
1. Обзор
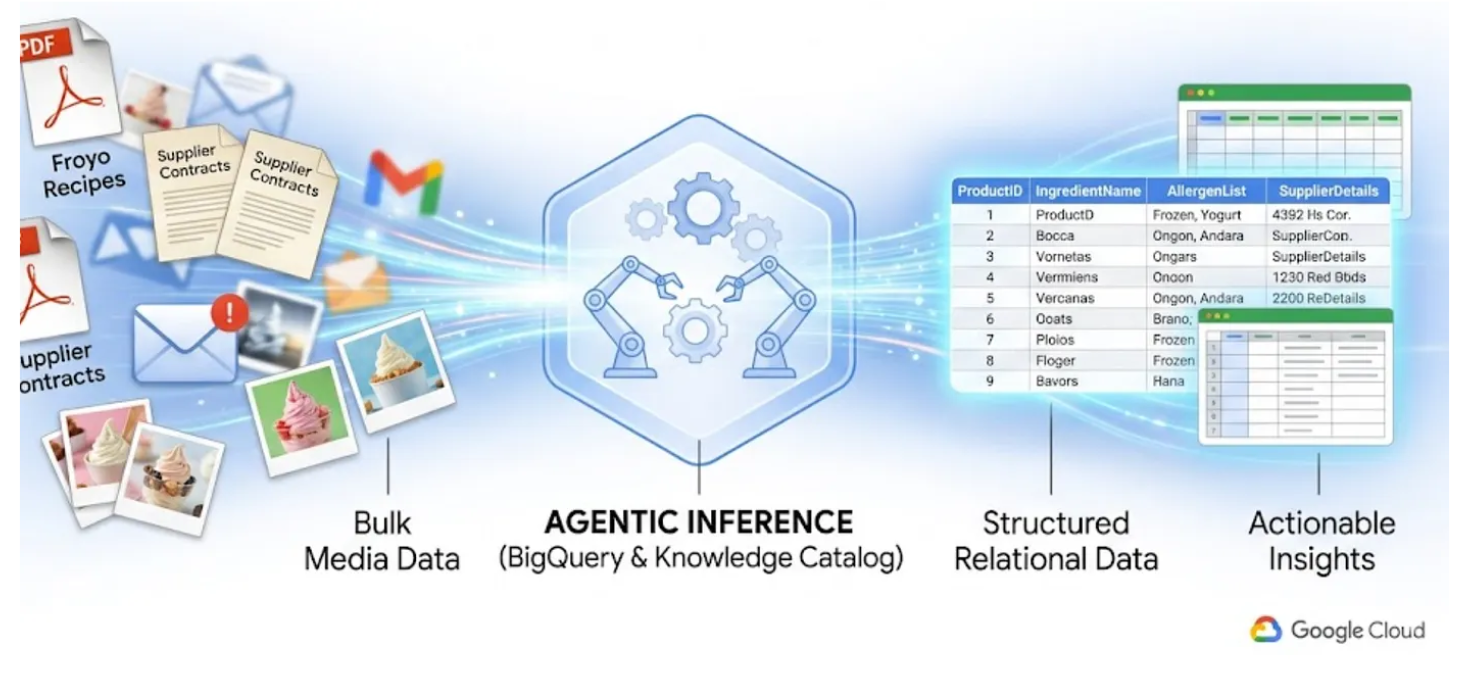
Всем известно, что такое «теневые данные». Это PDF-файлы, изображения и текстовые файлы, хранящиеся в облачных хранилищах и совершенно невидимые для SQL-запросов и BI-панелей. Традиционно для доступа к этим данным требовались сложные конвейеры оптического распознавания текста, ручной ввод данных или ненадежные пользовательские скрипты.
Уже нет.
В этой лабораторной работе я покажу вам, как преобразовать 400 неструктурированных PDF-файлов — содержащих текст, таблицы и изображения — в четко структурированные таблицы BigQuery с автоматически определяемыми связями между ними. И мы сделаем это за считанные минуты, используя BigQuery Knowledge Catalog и Dataplex.
Что вы построите
Чтобы это выглядело правдоподобно, давайте рассмотрим вымышленный бизнес: быстрорастущую франшизу по продаже замороженного йогурта.
Представьте, что вы управляете данными для этого бизнеса по производству замороженного йогурта. У вас сотни рецептов и спецификаций поставщиков, все сохранены в формате PDF. Руководство компании хочет запустить агента на основе искусственного интеллекта, чтобы помочь менеджерам магазинов и покупателям запрашивать информацию о продуктах.
Вот кошмарный сценарий: покупатель спрашивает: «Меня очень заинтересовал ваш замороженный йогурт Midnight Swirl. Есть ли в нем какие-либо аллергены?»
Для ответа на этот вопрос вашей системе, как правило, потребуется:
- Найдите PDF-файл с рецептом "Полуночного вихря".
- Внимательно изучите состав (например, «Какао-порошок», «Молочная основа», «Эмульгатор X»).
- Просмотрите десятки PDF-файлов от поставщиков, чтобы найти технические характеристики конкретных ингредиентов.
- Проверьте информационные листы поставщиков на наличие скрытых аллергенов, связанных с этими ингредиентами.
Попытка создать ИИ-агента, который будет делать это на лету, считывая 400 необработанных PDF-файлов во время выполнения, — это медленно, дорого и чревато галлюцинациями. Вместо этого мы будем использовать семантический вывод, чтобы сначала извлечь все это в реляционную базу данных, что сделает нашего будущего ИИ-агента молниеносно быстрым и на 100% основанным на фактических данных SQL.
Начнём строительство!
Что вы узнаете
- Как настроить хранилище Cloud Storage для исходных файлов (PDF-файлов)
- Как настроить и запустить задачу Datascan и семантический вывод в Knowledge Catalog для извлечения данных из исходных PDF-файлов, семантического вывода связей и контекста и сохранения их в BigQuery.
- Как использовать BigQuery Agents для общения с недавно созданным набором данных
Требования
2. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.

- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если вы хотите пройти аутентификацию
gcloud auth login
- Если ваш проект не задан, используйте следующую команду для его установки:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Включите необходимые API: Выполните эту команду, чтобы включить все необходимые API:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
Подводные камни и устранение неполадок
Синдром «Проекта-призрака» | Вы выполнили команду |
Баррикада Биллинга | Вы активировали проект, но забыли указать платежный аккаунт. AlloyDB — высокопроизводительный движок; он не запустится, если «топливо» (платежный бак) пуст. |
Задержка распространения API | Вы нажали «Включить API», но в командной строке по-прежнему отображается сообщение |
Квота Квагс | Если вы используете совершенно новую пробную учетную запись, вы можете столкнуться с региональной квотой на экземпляры AlloyDB. Если |
«Скрытый» сервисный агент | Иногда агенту службы AlloyDB автоматически не предоставляется роль |
3. Настройка хранилища Google Cloud Storage.
В этом разделе вы создаете организационную структуру в BigQuery для хранения данных о рецептах и поставщиках замороженного йогурта, в частности, подробной информации о продукте. Также устанавливается соединение с облачным ресурсом, которое выступает в качестве защищенного «моста», позволяющего BigQuery считывать файлы из внешних источников, таких как облачное хранилище.
Прежде чем начать:
В этом репозитории содержатся рецепты и PDF-файлы поставщиков, которые мы будем использовать в этом проекте. Обязательно скачайте эти файлы. Для скачивания файлов выполните следующие действия.
В оболочке Cloud Shell выполните следующую команду:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
Перейдите в только что созданную папку:
cd next-26-keynotes
Загрузите папку data-cloud-demo.
git sparse-checkout set genkey/data-cloud-demo
После завершения оформления заказа перейдите в папку data-cloud-demo и распакуйте ZIP-файлы, чтобы получить доступ к ресурсам Codelab.
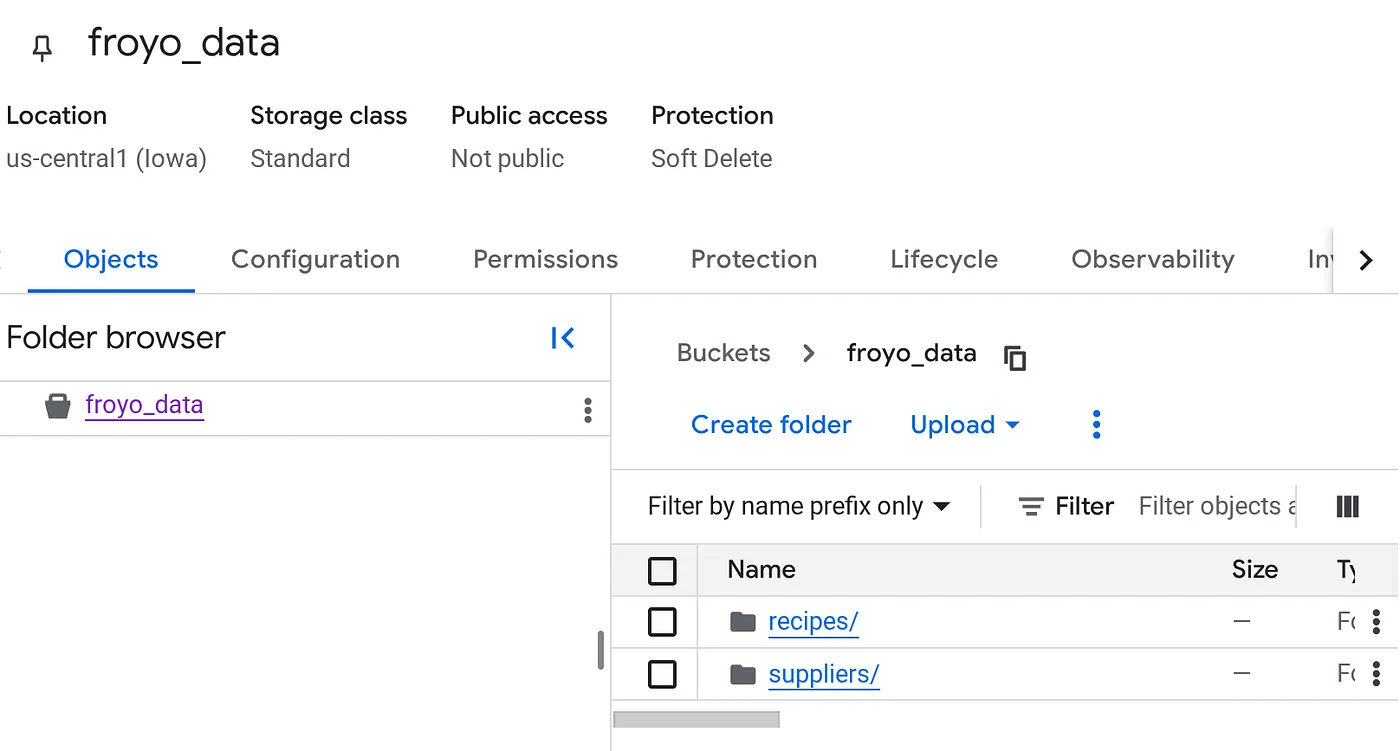
Создайте хранилище и загрузите PDF-файлы с рецептами и информацией о поставщиках замороженного йогурта.
- В консоли Google Cloud перейдите на страницу «Корзины облачного хранилища» .
- Нажмите «Создать».
- На странице «Создать корзину» введите информацию о вашей корзине. После каждого из следующих шагов нажимайте «Продолжить», чтобы перейти к следующему шагу:
- В разделе «Начало работы» введите имя хранилища. Например: froyo_data
- В разделе «Выберите место хранения данных» выберите «Регион», а затем введите свой регион. us-central1
- В разделе «Выберите способ управления доступом к объектам» снимите флажок «Применять публичную защиту доступа к этому сегменту».
- Нажмите «Создать».
- В списке сегментов щелкните по созданному вами сегменту.
- На вкладке «Объекты» для корзины нажмите «Загрузить», а затем «Загрузить папки».
- Выберите папку с рецептами , которую вы распаковали в разделе «Перед началом работы» этого практического задания.
- Нажмите «Загрузить».
- Повторите процесс загрузки для папки поставщиков .
После загрузки структура вашего хранилища должна выглядеть следующим образом (независимо от имени хранилища):
4. Настройка подключения к BigQuery
Создайте подключение к облачным ресурсам. Это создаст уникальную учетную запись службы, которая будет выступать в качестве «идентификационной карты» BigQuery для доступа к внешним файлам.
- Перейдите на страницу BigQuery .
- В левой панели щелкните «Проводник». Если левая панель не отображается, щелкните «Развернуть левую панель», чтобы открыть ее.
- В панели «Проводник» разверните название проекта, а затем щелкните «Подключения».
- На странице «Подключения» нажмите «Создать подключение».
- В поле «Тип подключения» выберите модели удаленного доступа Vertex AI, функции удаленного доступа, BigLake и Spanner (облачный ресурс).
- В поле «Идентификатор подключения» введите имя идентификатора подключения:
- bq-connection. Обязательно запишите этот ID, так как он понадобится вам при настройке сканирования данных позже в этом практическом задании.
- Установите тип местоположения на «Регион», а затем выберите регион. Например, us-central1. Соединение должно находиться в том же регионе, что и другие ваши ресурсы, такие как наборы данных.
- Нажмите «Создать соединение».
- Нажмите «Перейти к подключению».
- В панели «Информация о подключении» скопируйте идентификатор учетной записи службы для использования на следующем шаге. Учетная запись службы выглядит примерно так: bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
5. Настройка прав доступа
- Предоставьте необходимые разрешения подключению BigQuery для доступа к объектам Cloud Storage и каталогу знаний.
Перейдите на страницу IAM и администрирование, в разделе «Просмотр по субъектам» нажмите кнопку «Предоставить доступ», добавьте субъект, вставив учетную запись службы, скопированную на предыдущем шаге. В разделе «Роли» добавьте имена следующих ролей по очереди и сохраните:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/store.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- Предоставьте учетной записи службы Dataplex права доступа к облачному хранилищу.
Перейдите на страницу IAM и администрирование , в разделе « Просмотр по субъектам» нажмите кнопку «Предоставить доступ» и добавьте субъект, введя слово dataplex в текстовое поле «Новый субъект». Из списка, который автоматически заполнится, выберите субъект учетной записи службы Dataplex, который выглядит примерно так: ( используйте номер проекта, а не идентификатор проекта, в поле адреса электронной почты учетной записи службы ниже)
service-<< НОМЕР_ВАШЕГО_ПРОЕКТА >>@ gcp-sa-dataplex.iam.gserviceaccount.com
Если по какой-либо причине указанная выше учетная запись службы для номера вашего проекта не распознается, возможно, проект еще не инициализировал службу Dataplex. Перейдите в терминал Cloud Shell и попробуйте включить API (если это еще не было сделано на этапе подготовки к запуску ), выполнив следующую команду: gcloud services enable dataplex.googleapis.com
Даже если после этого учетная запись службы Dataplex не распознается, принудительно создайте тестовое задание сканирования Dataplex на странице «Управление метаданными» и введите данные на странице создания задания Discover:
Нажмите «Запустить сейчас» . Задание завершится с ошибкой, но это гарантирует инициализацию идентификатора учетной записи службы для вашей службы Dataplex.
Вернитесь на страницу IAM и администрирования , в разделе « Просмотр по субъектам» нажмите кнопку «Предоставить доступ» , а затем — «Добавить субъект». Вставьте учетную запись службы:
service-<< НОМЕР_ВАШЕГО_ПРОЕКТА >>@ gcp-sa-dataplex.iam.gserviceaccount.com
Затем предоставьте этой учетной записи службы следующие роли:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/store.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. Настройка каталога знаний
Создайте каталог знаний для объединения неструктурированных данных и автоматизации поиска неструктурированных файлов (таких как PDF-рецепты и поставщики PDF-файлов).
Создайте задание DataScan из консоли:
- Перейдите на страницу обработки метаданных .
- Нажмите «Создать» и введите данные, соответствующие вашей конфигурации:
Важное примечание: не забудьте установить флажок «Включить семантический вывод».
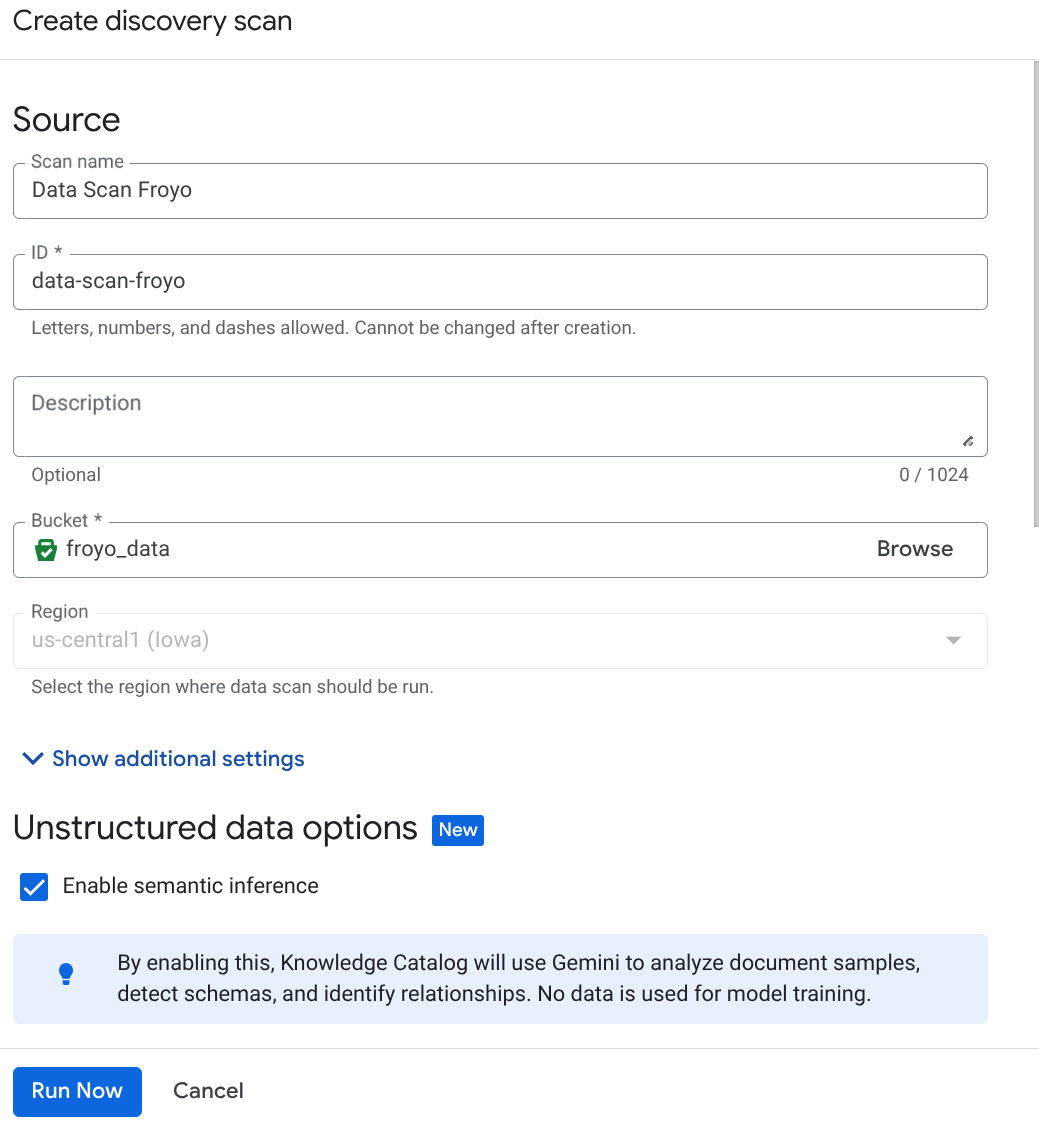
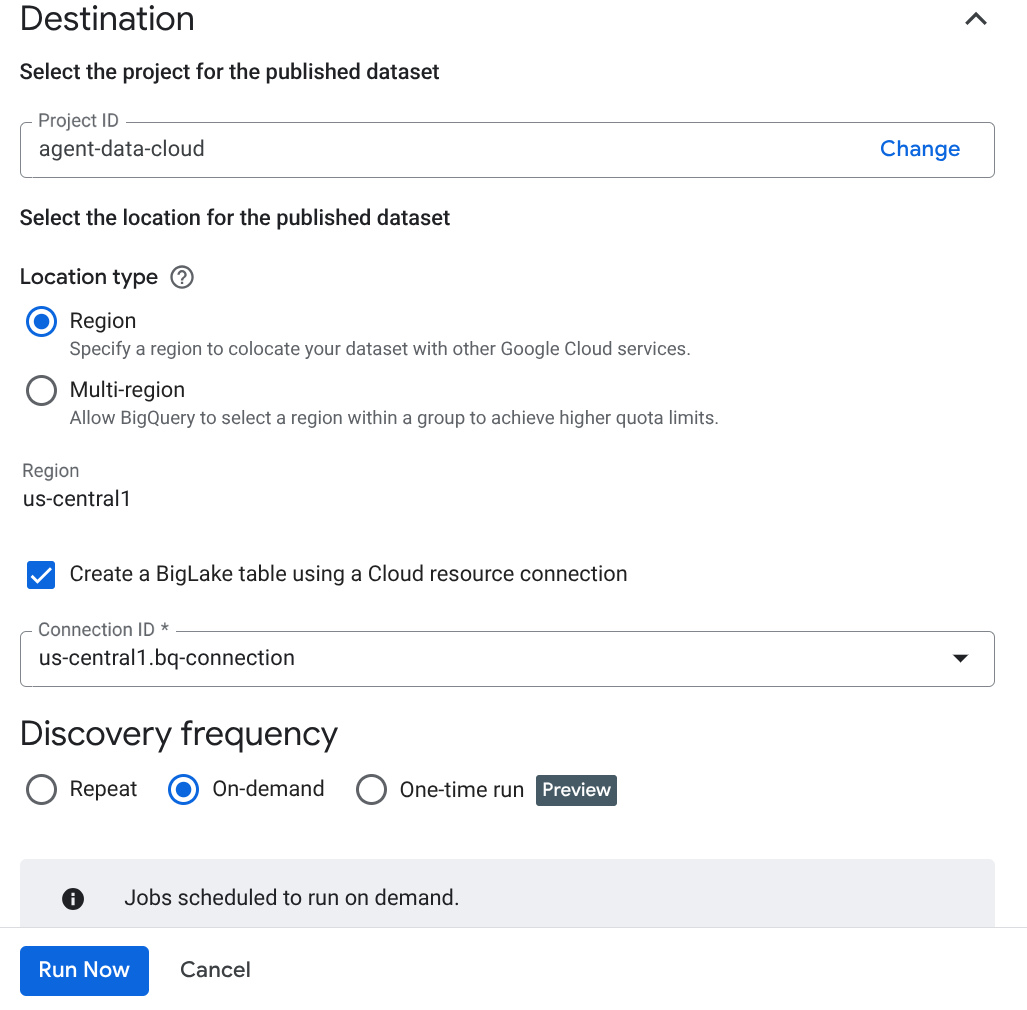
- Нажмите «Запустить сейчас».
- Сканирование займет некоторое время. После завершения проверьте наличие опубликованного набора данных. Чтобы проверить статус задания, перейдите на страницу управления метаданными , на вкладке «Обнаружение в облачном хранилище» и щелкните имя сканирования последнего запуска. Вы должны увидеть опубликованный набор данных, как показано ниже:
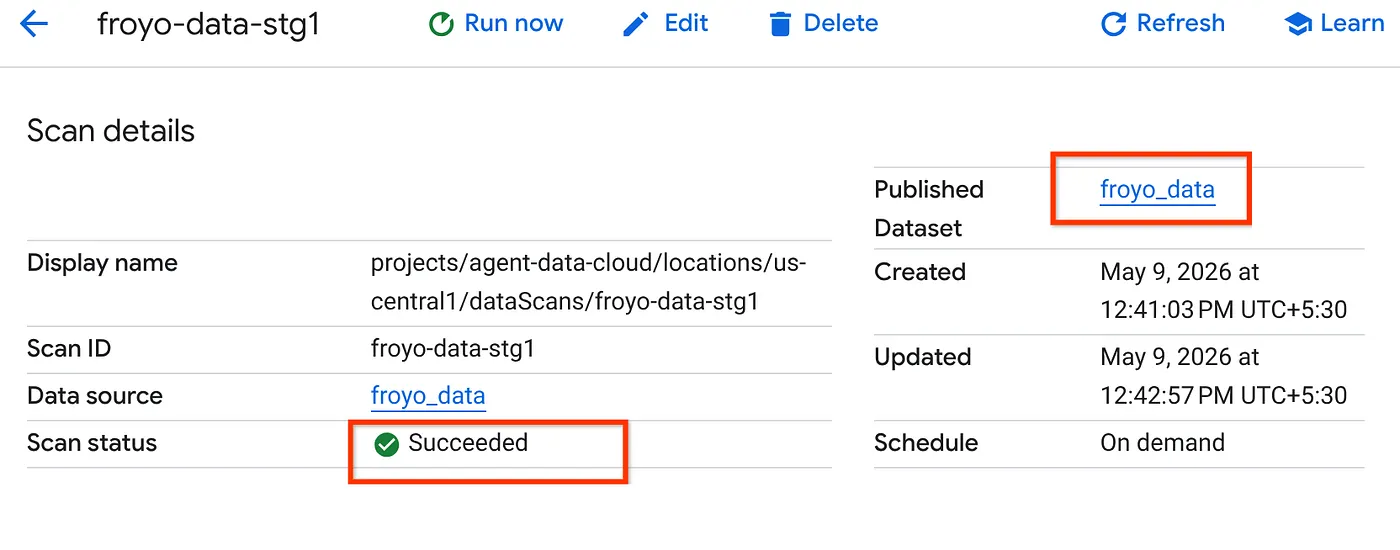
Примечание: Если на этапе сканирования возникнут ошибки, просто подождите немного и повторите попытку (на создание задания и его выполнение потребуется несколько минут).
- Вы можете просмотреть таблицу в BigQuery, щелкнув по ней и перейдя к набору данных froyo_data . Щелкните по идентификатору таблицы в BigQuery и выполните следующий запрос на вкладке «Редактор запросов»:
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
В результате получается код ошибки 400 (если нет, можно вернуться и запустить задание Datascan заново).
7. Извлечение семантических данных
Отлично!! Теперь давайте извлечем информацию из этих неструктурированных объектов с помощью каталога знаний.
Мы воспользуемся функцией Insights для генерации SQL-запросов с целью извлечения структурированных данных из неструктурированной таблицы.
- В консоли Google Cloud перейдите на страницу поиска по каталогу знаний .
- Найдите таблицу набора данных, для которой вы хотите просмотреть аналитические данные. В строке поиска введите имя набора данных/таблицы из предыдущего шага: "froyo_data" и нажмите Enter.
- В списке результатов щелкните по записи "ТАБЛИЦА" (а не по записи "Набор данных").
- Вы должны увидеть вкладку «АНАЛИТИКА» . Нажмите на неё (если требуется включить какой-либо API, следуйте инструкциям и просто включите API).
Если вы в итоге включили API на этом этапе, вам необходимо повторно запустить задание сканирования.
- На вкладке «АНАЛИТИКА» вы увидите выпадающее меню «ИЗВЛЕЧЕНИЕ». Нажмите на него и выберите опцию «Извлечение с помощью SQL».
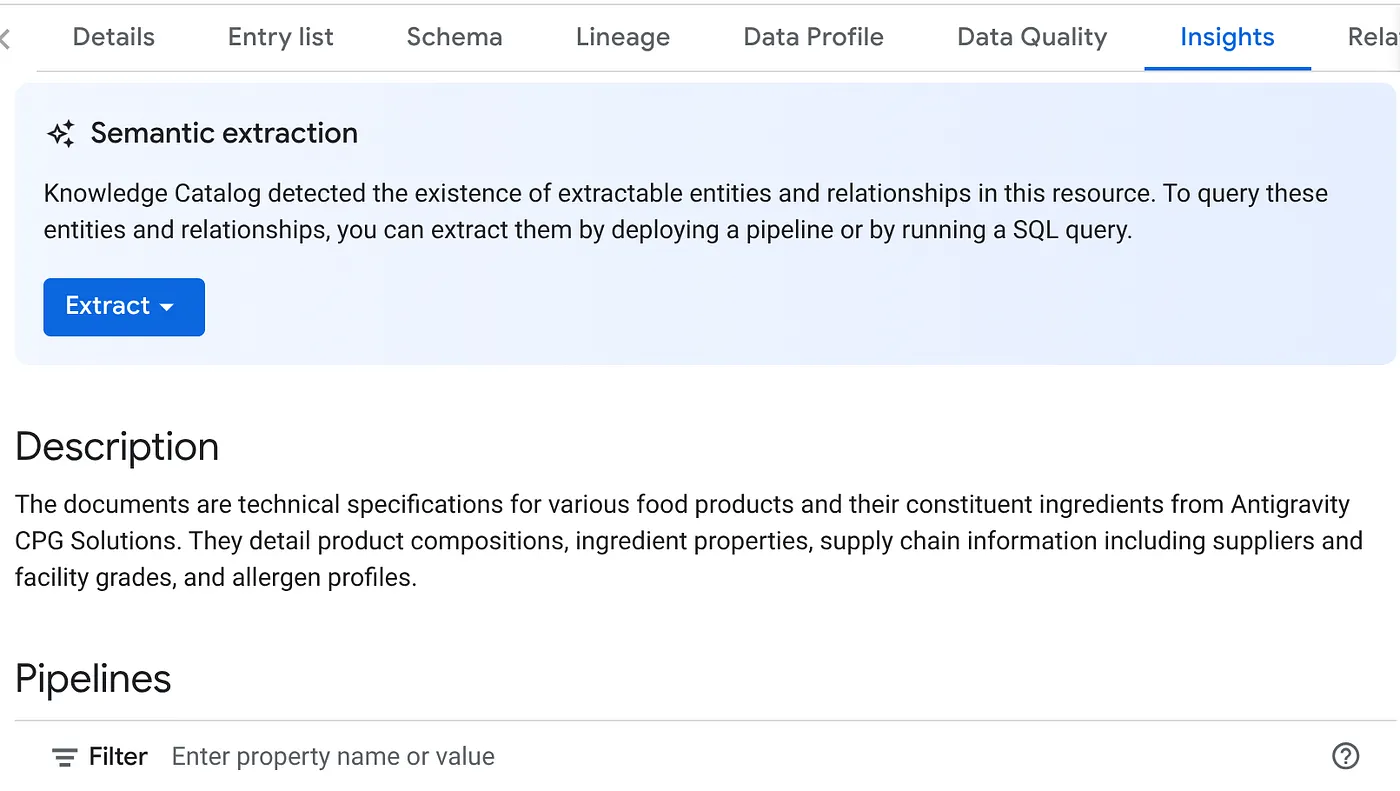
В появившемся диалоговом окне « Извлечение с помощью SQL » укажите в качестве целевого набора данных тот, который вы видели в результатах задания Datascan. Начните вводить его имя, и оно должно отобразиться в автозаполнении. Нажмите кнопку « Извлечь ». В качестве альтернативы вы можете создать новый набор данных и извлечь его оттуда.
Это должно открыть редактор запросов BigQuery с открытой вкладкой, заполненной извлеченными SQL-запросами из результатов сканирования данных.
8. Проверка SQL-запросов и создание схемы.
Если сгенерированный запрос кажется корректным и семантически релевантным вашим неструктурированным данным, смело запускайте его, нажав кнопку «Запустить» в редакторе запросов. Создание схемы, необходимой для структурированного хранения ваших неструктурированных медиафайлов, займет несколько минут.
После этого вы сможете проверить схему, развернув набор данных в панели обозревателя BigQuery Studio, как показано ниже:
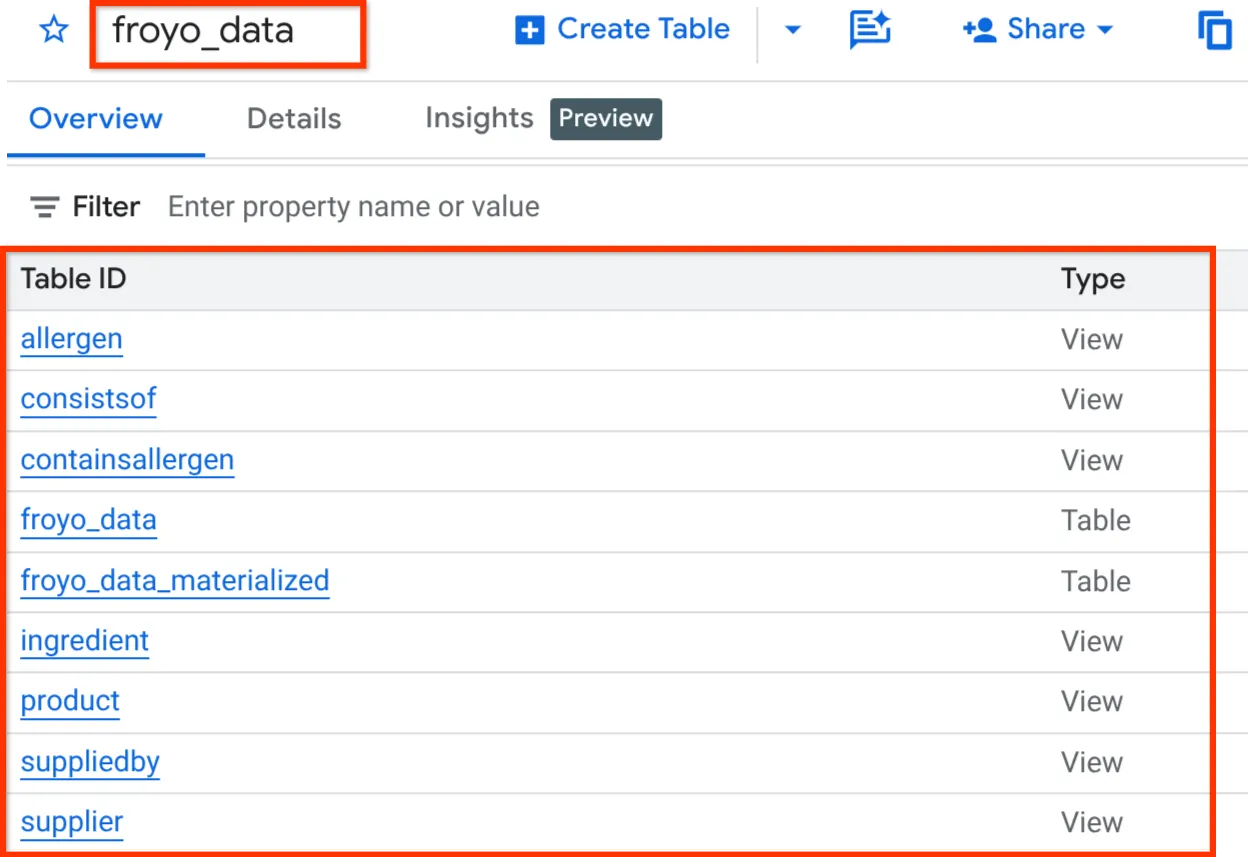
Отлично!!! Было здорово, что мы так быстро справились со всеми этими задачами, связанными с базами данных. Теперь настало время для решающего испытания!
Шаги для продолжения использования данных без платёжного аккаунта:
- Вы можете получить CSV- файлы с данными (данные BigQuery) по ссылке на репозиторий GitHub, указанной выше.
- Сначала создайте набор данных BigQuery, выполнив следующую команду в терминале Cloud Shell:
bq mk --location us-central1 --dataset froyo_data
- Далее загрузите 8 файлов данных (csv-файлы) из репозитория GitHub в свою рабочую директорию, выполнив следующие команды по очереди:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Выполните следующие команды по очереди, чтобы создать эти таблицы с данными из вашего нового набора данных.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
После создания набора данных, таблиц и самих данных вы можете приступить к тестированию и изучению данных, которые мы только что обсуждали.
9. Главное испытание!!!
Допустим, я хочу, чтобы мой агент отвечал на вопросы пользователя, предоставляя достоверную, полную и хорошо структурированную информацию, основанную на фактах. Я собираюсь задать вопрос, на который агент сможет ответить, только обратившись к многочисленным медиафайлам и ссылкам из моего источника.
Вот мой вопрос от пользователя:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
Обычно при обычном поиске или поиске с использованием LLM-запроса результат будет "Ноль ингредиентов". Но мы разработали полноценную систему семантического вывода, преобразующую все наши неструктурированные медиафайлы в структурированные данные. Итак, вот простой SQL-запрос, который извлечет эту информацию:
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
Ура! Посмотрите на результат:
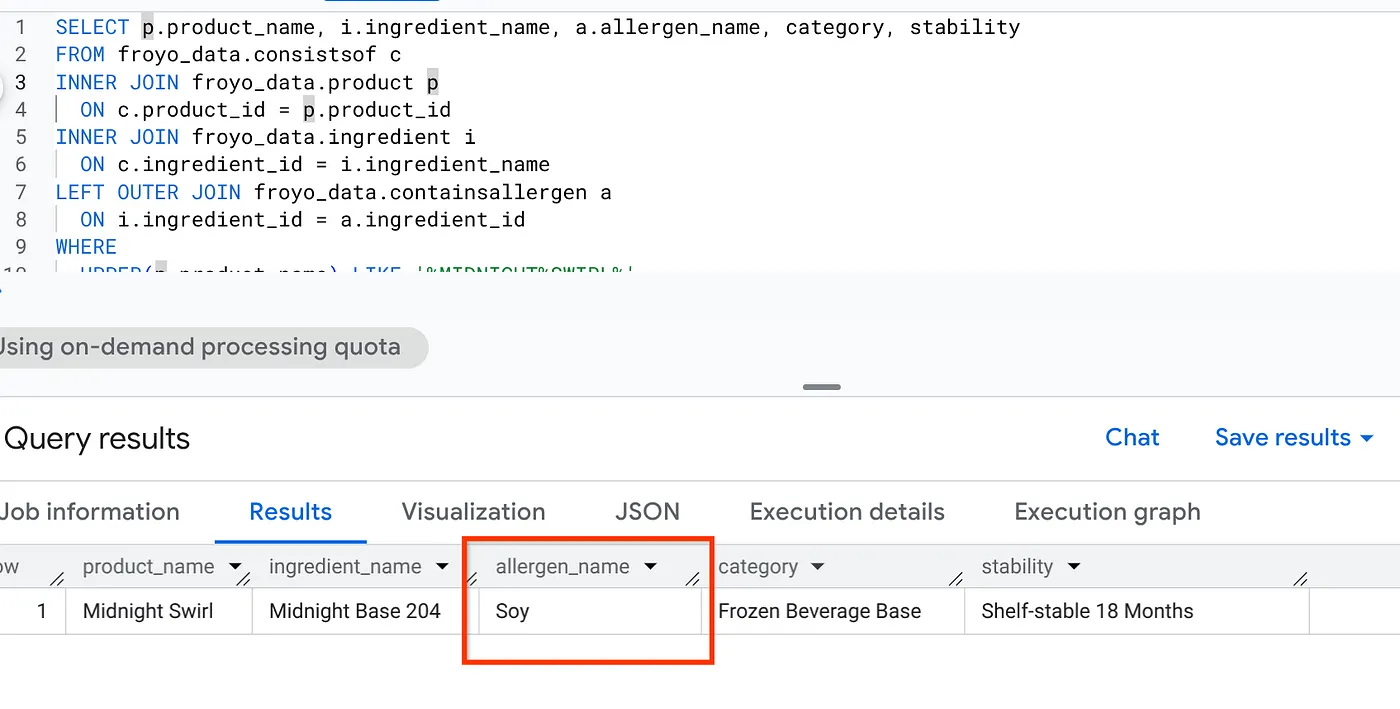
10. Уборка
После завершения этой лабораторной работы не забудьте удалить задание сканирования и таблицы BigQuery, которые оно создало.
Перейдите по ссылке https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery . Выберите задание, которое хотите удалить, щелкнув по вертикальным многоточиям рядом с ним, и нажмите УДАЛИТЬ.
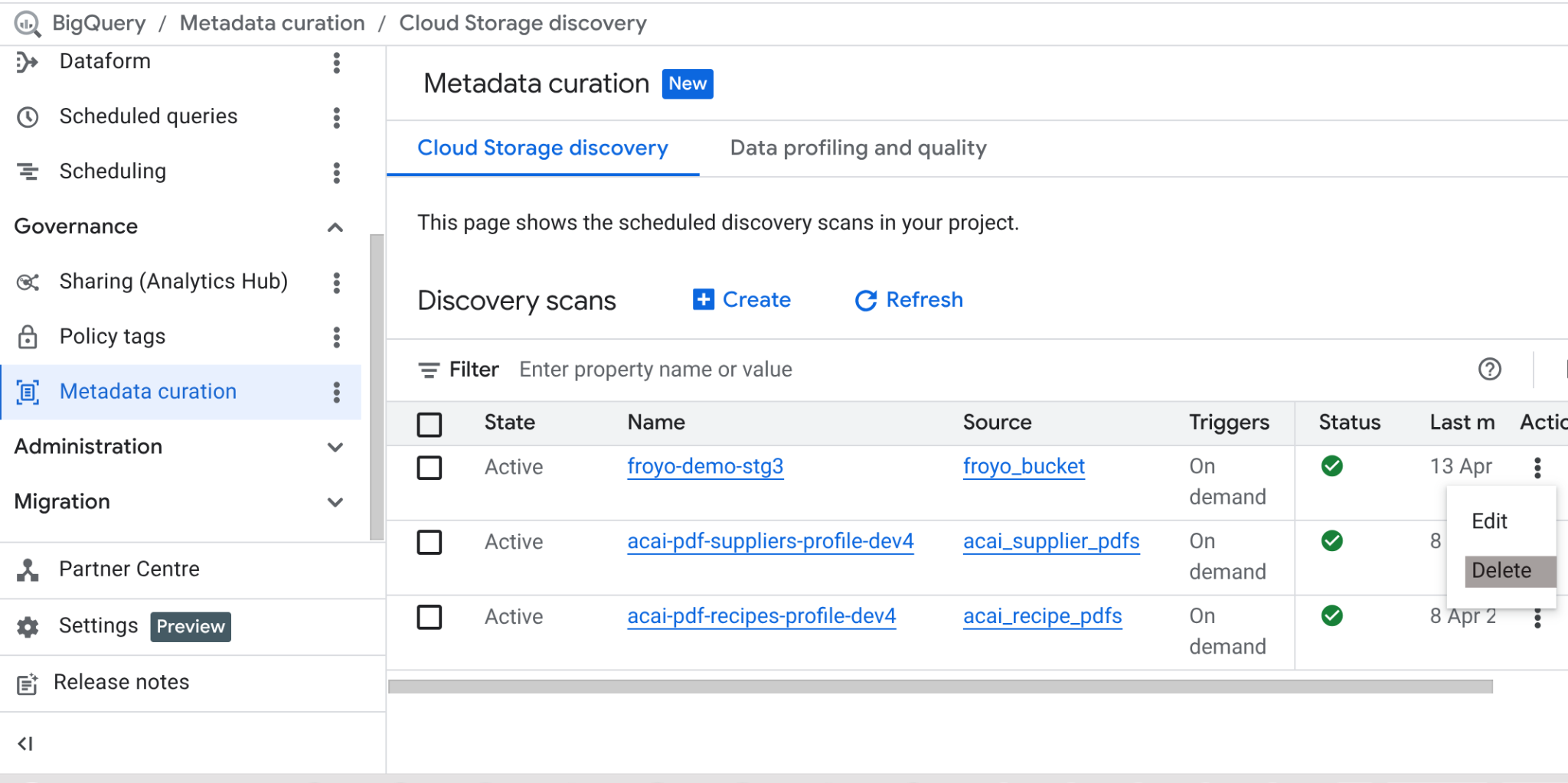
Это должно помочь завершить работу.
11. Поздравляем!
Наша реализация успешно выявила скрытый аллерген. Больше никаких скрытых данных, друзья!!! Во второй части мы объединим эти данные BigQuery в транзакционной системе с AlloyDB, чтобы унифицировать потребности в данных для нашего агентского приложения.