
1. Visão geral
Todos nós conhecemos a dificuldade dos "dados ocultos". São os PDFs, imagens e arquivos de texto armazenados em buckets do Cloud Storage, completamente invisíveis para suas consultas SQL e painéis de BI. Tradicionalmente, para acessar esses dados, eram necessários pipelines complexos de OCR, entrada manual de dados ou scripts personalizados frágeis.
Nada disso.
Neste laboratório, vou mostrar como converter 400 arquivos PDF não estruturados, que abrangem texto, tabelas e imagens, em tabelas do BigQuery bem estruturadas com relações inferidas automaticamente entre elas. Vamos fazer isso em minutos usando o BigQuery Knowledge Catalog e o Dataplex.
O que você vai criar
Para entender melhor, vamos analisar uma empresa fictícia: uma franquia de frozen yogurt em rápido crescimento.
Imagine que você gerencia os dados dessa empresa de Froyo. Você tem centenas de receitas e planilhas de especificações de fornecedores, tudo salvo como PDF. Os líderes empresariais querem lançar um agente de IA para ajudar os gerentes de loja e os clientes a consultar detalhes dos produtos.
Aqui está o cenário de pesadelo: um cliente pergunta: "Estou muito interessado no seu froyo Midnight Swirl. Tem algum alérgeno?"
Para responder a isso, seu sistema normalmente precisaria:
- Encontre o PDF da receita "Midnight Swirl".
- Leia os ingredientes (por exemplo, "cacau em pó", "base láctea", "emulsificante X").
- Pesquise em dezenas de PDFs de fornecedores para encontrar as fichas técnicas desses ingredientes específicos.
- Verifique as planilhas do fornecedor para ver se há alérgenos ocultos relacionados a esses ingredientes.
Tentar criar um agente de IA que faça isso lendo 400 PDFs brutos durante a execução é lento, caro e propenso a alucinações. Em vez disso, vamos usar a inferência semântica para extrair tudo isso em um banco de dados relacional primeiro, tornando nosso futuro agente de IA extremamente rápido e 100% baseado em dados SQL factuais.
Vamos começar a criar!
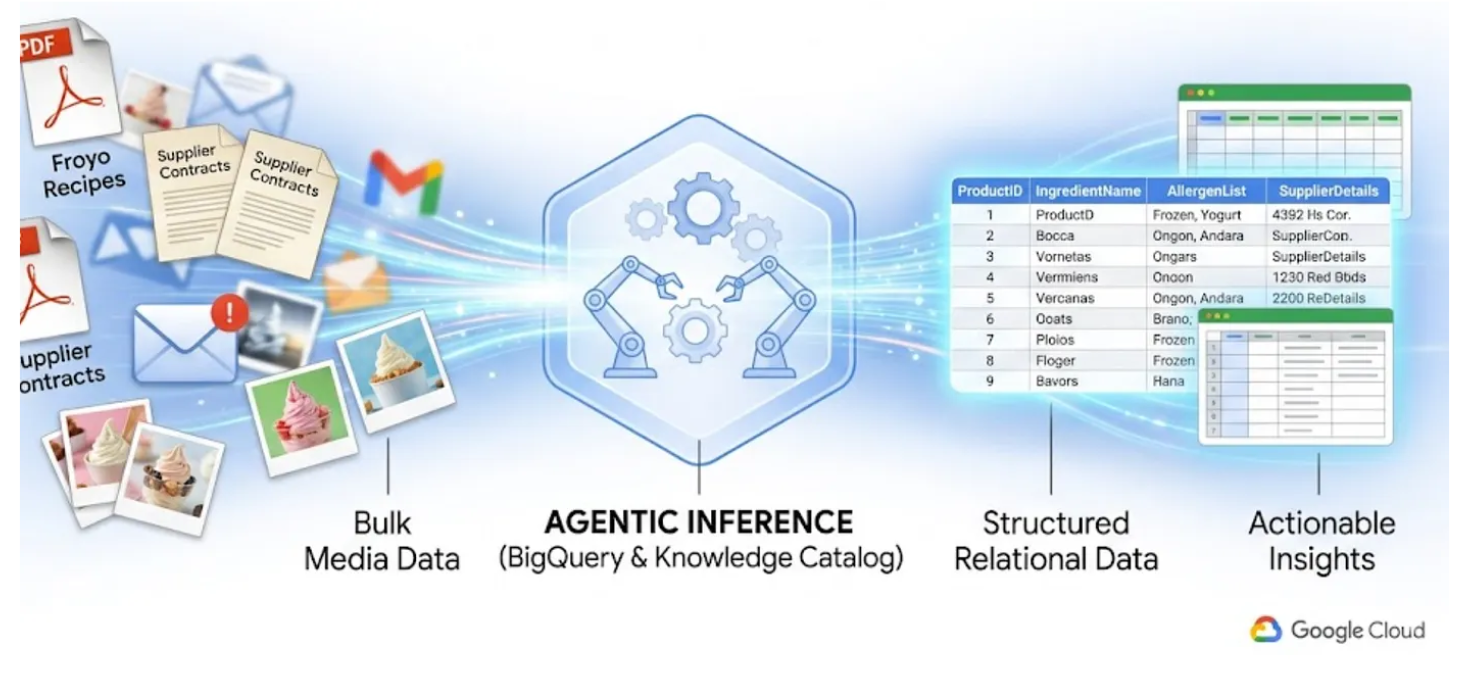
O que você vai aprender
- Como configurar um bucket do Cloud Storage para os arquivos de origem (PDFs)
- Como configurar e executar um job de verificação de dados e inferência semântica no catálogo do Knowledge para extrair dados de PDFs de origem e inferir semanticamente as conexões e o contexto, armazenando tudo no BigQuery
- Como usar os agentes do BigQuery para conversar com o conjunto de dados recém-criado
Requisitos
2. Antes de começar
Criar um projeto
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Confira se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud. Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud.

- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com seu ID do projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se você quiser autenticar
gcloud auth login
- Se o projeto não estiver definido, use este comando:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Ative as APIs necessárias: execute este comando para ativar todas as APIs necessárias:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
Problemas e solução de problemas
A síndrome do projeto fantasma | Você executou |
A barricada de faturamento | Você ativou o projeto, mas esqueceu a conta de faturamento. O AlloyDB é um mecanismo de alto desempenho. Ele não vai iniciar se o "tanque de combustível" (faturamento) estiver vazio. |
Atraso na propagação da API | Você clicou em "Ativar APIs", mas a linha de comando ainda mostra |
Quags de cota | Se você estiver usando uma conta de teste nova, talvez atinja uma cota regional para instâncias do AlloyDB. Se |
Agente de serviço"oculto" | Às vezes, o agente de serviço do AlloyDB não recebe automaticamente o papel |
3. Configuração do bucket do Google Cloud Storage
Nesta seção, você vai criar uma estrutura organizacional no BigQuery para armazenar dados de receitas e fornecedores do Froyo, especificamente para detalhes do produto Froyo. Ela também estabelece uma conexão a recursos do Cloud, que atua como uma "ponte" segura, permitindo que o BigQuery leia arquivos de fontes externas, como o Cloud Storage.
Antes de começar:
Este repositório contém receitas e arquivos PDF de fornecedores que vamos usar neste projeto. Faça o download desses arquivos. Para fazer o download dos arquivos, siga estas etapas:
No Cloud Shell, execute este comando:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
Acesse a pasta recém-criada:
cd next-26-keynotes
Extraia a pasta data-cloud-demo
git sparse-checkout set genkey/data-cloud-demo
Depois que a finalização da compra for concluída, navegue até a pasta data-cloud-demo e extraia os arquivos ZIP para acessar os recursos do codelab.
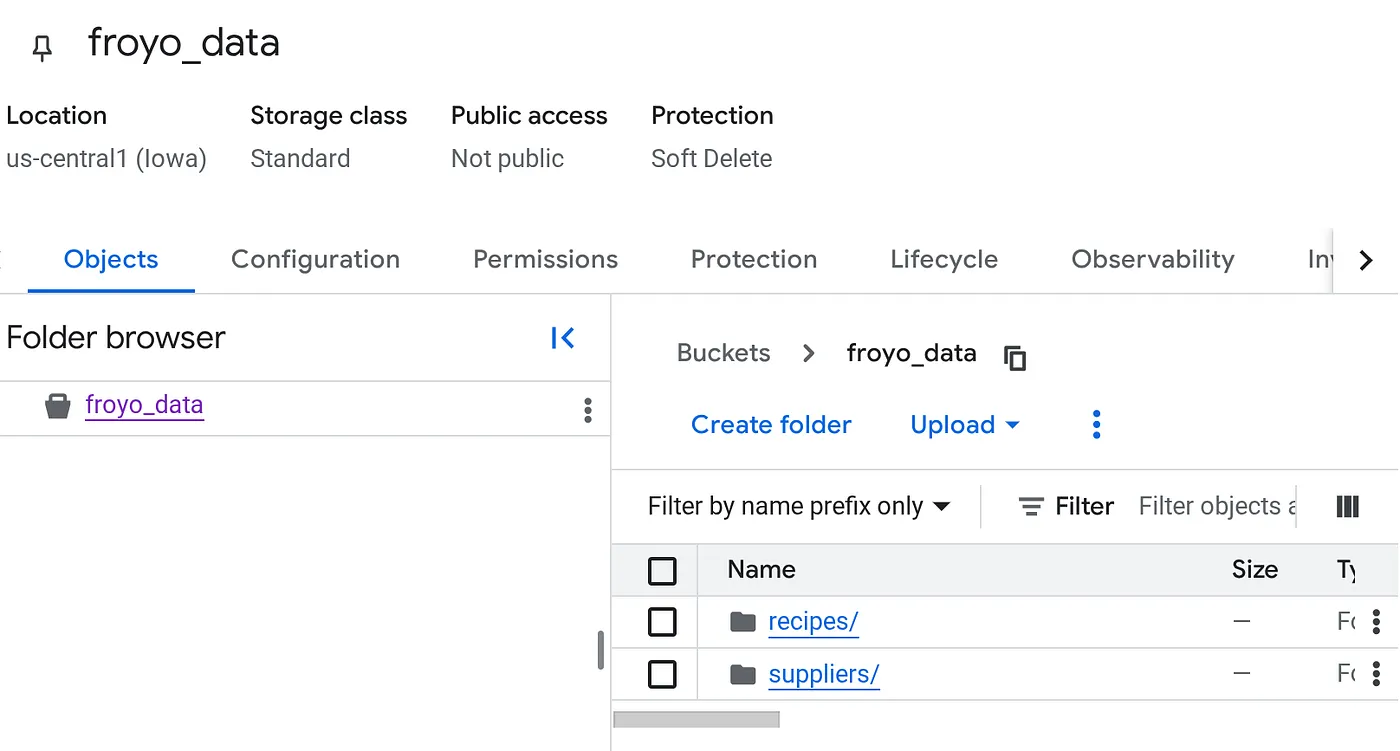
Criar um bucket e fazer upload dos arquivos PDF do Froyo (receitas e fornecedores)
- No console do Google Cloud, acesse a página Buckets do Cloud Storage.
- Clique em "Criar".
- Na página Criar um bucket, insira as informações do bucket. Após cada uma das etapas a seguir, clique em "Continuar" para prosseguir para a próxima etapa:
- Na seção Começar, insira o nome do bucket. Por exemplo: froyo_data
- Na seção Escolha onde armazenar seus dados, selecione "Região" e insira sua região. us-central1
- Na seção Escolha como controlar o acesso a objetos, desmarque a caixa de seleção "Aplicar a prevenção do acesso público neste bucket".
- Clique em "Criar".
- Na lista de buckets, clique no bucket que você criou.
- Na guia Objetos do bucket, clique em "Fazer upload" e depois em "Fazer upload de pastas".
- Selecione a pasta recipes que você extraiu na seção "Antes de começar" deste codelab.
- Clique em Enviar.
- Repita o processo de upload para a pasta suppliers.
Depois de fazer o upload, a estrutura do bucket vai ficar assim (qualquer que seja o nome do bucket):
4. Configuração da conexão do BigQuery
Crie uma conexão a recursos do Cloud. Isso gera uma conta de serviço exclusiva que funciona como o "documento de identidade" do BigQuery para acessar arquivos externos.
- Acesse a página do BigQuery.
- No painel à esquerda, clique em "Explorer". Se o painel esquerdo não aparecer, clique em "Expandir painel esquerdo" para abrir.
- No painel "Explorer", expanda o nome do projeto e clique em "Conexões".
- Na página "Conexões", clique em "Criar conexão".
- Em "Tipo de conexão", escolha "Modelos remotos da Vertex AI, funções remotas, BigLake e Spanner (recurso do Cloud)".
- No campo "ID da conexão", insira o nome do ID da conexão:
- bq-connection. Anote esse ID, porque você vai precisar dele ao configurar a verificação de dados mais adiante neste codelab.
- Defina o tipo de local como "Região" e selecione uma opção. Por exemplo, us-central1. A conexão precisa estar na mesma região que seus outros recursos, como conjuntos de dados.
- Clique em "Criar conexão".
- Clique em "Acessar a conexão".
- No painel "Informações da conexão", copie o ID da conta de serviço para usar em uma etapa posterior. A conta de serviço é semelhante a bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
5. Configuração de permissões
- Conceda as permissões necessárias à conexão do BigQuery para acessar objetos do Cloud Storage e o Knowledge Catalog
Acesse a página "IAM e administrador" e, na seção "Visualizar por principais", clique no botão "Conceder acesso". Adicione um principal colando a conta de serviço que você copiou na última etapa. Na seção de papéis, adicione os nomes dos seguintes papéis um por um e salve:
- roles/storage.objectUser
- roles/storage.objectViewer
- papéis/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- Conceder permissões à conta de serviço do Dataplex para acessar o bucket do Cloud Storage
Acesse a página IAM e administrador e, na seção Visualizar por principais, clique no botão Conceder acesso e adicione um principal digitando a palavra dataplex na barra de texto "Novo principal". Na lista de preenchimento automático, selecione o principal da conta de serviço do Dataplex que se parece com este: (use o número do projeto e não o ID do projeto no ID do e-mail da conta de serviço abaixo)
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Se, por algum motivo, a conta de serviço acima para o número do projeto não for reconhecida, talvez o projeto ainda não tenha inicializado o serviço do Dataplex. Acesse o terminal do Cloud Shell e tente ativar a API (se ainda não tiver feito isso na etapa Antes de começar) executando o seguinte comando: gcloud services enable dataplex.googleapis.com
Mesmo depois disso, se a conta de serviço do Dataplex não for reconhecida, force a criação de um job de verificação de teste do Dataplex na página de curadoria de metadados e insira os detalhes na página de criação de jobs de descoberta:
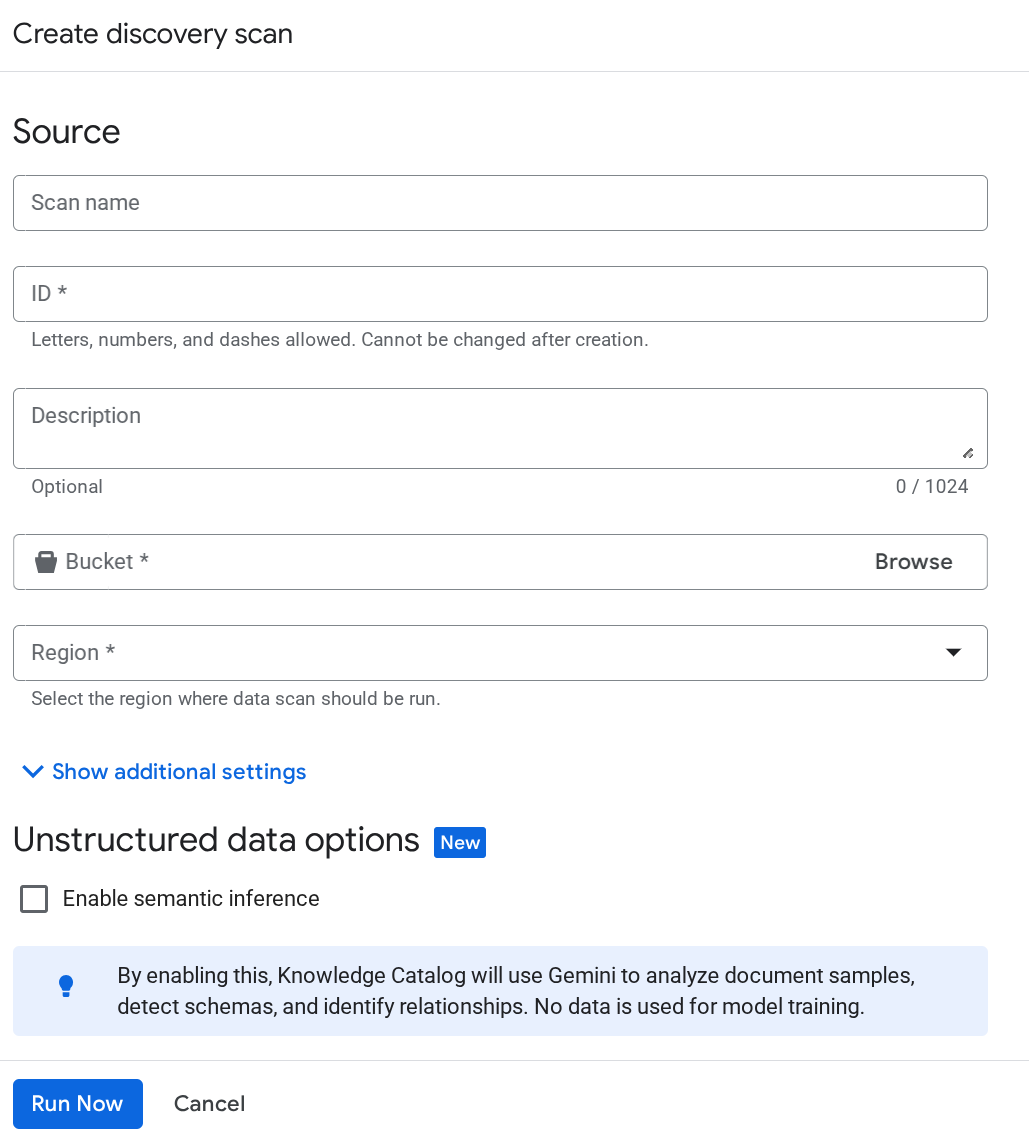
Clique em Executar agora. O job vai falhar, mas isso garante que o ID da conta de serviço seja inicializado para seu serviço do Dataplex agora.
Volte à página IAM e administrador e, na seção Visualizar por principais, clique no botão Conceder acesso e em "Adicionar um principal". Cole a conta de serviço:
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Em seguida, conceda os seguintes papéis a essa conta de serviço:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. Configuração do Knowledge Catalog
Crie um Knowledge Catalog para unificar os dados não estruturados e automatizar a descoberta de arquivos não estruturados, como receitas e fornecedores em PDF.
Crie o job DataScan no console:
- Acesse a página Criação de metadados.
- Clique em "Criar" e insira os detalhes correspondentes à sua configuração:
Observação importante: não se esqueça de marcar a opção "Ativar inferência semântica".
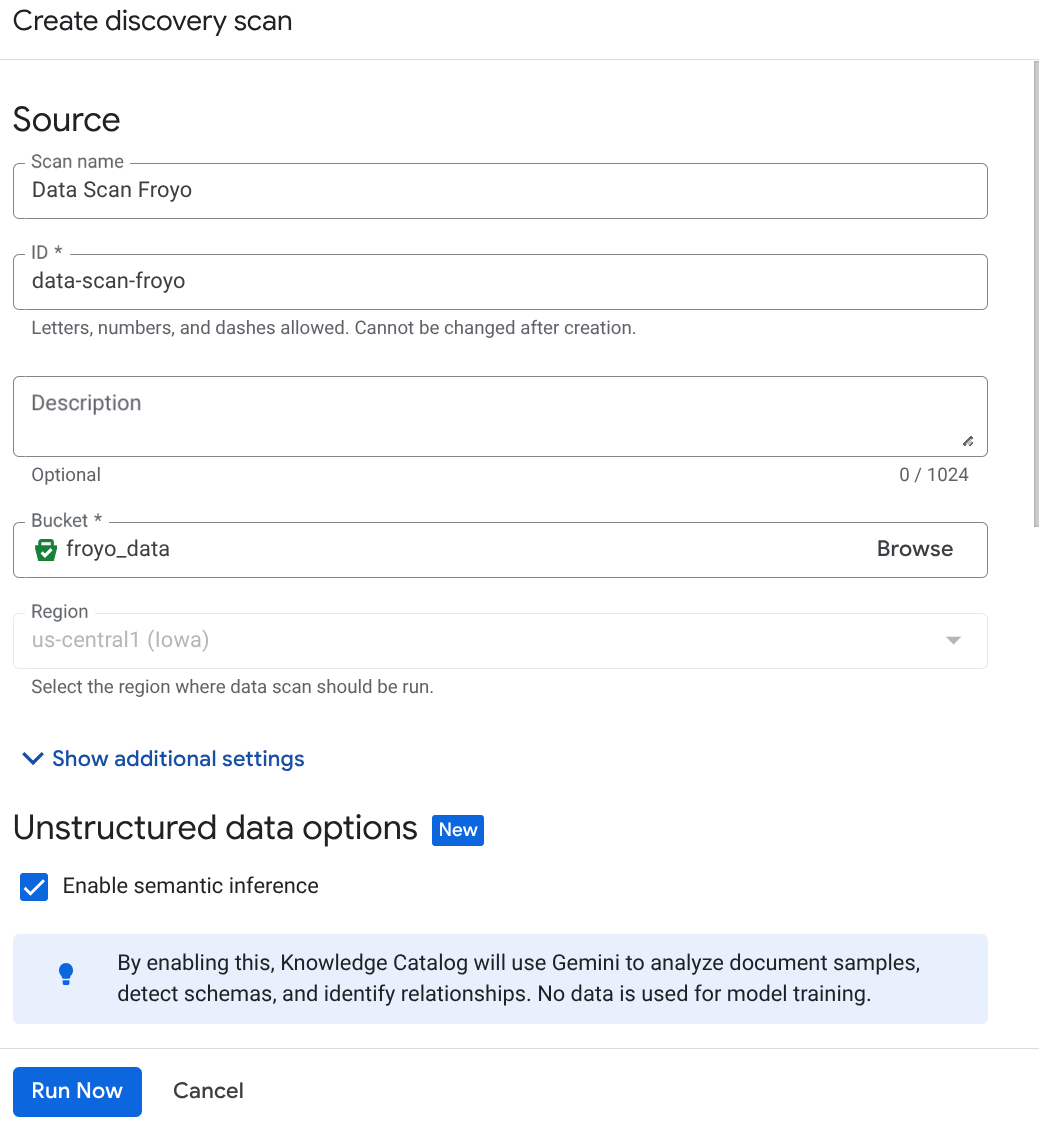
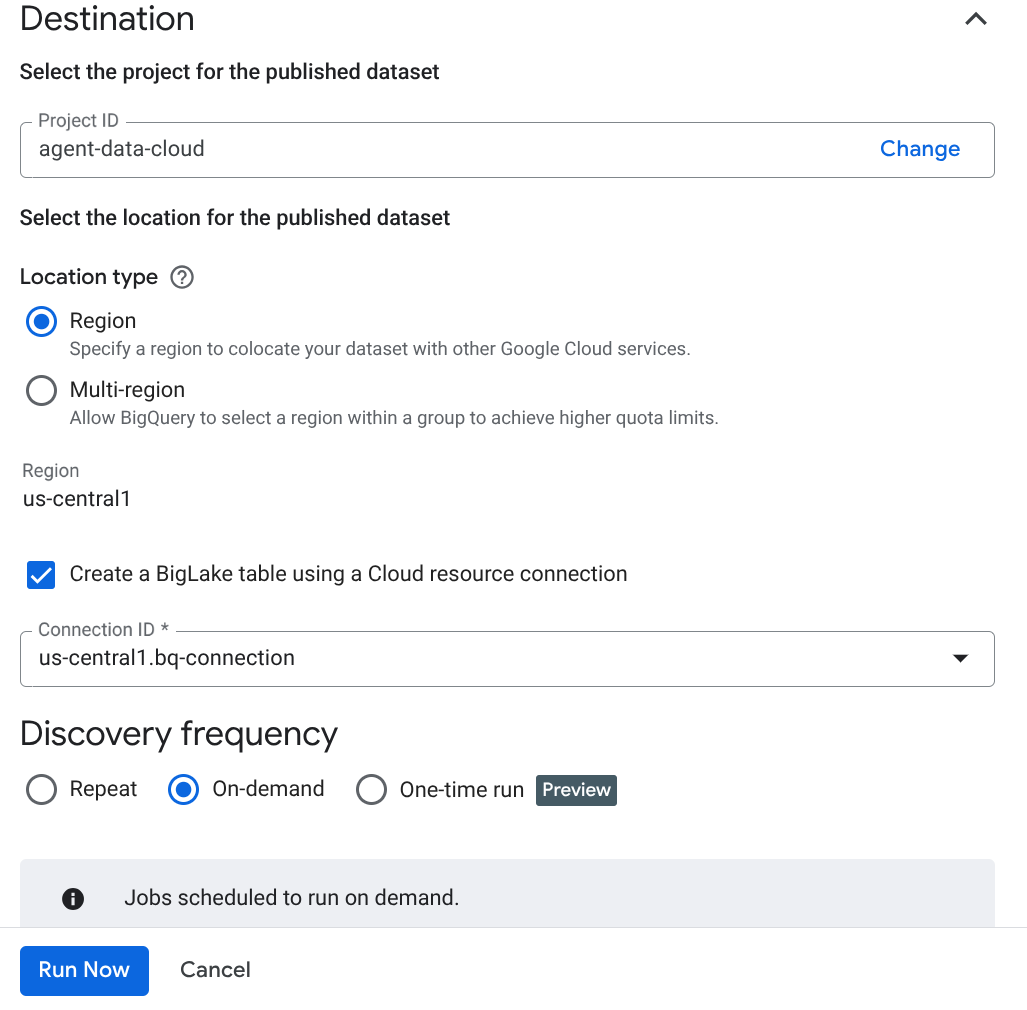
- Clique em "Executar agora".
- A conclusão do job de verificação vai levar algum tempo. Quando o job terminar, verifique se o conjunto de dados publicado está presente. Para verificar o status do job, acesse a página Criação de metadados, na guia "Descoberta do Cloud Storage", e clique no nome das verificações de descoberta da execução recente. O conjunto de dados publicado vai aparecer, como mostrado abaixo:
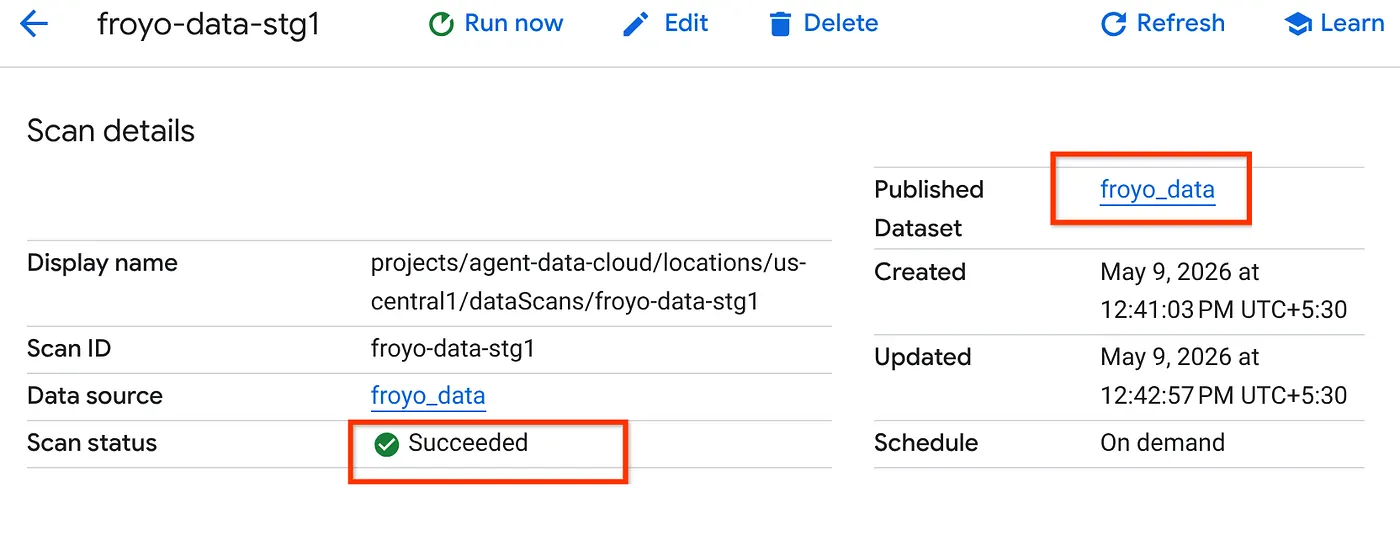
Observação: se você encontrar erros na etapa de verificação, aguarde um pouco e tente de novo. Leva alguns minutos para criar o job e concluir a execução.
- Para ver a tabela no BigQuery, clique e navegue até o conjunto de dados froyo_data. Clique no ID da tabela no BigQuery e execute a consulta abaixo na guia "Editor de consultas":
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
Isso resulta em 400 (se não, volte e execute o job de verificação de dados novamente).
7. Extração de dados semânticos
Ótimo! Agora vamos extrair a inferência desses objetos não estruturados usando o Knowledge Catalog.
Vamos usar o recurso Insights para gerar instruções SQL e extrair dados estruturados da tabela não estruturada.
- No console do Google Cloud, acesse a página Pesquisa do Knowledge Catalog.
- Pesquise a tabela do conjunto de dados para que você quer ver insights. Na barra de pesquisa, insira o nome do conjunto de dados / tabela da etapa anterior: "froyo_data" e pressione Enter.
- Na lista de resultados, clique na entrada TABLE (não a do conjunto de dados).
- A guia INSIGHTS vai aparecer. Clique nele. Se for necessário ativar alguma API, siga as instruções e faça isso.
Se você ativou APIs neste momento, execute o trabalho de verificação novamente.
- Na guia INSIGHTS, você vai encontrar o menu suspenso do botão EXTRAIR. Clique nessa opção e selecione "Extrair com SQL".
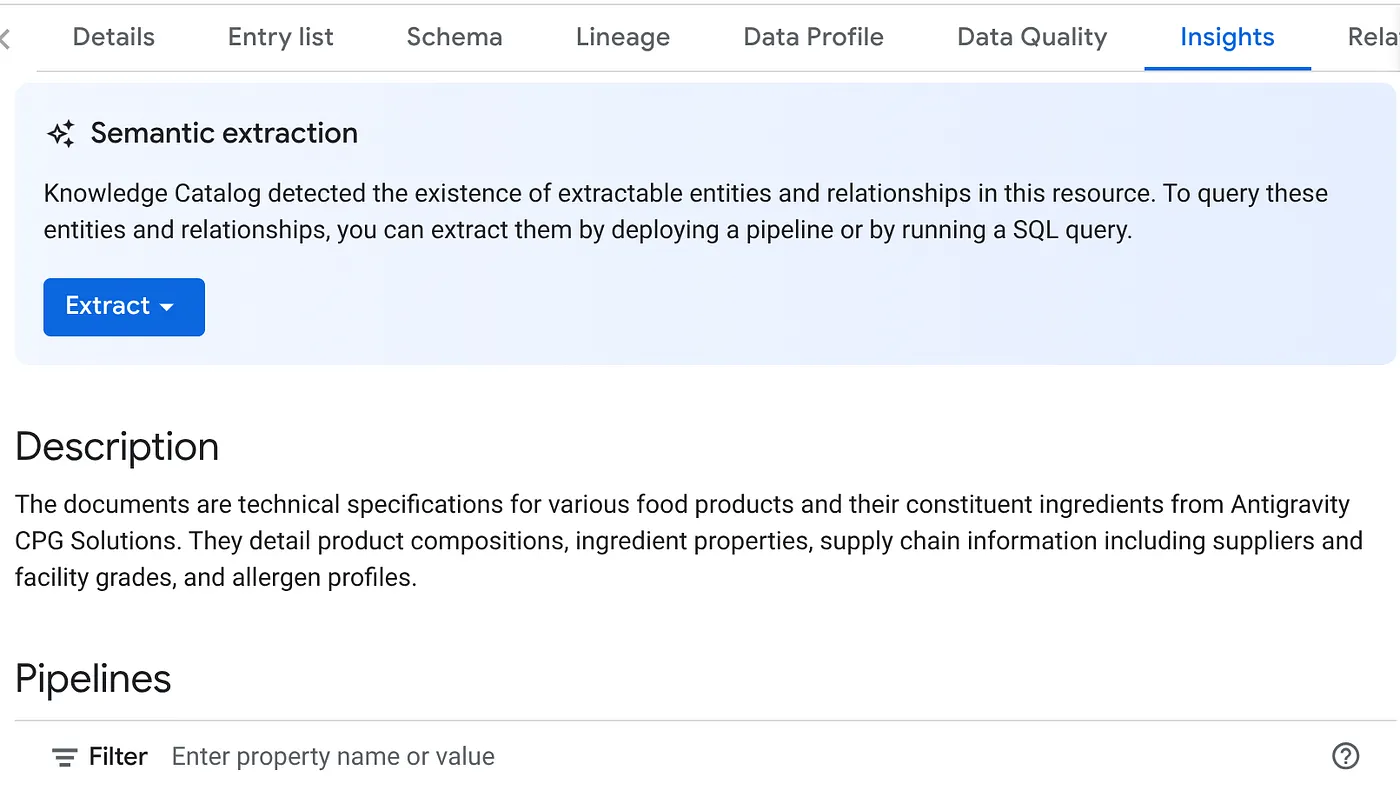
Na caixa de diálogo "Extrair com SQL", defina o conjunto de dados de DESTINO como aquele que você viu no resultado do job de verificação de dados. Comece a digitar o nome dele, que vai aparecer no preenchimento automático. Clique no botão Extrair. Você também pode criar um conjunto de dados e extrair informações.
Isso vai abrir o editor de consultas do BigQuery com uma guia preenchida com o SQL extraído da inferência da verificação de dados.
8. Validação de SQL e criação de esquema
Se a consulta gerada parecer boa e semanticamente relevante para seus dados não estruturados, execute-a clicando no botão "Executar" no editor de consultas. A criação do esquema necessário para o armazenamento estruturado da mídia não estruturada leva alguns minutos.
Depois disso, é possível verificar o esquema abrindo o conjunto de dados no painel do explorador do BigQuery Studio, conforme mostrado abaixo:
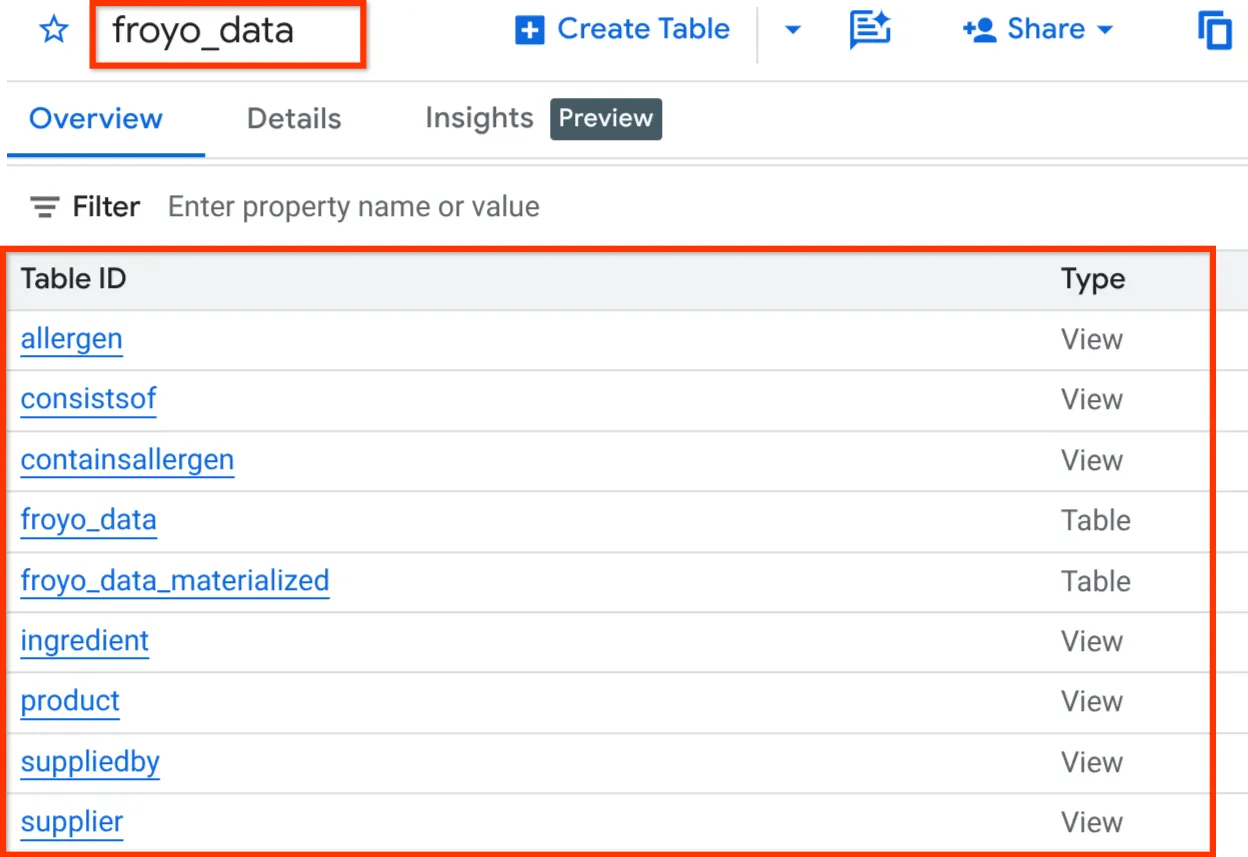
Tudo bem! Foi tão legal que fizemos todas essas coisas de banco de dados muito rápido. Agora é hora do teste final!
Etapas para continuar usando os dados sem a conta de faturamento:
- Você pode acessar os arquivos csv (dados do BigQuery) no link do repositório do GitHub acima.
- Primeiro, crie o conjunto de dados do BigQuery executando o comando abaixo no terminal do Cloud Shell:
bq mk --location us-central1 --dataset froyo_data
- Em seguida, baixe os oito arquivos de dados (arquivos CSV) do repositório do GitHub para seu diretório de trabalho executando os comandos a seguir um por um:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Execute os comandos a seguir um por um para criar essas tabelas com os dados no conjunto de dados recém-criado.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Depois que o conjunto de dados, as tabelas e os dados forem criados, você poderá testar e conhecer os dados que acabamos de discutir.
9. O teste final!!!
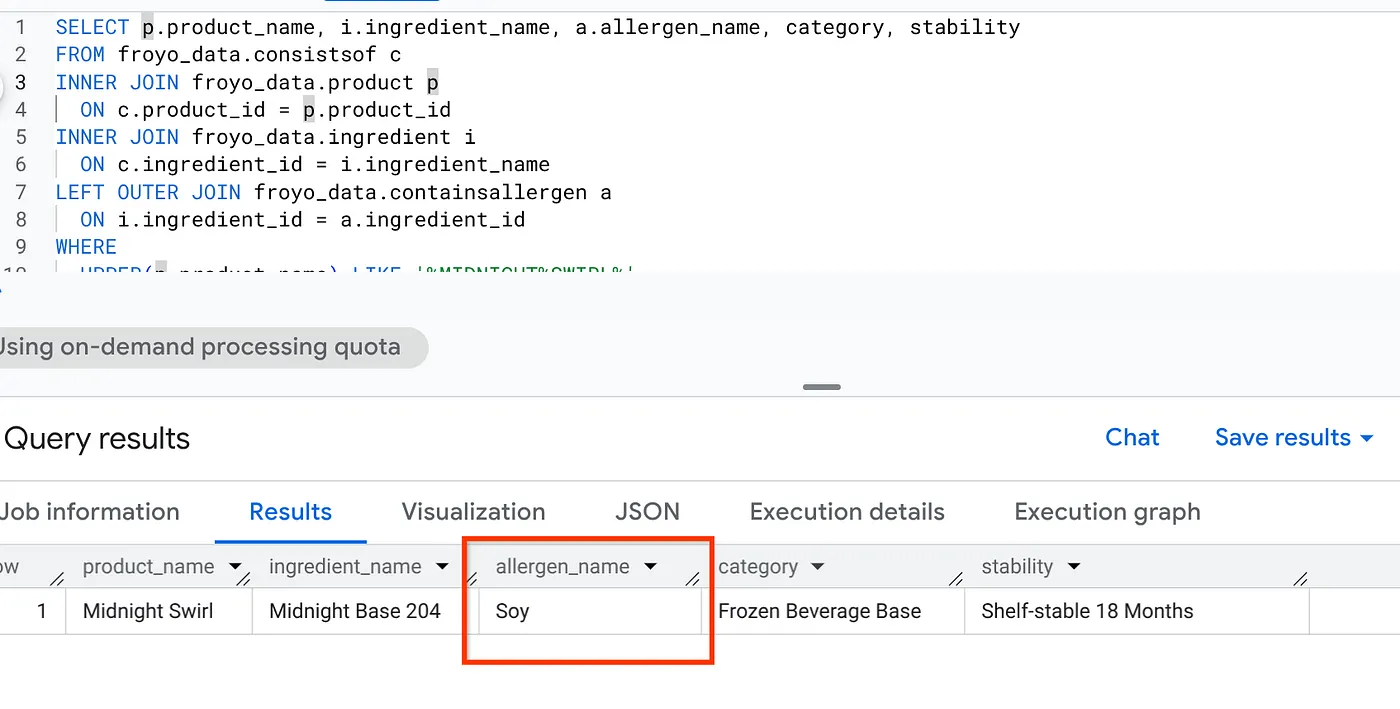
Digamos que eu queira que meu agente responda às perguntas do usuário com informações reais, completas e bem organizadas, baseadas em fatos. Vou fazer uma pergunta que o agente só poderá responder consultando vários arquivos de mídia e referências da minha fonte.
Esta é minha pergunta:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
Agora, uma pesquisa genérica ou de LLM vai dizer "Nenhum ingrediente". Mas criamos uma inferência semântica completa, convertendo toda a mídia não estruturada em dados estruturados. Aqui está um SQL simples que vai buscar essas informações:
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
Uhuuu! Confira o resultado:
10. Limpar
Depois de concluir este laboratório, não se esqueça de excluir o job de verificação e as tabelas do BigQuery que ele criou.
Acesse https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery. Clique nas reticências verticais ao lado do job que você quer excluir e clique em EXCLUIR.
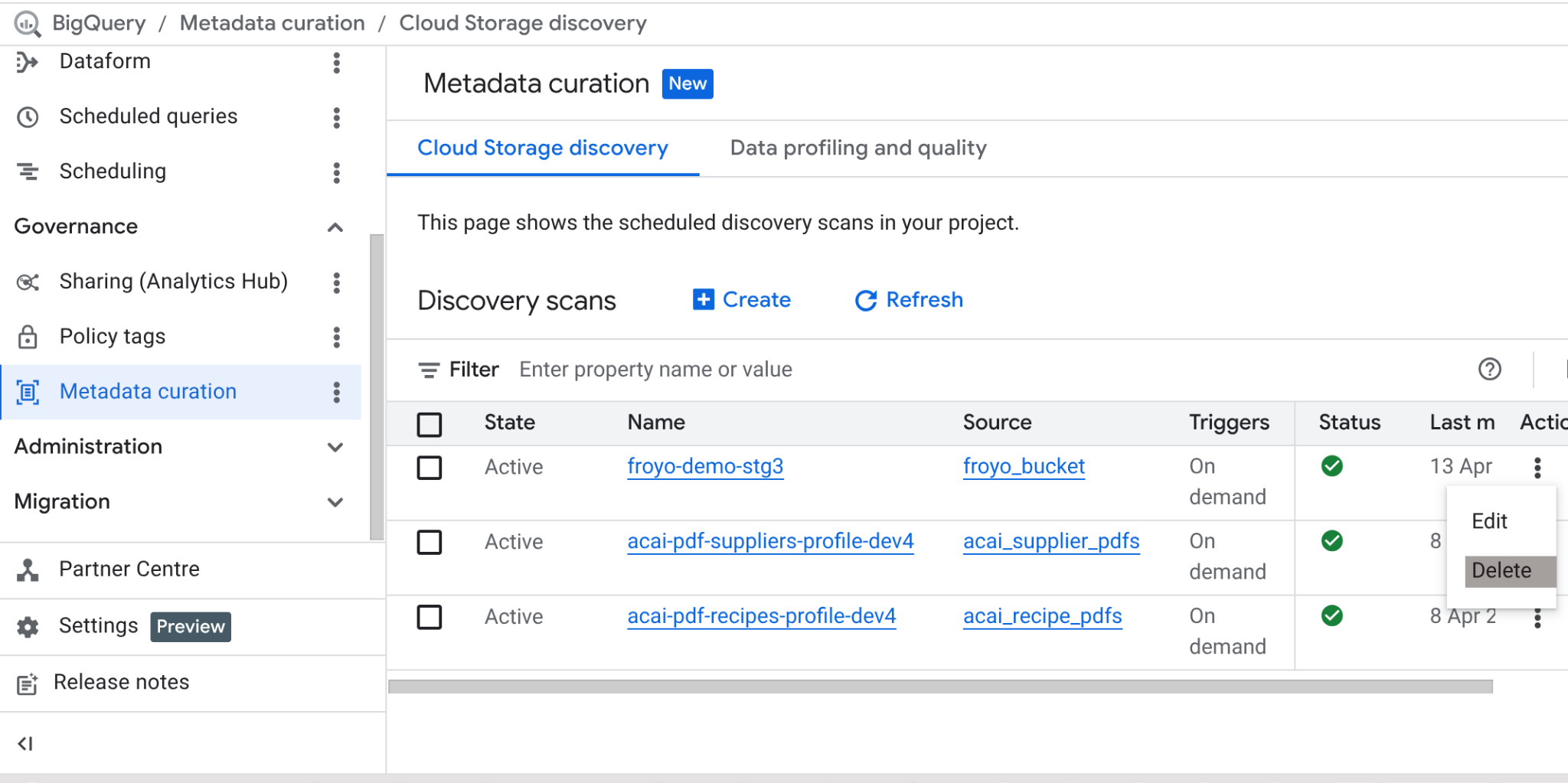
Isso vai limpar o job.
11. Parabéns
Nossa implementação conseguiu identificar o alérgeno oculto. Acabou o dark data, pessoal!!! Na parte 2, vamos federar esses dados do BigQuery em um sistema transacional com o AlloyDB para unificar as necessidades de dados do nosso aplicativo com agentes.