
1. Visão geral
Na Parte 1, transformamos PDFs caóticos e não estruturados em tabelas limpas, inteligentes e estruturadas no BigQuery usando o Knowledge Catalog e o DataScan. Agora temos um data warehouse robusto.
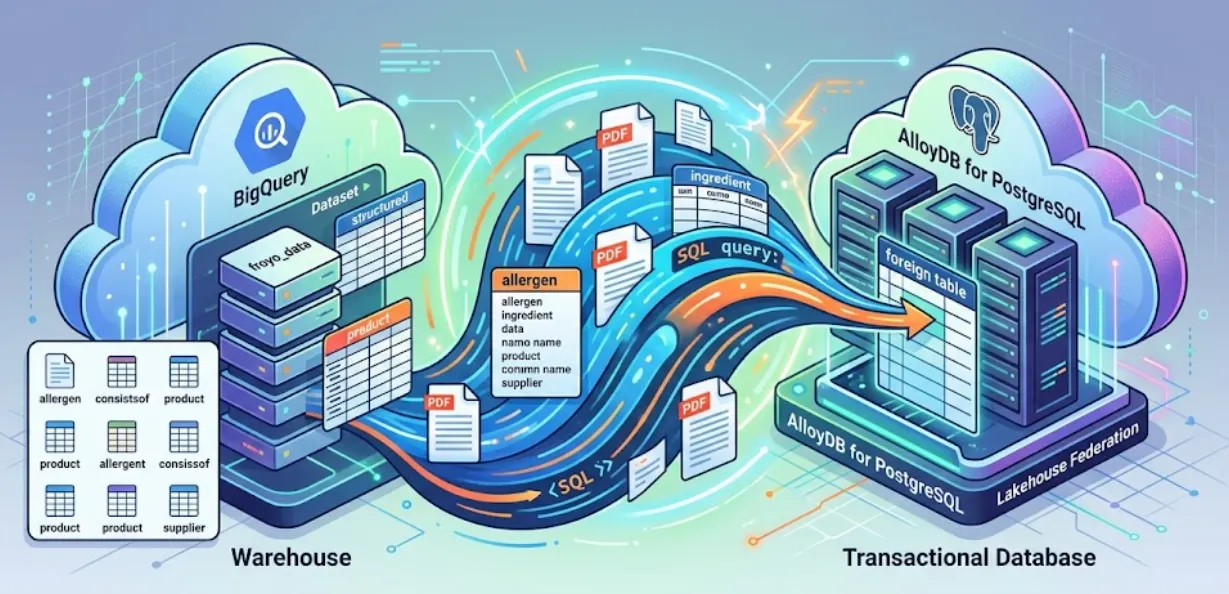
Para relembrar, no laboratório da parte 1, usamos o caso de uso de uma franquia fictícia de iogurte congelado e convertemos 400 arquivos PDF não estruturados, que abrangem texto, tabelas e imagens, em tabelas do BigQuery bem estruturadas com relações inferidas automaticamente entre elas usando o BigQuery Knowledge Catalog e o Dataplex.
O que você vai criar
Nesta sessão, vamos configurar o AlloyDB para PostgreSQL e fazer algo mágico: federar nossos dados do BigQuery diretamente no AlloyDB. Isso significa que nosso app transacional pode consultar os dados do nosso data warehouse em tempo real, sem copiar ou duplicar nada.
Como desenvolvedor, você precisa fazer esta pergunta nesta etapa:
"Se os dados já estão no BigQuery, por que usar o AlloyDB? Por que o aplicativo não executa uma instrução SELECT diretamente no BigQuery?"
Saiba por quê:
Com a federação de lakehouse, é possível usar o mecanismo de consulta do AlloyDB para impulsionar as cargas de trabalho transacionais e analíticas do seu aplicativo na mesma interface. Você também pode materializar ou importar esses dados no AlloyDB para ter acesso mais rápido e usar nos seus aplicativos, o que permite usar a IA do AlloyDB e o mecanismo colunar.
Você pode usar o AlloyDB como um banco de dados transacional e também ter grandes quantidades de dados no BigQuery ou no BigLake. Normalmente, seus aplicativos se integram de forma independente aos dois sistemas para acessar dados em diferentes serviços do Google Cloud. Com a federação do Lakehouse para AlloyDB, é possível usar o suporte a consultas federadas do AlloyDB implementado como um wrapper de dados externos para acessar dados do BigQuery e do AlloyDB usando uma interface SQL no AlloyDB.
Em vez de criar um pipeline de ETL frágil para consultar os dados do BigQuery no AlloyDB, vamos usar consultas federadas. O AlloyDB vai atuar como um endpoint unificado, acessando o BigQuery sem problemas quando necessário.
Vamos começar a criar!
O que você vai aprender
- Como configurar cluster, instância e rede do AlloyDB com um clique
- Como configurar a extensão para se preparar para a federação
- Como configurar a federação do BigQuery para o AlloyDB
- Testar
Requisitos
2. Antes de começar
Criar um projeto
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Confira se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud. Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud.

- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com seu ID do projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se você quiser autenticar
gcloud auth login
- Se o projeto não estiver definido, use este comando:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Ative as APIs necessárias: execute este comando para ativar todas as APIs necessárias:
gcloud services enable alloydb.googleapis.com
Problemas e solução de problemas
A síndrome do projeto fantasma | Você executou |
A barricada de faturamento | Você ativou o projeto, mas esqueceu a conta de faturamento. O AlloyDB é um mecanismo de alto desempenho. Ele não vai iniciar se o "tanque de combustível" (faturamento) estiver vazio. |
Atraso na propagação da API | Você clicou em "Ativar APIs", mas a linha de comando ainda mostra |
Quags de cota | Se você estiver usando uma conta de teste nova, talvez atinja uma cota regional para instâncias do AlloyDB. Se |
3. Resumo rápido dos dados da Parte 1
Nesta seção, você precisa garantir que os dados estruturados extraídos de PDFs não estruturados estejam disponíveis no BigQuery. Se você perdeu a parte 1 ou não tem uma conta de faturamento, não tem problema. Siga estas etapas para começar:
Acesse o console do Google Cloud com sua conta pessoal do Gmail e clique no botão "Ativar o Cloud Shell" no canto superior direito do console:
Em seguida, siga as etapas na seção "Sem conta de faturamento" abaixo:
Etapas para continuar usando os dados sem a conta de faturamento:
- Você pode acessar os arquivos csv (dados do BigQuery) no link do repositório do GitHub acima.
- Primeiro, crie o conjunto de dados do BigQuery executando o comando abaixo no terminal do Cloud Shell:
bq mk --location us-central1 --dataset froyo_data
- Em seguida, baixe os oito arquivos de dados (arquivos CSV) do repositório do GitHub para seu diretório de trabalho executando os seguintes comandos um por um:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Execute os comandos a seguir um por um para criar essas tabelas com os dados no conjunto de dados recém-criado.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Agora que temos os dados no BigQuery, vamos para as próximas etapas.
4. Configurar cluster, instância e rede do AlloyDB
Há um aplicativo de início rápido baseado na Web que ajuda a configurar o cluster, a instância e outras dependências do AlloyDB. Siga as etapas 2 a 4 deste laboratório para configurar com um clique:
https://codelabs.developers.google.com/quick-alloydb-setup
Depois que o cluster for criado, acesse a página "Visão geral do cluster" e copie os detalhes da conta de serviço.
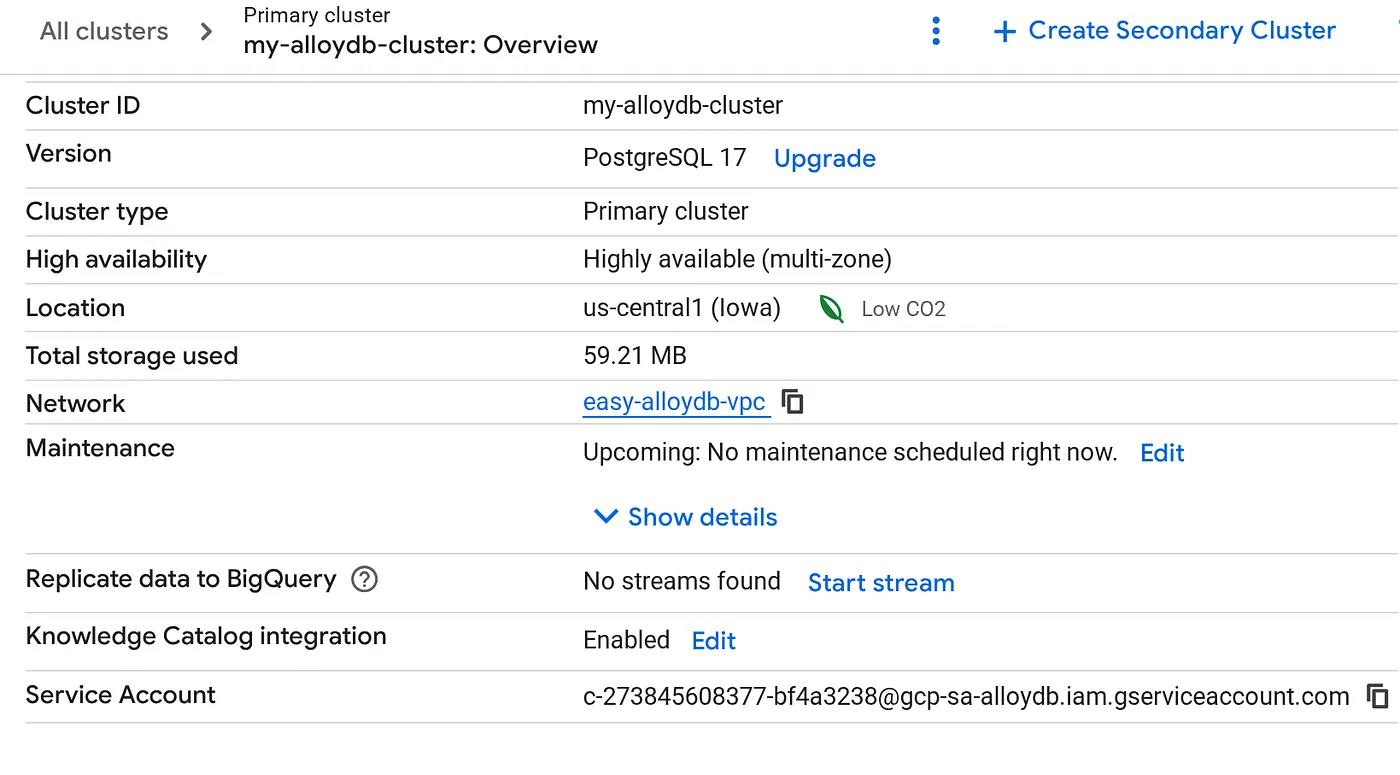
5. Configuração de permissões
Conceder permissões do BigQuery a essa conta de serviço
- Acesse IAM e administrador > IAM.
- Clique em "Conceder acesso".
- Cole o endereço da conta de serviço do AlloyDB no campo "Novos principais".
- Atribua os seguintes papéis:
- Leitor de dados do BigQuery (roles/bigquery.dataViewer): permite ler os dados.
- Usuário do BigQuery (roles/bigquery.user): permite executar as consultas.
- (Opcional, mas recomendado) Usuário da sessão de leitura do BigQuery (roles/bigquery.readSessionUser): otimiza a leitura de grandes conjuntos de dados pela API Storage Read.
6. Conectar-se ao AlloyDB e ativar a extensão do BigQuery
Agora vamos nos conectar à nossa nova instância do AlloyDB para configurar a extensão de federação. Vamos usar o AlloyDB Studio para isso.
- Na página "Visão geral do cluster" (console do AlloyDB), clique em Editar primário na instância principal e role até a parte de baixo para Opções de configuração avançada.
- Acesse a seção Flags e ative as duas flags como Ativado, conforme mostrado abaixo:
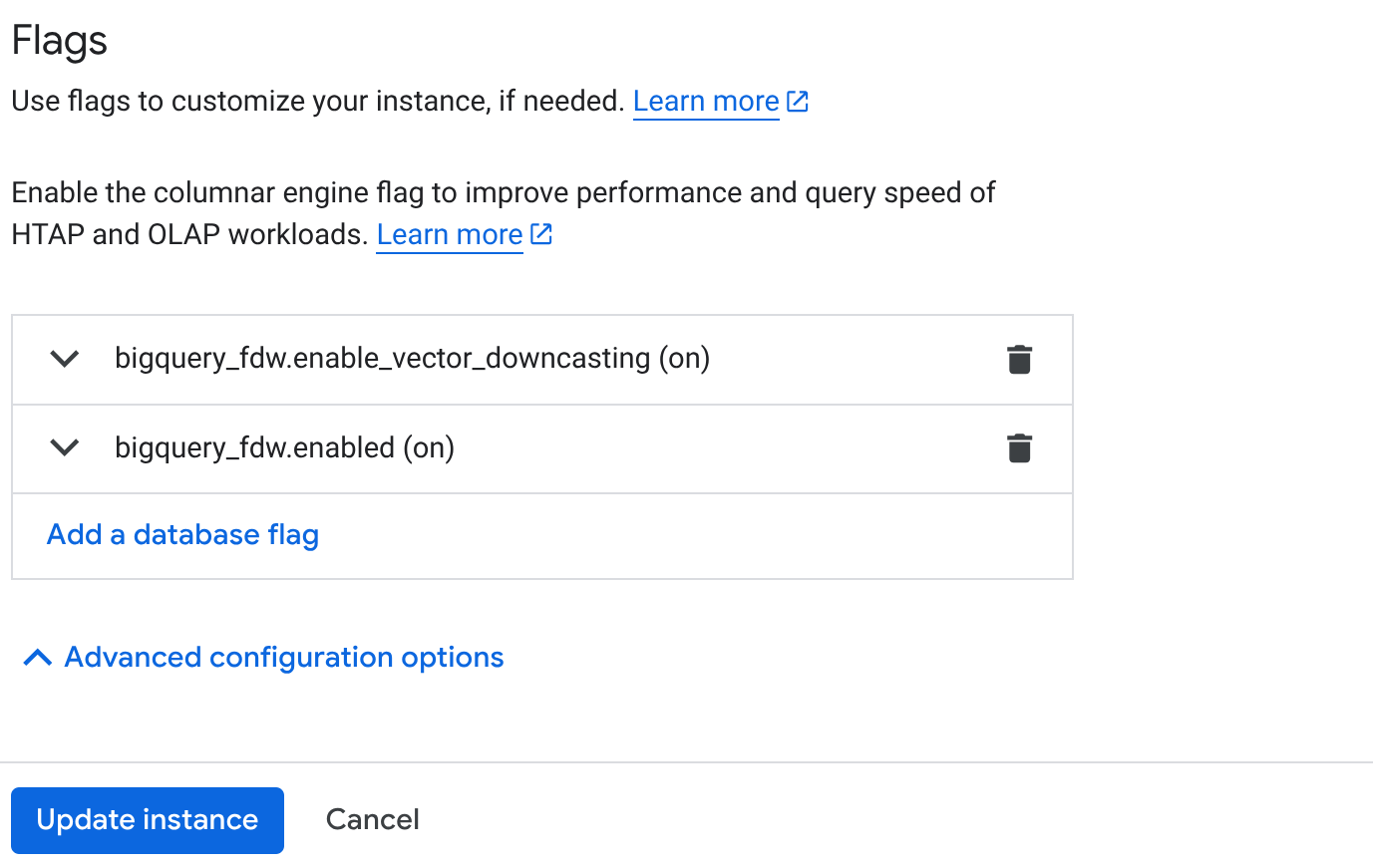 3. Clique no botão Atualizar instância. A atualização leva alguns minutos para ser concluída. 4. Na página "Visão geral do cluster" (console do AlloyDB), clique em "AlloyDB Studio".
3. Clique no botão Atualizar instância. A atualização leva alguns minutos para ser concluída. 4. Na página "Visão geral do cluster" (console do AlloyDB), clique em "AlloyDB Studio".
- Conecte-se com o banco de dados, o nome de usuário e a senha que você configurou na etapa de configuração rápida do AlloyDB.
- Depois de se conectar, na guia "Editor de consultas" à direita, insira as seguintes instruções e EXECUTE uma por uma:
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- Depois de fazer isso, navegue até o painel do explorador à esquerda e role para baixo até as tabelas do BigQuery:
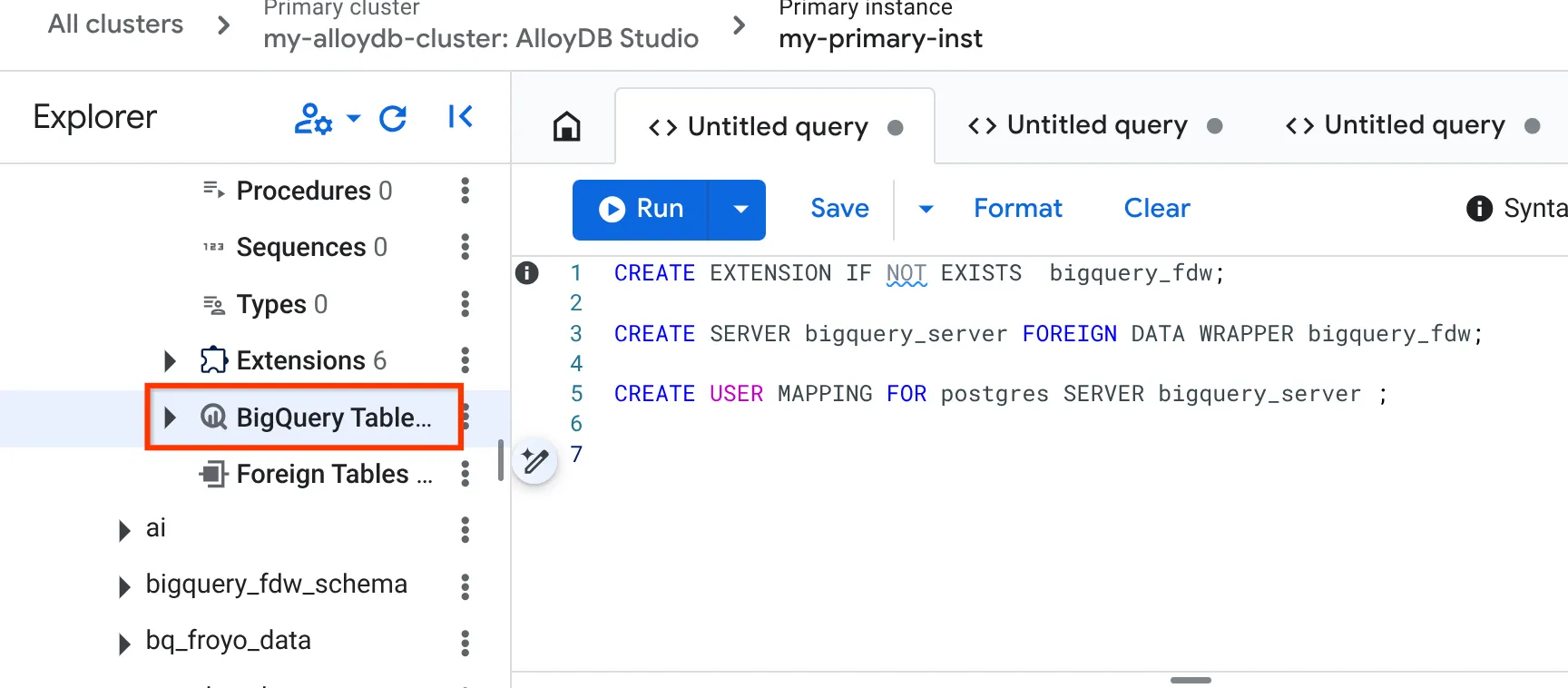
- Clique nos três pontos e em Conectar tabela do BigQuery.
- No pop-up "Conectar tabela do BigQuery" que aparece, selecione seu project_id e o nome do conjunto de dados do BigQuery (criado na parte 1) em que você quer consultar os dados no banco de dados do AlloyDB.
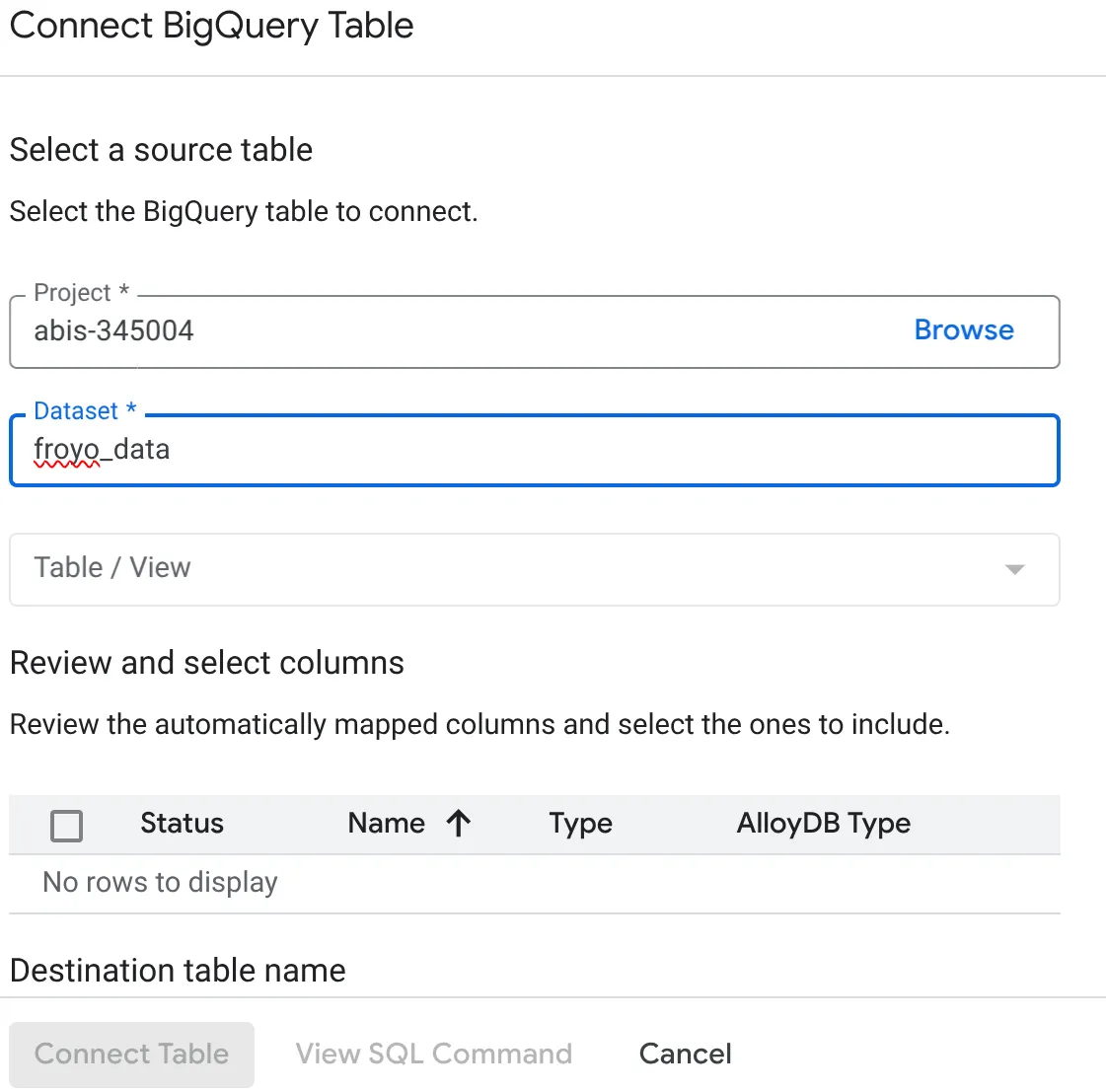
- Selecione cada tabela uma por uma para conectar todos os seus dados ao AlloyDB. Isso é feito para validar os tipos de coluna e garantir que eles sejam compatíveis com o AlloyDB.
Se você quiser fazer o mesmo com um SQL em vez da abordagem apontar e clicar:
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
A mágica!
Acabamos de criar "Tabelas externas" no AlloyDB. Elas parecem e agem como tabelas normais do PostgreSQL, mas não armazenam dados. Quando você consulta esses dados, o AlloyDB passa a consulta instantaneamente para o BigQuery, busca os resultados e os retorna para você.
7. Testar a federação no AlloyDB
Vamos verificar se podemos consultar nosso conjunto de dados analíticos do BigQuery diretamente do banco de dados transacional do PostgreSQL.
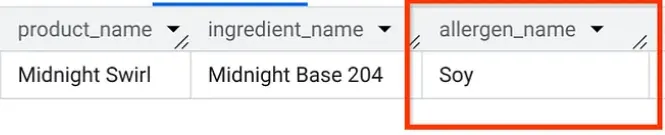
Ainda no AlloyDB Studio, vamos executar uma consulta para descobrir quais alérgenos estão no "Midnight Swirl" (a mesma pergunta que fizemos na Parte 1, mas desta vez feita pelo AlloyDB):
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
Boom. Você vai ver exatamente os mesmos resultados que no BigQuery.
8. Limpar
Depois de concluir este laboratório, não se esqueça de excluir o cluster e a instância do AlloyDB.
Ele vai limpar o cluster e as instâncias dele.
9. Parabéns pela sua camada de dados unificada
Pense no que acabamos de fazer:
- Nosso app transacional (executado no AlloyDB) pode processar sessões de usuários rápidas e simultâneas.
- Quando precisa de dados analíticos pesados ou contexto histórico (como detalhes do fornecedor ou mapeamentos complexos de ingredientes), ele consulta o froyo_dataschema do BigQuery.
- Zero ETL. Nenhum pipeline de dados sendo interrompido. Não há bancos de dados dessincronizados. Armazenamos uma vez (no BQ) e computamos onde precisamos.
Agora que nossa base de dados, tanto analítica quanto transacional, está sólida e interconectada, estamos prontos para a parte divertida.
Na Parte 3, vamos criar o aplicativo multiagente que fica em cima dessa arquitetura para executar as operações comerciais da Froyo.