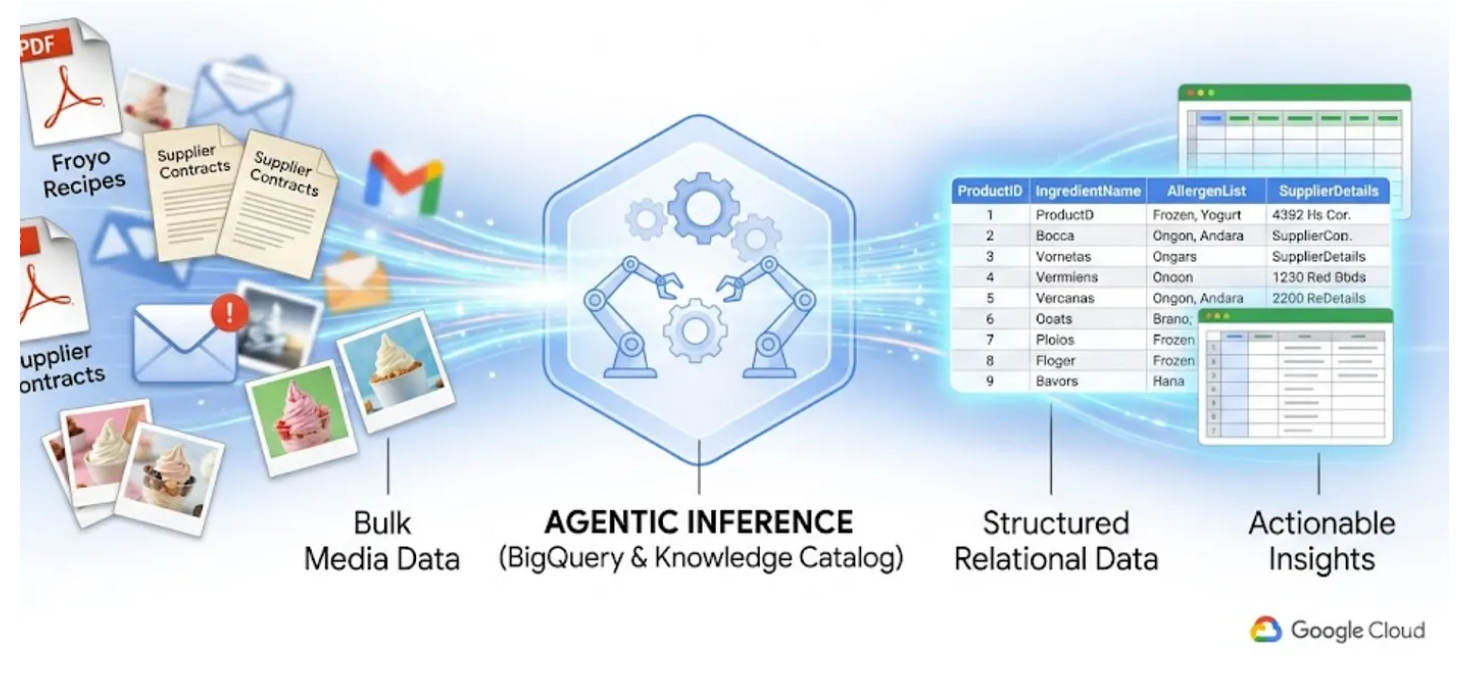
Czego się nauczysz
- Konfigurowanie zasobnika Cloud Storage dla plików źródłowych (PDF)
- Jak skonfigurować i uruchomić zadanie skanowania danych oraz wnioskowanie semantyczne w Knowledge Catalog, aby wyodrębniać dane ze źródłowych plików PDF, semantycznie wnioskować o połączeniach i kontekście oraz przechowywać je w BigQuery
- Jak używać agentów BigQuery do czatowania z nowo utworzonym zbiorem danych
Wymagania
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie włączone są płatności.
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli chcesz się uwierzytelnić
gcloud auth login
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API: aby włączyć wszystkie wymagane interfejsy API, uruchom to polecenie:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
Pułapki i rozwiązywanie problemów
Syndrom „projektu widma” | Uruchomiono polecenie |
Bariera rozliczeniowa | Projekt został włączony, ale zapomniano o koncie rozliczeniowym. AlloyDB to silnik o wysokiej wydajności, który nie uruchomi się, jeśli „zbiornik paliwa” (płatności) jest pusty. |
Opóźnienie propagacji interfejsu API | Kliknięto „Włącz interfejsy API”, ale w wierszu poleceń nadal wyświetla się |
Quota Quags | Jeśli korzystasz z nowego konta próbnego, możesz osiągnąć regionalny limit instancji AlloyDB. Jeśli |
Ukryty agent usługi | Czasami agentowi usługi AlloyDB nie jest automatycznie przyznawana rola |
3. Konfigurowanie zasobnika Google Cloud Storage
W tej sekcji utworzysz w BigQuery strukturę organizacyjną do przechowywania danych o przepisach i dostawcach Froyo, w szczególności szczegółów produktu Froyo. Ustanawia też połączenie zasobu Cloud, które działa jak bezpieczny „most” umożliwiający BigQuery odczytywanie plików ze źródeł zewnętrznych, takich jak Cloud Storage.
Zanim zaczniesz:
To repozytorium zawiera przepisy i pliki PDF dostawców, których użyjemy w tym projekcie. Pobierz te pliki. Aby pobrać pliki, wykonaj te czynności.
W Cloud Shell uruchom to polecenie:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
Przejdź do nowo utworzonego folderu:
cd next-26-keynotes
Pobierz folder data-cloud-demo.
git sparse-checkout set genkey/data-cloud-demo
Po zakończeniu płatności otwórz folder data-cloud-demo i wyodrębnij pliki ZIP, aby uzyskać dostęp do zasobów codelabu.
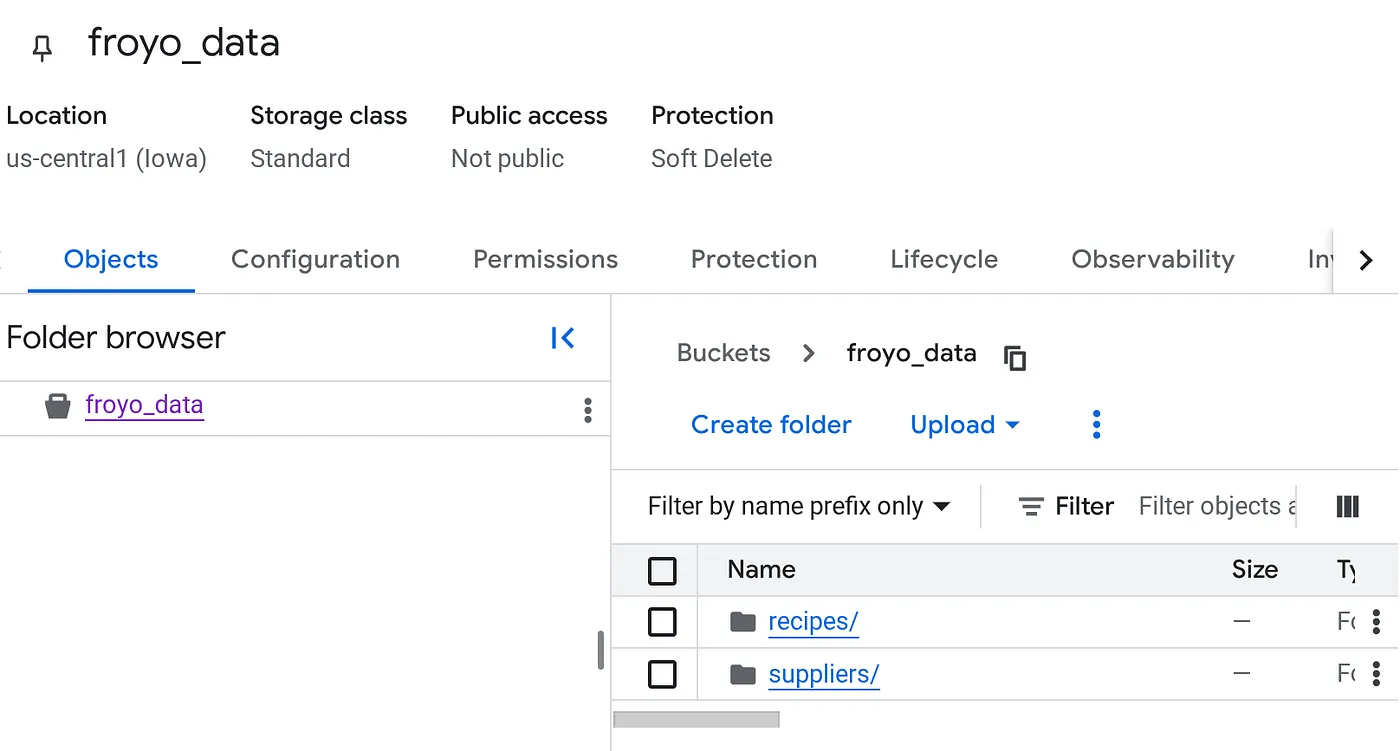
Utwórz zasobnik i prześlij pliki PDF Froyo (przepisy i dostawcy)
- W konsoli Google Cloud otwórz stronę Zasobniki Cloud Storage.
- Kliknij Utwórz.
- Na stronie Utwórz zasobnik wpisz informacje o zasobniku. Po wykonaniu każdego z tych kroków kliknij Dalej, aby przejść do następnego:
- W sekcji Rozpocznij wpisz nazwę zasobnika. Przykład: froyo_data
- W sekcji Wybierz miejsce przechowywania danych wybierz Region, a następnie wpisz swój region. us-central1
- W sekcji Wybierz sposób kontrolowania dostępu do obiektów odznacz pole wyboru Wyegzekwuj blokadę dostępu publicznego do tego zasobnika.
- Kliknij Utwórz.
- Na liście zasobników kliknij utworzony zasobnik.
- Na karcie Obiekty zasobnika kliknij Prześlij, a następnie Prześlij foldery.
- Wybierz folder recipes, który został wyodrębniony w sekcji Zanim zaczniesz w tym laboratorium.
- Kliknij przycisk Prześlij.
- Powtórz proces przesyłania w przypadku folderu suppliers.
Po przesłaniu struktura zasobnika powinna wyglądać tak (gdzie „nazwa_zasobnika” to nazwa zasobnika):
4. Konfigurowanie połączenia z BigQuery
Utwórz połączenie z zasobem Cloud. Spowoduje to wygenerowanie unikalnego konta usługi, które będzie pełnić rolę „karty identyfikacyjnej” BigQuery umożliwiającej dostęp do plików zewnętrznych.
- Otwórz stronę BigQuery.
- W panelu po lewej stronie kliknij Eksplorator. Jeśli nie widzisz lewego panelu, kliknij Rozwiń lewy panel, aby go otworzyć.
- W panelu Eksplorator rozwiń nazwę projektu, a następnie kliknij Połączenia.
- Na stronie Połączenia kliknij Utwórz połączenie.
- W polu Typ połączenia wybierz Modele zdalne Vertex AI, funkcje zdalne, BigLake i Spanner (zasób Cloud).
- W polu Identyfikator połączenia wpisz nazwę identyfikatora połączenia:
- bq-connection. Zapisz ten identyfikator, ponieważ będzie on potrzebny podczas konfigurowania skanowania danych w dalszej części tego ćwiczenia.
- Ustaw Typ lokalizacji na Region, a następnie wybierz region. Na przykład us-central1. Połączenie powinno znajdować się w tym samym regionie co inne zasoby, np. zbiory danych.
- Kliknij Utwórz połączenie.
- Kliknij Przejdź do połączenia.
- W panelu Informacje o połączeniu skopiuj identyfikator konta usługi, którego użyjesz w kolejnym kroku. Konto usługi wygląda podobnie do tego: bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
5. Konfiguracja uprawnień
- Przyznaj połączeniu BigQuery uprawnienia niezbędne do uzyskiwania dostępu do obiektów Cloud Storage i Knowledge Catalog
Otwórz stronę Administracja i w sekcji Wyświetl według podmiotów zabezpieczeń kliknij przycisk Przyznaj dostęp. Dodaj podmiot zabezpieczeń, wklejając konto usługi skopiowane w ostatnim kroku. W sekcji ról dodaj kolejno nazwy tych ról i zapisz:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- Przyznawanie kontu usługi Dataplex uprawnień dostępu do zasobnika Cloud Storage
Otwórz stronę IAM i administracja, a w sekcji Wyświetl według podmiotów zabezpieczeń kliknij przycisk Przyznaj dostęp i dodaj podmiot zabezpieczeń, wpisując słowo dataplex w polu tekstowym Nowy podmiot zabezpieczeń. Z listy, która uzupełnia się automatycznie, wybierz podmiot konta usługi Dataplex, który wygląda podobnie do tego: (w adresie e-mail konta usługi poniżej użyj numeru projektu, a nie identyfikatora projektu)
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Jeśli z jakiegokolwiek powodu powyższe konto usługi dla Twojego numeru projektu nie jest rozpoznawane, może to oznaczać, że usługa Dataplex nie została jeszcze zainicjowana w projekcie. Otwórz terminal Cloud Shell i spróbuj włączyć interfejs API (jeśli nie zostało to jeszcze zrobione na etapie przed rozpoczęciem), uruchamiając to polecenie: gcloud services enable dataplex.googleapis.com
Jeśli nawet po tym konto usługi Dataplex nie jest rozpoznawane, wymuś utworzenie testowego zadania skanowania Dataplex na stronie Zarządzanie metadanymi i wpisz szczegóły na stronie tworzenia zadania pozyskiwania:
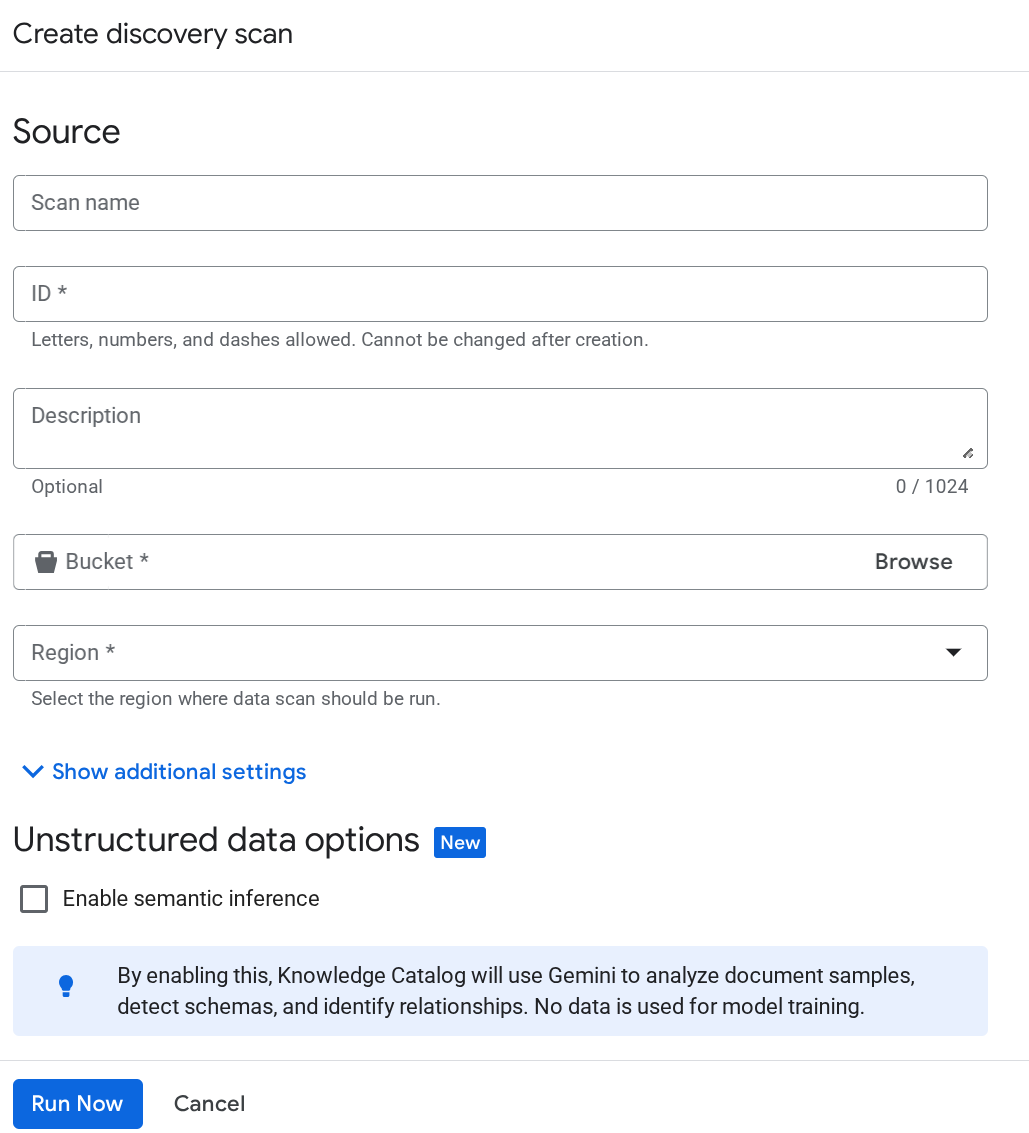
Kliknij Uruchom teraz. Zadanie zakończy się niepowodzeniem, ale dzięki temu identyfikator konta usługi zostanie zainicjowany w usłudze Dataplex.
Wróć na stronę Uprawnienia i administracja i w sekcji Wyświetl według podmiotów zabezpieczeń kliknij przycisk Przyznaj dostęp, a następnie kliknij Dodaj podmiot zabezpieczeń. Wklej konto usługi:
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Następnie przypisz do tego konta usługi te role:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. Konfiguracja Knowledge Catalog
Utwórz Knowledge Catalog, aby ujednolicić dane nieuporządkowane i zautomatyzować wykrywanie nieuporządkowanych plików (takich jak przepisy w formacie PDF i dostawcy w formacie PDF).
Utwórz zadanie DataScan w konsoli:
- Otwórz stronę Kuratorowanie metadanych.
- Kliknij Utwórz i wpisz szczegóły odpowiadające Twojej konfiguracji:
Ważna uwaga: nie zapomnij zaznaczyć opcji Włącz wnioskowanie semantyczne.
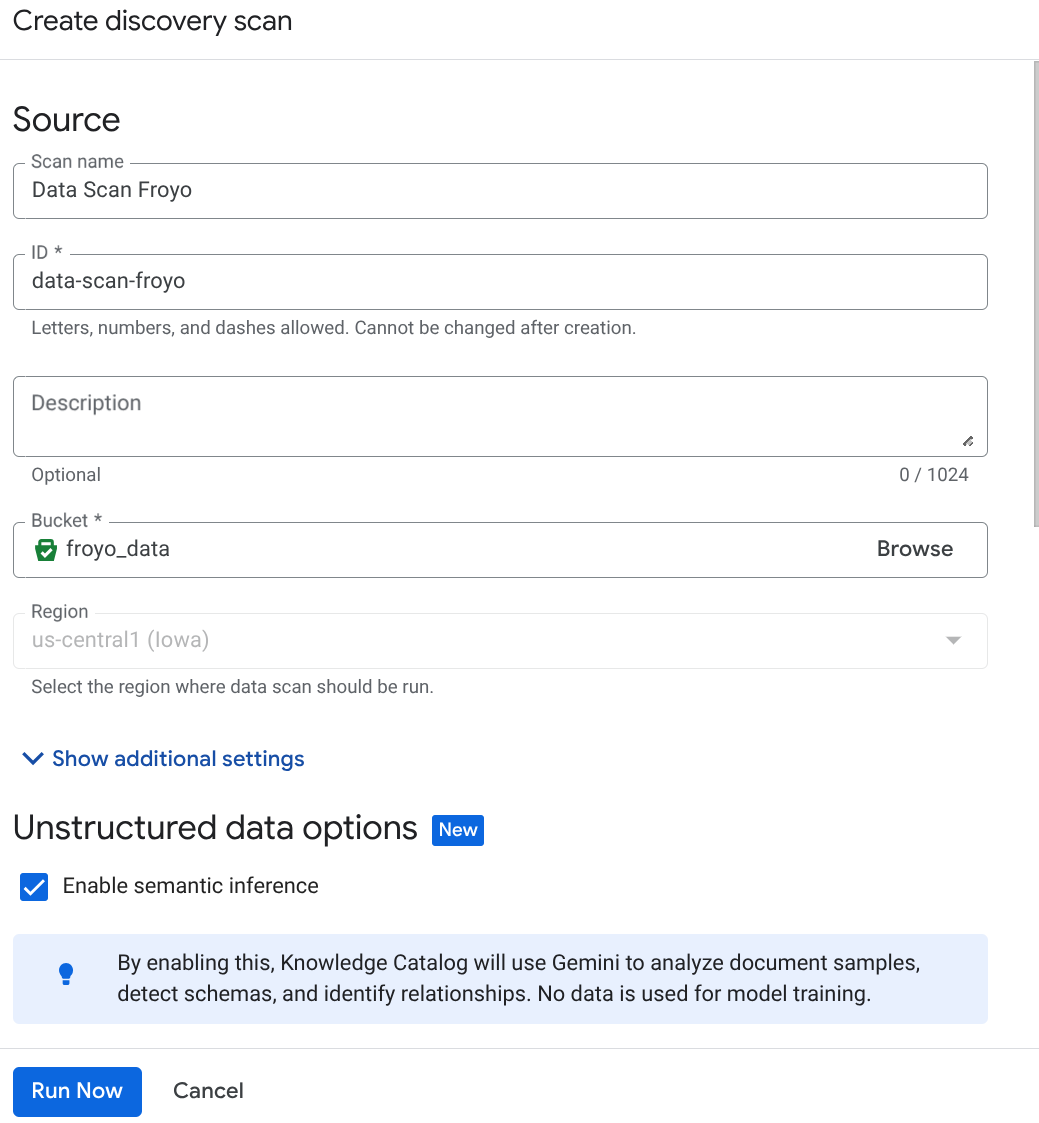
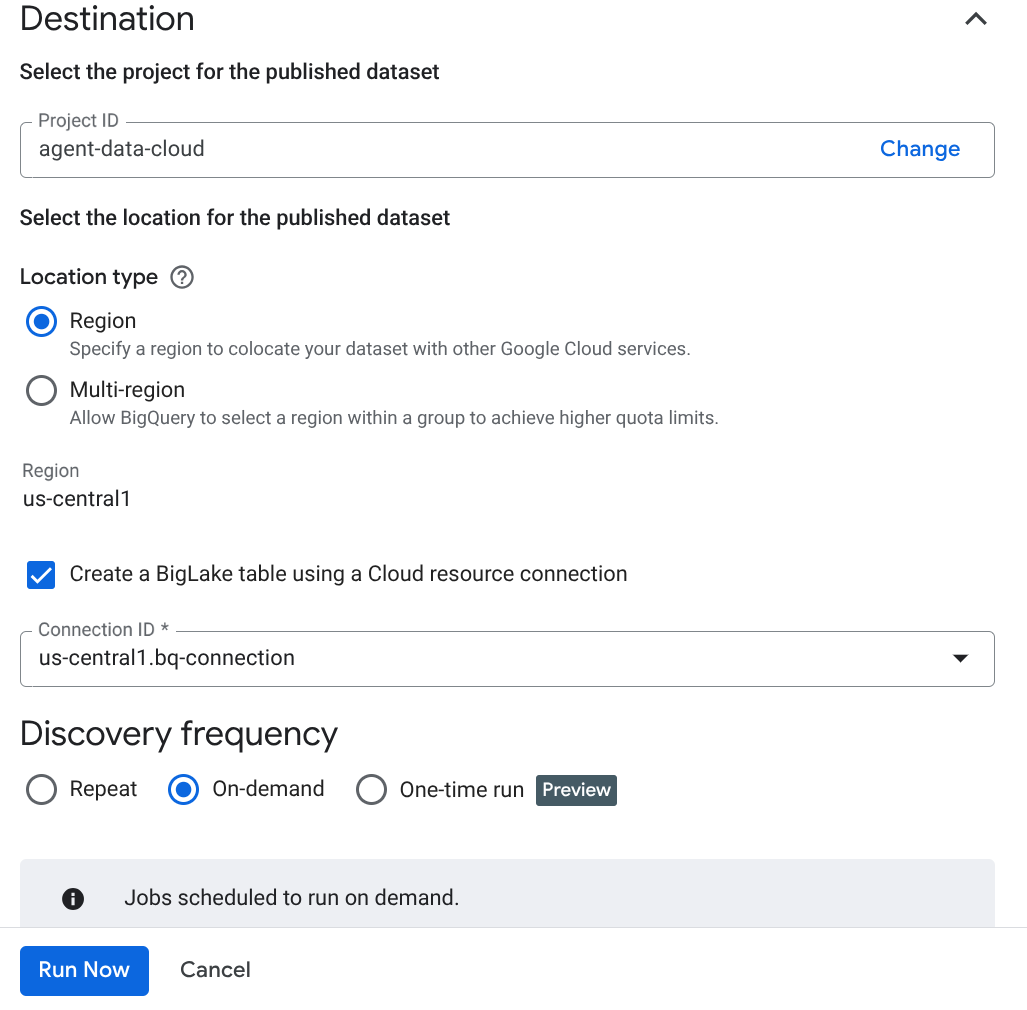
- Kliknij „Uruchom teraz”.
- Skanowanie może trochę potrwać. Po zakończeniu zadania sprawdź, czy opublikowany zbiór danych jest dostępny. Aby sprawdzić stan zadania, otwórz stronę Tworzenie metadanych. Na karcie wykrywania Cloud Storage kliknij nazwę skanów wykrywania z ostatniego uruchomienia. Powinien pojawić się opublikowany zestaw danych, jak pokazano poniżej:
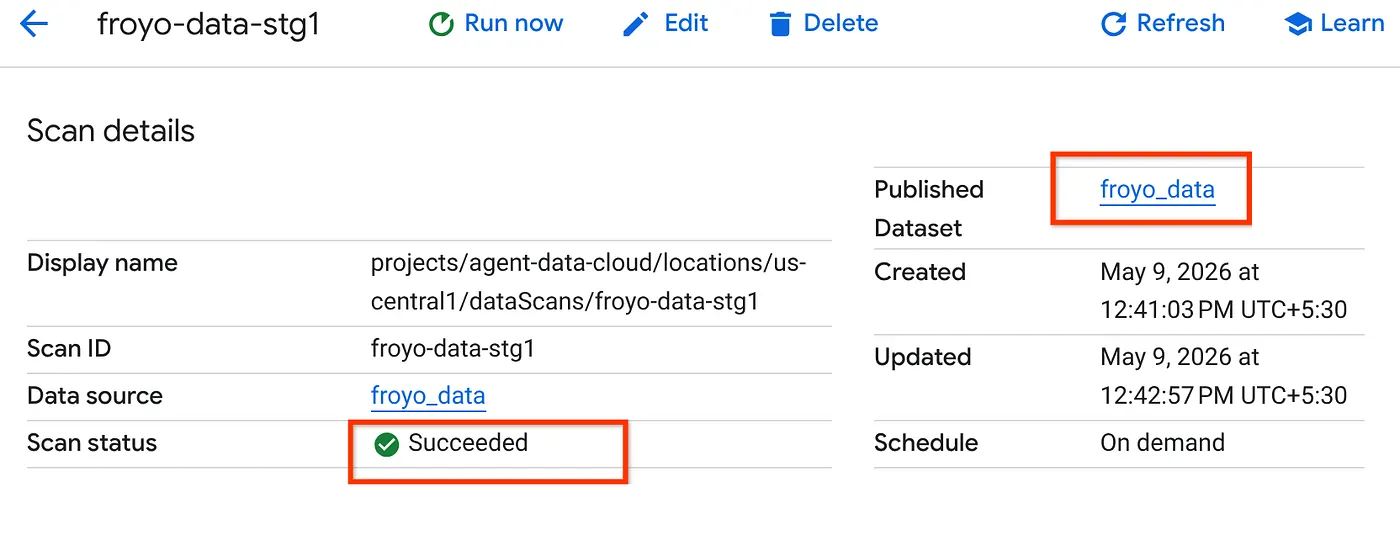
Uwaga: jeśli podczas skanowania wystąpią błędy, poczekaj chwilę i spróbuj ponownie (utworzenie zadania i jego wykonanie zajmuje kilka minut).
- Aby wyświetlić tabelę w BigQuery, kliknij zbiór danych froyo_data i przejdź do niego. Kliknij identyfikator tabeli w BigQuery i uruchom poniższe zapytanie na karcie Edytor zapytań:
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
Wynik to 400 (jeśli nie, możesz wrócić i ponownie uruchomić zadanie Datascan).
7. Wyodrębnianie danych semantycznych
Świetnie! Teraz wyodrębnijmy wnioskowanie dla tych nieustrukturyzowanych obiektów za pomocą Knowledge Catalog.
Użyjemy funkcji Statystyki, aby wygenerować instrukcje SQL do wyodrębniania danych strukturalnych z tabeli nieustrukturyzowanej.
- W konsoli Google Cloud otwórz stronę Wyszukiwanie w Knowledge Catalog.
- Wyszukaj tabelę zbioru danych, dla której chcesz wyświetlić statystyki. Na pasku wyszukiwania wpisz nazwę zbioru danych lub tabeli z poprzedniego kroku: „froyo_data” i naciśnij Enter.
- Na liście wyników kliknij wpis TABLE (nie zbiór danych).
- Powinna się wyświetlić karta STATYSTYKI. Kliknij ten przycisk (jeśli wymaga to włączenia interfejsu API, postępuj zgodnie z instrukcjami i włącz interfejsy API).
Jeśli w tym momencie włączysz interfejsy API, musisz ponownie uruchomić zadanie skanowania.
- Na karcie STATYSTYKI zobaczysz menu przycisku WYEKSTRAHUJ. Kliknij ją i wybierz opcję „Wyodrębnij za pomocą SQL”.
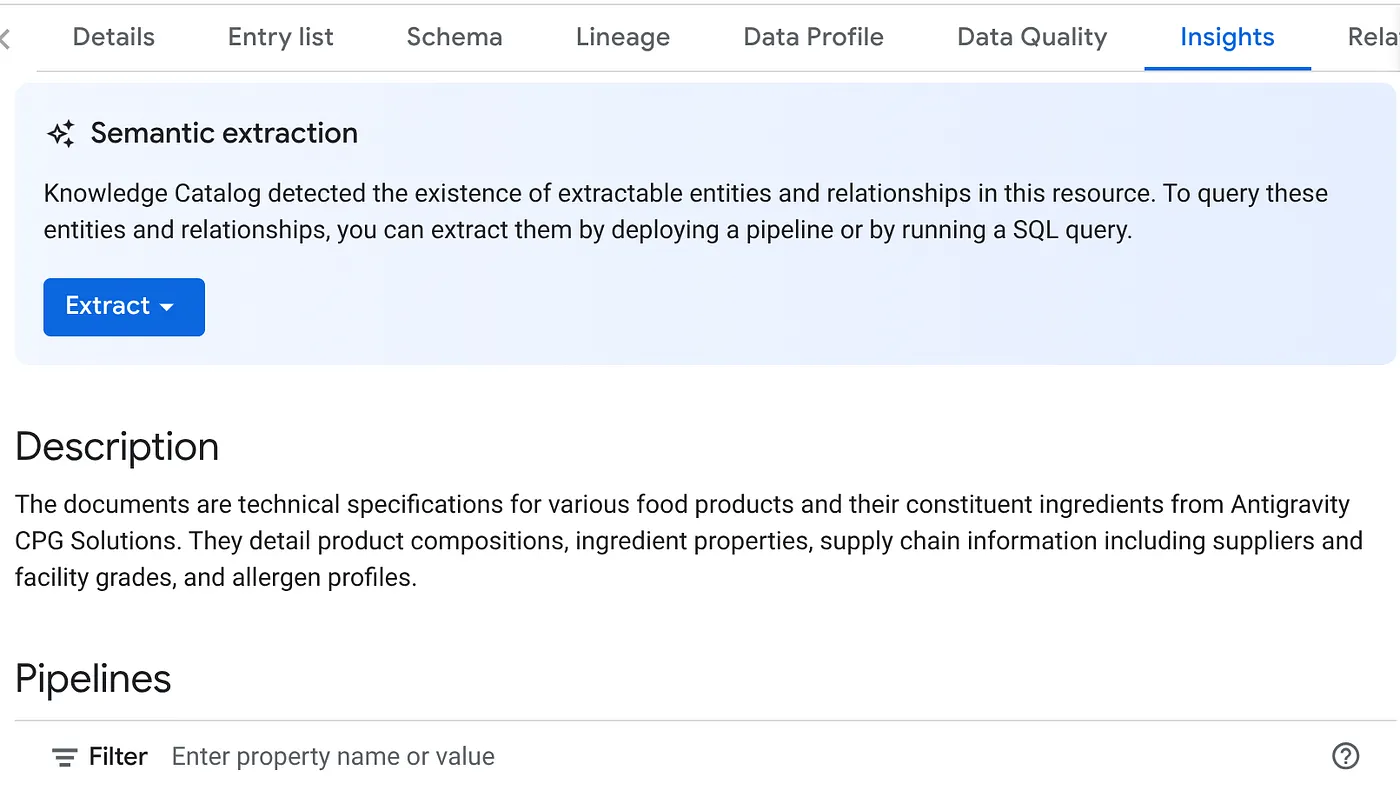
W wyskakującym okienku „Wyodrębnij za pomocą SQL” ustaw zbiór danych DESTINATION jako ten, który pojawił się w wyniku zadania skanowania danych. Zacznij wpisywać nazwę, a powinna się ona pojawić w autouzupełnianiu. Kliknij przycisk „Wyodrębnij”. Możesz też utworzyć w tym momencie nowy zbiór danych i wyodrębnić dane.
Powinien otworzyć się edytor zapytań BigQuery z otwartą kartą wypełnioną wyodrębnionym kodem SQL z wnioskowania ze skanowania danych.
8. Weryfikacja SQL i tworzenie schematu
Jeśli wygenerowane zapytanie wygląda dobrze i jest semantycznie powiązane z danymi bez struktury, uruchom je, klikając przycisk Uruchom w edytorze zapytań. Utworzenie schematu wymaganego do strukturalnego przechowywania nieustrukturyzowanych multimediów zajmie kilka minut.
Po zakończeniu tego procesu możesz sprawdzić schemat, rozwijając zbiór danych w okienku eksploratora BigQuery Studio, jak widać poniżej:
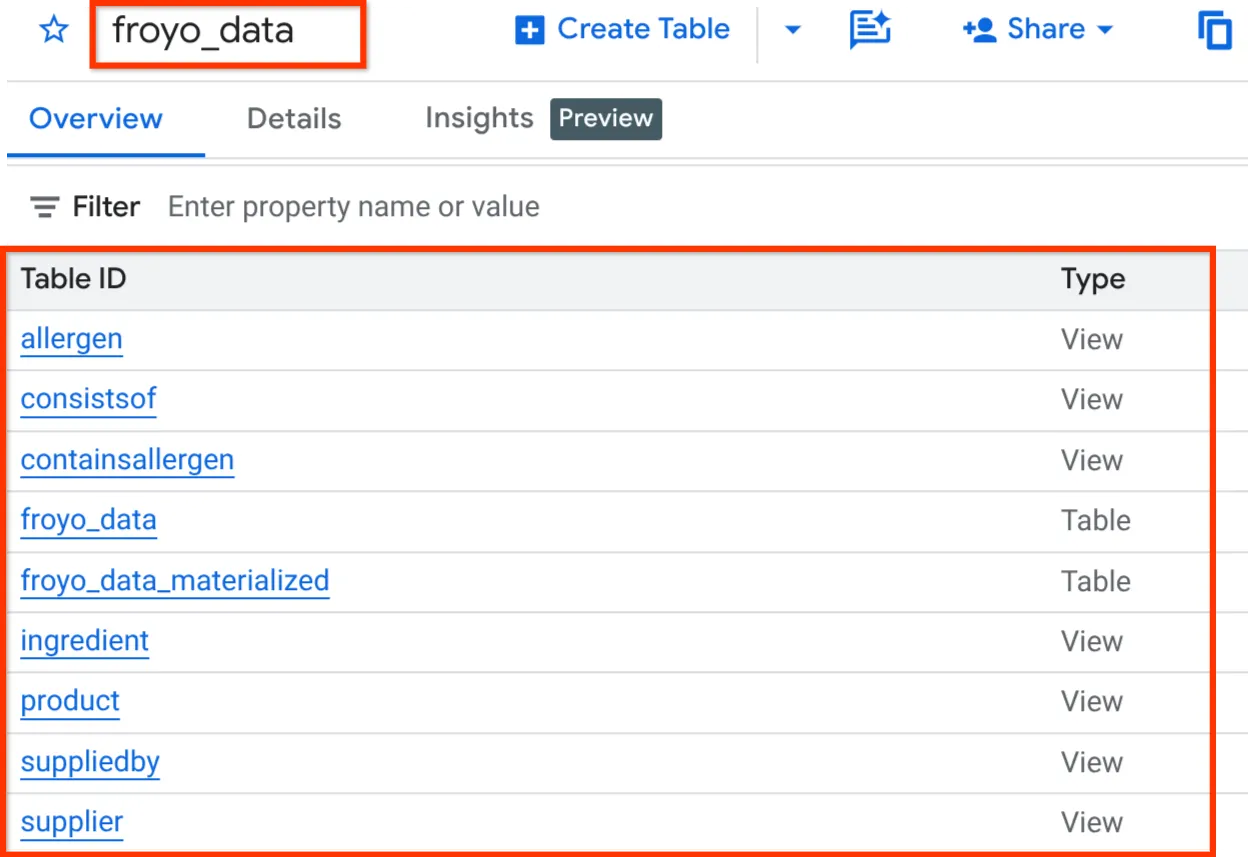
OK. To było tak słodkie, że wszystkie te rzeczy związane z bazą danych zrobiliśmy bardzo szybko. Czas na ostateczny test!
Aby nadal korzystać z danych bez konta rozliczeniowego:
- Pliki CSV (dane BigQuery) możesz pobrać z repozytorium GitHub, do którego link znajdziesz powyżej.
- Najpierw utwórz zbiór danych BigQuery, uruchamiając w terminalu Cloud Shell to polecenie:
bq mk --location us-central1 --dataset froyo_data
- Następnie pobierz 8 plików danych (plików CSV) z repozytorium GitHub do katalogu roboczego, wykonując kolejno te polecenia:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Aby utworzyć te tabele z danymi w nowo utworzonym zbiorze danych, uruchom kolejno te polecenia:
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Po utworzeniu zbioru danych, tabel i danych możesz przetestować i sprawdzić omówione przez nas dane.
9. Najtrudniejszy test!!!
Załóżmy, że chcę, aby mój agent odpowiadał na pytania użytkownika, podając prawdziwe, pełne i dobrze zorganizowane informacje oparte na faktach. Zadaję pytanie, na które agent może odpowiedzieć tylko na podstawie wielu plików multimedialnych i odwołań z mojego źródła.
Oto moje pytanie:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
Teraz w przypadku ogólnego wyszukiwania lub wyszukiwania za pomocą LLM pojawi się komunikat „Brak składników”. Stworzyliśmy jednak pełną inferencję semantyczną, która przekształca wszystkie nasze nieustrukturyzowane media w dane strukturalne. Oto proste zapytanie SQL, które pobierze te informacje:
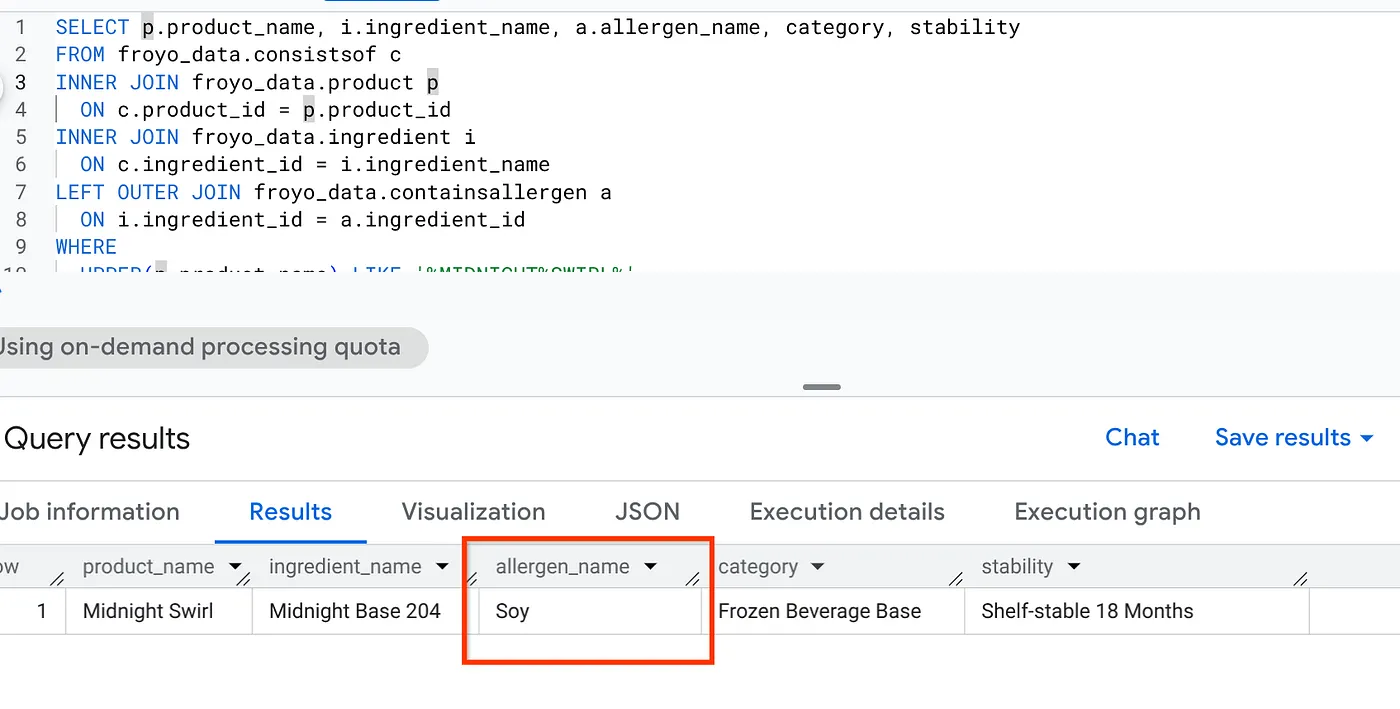
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
Super! Sprawdź wynik:
10. Czyszczenie danych
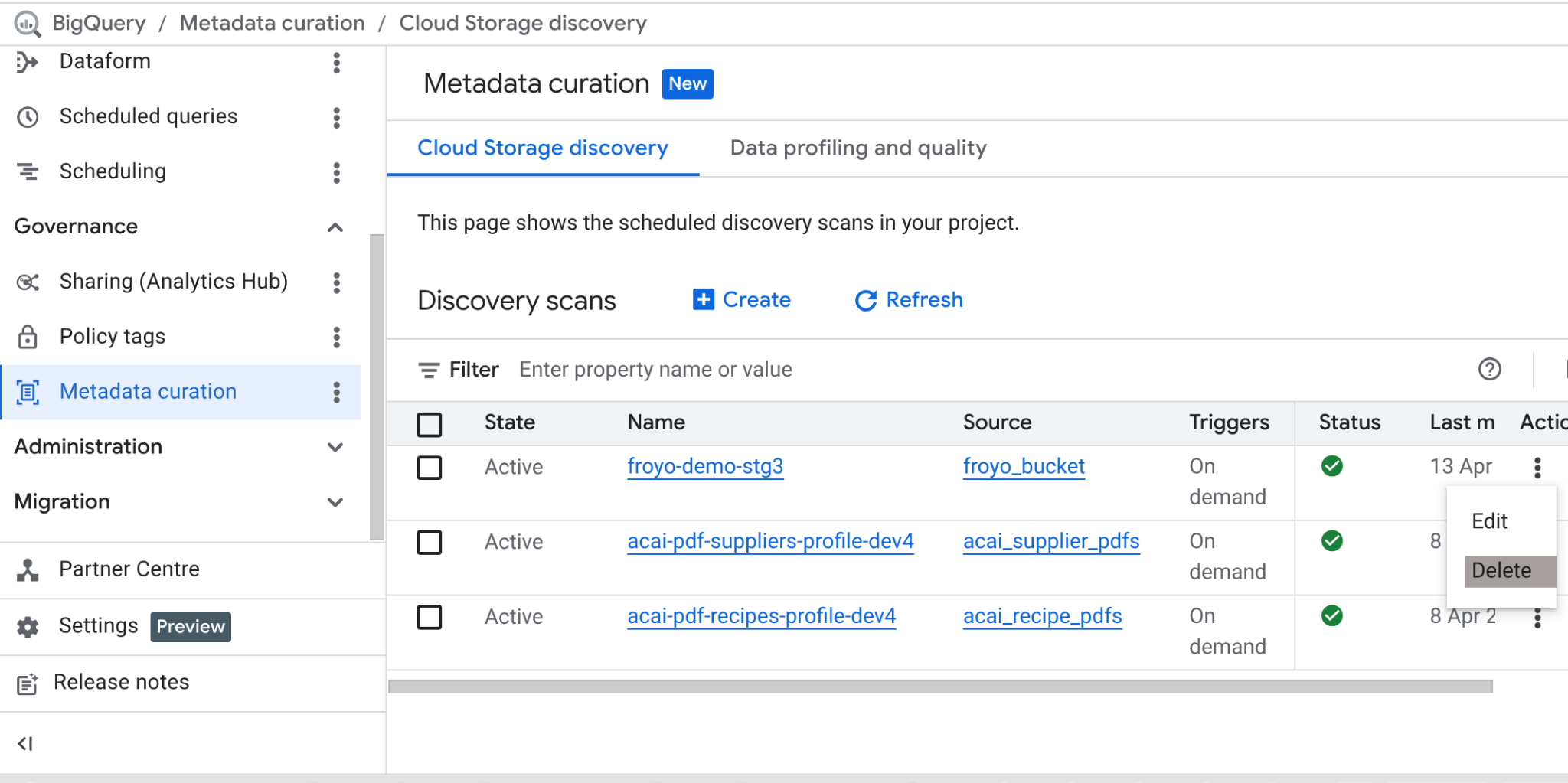
Po ukończeniu tego laboratorium nie zapomnij usunąć zadania skanowania i tabel BigQuery, które zostało utworzone w jego wyniku.
Otwórz stronę https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery. Wybierz zadanie, które chcesz usunąć, klikając obok niego wielokropek w pionie, a następnie kliknij USUŃ.
Powinno to zwolnić miejsce.
11. Gratulacje
Nasze wdrożenie pozwoliło zidentyfikować ukryty alergen. Koniec z ciemnymi danymi! W części 2 połączymy te dane BigQuery w systemie transakcyjnym z AlloyDB, aby ujednolicić potrzeby w zakresie danych w naszej aplikacji opartej na agentach.