
1. Przegląd
W części 1 udało nam się przekształcić chaotyczne, nieuporządkowane pliki PDF w przejrzyste, inteligentne i uporządkowane tabele w BigQuery za pomocą Knowledge Catalog i DataScan. Teraz mamy solidną hurtownię danych.
Jeśli potrzebujesz szybkiego przypomnienia, w części 1 tego laboratorium zajęliśmy się przypadkiem użycia fikcyjnej sieci franczyzowej Frozen Yogurt i przekształciliśmy 400 jej nieustrukturyzowanych plików PDF – zawierających tekst, tabele i obrazy – w czysto ustrukturyzowane tabele BigQuery z automatycznie wywnioskowanymi relacjami między nimi za pomocą BigQuery Knowledge Catalog i Dataplex.
Co utworzysz
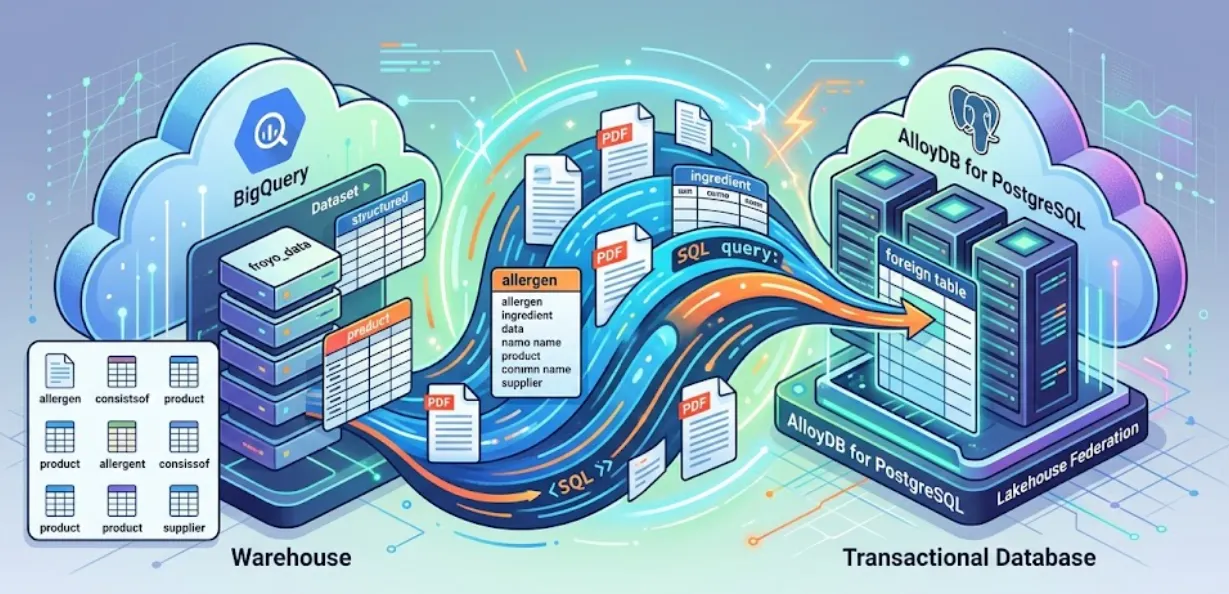
W tej sesji skonfigurujemy AlloyDB for PostgreSQL i zrobimy coś magicznego: sfederujemy dane BigQuery bezpośrednio w AlloyDB. Oznacza to, że nasza aplikacja transakcyjna może w czasie rzeczywistym wysyłać zapytania do danych w magazynie bez kopiowania ani powielania żadnych z nich.
Na tym etapie deweloper musi zadać sobie to pytanie:
„Jeśli dane są już w BigQuery, po co w to wszystko mieszać AlloyDB? Dlaczego aplikacja nie wykonuje po prostu instrukcji SELECT bezpośrednio w BigQuery?”
Oto powody:
Dzięki Lakehouse Federation możesz używać silnika zapytań AlloyDB do obsługi transakcyjnych i analitycznych zbiorów zadań aplikacji w tym samym interfejsie. Możesz też zmaterializować lub zaimportować te dane do AlloyDB, aby uzyskać do nich szybszy dostęp i używać ich w aplikacjach. Dzięki temu możesz korzystać z AlloyDB AI i silnika kolumnowego.
Możesz używać AlloyDB jako transakcyjnej bazy danych, a także przechowywać duże ilości danych w BigQuery lub BigLake. Aplikacje zwykle integrują się niezależnie z każdym z tych systemów, aby uzyskiwać dostęp do danych w różnych usługach Google Cloud. Federacja Lakehouse dla AlloyDB umożliwia korzystanie z obsługi zapytań sfederowanych w AlloyDB zaimplementowanej jako zewnętrzny moduł danych w celu uzyskiwania dostępu do danych BigQuery i AlloyDB za pomocą interfejsu SQL w AlloyDB.
Zamiast tworzyć podatny na uszkodzenia potok ETL do wykonywania zapytań na danych BigQuery z AlloyDB, użyjemy zapytań sfederowanych. AlloyDB będzie działać jako ujednolicony punkt końcowy, który w razie potrzeby będzie płynnie łączyć się z BigQuery.
Zacznijmy tworzyć.
Czego się nauczysz
- Jak skonfigurować klaster, instancję i sieć AlloyDB jednym kliknięciem
- Konfigurowanie rozszerzenia na potrzeby federacji
- Jak skonfigurować federację z BigQuery do AlloyDB
- Wypróbuj
Wymagania
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie włączone są płatności.
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli chcesz się uwierzytelnić
gcloud auth login
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API: aby włączyć wszystkie wymagane interfejsy API, uruchom to polecenie:
gcloud services enable alloydb.googleapis.com
Pułapki i rozwiązywanie problemów
Syndrom „projektu widma” | Uruchomiono polecenie |
Bariera rozliczeniowa | Projekt został włączony, ale zapomniano o koncie rozliczeniowym. AlloyDB to mechanizm o wysokiej wydajności, który nie uruchomi się, jeśli „zbiornik paliwa” (płatności) jest pusty. |
Opóźnienie propagacji interfejsu API | Kliknięto „Włącz interfejsy API”, ale w wierszu poleceń nadal widnieje znak |
Quota Quags | Jeśli korzystasz z nowego konta próbnego, możesz osiągnąć regionalny limit instancji AlloyDB. Jeśli |
3. Szybkie podsumowanie danych z części 1
W tej sekcji musisz się upewnić, że dane strukturalne wyodrębnione z nieustrukturyzowanych plików PDF są dostępne w BigQuery. Jeśli nie udało Ci się obejrzeć części 1 lub nie masz konta rozliczeniowego, możesz wykonać te czynności:
Otwórz konsolę Google Cloud na osobistym koncie Gmail i kliknij przycisk Aktywuj Cloud Shell w prawym górnym rogu konsoli:
Następnie wykonaj czynności opisane w sekcji poniżej dotyczącej braku konta płatniczego:
Aby nadal korzystać z danych bez konta rozliczeniowego:
- Pliki csv (dane BigQuery) możesz pobrać z repozytorium w GitHubie, klikając link powyżej.
- Najpierw utwórz zbiór danych BigQuery, uruchamiając w terminalu Cloud Shell to polecenie:
bq mk --location us-central1 --dataset froyo_data
- Następnie pobierz 8 plików danych (plików CSV) z repozytorium GitHub do katalogu roboczego, wykonując kolejno te polecenia:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Aby utworzyć te tabele z danymi w nowo utworzonym zbiorze danych, uruchom kolejno te polecenia:
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Teraz, gdy mamy już dane w BigQuery, przejdźmy do następnych kroków.
4. Konfigurowanie klastra, instancji i sieci AlloyDB
Dostępna jest internetowa aplikacja szybkiego startu, która pomoże Ci skonfigurować klaster AlloyDB, instancję i inne zależności. Aby skonfigurować go jednym kliknięciem, wykonaj czynności 2–4 w tym module:
https://codelabs.developers.google.com/quick-alloydb-setup
Po utworzeniu klastra otwórz stronę Przegląd klastra i skopiuj z niej szczegóły konta usługi.
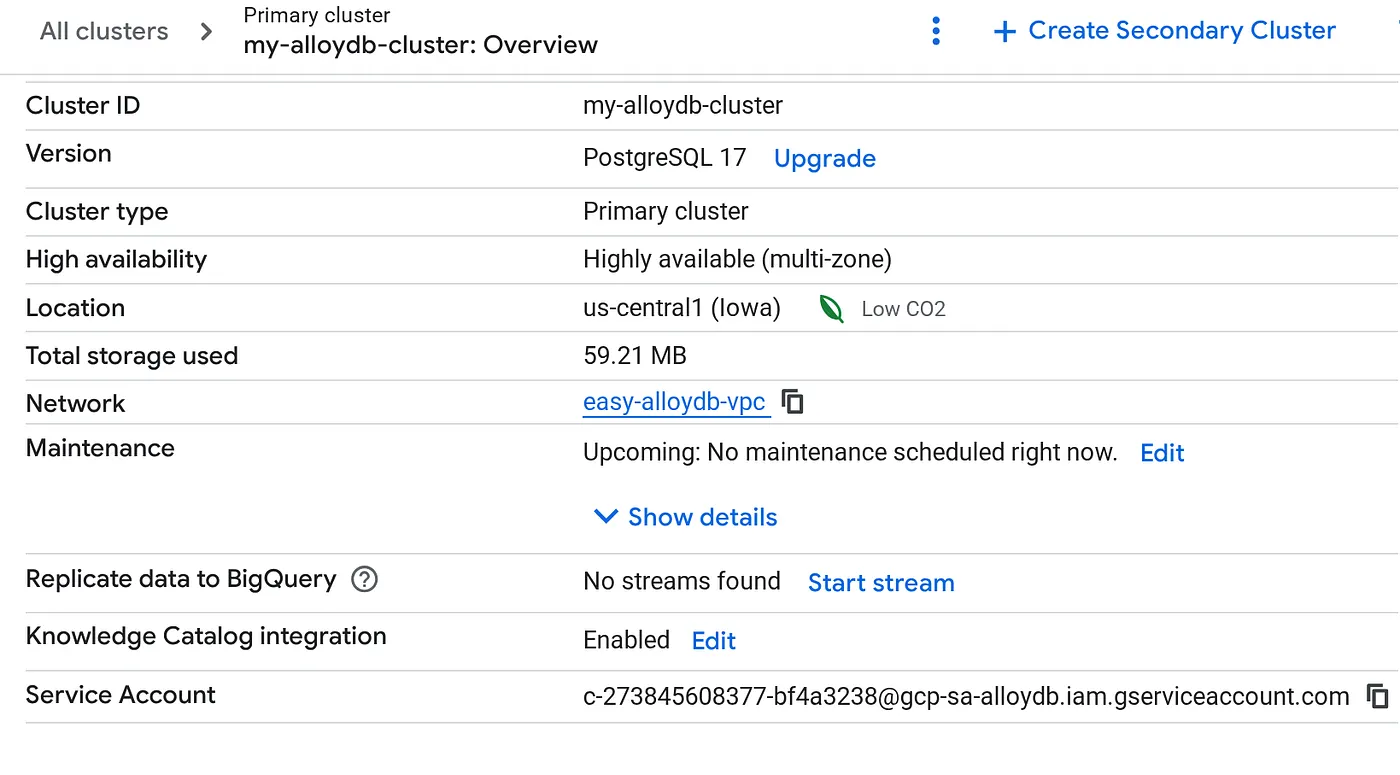
5. Konfigurowanie uprawnień
Przyznaj temu kontu usługi uprawnienia BigQuery
- Otwórz kolejno Administracja > Uprawnienia.
- Kliknij Przyznaj dostęp.
- Wklej adres konta usługi AlloyDB w polu Nowe podmioty zabezpieczeń.
- Przypisz te role:
- Wyświetlający dane BigQuery (roles/bigquery.dataViewer): umożliwia odczytywanie danych.
- Użytkownik BigQuery (roles/bigquery.user): umożliwia uruchamianie zapytań.
- (Opcjonalnie, ale zalecane) Użytkownik sesji odczytu BigQuery (roles/bigquery.readSessionUser): optymalizuje odczytywanie dużych zbiorów danych za pomocą interfejsu Storage Read API.
6. Łączenie z AlloyDB i włączanie rozszerzenia BigQuery
Teraz połączymy się z nową instancją AlloyDB, aby skonfigurować rozszerzenie federacji. W tym celu użyjemy AlloyDB Studio.
- Na stronie Przegląd klastra (konsola AlloyDB) kliknij „Edytuj instancję podstawową” na instancji podstawowej i przewiń w dół do „Zaawansowane opcje konfiguracji”.
- Otwórz sekcję „Flagi” i włącz 2 flagi, ustawiając je na „Włączone”, jak pokazano poniżej:
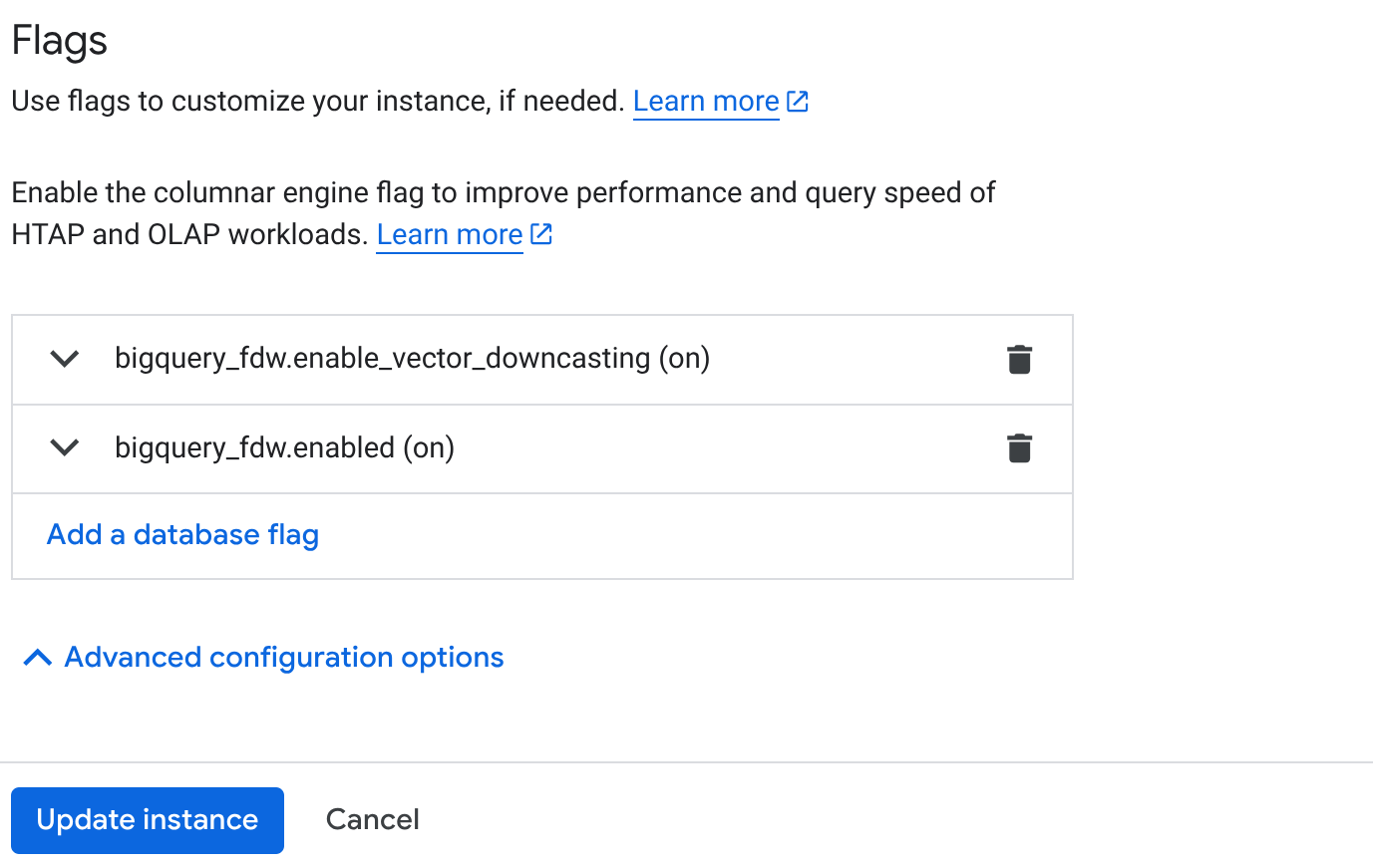 3. Kliknij przycisk Zaktualizuj instancję. Aktualizacja potrwa kilka minut. 4. Na stronie Przegląd klastra (konsola AlloyDB) kliknij AlloyDB Studio.
3. Kliknij przycisk Zaktualizuj instancję. Aktualizacja potrwa kilka minut. 4. Na stronie Przegląd klastra (konsola AlloyDB) kliknij AlloyDB Studio.
- Połącz się z bazą danych, używając nazwy użytkownika i hasła skonfigurowanych podczas szybkiej konfiguracji AlloyDB.
- Po nawiązaniu połączenia na karcie Edytor zapytań po prawej stronie wpisz te instrukcje i URUCHOM je kolejno:
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- Po wykonaniu tych czynności przejdź do panelu eksploratora po lewej stronie i przewiń w dół do tabel BigQuery:
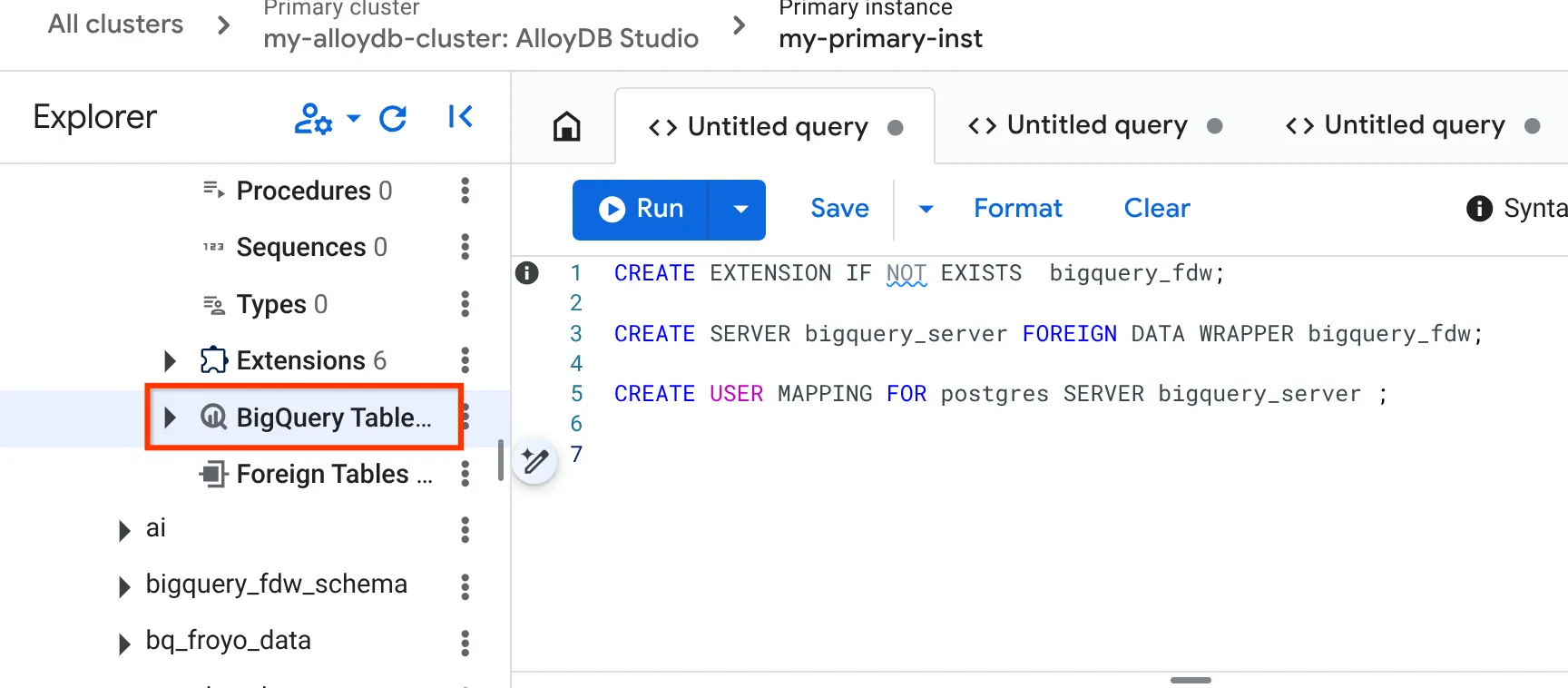
- Kliknij 3 kropki i wybierz „Połącz tabelę BigQuery”.
- W otwartym okienku Connect BigQuery Table (Połącz tabelę BigQuery) wybierz project_id i nazwę zbioru danych BigQuery (utworzonego w części 1), z którego chcesz wysyłać zapytania o dane w bazie danych AlloyDB.
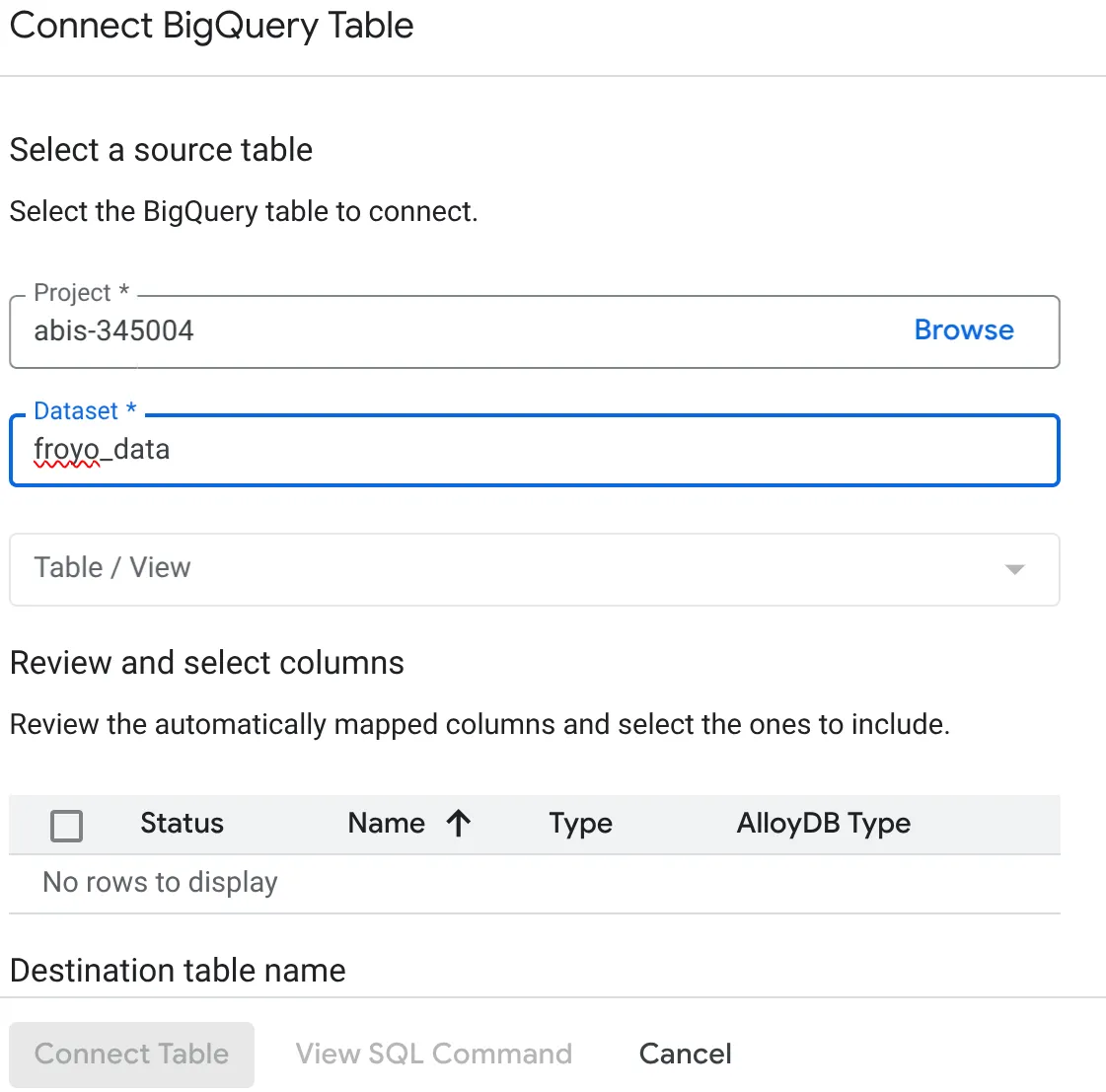
- Aby połączyć wszystkie dane z AlloyDB, wybierz każdą tabelę po kolei. Dzięki temu możemy sprawdzić typy kolumn i upewnić się, że są obsługiwane w AlloyDB.
Jeśli chcesz zrobić to samo za pomocą SQL zamiast metody wskaż i kliknij:
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
Magia!!!
Właśnie utworzyliśmy „tabele obce” w AlloyDB. Wyglądają i działają jak zwykłe tabele PostgreSQL, ale nie przechowują żadnych danych. Gdy wyślesz zapytanie, AlloyDB natychmiast przekaże je do BigQuery, pobierze wyniki i zwróci je do Ciebie.
7. Testowanie federacji w AlloyDB
Sprawdźmy, czy możemy wykonywać zapytania dotyczące naszego obszernego zbioru danych analitycznych BigQuery bezpośrednio z transakcyjnej bazy danych PostgreSQL.
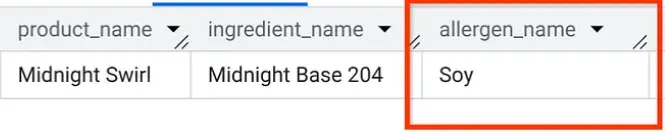
W AlloyDB Studio uruchom zapytanie, aby dowiedzieć się, jakie alergeny zawiera „Midnight Swirl” (to samo pytanie, które zadaliśmy w części 1, ale tym razem zadane z poziomu AlloyDB):
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
Boom. Powinny pojawić się dokładnie te same wyniki co w BigQuery.
8. Czyszczenie danych
Po ukończeniu tego laboratorium nie zapomnij usunąć klastra i instancji AlloyDB.
Powinien on zwalniać miejsce w klastrze wraz z jego instancjami.
9. Gratulujemy utworzenia ujednoliconej warstwy danych
Zastanów się, co właśnie osiągnęliśmy:
- Nasza aplikacja transakcyjna (działająca na AlloyDB) może obsługiwać szybkie, równoczesne sesje użytkowników.
- Gdy potrzebuje obszernych danych analitycznych lub kontekstu historycznego (np. szczegółów dostawcy lub złożonych map składników), wysyła zapytanie do schematu danych froyo_dataschema w BigQuery.
- Zero ETL. Żadne potoki danych nie są uszkodzone. Brak niesynchronizowanych baz danych. Przechowujemy dane tylko raz (w BQ) i przetwarzamy je tam, gdzie są potrzebne.
Teraz, gdy mamy solidne i wzajemnie połączone podstawy danych – zarówno analitycznych, jak i transakcyjnych – możemy przejść do przyjemniejszej części.
W części 3 utworzymy aplikację z wieloma agentami, która będzie działać w tej architekturze i zarządzać działalnością firmy Froyo.