
1. Обзор
В первой части мы успешно преобразовали хаотичные, неструктурированные PDF-файлы в чистые, интеллектуальные и структурированные таблицы в BigQuery с помощью Knowledge Catalog и DataScan. Теперь у нас есть надежное хранилище данных.
Если вам нужно быстро вспомнить, в первой части лабораторной работы мы взяли вымышленную франшизу по производству замороженного йогурта и преобразовали 400 ее неструктурированных PDF-файлов — содержащих текст, таблицы и изображения — в четко структурированные таблицы BigQuery с автоматически установленными связями между ними с помощью BigQuery Knowledge Catalog и Dataplex.
Что вы построите
В этом занятии мы настроим AlloyDB для PostgreSQL и совершим нечто волшебное: напрямую интегрируем наши данные из BigQuery в AlloyDB. Это означает, что наше транзакционное приложение сможет запрашивать данные из хранилища в режиме реального времени, без копирования или дублирования каких-либо данных.
На этом этапе вы, как разработчик, должны задать себе следующий вопрос:
«Если данные уже находятся в BigQuery, зачем добавлять AlloyDB? Почему приложение просто не выполнит запрос SELECT напрямую к BigQuery?»
Вот почему:
С помощью Lakehouse Federation вы можете использовать механизм запросов AlloyDB для обработки транзакционных и аналитических задач вашего приложения из одного интерфейса. Вы также можете материализовать или импортировать эти данные в AlloyDB для более быстрого доступа к ним в ваших приложениях, что позволяет использовать AlloyDB AI и столбцовый механизм .
Вы можете использовать AlloyDB как транзакционную базу данных, а также хранить большие объемы данных в BigQuery или BigLake. Ваши приложения обычно интегрируются независимо с обеими этими системами для доступа к данным в различных сервисах Google Cloud. Lakehouse Federation for AlloyDB позволяет использовать поддержку федеративных запросов AlloyDB, реализованную в виде внешней оболочки данных, для доступа к данным BigQuery и AlloyDB с помощью SQL-интерфейса в AlloyDB.
Вместо создания ненадежного ETL-конвейера для запросов к данным BigQuery из AlloyDB, мы будем использовать федеративные запросы. AlloyDB будет выступать в качестве единой конечной точки, беспрепятственно подключаясь к BigQuery при необходимости.
Начнём строительство!
Что вы узнаете
- Как настроить кластер, экземпляр и сеть AlloyDB одним щелчком мыши
- Как настроить расширение для подготовки к созданию федерации
- Как настроить федерацию из BigQuery в AlloyDB
- Проверьте это
Требования
2. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.

- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если вы хотите пройти аутентификацию
gcloud auth login
- Если ваш проект не задан, используйте следующую команду для его установки:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Включите необходимые API: Выполните эту команду, чтобы включить все необходимые API:
gcloud services enable alloydb.googleapis.com
Подводные камни и устранение неполадок
Синдром «Проекта-призрака» | Вы выполнили команду |
Баррикада Биллинга | Вы активировали проект, но забыли указать платежный аккаунт. AlloyDB — высокопроизводительный движок; он не запустится, если «топливо» (платежный бак) пуст. |
Задержка распространения API | Вы нажали «Включить API», но в командной строке по-прежнему отображается сообщение |
Квота Квагс | Если вы используете совершенно новую пробную учетную запись, вы можете столкнуться с региональной квотой на экземпляры AlloyDB. Если |
3. Краткий обзор данных из части 1.
В этом разделе вам необходимо убедиться, что структурированные данные, извлеченные из неструктурированных PDF-файлов, доступны в BigQuery. Если вы пропустили часть 1 или у вас нет платежного аккаунта, ничего страшного, вы можете выполнить следующие шаги и продолжить:
Перейдите в Google Cloud Console из своей личной учетной записи Gmail и нажмите кнопку «Активировать Cloud Shell» в правом верхнем углу консоли:
Затем выполните действия, описанные в разделе «Без платёжного аккаунта» ниже:
Шаги для продолжения использования данных без платёжного аккаунта:
- Вы можете получить CSV- файлы с данными (данные BigQuery) по ссылке на репозиторий GitHub, указанной выше.
- Сначала создайте набор данных BigQuery, выполнив следующую команду в терминале Cloud Shell:
bq mk --location us-central1 --dataset froyo_data
- Далее загрузите 8 файлов данных (csv-файлы) из репозитория GitHub в свою рабочую директорию, выполнив следующие команды по очереди:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Выполните следующие команды по очереди, чтобы создать эти таблицы с данными из вашего нового набора данных.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Теперь, когда данные загружены в BigQuery, перейдём к следующим шагам.
4. Настройка кластера, экземпляра и сети AlloyDB.
Существует веб-приложение для быстрого запуска, которое поможет вам настроить кластер AlloyDB, экземпляр и другие зависимости. Вы можете выполнить шаги 2–4 в этом лабораторном задании, чтобы настроить его одним нажатием кнопки:
https://codelabs.developers.google.com/quick-alloydb-setup
После создания кластера перейдите на страницу «Обзор кластера» и скопируйте оттуда данные учетной записи службы.
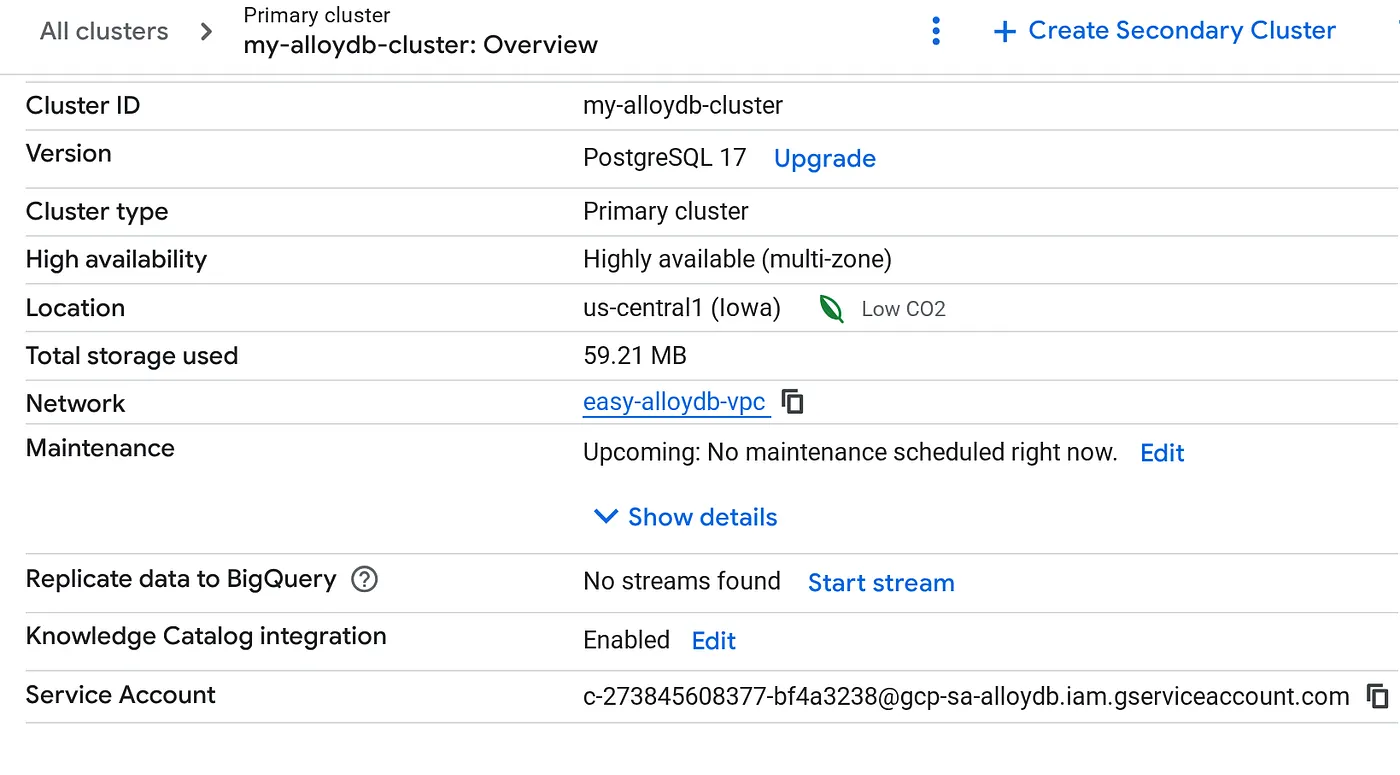
5. Настройка прав доступа
Предоставьте этой учетной записи службы права доступа к BigQuery.
- Перейдите в раздел IAM и администрирование > IAM.
- Нажмите «Предоставить доступ».
- Вставьте адрес учетной записи службы AlloyDB в поле «Новые участники».
- Назначьте следующие роли:
- Средство просмотра данных BigQuery (roles/bigquery.dataViewer): позволяет читать данные.
- Пользователь BigQuery (roles/bigquery.user): разрешает выполнение запросов.
- (Необязательно, но рекомендуется) Пользователь сессии чтения BigQuery (roles/bigquery.readSessionUser): Оптимизирует чтение больших наборов данных через API чтения хранилища.
6. Подключитесь к AlloyDB и включите расширение BigQuery.
Теперь подключимся к нашему новому экземпляру AlloyDB, чтобы настроить расширение федерации. Для этого мы будем использовать AlloyDB Studio.
- На странице обзора кластера (консоль AlloyDB) нажмите « Редактировать основной экземпляр » на вашем основном экземпляре и прокрутите вниз до раздела « Расширенные параметры конфигурации ».
- Перейдите в раздел « Флаги » и включите оба флага, как показано ниже:
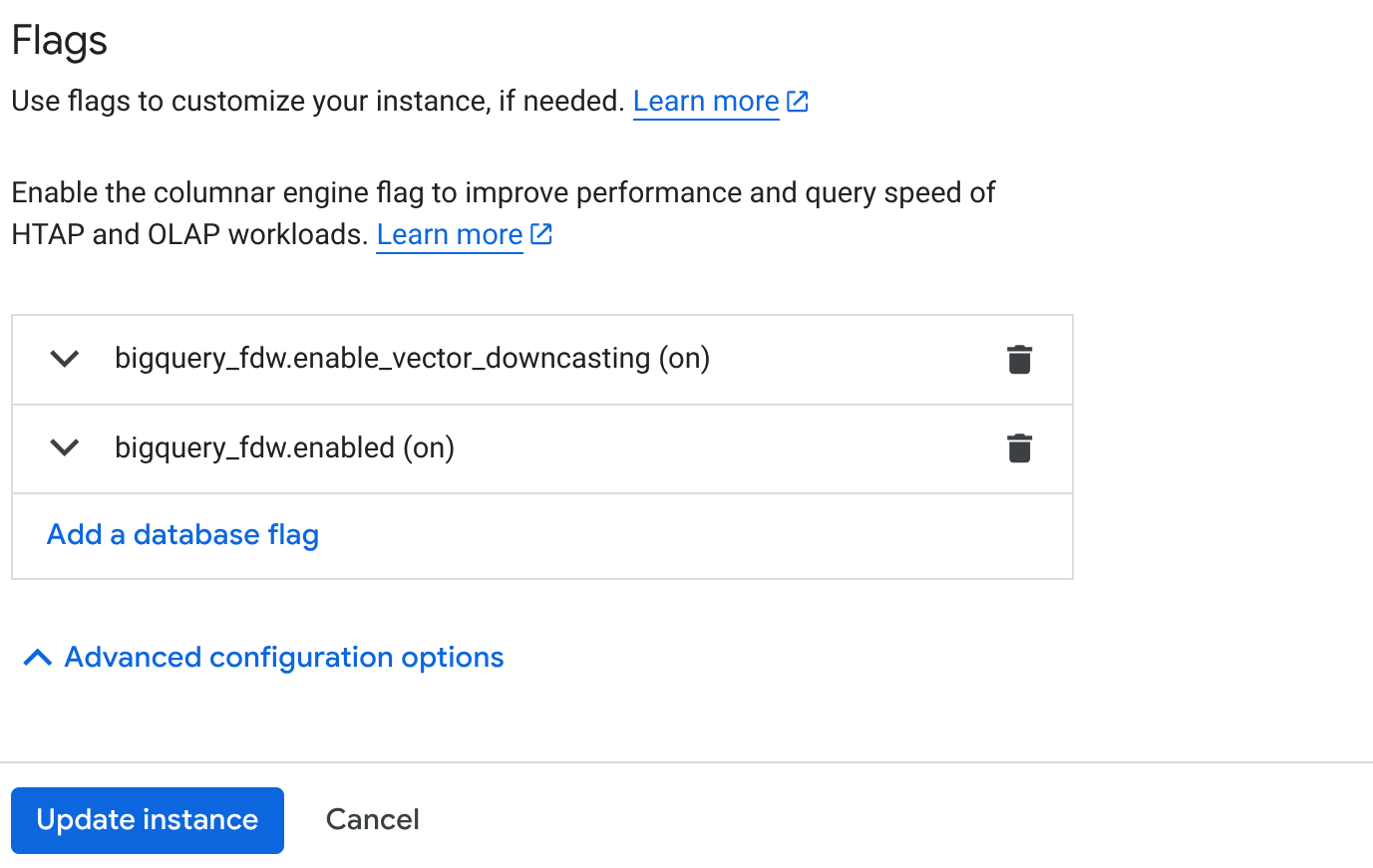 3. Нажмите кнопку **Обновить экземпляр**, обновление займет несколько минут. 4. На странице обзора кластера (консоль AlloyDB) нажмите AlloyDB Studio.
3. Нажмите кнопку **Обновить экземпляр**, обновление займет несколько минут. 4. На странице обзора кластера (консоль AlloyDB) нажмите AlloyDB Studio. 
- Подключитесь к базе данных, используя имя пользователя и пароль, которые вы указали на этапе быстрой настройки AlloyDB.
- После подключения на вкладке «Редактор запросов» справа введите следующие операторы и выполните их по одному:
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- После успешного завершения перейдите в панель проводника слева и прокрутите вниз до таблиц BigQuery:
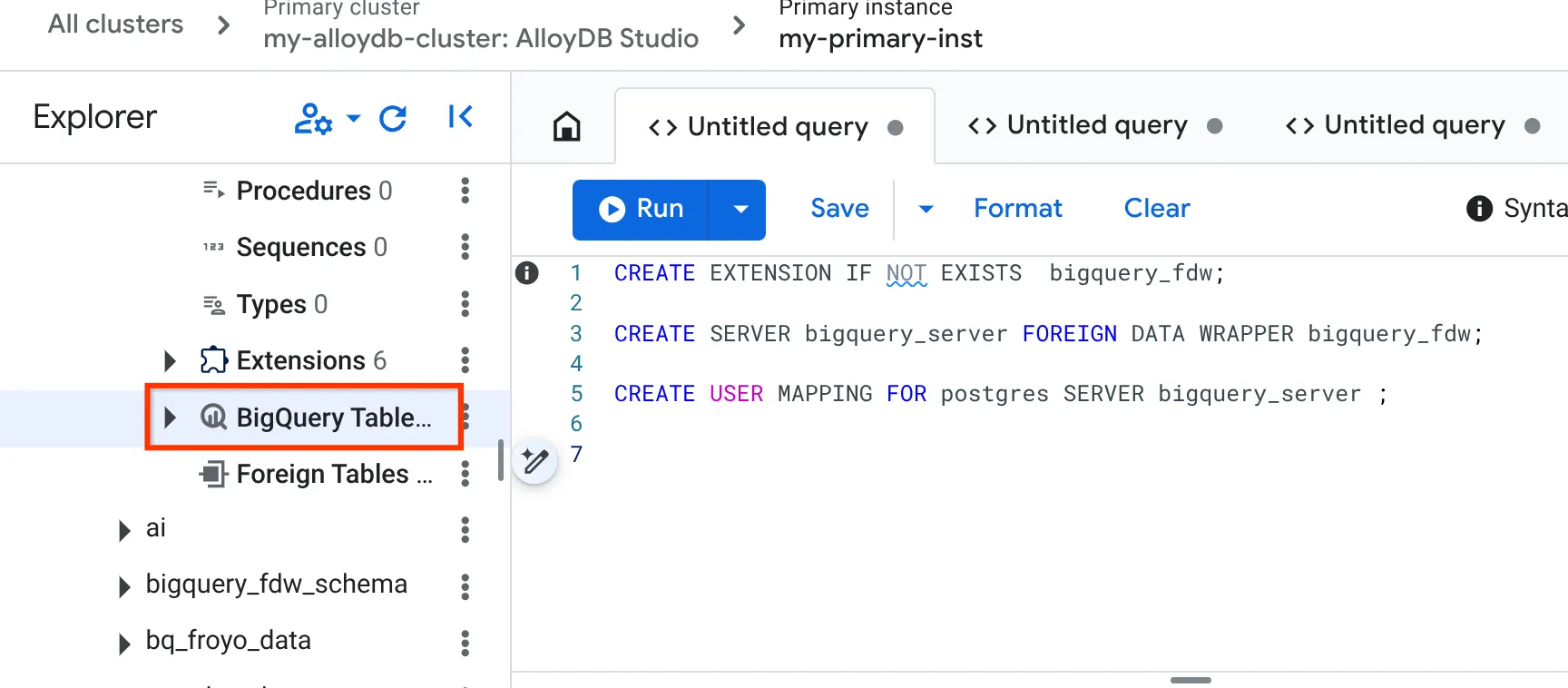
- Нажмите на три точки и выберите « Подключить таблицу BigQuery ».
- В открывшемся всплывающем окне «Подключение таблицы BigQuery» выберите свой project_id и имя набора данных BigQuery (созданного в части 1), из которого вы хотите запросить данные в вашей базе данных AlloyDB.
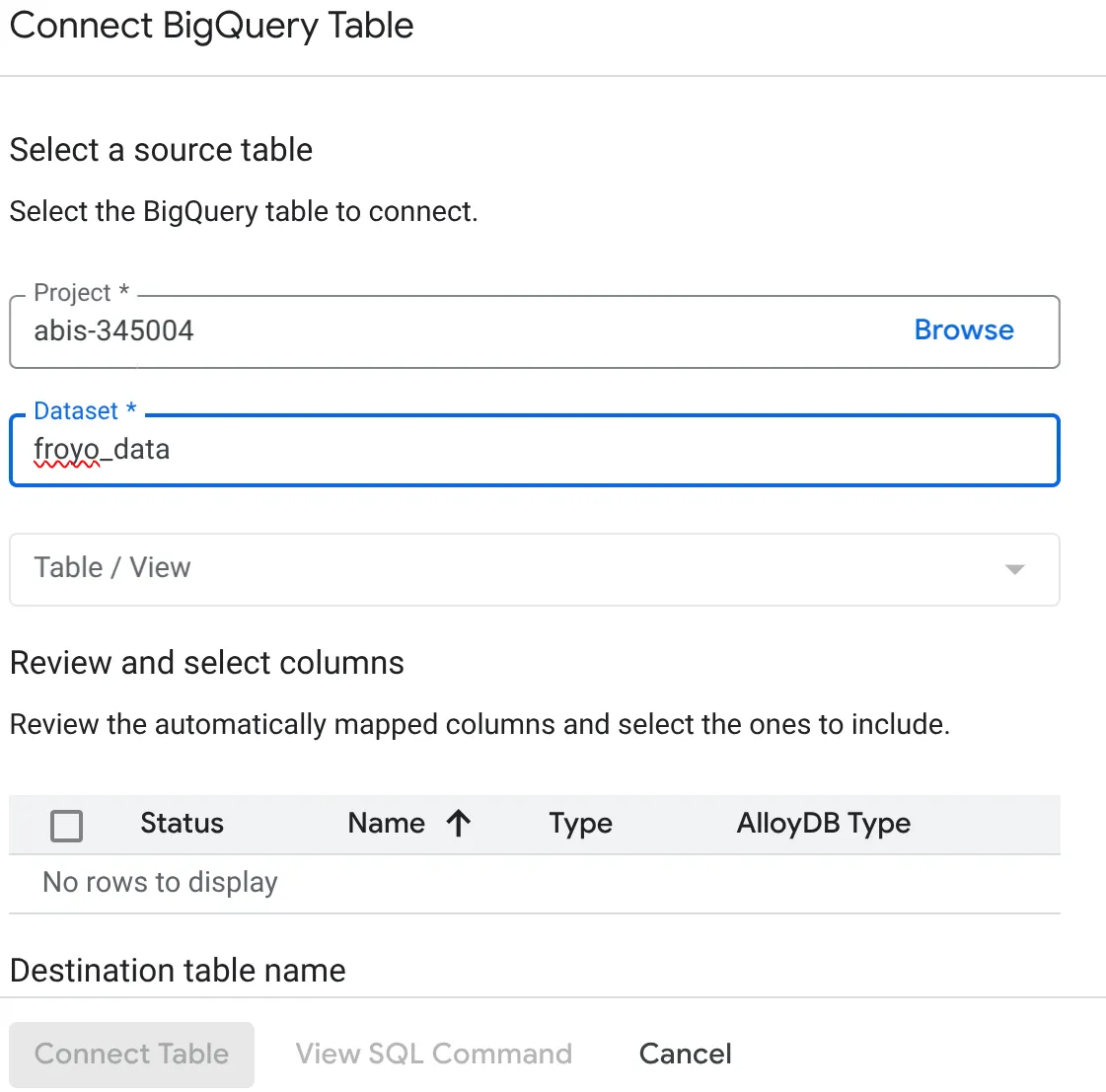
- Выберите каждую таблицу по очереди, чтобы подключить все ваши данные к AlloyDB. Это необходимо для проверки типов столбцов и обеспечения их поддержки в AlloyDB.
Если вы хотите сделать то же самое с помощью SQL-запроса, а не методом "наведи и щелкни" :
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
Волшебство!!!
Мы только что создали «внешние таблицы» в AlloyDB. Они выглядят и работают как обычные таблицы PostgreSQL, но не хранят никаких данных. При выполнении запроса к ним AlloyDB мгновенно передает запрос в BigQuery, извлекает результаты и возвращает их вам.
7. Протестируйте федерацию в AlloyDB.
Давайте убедимся, что мы можем напрямую запрашивать наш огромный аналитический набор данных BigQuery из нашей транзакционной базы данных PostgreSQL.
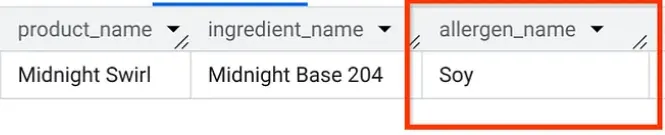
Оставаясь в AlloyDB Studio, давайте выполним запрос, чтобы узнать, какие аллергены содержатся в "Midnight Swirl" (тот же вопрос, который мы задавали в части 1, но на этот раз заданный AlloyDB!):
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
И всё. Вы должны увидеть точно такие же результаты, как и в BigQuery.
8. Уборка
После завершения этой лабораторной работы не забудьте удалить кластер и экземпляр AlloyDB.
Это должно привести к очистке кластера вместе с его экземплярами.
9. Поздравляем с созданием унифицированного слоя данных!
Подумайте о том, чего мы только что добились:
- Наше транзакционное приложение (работающее на AlloyDB) способно обрабатывать быстрые одновременные пользовательские сессии.
- Когда требуются обширные аналитические данные или исторический контекст (например, информация о поставщиках или сложные сопоставления ингредиентов), система обращается к схеме данных froyo_dataschema в BigQuery.
- Никаких ETL-процессов. Никаких сбоев в конвейерах обработки данных. Никаких рассинхронизированных баз данных. Мы храним данные один раз (в BQ) и вычисляем их там, где это необходимо.
Теперь, когда наша база данных — как аналитическая, так и транзакционная — прочна и взаимосвязана, мы готовы к самой интересной части.
В третьей части мы создадим многоагентное приложение, которое будет работать поверх этой архитектуры и управлять бизнес-процессами Froyo!